Spark3.0.1各種集群模式搭建
對於spark前來圍觀的小夥伴應該都有所了解,也是現在比較流行的計算框架,基本上是有點規模的公司標配,所以如果有時間也可以補一下短板。
簡單來說Spark作為準實時大數據計算引擎,Spark的運行需要依賴資源調度和任務管理,Spark自帶了standalone模式資源調度和任務管理工具,運行在其他資源管理和任務調度平台上,如Yarn、Mesos、Kubernates容器等。
spark的搭建和Hadoop差不多,稍微簡單點,本文針對下面幾種部署方式進行詳細描述:
-
Local:多用於本地測試,如在eclipse,idea中寫程序測試等。
-
Standalone:Standalone是Spark自帶的一個資源調度框架,它支持完全分佈式。
-
Yarn:Hadoop生態圈裏面的一個資源調度框架,Spark也是可以基於Yarn來計算的。
了解一個框架最直接的方式首先要拿來玩玩,玩之前要先搭建,廢話少說,進入正題,搭建spark集群。
一、環境準備
搭建環境:CentOS7+jdk8+Hadoop2.10.1+Spark3.0.1
- 機器準備,由於已經搭建過Hadoop,spark集群也是使用相同集群(個人電腦資源有限),可以參照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 需要安裝jdk1.8、Scala2.12.12、hadoop2.10.1、spark3.0.1,其中jdk1.8和Hadoop2.10也都已經安裝完成,這裡只介紹Scala和spark環境配置
- 機器免密登錄,也在Hadoop部署時做過,可以參照Hadoop搭建博客:centos7中搭建hadoop2.10高可用集群
- 下載Scala2.12.12(//www.scala-lang.org/download/2.12.12.html)、下載spark3.0.1(//spark.apache.org/downloads.html)
二、配置環境變量
1.配置Scala環境
tar -zxvf scala-2.12.12.tgz -C /opt/soft/ cd /opt/soft ln -s scala-2.12.12 scala
vim /etc/profile
添加環境變量
#SCALA
export SCALA_HOME=/opt/soft/scala
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
測試是否正常

正常
2.配置spark環境變量
由於各個部署方式都需要該步驟,在此單獨配置,各個部署方式不再配置
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /opt/soft cd /opt/soft ln -s spark-3.0.1-bin-hadoop2.7 spark
vim /etc/profile
添加環境變量
#spark
export SPARK_HOME=/opt/soft/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
三、搭建步驟
1.本地Local模式
上述已經解壓配置好spark環境變量,本地模式不需要配置其他配置文件,可以直接使用,很簡單吧,先測試一下運行樣例:
cd /opt/soft/spark/binrun-example SparkPi 10

可以計算出結果
測試spark-shell
spark-shell

啟動成功,說明Local模式部署成功
2.Standalone模式
1>修改Spark的配置文件spark-env.sh
cd /opt/soft/spark/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh
添加如下配置:
# 主節點機器名稱 export SPARK_MASTER_HOST=s141 # 默認端口號為7077 export SPARK_MASTER_PORT=7077
2>修改配置文件slaves(從節點配置)
cd /opt/soft/spark/conf
cp slaves.template slaves
vim slaves
刪除原有節點,添加從節點主機如下配置:
s142
s143
s144
s145
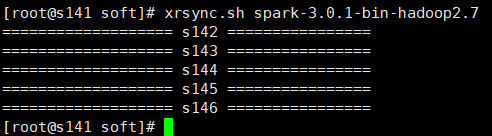
3>將spark目錄發送到其他機器,可以使用scp一個一個機器複製,這裡使用的是自己寫的批量複製腳本xrsync.sh(hadoop批量命令腳本xrsync.sh傳輸腳本)
xrsync.sh spark-3.0.1-bin-hadoop2.7
4>在各個機器中建立spark軟連接,可以進入各個機器的/opt/soft目錄
ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark
這裡使用的是批量執行命令腳本xcall.sh(hadoop批量命令腳本xcall.sh及jps找不到命令解決)
xcall.sh ln -s /opt/soft/spark-3.0.1-bin-hadoop2.7 /opt/soft/spark

5>啟動spark集群
cd /opt/soft/spark/sbin 可以單獨啟動master和slave ./start-master.sh ./start-slaves.sh spark://s141:7077 也可以一鍵啟動master和slave ./start-all.sh
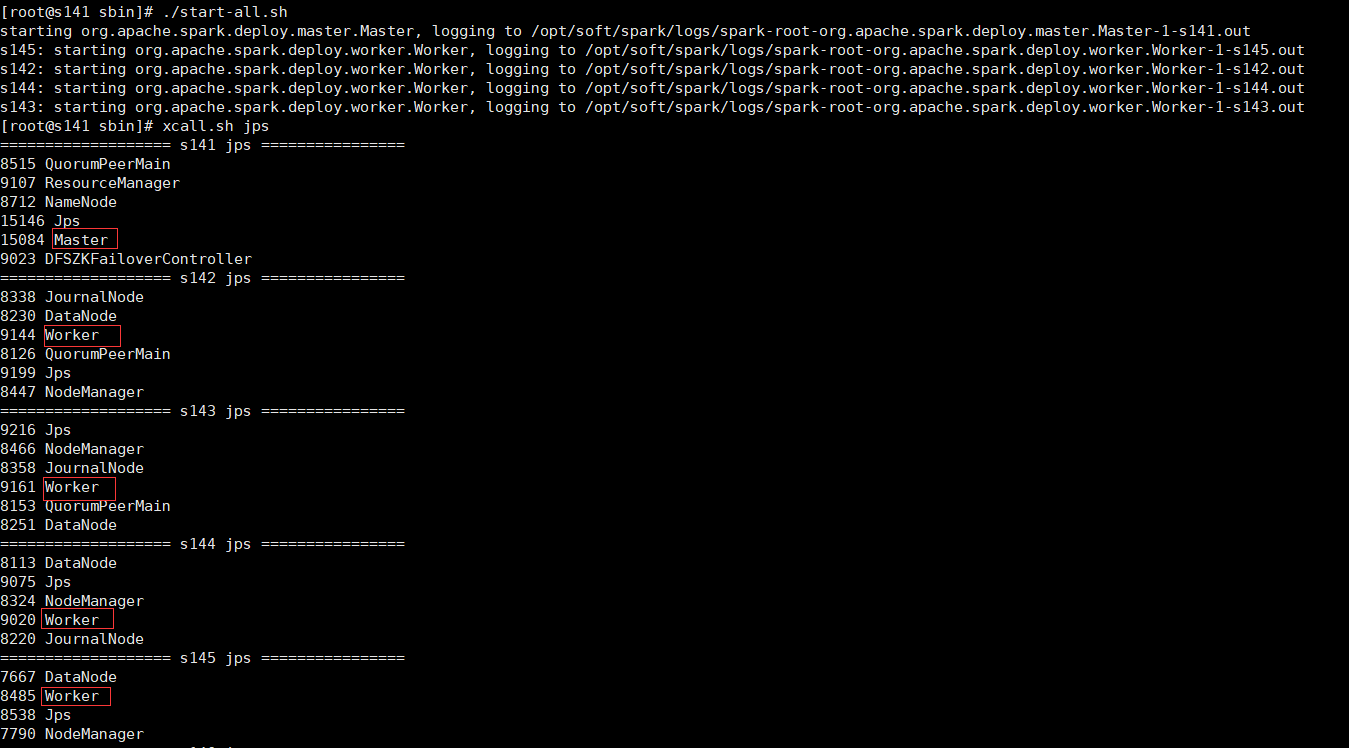
可以看到master和worker進程已經啟動成功
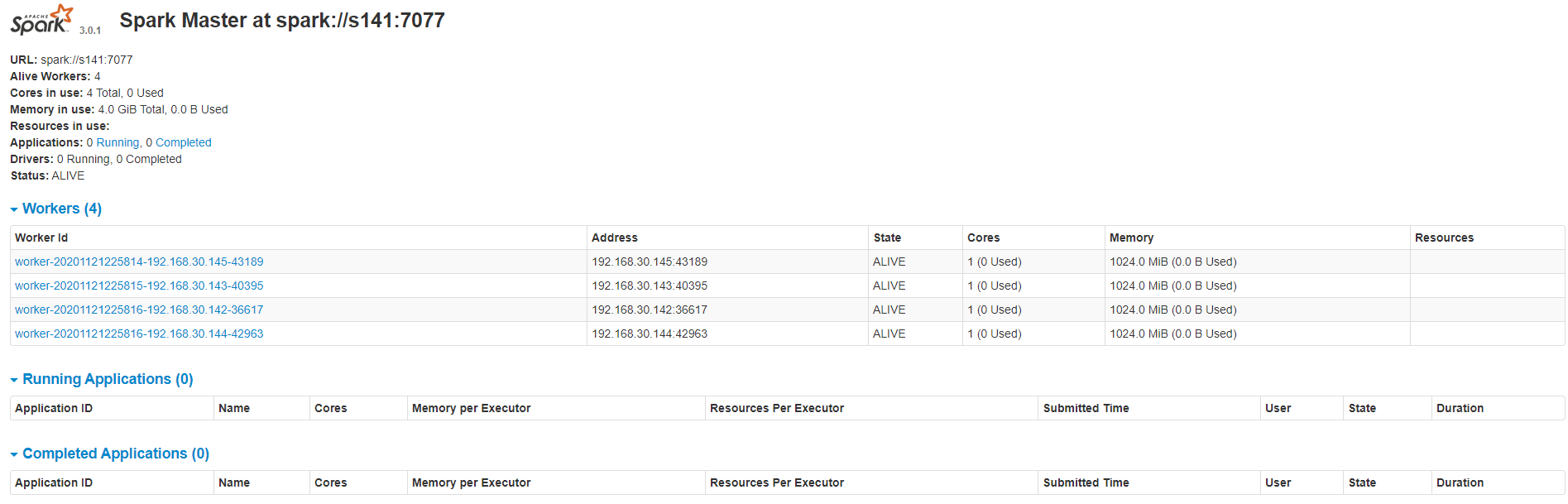
6>查看集群資源頁面(webUI://192.168.30.141:8080/),如果8080端口查不到可以看一下master啟動日誌,可能是8081端口

7>進入集群shell驗證
cd /opt/soft/spark/bin
./spark-shell –master spark://s141:7077

也是正常的,說明Standalone模式部署成功
3.yarn集群模式
1>修改配置文件spark-env.sh
在Standalone模式下搭建yarn集群模式很簡單,只需要在spark-env.sh配置文件加入如下內容即可。
# 添加hadoop的配置目錄
export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
將spark-env.sh分發到各個機器

4>啟動spark集群
先啟動Hadoop的yarn集群
start-yarn.sh
再啟動spark集群,和Standalone模式一樣有兩種方式
cd /opt/soft/spark/sbin 可以單獨啟動master和slave ./start-master.sh ./start-slaves.sh spark://s141:7077 也可以一鍵啟動master和slave ./start-all.sh
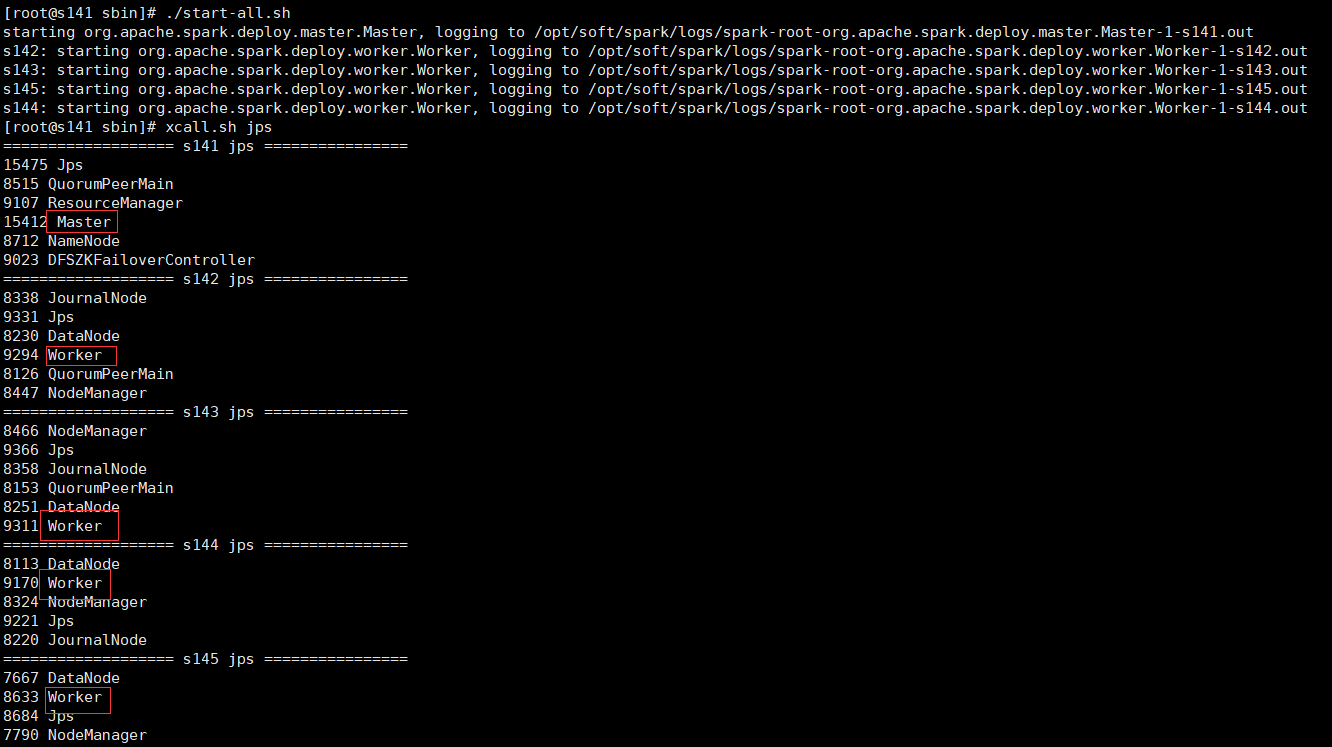
查看master和worker進程正常
5>查看集群資源頁面(webUI://192.168.30.141:8080/),如果8080端口查不到可以看一下master啟動日誌,可能是8081端口
6>進入集群shell驗證
cd /opt/soft/spark/bin
./spark-shell –master yarn

啟動也正常


