Boost隨機庫的簡單使用:Boost.Random(STL通用)
文章目錄
文章內容介紹
Boost.Random是Boost裏面的一個隨機庫,它的第一正式版是在Boost 1.15中提供。它裏面提供了大量的隨機算法,比如mt19937算法,加權概率,隨機密碼等。可以很方便的提高編碼效率。
本文主要介紹了Boost.Random的一些簡單使用本文主要分為四個部分,第一部分為此簡單介紹,第二部分為Boost.Random的使用,第四部分為總結。
本文參考的Boost版本為1.74。
Boost隨機庫的簡單使用
生成一個隨機的整數
boost::random::mt19937 gen(time((time_t *)NULL));
std::cout << gen() << std::endl;
首先構造一個隨機數生成器,這裡我們使用mt19937算法的隨機數生成器。然後直接將隨機數生成器作為一個函數對象使用,便可以得到一個區間為\([0, 2^{32}-1]\)的隨機數。
如果要生成64位的隨機數,可以使用boost::random:mt19937_64。相應的,它可以產生區間為\([0, 2^{64}] – 1\)的隨機數。
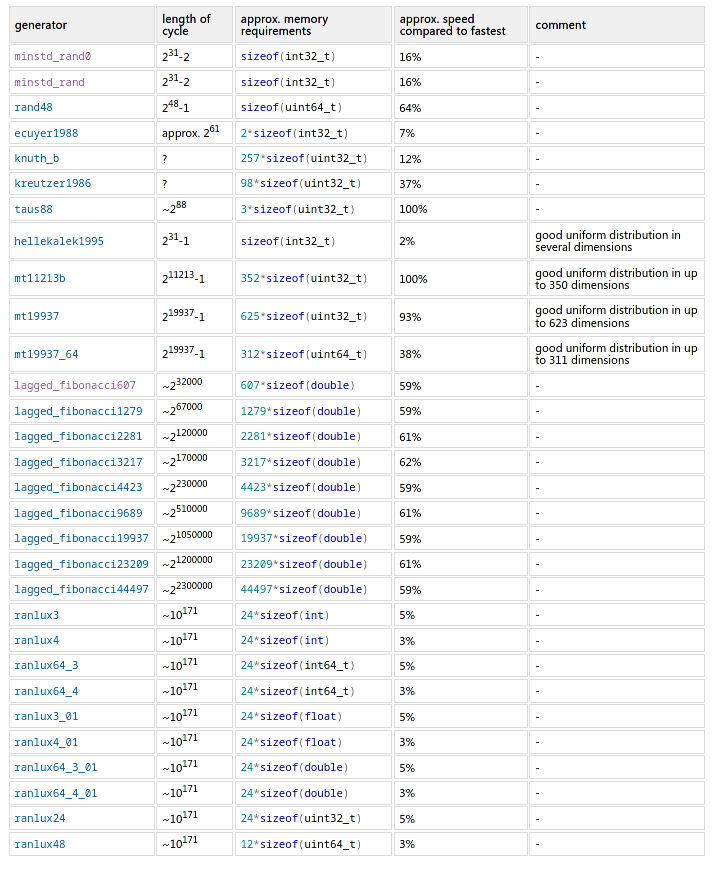
除了mt19937算法以外,Boost.Random還提供了非常多種的平均隨機數算法,譬如minstd_rand0、minstd_rand、rand48、ecuyer1988、knuth_b等。
除了使用算法生成一個偽隨機數外,Boost還提供了一個接口random_device,可以產生真·隨機數。它依賴於系統提供的硬件隨機,比如在Linux下會使用/dev/urandom。理論上來說,提供的硬件隨機應該是不會產生錯誤,或者讀取到結尾的。如果發生了,便會拋出std::io_base::failure異常。使用entropy方法可以獲得隨機數生成器的熵值。
生成一個區間的平均概率隨機數
一般情況下,我們都是需要生成一個區間內的隨機數,這才有一定的使用價值。在C語言中,我們通過以下方法獲得
rand()%(upper_bound - lower_bound) + lower_bound
而在Boost中,它為我們提供了一個方法,可以通過定義分佈的方法,來生成一個區間的隨機整數。
boost::random::uniform_int_distribution<> dis(1, 6);
std::cout << dis(gen) << std::endl;
首先我們定義了一個分佈,從這個類的名稱我們就可以知道,這是一個平均的整數分佈。分佈和生成器一樣,是一個函數對象,通過輸入一個隨機數生成器,就可以得到隨機區域內的整數。生成的範圍為\([min, max]\)
生成隨機實數也是類似,生成的範圍為\([min, max)\)
boost::random::uniform_real_distribution<> fdis(0, 2);
std::cout << fdis(gen) << std::endl;
除了這些比較常用的平均分佈外,Boost還提供了兩種使用次數比較多的平均分佈:
uniform_smallint,它和uniform_int_distribution類似,不過這個分佈要求生成的範圍要遠小於隨機數生成器的範圍;uniform_01產生\([0, 1)\)之間的隨機數。
按概率生成一個區間的隨機整數
這種情況如果使用C語言實現,一般會是這樣操作。
// 選擇的概率,選擇的數據為[0,3]
double prob = {0.1, 0.2, 0.3, 0.4};
double choose_prob = (random() % 100000)/100000.0;
choosed_number = 0;
for (choosed_number = 0; choosed_number < 4; ++choosed_number) {
choose_prob -= prob[choosed_number];
if (choose_prob < 0) break;
}
此時,choosed_number為選擇的數據。在Boost.Random中,提供了更為優雅的方法,來實現這一操作。
boost::random::discrete_distribution<> prob_dis({0.1, 0.2, 0.3, 0.4});
std::vector<int> count(4, 0);
for (int loop_i = 0; loop_i < 100000; ++loop_i) {
count[prob_dis(gen)]++;
}
for (int loop_i = 0; loop_i < 4; ++loop_i) {
std::cout << count[loop_i] << ",";
}
std::cout << std::endl;
為了更好的表現數據的分佈,我使用了一個計數器,來對10萬次實驗的結果進行統計。得到結果如下:
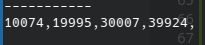
可以看到結果的分佈和我們設置的概率相近。
當然,部分的時候,我們設置的並不是概率(和為一),而是權重(和可能不為一),這個在discrete_distribution中也是可行的,也就是:
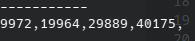
boost::random::discrete_distribution<> prob_dis({1, 2, 3, 4});
是可行的,而且它們的結果是一致的。
除此之外,還可以通過Boost.range和函數來設置不同的概率。
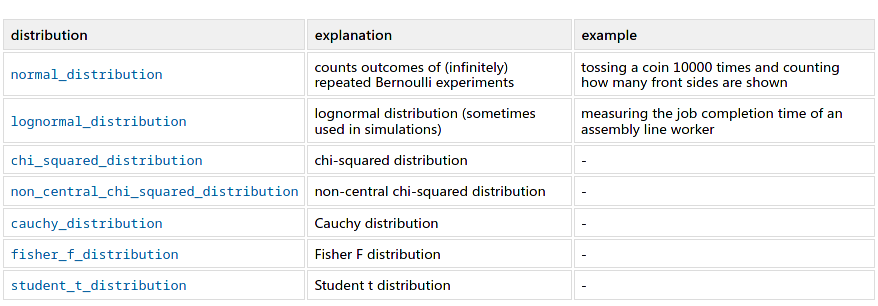
一些經典的分佈
除了自定義分佈外,Boost還提供了許多的經典分佈,只需要通過簡單的參數設置就可以獲得一些經典的分佈器。
- 伯努利分佈
伯努利分佈又稱為0-1分佈,結果只有0或者1。

- 泊松分佈
泊松分佈適合於描述單位時間內隨機事件發生的次數的概率分佈。如某一服務設施在一定時間內受到的服務請求的次數,電話交換機接到呼叫的次數、汽車站台的候客人數、機器出現的故障數、自然災害發生的次數、DNA序列的變異數、放射性原子核的衰變數、激光的光子數分佈等等。

- 正態分佈
正態分佈又名高斯分佈,是一個非常常見的連續概率分佈。正態分佈在統計學上十分重要,經常用在自然和社會科學來代表一個不明的隨機變量。
與STL的對比
STL作為C++的標準庫,裏面也包含有Random庫。根據我的查閱的資料,他們之間的借口大部分是相同的,不過也有一小部分的差異。譬如:
- default_random_engine
STL提供了一個default_random_engine。但是這個隨機數生成器並不好用,也需要輸入一個種子,而且當種子相近的時候,其值也非常相近。個人認為隨機性並不是特別好。
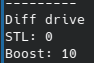
- random_drive
STL和Boost.Random中的硬件隨機數生成器描述相近,但是在我個人實際的使用中,Boost.Random給出的熵值為10(部分使用隨機?),STL給出的熵值為0(完全使用隨機算法)。
Ref
- //www.boost.org/doc/libs/1_74_0/doc/html/boost_random/tutorial.html
- //zh.wikipedia.org/wiki/伯努利分佈
- //zh.wikipedia.org/wiki/泊松分佈
- //zh.wikipedia.org/wiki/正態分佈
博客原文地址://www.cnblogs.com/ink19/p/Boost_Random.html