MySQL索引(一)索引基礎
索引是數據庫系統裏面最重要的概念之一。一句話簡單來說,索引的出現其實是為了提高數據查詢的效率,就像書的目錄一樣。
常見模型
索引的出現是為了提高查詢效率,但是實現索引的方式卻有很多種,這裡就介紹三種常見、也比較簡單的數據結構,它們分別是哈希表、有序數組和搜索樹。
哈希表
哈希表是一種以key-value存儲數據的結構。通過哈希函數把key換算成一個確定位置,然後把value放在這個數據的這個位置上。
但是當存儲的數據越來越多,就有可能出現兩個不同的key通過哈希函數得到了一樣的值,這時候就出現衝突。而這時就引入鏈表來解決這種衝突了。
哈希表這種數據結構適用於只有等值查詢的場景,時間複雜度為O(1),但是對於範圍查找就必須全部遍歷了,時間複雜度為O(n)。
有序數組
有序數組在等值查詢和範圍查詢場景中的性能非常優秀。
但是需要往中間插入時就必須要挪動數據,時間複雜度很高。
搜索樹
二叉搜索樹在查詢和插入、刪除數據方面能夠中和上面兩種結構。查找時間複雜為O(logn)、插入刪除的時間複雜度為O(logn)。
雖然二叉搜索樹的搜索效率很高,但是在大多數的數據庫並不使用二叉樹。原因是索引要寫在磁盤上。
磁盤上的隨機讀是很耗時間的,為了讓一個查詢盡量少地讀磁盤,就必須在查詢過程中訪問盡量少的數據塊。
那麼就不應該使用二叉樹,而是要使用「N」叉樹,這裡的「N」取決於數據塊的大小。
B+樹是為磁盤設計的一種平衡查找樹。在B+樹中,所有記錄節點都是按鍵值的大小順序存放在同一層的葉子節點上,由各葉子節點指針進行連接。
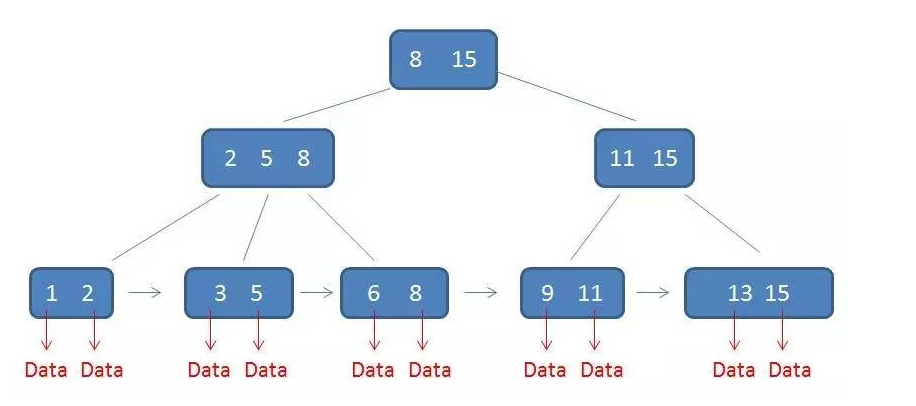
索引類型
B+樹索引
數據庫中的B+樹索引可以分為主鍵索引和普通索引兩種,也有叫聚集索引(clustered index)和輔助索引(secondary index)
但不管是主鍵索引還是普通索引,都是使用B+樹的,即高度平衡的,葉子節點存放着所有數據。
主鍵索引
InnoDB存儲引擎表是索引組織表,即表中數據按主鍵順序存放。
主鍵索引就是按照每張表的主鍵構造一棵B+樹,同時葉子節點中存放的是行數據。每張表只能擁有一個主鍵索引。
普通索引
普通索引與主鍵索引的區別在於,普通索引的葉子節點並不包含行數據,而是包含主鍵。
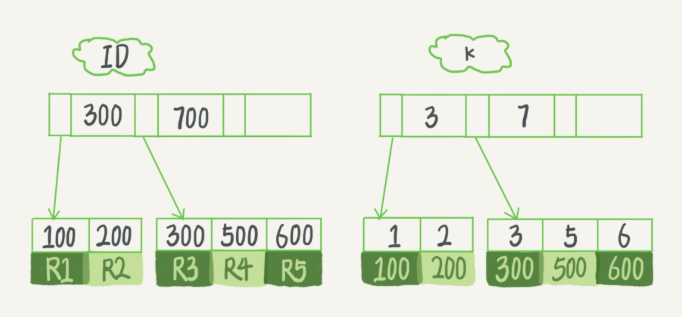
基於主鍵索引和普通索引的查詢有什麼區別?
- 如果語句是select * from T where ID=500,即主鍵索引查詢方式,則只需要搜索ID這棵B+樹;
- 如果語句是select * from T where k=5,即普通索引查詢,則需要先搜索k索引樹,得到ID的值為500,再到ID索引樹搜索一次。這個過程稱為回表。
也就是說,基於非主鍵索引的查詢需要多掃描一棵索引樹。因此我們應該盡量使用主鍵索引查詢。
哈希索引
哈希索引基於哈希表實現,在MySQL中只有Memory引擎顯示支持哈希索引,也是Memory引擎表的默認索引類型。
下面是創建Memory引擎表的語句:
CREATE TABLE `testhash` (
`fname` varchar(50) DEFAULT NULL,
`lname` varchar(50) DEFAULT NULL,
KEY `fname` (`fname`) USING HASH
) ENGINE=MEMORY;
哈希索引限制
- 哈希索引只保存哈希碼和指針,而不存儲字段值,所以不能使用索引中的值來避免讀取行。不過訪問內存中的行速度非常快,所以對性能影響並不大。
- 哈希索引數據並不是按照索引值順序存儲的,所以無法無法用於排序
- 哈希索引不支持部分索引列查找,因為哈希索引始終是使用索引列的全部內容來計算哈希碼。
- 哈希索引只支持等值比較查詢,不支持範圍查詢。
- 哈希衝突會影響查詢速度,此時需要遍歷索引中的行指針,逐行進行比較。
- 如果哈希衝突很多,一些索引維護操作的代價會很高。
自定義哈希索引
在InnoDB中,某些索引值被使用的非常頻繁的時候,它會在內存中基於B+樹的基礎上再創建一個哈希索引,使其不必要從根節點就查找。完全自動的內部行為,用戶無法配置或更改。

