認識Redis集群——Redis Cluster
前言
Redis集群分三種模式:主從模式、sentinel模式、Redis Cluster。之前沒有好好的全面理解Redis集群,特別是Redis Cluster,以為這就是redis集群的英文表達啊,故寫本篇博文來儘可能全面加深理解Redis Cluster。主要參考資料《Redis設計與實現》,主要是PDF電子版,有需要的朋友評論或者私聊!
一、Redis Cluster簡單概述
1. Redis Cluster特點
- 多主多從,去中心化:從節點作為備用,複製主節點,不做讀寫操作,不提供服務
- 不支持處理多個key:因為數據分散在多個節點,在數據量大高並發的情況下會影響性能;
- 支持動態擴容節點:這是我認為算是Rerdis Cluster最大的優點之一;
- 節點之間相互通信,相互選舉,不再依賴sentinel:準確來說是主節點之間相互「監督」,保證及時故障轉移
2. Redis Cluster與其它集群模式的區別
- 相比較sentinel模式,多個master節點保證主要業務(比如master節點主要負責寫)穩定性,不需要搭建多個sentinel實例監控一個master節點;
- 相比較一主多從的模式,不需要手動切換,具有自我故障檢測,故障轉移的特點;
- 相比較其他兩個模式而言,對數據進行分片(sharding),不同節點存儲的數據是不一樣的;
- 從某種程度上來說,Sentinel模式主要針對高可用(HA),而Cluster模式是不僅針對大數據量,高並發,同時也支持HA。
以上都是一些查看資料後個人的見解,其中不足或者不完善的地方歡迎各位大佬指出!
二、Redis Cluster如何集群實現?
1.Redis Cluster是如何將數據分片的?—-哈希槽Slot
(1)哈希槽介紹
Redis集群使用一種稱作一致性哈希的複合分區形式(組合了哈希分區和列表分袂的特徵來計算鍵的歸屬實例),鍵的CRC16哈希值被稱為哈希槽。比如對於三個Redis節點,哈希槽的分配方式如下:
第一個節點擁有0-5500哈希槽
第二節點擁有5501-11000哈希槽
第三節點擁有剩餘的11001-16384哈希槽
一個鍵的對應的哈希槽通過計算鍵的CRC16 哈希值,然後對16384進行取模得到:HASH_SLOT=CRC16(key) modulo 16383,Redis提供了CLUSTER KEYSLOT命令來執行哈希槽的計算:

實踐舉例說明:當我們創建一個Cluster時,系統會默認給我們分好片(你選擇接受系統分配的配置),比如現在有7000-7005六個節點,其中我們分配3個主節點(7000-7002),3個從節點(7003-7005):
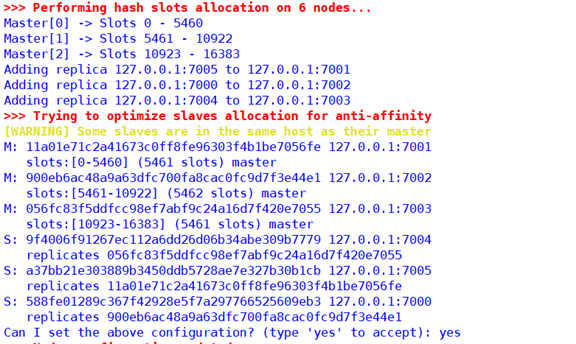
其中slots系統已經指派給了:Master[1]節點擁有0-5500哈希槽、Master[2]節點擁有5501-11000哈希槽、Master[3]節點擁有剩餘的11001-16384哈希槽。
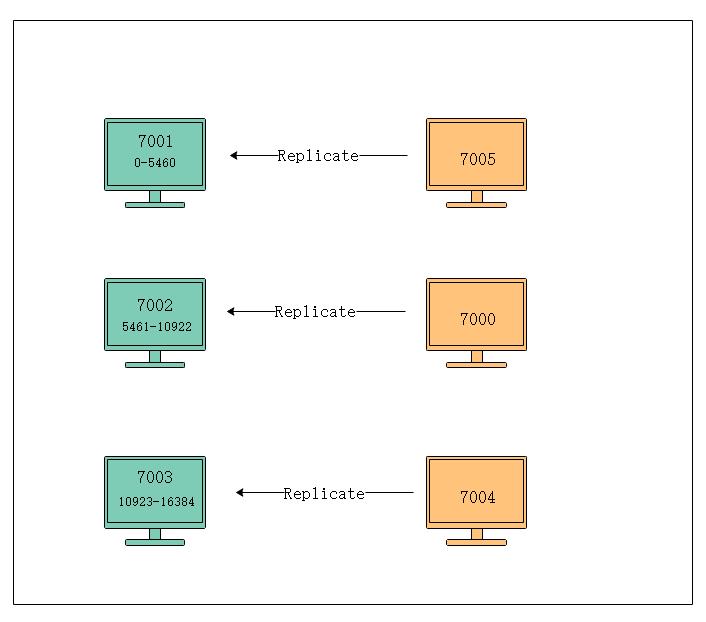
2. 在集群中執行命令
(1)在集群中執行set/get命令
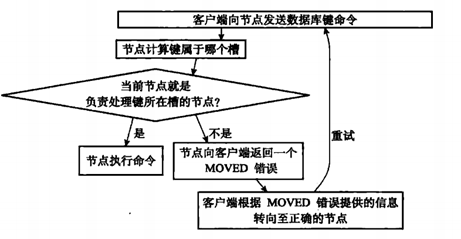
對數據庫中的16384個槽都進行了指派後,集群就會進入上線狀態,這是客戶端就可以向集群中的節點發送數據命令,需要進行計算出命令要處理的鍵是屬於哪個槽的,並檢查是否指派給了自己。
如果鍵所在的槽正好指派當前節點,那麼節點直接執行這個命令:

如果鍵所在的槽並沒有指派給當前節點,那麼節點會向客戶端返回一個MOVED錯誤(集群模式下,MOVED錯誤是回被隱藏的,不會顯示的,而是直接顯示Redirected,註:MOVED錯誤接下來會詳細介紹),指引客戶端轉向(redirect)至正確的節點,並再次發送之前想要執行的命令。
比如:msg這個可以就被重定向指派到了7002節點上,

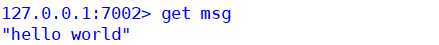
(2)執行加入集群命令(這周內補充完,先mark下使文章結構清晰)
3. 節點數據庫的實現
集群節點保存鍵值對以及鍵值對過期時間的處理方式與Redis單機模式是一樣的,唯一不同就是節點只能使用0號數據庫,而單機Redis服務器則沒有限制。這其實是一個小細節,也是需要注意的!
4. 重新分片
- Redis集群重新分片操作可以將任意數量的已經指派給某個節點的槽改為指派給另一個節點(目標節點),並且相關槽所屬的鍵值對也會從源節點被移動到目標節點上。
- 重新分片操作可以在線進行,在重新分片過程中,集群不需要下線,並且源節點和目標節點都可以繼續處理命令請求。
- Redis集群的重新分片操作是由集群管理軟件redis-trib負責執行的,Redis提供了進行重新分片所需要的所有命令,redis-trib則通過向源節點和目標節點發送命令來重新分片操作。
———————–這裡還沒有完全對相關命令實踐,先mark一下,這周內補充完成(其實就是督促自己不斷學習)——————————-
5. MOVED錯誤與ASK錯誤
(1)MOVED錯誤
上述在集群中執行:set/get命令時,提到過MOVED錯誤,MOVED的錯誤格式(實際上會被隱藏):
# 表示槽10086正由127.0.0.1,端口號為7002的節點負責。
MOVED 10086 127.0.0.1:7002
客戶端與7000節點之間的通信如下:

客戶端根據MOVED錯誤,轉向到7001節點再次發送SET命令:

一個集群客戶端通常會與集群中的多個節點創建套接字連接,而所謂的節點轉向實際上就是換一個套接字進行發送命令。具體的流程如下:
(2)ASK錯誤
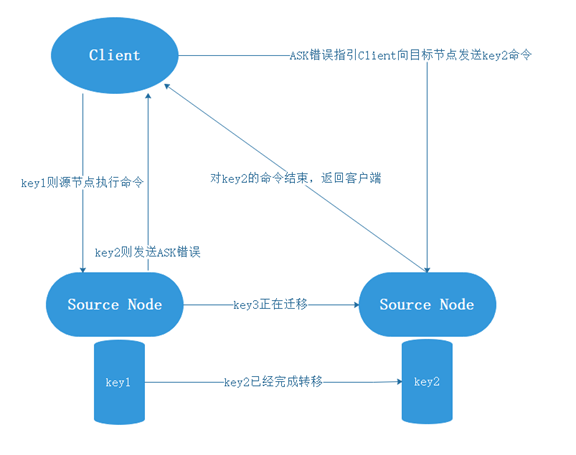
在進行重新分片期間,源節點向目標節點遷移過程中,可能會出現這樣一種情況:當客戶端有操作鍵值對的有關的命令,同時該鍵值對正好屬於被遷移槽。並且被遷移槽的部分鍵值對還駐留在source節點中,另外部分鍵已經保存在target節點中;則會進行下列動作:
- 如果能在source節點找到對應的key,那麼直接執行client的命令;
- 如果找不到該key,那很有可能就在target中,此時source節點會向client發送一個ASK錯誤,引導client轉向正在導入槽的target節點,並再次發送之前想要執行的命令。
舉例說明:比如在源節點中一開始有key1-key3三個key,此時需要源節點需要向目標節點遷移,key2已經遷移完成,key3正在遷移,則會發生以下動作:
(7)ASK錯誤與MOVED錯誤的區別
按照參考書上定義其實就已經很明了,兩者之間的區別
- MOVED錯誤表示槽的負責權已經從一個節點轉移到另外的節點。
- ASK錯誤則是表示兩個節點在遷移槽過程中對key處理的負責權。
三、Redis Cluser是如何保證HA的?
Redis Cluster保證高可用主要還是依靠:故障檢測與故障轉移兩種策略,這其實很多分佈式集群都能保證,但是針對Redis Cluster有一些細節需要好好學習並理解。
1、故障轉移
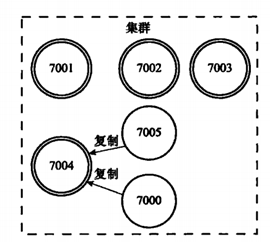
舉例說明:包含7000、7001、7002、7003四個主節點的集群,我們此時加入7004、7005兩個節點,併當做7000的主節點的兩個從節點。
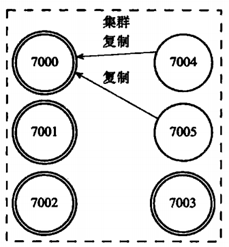
如果此時主節點7000下線(宕機),那麼集群中仍然有幾個主節點將在節點7000的兩個從節點7004、7005中選擇一個節點作為主節點,比如選擇了7004則這個新節點將接管原來節點7000負責處理的槽,並繼續處理客戶端發送的請求,而7005此時作為7004的從節點。
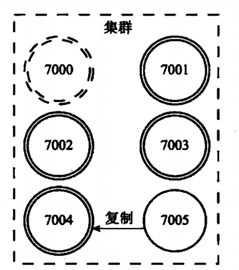
如果下線的7000節點,又重新上線的話,那它將作為節點7004的從節點。
(1)設置從節點
命令:CLUSTER REPLICATE <node_id>,可以讓接受命令的節點成為node_id所指定的從節點,並開始對主節點進行複製;比如根據之前實際操作的例子,我啟動一個7006的節點,然後讓它成為主節點7002的從節點。
在此之前的集群情況是這樣的:

一個節點成為從節點以後,開始複製某個主節點這一信息會通過消息發送給集群中的其他節點,最終集群中所有節點都會知道某個從節點正在複製某個主節點。
———————–這裡還沒有完全對相關命令實踐,先mark一下,這周內補充完成(其實就是督促自己不斷學習)——————————-
(2)故障轉移具體流程:
當一個從節點發現自己正在複製的主節點下線時,從節點將開始對下線主節點進行故障轉移:
1) 在該下線主節點的所有從節點中,選擇一個做主節點
2) 被選中的從節點會執行SLAVEOF no one命令,成為新的主節點;
3) 新的主節點會撤銷對所有對已下線主節點的槽指派,並將這些槽全部派給自己。
4) 新的主節點向集群廣播一條PONG消息,讓其他節點知道「我已經變成主節點了,並且我會接管已下線節點負責的處理的槽」;
5) 新主節點開始接收和自己負責處理的槽有關的命令請求,故障轉移完成。
(3)選舉新節點
1)集群配置紀元是一個自增計數器,它的初始值為0;
2)當集群里的某個節點開始一次故障轉移時,集群配置紀元的值會被增加1
3)對於每個配置紀元,集群里的每個負責處理槽的主節點都有一次投票的機會,而第一個向主節點要求投票的從節點將獲得主節點的投票。
4)當從節點發現自己正在複製的主節點進入已下線狀態時,從節點會向集群廣播消息:要求所有收到這條消息、並且具有投票權的主節點向這個從節點投票。
5)如果一個主節點具有投票權,並且這個主節點尚未投票跟其它從節點,那麼主節點將要求投票的從節點返回一條ACK消息,表示支持該從節點成為新的主節點。
6)每個主節點只有一次投票機會,所有有N個主節點的話,那麼具有大於N/2+1張支持票的從節點只有一個。
7)如果在一個配置紀元里沒有從節點能收集到足夠多的支持票,那麼集群進入一個新的配置紀元,並再次進行選舉,直到選出新的主節點為止。
總結:這跟sentinel模式下的選舉類似,兩個都是基於Raft算法的領頭選舉方法來實現(不是很了解Raft算法,這裡Mark下之後需要補充下Raft算法)。
2、故障檢測
集群中每個節點都會定期地向集群中的其他節點發送PING消息,以此檢測對方是否在線;如果接收PING消息的節點沒有在規定的時間內,向發送PING消息的節點返回PONG消息,那麼發送PING消息的節點就會將PING消息節點標記為疑似下線(possible fail,PFAIL)。
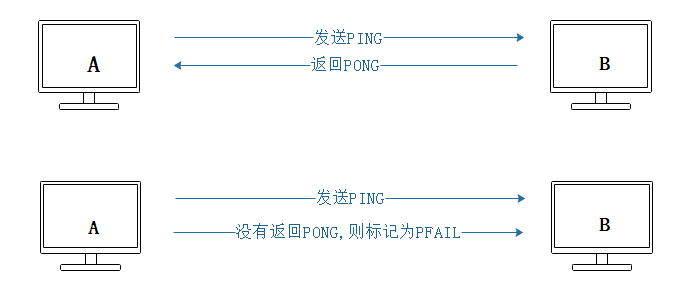
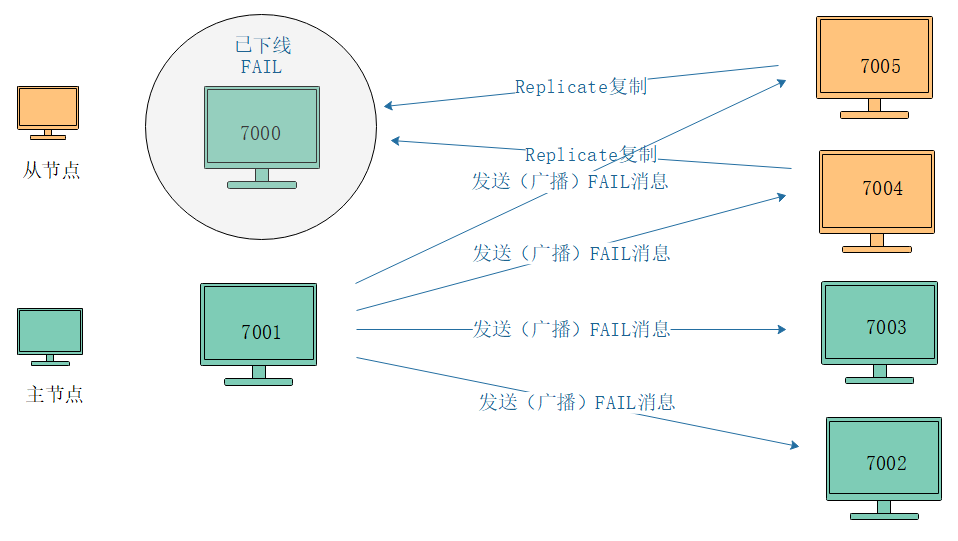
如果在集群中,超過半數以上負責處理槽的主節點都將某個節點X標記為PFAIL,則某個主節點就會將這個主節點X就會被標記為已下線(FAIL),並且廣播到這條消息,這樣其他所有的節點都會立即將主節點X標記為FAIL。
假設:
- Redis Cluster有四個主節點:7000-7003,兩個從節點:7004與7005
- 此時7000已下線,並且主節點7001認為主節點7000進入PFAIL
- 同時主節點7002、7003也認為主節點7000進入下線狀態
這樣一來超過半數的主節點都認為7000節點FAIL,那麼7001便會標記7000為FAIL狀態,並向集群廣播主節點7000已經FAIL消息。