精盡MyBatis源碼分析 – SQL執行過程(一)之 Executor
- 2020 年 11 月 24 日
- 筆記
- mybatis, 源碼解析, 精盡MyBatis源碼分析
該系列文檔是本人在學習 Mybatis 的源碼過程中總結下來的,可能對讀者不太友好,請結合我的源碼注釋(Mybatis源碼分析 GitHub 地址、Mybatis-Spring 源碼分析 GitHub 地址、Spring-Boot-Starter 源碼分析 GitHub 地址)進行閱讀
MyBatis 版本:3.5.2
MyBatis-Spring 版本:2.0.3
MyBatis-Spring-Boot-Starter 版本:2.1.4
MyBatis的SQL執行過程
在前面一系列的文檔中,我已經分析了 MyBatis 的基礎支持層以及整個的初始化過程,此時 MyBatis 已經處於就緒狀態了,等待使用者發號施令了
那麼接下來我們來看看它執行SQL的整個過程,該過程比較複雜,涉及到二級緩存,將返回結果轉換成 Java 對象以及延遲加載等等處理過程,這裡將一步一步地進行分析:
- 《SQL執行過程(一)之Executor》
- 《SQL執行過程(二)之StatementHandler》
- 《SQL執行過程(三)之ResultSetHandler》
- 《SQL執行過程(四)之延遲加載》
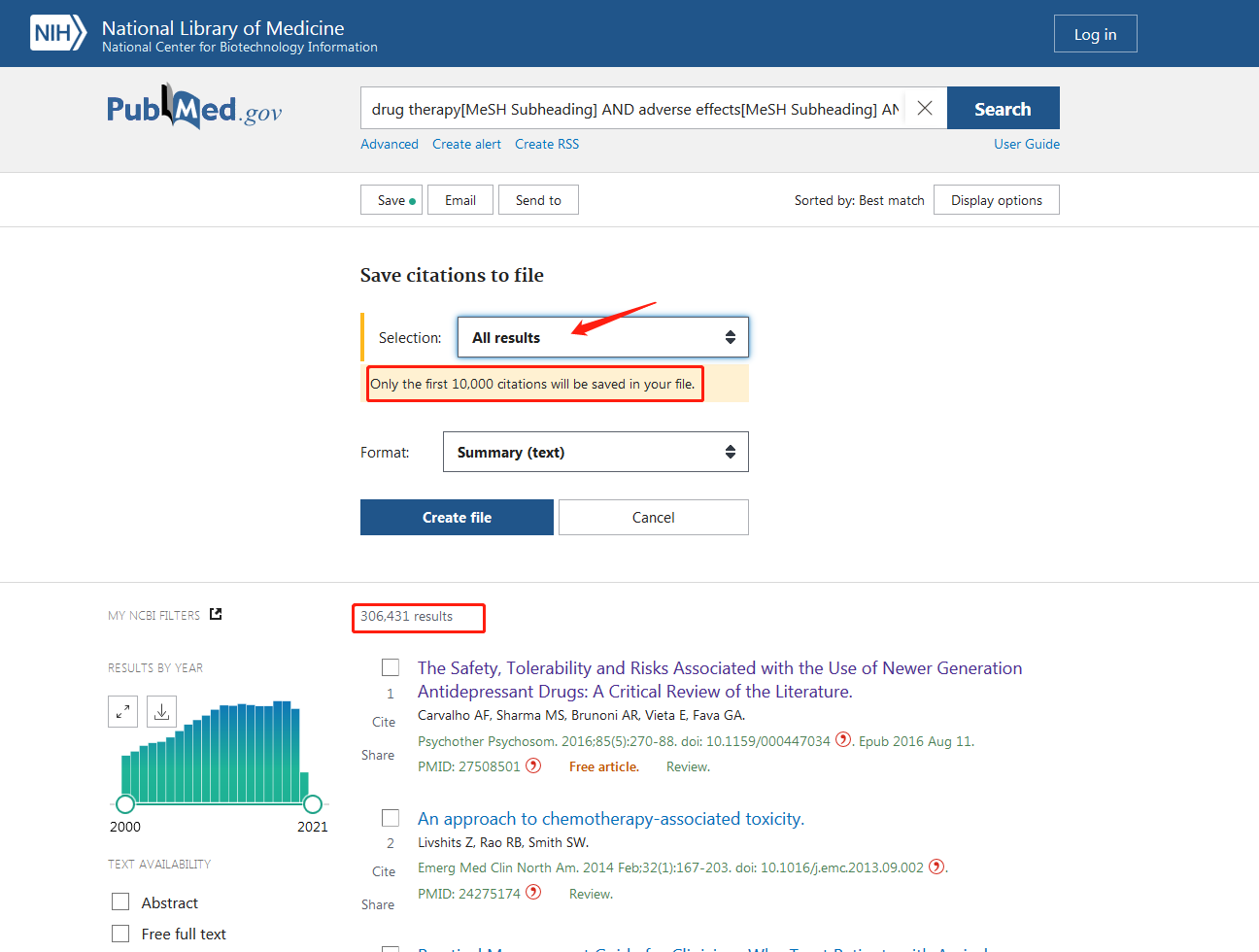
MyBatis中SQL執行的整體過程如下圖所示:
在 SqlSession 中,會將執行 SQL 的過程交由Executor執行器去執行,過程大致如下:
- 通過
DefaultSqlSessionFactory創建一個與數據的SqlSession會話,其中會創建一個Executor執行器對象 - 然後
Executor執行器通過StatementHandler創建對應的java.sql.Statement對象,並通過ParameterHandler設置參數,然後操作數據庫 - 如果是更新數據的操作,則可能需要通過
KeyGenerator設置自增鍵,返回受影響的行數 - 如果是查詢操作,則將操作數據庫返回的
ResultSet結果集對象包裝成ResultSetWrapper,然後通過DefaultResultSetHandler對結果集進行映射,返回 Java 對象
上面還涉及到一級緩存、二級緩存和延遲加載等其他處理過程
SQL執行過程(一)之Executor
在MyBatis的SQL執行過程中,Executor執行器擔當著一個重要的角色,相關操作都需要通過它來執行,相當於一個調度器,把SQL語句交給它,它來調用各個組件執行操作
其中一級緩存和二級緩存都是在Executor執行器中完成的
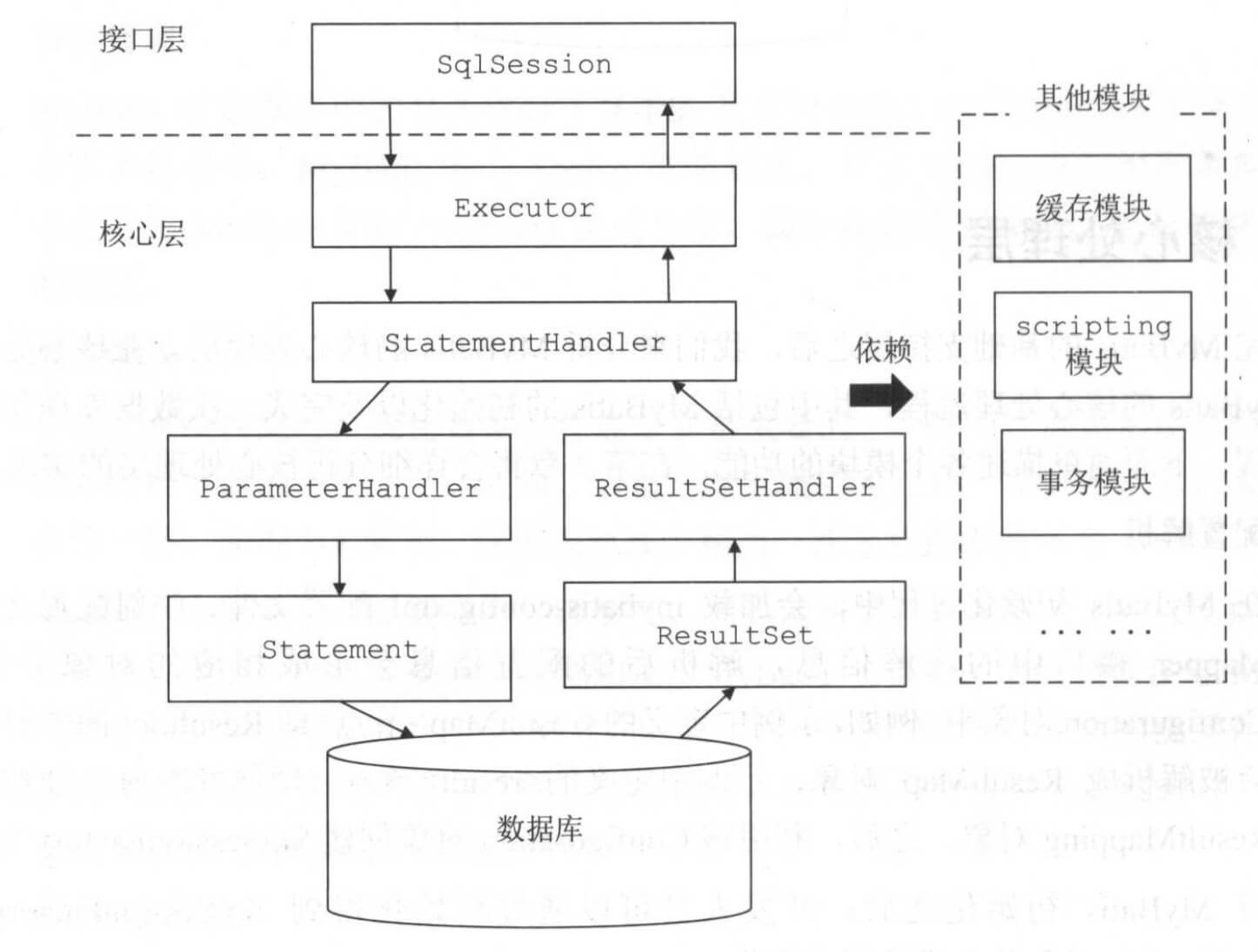
Executor執行器接口的實現類如下圖所示:
-
org.apache.ibatis.executor.BaseExecutor:實現Executor接口,提供骨架方法,支持一級緩存,指定幾個抽象的方法交由不同的子類去實現 -
org.apache.ibatis.executor.SimpleExecutor:繼承 BaseExecutor 抽象類,簡單的 Executor 實現類(默認) -
org.apache.ibatis.executor.ReuseExecutor:繼承 BaseExecutor 抽象類,可重用的 Executor 實現類,相比SimpleExecutor,在Statement執行完操作後不會立即關閉,而是緩存起來,執行的SQL作為key,下次執行相同的SQL時優先從緩存中獲取Statement對象 -
org.apache.ibatis.executor.BatchExecutor:繼承 BaseExecutor 抽象類,支持批量執行的 Executor 實現類 -
org.apache.ibatis.executor.CachingExecutor:實現 Executor 接口,支持二級緩存的 Executor 的實現類,實際採用了裝飾器模式,裝飾對象為左邊三個Executor類
Executor
org.apache.ibatis.executor.Executor:執行器接口,代碼如下:
public interface Executor {
/**
* ResultHandler 空對象
*/
ResultHandler NO_RESULT_HANDLER = null;
/**
* 更新或者插入或者刪除
* 由傳入的 MappedStatement 的 SQL 所決定
*/
int update(MappedStatement ms, Object parameter) throws SQLException;
/**
* 查詢,帶 ResultHandler + CacheKey + BoundSql
*/
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey cacheKey, BoundSql boundSql) throws SQLException;
/**
* 查詢,帶 ResultHandler
*/
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)
throws SQLException;
/**
* 查詢,返回 Cursor 游標
*/
<E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException;
/**
* 刷入批處理語句
*/
List<BatchResult> flushStatements() throws SQLException;
/**
* 提交事務
*/
void commit(boolean required) throws SQLException;
/**
* 回滾事務
*/
void rollback(boolean required) throws SQLException;
/**
* 創建 CacheKey 對象
*/
CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql);
/**
* 判斷是否緩存
*/
boolean isCached(MappedStatement ms, CacheKey key);
/**
* 清除本地緩存
*/
void clearLocalCache();
/**
* 延遲加載
*/
void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType);
/**
* 獲得事務
*/
Transaction getTransaction();
/**
* 關閉事務
*/
void close(boolean forceRollback);
/**
* 判斷事務是否關閉
*/
boolean isClosed();
/**
* 設置包裝的 Executor 對象
*/
void setExecutorWrapper(Executor executor);
}
執行器接口定義了操作數據庫的相關方法:
- 數據庫的讀和寫操作
- 事務相關
- 緩存相關
- 設置延遲加載
- 設置包裝的 Executor 對象
BaseExecutor
org.apache.ibatis.executor.BaseExecutor:實現Executor接口,提供骨架方法,指定幾個抽象的方法交由不同的子類去實現,例如:
protected abstract int doUpdate(MappedStatement ms, Object parameter) throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException;
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException;
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds,
BoundSql boundSql) throws SQLException;
上面這四個方法交由不同的子類去實現,分別是:更新數據庫、刷入批處理語句、查詢數據庫和查詢數據返回遊標
構造方法
public abstract class BaseExecutor implements Executor {
private static final Log log = LogFactory.getLog(BaseExecutor.class);
/**
* 事務對象
*/
protected Transaction transaction;
/**
* 包裝的 Executor 對象
*/
protected Executor wrapper;
/**
* DeferredLoad(延遲加載)隊列
*/
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
/**
* 本地緩存,即一級緩存,內部就是一個 HashMap 對象
*/
protected PerpetualCache localCache;
/**
* 本地輸出類型參數的緩存,和存儲過程有關
*/
protected PerpetualCache localOutputParameterCache;
/**
* 全局配置
*/
protected Configuration configuration;
/**
* 記錄當前會話正在查詢的數量
*/
protected int queryStack;
/**
* 是否關閉
*/
private boolean closed;
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
this.deferredLoads = new ConcurrentLinkedQueue<>();
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
}
其中上面的屬性可根據注釋進行查看
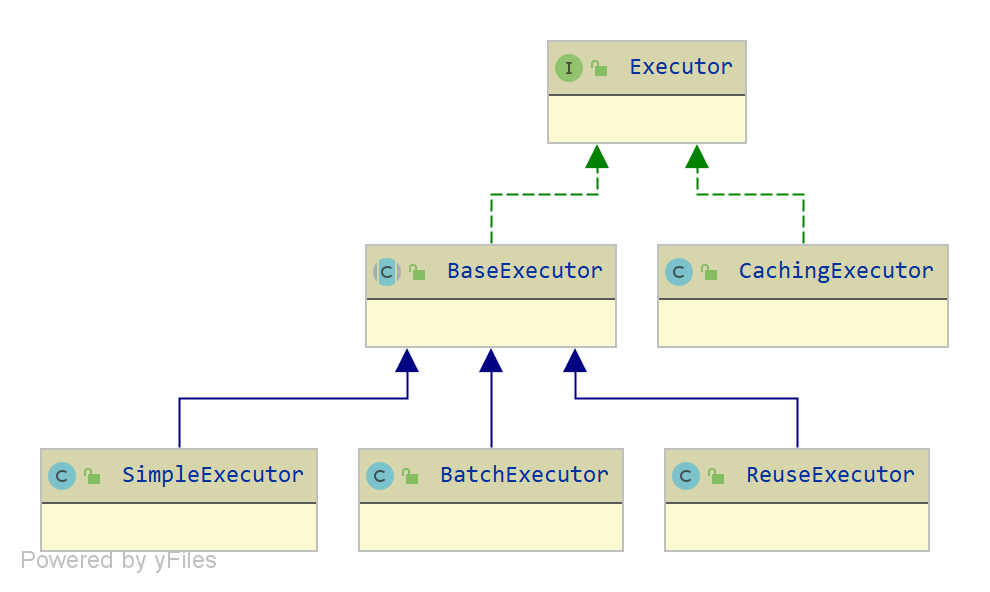
這裡提一下localCache屬性,本地緩存,用於一級緩存,MyBatis的一級緩存是什麼呢?
每當我們使用 MyBatis 開啟一次和數據庫的會話,MyBatis 都會創建出一個 SqlSession 對象,表示與數據庫的一次會話,而每個 SqlSession 都會創建一個 Executor 對象
在對數據庫的一次會話中,我們有可能會反覆地執行完全相同的查詢語句,每一次查詢都會訪問一次數據庫,如果在極短的時間內做了完全相同的查詢,那麼它們的結果極有可能完全相同,由於查詢一次數據庫的代價很大,如果不採取一些措施的話,可能造成很大的資源浪費
為了解決這一問題,減少資源的浪費,MyBatis 會在每一次 SqlSession 會話對象中建立一個簡單的緩存,將每次查詢到的結果緩存起來,當下次查詢的時候,如果之前已有完全一樣的查詢,則會先嘗試從這個簡單的緩存中獲取結果返回給用戶,不需要再進行一次數據庫查詢了 😈 注意,這個「簡單的緩存」就是一級緩存,且默認開啟,無法「關閉」
如下圖所示,MyBatis 的一次會話:在一個 SqlSession 會話對象中創建一個
localCache本地緩存,對於每一次查詢,都會根據查詢條件嘗試去localCache本地緩存中獲取緩存數據,如果存在,就直接從緩存中取出數據然後返回給用戶,否則訪問數據庫進行查詢,將查詢結果存入緩存並返回給用戶(如果設置的緩存區域為STATEMENT,默認為SESSION,在一次會話中所有查詢執行後會清空當前 SqlSession 會話中的localCache本地緩存,相當於「關閉」了一級緩存)所有的數據庫更新操作都會清空當前 SqlSession 會話中的本地緩存
如上描述,MyBatis的一級緩存在多個 SqlSession 會話時,可能導致數據的不一致性,某一個 SqlSession 更新了數據而其他 SqlSession 無法獲取到更新後的數據,出現數據不一致性,這種情況是不允許出現了,所以我們通常選擇「關閉」一級緩存
clearLocalCache方法
clearLocalCache()方法,清空一級(本地)緩存,如果全局配置中設置的localCacheScope緩存區域為STATEMENT(默認為SESSION),則在每一次查詢後會調用該方法,相當於關閉了一級緩存,代碼如下:
@Override
public void clearLocalCache() {
if (!closed) {
localCache.clear();
localOutputParameterCache.clear();
}
}
createCacheKey方法
createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql)方法,根據本地查詢的相關信息創建一個CacheKey緩存key對象,代碼如下:
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// <1> 創建 CacheKey 對象
CacheKey cacheKey = new CacheKey();
// <2> 設置 id、offset、limit、sql 到 CacheKey 對象中
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
// <3> 設置 ParameterMapping 數組的元素對應的每個 value 到 CacheKey 對象中
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) { // 該參數需要作為入參
Object value;
String propertyName = parameterMapping.getProperty();
/*
* 獲取該屬性值
*/
if (boundSql.hasAdditionalParameter(propertyName)) {
// 從附加參數中獲取
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
// 入參對象為空則直接返回 null
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
// 入參有對應的類型處理器則直接返回該參數
value = parameterObject;
} else {
// 從入參對象中獲取該屬性的值
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
// <4> 設置 Environment.id 到 CacheKey 對象中
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
-
創建一個
CacheKey實例對象 -
將入參中的
id、offset、limit、sql,通過CacheKey的update方法添加到其中,它的方法如下:public void update(Object object) { // 方法參數 object 的 hashcode int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object); this.count++; // checksum 為 baseHashCode 的求和 this.checksum += baseHashCode; // 計算新的 hashcode 值 baseHashCode *= this.count; this.hashcode = this.multiplier * this.hashcode + baseHashCode; // 添加 object 到 updateList 中 this.updateList.add(object); } -
獲取本次查詢的入參值,通過
CacheKey的update方法添加到其中 -
獲取本次環境的
Environment.id,通過CacheKey的update方法添加到其中 -
返回
CacheKey實例對象,這樣就可以為本次查詢生成一個唯一的緩存key對象,可以看看CacheKey重寫的equal方法:@Override public boolean equals(Object object) { if (this == object) { return true; } if (!(object instanceof CacheKey)) { return false; } final CacheKey cacheKey = (CacheKey) object; if (hashcode != cacheKey.hashcode) { return false; } if (checksum != cacheKey.checksum) { return false; } if (count != cacheKey.count) { return false; } for (int i = 0; i < updateList.size(); i++) { Object thisObject = updateList.get(i); Object thatObject = cacheKey.updateList.get(i); if (!ArrayUtil.equals(thisObject, thatObject)) { return false; } } return true; }
query相關方法
查詢數據庫因為涉及到一級緩存,所以這裡有多層方法,最終訪問數據庫的doQuery方法是交由子類去實現的,總共分為三層:
-
根據入參獲取BoundSql和CacheKey對象,然後再去調用查詢方法
-
涉及到一級緩存和延遲加載的處理,緩存未命中則再去調用查詢數據庫的方法
-
保存一些信息供一級緩存使用,內部調用
doQuery方法執行數據庫的讀操作
接下來我們分別來看看這三個方法
① query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)方法,數據庫查詢操作的入口,代碼如下
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)
throws SQLException {
// <1> 獲得 BoundSql 對象
BoundSql boundSql = ms.getBoundSql(parameter);
// <2> 創建 CacheKey 對象
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// <3> 查詢
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
- 通過
MappedStatement對象根據入參獲取BoundSql對象,在《MyBatis初始化(四)之SQL初始化(下)》中的SqlSource小節中有講到這個方法,如果是動態SQL則需要進行解析,獲取到最終的SQL,替換成?佔位符 - 調用
createCacheKey方法為本次查詢創建一個CacheKey對象 - 繼續調用
query(...)方法執行查詢
② query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)方法,處理數據庫查詢操作,涉及到一級緩存,代碼如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
// <1> 已經關閉,則拋出 ExecutorException 異常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// <2> 清空本地緩存,如果 queryStack 為零,並且要求清空本地緩存(配置了 flushCache = true)
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// <3> queryStack + 1
queryStack++;
// <4> 從一級緩存中,獲取查詢結果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) { // <4.1> 獲取到,則進行處理
// 處理緩存存儲過程的結果
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else { // <4.2> 獲得不到,則從數據庫中查詢
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
// <5> queryStack - 1
queryStack--;
}
if (queryStack == 0) { // <6> 如果當前會話的所有查詢執行完了
// <6.1> 執行延遲加載
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
// <6.2> 清空 deferredLoads
deferredLoads.clear();
// <6.3> 如果緩存級別是 LocalCacheScope.STATEMENT ,則進行清理
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
// <7> 返回查詢結果
return list;
}
-
當前會話已經被關閉則拋出異常
-
如果
queryStack為0(表示是當前會話只有本次查詢而沒有其他的查詢了),並且要求清空本地緩存(配置了flushCache=true),那麼直接清空一級(本地)緩存 -
當前會話正在查詢的數量加一,
queryStack++ -
從
localCache一級緩存獲取緩存的查詢結果- 如果有緩存數據,則需要處理儲存過程的情況,將需要作為出參(
OUT)的參數設置到本次查詢的入參的屬性中 - 如果沒有緩存數據,則調用
queryFromDatabase方法,執行數據庫查詢操作
- 如果有緩存數據,則需要處理儲存過程的情況,將需要作為出參(
-
當前會話正在查詢的數量減一,
queryStack-- -
如果當前會話所有查詢都執行完
-
執行當前會話中的所有的延遲加載
deferredLoads,這種延遲加載屬於查詢後的延遲,和後續講到的獲取屬性時再加載不同,這裡的延遲加載是在哪裡生成的呢?在
DefaultResultSetHandler中進行結果映射時,如果某個屬性配置的是子查詢,並且本次的子查詢在一級緩存中有緩存數據,那麼將會創建一個DeferredLoad對象保存在deferredLoads中,該屬性值先設置為DEFERRED延遲加載對象(final修飾的Object對象),待當前會話所有的查詢結束後,也就是當前執行步驟,則會從一級緩存獲取到數據設置到返回結果中 -
清空所有的延遲加載
deferredLoads對象 -
如果全局配置的緩存級別為STATEMENT(默認為SESSION),則清空當前會話中一級緩存的所有數據
-
-
返回查詢結果
③ queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)方法,執行數據庫查詢操作,代碼如下:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// <1> 在緩存中,添加正在執行的佔位符對象,因為正在執行的查詢不允許提前加載需要延遲加載的屬性,可見 DeferredLoad#canLoad() 方法
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// <2> 執行讀操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// <3> 從緩存中,移除佔位對象
localCache.removeObject(key);
}
// <4> 添加到緩存中
localCache.putObject(key, list);
// <5> 如果是存儲過程,則將入參信息保存保存,跟一級緩存處理存儲過程相關
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
// <6> 返回查詢結果
return list;
}
- 在緩存中,添加正在執行的
EXECUTION_PLACEHOLDER佔位符對象,因為正在執行的查詢不允許提前加載需要延遲加載的屬性,可見 DeferredLoad#canLoad() 方法 - 調用查詢數據庫
doQuery方法,該方法交由子類實現 - 刪除第
1步添加的佔位符 - 將查詢結果添加到
localCache一級緩存中 - 如果是存儲過程,則將入參信息保存保存,跟一級緩存處理存儲過程相關,可見上面的第
②個方法的第4.1步 - 返回查詢結果
update方法
update(MappedStatement ms, Object parameter)方法,執行更新數據庫的操作,代碼如下:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
// <1> 已經關閉,則拋出 ExecutorException 異常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// <2> 清空本地緩存
clearLocalCache();
// <3> 執行寫操作
return doUpdate(ms, parameter);
}
- 當前會話已經被關閉則拋出異常
- 清空當前會話中一級緩存的所有數據
- 調用更新數據庫
doUpdate方法,該方法交由子類實現
其他方法
除了上面介紹的幾個重要的方法以外,還有其他很多方法,例如獲取當前事務,提交事務,回滾事務,關閉會話等等,這裡我就不一一列出來了,請自行閱讀該類
SimpleExecutor
org.apache.ibatis.executor.SimpleExecutor:繼承 BaseExecutor 抽象類,簡單的 Executor 實現類(默認使用)
-
每次對數據庫的操作,都會創建對應的Statement對象
-
執行完成後,關閉該Statement對象
代碼如下:
public class SimpleExecutor extends BaseExecutor {
public SimpleExecutor(Configuration configuration, Transaction transaction) {
super(configuration, transaction);
}
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 創建 StatementHandler 對象
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
// 初始化 Statement 對象
stmt = prepareStatement(handler, ms.getStatementLog());
// 通過 StatementHandler 執行寫操作
return handler.update(stmt);
} finally {
// 關閉 Statement 對象
closeStatement(stmt);
}
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 創建 StatementHandler 對象
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 初始化 Statement 對象
stmt = prepareStatement(handler, ms.getStatementLog());
// 通過 StatementHandler 執行讀操作
return handler.query(stmt, resultHandler);
} finally {
// 關閉 Statement 對象
closeStatement(stmt);
}
}
@Override
protected <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, null, boundSql);
Statement stmt = prepareStatement(handler, ms.getStatementLog());
Cursor<E> cursor = handler.queryCursor(stmt);
stmt.closeOnCompletion();
return cursor;
}
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) {
return Collections.emptyList();
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 獲得 Connection 對象,如果開啟了 Debug 模式,則返回的是一個代理對象
Connection connection = getConnection(statementLog);
// 創建 Statement 或 PrepareStatement 對象
stmt = handler.prepare(connection, transaction.getTimeout());
// 往 Statement 中設置 SQL 語句上的參數,例如 PrepareStatement 的 ? 佔位符
handler.parameterize(stmt);
return stmt;
}
}
我們看到這些方法的實現,其中的步驟差不多都是一樣的
-
獲取
Configuration全局配置對象 -
通過上面全局配置對象的
newStatementHandler方法,創建RoutingStatementHandler對象,採用了裝飾器模式,根據配置的StatementType創建對應的對象,默認為PreparedStatementHandler對象,進入BaseStatementHandler的構造方法你會發現有幾個重要的步驟,在後續會講到😈然後使用插件鏈對該對象進行應用,方法如下所示:
// Configuration.java public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { /* * 創建 RoutingStatementHandler 路由對象 * 其中根據 StatementType 創建對應類型的 Statement 對象,默認為 PREPARED * 執行的方法都會路由到該對象 */ StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); // 將 Configuration 全局配置中的所有插件應用在 StatementHandler 上面 statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler); return statementHandler; } -
調用
prepareStatement方法初始化Statement對象- 從事務中獲取一個
Connection數據庫連接,如果開啟了Debug模式,則會為該Connection創建一個動態代理對象的實例,用於打印Debug日誌 - 通過上面第
2步創建的StatementHandler對象創建一個Statement對象(默認為PrepareStatement),還會進行一些準備工作,例如:如果配置了KeyGenerator(設置主鍵),則會設置需要返回相應自增鍵,在後續會講到😈 - 往
Statement對象中設置SQL的參數,例如PrepareStatement的?佔位符,實際上是通過DefaultParameterHandler設置佔位符參數,在前面的《MyBatis初始化(四)之SQL初始化(下)》中有講到 - 返回已經創建好的
Statement對象,就等待着執行數據庫操作了
- 從事務中獲取一個
-
通過
StatementHandler對Statement進行數據庫的操作,如果是查詢操作則會通過DefaultResultSetHandler進行參數映射(非常複雜,後續逐步分析😈)
ReuseExecutor
org.apache.ibatis.executor.ReuseExecutor:繼承 BaseExecutor 抽象類,可重用的 Executor 實現類
- 每次對數據庫的操作,優先從當前會話的緩存中獲取對應的Statement對象,如果不存在,才進行創建,創建好了會放入緩存中
- 數據庫操作執行完成後,不關閉該Statement對象
- 其它的和SimpleExecutor是一致的
我們來看看他的prepareStatement方法就好了:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
/*
* 根據需要執行的 SQL 語句判斷 是否已有對應的 Statement 並且連接未關閉
*/
if (hasStatementFor(sql)) {
// 從緩存中獲得 Statement 對象
stmt = getStatement(sql);
// 重新設置事務超時時間
applyTransactionTimeout(stmt);
} else {
// 獲得 Connection 對象
Connection connection = getConnection(statementLog);
// 初始化 Statement 對象
stmt = handler.prepare(connection, transaction.getTimeout());
// 將 Statement 添加到緩存中,key 值為 當前執行的 SQL 語句
putStatement(sql, stmt);
}
// 往 Statement 中設置 SQL 語句上的參數,例如 PrepareStatement 的 ? 佔位符
handler.parameterize(stmt);
return stmt;
}
在創建Statement對象前,會根據本次查詢的SQL從本地的Map<String, Statement> statementMap獲取到對應的Statement對象
-
如果緩存命中,並且該對象的連接未關閉,那麼重新設置當前事務的超時時間
-
如果緩存未命中,則執行和
SimpleExecutor中的prepareStatement方法相同邏輯創建一個Statement對象並放入statementMap緩存中
BatchExecutor
org.apache.ibatis.executor.BatchExecutor:繼承 BaseExecutor 抽象類,支持批量執行的 Executor 實現類
-
我們在執行數據庫的更新操作時,可以通過
Statement的addBatch()方法將數據庫操作添加到批處理中,等待調用Statement的executeBatch()方法進行批處理 -
BatchExecutor維護了多個Statement對象,一個對象對應一個SQL(sql和MappedStatement對象都相等),每個Statement對象對應多個數據庫操作(同一個sql多種入參),就像蘋果藍里裝了很多蘋果,番茄藍里裝了很多番茄,最後,再統一倒進倉庫
由於JDBC不支持數據庫查詢的批處理,所以這裡就不展示它數據庫查詢的實現方法,和SimpleExecutor一致,我們來看看其他的方法
構造方法
public class BatchExecutor extends BaseExecutor {
public static final int BATCH_UPDATE_RETURN_VALUE = Integer.MIN_VALUE + 1002;
/**
* Statement 數組
*/
private final List<Statement> statementList = new ArrayList<>();
/**
* BatchResult 數組
*
* 每一個 BatchResult 元素,對應 {@link #statementList} 集合中的一個 Statement 元素
*/
private final List<BatchResult> batchResultList = new ArrayList<>();
/**
* 上一次添加至批處理的 Statement 對象對應的SQL
*/
private String currentSql;
/**
* 上一次添加至批處理的 Statement 對象對應的 MappedStatement 對象
*/
private MappedStatement currentStatement;
public BatchExecutor(Configuration configuration, Transaction transaction) {
super(configuration, transaction);
}
}
-
statementList屬性:維護多個Statement對象 -
batchResultList屬性:維護多個BatchResult對象,每個對象對應上面的一個Statement對象,每個BatchResult對象包含同一個SQL和其每一次操作的入參 -
currentSql屬性:上一次添加至批處理的Statement對象對應的SQL -
currentStatement屬性:上一次添加至批處理的Statement對象對應的MappedStatement對象
BatchResult
org.apache.ibatis.executor.BatchResult:相同SQL(sql和MappedStatement對象都相等)聚合的結果,包含了同一個SQL每一次操作的入參,代碼如下:
public class BatchResult {
/**
* MappedStatement 對象
*/
private final MappedStatement mappedStatement;
/**
* SQL
*/
private final String sql;
/**
* 參數對象集合
*
* 每一個元素,對應一次操作的參數
*/
private final List<Object> parameterObjects;
/**
* 更新數量集合
*
* 每一個元素,對應一次操作的更新數量
*/
private int[] updateCounts;
public BatchResult(MappedStatement mappedStatement, String sql) {
super();
this.mappedStatement = mappedStatement;
this.sql = sql;
this.parameterObjects = new ArrayList<>();
}
public BatchResult(MappedStatement mappedStatement, String sql, Object parameterObject) {
this(mappedStatement, sql);
addParameterObject(parameterObject);
}
public void addParameterObject(Object parameterObject) {
this.parameterObjects.add(parameterObject);
}
}
doUpdate方法
更新數據庫的操作,添加至批處理,需要調用doFlushStatements執行批處理,代碼如下:
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
// <1> 創建 StatementHandler 對象
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
// <2> 如果和上一次添加至批處理 Statement 對象對應的 currentSql 和 currentStatement 都一致,則聚合到 BatchResult 中
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// <2.1> 獲取上一次添加至批處理 Statement 對象
int last = statementList.size() - 1;
stmt = statementList.get(last);
// <2.2> 重新設置事務超時時間
applyTransactionTimeout(stmt);
// <2.3> 往 Statement 中設置 SQL 語句上的參數,例如 PrepareStatement 的 ? 佔位符
handler.parameterize(stmt);// fix Issues 322
// <2.4> 獲取上一次添加至批處理 Statement 對應的 BatchResult 對象,將本次的入參添加到其中
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else { // <3> 否則,創建 Statement 和 BatchResult 對象
// <3.1> 初始化 Statement 對象
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); // fix Issues 322
// <3.2> 設置 currentSql 和 currentStatemen
currentSql = sql;
currentStatement = ms;
// <3.3> 添加 Statement 到 statementList 中
statementList.add(stmt);
// <3.4> 創建 BatchResult 對象,並添加到 batchResultList 中
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// <4> 添加至批處理
handler.batch(stmt);
// <5> 返回 Integer.MIN_VALUE + 1002
return BATCH_UPDATE_RETURN_VALUE;
}
-
創建
StatementHandler對象,和SimpleExecutor中一致,在後續會講到😈 -
如果和上一次添加至批處理
Statement對象對應的currentSql和currentStatement都一致,則聚合到BatchResult中- 獲取上一次添加至批處理
Statement對象 - 重新設置事務超時時間
- 往
Statement中設置 SQL 語句上的參數,例如PrepareStatement的?佔位符,在SimpleExecutor中已經講到 - 獲取上一次添加至批處理
Statement對應的BatchResult對象,將本次的入參添加到其中
- 獲取上一次添加至批處理
-
否則,創建
Statement和BatchResult對象- 初始化
Statement對象,在SimpleExecutor中已經講到,這裡就不再重複了 - 設置
currentSql和currentStatemen屬性 - 添加
Statement到statementList集合中 - 創建
BatchResult對象,並添加到batchResultList集合中
- 初始化
-
添加至批處理
-
返回
Integer.MIN_VALUE + 1002,為什麼返回這個值?不清楚
doFlushStatements方法
執行批處理,也就是將之前添加至批處理的數據庫更新操作進行批處理,代碼如下:
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
List<BatchResult> results = new ArrayList<>();
if (isRollback) { // <1> 如果 isRollback 為 true ,返回空數組
return Collections.emptyList();
}
// <2> 遍歷 statementList 和 batchResultList 數組,逐個提交批處理
for (int i = 0, n = statementList.size(); i < n; i++) {
// <2.1> 獲得 Statement 和 BatchResult 對象
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// <2.2> 提交該 Statement 的批處理
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
/*
* <2.3> 獲得 KeyGenerator 對象
* 1. 配置了 <selectKey /> 則會生成 SelectKeyGenerator 對象
* 2. 配置了 useGeneratedKeys="true" 則會生成 Jdbc3KeyGenerator 對象
* 否則為 NoKeyGenerator 對象
*/
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
// <2.3.1> 批處理入參對象集合,設置自增鍵
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { // issue #141
for (Object parameter : parameterObjects) {
// <2.3.1> 一次處理每個入參對象,設置自增鍵
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
// <2.4> 關閉 Statement 對象
closeStatement(stmt);
} catch (BatchUpdateException e) {
// 如果發生異常,則拋出 BatchExecutorException 異常
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
// <2.5> 添加到結果集
results.add(batchResult);
}
return results;
} finally {
// <3.1> 關閉 Statement 們
for (Statement stmt : statementList) {
closeStatement(stmt);
}
// <3.2> 置空 currentSql、statementList、batchResultList 屬性
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
在調用doUpdate方法將數據庫更新操作添加至批處理後,我們需要調用doFlushStatements方法執行批處理,邏輯如下:
-
如果
isRollback為true,表示需要回退,返回空數組 -
遍歷
statementList和batchResultList數組,逐個提交批處理- 獲得
Statement和BatchResult對象 - 提交該
Statement的批處理 - 獲得
KeyGenerator對象,用於設置自增鍵,在後續會講到😈 - 關閉
Statement對象 - 將
BatchResult對象添加到結果集
- 獲得
-
最後會關閉所有的
Statement和清空當前會話中保存的數據
二級緩存
在BaseExecutor中講到的一級緩存中,緩存數據僅在當前的 SqlSession 會話中進行共享,可能會導致多個 SqlSession 出現數據不一致性的問題
如果需要在多個 SqlSession 之間需要共享緩存數據,則需要使用到二級緩存
開啟二級緩存後,會使用CachingExecutor對象裝飾其他的Executor類,這樣會先在CachingExecutor進行二級緩存的查詢,緩存未命中則進入裝飾的對象中,進行一級緩存的查詢
流程如下圖所示:
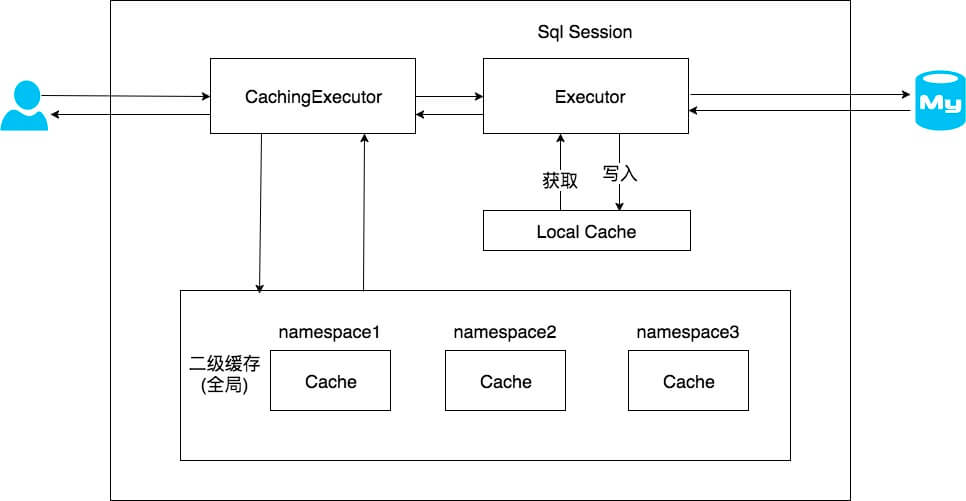
在《MyBatis初始化》的一系列文檔中講過MappedStatement會有一個Cache對象,是根據@CacheNamespace註解或<cache />標籤創建的對象,該對象也會保存在Configuration全局配置對象的Map<String, Cache> caches = new StrictMap<>("Caches collection")中,key為所在的namespace,也可以通過@CacheNamespaceRef註解或<cache-ref />標籤來指定其他namespace的Cache對象
在全局配置對象中cacheEnabled是否開啟緩存屬性默認為true,可以在mybatis-config.xml配置文件中添加以下配置關閉:
<configuration>
<settings>
<setting name="cacheEnabled" value="false" />
</settings>
</configuration>
我們來看看MyBatis是如何實現二級緩存的
CachingExecutor
org.apache.ibatis.executor.CachingExecutor:實現 Executor 接口,支持二級緩存的 Executor 的實現類
構造方法
public class CachingExecutor implements Executor {
/**
* 被委託的 Executor 對象
*/
private final Executor delegate;
/**
* TransactionalCacheManager 對象
*/
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
// 設置 delegate 被當前執行器所包裝
delegate.setExecutorWrapper(this);
}
}
delegate屬性,為被委託的Executor對象,具體的數據庫操作都是交由它去執行tcm屬性,TransactionalCacheManager對象,支持事務的緩存管理器,因為二級緩存是支持跨 SqlSession 共享的,此處需要考慮事務,那麼,必然需要做到事務提交時,才將當前事務中查詢時產生的緩存,同步到二級緩存中,所以需要通過TransactionalCacheManager來實現
query方法
處理數據庫查詢操作的方法,涉及到二級緩存,會將Cache二級緩存對象裝飾成TransactionalCache對象並存放在TransactionalCacheManager管理器中,代碼如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// <1> 獲取 Cache 二級緩存對象
Cache cache = ms.getCache();
// <2> 如果配置了二級緩存
if (cache != null) {
// <2.1> 如果需要清空緩存,則進行清空
flushCacheIfRequired(ms);
// <2.2> 如果當前操作需要使用緩存(默認開啟)
if (ms.isUseCache() && resultHandler == null) {
// <2.2.1> 如果是存儲過程相關操作,保證所有的參數模式為 ParameterMode.IN
ensureNoOutParams(ms, boundSql);
// <2.2.2> 從二級緩存中獲取結果,會裝飾成 TransactionalCache
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// <2.2.3> 如果不存在,則從數據庫中查詢
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// <2.2.4> 將緩存結果保存至 TransactionalCache
tcm.putObject(cache, key, list); // issue #578 and #116
}
// <2.2.5> 直接返回結果
return list;
}
}
// <3> 沒有使用二級緩存,則調用委託對象的方法
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
-
獲取
Cache二級緩存對象 -
如果該對象不為空,表示配置了二級緩存
- 如果需要清空緩存,則進行清空
- 如果當前操作需要使用緩存(默認開啟)
- 如果是存儲過程相關操作,保證所有的參數模式為
ParameterMode.IN - 通過
TransactionalCacheManager從二級緩存中獲取結果,會裝飾成TransactionalCach對象 - 如果緩存未命中,則調用委託對象的
query方法 - 將緩存結果保存至
TransactionalCache對象中,並未真正的保存至Cache二級緩存中,需要待事務提交才會保存過去,其中緩存未命中的也會設置緩存結果為null - 直接返回結果
- 如果是存儲過程相關操作,保證所有的參數模式為
-
沒有使用二級緩存,則調用委託對象的方法
update方法
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
// 如果需要清空緩存,則進行清空
flushCacheIfRequired(ms);
// 執行 delegate 對應的方法
return delegate.update(ms, parameterObject);
}
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
數據庫的更新操作,如果配置了需要清空緩存,則清空二級緩存
這裡就和一級緩存不同,一級緩存是所有的更新操作都會清空一級緩存
commit方法
@Override
public void commit(boolean required) throws SQLException {
// 執行 delegate 對應的方法
delegate.commit(required);
// 提交 TransactionalCacheManager
tcm.commit();
}
在事務提交後,通過TransactionalCacheManager二級緩存管理器,將本次事務生成的緩存數據從TransactionalCach中設置到正真的Cache二級緩存中
rollback方法
@Override
public void rollback(boolean required) throws SQLException {
try {
// 執行 delegate 對應的方法
delegate.rollback(required);
} finally {
if (required) {
// 回滾 TransactionalCacheManager
tcm.rollback();
}
}
}
在事務回滾後,如果需要的話,通過TransactionalCacheManager二級緩存管理器,將本次事務生成的緩存數據從TransactionalCach中移除
close方法
@Override
public void close(boolean forceRollback) {
try {
// issues #499, #524 and #573
if (forceRollback) {
tcm.rollback();
} else {
tcm.commit();
}
} finally {
delegate.close(forceRollback);
}
}
在事務關閉前,如果是強制回滾操作,則TransactionalCacheManager二級緩存管理器,將本次事務生成的緩存數據從TransactionalCach中移除,否則還是將緩存數據設置到正真的Cache二級緩存中
TransactionalCacheManager
org.apache.ibatis.cache.TransactionalCacheManager:二級緩存管理器,因為二級緩存是支持跨 SqlSession 共享的,所以需要通過它來實現,當事務提交時,才將當前事務中查詢時產生的緩存,同步到二級緩存中,代碼如下:
public class TransactionalCacheManager {
/**
* Cache 和 TransactionalCache 的映射
*/
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
// 首先,獲得 Cache 對應的 TransactionalCache 對象
// 然後,添加 KV 到 TransactionalCache 對象中
getTransactionalCache(cache).putObject(key, value);
}
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
-
getTransactionalCache(Cache cache)方法,根據Cache二級緩存對象獲取對應的TransactionalCache對象,如果沒有則創建一個保存起來 -
getObject(Cache cache, CacheKey key)方法,會先調用getTransactionalCache(Cache cache)方法獲取對應的TransactionalCache對象,然後根據CacheKey從該對象中獲取緩存結果 -
putObject(Cache cache, CacheKey key, Object value)方法,同樣也先調用getTransactionalCache(Cache cache)方法獲取對應的TransactionalCache對象,根據該對象將結果進行緩存 -
commit()方法,遍歷transactionalCaches,依次調用TransactionalCache的提交方法 -
rollback()方法,遍歷transactionalCaches,依次調用TransactionalCache的回滾方法
TransactionalCache
org.apache.ibatis.cache.decorators.TransactionalCache:用來裝飾二級緩存的對象,作為二級緩存一個事務的緩衝區
在一個SqlSession會話中,該類包含所有需要添加至二級緩存的的緩存數據,當提交事務後會全部刷出到二級緩存中,或者事務回滾後移除這些緩存數據,代碼如下:
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
/**
* 委託的 Cache 對象。
*
* 實際上,就是二級緩存 Cache 對象。
*/
private final Cache delegate;
/**
* 提交時,清空 {@link #delegate}
*
* 初始時,該值為 false
* 清理後{@link #clear()} 時,該值為 true ,表示持續處於清空狀態
*
* 因為可能事務還未提交,所以不能直接清空所有的緩存,而是設置一個標記,獲取緩存的時候返回 null 即可
* 先清空下面這個待提交變量,待事務提交的時候才真正的清空緩存
*
*/
private boolean clearOnCommit;
/**
* 待提交的 Key-Value 映射
*/
private final Map<Object, Object> entriesToAddOnCommit;
/**
* 查找不到的 KEY 集合
*/
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
@Override
public Object getObject(Object key) {
// issue #116
// <1> 從 delegate 中獲取 key 對應的 value
Object object = delegate.getObject(key);
if (object == null) {// <2> 如果不存在,則添加到 entriesMissedInCache 中
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {// <3> 如果 clearOnCommit 為 true ,表示處於持續清空狀態,則返回 null
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
// 暫存 KV 到 entriesToAddOnCommit 中
entriesToAddOnCommit.put(key, object);
}
@Override
public void clear() {
// <1> 標記 clearOnCommit 為 true
clearOnCommit = true;
// <2> 清空 entriesToAddOnCommit
entriesToAddOnCommit.clear();
}
public void commit() {
// <1> 如果 clearOnCommit 為 true ,則清空 delegate 緩存
if (clearOnCommit) {
delegate.clear();
}
// 將 entriesToAddOnCommit、entriesMissedInCache 刷入 delegate 中
flushPendingEntries();
// 重置
reset();
}
public void rollback() {
// <1> 從 delegate 移除出 entriesMissedInCache
unlockMissedEntries();
// <2> 重置
reset();
}
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
}
根據上面的注釋查看每個屬性的作用,我們依次來看下面的方法,看看在不同事務之前是如何處理二級緩存的
-
putObject(Object key, Object object)方法,添加緩存數據時,先把緩存數據保存在entriesToAddOnCommit中,這個對象屬於當前事務,事務還未提交,其他事務是不能訪問到的 -
clear()方法,設置clearOnCommit標記為true,告訴當前事務正處於持續清空狀態,先把entriesToAddOnCommit清空,也就是當前事務中還未提交至二級緩存的緩存數據,事務還未提交,不能直接清空二級緩存中的數據,否則影響到其他事務了 -
commit()方法,事務提交後,如果clearOnCommit為true,表示正處於持續清空狀態,需要先把二級緩存中的數據全部清空,然後再把當前事務生成的緩存設置到二級緩存中,然後重置當前對象這裡為什麼處於清空狀態把二級緩存的數據清空後,還要將當前事務生成的緩存數據再設置到二級緩存中呢?因為當前事務調用
clear()方法後可能有新生成了新的緩存數據,而不能把這些忽略掉 -
getObject(Object key)方法- 先從
delegate二級緩存對象中獲取結果 - 如果緩存未命中則將該key添加到
entriesMissedInCache屬性中,因為二級緩存也會將緩存未命中的key起來,數據為null - 如果
clearOnCommit為true,即使你緩存命中了也返回null,因為觸發clear()方法的話,本來需要清空二級緩存的,但是事務還未提交,所以先標記一個緩存持續清理的這麼一個狀態,這樣相當於在當前事務中既清空了二級緩存數據,也不影響其他事務的二級緩存數據 - 返回獲取到的結果,可能為null
- 先從
Executor在哪被創建
前面對Executor執行器接口以及實現類都有分析過,那麼它是在哪創建的呢?
在《MyBatis初始化(一)之加載mybatis-config.xml》這一篇文檔中講到,整個的初始化入口在SqlSessionFactoryBuilder的build方法中,創建的是一個DefaultSqlSessionFactory對象,該對象用來創建SqlSession會話的,我們來瞧一瞧:
public class DefaultSqlSessionFactory implements SqlSessionFactory {
private final Configuration configuration;
@Override
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level,
boolean autoCommit) {
Transaction tx = null;
try {
// 獲得 Environment 對象
final Environment environment = configuration.getEnvironment();
// 創建 Transaction 對象
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 創建 Executor 對象
final Executor executor = configuration.newExecutor(tx, execType);
// 創建 DefaultSqlSession 對象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
// 如果發生異常,則關閉 Transaction 對象
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
我們所有的數據庫操作都是在MyBatis的一個SqlSession會話中執行的,在它被創建的時候,會先通過Configuration全局配置對象的newExecutor方法創建一個Executor執行器
newExecutor(Transaction transaction, ExecutorType executorType)方法,根據執行器類型創建執行Executor執行器,代碼如下:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// <1> 獲得執行器類型
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
// <2> 創建對應實現的 Executor 對象
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// <3> 如果開啟緩存,創建 CachingExecutor 對象,進行包裝
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// <4> 應用插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
- 獲得執行器類型,默認為
SIMPLE - 創建對應的
Executor對象,默認就是SimpleExecutor執行器了 - 如果全局配置了開啟二級緩存,則將
Executor對象,封裝成CachingExecutor對象 - 插件鏈應用該對象,在後續會講到😈
總結
本文分析了MyBatis在執行SQL的過程中,都是在SimpleExecutor(默認類型)執行器中進行的,由它調用其他「組件」來完成數據庫操作
其中需要通過PrepareStatementHandler(默認)來創建對應的PrepareStatemen,進行參數的設置等相關處理,執行數據庫操作
獲取到結果後還需要通過DefaultResultSetHandler進行參數映射,轉換成對應的Java對象,這兩者在後續會進行分析
關於MyBatis的緩存,存在局限性,我們通常不會使用,如有需要使用緩存,查看我的另一篇源碼解析文檔《JetCache源碼分析》
一級緩存
僅限於單個 SqlSession 會話,多個 SqlSession 可能導致數據的不一致性,例如某一個 SqlSession 更新了數據而其他 SqlSession 無法獲取到更新後的數據,出現數據不一致性,這種情況是不允許出現了
二級緩存
MyBatis配置
二級緩存是通過在XML映射文件添加<cache / >標籤創建的(註解也可以),所以不同的XML映射文件所對應的二級緩存對象可能不是同一個
二級緩存雖然解決的一級緩存中存在的多個 SqlSession 會話可能出現臟讀的問題,但還是針對同一個二級緩存對象不會出現這種情況,如果其他的XML映射文件修改了相應的數據,當前二級緩存獲取到的緩存數據就不是最新的數據,也出現了臟讀的問題例如,在一個XML映射文件中配置了二級緩存,獲取到某個用戶的信息並存放在對應的二級緩存對象中,其他的XML映射文件修改了這個用戶的信息,那麼之前那個緩存數據就不是最新的
當然你可以XML映射文件對指向同一個Cache對象(通過
<cache-ref / >標籤),這樣就太局限了,所以MyBatis的緩存存在一定的缺陷,且緩存的數據僅僅是保存在了本地內存中,對於當前高並發的環境下是無法滿足要求的,所以我們通常不使用MyBatis的緩存
參考文章:芋道源碼《精盡 MyBatis 源碼分析》