擴展Linux網絡棧
擴展Linux網絡棧
來自Linux內核文檔。之前看過這篇文章,一直好奇,問什麼一條網絡流會固定在一個CPU上進行處理,本文檔可以解決這個疑問。為了更好地理解本文章中的功能,將這篇文章穿插入內。
簡介
本文的描述了Linux網絡棧中的一組補充技術,用於增加多處理器系統的並行性和提高性能。
描述的結束為:
- RSS: Receive Side Scaling
- RPS: Receive Packet Steering
- RFS: Receive Flow Steering
- Accelerated Receive Flow Steering
- XPS: Transmit Packet Steering
RSS: Receive Side Scaling
現代NICs支持多個接收和傳輸描述符隊列(多隊列)。在接收報文時,NIC可以通過將不同的報文發送到不同的隊列的方式來分配多個CPU處理。NIC通過過濾器來分發報文,過濾器會將報文分配給某條邏輯流。每條流中的報文都被導向不同的接收隊列,然後由不同CPU處理。這個機制稱為「Receive-side Scaling」 (RSS)。RSS和其他擴展技術的目的是提升性能。多隊列分發技術也可以按照優先級處理流量,但這不是該技術關注的內容。
RSS中的過濾器通常是一個針對網絡和/或傳輸層首部的哈希函數,如對IP地址的4元組和報文的TCP端口進行哈希。最常見的RSS的硬件實現是使用一個128個表項的間接表,每個表項存儲一個隊列元素。根據由報文計算出的哈希值的低7位來決定報文的接收隊列(通常是Toeplitz哈希),使用該值作為間接表的索引,然後讀取相應的值。
一些先進的NICs允許根據編程的過濾器將報文導入隊列。例如,使用TCP 80端口的web服務器的報文可以直接導入其歸屬的接收隊列。可以使用ethtool配置這種n元組過濾器(–config-ntuple)。
RSS配置
對於支持多隊列的NIC,驅動通常會提供一個內核模塊參數來配置硬件隊列的數目。例如在bnx2x驅動中,該參數稱為num_queues。一個典型的RSS配置應該給每個CPU分配一個接收隊列(如果驅動支持足夠多隊列的話),或至少給每個內存域分配一個接收隊列(內存域指共享一個特定內存級別(L1, L2, NUMA 節點等)的一組CPUs)。
RSS設備的間接表(通過掩碼哈希解析隊列)通常是在驅動初始化時進行編程。默認會將隊列平均分佈到表中,但也可以在運行時通過ethtool命令進行檢索和修改(–show-rxfh-indir 和 –set-rxfh-indir)。通過修改間接表,可以給不同的隊列分配不同的相對權重。
RSS IRQ 配置
每個接收隊列都會關聯一個IRQ(中斷請求)。當給定的隊列接收到新的報文後,NIC會觸發中斷,通知CPU。PCIe設備的信令路徑使用消息信令中斷(MSI-X),可以將每個中斷路由到一個特定的CPU上。可以在/proc/interrupts中查看到IRQs的隊列映射。默認情況下,任何CPU都可以處理IRQ。由於報文接收中斷處理中包含一部分不可忽略的處理過程,因此在CPU之間分散處理中斷是有利的(防止新的中斷無法被即時處理)。如果要手動調節IRQ的親和性,參見SMP IRQ affinity。一些系統會運行irqbalance,這是一個守護進程,自動分配IRQ,可能會覆蓋手動設置的結果。
建議配置
當關注延遲或當接收中斷處理成為瓶頸後應該啟用RSS。將負載分擔給多個CPU可以有效減小隊列長度。對於低延遲網絡來說,最佳設置是分配與系統中CPU數量一樣多的隊列。最高效的高速率配置可能是接收隊列數量最少的配置,這樣不會由於CPU飽和而導致接收隊列溢出,由於在默認模式下啟用了中斷合併,中斷的總數會隨着每個其他隊列的增長而增加。
可以使用mpstat工具查看單CPU的負載,但對於啟用了超線程(HT)的處理器,每個超線程都表示一個單獨的CPU。但對於中斷處理,HT在初始測試中沒有顯示任何好處,因此應該將隊列的數目限制為系統上的CPU core的數目。
RSS 是一個網卡特性,其使用的是硬件隊列。
為了確定一個接口支持RSS,可以在
/proc/interrupts中查看一個接口是否對應了多個中斷請求隊列。如下NIC為p1p1接口創建了6個接收隊列(p1p1-0到p1p1-5)。# egrep 'CPU|p1p1' /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 89: 40187 0 0 0 0 0 IR-PCI-MSI-edge p1p1-0 90: 0 790 0 0 0 0 IR-PCI-MSI-edge p1p1-1 91: 0 0 959 0 0 0 IR-PCI-MSI-edge p1p1-2 92: 0 0 0 3310 0 0 IR-PCI-MSI-edge p1p1-3 93: 0 0 0 0 622 0 IR-PCI-MSI-edge p1p1-4 94: 0 0 0 0 0 2475 IR-PCI-MSI-edge p1p1-5可以在
/sys/class/net/<dev>/queues目錄中看到一個接口上現有的隊列,如下面的eth0有兩組隊列:# ll /sys/class/net/eth0/queues total 0 drwxr-xr-x 3 root root 0 Aug 19 16:23 rx-0 drwxr-xr-x 3 root root 0 Aug 19 16:23 rx-1 drwxr-xr-x 3 root root 0 Aug 19 16:23 tx-0 drwxr-xr-x 3 root root 0 Aug 19 16:23 tx-1也可以使用ethtool -l
查看。如下面的eth0最多支持2組隊列,當前啟用了2組(就是上述的兩組),可以使用ethtool -L eth0 combined 10修改當前啟用的隊列數,需要注意的的是,目前很多環境都是雲化的虛擬環境,大部分ethtool操作功能和權限都受到了限制。 # ethtool -l eth0 Channel parameters for eth0: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 2 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2如上所述,下圖的硬件過濾器就是個根據4元組或5元組等進行哈希的哈希函數。可以使用
ethtool -x <dev>命令查看RSS使用的哈希函數(但大部分虛擬環境不支持該命令,可以在/proc/sys/net/core/netdev_rss_key中查看RSS使用的哈希key)。
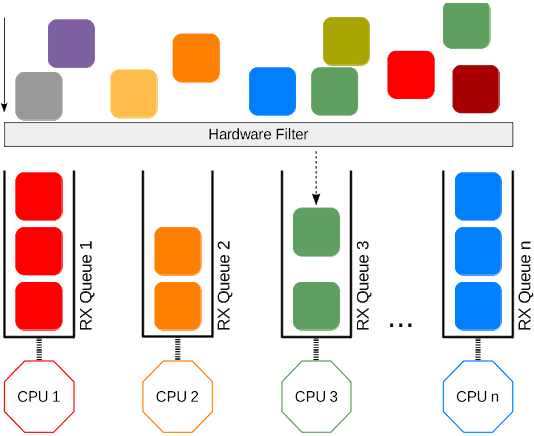
RPS: Receive Packet Steering
Receive Packet Steering (RPS)是RSS的一個軟件邏輯實現。作為一個軟件實現,需要在數據路徑的後端調用它。鑒於RSS會給流量選擇CPU隊列,因此會觸發CPU運行硬件中斷處理程序,RPS會在中斷處理程序之上選擇CPU來執行協議處理。整個過程是通過將報文放到期望的CPU backlog隊列中,然後喚醒該CPU進行處理來實現的。RPS相比RSS有一些優勢:
- 可以使用任何NIC
- 可以方便地添加軟件過濾器來哈希新的協議
- 不會增加硬件設備的中斷頻率(雖然它會引入內部處理中斷(IPIs))
在接收中斷處理程序的下半部分會調用RPS(當一個驅動使用netif_rx()或netif_receive_skb()發送一個報文到網絡棧時)。這些函數會調用get_rps_cpu() 函數,get_rps_cpu() 會選擇一個處理報文的隊列。
RPS的第一步是通過對一條流中的報文的地址或端口(2元組或4元組,具體取決於協議)進行哈希來確定目標CPU。哈希操作會涉及相關流中的所有報文。可以通過硬件或棧來支持對報文的哈希。支持報文哈希的硬件會在接收的報文描述符中傳入哈希值,通常與RSS使用的哈希相同(如Toeplitz 哈希)。哈希值會保存在skb->hash中,並且可以在棧的其他位置用作報文流的哈希值。
每個接收硬件隊列都有相關的CPU列表,RPS會將報文入隊列並進行處理。對於每個接收到的報文,會根據流哈希以列表大小為模來計算列表的索引。索引到的CPU就是處理報文的CPU,且報文會放到CPU backlog隊列的末尾。在下半部分的例程處理結束之後,會給有報文進入backlog隊列的CPU發送IPIs。IPI會喚醒遠端CPU對backlog的處理,後續隊列中的報文會在網絡棧中進行處理。
RPS配置
RPS需要在內核編譯時啟用CONFIG_RPS 選項(SMP上默認啟用,可以使用 cat /boot/config-$(uname -r)|grep CONFIG_RPS命令查看)。但即使在編譯時指定了該功能,後續也需要通過明確配置才能啟用該功能。可以通過sys文件系統中的文件來配置RPS可以為接收隊列轉發流量的CPU列表。
/sys/class/net/<dev>/queues/rx-<n>/rps_cpus
該文件實現了CPU位圖。當上述值為0時(默認為0),不會啟用RPS,這種情況下,報文將在中斷的CPU上進行處理。SMP IRQ affinity解釋了如何將CPU分配給位圖。
建議配置
對於一個單隊列設備,典型的RPS配置會將rps_cpus 設置為與中斷CPU相同的內存域中的CPUs。如果NUMA的本地性不是問題,則也可以設置為系統上的所有CPUs。在高中斷率的情況下,最好從位圖中排除該CPU(因為該CPU已經足夠繁忙)。
對於一個多隊列系統,如果配置了RSS,則硬件接收隊列會映射到每個CPU上,此時RPS可能會冗餘。但如果硬件隊列的數目少於CPU,那麼,如果rps_cpus為每個隊列指定的CPU與中斷該隊列的CPU共享相同的內存域時,則RPS可能是有用的。
RPS使用
/sys/class/net/<dev>/queues/rx-<n>/rps_cpus來設置某個接收隊列使用的CPU。如果要使用CPU 1~3,則位圖為0 0 0 0 0 1 1 1,即0x7,將7 寫入rps_cpus即可,後續rx-0將會使用CPU 1~3來接收報文。# echo 7 > /sys/class/net/eth0/queues/rx-0/rps_cpus在驅動將報文封裝到sk_buff之後,將會經過
netif_rx_internal()或netif_receive_skb_internal(),然後調用get_rps_cpu()將哈希值映射到rps_map中的某個表項,即CPU id。在獲取到CPU id之後,enqueue_to_backlog()會將sk_buff 放到指定的CPU隊列中(後續處理)。為每個CPU分配的隊列是一個per-cpu變量,softnet_data。
如果已經啟用了RSS,則可以不啟用RPS。但如果系統上CPU的數目大於隊列的數目時,可以啟用RPS,給隊列關聯更多的CPU,這樣一個隊列的報文就可以在多個CPU上處理。
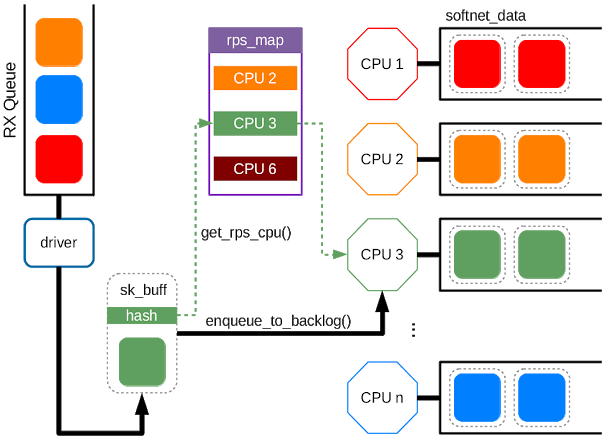
RPS流限制
RPS擴展了內核跨CPU接收處理的能力,而不會引入重排。如果報文的速率不同,則將同一流上的所有報文發送到同一CPU會導致CPU負載失衡。在極端情況下,單條流會主導流量。特別是在存在很多並行連接的通用服務器上,這類行為可能表現為配置錯誤或欺騙源拒絕服務攻擊。
流限制是RPS的一個可選特性,在CPU競爭期間,通過提前一點丟棄大流量的報文來為小流量騰出處理的機會。只有當RPS或RFS目標CPU達到飽和時,才會激活此功能。一旦一個CPU的輸入報文隊列超過最大隊列長度(即,net.core.netdev_max_backlog)的一半,內核會從最近的256個報文開始按流計數,如果接收到一個新的報文,且此時這條流的報文數超過了設置的比率(默認為一半,即超過了256/2個),則會丟棄新報文。其他流的報文只有在輸入報文隊列達到netdev_max_backlog時才會丟棄報文。如果報文隊列長度低於閾值,則不會丟棄報文,因此流量限制不會完全切斷連接:即使是大流量也可以保持連接。
如果因為 CPU backlog 不夠或者 flow limit 不夠,被丟棄的報文會將丟包信息計入
/proc/net/softnet_stat
接口
流控制功能默認會編譯到內核中(CONFIG_NET_FLOW_LIMIT),但不會啟用。它是為每個CPU獨立實現的(以避免鎖和緩存競爭),並通過在sysctl net.core.flow_limit_cpu_bitmap中設置相關位來切換CPU,它的CPU位圖接口與rps_cpus 相同。
/proc/sys/net/core/flow_limit_cpu_bitmap
通過將每個報文散列到一個哈希表bucket中,並增加每個bucket計數器來計算每條流的速率。哈希函數與RPS選擇CPU時使用的相同,但由於bucket的數目要遠大於CPU的數目,因此流控制可更精細地識別大流量,並減少誤報。默認的表大小為4096個bucket,可以通過sysctl工具修改:
net.core.flow_limit_table_len
只有在分配新表時才會查詢該值。修改該值不會更新現有的表。
建議配置
流控制在系統上有很多並行流時有用,如果單個連接佔用了CPU的50%,則表明存在問題。這種環境下,可以為所有的CPU啟用流控制特性,來處理網絡rx中斷(/proc/irq/N/smp_affinity可以設置中斷親和性)。
該特性依賴於輸入報文隊列長度超過流限制閾值(50%)+流歷史長度(256)。在實驗中將net.core.netdev_max_backlog設置為1000或10000效果很好。
RPS/RFS主要是針對單隊列網卡多CPU環境。而
/proc/irq/{IRQ}/smp_affinity和/proc/irq/{IRQ}/smp_affinity_list指定了哪些CPU能夠關聯到一個給定的IRQ源。RPS只是單純把數據包均衡到不同的cpu,這個時候如果應用程序所在的cpu和軟中斷處理的cpu不是同一個,此時對cpu cache的影響會很大。目前大多數SMP系統會使用smp_affinity功能,默認不啟用RPS。
RFS: Receive Flow Steering
雖然基於哈希的RPS可以很好地分配處理報文時的負載,但沒有考慮到應用所在的位置。Receive Flow Steering (RFS)擴展了這一點。RFS的目的是通過將報文的處理引導到正在消耗報文的應用程序線程所在的CPU上來提高數據緩存命中率。RFS依賴與RPS相同的機制來將入隊列的報文導向另外一個CPU的backlog隊列,並喚醒該CPU。
在RFS中,報文不會根據哈希結果進行轉發,哈希結果會作為流查詢表的索引。該表會將流映射到正在處理這些流的CPU上。流哈希(見RPS)用於計算該表的索引。記錄在表項中的CPU就是上次處理該條流的CPUs。如果一個表項中不包含有效的CPU,則映射到該表項的報文將會完全使用RPS。多個表項可能映射到相同的CPU上(存在很多條流,但僅有很少的CPU,且一個應用可能會使用很多流哈希來處理流)。
rps_sock_flow_table 是一個全局的流表,包含流期望的CPUs:處理當前在用戶空間中使用的流的CPU。每個表的值都對應一個CPU索引,並在執行recvmsg 和 sendmsg (準確地講是 inet_recvmsg(), inet_sendmsg(), inet_sendpage() 和 tcp_splice_read())時更新。
當調度器將一個線程轉移到一個新的CPU,但它在舊CPU上有未處理的接收報文時,收到的報文可能會亂序。為了防止發生這種情況,RFS使用一個秒流表來跟蹤每個流中未處理的報文:rps_dev_flow_table 是針對每個設備的每個硬件接收隊列的表。每個表中的值都保存了一個CPU索引和一個計數器。CPU索引表示入隊列(cpu的backlog隊列)流報文的當前CPU,後續由內核處理。理想情況下,內核和用戶空間的處理會發生在相同的CPU上,此時兩個表(rps_sock_flow_table和rps_dev_flow_table)中的CPU索引是相同的。但如果調度器最近轉移了用戶線程,而報文的入隊列和處理仍舊發生在老的CPU上,此時就會發生CPU不一致的情況。
當CPU處理的流有新報文入隊列時,rps_dev_flow_table 中的計數器會記錄當前CPU的backlog的長度。每個backlog隊列都有一個頭計數器,在報文出隊列時增加。尾計數器的計算方式為:頭計數器+隊列長度。即rps_dev_flow[i]中的計數器記錄了流i中的最後一個元素,該元素入隊列到為流i分配的CPU中(當然,表項i實際上是通過哈希選擇的,多條流可能會哈希到同一表項i)。
現在,避免出現亂序數據包的技巧是:當選擇處理報文的CPU時(通過get_rps_cpu()),會比較接收到數據包的隊列的rps_sock_flow表和rps_dev_flow表。如果流的rps_sock_flow 表中期望的CPU與rps_dev_flow 表中記錄的當前CPU匹配的話,報文會進入該CPU的backlog隊列。如果不同,當下面任一條成立時,會更新CPU,使其與期望的CPU匹配:
- 當前CPU的隊列頭計數器 >=
rps_dev_flow[i]中記錄的尾計數器 - 當前CPU未設置(>= nr_cpu_ids)
- 當前CPU下線
在上述檢查之後,報文會發送(可能會更新CPU)到當前CPU。上述規則用於保證只有當老CPU上不存在未處理的報文時才會將一個流轉移到一個新的CPU上(因為未處理的報文可能晚於將要在新CPU上處理的報文)。
RFS 配置
只有啟用了內核參數CONFIG_RPS (SMP默認會啟用)之後才能使用RFS。該功能只有在明確配置之後才能使用。可以通過如下參數設置全局流表rps_sock_flow_table的表項數:
/proc/sys/net/core/rps_sock_flow_entries
每個隊列的rps_dev_flow_table 流表中的表項數可以通過如下參數設置:
/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt
建議配置
上述配置都需要在為接收隊列啟用RFS前完成配置。兩者的值會四捨五入到最接近的2的冪。建議的流數應該取決於任意時間活動的連接數,這可能大大少於打開的連接數。我們發現rps_sock_flow_entries的值32768在中等負載的服務器上可以很好地工作。
對於一個單隊列設備,單隊列的rps_flow_cnt 的值通常設置為與rps_sock_flow_entries相同的值。對於多隊列設備,每個隊列的rps_flow_cnt 的值可以配置為與rps_sock_flow_entries/N,N表示隊列的數目。例如,如果rps_sock_flow_entries 為32768,且配置了16個接收隊列,每個隊列的rps_flow_cnt 為2048。
rps_sock_flow_table的結構如下:struct rps_sock_flow_table { u32 mask; u32 ents[0]; };
mask用於將哈希值映射到表的索引。由於表大小會四捨五入為2的冪,因此mask設為table_size – 1,並且很容易通過hash & scok_table->mask索引到一個sk_buff。表項通過rps_cpu_mask分為流id和CPU id。低位為CPU id,高位為流id。當應用在socket上進行操作 (inet_recvmsg(), inet_sendmsg(), inet_sendpage(), tcp_splice_read())時,會調用sock_rps_record_flow() 更新
rps_sock_flow_table表。當接收到一個報文時,會調用
get_rps_cpu()來決定報文發到哪個CPU隊列,下面是其計算方式:ident = sock_flow_table->ents[hash & sock_flow_table->mask]; if ((ident ^ hash) & ~rps_cpu_mask) goto try_rps; next_cpu = ident & rps_cpu_mask;
get_rps_cpu()使用流表的mask字段來獲取表項的索引,然後檢查匹配到的表項是否存在高比特位,如果存在,則使用表項中的CPU,並將其分配給該報文。否則使用RPS映射。RFS使用pre-queue的
rps_dev_flow_table來跟蹤未處理的報文,解決在CPU切換之後,應用可能接收到亂序報文的問題。rps_dev_flow_table的結構如下:struct rps_dev_flow { u16 cpu; u16 filter; /* For aRFS */ unsigned int last_qtail; }; struct rps_dev_flow_table { unsigned int mask; struct rcu_head rcu; struct rps_dev_flow flows[0]; };與sock流表一樣,
rps_dev_flow_table也使用table_size-1作為掩碼,而表大小也必須四捨五入為2的冪。當一個報文入隊列後,last_qtail更新為CPU隊列的末尾。如果應用遷移到一個新的CPU,則sock流表會反應這種變化,且get_rps_cpu()會為流選擇新的CPU。在設置新CPU之前,get_rps_cpu()會檢查當前隊列的首部是否經過了last_qtail,如果是,則表示隊列中沒有未處理的報文,可以安全地切換CPU,否則get_rps_cpu()會使用rps_dev_flow->cpu中記錄的老CPU。
上圖展示了RFS是如何工作的。內核獲取一個藍色的報文,屬於藍色的流。 per-queue流表 (
rps_dev_flow_table)檢測到藍色的報文屬於CPU2(老的CPU),而此時socket將sock流表更新為使用CPU1,即新的CPU。get_rps_cpu()會對兩個表進行檢查,發現CPU發生了遷移,因此會更新 per-queue流表(假設此時在CPU2上沒有未處理的報文) ,並將CPU1分配給藍色的報文。
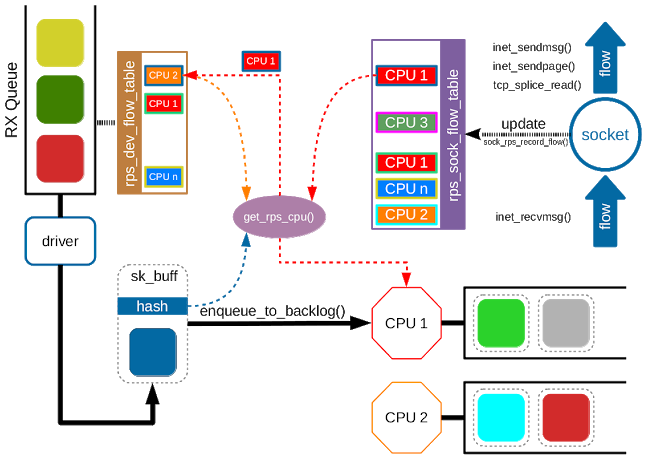
加速(Accelerated )RFS
加速RFS 對RFS來說,就像RSS對RPS:它是一個硬件加速負載均衡機制,基於消耗流報文的應用所運行的位置來使用軟狀態進行導流。加速RFS的性能要比RFS好,因為報文會直接發送到消耗該報文的線程所在的CPU上。目標CPU可能是應用運行的CPU,或在緩存結構中接近應用線程所在的CPU的CPU。
為了啟用加速RFS,網絡棧會帶調用ndo_rx_flow_steer 驅動函數來與期望(匹配特定流)的硬件隊列進行交互。網絡棧會在rps_dev_flow_table 中的流表項更新之後調用該函數。驅動會使用一個設備特定的方法來編程NIC,使其引導報文。
流的硬件隊列是從rps_dev_flow_table中記錄的CPU派生的。網絡棧會查詢CPU到硬件隊列的映射,該映射由NIC驅動程序維護,它是自動生成(/proc/interrupts中展示)的IRQ親和表的反向映射。驅動可以使用內核庫cpu_rmap (「CPU affinity reverse map」)來生成映射。對於每個CPU,映射中相應的隊列設置為最接近緩存位置的CPU的隊列。
加速RFS 配置
只有在內核編譯時啟用了CONFIG_RFS_ACCEL且NIC設備和驅動同時支持的情況下才能使用加速RFS功能。同時它還要求通過ethtool啟用ntuple過濾功能。驅動程序會為每個接收隊列配置的IRQ親和性自動推導CPU到隊列的映射,不需要額外的配置。
建議配置
如果希望使用RFS且NIC支持硬件加速,就可以啟用該技術。
為了啟用aRFS,需要一張帶有可編程ntupter過濾器的網卡,和驅動程序的支持。可以使用如下方式啟用ntuple過濾器:
# ethtool -K eth0 ntuple on對於支持aRFS的驅動,需要實現ndo_rx_flow_steer 來幫助set_rps_cpu()配置硬件過濾器。當
get_rps_cpu()決定為一條流分配CPU時,它會調用set_rps_cpu()。set_rps_cpu()首先會檢查網卡是否支持ntuple過濾器,如果支持,它會請求rx_cpu_rmap來為流找一個合適的RX隊列。rx_cpu_rmap是一個由驅動維護的特殊的映射,該映射用來為CPU查找一個合適的RX隊列,找到的隊列可是與給定CPU直接關聯的隊列,也可能是臨近的緩存位置上的隊列。在獲取到RX隊列索後,set_rps_cpu()會調用ndo_rx_flow_steer()來通知驅動為給定的流創建一個新的過濾器。ndo_rx_flow_steer()會返回過濾器id,過濾器id會被保存到per-queue流表中。除了實現
ndo_rx_flow_steer(),驅動還需要周期性地調用rps_may_expire_flow()檢查過濾器是否有效,並移除過期的過濾器。

XPS: Transmit Packet Steering
Transmit Packet Steering是一種在多隊列設備上傳輸報文時,為報文智能選擇傳輸隊列的機制。可以通過記錄兩種映射來實現,即將CPU映射到硬件隊列或將接收隊列映射到傳輸隊列。
-
XPS使用CPU映射
該映射的目的是隊列專門分配給 CPU 的一個子集,在此隊列上的CPU會完成這些隊列的報文傳輸。這種方式提供了兩種好處:首先,由於競爭同一個隊列的cpu更少,因此大大降低了設備隊列的鎖競爭(當每個CPU完成自己的傳輸隊列時會釋放鎖);其次,降低了傳輸競爭導致的緩存miss率,特別是對那些保存了sk_buff結構的數據緩存行。
-
XPS使用接收隊列映射
該映射用於基於管理員設置的接收隊列映射選擇傳輸隊列。一組接收隊列可以映射到一組傳輸隊列(多對多,但通常會使用1:1映射)。這將允許在相同的隊列上下文(如CPU和緩存等)中對報文進行傳輸和接收。這種方式可以用於繁忙的輪詢多線程工作負載,在這些工作負載中,很難將特定的CPU與特定的應用程序線程關聯起來。應用線程不會固定運行在某些CPU上,且每個線程會基於一個單獨的隊列接收報文。socket會緩存接收隊列的數目。在這種模型下,將傳輸隊列與相關的接收隊列關聯起來,可以有效降低CPU開銷。此時傳輸工作會鎖定到給定應用執行輪詢的上下文中,避免觸發其他CPU造成的開銷。當應用程序在繁忙的輪詢期間清理報文時,可能會在與應用相同的線程上下文中完成傳輸,從而減少延遲。
可以通過設置一個CPUs/接收隊列位圖來為每個傳輸隊列配置XPS。每個網絡設備會計算並維護從CPUs到傳輸隊列或從接收隊列到傳輸隊列的反向映射。當在一條流中傳輸首個報文時,會調用get_xps_queue()選擇一個隊列。該函數會為每個socket連接使用的接收隊列的ID來匹配”接收隊列到傳輸隊列”的查詢表。另外,該函數也可以使用運行的CPU ID作為key來匹配”CPU到隊列”的查詢表。如果這個ID匹配到一個隊列,則使用該隊列傳輸報文。如果匹配到多個隊列,則通過流哈希計算出的索引來選擇一個隊列。當基於接收隊列映射選擇傳輸隊列時,傳輸設備不會針對接收設備進行驗證,因為這需要在數據路徑中進行代價高昂的查找操作。
為特定傳輸流選擇的隊列會保存在對應的流(如TCP)socket結構體中。該傳輸隊列會用於這條流上的後續報文的傳輸,方式發送亂序(ooo)報文。這種方式還分攤了流中所有報文調用get_xps_queues()的開銷。為了防止亂序報文,只有設置了流報文的skb->ooo_okay字段,才能變更這條流使用的隊列。這個標誌位標識這條流中沒有未處理的報文,這樣就可以切換傳輸隊列,而不用擔心生成亂序報文的風險。傳輸層會負責正確處理亂序報文。如TCP,當確認一個連接上的所有數據後就會設置該標誌。
XPS配置
只有在內核啟用了CONFIG_XPS 符號時才能使用XPS功能。如果內核編譯了該功能,由驅動決定是否以及如何在設備初始化時配置XPS。使用sfsfs來檢查和配置CPUs/接收隊列到傳輸隊列的映射。
對於基於CPUs的映射:
xps_cpus的意義與rx-
/rps_cpus類似,確定隊列使用的CPU。
/sys/class/net/<dev>/queues/tx-<n>/xps_cpus
對於基於接收隊列的映射:
/sys/class/net/<dev>/queues/tx-<n>/xps_rxqs
建議配置
對於一個只有一條傳輸隊列的網絡設備,由於這種情況下無法選擇傳輸對,此時XPS是不起作用的。在多隊列系統中,建議配置XPS,這樣每個CPU會映射到一個傳輸隊列。如果系統中傳輸隊列的數目等於CPUs的數目,則每個隊列仍然會映射到一個CPU,此時不會產生多隊列競爭CPU的情況。如果隊列的數目少於CPUs的數目,那麼,共享給特定隊列的最佳CPU可能是與處理該隊列的傳輸完成(傳輸中斷)的CPU共享高速緩存的CPU。
對於基於接收隊列選擇的傳輸隊列,XPS需要明確配置接收隊列到傳輸隊列的映射關係。如果用戶配置的接受隊列映射沒有生效,則會使用基於CPU映射來選擇傳輸隊列。
單傳輸隊列速率限制
這是由硬件實現的速率限制機制,當前支持設置最大速率熟悉,使用如下值設置一個Mbps值:
/sys/class/net/<dev>/queues/tx-<n>/tx_maxrate
0值表示不啟用,默認為0.
更多信息
RPS 和RFS是內核2.6.35引入的,XPS是2.6.38引入的。
加速RFS是2.6.35引入的。
參考:
- Queues, RSS, interrupts and cores
- Linux Network Scaling: Receiving Packets
- Linux 網絡協議棧收消息過程-Per CPU Backlog


