信貸業務風控策略簡介
- 2019 年 11 月 22 日
- 筆記

分享嘉賓:韓士淵 百融雲創 高級風控總監
編輯整理:張祥
內容來源:百融雲創 & DataFun Talk
出品社區:DataFun
註:歡迎轉載,轉載請註明出處
導讀:大家好,今天分享的主題是信貸業務風控策略。風控業務主要經歷了幾個階段:
- 規則:直接判斷通過,或不通過。
- 數據:可以通過客戶的資產,流水,來判斷客戶的資質優劣。
- 模型:通過數據分析、數據挖掘,找到相應的規律,識別出人工難以找到的部分人群。
但是,數據是有限的,成本很高,會限制風控的上限;同時,如何有效的結合數據、規則、模型,來實現業務目標,這就需要風控策略來完成。
本次分享,將介紹如何在信貸業務中利用數據、規則、模型等完善風控策略,包括原有風控流程及規則優化、定價策略、額度策略等內容。
▌背景
1.1 消費信貸行業背景
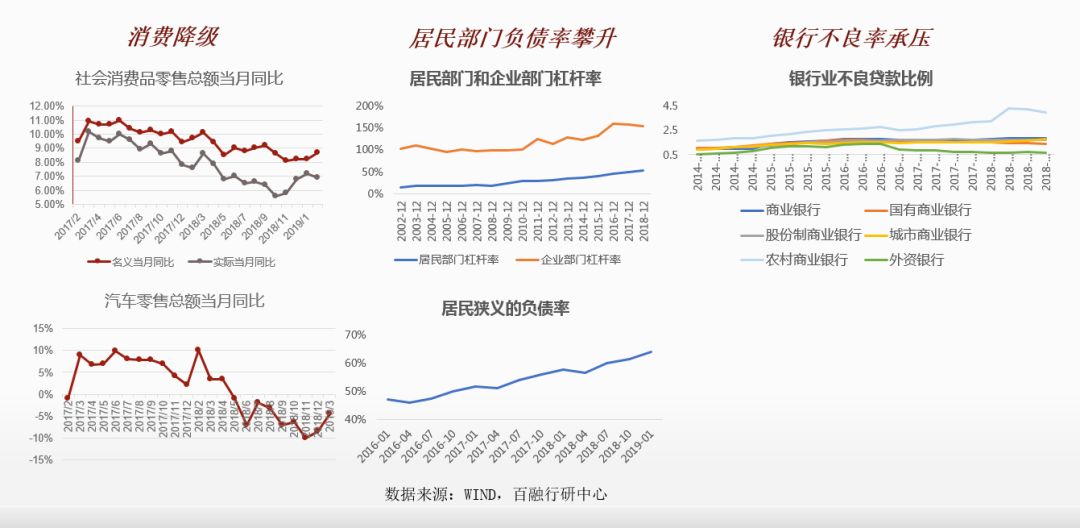
首先給大家普及下消費信貸行業的情況,目前的消費信貸市場和2年前的不太一樣。2年甚至3年以前,它是一個蓬勃發展的階段,但是現在出現了一個情況,就是消費降級,社會消費品零售總額、汽車零售總額增長放緩,居民狹義的負債率攀升,以及銀行不良貸款率增長態勢。信貸市場相較前幾年的市場發生了變化,前幾年屬於資產紅利,風控的價值本質上是資產獲利的多少;目前而言,風控的價值是有效降低風險,減少虧損。因此,對於成本的控制,對於風控的效果,需要有更精細化的應用和實踐。
1.2 消費信貸行業客戶滲透

客戶滲透率
橫軸表示滲透佔比,橫軸越長,滲透率越高;單個顏色越長,表明用戶群重合也越高。當某個產品受到監管,會導致其客戶流失,隨之帶來金融風險問題。以 P2P 和超利貸為例,正常情況下,P2P 的客戶應該比超利貸好,但是由於市場監管的變化,二者的客戶質量已經差不多了。所以,當市場規則發生變化的時候,原來的規則和模型都失效,因此,風控策略就成為了最後一道關卡。
1.3 傳統評分卡的開發流程

評分卡開發流程
① 目標定義
- 定義風控業務的目標,要求熟悉業務邏輯,好壞客戶的定義。
② 數據的整合加工
- 數據:包括用戶的姓名、身份證號、手機號、銀行卡號,購物記錄等
- 清洗:錯誤值、缺失值、離群值
- 衍生變量的處理:引入其它維度的數據,以及做特徵組合
③ 特徵選擇、調優、效果評估
- 特徵選擇:利用統計顯著性、變量重要度、IV 指標,變量聚類等算法來挑選重要的變量,通常還需要採用分箱的方式,將連續值離散化,增加變量的魯棒性,增加了變量的整體穩定性。
- 模型調優:在訓練集上調整模型參數,對比 KS 值的變化,選擇 KS 最大的模型。
- 效果評估:對比訓練集、測試集、樣本外數據集的 KS 值,查看模型是否穩定。
- 共線性:此外,還需要檢驗模型變量之間是否存在共線性問題,一般計算 VIF 值,如果 VIF>5,表明存在共線性問題,該變量不可用。
- 模型穩定性:計算 PSI 值,如果 PSI<0.1,則模型穩定性較好,如果 PSI>0.2,則模型穩定性較差,不可用。
④ 模型打分、部署、監控
- 對變量每個分箱都打一個分值,形成一張評分卡(相較於機器學習,優點是可解釋性強),最後上線部署。
1.4 機器學習模型開發流程

機器學習開發流程
相較於評分卡開發流程,差異如下:
① 機器學習中人工介入少;
② 可解釋性差;
③ 重點是調整參數,避免模型過擬合。
▌貸前風控流程與策略
2.1 風控流程設計
目標是發現風險點(包括:信用卡欺詐、團伙窩案、高危用戶等),降低風險;同時降低成本、提升效率。
銀行的風控流程,以某四大行信用卡業務為例。
案例1:

① 身份核查:驗證身份的真實性,是否為本人、是否有欺詐等行為。
② 剔除其它點影響:行內黑名單、負面信息驗證。
③ 將成本低的借貸意向驗證放在成本高的團伙欺詐識別前面,達到節省成本的作用。
④ 結合人行拒絕規則、人行數據以及第三方數據建模,其優點是結合雙方數據優勢,模型效果會較好。但數據不穩定時,模型二次迭代工作量較大。
案例2:

相較於案例1,案例2較為保守,沒有將人行數據和三方數據結合起來做來模型,對於拒絕的用戶再次做人工審核,將符合的用戶再次撈起來。這樣做數據成本低,但是有人行客戶模型效果下降,誤殺率增加。
案例3:

同案例1的區別:將各個數據構建子模型,然後整合為一個綜合模型,如收入數據、支出數據建模。差異在於客群建模的差異,將不同的客群用戶分開做模型。這樣在評分二次迭代時,模型變量調整較少,主要調整各變量權重即可。但是在極端情況下,會出現某個評分變量不顯著的情況。
綜合上述三個案例,風控策略並不是完全依賴於成本,還要依賴於實際業務情況和業務目標。很多時候,風控流程是根據業務情況來進行的。
2.2 利率策略和額度策略

完成模型構建後,對每位客戶打分,統計每個分段內的壞賬率,以控制收益與成本。怎麼給合適的利率和額度呢?
① 利率策略:

風險與利率計算公式
A 表示額度,r 表示預期收益率,p 表示壞賬率,對每個評分段分別計算預期收益 ri,但通常情況下,利率是固定的,當分數在某個閾值時,就直接拒絕掉。
② 額度策略:

風險情況與平均每件額度
額度策略本身受限於產品設計、客戶需求及競品情況,結合自身成本和風險偏好,可初步確定產品的額度區間 [A1,A2] 和件均 A0。由於右圖中倆個梯形的面積應該是相等的,因此,可以得到關於 A0 的計算表達式,由於 A0、A1、A2 都是已知的,因此我們能計算出 A0 對應的常數 K0,這樣就可以把右圖中藍色的折線擬合出來,即相對最優的一個解。可以實現,根據不同的分位數,給不同的額度。那麼,這麼做合理嗎?它是需要滿足一定的假設條件的:
- 額度在借款區間中變化時,同一分段的壞客戶佔比沒有明顯差異;
- 評分有較好的排序能力,每一分段對應的壞客戶佔比有顯著差異。
③ 額度策略優化:

額度策略優化
採用 sigmoid 來替代分段函數,確定基礎風險額度。對於大額借貸,還是考慮用戶的償債能力,即收入,資產,流水等指標,先算出基礎風險額度,再結合收入等指標,差異化調整基礎額度。
2.3 風控規則有效性診斷

各規則拒絕人群評分分佈
怎麼確認規則的有效性和調整?
首先對拒絕客戶進行打分,然後對比『通過客戶評分分佈』和『拒絕客戶評分分佈』,找出異常規則,再把各規則進行分組評分分佈對比,最後進行規則調整。
如上圖,對拒絕的客戶重新打分,與整體樣本中拒絕用戶評分對比:
- 規則1,效果最好,最低分段的用戶拒絕率高,高分段的用戶拒絕率。
- 規則2,效果不明顯,與整體數據的分佈差異不大,效果不明顯。
- 規則3,太過於波動,不穩定。
2.4 信用評估模型的構建與優化——模型優化

風控建模流程圖
基礎的風控建模流程如上。在進行模型迭代時,主要利用通過樣本進行模型構建,被迭代的模型拒絕率較高;如不考慮模型拒絕人群,進行拒絕推斷,則新模型的應用效果會有明顯下滑,且多次迭代後,新模型的效果提升比例會越來越小。因此重要的一點在於,如何做拒絕推斷,找到之前被規則淹沒的特徵。

解決樣本淹沒問題的三種方案
為了解決樣本淹沒問題,將規則拒絕的樣本加入模型訓練階段,有三種方案:
① 比例分配:將拒絕對象隨機劃分為「好」和「差」的賬戶,再次帶入評分流程中,構建一個模型;
② 簡單增強法:對拒絕客戶打分,並選取某個 cutoff 點進行區分,cutoff 點的兩邊分別為「好」和「壞」客戶,代入模型中迭代;
③ Parcelling:是結合比例分配和簡單增強法,對拒絕客戶打分,對每個分段按照比例進行好壞客戶劃分,再次代入模型進行迭代。

模型優化
我們的做法是使用通過的樣本和通過的壞客戶構建模型1,拿當前時間點跑客戶評分,分為高分段和低分段,把原來拒絕客戶跑完模型後高分段的樣本剔除掉,對低分段特徵做 parcelling,然後推斷好客戶和壞客戶,合在一起再做模型2,然後不斷的迭代這個模型,這時跑出來的模型,要比剛剛介紹的模型1方法要好。但是這種拒絕推斷是沒辦法從樣本上解決樣本有偏的問題,只能從某種程度上解決。
以上就是今天要分享的內容,謝謝大家。

嘉賓介紹
韓士淵,百融雲創金融科技部高級風控總監。負責百融雲創非銀風控業務,帶領團隊完成了眾多金融機構的風控體系構建,包括金融產品設計、整體審批流程設計、風控模型建設、審批決策建議等,在貸前審批、貸中監控及貸後管理等不同業務階段有豐富經驗。
——END——