智能機械人在滴滴出行場景的技術探索
- 2019 年 11 月 22 日
- 筆記

分享嘉賓:熊超 滴滴 AI Labs
編輯整理:Hoh Xil
內容來源:AI 科學前沿大會
出品社區:DataFun
註:歡迎轉載,轉載請註明出處
本次分享是在2019年 AI 科學前沿大會上的分享,主要介紹智能對話機械人在滴滴出行場景中的技術探索,主要內容為:
- 單輪問答
- 多輪對話
- 整體架構
▌單輪問答
單輪問答指識別用戶問題,並給出相應答案。這種場景下的目標是做到識別準確,盡量理解用戶問題,給出合適的答案。
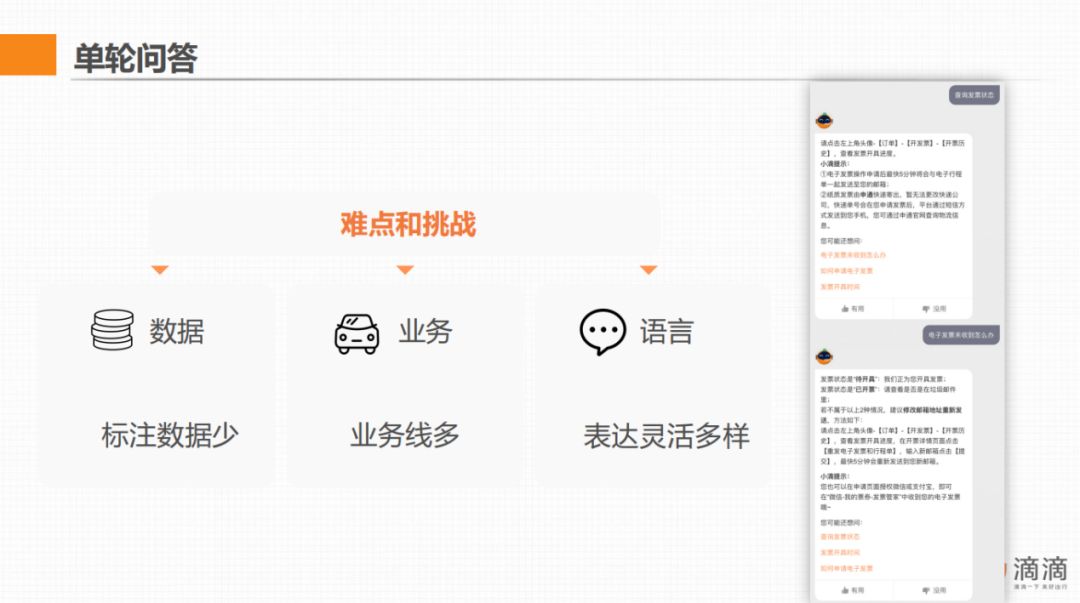
開發過程中的難點和挑戰:
- 數據:標註數據少,這是 NLP 領域的痛點問題,因為標註成本相對較高;
- 業務:業務線比較多,我們目前支持滴滴場景下的業務線有10多個,會導致數據標註的問題更突出,數據量少的業務,可標註的數據更少。
- 語言:用戶的表達方式靈活多樣,即同一個語義有多種表達方式。
針對上述問題,我們想了一些辦法,分析了滴滴場景下和其他智能客服的區別,比如快車和專車業務線,都是由不同模型來支持的,但是快車和專車業務其實是非常相似的,經過統計分析,二者知識點重複率接近一半。我們考慮是否可以把大業務線的數據遷移到小的業務線,但是當我們細看數據的時候,發現還是不一樣的,因為不同業務場景下的相似問,還是有區別的,比如業務獨有的知識,不能直接用在其他業務線上。

為了解決這些問題,我們一直在想數據如何更好的去遷移,減少數據的標註量。提出了類似 Multi-Task 多任務學習的架構,因為我們有不同的業務線,如果不考慮 Multi-Task 結構的話,每個業務線會有一個模型。有了 Multi-Task 之後,可以多個業務線共享一個語義模型,讓模型的泛化能力更強,為了解決不能直接映射的問題,每個業務線還有獨立的模型在後面,優化各自的目標。語義模型可以有任意模型,我們嘗試過 CNN、LSTM、Transformer、Bert 等。

上圖為我們加上 Multi-Task 之後的一些實驗結果,包括 CNN、LSTM、Transformer、Bert,其中,橙色和藍色為 Top1 準確率,灰色和黃色為 Top3 準確率,橙色為模型本身的結果,藍色為模型+Multi-Task 之後的結果,從結果上看,CNN+Multi-Task 後有一定的提升,從這一點上看 Multi-Task 還是有幫助的,進而我們做了更多的實驗,比如 Bert+Multi-task 的 Top1 準確率相比於 CNN 有了顯著的提升,在本身沒有增加新的成本的情況下,提升顯著,為什麼加了 Multi-Task 後結果這麼好呢?我們發現,新的模型特徵抽取的能力比較強,但是也存在一些特點,需要足夠的數據,才能讓模型發揮出能力,我們看四個 Multi-task 模型對比(藍色),給了充足的數據後,效果提升明顯。效果好是不是因為模型好就可以了?也不是,其實如果單獨業務線,同樣的數據下,從圖中不使用 Multi-task 模型結果(橙色)的對比可以看出 CNN 的效果反而更好。原因是在數據不充足的情況下,複雜的模型參數更多,容易引起過擬合。

除了分類的結構,我們也嘗試了搜索+語義匹配+排序的架構,主要是用來做情緒安撫,思路是把候選的問答對語料,通過搜索、生成式模型得到候選,然後經過粗排,粗排是用文本相關性的分數來計算,最後交給多輪對話深度匹配模型,主要參考了去年這篇的論文:Modeling Multi-turn Conversation with Deep Utterance Aggregation ,DUA 的特點是除了計算當前的對話,還會把上下文建模進來,重新考慮。比如情緒回復,如果是一個負向語句,如果單看這句話,它的回復可能是非常通用的,但是結合上下文,比如有的司機聽不到單了,然後他會回復一些負面語句,這時我們的回復是針對聽單場景的安撫。

除此之外,我們還有些離線的工作:
模型訓練:如上圖,為 Multi-Task 整體的一個效果,我們建立了一個每天模型自動更新的 pipeline,包括自動測試、自動上線。剛剛也提過了,數據很重要,我們會標註新的數據,來解決新的問題的出現,所以我們採用的是主動學習 Active Learning 的思想,去對邊界樣本進行採樣,這樣標註效率會更高,構建模型訓練及在線服務的閉環,來達到每天模型更新的效果,讓新的知識、新的問題,更快的更新到我們的服務上來。讓機械人有了自我學習進化的能力。
數據標註:其實在現有的標註語料中,還存在噪音,準確率沒有那麼高。我們通過聚類的方式,把已經標註的語料聚類,這時有些樣本是偏離聚類中心的,然後把偏離的樣本通過人工檢查,如果真的錯了,就可以把噪音刪除,如果是對的則保留。
▌多輪對話

在出行場景下,存在倆大類的問題,一類是諮詢了問題,比如用戶需要諮詢一些政策、規則等信息;還有一類是尋求解決的,這兩類問題,單輪問答都很難解決用戶問題,為此我們提出了多輪對話。
1. 整體架構

我們可以看下這個例子,比如有乘客反饋,司機繞路,如果是單輪的話,只能給一個答案,而我們現在可以通過交互的方式來引導用戶去選擇訂單,選擇訂單之後,我們可以直接調用後台的接口服務能力,去判斷是否繞路了,如果真實存在,我們就會直接在機械人里把多收的費用返還給乘客,提升了用戶體驗。
具體的方法:將傳統的多輪對話,多輪交互,引入滴滴客服機械人。主要包括幾大模塊:
① 語言理解
- 意圖識別,知識點的識別,明確問的問題是什麼
- 屬性抽取,可以理解為選擇訂單,日期等等
② 對話管理
- 對話狀態跟蹤:結合當前語義理解的結果,並結合歷史對話,上下文綜合來看,得到對話的狀態(Act 和 slot)
- 對話策略:給定對話狀態,選擇對應的動作,目前主要採用狀態機的方式,並嘗試強化學習對話策略
③ 語言生成
- 有了動作之後,我們就需要生成用戶可以理解的語言。
以上是多輪對話的整體架構。
2. 語言理解

意圖識別:
我們採用的模型為 BERT + Multi-Task Learning
槽位抽取:
我們主要是基於規則和模型結合的方法,如選訂單的組件,模型如 BILSTM + CRF 模型, 來對槽位信息進行抽取。
3. 對話管理

這個剛剛有介紹過,右圖為狀態機,基於規則配置,左圖為我們在研發的強化學習模型,它需要一個用戶的模擬器來模擬用戶,抽樣用戶目標,根據目標和機械人去交互,從交互中生成經驗,再根據經驗進行學習,達到自動學習的效果,而不是像右邊狀態機,是由領域內的專家來配置的。
4. 智能反問

如果用戶表達的意圖不清晰,無法精確定位問題的時候,我們採用了智能反問技術:
- 圖譜查詢:通過圖譜去查詢,得到相關聯的知識點。
- 反問引導:產品形式上,在這個例子中,我們會引導用戶,會問用戶是實時單還是預約單,用戶只要選擇之後,會給用戶推送一個更具體的、有針對性的答案。
5. 閑聊-寒暄

機械人里都會涉及到閑聊,比如「你好」,「謝謝」之類的。針對這些問題做的工作有:
分類模型、檢索匹配等,專家編寫的答案,現在我們在探索的是生成模型,讓答案更靈活。
▌機械人架構

我們整體看下機械人的架構:用戶的請求來了之後,將「查詢」和「上下文」作為輸入去查詢 frontend,frontend 作為機械人的中控,也會包括一些業務邏輯,然後通過ranker模塊做分發和選擇,下面有問答型、任務型、多輪對話型、閑聊型、圖譜型等,綜合的做一個仲裁去選擇,給到用戶一個最終的答案。

最後講一下智能客服的整體架構:
產品:我們支持的業務,包括智能客服(的士、快車、專車等一系列業務)、司機助手、國際化客服等。
這就是我們整體的架構,這就是我今天要分享的內容,謝謝大家。

嘉賓介紹
熊超,滴滴AI Labs 智能對話團隊負責人。2010年畢業於北京航空航天大學模式識別與智能系統專業。畢業後加入騰訊從事搜索廣告算法策略研發工作。2013年加入阿里巴巴從事智能人機交互方向。2017年加入滴滴,組建智能客服算法團隊,主要研究方向為多輪對話,問答,智能輔助,強化學習和智能推薦。擔任頂級期刊和學術會議,如TKDE,KDD等審稿人。多項智能客服領域技術專利發明人,專利覆蓋多輪對話、問答、閑聊、智能預測等。
——END——


