論文閱讀——D2-Net: A Trainable CNN for Joint Description and Detection of Local Features
- 2020 年 12 月 4 日
- AI
一、概述
作為近兩年detector和descriptor joint learning(也稱one-stage)類型論文的又一代表,D2-Net是一種相當特別的結構。其特點是「一圖兩用」,即網絡預測出的dense tensor即是detection score maps,又是description map特徵圖即代表特徵檢測結果又代表特徵描述結果(注意預測的特徵圖並不是原圖分辨率大小)。換句話說,D2-Net的特徵檢測模塊和描述模塊是高度耦合的。
本文主要針對的是appearance變化較大(包括日-夜變化、大的視角變化等)場景下的圖像匹配任務。文章作者比較了兩種局部特徵學習方法:sparse方法和dense方法。其中sparse方法高效,但是在appearance變化大的場景提取不到可重複的關鍵點,其原因在於特徵提取器只使用淺層圖像信息,不使用語義信息;dense方法則直接利用深層特徵提取密集特徵描述,更加魯棒卻以更高的匹配時間和內存開銷為代價。
因此作者的目的在於,提出一種足夠魯棒的sparse local feature,讓其提取的特徵(興趣點)具有更好的repeatability,進而實現既有sparse方法的高效性,又有dense方法的魯棒性。其核心idea是將特徵提取階段延後,使得局部特徵也可以利用高層語義信息,而不是只考慮低層信息。
問題:關於這裡的sparse和dense方法
-
作者這裡提到sparse方法的缺陷是keypoint不夠可重複,因為這些sparse feature提取時只考慮圖像低層特徵。但是這段又沒給參考文獻,所以本文究竟是針對哪些論文做的改進呢?近幾年的local feature並不會像作者說的那樣「only consider small low-level information like image regions」啊?難道是針對SIFT為代表的的傳統方法的缺陷嗎?看到下面評估部分也有和SuperPoint對比,那SuperPoint也有這個缺陷嗎?
-
dense方法這幾篇文獻沒讀過,但是作者說這些方法「跳過檢測直接提取密集描述子的方法」,這還是圖像匹配嗎?
答:閱讀了下UCN的論文,發現所謂密集匹配方法就是直接對輸入兩圖(A,B)預測特徵然後在特徵空間上進行最近鄰搜索等方法,預測出特徵之間的稠密關聯,簡單理解就是已知圖像A上的關鍵點就是每個像素點,然後要求它們在圖像B上的對應位置(理解的不一定準確)。
關鍵詞:A single CNN plays a dual role; joint optimization; different train/test model structure
二、方法
2.1 模型結構設計
不同於SuperPoint或者SEKD,本文雖然也是dense prediction類型的結構,但並不同時預測kpt和description兩個圖,而是只預測了一個形狀為HxWxd(d為特徵描述的長度)的特徵圖,然後既作描述結果又作檢測結果…從spatial維度來說,該特徵圖的每個像素位置是一個描述子;從channel維度來說,每一個通道代表一個特徵檢測器的檢測結果,總共得到d個2D響應圖,這裡可以用SIFT中的高斯差分金字塔響應來類比。

後續的興趣點提取需要對這個d通道的特徵圖做進一步的後處理:
按照上面對D2特徵圖的定義,如果(i,j)位置是一個興趣點,則從通道維度來說該像素位置最終的檢測結果肯定要取檢測器響應值最大的通道對應數值,這樣就選出了通道;從空間維度來說又要滿足該位置在該通道的2D map必須為一個局部最大值。即本文中的”hard feature detection”:

首先對輸入圖像構建圖像金字塔,然後在每個scale上進行forward,得到D2特徵圖,再把多尺度特徵圖逐scale上採樣並與同分辨率融合(見下式),得到融合後的特徵圖。預測階段根據融合特徵圖進行上述後處理,即可提取出特徵點。

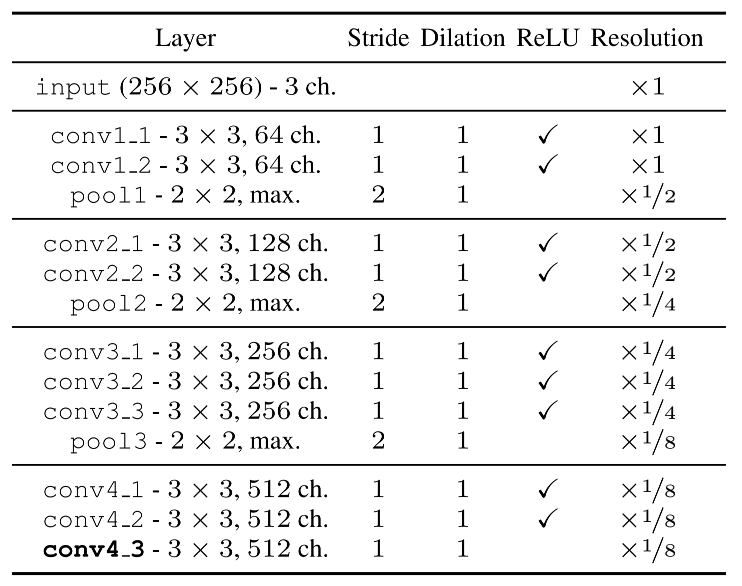
由於上述特點,網絡結構本身發非常簡單,直接用VGG16 conv4_3之前的部分,恢復ImageNet上的預訓練權重,然後除了最後一層conv4_3之外全部凍結,只對該層做微調。不過關於模型,有兩個值得注意的地方:
1.使用VGG16的結果比ReseNet好很多
2.訓練時和測試時的模型結構不同
具體來說,在測試階段為了提高特徵的分辨率,將pool3改成一個stride為1的avg pool,隨後的三層conv dilation ratio調整為2,以維持相同的感受野。作者解釋是說訓練時為了減小內存使用比較小的特徵分辨率,測試時為了提高特徵定位能力,將分辨率提升到原圖的1/4,並加上了一個類似SIFT中使用的局部特徵提煉,然後將特徵插值上採樣到原分辨率。

不過訓練過程不能用上面的hard feature detection,因為其不可微。故作者提出了一個soft的版本,其設計思想就是模仿hard方法的通道選擇和空間位置選擇(即通道內的局部最大值):
對於空間位置選擇,作者會對特徵圖的每個像素求一個α(i,j),得到α map(shape為[h,w,d]):

其中N(i,j)代表以(i,j)為中心的9-鄰域。因此可見這裡的局部最大值其實是在3×3區域內的最大值,而不是式(3)中寫的那樣,整個通道只輸出一個最大值。
對於通道選擇,直接計算一個ratio-to-max得到β圖(shape為[h,w,d]):

根據kpt的定義,score map s就應該是α map和β map的乘積map在通道維度求最大值的結果。最後再做一個歸一化:(問題:這個歸一化讓score map的像素值之和為1是什麼意思?score map不應該用sigmoid之類的轉為0-1之間的分佈比較合理嗎?)


關於這部分還要考慮一個問題,為什麼D2-Net需要在訓練中提取興趣點?(比如R2D2等結構,都是直接針對kpt score map做優化,只有實際預測時才需要根據score map提取特徵點這個步驟)
答:這個問題的理解是不正確的,訓練中並不是提取興趣點,而是在得到」single score map”。上面的hard feature detection相當於NMS的過程,輸出的是稀疏的興趣點位置坐標;而訓練檢測模塊需要hxw的score map,故先要把hxwxd的特徵圖經過一個可微的步驟,處理後得到該score map。
2.2 聯合優化目標函數設計
①triplet margin ranking loss(只考慮描述子)
訓練描述子其實沒有太多不一樣的地方,就是根據輸入pair的correspondences,將每一個匹配對c視為正對,不匹配對為負對,對構成的三元組進行訓練。主要問題是如何根據當前匹配對c構建最有意義的負對。作者這裡用了一個基於鄰域的困難樣本挖掘策略,假如當前匹配為下圖的點A和點B,那麼分別在I1和I2扣去A\B鄰域的區域找負對,並分別與B的描述子dB、A的描述子dA進行比較,找到所有這種負對中相似度最小的,與c構建三元組。
以下p(c)和n(c)分別代表正對距離和負對距離。m(c)代表當前匹配c的triplet loss。




②加入描述子優化的triplet margin ranking loss
由於D2特徵即代表興趣點score map也代表描述子,本文的優化需要對檢測和描述進行聯合優化。作者在triplet margin ranking loss基礎上加入了提升檢測結果可重複性這一優化目標,具體實現方法是:利用輸入兩圖像中所有correspondences的檢測得分來對當前匹配計算出的triplet loss進行加權平均,如果當前匹配triplet loss很低(即該對匹配的距離遠小於其各自的最難負對),則為了最小化loss,這一對triplet loss小(即區分度高)的correspondence自然要給更大的權值;其他triplet loss大的correspondence就給小點的權值。
感覺文中式(13)的符號有點confusing,m(p(c),n(c))直接寫成,m(c)可能更加簡潔。

三、評價
- 本文核心idea是將特徵提取延後,使用網絡提取的深層特徵進行後處理,得到用於檢測kpt的score map。與此同時作者發現提取到的特徵也可以順便作為描述子,故提出了這種「一圖兩用」,聯合優化的結構
- 本文論文的比較簡單,但是給出的代碼實現非常整齊。
- D2-Net測試階段為了獲得更高的分辨率,將訓練的網絡結構進行修改(通過減小pool stride和增大conv dilate rate維持感受野),使得測試時可以正常加載訓練的權重,且特徵分辨率更高。這種操作感覺很有創意,之前沒有遇到過。
- 作者在實驗階段嘗試用預訓練好的resnet作為backbone,但是結果比vgg差不少,這個也比較奇怪。

