Java(6)集合
一、Java集合框架概述
1、什麼是集合
- 集合框架:用於存儲數據的容器。
- 數組、集合等存儲數據的結構,叫Java容器。
- 此時的存儲,是指內存層面的存儲,不涉及持久化的存儲。
- 任何集合框架都包含三大塊的內容:對外的接口、接口的實現、對集合運算的算法。
2、集合的特點
-
數組的特點/缺點:
- 長度固定。一旦初始化,長度不能修改。
- 類型確定。類型嚴格(算是一個好處),當然要想可以放多種類型的數據,也可以聲明為Object類型。
- 方法有限。添加、刪除元素效率低;獲取元素個數不方便。
- 元素有序可重。對於無序、不重複的元素,不能滿足。
-
集合的特點/優點
- 容量自增長。
3、集合的體系
- Collection接口和Map接口是所有集合框架的父接口。
- Collection接口繼承樹
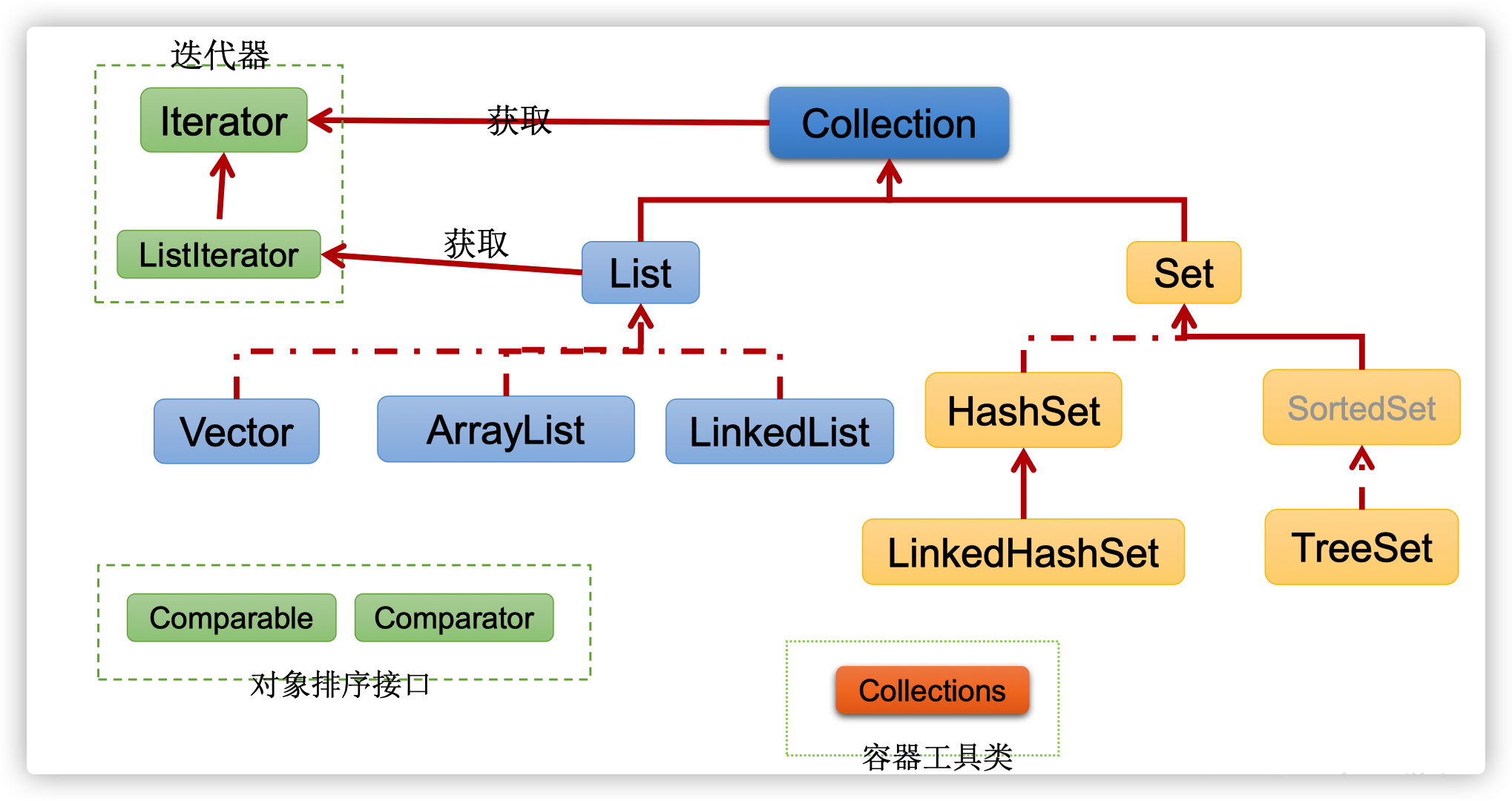
說明:
- List接口:存儲有序、可重複的數據。「動態數組」
- Set接口:存儲無序、不可重複的數據。「數學中的集合」
- Map接口繼承樹
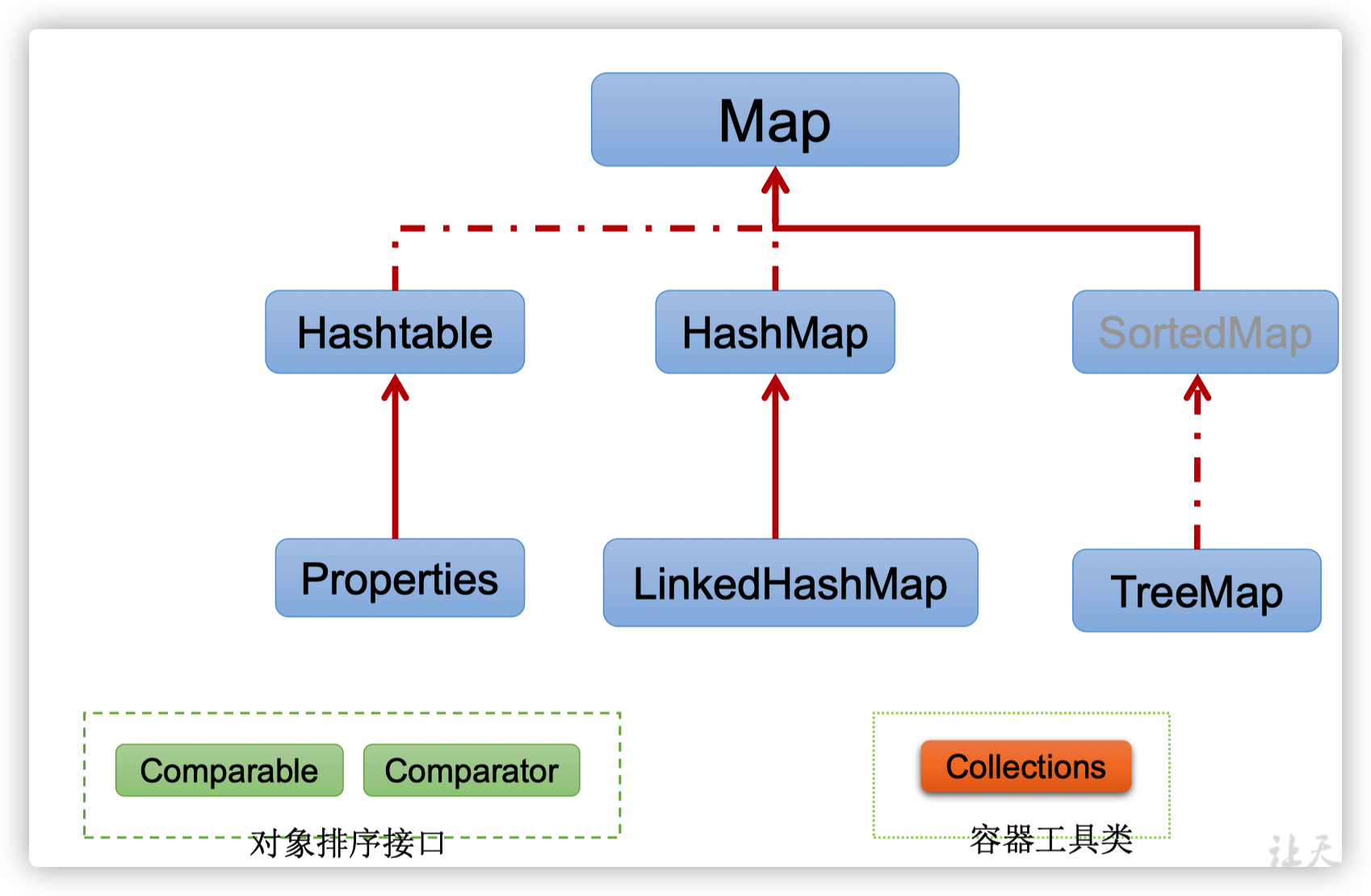
說明:
- Map接口:雙列集合,用於存儲成對的數據(key-value)。「數學中的函數」
二、Collection接口中的方法(15個)
1、說明
- 因為Collection接口是List、Set、Queue接口的父接口,所以定義在Collection接口的中方法可以用於操作子接口的實現類的對象。
2、15個方法
| 方法 | 描述 |
|---|---|
| add(Object obj) | 添加元素 |
| addAll(Collection c) | 添加另一個集合中所以元素 |
| size() | 元素個數 |
| clear() | 清空集合 |
| isEmpty() | 是否為空 |
| contains(Object obj) | 包含某個元素 |
| containsAll(Collection c) | 包含某個集合中所有元素 |
| remove(Object obj) | 刪除元素 |
| removeAll(Collection c) | 差集 |
| retainAll(Collection c) | 交集 |
| equals(Object obj) | 判斷集合是否相等 |
| toArray() | 轉換為數組 |
| toArray(T[] a) | |
| hashCode() | 求集合的哈希值 |
| iterator() | 返回迭代器對象 |
注意事項:
-
想Collection接口的實現類對象中添加數據obj時,要求obj所在類重寫equals()。
-
數組—>集合:Arrays.asList()
-
List arr1 = Arrays.asList(new int[]{123, 456}); System.out.println(arr1.size());//1 -
List arr2 = Arrays.asList(new Integer[]{123, 456}); System.out.println(arr2.size());//2 -
asList中是整型時,用int,默認會把數組當場一個對象。
-
3、Iterator迭代器接口
- Iterator是什麼?
- Iterator對象成為迭代器,是設計模式的一種。主要用於遍歷集合中的元素。
- 迭代器模式:提供一種方法訪問一個容器(container)對象中各個元 素,而又不需暴露該對象的內部細節。迭代器模式,就是為容器而生。
- Iterator接口中方法
- hasNext()
- next()
- remove()遍歷過程中移除某元素
- Iterator可以刪除集合的元素,但是是遍歷過程中通過迭代器對象的 remove方 法,不是集合對象的remove方法。
- 如果還未調用next()或在上一次調用 next 方法之後已經調用了 remove 方法, 再調用remove都會報IllegalStateException
- 怎麼用Iterator遍歷集合
//用集合中的iterator方法得到迭代器對象
Iterator iterator = coll.iterator();
//遍歷集合
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//當然我們也可以用foreach來遍歷,其實foreach本質也是調用了迭代器。
-
Iterator原理
- 得到的迭代器對象,默認指針指向第一個元素的前面
- hasNext()來判斷下一位是否有元素。(在調用it.next()方法之前必須要調用it.hasNext()進行檢測。若不調用,且 下一條記錄無效,直接調用it.next()會拋出NoSuchElementException異常)
- next():兩個作用:①指針下移②取出指針指向的元素
-
注意
- 集合對象每次調用iterator()方法都得到一個全新的迭代器對象,默認游標都在集合 的第一個元素之前。因此下面這種寫法不正確
while (coll.iterator().hasNext()){
System.out.println(coll.iterator().next());
}
三、List接口
1、List接口概述
- List接口是Collection的子接口
- List被稱為「動態數組」,是因為數組的局限性而代替數組的一種容器。
- 存儲的元素有序、可重複。每個元素都有對應的順序索引。
- 實現類有三個:ArrayList、LinkedList、Vector
2、ArrayList、LinkedList、Vector的異同(面試題)
- 同
- 三個類都是List接口的實現類,因此存儲數據都是有序可重複的。
- 異
| 實現類 | 地位 | since | 線程安全否 | 底層 | 應用場景 |
|---|---|---|---|---|---|
| ArrayList | 主要實現類 | 1.2 | 線程不安全、效率高 | Object[] | 遍歷、查找 |
| LinkedList | 1.2 | 雙向鏈表 | 頻繁插入、刪除 | ||
| Vector | 古老實現類 | 1.0 | 線程安全、效率低 | Object[] |
3、源碼分析(加分項)
-
ArrayList源碼分析—–JDK7
- 創建:調用空參構造器時,底層創建一個長度為10的Object[]數組elementData
- 擴容:默認擴容為原來的1.5倍(使用移位操作),並將原來數組中的數據複製到新的數組中
- 結論:開發中使用帶參構造器指定容量:
ArrayList list = new ArrayList(int capacity)
-
ArrayList源碼分析—–JDK8
- 創建:調用空參構造器時,底層創建一個Object[]數組elementData,初始化為空{}
- 擴容:同JDK7
- 對比:jdk7中的ArrayList的對象的創建類似於單例的餓漢式,而jdk8中的ArrayList的對象的創建類似於單例的懶漢式,延遲了數組的創建,節省內存。
-
LinkedList源碼分析
- 創建:調用空參構造器時,內部聲明了Node類型的first和last屬性,默認值為null
- 添加:將數據封裝在Node中,創建Node對象
-
Vector源碼分析
- 創建:調用空參構造器時,底層創建一個長度為10的Object[]數組elementData
- 擴容:默認擴容為原來的2倍,並將原來數組中的數據複製到新的數組中
4、List常用方法
-
List除了從Collection集合繼承的方法外,還有一些獨有的、根據索引來操作集合元素的方法。
-
總結的簡化版(常用的、便於記憶的總結)
| 常用方法的作用 | 方法名 |
|---|---|
| 增 | add(Object obj) |
| 刪 | remove(Object obj)、remove(int index) |
| 改 | set(int index, Object obj) |
| 查 | get(int index) |
| 插 | add(int index, Object obj) |
| 長度 | size() |
| 遍歷 | ①、Iterator迭代器 ②、增強for循環 ③、普通for循環 |
- 區分List中的remove方法
- list.remove(2):刪除索引為2的,因為有remove(int index)的方法,直接匹配上不用自動裝箱就能匹配,name何必自動裝箱呢?
- list.remove(new Integer(2)):刪除數據2,匹配的是remove(Object obj)的方法
四、Set接口
1、Set接口概述
- Set接口是Collection的子接口。
- Set中沒有額外的方法
- Set中的元素不可重複,判斷是否相等用的是equals()方法
- 實現類有HashSet、LinkedHashSet、TreeSet
2、HashSet、LinkedHashSet、TreeSet的異同
- HashSet:是Set接口的主要實現類;線程不安全;可以存儲null值;
- LinkedHashSet:是HashSet的子類;可以按照添加順序遍歷,遍歷效率高;
- TreeSet:可以按照添加對象的指定屬性排序
- 要求1:添加的對象類型相同
- 要求2:對象的類要實現Comparable接口來進行自然排序,或者,實現Comparator接口來進行定製排序
- 自然排序中,比較兩個對象是否相同的標準為(是否可添加「相同對象」):compareTo()返回0.不再是equals().
- 定製排序中,比較兩個對象是否相同的標準為:compare()返回0.不再是equals().
3、理解無序、可重複
- 無序
- 指的是存儲在底層數組的數據,並不是按照數組索引的順序添加的,而是根據數據的哈希值決定的。
- 無序性,不等於隨機性
- 不可重複
- 相同的元素只能添加一個。元素按照equals()判斷,不能返回true。
4、添加元素的過程(以HashSet為例)
-
添加過程並不會單獨考察,但是對於理解HashMap有很大幫助
-
我們向HashSet中添加元素a,首先調用元素a所在類的hashCode()方法,計算元素a的哈希值,此哈希值接着通過某種算法計算出在HashSet底層數組中的存放位置(即為:索引位置),判斷數組此位置上是否已經有元素:
- 如果此位置上沒有其他元素,則元素a添加成功。 —>情況1
- 如果此位置上有其他元素b(或以鏈表形式存在的多個元素),則比較元素a與元素b的hash值:
- 如果hash值不相同,則元素a添加成功。—>情況2
- 如果hash值相同,進而需要調用元素a所在類的equals()方法:
- equals()返回true,元素a添加失敗
- equals()返回false,則元素a添加成功。—>情況3
-
對於添加成功的情況2和情況3而言:元素a 與已經存在指定索引位置上數據以鏈表的方式存儲
- jdk 7 :元素a放到數組中,指向原來的元素。
- jdk 8 :原來的元素在數組中,指向元素a
- 總結:七上八下
-
HashSet底層:數組+鏈表的結構。
5、重寫hashCode()和equals()方法
-
要求:向Set(主要指:HashSet、LinkedHashSet)中添加的數據,其所在的類一定要重寫hashCode()和equals()
-
重寫要求:重寫的hashCode()和equals()儘可能保持一致性:相等的對象必須具有相等的散列碼
-
重寫兩個方法的小技巧:對象中用作 equals() 方法比較的 Field,都應該用來計算 hashCode 值。
6、面試題
-
在List內去除重複數字值,要求盡量簡單
- 可以用Set實現
-
//程序的輸出結果 HashSet set = new HashSet(); Person p1 = new Person(1001,"AA"); Person p2 = new Person(1002,"BB"); set.add(p1); set.add(p2); p1.name = "CC"; set.remove(p1); System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}] /* 存放p1、p2時,根據p1和p2的屬性算出了hashCode來確定存放位置 p1的name改為CC後,再刪除p1--->根據此時p1的屬性算hashCode來找set中和p1相同的元素,此時算出來的hashCode大概率不是p1的位置,相當於沒有找到,所以刪除並沒有成功。 */ set.add(new Person(1001,"CC")); System.out.println(set); //[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}] /* 存放新建的p,是根據1001和CC來算hashCode,此時數組中這個位置空的,所以存放成功 */ set.add(new Person(1001,"AA")); System.out.println(set);//[Person{id=1002, name='BB'}, Person{id=1001, name='CC'}, Person{id=1001, name='CC'}, Person{id=1001, name='AA'}] /* 存放新建的p,先hashCode後和p1是一樣的,再equals發現不一樣,加到鏈表上,存放成功 */
五、Map接口
1、Map接口概述
- Map接口繼承樹
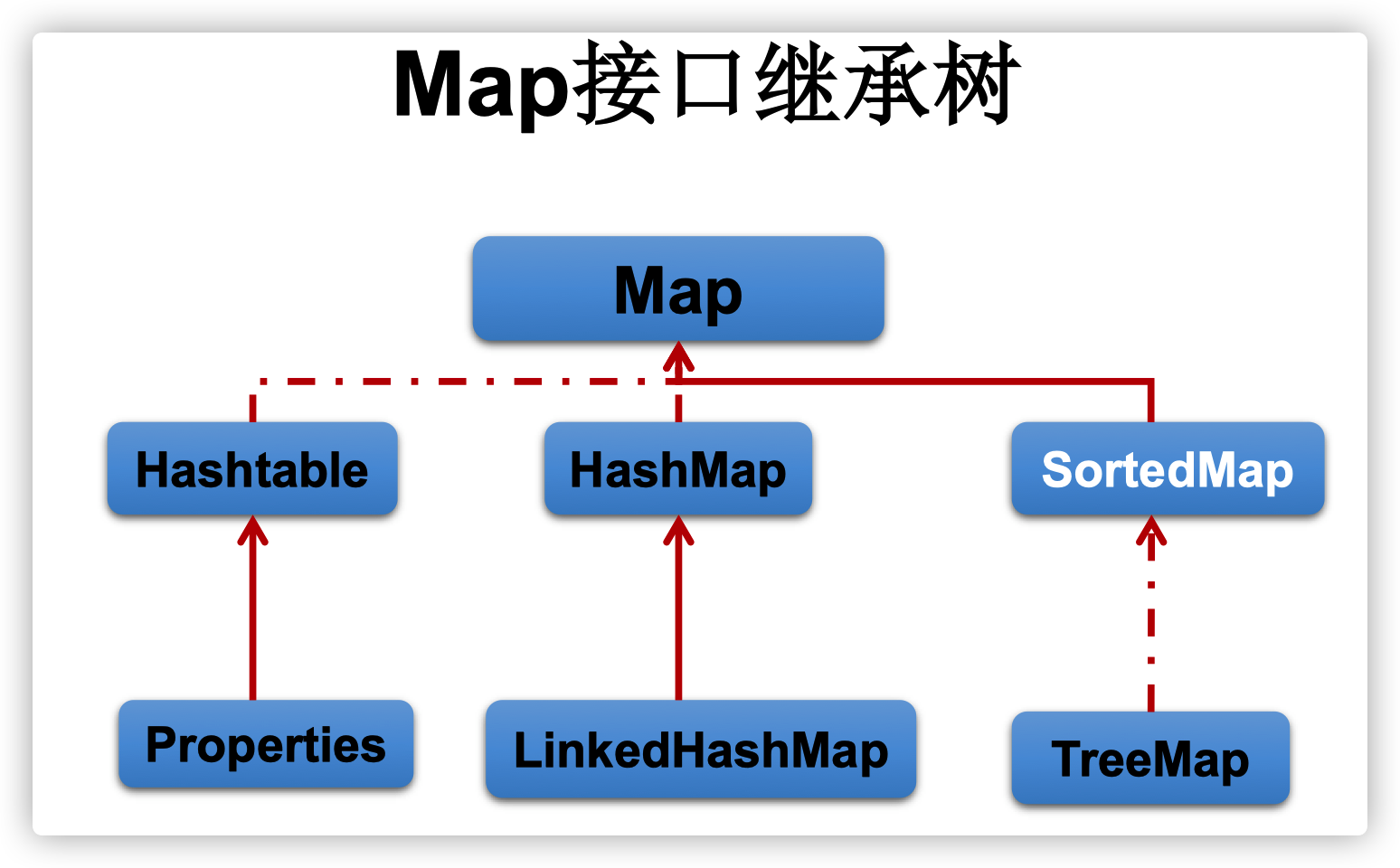
- Map接口:
- 存儲key-value的鍵值對,類似於數學中的函數
- Map實現類對比
| Map實現類 | 底層實現 | 線程 | 地位 | 特點 |
|---|---|---|---|---|
| HashMap | JDK7及以前:數組+鏈表 JDK8:數組+鏈表+紅黑樹 |
線程不安全 | 主要實現類 | 可以存儲null的k-v |
| LinkedHashMap | 同上 | 同上 | 同上 | 可按照添加順序遍歷 |
| TreeMap | — | — | — | 可排序遍歷 |
| Hashtable | — | 線程安全 | 古老實現類 | 不可存儲null的k-v |
| Properties | — | — | — | 常用來處理配置文件 |
2、面試題
-
HashMap的底層實現原理★★★★★(見下面第四點) -
HashMap和Hashtable的異同 -
CurrentHashMap和Hashtable的異同(暫時不學)
3、Map結構的理解
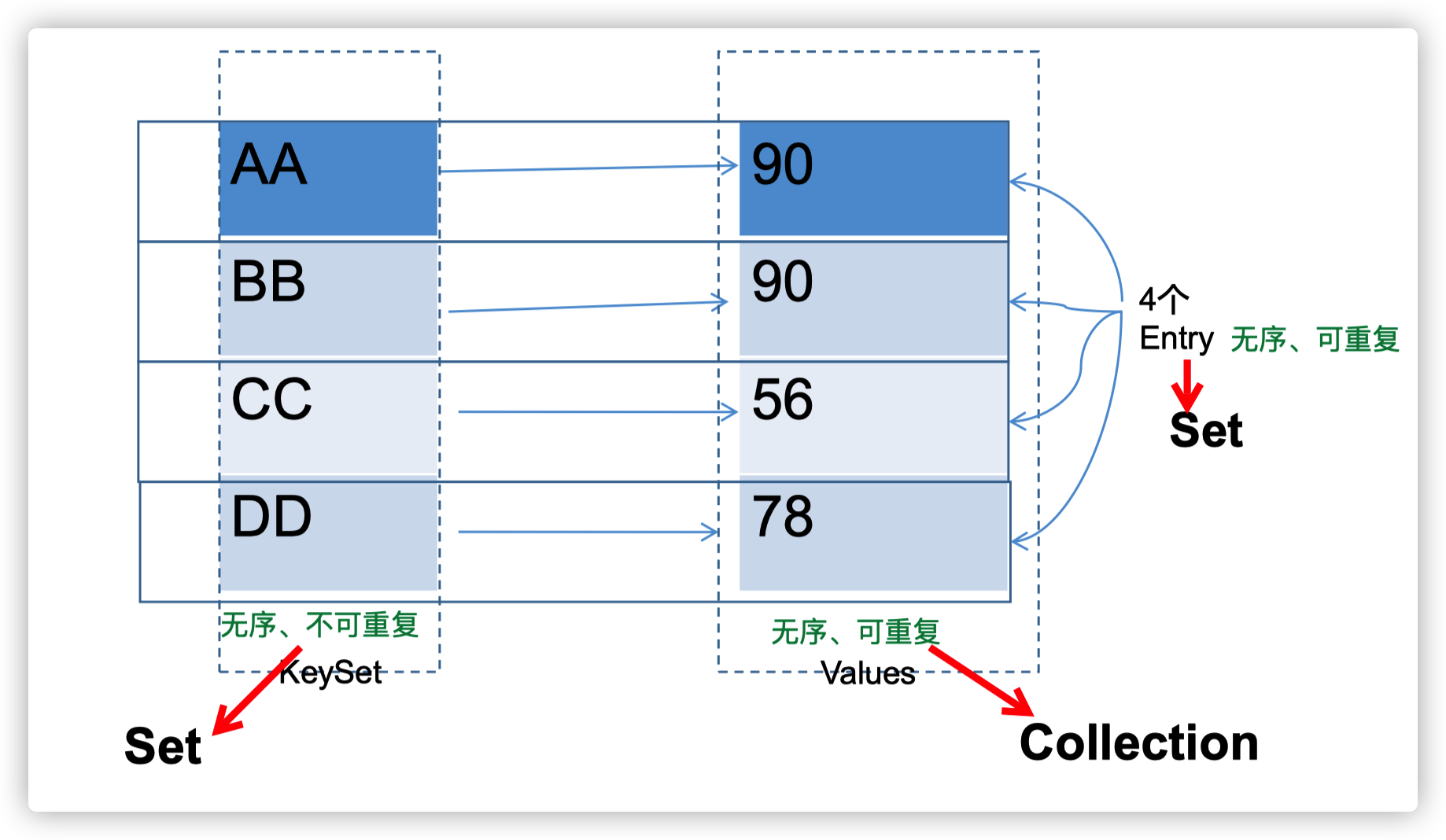
-
Map中的key:無序的、不可重複的,使用Set存儲所有的key —> key所在的類要重寫equals()和hashCode() (以HashMap為例);當然如果是LinkedHashMap還要實現排序接口
-
Map中的value:無序的、可重複的,使用Collection存儲所有的value —>value所在的類要重寫equals()
-
一個鍵值對:key-value構成了一個Entry對象。
-
Map中的entry:無序的、不可重複的,使用Set存儲所有的entry
四、 HashMap的底層實現原理★★★★★(高頻面試題)
1、JDK7
-
HashMap map = new HashMap():底層創建一個長度為16的數組Entry[] table。 -
map.put(key1, value1)- 調用key1所在類的hashCode()方法計算key1的哈希值,用哈希值在計算得到在Entry[]數組中的存放位置
- 如果此位置為空,添加成功——>情況1
- 如果此位置不為空,比較key1和已經存在的數據的哈希值
- 如果key1的哈希值和已經存在的數據的哈希值不同,添加成功——>情況2
- 如果key1的哈希值和已經存在的某一個數據(key2,value2)的哈希值相同,繼續調用key1所在類的equals()方法,傳入參數key2進行比較
- 如果equals()返回值為false,添加成功——>情況3
- 如果equals()返回值為true,用value1替換value2
- 調用key1所在類的hashCode()方法計算key1的哈希值,用哈希值在計算得到在Entry[]數組中的存放位置
-
擴容:(當超出臨界值且要添加數據的位置不為空時)默認擴容為原來的2倍,並複製數據到新數組
2、JDK8與JDK7的不同之處
HashMap map = new HashMap()時,底層沒有直接創建數組,而是在首次put()時創建- 數組是Node[]類型,而非Entry[]類型
- JDK7底層是:數組+鏈表;而JDK8底層是:數組+鏈表+紅黑樹
- 形成鏈表時,七上八下(jdk7:新的元素指向舊的元素。jdk8:舊的元素指向新的元素)
- 當數組的某一個索引位置上的元素以鏈表形式存在的數據個數 > 8 且當前數組的長度 > 64時,此時此索引位置上的所數據改為使用紅黑樹存儲。
3、LinkedHashMap底層實現原理
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;//能夠記錄添加的元素的先後順序
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
六、Map接口常用方法
1、添加、刪除、修改操作:
-
Object put(Object key,Object value):將指定key-value添加到(或修改)當前map對象中void putAll(Map m):將m中的所有key-value對存放到當前map中 -
Object remove(Object key):移除指定key的key-value對,並返回value
void clear():清空當前map中的所有數據
2、 元素查詢的操作:
-
Object get(Object key):獲取指定key對應的value -
boolean containsKey(Object key):是否包含指定的keyboolean containsValue(Object value):是否包含指定的value -
int size():返回map中key-value對的個數 -
boolean isEmpty():判斷當前map是否為空 -
boolean equals(Object obj):判斷當前map和參數對象obj是否相等
3、元視圖操作的方法:
Set keySet():返回所有key構成的Set集合Collection values():返回所有value構成的Collection集合Set entrySet():返回所有key-value對構成的Set集合
4、總結常用方法:
- 添加:
put(Object key,Object value) - 刪除:
remove(Object key) - 修改:
put(Object key,Object value) - 查詢:
get(Object key) - 長度:
size() - 遍歷:
keySet() / values() / entrySet()
七、Properties
1、配置文件
-
默認存放路徑為當前工程下
-
創建配置文件的方式
- 右鍵工程名—>new—>File:這時要寫上
.properties,如jdbc.properties - 右鍵工程名—>new—>Resource Bundle:這時秩序寫名稱就會自動補全後綴
- 右鍵工程名—>new—>File:這時要寫上
-
存取數據時,建議使用
setProperty(String key,String value)方法和getProperty(String key)方法
八、Collections工具類
1、Collections概述
- Collections是一個操作Set、List、Map等集合的工具類
- Collections 中提供了一系列靜態的方法對集合元素進行排序、查詢和修改等操作, 還提供了對集合對象設置不可變、對集合對象實現同步控制等方法
2、Collections常用方法
排序操作
- 排序操作都是針對List來講的,因為Map本身無序,何談排序
- 返回值都是void,說明對List本身做了修改
| 方法 | 解釋 |
|---|---|
| reverse(List) | 反轉List中的元素 |
| shuffle(List) | 隨機排序 |
| sort(List) | 自然排序 |
| Sort(List, Comparator) | 定製排序 |
| swap(List, int i, int j) | 交換 |
查詢、替換
| 方法 | 解釋 |
|---|---|
| Object max/min(Collection) | 返回自然排序的最大、小值 |
| Object max/min(Collection, Comparator) | 返回定製排序的最大、小值 |
| int frequency(Collection, Object) | 返回某集合中某元素的出現次數 |
| void copy(List dest, List src) | 複製 |
| boolean replaceAll(List list, Object oldVal, Object newVal) | 替換 |
- void copy(List dest, List src)中,新List容量不能小於舊List,因此要用
List dest = Arrays.asList(new Object[list.size()]);來創建


