Android全面解析之由淺及深Handler消息機制
前言
很高興遇見你~ 歡迎閱讀我的文章。
關於Handler的博客可謂是俯拾皆是,而這也是一個老生常談的話題,可見的他非常基礎,也非常重要。但很多的博客,卻很少有從入門開始介紹,這在我一開始學習的時候就直接給我講Looper講阻塞,非常難以理解。同時,也很少有系統地講解關於Handler的一切,知識比較零散。我希望寫一篇從入門到深入,系統地全面地講解Handler的文章,幫助大家認識Handler。
這篇文章的講解深度循序漸進,不同程序的讀者可選擇對應的部分查看:
- 第一部分是對於Handler的入門概述。了解一個新事物,需要問三個問題:是什麼、為什麼、怎麼用。包括關於Handler的結構等都有介紹。
- 第二部分是在對Handler有一定的認知基礎上,對各個類進行詳細的講解和源碼分析。
- 第三部分是整體的流程分析以及常見問題的解析。
- 最後一部分是Android對於消息機制設計的講解以及全文總結。
文章基本涵蓋了關於Handler相關的知識,因而篇幅也比較長
考慮過把文章分割成幾篇小文章,考慮到閱讀的整體性以及方便性,最終還是集成了一篇大文章
文章成體系,全面地講解知識點,而不是把知識碎片化,否則很難真正去理解單一的知識,更不易於對整體知識的把握
讀者可自行選擇感興趣的章節閱讀
那麼,我們開始吧。
概述
什麼是Handler?
準確來說,是Handler機制,Handler只是Handler機制中的一個角色。只是我們對Handler接觸比較多,所以經常以Handler來代稱。
Handler機制是Android中基於單線消息隊列模式的一套線程消息機制。
他的本質是消息機制,負責消息的分發以及處理。這樣講可能有點抽象,不太容易理解。什麼是「單線消息隊列模式」?什麼是「消息」?
通俗點來說,每個線程都有一個「流水線」,我們可往這條流水線上放「消息」,流水線的末端有工作人員會去處理這些消息。因為流水線是單線的,所有消息都必須按照先來後到的形式依次處理(在Handler機制中有「加急線」:同步屏障,這個後面講)。如下圖:
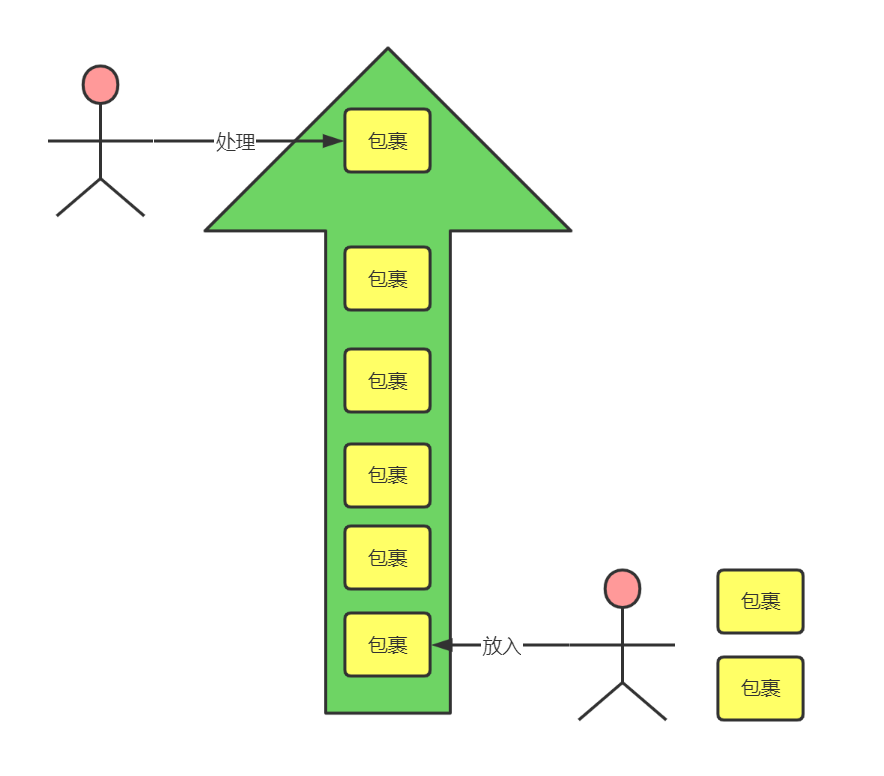
放什麼消息以及怎麼處理消息,是需要我們去自定義的。Handler機制相當於提供了這樣的一套模式,我們只需要「放消息到流水線上」,「編寫這些消息的處理邏輯」就可以了,流水線會源源不斷把消息運送到末端處理。最後注意重點:每個線程只有一個「流水線」,他的基本範圍是線程,負責線程內的通信以及線程間的通信。每個線程可以看成一個廠房,每個廠房只有一個生產線。
兩個關鍵問題
了解Handler的作用前需要了解Handler背景下的兩個關鍵問題:
- 不能在非UI創建線程去操作UI
- 不能在主線程執行耗時任務
我們普遍的認知是:不能在非主線程更新UI。但這是不準確的,如果我們在子線程更新了UI,看看報錯信息是什麼:

筆者留下了英語渣渣的眼淚,百度翻譯一下:
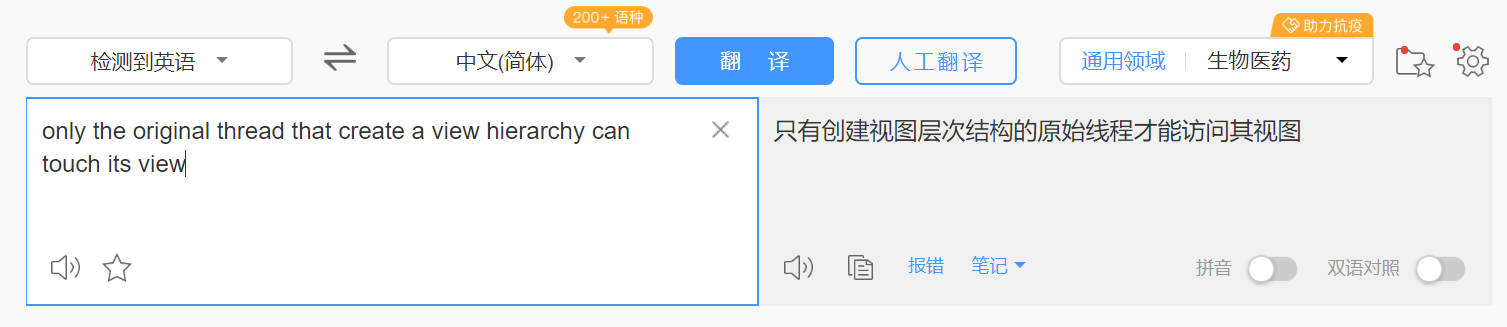
只有創建視圖層次結構的原始線程才能訪問其視圖。但為什麼我們一直都說是非主線程不能更新ui?這是因為我們的界面一般都是由主線程進行繪製的,所以界面的更新也就一般都限制在主線程內。這個異常是在viewRootIimpl.checkThread()方法中拋出來的,那可不可以繞過他?當然可以,在他還沒創建出來的時候就可以偷偷更新ui了。閱讀過Activity啟動流程的讀者知道,ViewRootImpl是在onCreate方法之後被創建的,所以我們可以在onCreate方法中創建個子線程偷偷更新UI。(Actvity啟動流程解析傳送門)但還是那句話,可以,但沒必要去繞過這個限制,因為這是谷歌為了我們的程序更加安全而設計的。
為什麼不能在子線程去更新UI?因為這會讓界面產生不可預期的結果。例如主線程在繪製一個按鈕,繪製一半另一個線程突然過來把按鈕的大小改成兩倍大,這個時候再回去主線程繼續執行繪製邏輯,這個繪製的效果就會出現問題。所以UI的訪問是決不能是並發的。但,子線程又想更新UI,怎麼辦?加鎖。加鎖確實可以解決這個問題,但是會帶來另外的問題:界面卡頓。鎖對於性能是有消耗的,是比較重量級的操作,而ui操作講究快准狠,加鎖會讓ui操作性能大打折扣。那有什麼更好的方法?Handler就是解決這個問題的。
第二個問題,不能在主線程執行耗時操作。耗時操作包括網絡請求、數據庫操作等等,這些操作會導致ANR(Application Not Responding)。這個是比較好理解的,沒有什麼問題,但是這兩個問題結合起來,就有大問題了。數據請求一般是耗時操作,必須在子線程進行請求,而當請求完成之後又必須更新UI,UI又只能在主線程更新,這就導致必須切換線程執行代碼,上面討論了加鎖是不可取的,那麼Handler的重要性就體現出來了。
不用Handler可不可以?可以,但沒必要。Handler是谷歌設計來方便開發者切換線程以及處理消息,然後你說我偏不用,我自己用Java工具類,自己弄個出來不可以嗎?那。。。請收下小的膝蓋。
為什麼要有Handler?
先給結論:
- 切換代碼執行的線程
- 按順序規則地處理消息,避免並發
- 阻塞線程,避免讓線程結束
- 延遲處理消息
第一個作用是最明顯也是最常用的,上一部分已經講了Handler存在的必要性,android限制了不能在非UI創建線程去操作UI,同時不能在主線程執行耗時任務,所以我們一般是在子線程執行網絡請求等耗時操作請求數據,然後再切換到主線程來更新UI。這個時候就必須用到Handler來切換線程了。上面討論過了這裡不再贅述。
這裡有一個誤區是:我們的activity是執行在主線程的,我們在網絡請求完成之後回調主線程的方法不就切換到主線程了嗎?咳咳,不要笑,不要覺得這種低級錯誤太離譜,很多童鞋剛開始接觸開發的時候都會犯這個思維錯誤。這其實是理解錯了線程這個概念。代碼本身並沒有限制運行在哪個線程,代碼執行的線程環境取決於你的執行邏輯是在哪個線程。這樣講可能還是有點抽象。例如現在有一個方法void test(){},然後兩個不同的線程去調用它:
new Thread(){
// 第一個線程調用
test();
}.start();
new Thread(){
// 第二個線程調用
test();
}
此時雖然都是test這個方法,但是他的執行邏輯是由不同的線程調用的,所以他是執行在兩個不同的線程環境下。而當我們想要把邏輯切換到另一個線程去執行的時候,就需要用到Handler來切換邏輯。
第二個作用可能看着有點懵。但其實他解決了另一個問題:並發操作。雖然切換線程解決了,如果主線程正在繪製一個按鈕,剛測量好按鈕的長寬,突然子線程一個新的請求過來打斷了,先停下這邊的繪製操作,把按鈕改成了兩倍大,然後邏輯切回來繼續繪製,這個時候之前的測量的長寬已經是不準確的了,繪製的結果肯定也不準確。怎麼解決?單線消息隊列模型。在講什麼是Handler那部分簡單介紹過,就是相當於一個流水線一樣的模型。子線程的請求會變成一個個的消息,然後主線程依次處理,那麼就不會出現繪製一半被打斷的問題了。
同時這種模型也不止用於解決ui並發問題,在ActivityThread中有一個H類,他其實就是個Handler。在ActivityThread中定義了一百多中消息類型以及對應的處理邏輯,這樣,當需要讓ActivityThread處理某一個邏輯的時候,只需要發送對應的消息給他即可,而且可以保證消息按順序執行,例如先調用onCreate再調用onResume。而如果沒有Hanlder的話,就需要讓ActivityThread有一百多個接口對外開放,同時還需要不斷進行回調保證任務按順序執行。這顯然複雜了非常多。
我們執行一個Java程序的時候,從main方法入口,執行完成之後,馬上就退出了,但是我們android應用程序肯定是不可以的,他需要一直等待用戶的操作。而Handler機制就解決了這個問題,但消息隊列中沒有任務的時候,他就會把線程阻塞,等到有新的任務的時候,再重新啟動處理消息。
第四個作用讓延遲處理消息得到了最佳解決方案。假如你想讓應用啟動5秒後界面彈出一個對話框,沒有handler的情況下,會如何處理?開一個Thread然後使用Thread.sleep讓線程睡眠一對應的時間對吧,但如果多個延遲任務呢?而開啟線程也是個比較重量級的操作且線程的數量有限。而可以直接給Handler發送延遲對應時間的消息,他會在對應時間之後準時處理該消息(當然有特殊情況,如單件消息處理時間過長或者同步屏障,後面會講到)。而且無論發送多少延遲消息都不會對性能有任何影響。同時,也是通過這個功能來記錄ANR的時間。
講這些作用可能讀者心中並沒有一個很形象的概念,也可能看完就忘了。但是關於Handler的定義不能忘:Handler機制是Android中基於單線消息隊列模式的一套線程消息機制。,上述四個作用是為了讓讀者更好地理解Handler機制。
如何使用Handler
我們平常使用Handler有兩種不同的創建方式,但總體流程是相同的:
- 創建Looper
- 使用Looper創建Handler
- 啟動Looper
- 使用Handler發送信息
Looper可理解為循環器,就像「流水線」上的滾帶,後面會詳細講到。每個線程只有一個Looper,通常主線程已經創建好了,追溯應用程序啟動流程可以知道啟動過程中調用了Looper.prepareMainLooper,而在子線程就必須使用如下方法來初始化Looper:
Looper.prepare();
第二步是創建Handler,也是最熟悉的一步。我們有兩種方法來創建Handler:傳入callBack對象和繼承。如下:
public class MainActivity extends AppComposeActivity{
...;
// 第一種方法:使用callBack創建handler
public void onCreate(Bundle savedInstanceState){
super.onCreate(savedInstanceState);
Handler handler = Handler(Looper.myLooper(),new CallBack(){
public Boolean handleMessage(Message msg) {
TODO("Not yet implemented")
}
});
}
// 第二種方法:繼承Handler並重寫handlerMessage方法
static MyHandler extends Hanlder{
public MyHandler(Looper looper){
super(looper);
}
@Override
public void handleMessage(Message msg){
super.handleMessage(msg);
// TODO(重寫這個方法)
}
}
}
注意第二種方法,要使用靜態內部類,不然可能會造成內存泄露。原因是非靜態內部類會持有外部類的引用,而Handler發出的Message會持有Handler的引用。如果這個Message是個延遲的消息,此時activity被退出了,但Message依然在「流水線」上,Message->handler->activity,那麼activity就無法被回收,導致內存泄露。
兩種Handler的寫法各有千秋,繼承法可以寫比較複雜的邏輯,callback法適合比價簡單的邏輯,看具體的業務來選擇。
然後再調用Looper的loope方法來啟動Looper:
Looper.loop();
最後就是使用Handler來發送信息了。當我們獲得handler的實例之後,就可以通過他的sendMessage相方法和post相關方法來發送信息,如下:
handler.sendMessage(msg);
handler.sendMessageDelayed(msg,delayTime);
handler.post(runnable);
handler.postDelayed(runnable,delayTime);
然後一般情況下是哪個Handler發出的信息,最終由哪個Handler來處理。這樣,只要我們拿到Handler對象,就可以往對應的線程發送信息了。
Handler內部模式結構
經過前面的介紹對於Looper已經有了一定的認知,但可能對他內部的模式還不太清楚。這一部分先講解Handler的大概內部模式,目的是為下面的詳解做鋪墊,為做整體概念感知。先上圖:
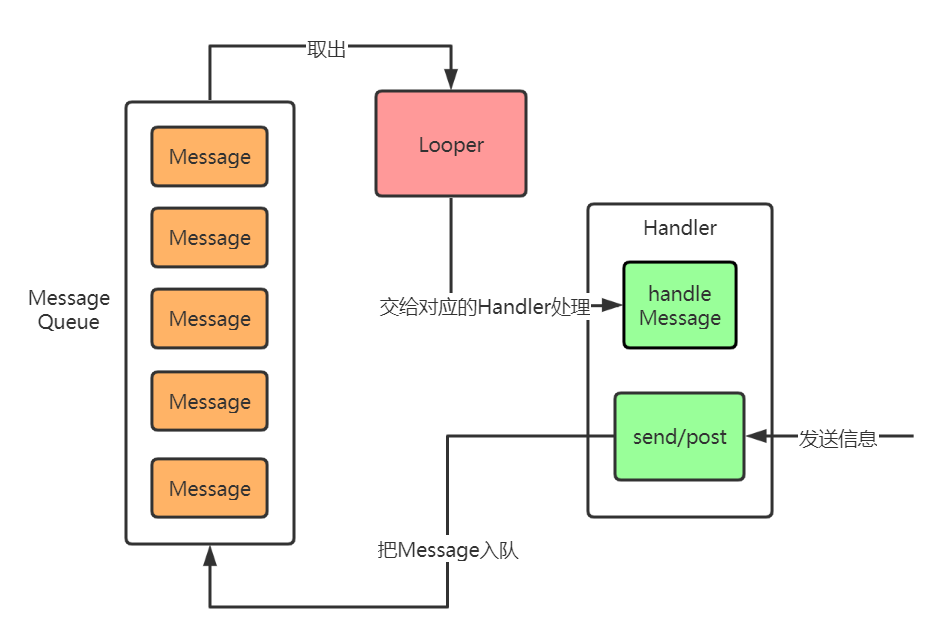
Handler機制內部有三大關鍵角色:Handler,Looper,MessageQueue。其中MessageQueue是Looper內部的一個對象,MessageQueue和Looper每個線程有且只有一個,而Handler是可以有很多個的。他們的工作流程是:
- 用戶使用線程的Looper構建Handler之後,通過Handler的send和post方法發送消息
- 消息會加入到MessageQueue中,等待Looper獲取處理
- Looper會不斷地從MessageQueue中獲取Message然後交付給對應的Handler處理
這就是大名鼎鼎的Handler機制內部模式了,說難,其實也是很簡單。
Handler機制關鍵類
一、ThreadLocal
概述
ThreadLocal是Java中一個用於線程內部存儲數據的工具類。
ThreadLocal是用來存儲數據的,但是每個線程只能訪問到各自線程的數據。我們一般的用法是:
ThreadLocal<String> stringLocal = new ThreadLocal<>();
stringLocal.set("java");
String s = stringLocal.get();
不同的線程之間訪問到的數據是不一樣的:
public static void main(String[] args){
ThreadLocal<String> stringLocal = new ThreadLocal<>();
stringLocal.set("java");
System.out.println(stringLocal.get());
new Thread(){
System.out.println(stringLocal.get());
}
}
結果:
java
null
線程只能訪問到自己線程存儲的數據。
ThreadLocal的作用
ThreadLocal的特性適用於同樣的數據類型,不同的線程有不同的備份情況,如我們這篇文章一直在講的Looper。每個線程都有一個對象,但是不同線程的Looper是不一樣的,這個時候就特別適合使用ThreadLocal來存儲數據,這也是為什麼這裡要講ThreadLocal的原因
ThreadLocal內部結構
ThreadLocal的內部機制結構如下:
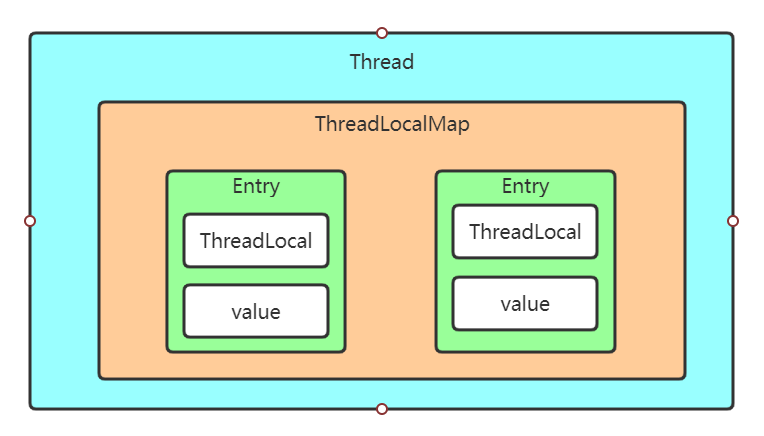
每個Thread,也就是每個線程內部維護有一個ThreadLocalMap,ThreadLocalMap內部存儲多個Entry。Entry可以理解為鍵值對,他的本質是一個弱引用,內部有一個object類型的內部變量,如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
Entry是ThreadLocalMap的一個靜態內部類,這樣每個Entry裏面就維護了一個ThreadLocal和ThreadLocal泛型對象。每個線程的內部維護有一個Entry數組,並通過hash算法使得讀取數據的速度達到O(1)。由於不同的線程對應的Thread對象不同,所以對應的ThreadLocalMap肯定也不同,這樣只有獲取到Thread對象才能獲取到其內部的數據,數據就被隔離在不同的線程內部了。
ThreadLocal工作流程
那ThreadLocal是怎麼實現把數據存儲在不同線程中的?先從他的set方法入手:
TheadLocal.class
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
邏輯不是很複雜,首先獲取當前線程的Thread對象,然後再獲取Thread的ThreadLocalMap對象,如果該map對象不存在則創建一個並調用他的set方法把數據存儲起來。我們繼續看ThreadLocalMap的set方法:
ThreadLocalMap.class
private void set(ThreadLocal<?> key, Object value) {
// 每個ThreadLocalMap內部都有一個Entry數組
Entry[] tab = table;
int len = tab.length;
// 獲取新的ThreadLocal在Entry數組中的下標
int i = key.threadLocalHashCode & (len-1);
// 判斷當前位置是否發生了Hash衝突
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 如果數據存在且相同則直接返回
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 若當前位置沒有其他元素則直接把新的Entry對象放入
tab[i] = new Entry(key, value);
int sz = ++size;
// 判斷是否需要對數組進行擴容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
這裡的邏輯和HashMap是很像的,我們可以直接使用HashMap的思維來理解ThreadLocalMap:ThreadLocalMap的key是ThreadLocal,value是ThreadLocal對應的泛型。他的存儲步驟如下:
- 根據自身的threadLocalHashCode與數組的長度進行相與得到下標
- 如果此下標為空,則直接插入
- 如果此下標已經有元素,則判斷兩者的ThreadLocal是否相同,相同則更新value後返回,否則找下一個下標
- 直到找到合適的位置把entry對象插入
- 最後判斷是否需要對entry數組進行擴容
是不是和HashMap非常像?和HashMap的不同是:hash算法不一樣,以及這裡使用的是開發地址法,而HashMap使用的是鏈表法。ThreadLocalMap犧牲一定的空間來換取更快的速度。具體的Hash算法這裡就不再深入了,有興趣的讀者可以閱讀這篇文章ThreadLocal傳送門
然後繼續看ThreadLocal的get方法:
ThreadLocal.class
public T get() {
// 獲取當前線程的ThreadLocalMap
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
// 根據ThreadLocal獲取Entry對象
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果沒找到也會執行初始化工作
if (e != null) {
@SuppressWarnings("unchecked")
// 把獲取到的對象進行返回
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
前面講到ThreadLocalMap其實非常像一個HashMap,他的get方法也是一樣的。使用ThreadLocal作為key獲取到對應的Entry,再把value返回即可。如果map尚未初始化則會執行初始化操作。下面繼續看下ThreadLocalMap的get方法:
ThreadLocalMap.class
private Entry getEntry(ThreadLocal<?> key) {
// 根據hash算法找到下標
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 找到數據則返回,否則通過開發地址法尋找下一個下標
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
利用ThreadLocal的threadLocalHashCode得到下標,然後根據下標找到數據。沒找到則根據算法尋找下個下標。
內存泄露問題
我們會發現Entry中,ThreadLocal是一個弱引用,而value則是強引用。如果外部沒有對ThreadLocal的任何引用,那麼ThreadLocal就會被回收,此時其對應的value也就變得沒有意義了,但是卻無法被回收,這就造成了內存泄露。怎麼解決?在ThreadLocal回收的時候記得調用其remove方法把entry移除,防止內存泄露。
ThreadLocal總結
ThreadLocal適合用於在不同線程作用域的數據備份
ThreadLocal機制通過在每個線程維護一個ThreadLocalMap,其key為ThreadLocal,value為ThreadLocal對應的泛型對象,這樣每個ThreadLocal就可以作為key將不同的value存儲在不同Thread的Map中,當獲取數據的時候,同個ThreadLocal就可以在不同線程的Map中得到不同的數據,如下圖:
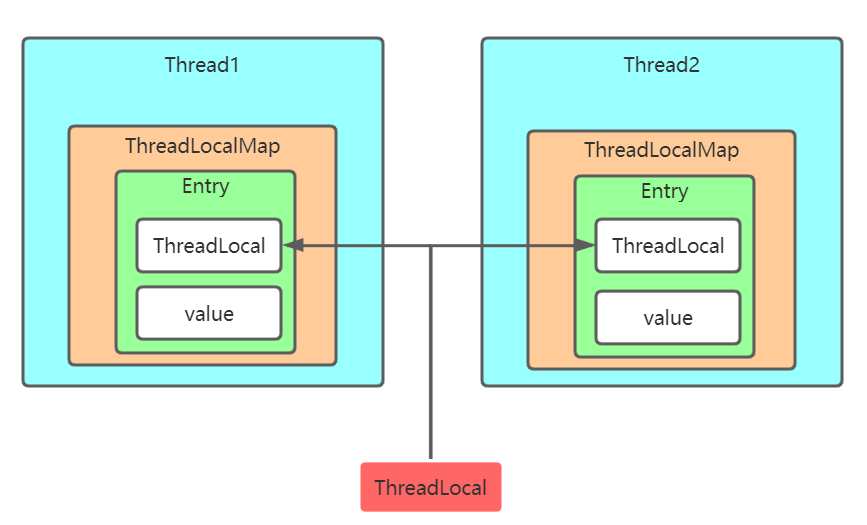
ThreadLocalMap類似於一個改版的HashMap,內部也是使用數組和Hash算法來存儲數據,使得存儲和讀取的速度非常快。
同時使用ThreadLocal需要注意內存泄露問題,當ThreadLocal不再使用的時候,需要通過remove方法把value移除。
二、Message
概述
Message是負責承載消息的類,主要是關注他的內部屬性:
// 用戶自定義,主要用於辨別Message的類型
public int what;
// 用於存儲一些整型數據
public int arg1;
public int arg2;
// 可放入一個可序列化對象
public Object obj;
// Bundle數據
Bundle data;
// Message處理的時間。相對於1970.1.1而言的時間
// 對用戶不可見
public long when;
// 處理這個Message的Handler
// 對用戶不可見
Handler target;
// 當我們使用Handler的post方法時候就是把runnable對象封裝成Message
// 對用戶不可見
Runnable callback;
// MessageQueue是一個鏈表,next表示下一個
// 對用戶不可見
Message next;
循環利用Message
當我們獲取Message的時候,官方建議是通過Message.obtain()方法來獲取,當使用完之後使用recycle()方法來回收循環利用。而不是直接new一個新的對象:
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
Message維護了一個靜態鏈表,鏈表頭是sPool,Message有一個next屬性,Message本身就是鏈表結構。sPoolSync是一個object對象,僅作為解決並發訪問安全設計。當我們調用obtain來獲取一個新的Message的時候,首先會檢查鏈表中是否有空閑的Message,如果沒有則新建一個返回。
當我們使用完成之後,可以調用Message的recycle方法進行回收:
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}
如果這個Message正在使用則會拋出異常,否則則調用recycleUnchecked進行回收:
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
這個方法的邏輯也非常簡單,把Message中的內容清空,然後判斷鏈表是否達到最大值(50),然後插入鏈表中。
Message總結
Message的作用就是承載消息,他的內部有很多的屬性用於給用戶賦值。同時Message本身也是一個鏈表結構,無論是在MessageQueue還是在Message內部的回收機制,都是使用這個結構來形成鏈表。同時官方建議不要直接初始化Message,而是通過Message.obtain()方法來獲取一個Message循環利用。一般來說我們不需要去調用recycle進行回收,在Looper中會自動把Message進行回收,後面會講到。
三、MessageQueue
概述
每個線程都有且只有一個MessageQueue,他是一個用於承載消息的隊列,內部使用鏈表作為數據結構,所以待處理的消息都會在這裡排隊。前面講到ThreadLocalMap是一個「修改版的HashMap」,而MessageQueue就是一個「修改版的LinkQueue」。他也有兩個關鍵的方法:入隊(enqueueMessage)和出隊(next)。這也是MessageQueue的重點所在。
Message還涉及到一個關鍵概念:線程休眠。當MessageQueue中沒有消息或者都在等待中,則會將線程休眠,讓出cpu資源,提高cpu的利用效率。進入休眠後,如果需要繼續執行代碼則需要將線程喚醒。當方法暫時無法直接返回需要等待的時候,則可以將線程阻塞,即休眠,等待被喚醒繼續執行邏輯。這部分內容也會在後面詳細講。
關鍵方法
-
出隊 — next()
next方法主要是做消息出隊工作。
Message next() { // 如果looper已經退出了,這裡就返回null final long ptr = mPtr; if (ptr == 0) { return null; } ... // 阻塞時間 int nextPollTimeoutMillis = 0; for (;;) { if (nextPollTimeoutMillis != 0) { Binder.flushPendingCommands(); } // 阻塞對應時間 nativePollOnce(ptr, nextPollTimeoutMillis); // 對MessageQueue進行加鎖,保證線程安全 synchronized (this) { final long now = SystemClock.uptimeMillis(); Message prevMsg = null; Message msg = mMessages; ... if (msg != null) { if (now < msg.when) { // 下一個消息還沒開始,等待兩者的時間差 nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE); } else { // 獲得消息且現在要執行,標記MessageQueue為非阻塞 mBlocked = false; // 鏈表操作 if (prevMsg != null) { prevMsg.next = msg.next; } else { mMessages = msg.next; } msg.next = null; msg.markInUse(); return msg; } } else { // 沒有消息,進入阻塞狀態 nextPollTimeoutMillis = -1; } ... } }代碼很長,其中還涉及了同步屏障和IdleHandler,這兩部分內容我放在後面講,這裡先講主要的出隊邏輯。代碼中我都加了注釋,這裡還是再講一下。next方法目的是獲取MessageQueue中的一個Message,如果隊列中沒有消息的話,就會把方法阻塞住,等待新的消息來喚醒。主要步驟如下:
- 如果Looper已經退出了,直接返回null
- 進入死循環,直到獲取到Message或者退出
- 循環中先判斷是否需要進行阻塞,阻塞結束後,對MessageQueue進行加鎖,獲取Message
- 如果MessageQueue中沒有消息,則直接把線程無限阻塞等待喚醒;
- 如果MessageQueue中有消息,則判斷是否需要等待,否則則直接返回對應的message。
可以看到邏輯就是判斷當前時間Message中是否需要等待。其中
nextPollTimeoutMillis表示阻塞的時間,-1表示無限時間,只有通過喚醒才能打破阻塞。 -
入隊 — enqueueMessage()
MessageQueue.class boolean enqueueMessage(Message msg, long when) { // Hanlder不允許為空 if (msg.target == null) { throw new IllegalArgumentException("Message must have a target."); } if (msg.isInUse()) { throw new IllegalStateException(msg + " This message is already in use."); } // 對MessageQueue進行加鎖 synchronized (this) { // 判斷目標thread是否已經死亡 if (mQuitting) { IllegalStateException e = new IllegalStateException( msg.target + " sending message to a Handler on a dead thread"); Log.w(TAG, e.getMessage(), e); msg.recycle(); return false; } // 標記Message正在被執行,以及需要被執行的時間,這裡的when是距離1970.1.1的時間 msg.markInUse(); msg.when = when; // p是MessageQueue的鏈表頭 Message p = mMessages; boolean needWake; // 判斷是否需要喚醒MessageQueue // 如果有新的隊頭,同時MessageQueue處於阻塞狀態則需要喚醒隊列 if (p == null || when == 0 || when < p.when) { msg.next = p; mMessages = msg; needWake = mBlocked; } else { ... // 根據時間找到插入的位置 Message prev; for (;;) { prev = p; p = p.next; if (p == null || when < p.when) { break; } ... } msg.next = p; prev.next = msg; } // 如果需要則喚醒隊列 if (needWake) { nativeWake(mPtr); } } return true; }這部分的代碼好像也很多,但是邏輯也是不複雜,主要就是鏈表操作以及判斷是否需要喚醒MessageQueue,代碼中我加了一些注釋,下面再總結一下:
-
首先判斷message的目標handler不能為空且不能正在使用中
-
對MessageQueue進行加鎖
-
判斷目標線程是否已經死亡,死亡則直接返回false
-
初始化Message的執行時間以及標記正在執行中
-
然後根據Message的執行時間,找到在鏈表中的插入位置進行插入
-
同時判斷是否需要喚醒MessageQueue。有兩種情況需要喚醒:當新插入的Message在鏈表頭時,如果messageQueue是空的或者正在等待下個任務的延遲時間執行,這個時候就需要喚醒MessageQueue。
-
MessageQueue總結
Message兩大重點:阻塞休眠和隊列操作。基本都是圍繞着兩點來展開。而源碼中還涉及到了同步屏障以及IdleHandler,這兩部分內容我分開到了最後一部分的相關問題中講。平時用的比較少,但也是比較重要的內容。
四、Looper
概述
Looper可以說是Handler機制中的一個非常重要的核心。Looper相當於線程消息機制的引擎,驅動整個消息機制運行。Looper負責從隊列中取出消息,然後交給對應的Handler去處理。如果隊列中沒有消息,則MessageQueue的next方法會阻塞線程,等待新的消息的到來。每個線程有且只能有一個「引擎」,也就是Looper,如果沒有Looper,那麼消息機制就運行不起來,而如果有多個Looper,則會違背單線操作的概念,造成並發操作。
每個線程僅有一個Looper,由不同Looper分發的Message運行在不同的線程中。Looper的內部維護一個MessageQueue,當初始化Looper的時候會順帶初始化MessageQueue。
Looper使用ThreadLocal來保證每個線程都有且只有一個相同的副本。
關鍵方法
-
prepare : 初始化Looper
Looper.class static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>(); public static void prepare() { prepare(true); } // 最終調用到了這個方法 private static void prepare(boolean quitAllowed) { if (sThreadLocal.get() != null) { throw new RuntimeException("Only one Looper may be created per thread"); } sThreadLocal.set(new Looper(quitAllowed)); }每個線程使用Handler之前,都必須調用
Looper.prepare()方法來初始化當前線程的Looper。參數quitAllowed表示該Looper是否可以退出。主線程的Looper是不能退出的,不然程序就直接終止了。我們在主線程使用Handler的時候是不用初始化Looper的,為什麼?因為Activiy在啟動的時候就已經幫我們初始化主線程Looper了,這點在後面再詳細展開。所以在主線程我們可以直接調用Looper.myLooper()獲取當前線程的Looper。prepare方法重點在
sThreadLocal.set(new Looper(quitAllowed));,可以看出來這裡使用了ThreadLocal來創建當前線程的Looper對象副本。如果當前線程已經有Looper了,則會拋出異常。sThreadLocal是Looper類的靜態變量,前面我們介紹過了ThreadLocal了,這裡每個線程調用一次prepare方法就可以初始化當前線程的Looper了。接下來再看到Looper的構造方法:
private Looper(boolean quitAllowed) { mQueue = new MessageQueue(quitAllowed); mThread = Thread.currentThread(); }邏輯很簡單,初始化了一個MessageQueue,再把當前的線程的Thread對象賦值給mThread。
-
myLooper() : 獲取當前線程的Looper對象
獲取當前線程的Looper對象。這個方法就是直接調用ThreadLocal的get方法:
public static @Nullable Looper myLooper() { return sThreadLocal.get(); } -
loop() : 循環獲取消息
當Looper初始化完成之後,他是不會自己啟動的,需要我們自己去啟動Looper,調用Looper的
loop()方法即可:public static void loop() { // 獲取當前線程的Looper final Looper me = myLooper(); if (me == null) { throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread."); } final MessageQueue queue = me.mQueue; ... for (;;) { // 獲取消息隊列中的消息 Message msg = queue.next(); // might block if (msg == null) { // 返回null說明MessageQueue退出了 return; } ... try { // 調用Message對應的Handler處理消息 msg.target.dispatchMessage(msg); if (observer != null) { observer.messageDispatched(token, msg); } dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0; } ... // 回收Message msg.recycleUnchecked(); } }loop()方法就是Looper這個「引擎」的核心所在。首先獲取當前線程的Looper對象,沒有則拋出異常。然後進入一個死循環:不斷調用MessageQueue的next方法來獲取消息,然後調用message的目標handler的dispatchMessage方法來處理Message。
前面我們了解過了MessageQueue,next方法是可能會進行阻塞的:當MessageQueue為空或者目前沒有任何消息需要處理。所以Looper就會一直等待,阻塞在里,線程也就不會結束。當我們退出Looper的時候,next方法會返回null,那麼Looper也就會跟着結束了。
同時,因為Looper是運行在不同線程的邏輯,其調用的dispatchMessage方法也是運行在不同的線程,這就達到了切換線程的目的。
-
quit/quitSafely : 退出Looper
quit是直接將Looper退出,quitSafely是將MessageQueue中的不需要等待的消息處理完成之後再退出,看一下代碼:
public void quit() { mQueue.quit(false); } // 最終都是調用到了這個方法 void quit(boolean safe) { // 如果不能退出則拋出異常。這個值在初始化Looper的時候被賦值 if (!mQuitAllowed) { throw new IllegalStateException("Main thread not allowed to quit."); } synchronized (this) { // 退出一次之後就無法再次運行了 if (mQuitting) { return; } mQuitting = true; // 執行不同的方法 if (safe) { removeAllFutureMessagesLocked(); } else { removeAllMessagesLocked(); } // 喚醒MessageQueue nativeWake(mPtr); } }我們可以發現最後都調用了quitSafely方法。這個方法先判斷是否能退出,然後再執行退出邏輯。如果mQuitting==true,那麼這裡會直接方法,我們會發現mQuitting這個變量只有在這裡被執行了賦值,所以一旦looper退出,則無法再次運行了。之後執行不同的退出邏輯,我們分別看一下:
private void removeAllMessagesLocked() { Message p = mMessages; while (p != null) { Message n = p.next; p.recycleUnchecked(); p = n; } mMessages = null; }這個方法很簡單,直接把當前所有的Message全部移除。再看一下另一個方法:
private void removeAllFutureMessagesLocked() { final long now = SystemClock.uptimeMillis(); Message p = mMessages; if (p != null) { // 如果都在等待,則全部移除,直接退出 if (p.when > now) { removeAllMessagesLocked(); } else { Message n; // 把需要等待的Message全部移除 for (;;) { n = p.next; if (n == null) { return; } if (n.when > now) { break; } p = n; } p.next = null; do { p = n; n = p.next; p.recycleUnchecked(); } while (n != null); } } }這個方法邏輯也不複雜,就是把需要等待的Message全部移除,當前需要執行的Message則保留。最終在MessageQueue的next方法中,會進行判斷後返回null,表示退出,Looper收到這個返回值之後也跟着退出了。
Looper總結
Looper作為Handler消息機制的「動力引擎」,不斷從MessageQueue中獲取消息,然後交給Handler去處理。Looper的使用前需要先初始化當前線程的Looper對象,再調用loop方法來啟動它。
同時Handler也是實現切換的核心,因為不同的Looper運行在不同的線程,他所調用的dispatchMessage方法則運行在不同的線程,所以Message的處理就被切換到Looper所在的線程了。當looper不再使用時,可調用不同的退出方法來退出他,注意Looper一旦退出,線程則會直接結束。
五、Handler
概述
我們整個消息機制稱為Handler機制就可以知道Handler我們的使用頻率之高,一般情況下我們的使用也是圍繞着Handler來展開。Handler是作為整個消息機制的消息發起者與處理者,消息在不同的線程通過Handler發送到目標線程的MessageQueue中,然後目標線程的Looper再調用Handler的dispatchMessage方法來處理消息。
創建Handler
一般情況下我們使用Handler有兩種方式: 繼承Handler並重寫handleMessage方法,直接創建Handler對象並傳入callBack,這在前面使用Handler部分講過就不再贅述。
需要注意的一點是:創建Handler必須顯示指明Looper參數,而不能直接使用無參構造函數,如:
Handler handler = new Handler(); //1
Handler handler = new Handler(Looper.myLooper())//2
1是錯的,2是對的。避免在Handler創建過程中Looper已經退出的情況。
發送消息
Handler發送消息有兩種系列方法 : postxx 和 sendxx。如下:
public final boolean post(@NonNull Runnable r);
public final boolean postDelayed(@NonNull Runnable r, long delayMillis);
public final boolean postAtTime(@NonNull Runnable r, long uptimeMillis);
public final boolean postAtFrontOfQueue(@NonNull Runnable r);
public final boolean sendMessage(@NonNull Message msg);
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis);
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis);
public final boolean sendMessageAtFrontOfQueue(@NonNull Message msg)
這裡我只列出了比較常用的兩類方法。除了插在隊列頭的兩個方法,其他方法最終都調用到了sendMessageAtTime。我們從post方法跟源碼分析一下:
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}
post方法把runnable對象封裝成一個Message,再調用sendMessageDelayed方法,我們看看他是如何封裝的:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
可以看到邏輯很簡單,把runnable對象直接賦值給callBack屬性。接下來回去繼續看sendMessageDelayed:
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
sendMessageDelayed把小於0的延遲時間改成0,然後調用sendMessageAtTime。這個方法主要是判斷MessageQueue是否已經初始化了,然後再調用enqueueMessage方法進行入隊操作:
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
// 這裡把target設置成自己
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
// 異步handler設置標誌位true,後面會講到同步屏障
if (mAsynchronous) {
msg.setAsynchronous(true);
}
// 最後調用MessageQueue的方法入隊
return queue.enqueueMessage(msg, uptimeMillis);
}
可以看到Handler的入隊操作也是很簡單,把Message的target設置成本身,這樣這個Message最後就是由自己來處理。最後調用MessageQueue的入隊方法來入隊,這在前面講過就不再贅述。
其他的發送消息方法都是大同小異,讀者感興趣可以自己去跟蹤一下源碼。
處理消息
上面講Looper處理消息的時候,最後就是調用handler的dispatchMessage方法來處理。我們來看一下這個方法:
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
private static void handleCallback(Message message) {
message.callback.run();
}
他的邏輯也不複雜。首先判斷Message是否有callBack,有的話就直接執行callBack的邏輯,這個callBack就是我們調用handler的post系列方法傳進去的Runnable對象。否則判斷Handler是否有callBack,有的話執行他的方法,如果返回true則結束,如果返回false則直接Handler本身的handleMessage方法。這個過程可以用下面的圖表示一下:
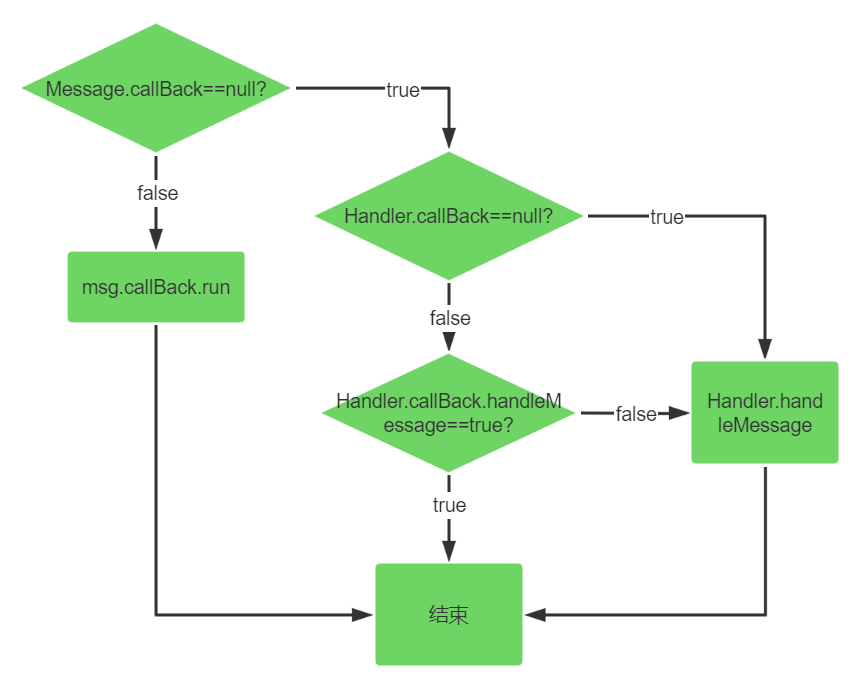
內存泄露問題
當我們使用繼承Handler方法來使用Handler的時候,要注意使用靜態內部類,而不要用非靜態內部類。因為非靜態內部類會持有外部類的引用,而從上面的分析我們知道Message在被入隊之後他的target屬性是指向了Handler,如果這個Message是一個延遲的消息,那麼這一條引用鏈的對象就遲遲無法被釋放,造成內存泄露。
一般這種泄露現象在於:我們在Activity中發送了一個延遲消息,然後退出了activity,但是由於無法釋放,這樣activity就無法被回收,造成內存泄露。
Handler總結
Handler作為消息的處理和發送者,是整個消息機制的起點和終點,也是我們接觸最多的一個類,因為我們稱此消息機製為Handler機制。Handler最重要的就是發送和處理消息,只要熟練掌握這兩方面的內容就可以了。同時注意內存泄露問題,不要使用非靜態內部類去繼承Handler。
六、HandlerThread
概述
有時候我們需要開闢一個線程來執行一些耗時的任務。一般情況下可以通過新建一個Thread,然後再在他的run方法里初始化該線程的Looper,這樣就可以用他的Looper來切線程處理消息了。如下(這裡是kotlin代碼,和java差不多相信可以看得懂的):
val thread = object : Thread(){
lateinit var mHandler: Handler
override fun run() {
super.run()
Looper.prepare()
mHandler = Handler(Looper.myLooper()!!)
Looper.loop()
}
}
thread.start()
thread.mHandler.sendMessage(Message.obtain())
但是,運行一下,炸了:

Handler還未初始化。Looper初始化是需要一定的時間,就導致了這個問題,那簡單,等待一下就可以了,上代碼:
val thread = object : Thread(){
lateinit var mHandler: Handler
override fun run() {
super.run()
Looper.prepare()
mHandler = Handler(Looper.myLooper()!!)
Looper.loop()
}
}
thread.start()
Thread(){
Thread.sleep(10000)
thread.mHandler.sendMessage(Message.obtain())
}.start()
執行一下,誒,沒有報錯了果然可以。但是!!! ,這樣的代碼顯得特別的難堪和臃腫,還要再開啟一個線程來延遲處理。那有沒有更好的解決方案?有,HandlerThread。
HandlerThread本身是一個Thread,他繼承自Thread,他的代碼並不複雜,看一下(代碼還是有點多,可以選擇看或者不看,我下面會講重點方法):
public class HandlerThread extends Thread {
// 依次是:線程優先級、線程id、線程looper、以及內部handler
int mPriority;
int mTid = -1;
Looper mLooper;
private @Nullable Handler mHandler;
// 兩個構造器。name是線程名字,priority是線程優先級
public HandlerThread(String name) {
super(name);
mPriority = Process.THREAD_PRIORITY_DEFAULT;
}
public HandlerThread(String name, int priority) {
super(name);
mPriority = priority;
}
// 在Looper開始運行前的方法
protected void onLooperPrepared() {
}
// 初始化Looper
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
// 通知初始化完成
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
// 獲取當前線程的Looper
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// 如果尚未初始化則會一直阻塞知道初始化完成
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
// 利用Object對象的wait方法
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
// 獲取handler,該方法被標記為hide,用戶無法獲取
@NonNull
public Handler getThreadHandler() {
if (mHandler == null) {
mHandler = new Handler(getLooper());
}
return mHandler;
}
// 兩種不同類型的退出,前面講過不再贅述
public boolean quit() {
Looper looper = getLooper();
if (looper != null) {
looper.quit();
return true;
}
return false;
}
public boolean quitSafely() {
Looper looper = getLooper();
if (looper != null) {
looper.quitSafely();
return true;
}
return false;
}
// 獲取線程id
public int getThreadId() {
return mTid;
}
}
整個類的代碼不是很多,重點在run()和getLooper()方法。首先看到getLooper方法:
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// 如果尚未初始化則會一直阻塞知道初始化完成
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
// 利用Object對象的wait方法
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}
和我們前面自己寫的不同,他有一個wait(),這個是Java中Object類提供的一個方法,類似於我們前面講的MessageQueue阻塞。等到Looper初始化完成之後就會喚醒他,就可以順利返回了,不會造成Looper尚未初始化完成的情況。然後再看到run方法:
// 初始化Looper
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
// 通知初始化完成
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
常規的Looper初始化,完成之後調用了notifyAll()方法進行喚醒,對應了上面的getLooper方法。
HandlerThread的使用
HandlerThread的使用範圍很有限,開個子線程不斷接受消息處理耗時任務。所以他的使用方法也是比較固定:
HandlerThread ht = new HandlerThread("handler");
Handler handler = new Hander(ht.getLooper());
handler.sendMessage(msg);
獲取到他的Looper,外部自定義Handler來使用即可。
七、總結
Handler,MessageQueue,Looper三者共同構成了android消息機制,各司其職。其中Handler主要負責發送和處理消息,MessageQueue主要負責消息的排序以及在沒有需要處理的消息的時候阻塞代碼,Looper負責從MessageQueue中取出消息給Handler處理,同時達到切換線程的目的。通過源碼分析,希望讀者可以對這些概念有更加清晰的認知。
工作流程
這一部分主要講整體的流程,前面零零散散講了各個組件的功能以及源碼,現在就統一來講一下他們的整體流程。先看圖:
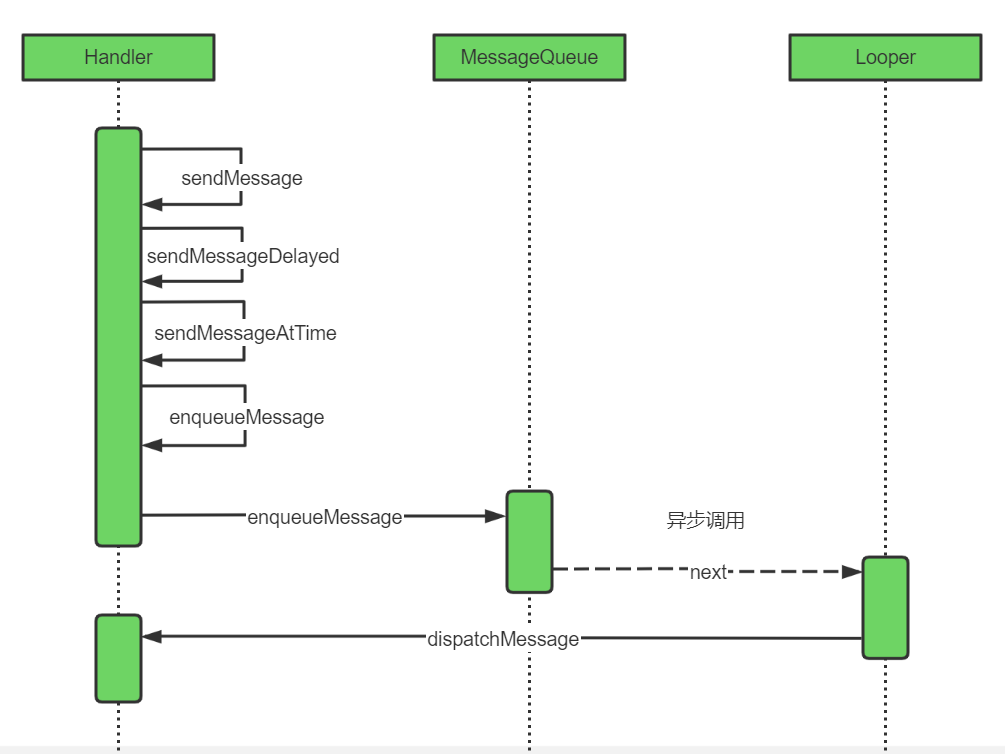
- Handler設置一系列的api供給開發者可以使用Handler發送各種類型的信息,最終都調用到了enqueueMessage方法來入隊
- 調用MessageQueue的enqueueMessage方法把消息插入到MessageQueue的鏈表中,等待被Looper獲取處理
- Looper獲取到Message之後,調用Message對應的Handler處理Message
這樣整理的流程就清晰了,細節的源碼分析我就不再贅述了,如果有讀者哪個部分不夠清晰,可以回到上面對應部分再看一遍。
相關問題
主線程為什麼不用初始化Looper?
答:因為應用在啟動的過程中就已經初始化主線程Looper了。
每個java應用程序都是有一個main方法入口,Android是基於Java的程序也不例外。Android程序的入口在ActivityThread的main方法中:
public static void main(String[] args) {
...
// 初始化主線程Looper
Looper.prepareMainLooper();
...
// 新建一個ActivityThread對象
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
// 獲取ActivityThread的Handler,也是他的內部類H
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
...
Looper.loop();
// 如果loop方法結束則拋出異常,程序結束
throw new RuntimeException("Main thread loop unexpectedly exited");
}
main方法中先初始化主線程Looper,新建ActivityThread對象,然後再啟動Looper,這樣主線程的Looper在程序啟動的時候就跑起來了。我們不需要再去初始化主線程Looper。
為什麼主線程的Looper是一個死循環,但是卻不會ANR?
答: 因為當Looper處理完所有消息的時候會進入阻塞狀態,當有新的Message進來的時候會打破阻塞繼續執行。
這其實沒理解好ANR這個概念。ANR,全名Application Not Responding。當我發送一個繪製UI 的消息到主線程Handler之後,經過一定的時間沒有被執行,則拋出ANR異常。Looper的死循環,是循環執行各種事務,包括UI繪製事務。Looper死循環說明線程沒有死亡,如果Looper停止循環,線程則結束退出了。Looper的死循環本身就是保證UI繪製任務可以被執行的原因之一。同時UI繪製任務有同步屏障,可以更加快速地保證繪製更快執行。同步屏障下面會講。
Handler如何保證MessageQueue並發訪問安全?
答:循環加鎖,配合阻塞喚醒機制。
我們可以發現MessageQueue其實是「生產者-消費者」模型,Handler不斷地放入消息,Looper不斷地取出,這就涉及到死鎖問題。如果Looper拿到鎖,但是隊列中沒有消息,就會一直等待,而Handler需要把消息放進去,鎖卻被Looper拿着無法入隊,這就造成了死鎖。Handler機制的解決方法是循環加鎖。在MessageQueue的next方法中:
Message next() {
...
for (;;) {
...
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
...
}
}
}
我們可以看到他的等待是在鎖外的,當隊列中沒有消息的時候,他會先釋放鎖,再進行等待,直到被喚醒。這樣就不會造成死鎖問題了。
那在入隊的時候會不會因為隊列已經滿了然後一邊在等待消息處理一邊拿着鎖呢?這一點不同的是MessageQueue的消息沒有上限,或者說他的上限就是JVM給程序分配的內存,如果超出內存會拋出異常,但一般情況下是不會的。
Looper退出後是否可以重新運行?
答: 不可以。
線程的存活是靠Looper調用的next方法進行阻塞實現的。如果Looper退出後,那麼線程會馬上結束,也不會再有第二次運行的機會了。即使線程還沒結束再一次調用loop(),Looper內部有一個mQuitting變量,當他被賦值為false之後就無法再被賦值為true。所以就無法再重新運行了。
Handler是如何切換線程的?
答: 使用不同線程的Looper處理消息。
前面我們聊到,代碼的執行線程,並不是代碼本身決定,而是執行這段代碼的邏輯是在哪個線程,或者說是哪個線程的邏輯調用的。每個Looper都運行在對應的線程,所以不同的Looper調用的dispatchMessage方法就運行在其所在的線程了。
Handler的阻塞喚醒機制是怎麼回事?
答: Handler的阻塞喚醒機制是基於Linux的阻塞喚醒機制。
這個機制也是類似於handler機制的模式。在本地創建一個文件描述符,然後需要等待的一方則監聽這個文件描述符,喚醒的一方只需要修改這個文件,那麼等待的一方就會收到文件從而打破喚醒。和Looper監聽MessageQueue,Handler添加message是比較類似的。具體的Linux層知識讀者可通過這篇文章詳細了解(傳送門)
能不能讓一個Message加急被處理?/ 什麼是Handler同步屏障?
答:可以 / 一種使得異步消息可以被更快處理的機制
如果向主線程發送了一個UI更新的操作Message,而此時消息隊列中的消息非常多,那麼這個Message的處理就會變得緩慢,造成界面卡頓。所以通過同步屏障,可以使得UI繪製的Message更快被執行。
什麼是同步屏障?這個「屏障」其實是一個Message,插入在MessageQueue的鏈表頭,且其target==null。Message入隊的時候不是判斷了target不能為null嗎?不不不,添加同步屏障是另一個方法:
public int postSyncBarrier() {
return postSyncBarrier(SystemClock.uptimeMillis());
}
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
Message p = mMessages;
// 把當前需要執行的Message全部執行
if (when != 0) {
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
// 插入同步屏障
if (prev != null) { // invariant: p == prev.next
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
mMessages = msg;
}
return token;
}
}
可以看到同步屏障就是一個特殊的target,哪裡特殊呢?target==null,我們可以看到他並沒有給target屬性賦值。那這個target有什麼用呢?看next方法:
Message next() {
...
// 阻塞時間
int nextPollTimeoutMillis = 0;
for (;;) {
...
// 阻塞對應時間
nativePollOnce(ptr, nextPollTimeoutMillis);
// 對MessageQueue進行加鎖,保證線程安全
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
/**
* 1
*/
if (msg != null && msg.target == null) {
// 同步屏障,找到下一個異步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// 下一個消息還沒開始,等待兩者的時間差
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 獲得消息且現在要執行,標記MessageQueue為非阻塞
mBlocked = false;
/**
* 2
*/
// 一般只有異步消息才會從中間拿走消息,同步消息都是從鏈表頭獲取
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
// 沒有消息,進入阻塞狀態
nextPollTimeoutMillis = -1;
}
// 當調用Looper.quitSafely()時候執行完所有的消息後就會退出
if (mQuitting) {
dispose();
return null;
}
...
}
...
}
}
這個方法我在前面講過,我們重點看一下關於同步屏障的部分,看注釋1的地方的代碼:
if (msg != null && msg.target == null) {
// 同步屏障,找到下一個異步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
如果遇到同步屏障,那麼會循環遍歷整個鏈表找到標記為異步消息的Message,即isAsynchronous返回true,其他的消息會直接忽視,那麼這樣異步消息,就會提前被執行了。注釋2的代碼注意一下就可以了。
注意,同步屏障不會自動移除,使用完成之後需要手動進行移除,不然會造成同步消息無法被處理。從源碼中可以看到如果不移除同步屏障,那麼他會一直在那裡,這樣同步消息就永遠無法被執行了。
有了同步屏障,那麼喚醒的判斷條件就必須再加一個:MessageQueue中有同步屏障且處於阻塞中,此時插入在所有異步消息前插入新的異步消息。這個也很好理解,跟同步消息是一樣的。如果把所有的同步消息先忽視,就是插入新的鏈表頭且隊列處於阻塞狀態,這個時候就需要被喚醒了。看一下源碼:
boolean enqueueMessage(Message msg, long when) {
...
// 對MessageQueue進行加鎖
synchronized (this) {
...
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
/**
* 1
*/
// 當線程被阻塞,且目前有同步屏障,且入隊的消息是異步消息
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
/**
* 2
*/
// 如果找到一個異步消息,說明前面有延遲的異步消息需要被處理,不需要被喚醒
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
// 如果需要則喚醒隊列
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
同樣,這個方法我之前講過,把無關同步屏障的代碼忽視,看到注釋1處的代碼。如果插入的消息是異步消息,且有同步屏障,同時MessageQueue正處於阻塞狀態,那麼就需要喚醒。而如果這個異步消息的插入位置不是所有異步消息之前,那麼不需要喚醒,如注釋2。
那我們如何發送一個異步類型的消息呢?有兩種辦法:
- 使用異步類型的Handler發送的全部Message都是異步的
- 給Message標誌異步
Handler有一系列帶Boolean類型的參數的構造器,這個參數就是決定是否是異步Handler:
public Handler(@NonNull Looper looper, @Nullable Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
// 這裡賦值
mAsynchronous = async;
}
在發送消息的時候就會給Message賦值:
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
// 賦值
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
但是異步類型的Handler構造器是標記為hide,我們無法使用,所以我們使用異步消息只有通過給Message設置異步標誌:
public void setAsynchronous(boolean async) {
if (async) {
flags |= FLAG_ASYNCHRONOUS;
} else {
flags &= ~FLAG_ASYNCHRONOUS;
}
}
但是!!!!,其實同步屏障對於我們的日常使用的話其實是沒有多大用處。因為設置同步屏障和創建異步Handler的方法都是標誌為hide,說明谷歌不想要我們去使用他。所以這裡同步屏障也作為一個了解,可以更加全面地理解源碼中的內容。
什麼是IdleHandler?
答: 當MessageQueue為空或者目前沒有需要執行的Message時會回調的接口對象。
IdleHandler看起來好像是個Handler,但他其實只是一個有單方法的接口,也稱為函數型接口:
public static interface IdleHandler {
boolean queueIdle();
}
在MessageQueue中有一個List存儲了IdleHandler對象,當MessageQueue沒有需要被執行的MessageQueue時就會遍歷回調所有的IdleHandler。所以IdleHandler主要用於在消息隊列空閑的時候處理一些輕量級的工作。
IdleHandler的調用是在next方法中:
Message next() {
// 如果looper已經退出了,這裡就返回null
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
// IdleHandler的數量
int pendingIdleHandlerCount = -1;
// 阻塞時間
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
// 阻塞對應時間
nativePollOnce(ptr, nextPollTimeoutMillis);
// 對MessageQueue進行加鎖,保證線程安全
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// 同步屏障,找到下一個異步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// 下一個消息還沒開始,等待兩者的時間差
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 獲得消息且現在要執行,標記MessageQueue為非阻塞
mBlocked = false;
// 一般只有異步消息才會從中間拿走消息,同步消息都是從鏈表頭獲取
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
// 沒有消息,進入阻塞狀態
nextPollTimeoutMillis = -1;
}
// 當調用Looper.quitSafely()時候執行完所有的消息後就會退出
if (mQuitting) {
dispose();
return null;
}
// 當隊列中的消息用完了或者都在等待時間延遲執行同時給pendingIdleHandlerCount<0
// 給pendingIdleHandlerCount賦值MessageQueue中IdleHandler的數量
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
// 沒有需要執行的IdleHanlder直接continue
if (pendingIdleHandlerCount <= 0) {
// 執行IdleHandler,標記MessageQueue進入阻塞狀態
mBlocked = true;
continue;
}
// 把List轉化成數組類型
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// 執行IdleHandler
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // 釋放IdleHandler的引用
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
// 如果返回false,則把IdleHanlder移除
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// 最後設置pendingIdleHandlerCount為0,防止再執行一次
pendingIdleHandlerCount = 0;
// 當在執行IdleHandler的時候,可能有新的消息已經進來了
// 所以這個時候不能阻塞,要回去循環一次看一下
nextPollTimeoutMillis = 0;
}
}
代碼很多,可能看着有點亂,我梳理一下邏輯,然後再回去看源碼就會很清晰了:
- 當調用next方法的時候,會給
pendingIdleHandlerCount賦值為-1 - 如果隊列中沒有需要處理的消息的時候,就會判斷
pendingIdleHandlerCount是否為<0,如果是則把存儲IdleHandler的list的長度賦值給pendingIdleHandlerCount - 把list中的所有IdleHandler放到數組中。這一步是為了不讓在執行IdleHandler的時候List被插入新的IdleHandler,造成邏輯混亂
- 然後遍歷整個數組執行所有的IdleHandler
- 最後給
pendingIdleHandlerCount賦值為0。然後再回去看一下這個期間有沒有新的消息插入。因為pendingIdleHandlerCount的值為0不是-1,所以IdleHandler只會在空閑的時候執行一次 - 同時注意,如果IdleHandler返回了false,那麼執行一次之後就被丟棄了。
建議讀者再回去把源碼看一遍,這樣邏輯會清晰很多。
Handler消息機制的再認識
到這裡關於Handler機制該講的已經講得差不多了。但不知讀者和我一樣是否有同樣的疑惑:
Handler機製為什麼叫做Android中的消息機制?Handler真的就只是用來切換線程更新UI 的嗎?怎麼樣從源碼設計的角度來更好地理解Handler消息機制?
每次學習關於Android中的機制問題時,我都喜歡從研究他在android源碼設計中體現的作用,或者說思想。這有助於讓我的理解提高一個層次。這裡就簡單談談我對Handler機制的理解。
Handler機制,之所以叫handler,我覺得只是因為我們接觸的都是Handler,所以叫做Handler機制,如果我們接觸Looper比較多可能他的名字就是Looper機制了。更準確來說,他應該是Android消息機制。
我們知道,每個java程序都有一個入口:main方法,然後我們從這裡開始進入我們的應用程序。相信每個讀者都有使用c語言寫學生管理系統的經歷,我們是如何讓程序暫停下來不要直接結束的?通過循環+輸入等待。我們會在最外層寫一個死循環,然後不斷地監聽輸入,再根據輸入執行命令。當用戶無輸入的時候,就會一直等待。這其實和Handler機制是類似的。Handler機制使用的是多線程的思路,主線程不斷等待消息,然後從別的線程發送消息讓主線程執行邏輯,這也稱為事務驅動型設計,主線程的邏輯都是通過message來驅動的。
我們直接來看一下Android應用程序的main方法:
public static void main(String[] args) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ActivityThreadMain");
AndroidOs.install();
CloseGuard.setEnabled(false);
Environment.initForCurrentUser();
final File configDir = Environment.getUserConfigDirectory(UserHandle.myUserId());
TrustedCertificateStore.setDefaultUserDirectory(configDir);
Process.setArgV0("<pre-initialized>");
// 初始化Looper
Looper.prepareMainLooper();
long startSeq = 0;
if (args != null) {
for (int i = args.length - 1; i >= 0; --i) {
if (args[i] != null && args[i].startsWith(PROC_START_SEQ_IDENT)) {
startSeq = Long.parseLong(
args[i].substring(PROC_START_SEQ_IDENT.length()));
}
}
}
// 創建ActivityThread
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
// 啟動Looper
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
但是我們可以看到他的代碼其實並不多,啟動了ActivityThread和Looper之後就沒有再執行其他邏輯了,那我們的Activity是如何被調用並執行邏輯的?通過Handler。Android是事務驅動型的設計,通過不斷地分發事務來讓整個程序運行起來。熟悉Activity啟動流程的讀者應該可以聯想到,AMS通過binder機制和程序聯繫,然後binder線程再發送一個消息給到主線程,主線程再執行相對應的邏輯。他們的關係可以用下面的圖來表示:
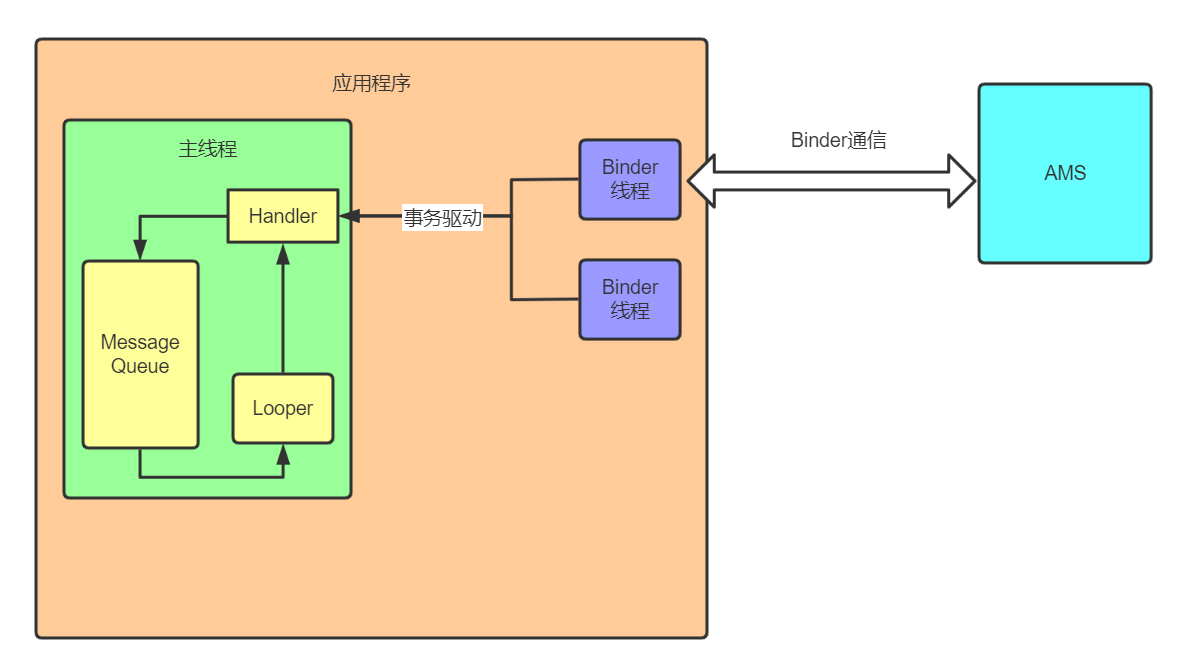
當應用進程被創建的時候,只是創建了主線程的Looper和handler,以及其他的binder線程等。之後AMS通過Binder與應用程序通信,給主線程發送message,讓程序執行創建Activity等的操作。這樣的設計我們不用去寫死循環和等待用戶輸入等邏輯,應用程序就能跑起來且不會結束。關於Activity的啟動相關我這裡就不展開講了,讀者可以去看筆者的另一篇文章(Activity啟動流程詳解)。之後程序會開啟其他的線程來接收用戶的觸摸輸入等,然後把這些包裝成一個message發送到主線程去更新UI。
可以說,「無消息,無安卓」,整個安卓的程序運行都是基於這套消息機制來跑的。他不僅僅只是切換線程這麼簡單,他涉及到整個android程序的根基。
總結
這篇文章從一開始的入門講解,到深入講解各個類的源碼和作用,最後再升華一下整個消息機制的設計思想。相信讀者關於Handler消息機制的認識已經非常深刻了。
消息機制我們日常使用得並不多,雖然他非常重要,但我們的使用也是主要用戶切換線程更新UI這一塊。而我們有很多成熟且非常方便的框架可以使用:RxJava、kotlin協程等等。但由於Handler機制對於android程序實在是非常重要,對於深入學習android還是非常有必要去學習、去理解。
希望文章對你有幫助。
全文到此,原創不易,覺得有幫助可以點贊收藏評論轉發。
筆者能力有限,有任何想法歡迎評論區交流指正。
如需轉載請私信交流。另外歡迎光臨筆者的個人博客:傳送門


