mmdetection2.6自定義數據集pipeline
1. data pipeline的基本使用
mmdetection的數據讀取方式分為兩部分,第一部分為數據集,第二部分為data pipeline,通常數據集定義如何處理標註信息,而pipeline定義處理數據字典的所有步驟,一個pipeline由一系列的操作組成,每一個操作都採用一個dict作為輸入,並且也輸出一個dict作為下一個操作的輸入。
下圖是一個經典的pipeline,藍色的方塊是piplline的基本操作,隨着pipeline的移動,每個操作都可以加入新的鍵(綠色的字)作為結果的dict。並且更新已經存在的鍵值(橘色的字)。
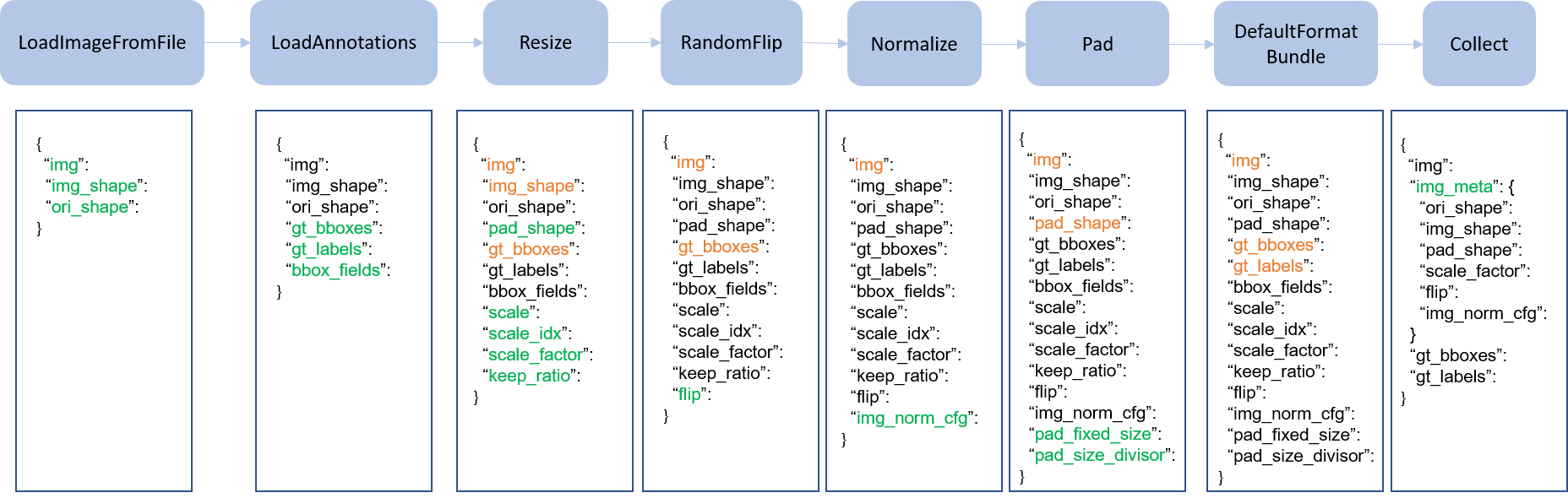
這些操作被分為數據加載,預處理,格式化,測試時增強。
faster rcnn的pipeline的例子:
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
下邊列出了各種operation添加,更新與移除的dict行為。
1.1 數據加載
LoadImageFromFile
添加:img,img_shape,ori_shape
LoadAnnotations
添加:gt_bboxes,gt_bboxes_ignore,gt_labels,gt_masks,gt_semantic_seg,bbox_fields,mask_fields
LoadProposals
添加:proposals
1.2 預處理
Resize
添加:scale,scale_idx,pad_shape,scale_factor,keep_ratio
更新:img,img_shape,* bbox_fields,* mask_fields,* seg_fields
RandomFlip
添加:flip
更新:img,* bbox_fields,* mask_fields,* seg_fields
Pad
添加:pad_fixed_size,pad_size_divisor
更新:img,pad_shape,* mask_fields,* seg_fields
RandomCrop
更新:img,pad_shape,gt_bboxes,gt_labels,gt_masks,* bbox_fields
Normalize
添加:img_norm_cfg
更新:img
SegRescale
更新:gt_semantic_seg
PhotoMetricDistortion
更新:img
Expand
更新:img,gt_bboxes
MinIoURandomCrop
更新:img,gt_bboxes,gt_labels
Corrupt
更新:img
1.3 格式化
ToTensor
更新:specified by keys.
ImageToTensor
更新:specified by keys.
Transpose
更新:specified by keys.
ToDataContainer
更新:specified by fields.
DefaultFormatBundle
更新:img,proposals,gt_bboxes,gt_bboxes_ignore,gt_labels,gt_masks,gt_semantic_seg
Collect
添加:img_meta(img_meta的鍵由指定meta_keys)
刪除:除由所指定的鍵外的所有其他鍵
1.4 測試時增強
MultiScaleFlipAug
2. 擴展並使用自定義的pipeline
- 新建一個python文件,例如:
my_pipeline.py,輸入為一個dict輸出也為一個dict
from mmdet.datasets import PIPELINES
@PIPELINES.register_module()
class MyTransform:
def __call__(self, results):
results['dummy'] = True
return results
- Import這個新類
from .my_pipeline import MyTransform
- 在config文件中使用這個pipeline
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='MyTransform'),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]

