馬爾可夫網絡、馬爾可夫模型、馬爾可夫過程
- 2019 年 11 月 20 日
- 筆記
貝葉斯網絡介紹
這一節我們重點來講一下馬爾可夫,正如題目所示,看了會一臉蒙蔽,好在我們會一點一點的來解釋上面的概念,請大家按照順序往下看就會完全弄明白了,這裡我給一個通俗易懂的定義,後面我們再來一個個詳解。
以下共分六點說明這些概念,分成條目只是方便邊閱讀邊思考,這6點是依次遞進的,不要跳躍着看。
- 將隨機變量作為結點,若兩個隨機變量相關或者不獨立,則將二者連接一條邊;若給定若干隨機變量,則形成一個有向圖,即構成一個網絡。
- 如果該網絡是有向無環圖,則這個網絡稱為貝葉斯網絡。
- 如果這個圖退化成線性鏈的方式,則得到馬爾可夫模型;因為每個結點都是隨機變量,將其看成各個時刻(或空間)的相關變化,以隨機過程的視角,則可以看成是馬爾可夫過程。
- 若上述網絡是無向的,則是無向圖模型,又稱馬爾可夫隨機場或者馬爾可夫網絡。
- 如果在給定某些條件的前提下,研究這個馬爾可夫隨機場,則得到條件隨機場。
- 如果使用條件隨機場解決標註問題,並且進一步將條件隨機場中的網絡拓撲變成線性的,則得到線性鏈條件隨機場。
2. 馬爾可夫模型
2.1 馬爾可夫過程
馬爾可夫過程(Markov process)是一類隨機過程。它的原始模型馬爾可夫鏈,由俄國數學家A.A.馬爾可夫於1907年提出。該過程具有如下特性:在已知目前狀態(現在)的條件下,它未來的演變(將來)不依賴於它以往的演變 (過去 )。例如森林中動物頭數的變化構成——馬爾可夫過程。在現實世界中,有很多過程都是馬爾可夫過程,如液體中微粒所作的布朗運動、傳染病受感染的人數、車站的候車人數等,都可視為馬爾可夫過程。
每個狀態的轉移只依賴於之前的n個狀態,這個過程被稱為1個n階的模型,其中n是影響轉移狀態的數目。最簡單的馬爾可夫過程就是一階過程,每一個狀態的轉移只依賴於其之前的那一個狀態,這個也叫作馬爾可夫性質。用數學表達式表示就是下面的樣子:
假設這個模型的每個狀態都只依賴於之前的狀態,這個假設被稱為馬爾科夫假設,這個假設可以大大的簡化這個問題。顯然,這個假設可能是一個非常糟糕的假設,導致很多重要的信息都丟失了。

因此,一階馬爾可夫過程定義了以下三個部分:
- 狀態:晴天和陰天
- 初始向量:定義系統在時間為0的時候的狀態的概率
- 狀態轉移矩陣:每種天氣轉換的概率
馬爾可夫模型(Markov Model)是一種統計模型,廣泛應用在語音識別,詞性自動標註,音字轉換,概率文法等各個自然語言處理等應用領域。經過長期發展,尤其是在語音識別中的成功應用,使它成為一種通用的統計工具。到目前為止,它一直被認為是實現快速精確的語音識別系統的最成功的方法。
3. 隱馬爾可夫模型(HMM)
在某些情況下馬爾科夫過程不足以描述我們希望發現的模式。回到之前那個天氣的例子,一個隱居的人可能不能直觀的觀察到天氣的情況,但是有一些海藻。民間的傳說告訴我們海藻的狀態在某種概率上是和天氣的情況相關的。在這種情況下我們有兩個狀態集合,一個可以觀察到的狀態集合(海藻的狀態)和一個隱藏的狀態(天氣的狀況)。我們希望能找到一個算法可以根據海藻的狀況和馬爾科夫假設來預測天氣的狀況。
而這個算法就叫做隱馬爾可夫模型(HMM)。

隱馬爾可夫模型 (Hidden Markov Model) 是一種統計模型,用來描述一個含有隱含未知參數的馬爾可夫過程。它是結構最簡單的動態貝葉斯網,這是一種著名的有向圖模型,主要用於時序數據建模,在語音識別、自然語言處理等領域有廣泛應用。
3.1 隱馬爾可夫三大問題
- 給定模型,如何有效計算產生觀測序列的概率?換言之,如何評估模型與觀測序列之間的匹配程度?
- 給定模型和觀測序列,如何找到與此觀測序列最匹配的狀態序列?換言之,如何根據觀測序列推斷出隱藏的模型狀態?
- 給定觀測序列,如何調整模型參數使得該序列出現的概率最大?換言之,如何訓練模型使其能最好地描述觀測數據?
前兩個問題是模式識別的問題:1) 根據隱馬爾科夫模型得到一個可觀察狀態序列的概率(評價);2) 找到一個隱藏狀態的序列使得這個序列產生一個可觀察狀態序列的概率最大(解碼)。第三個問題就是根據一個可以觀察到的狀態序列集產生一個隱馬爾科夫模型(學習)。
對應的三大問題解法:
- 向前算法(Forward Algorithm)、向後算法(Backward Algorithm)
- 維特比算法(Viterbi Algorithm)
- 鮑姆-韋爾奇算法(Baum-Welch Algorithm) (約等於EM算法)
下面我們以一個場景來說明這些問題的解法到底是什麼?
小明現在有三天的假期,他為了打發時間,可以在每一天中選擇三件事情來做,這三件事情分別是散步、購物、打掃衛生(對應着可觀測序列),可是在生活中我們所做的決定一般都受到天氣的影響,可能晴天的時候想要去購物或者散步,可能下雨天的時候不想出門,留在家裡打掃衛生。而天氣(晴天、下雨天)就屬於隱藏狀態,用一幅概率圖來表示這一馬爾可夫過程:

那麼,我們提出三個問題,分別對應馬爾可夫的三大問題:
- 已知整個模型,我觀測到連續三天做的事情是:散步,購物,收拾。那麼,根據模型,計算產生這些行為的概率是多少。
- 同樣知曉這個模型,同樣是這三件事,我想猜,這三天的天氣是怎麼樣的。
- 最複雜的,我只知道這三天做了這三件事兒,而其他什麼信息都沒有。我得建立一個模型,晴雨轉換概率,第一天天氣情況的概率分佈,根據天氣情況選擇做某事的概率分佈。
下面我們就依據這個場景來一一解答這些問題。
3.1.1 第一個問題解法
遍歷算法:
這個是最簡單的算法了,假設第一天(T=1 時刻)是晴天,想要購物,那麼就把圖上的對應概率相乘就能夠得到了。
第二天(T=2 時刻)要做的事情,在第一天的概率基礎上乘上第二天的概率,依次類推,最終得到這三天(T=3 時刻)所要做的事情的概率值,這就是遍歷算法,簡單而又粗暴。但問題是用遍歷算法的複雜度會隨着觀測序列和隱藏狀態的增加而成指數級增長。

前向算法:
- 假設第一天要購物,那麼就計算出第一天購物的概率(包括晴天和雨天);假設第一天要散步,那麼也計算出來,依次枚舉。
- 假設前兩天是購物和散步,也同樣計算出這一種的概率;假設前兩天是散步和打掃衛生,同樣計算,枚舉出前兩天行為的概率。
- 第三步就是計算出前三天行為的概率。
細心的讀者已經發現了,第二步中要求的概率可以在第一步的基礎上進行,同樣的,第三步也會依賴於第二步的計算結果。那麼這樣做就能夠節省很多計算環節,類似於動態規劃。
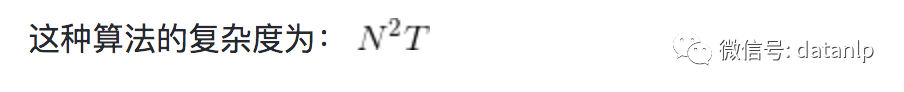
後向算法
跟前向算法相反,我們知道總的概率肯定是1,那麼B_t=1,也就是最後一個時刻的概率合為1,先計算前三天的各種可能的概率,在計算前兩天、前一天的數據,跟前向算法相反的計算路徑。
3.1.2 第二個問題解法
維特比算法(Viterbi)
說起安德魯·維特比(Andrew Viterbi),通信行業之外的人可能知道他的並不多,不過通信行業的從業者大多知道以他的名字命名的維特比算法(ViterbiAlgorithm)。維特比算法是現代數字通信中最常用的算法,同時也是很多自然語言處理採用的解碼算法。可以毫不誇張地講,維特比是對我們今天的生活影響力最大的科學家之一,因為基於CDMA的3G移動通信標準主要就是他和厄文·雅各布(Irwin Mark Jacobs)創辦的高通公司(Qualcomm)制定的,並且高通公司在4G時代依然引領移動通信的發展。
維特比算法是一個特殊但應用最廣的動態規划算法。利用動態規劃,可以解決任何一個圖中的最短路徑問題。而維特比算法是針對一個特殊的圖—籬笆網絡(Lattice)的有向圖最短路徑問題而提出的。它之所以重要,是因為凡是使用隱含馬爾可夫模型描述的問題都可以用它來解碼,包括今天的數字通信、語音識別、機器翻譯、拼音轉漢字、分詞等。
維特比算法一般用於模式識別,通過觀測數據來反推出隱藏狀態,下面一步步講解這個算法。

因為是要根據觀測數據來反推,所以這裡要進行一個假設,**假設這三天所做的行為分別是:散步、購物、打掃衛生,**那麼我們要求的是這三天的天氣(路徑)分別是什麼。



合起來的路徑就是Sunny->Sunny->Rainy,這就是我們所求。
以上是比較通俗易懂的維特比算法
4. 馬爾可夫網絡
4.1 因子圖
wikipedia上是這樣定義因子圖的:將一個具有多變量的全局函數因子分解,得到幾個局部函數的乘積,以此為基礎得到的一個雙向圖叫做因子圖(Factor Graph)。
通俗來講,所謂因子圖就是對函數進行因子分解得到的一種概率圖。一般內含兩種節點:變量節點和函數節點。我們知道,一個全局函數通過因式分解能夠分解為多個局部函數的乘積,這些局部函數和對應的變量關係就體現在因子圖上。
舉個例子,現在有一個全局函數,其因式分解方程為:


4.2 馬爾可夫網絡
我們已經知道,有向圖模型,又稱作貝葉斯網絡,但在有些情況下,強制對某些結點之間的邊增加方向是不合適的。使用沒有方向的無向邊,形成了無向圖模型(Undirected Graphical Model,UGM), 又被稱為馬爾可夫隨機場或者馬爾可夫網絡(Markov Random Field, MRF or Markov network)。

在概率圖中,求某個變量的邊緣分佈是常見的問題。這問題有很多求解方法,其中之一就是把貝葉斯網絡或馬爾可夫隨機場轉換成因子圖,然後用sum-product算法求解。換言之,基於因子圖可以用sum-product 算法高效的求各個變量的邊緣分佈。
5. 條件隨機場(CRF)
一個通俗的例子
假設你有許多小明同學一天內不同時段的照片,從小明提褲子起床到脫褲子睡覺各個時間段都有(小明是照片控!)。現在的任務是對這些照片進行分類。比如有的照片是吃飯,那就給它打上吃飯的標籤;有的照片是跑步時拍的,那就打上跑步的標籤;有的照片是開會時拍的,那就打上開會的標籤。問題來了,你準備怎麼干?
一個簡單直觀的辦法就是,不管這些照片之間的時間順序,想辦法訓練出一個多元分類器。就是用一些打好標籤的照片作為訓練數據,訓練出一個模型,直接根據照片的特徵來分類。例如,如果照片是早上6:00拍的,且畫面是黑暗的,那就給它打上睡覺的標籤;如果照片上有車,那就給它打上開車的標籤。
乍一看可以!但實際上,由於我們忽略了這些照片之間的時間順序這一重要信息,我們的分類器會有缺陷的。舉個例子,假如有一張小明閉着嘴的照片,怎麼分類?顯然難以直接判斷,需要參考閉嘴之前的照片,如果之前的照片顯示小明在吃飯,那這個閉嘴的照片很可能是小明在咀嚼食物準備下咽,可以給它打上吃飯的標籤;如果之前的照片顯示小明在唱歌,那這個閉嘴的照片很可能是小明唱歌瞬間的抓拍,可以給它打上唱歌的標籤。
所以,為了讓我們的分類器能夠有更好的表現,在為一張照片分類時,我們必須將與它**相鄰的照片的標籤信息考慮進來。這——就是條件隨機場(CRF)大顯身手的地方!**這就有點類似於詞性標註了,只不過把照片換成了句子而已,本質上是一樣的。
如同馬爾可夫隨機場,條件隨機場為具有無向的圖模型,圖中的頂點代表隨機變量,頂點間的連線代表隨機變量間的相依關係,在條件隨機場中,隨機變量Y 的分佈為條件機率,給定的觀察值則為隨機變量 X。下圖就是一個線性連條件隨機場。

條件概率分佈P(Y|X)稱為條件隨機場。
6. EM算法、HMM、CRF的比較
- EM算法是用於含有隱變量模型的極大似然估計或者極大後驗估計,有兩步組成:E步,求期望(expectation);M步,求極大(maxmization)。本質上EM算法還是一個迭代算法,通過不斷用上一代參數對隱變量的估計來對當前變量進行計算,直到收斂。注意:EM算法是對初值敏感的,而且EM是不斷求解下界的極大化逼近求解對數似然函數的極大化的算法,也就是說EM算法不能保證找到全局最優值。對於EM的導出方法也應該掌握。
- 隱馬爾可夫模型是用於標註問題的生成模型。有幾個參數(π,A,B):初始狀態概率向量π,狀態轉移矩陣A,觀測概率矩陣B。稱為馬爾科夫模型的三要素。馬爾科夫三個基本問題: 概率計算問題:給定模型和觀測序列,計算模型下觀測序列輸出的概率。–》前向後向算法 學習問題:已知觀測序列,估計模型參數,即用極大似然估計來估計參數。–》Baum-Welch(也就是EM算法)和極大似然估計。 預測問題:已知模型和觀測序列,求解對應的狀態序列。–》近似算法(貪心算法)和維比特算法(動態規劃求最優路徑)
- 條件隨機場CRF,給定一組輸入隨機變量的條件下另一組輸出隨機變量的條件概率分佈密度。條件隨機場假設輸出變量構成馬爾科夫隨機場,而我們平時看到的大多是線性鏈條隨機場,也就是由輸入對輸出進行預測的判別模型。求解方法為極大似然估計或正則化的極大似然估計。
- 之所以總把HMM和CRF進行比較,主要是因為CRF和HMM都利用了圖的知識,但是CRF利用的是馬爾科夫隨機場(無向圖),而HMM的基礎是貝葉斯網絡(有向圖)。而且CRF也有:概率計算問題、學習問題和預測問題。大致計算方法和HMM類似,只不過不需要EM算法進行學習問題。
- **HMM和CRF對比:**其根本還是在於基本的理念不同,一個是生成模型,一個是判別模型,這也就導致了求解方式的不同。
8. HMM詞性標註



