適用初學者的5種Python數據輸入技術
摘要:數據是數據科學家的基礎,因此了解許多加載數據進行分析的方法至關重要。在這裡,我們將介紹五種Python數據輸入技術,並提供代碼示例供您參考。
數據是數據科學家的基礎,因此了解許多加載數據進行分析的方法至關重要。在這裡,我們將介紹五種Python數據輸入技術,並提供代碼示例供您參考。
作為初學者,您可能只知道一種使用p andas.read_csv函數讀取數據的方式(通常以CSV格式)。它是最成熟,功能最強大的功能之一,但其他方法很有幫助,有時肯定會派上用場。
我要討論的方法是:
- Manual 函數
- loadtxt 函數
- genfromtxtf 函數
- read_csv 函數
- Pickle
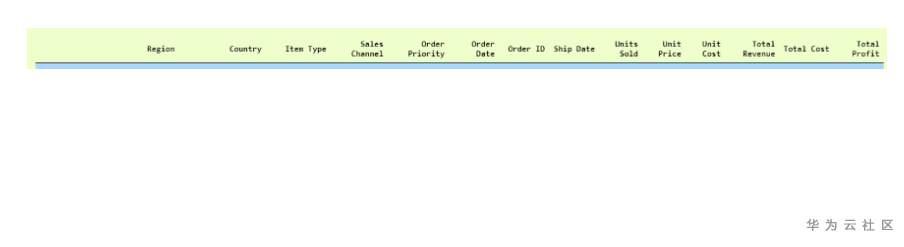
我們將用於加載數據的數據集可以在此處找到 。它被稱為100-Sales-Records。
Imports
我們將使用Numpy,Pandas和Pickle軟件包,因此將其導入。

1. Manual Function
這是最困難的,因為您必須設計一個自定義函數,該函數可以為您加載數據。您必須處理Python的常規歸檔概念,並使用它來讀取 .csv 文件。
讓我們在100個銷售記錄文件上執行此操作。

嗯,這是什麼????似乎有點複雜的代碼!!!讓我們逐步打破它,以便您了解正在發生的事情,並且可以應用類似的邏輯來讀取 自己的 .csv文件。
在這裡,我創建了一個 load_csv 函數,該函數將要讀取的文件的路徑作為參數。
我有一個名為data 的列表, 它將具有我的CSV文件數據,而另一個列表 col 將具有我的列名。現在,在手動檢查了csv之後,我知道列名在第一行中,因此在我的第一次迭代中,我必須將第一行的數據存儲在 col中, 並將其餘行存儲在 data中。
為了檢查第一次迭代,我使用了一個名為checkcol 的布爾變量, 它為False,並且在第一次迭代中為false時,它將第一行的數據存儲在 col中 ,然後將checkcol 設置 為True,因此我們將處理 數據列表並將其餘值存儲在 數據列表中。
邏輯
這裡的主要邏輯是,我使用readlines() Python中的函數在文件中進行了迭代 。此函數返回一個列表,其中包含文件中的所有行。
當閱讀標題時,它會將新行檢測為 \ n 字符,即行終止字符,因此為了刪除它,我使用了 str.replace 函數。
由於這是一個 的.csv 文件,所以我必須要根據不同的東西 逗號 ,所以我會各執一個字符串, 用 string.split(「」) 。對於第一次迭代,我將存儲第一行,其中包含列名的列表稱為 col。然後,我會將所有數據附加到名為data的列表中 。
為了更漂亮地讀取數據,我將其作為數據框格式返回,因為與numpy數組或python的列表相比,讀取數據框更容易。
輸出量
利弊
重要的好處是您具有文件結構的所有靈活性和控制權,並且可以以任何想要的格式和方式讀取和存儲它。
您也可以使用自己的邏輯讀取不具有標準結構的文件。
它的重要缺點是,特別是對於標準類型的文件,編寫起來很複雜,因為它們很容易讀取。您必須對需要反覆試驗的邏輯進行硬編碼。
僅當文件不是標準格式或想要靈活性並且以庫無法提供的方式讀取文件時,才應使用它。
2. Numpy.loadtxt函數
這是Python中著名的數字庫Numpy中的內置函數。加載數據是一個非常簡單的功能。這對於讀取相同數據類型的數據非常有用。
當數據更複雜時,使用此功能很難讀取,但是當文件簡單時,此功能確實非常強大。
要獲取單一類型的數據,可以下載 此處 虛擬數據集。讓我們跳到代碼。
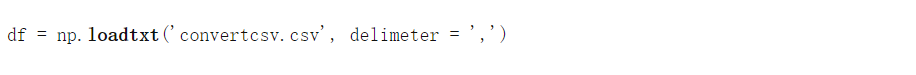
這裡,我們簡單地使用了在傳入的定界符中 作為 ‘,’的 loadtxt 函數 , 因為這是一個CSV文件。
現在,如果我們打印 df,我們將看到可以使用的相當不錯的numpy數組中的數據。

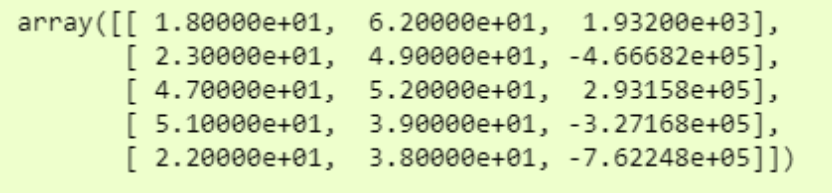
由於數據量很大,我們僅打印了前5行。
利弊
使用此功能的一個重要方面是您可以將文件中的數據快速加載到numpy數組中。
缺點是您不能有其他數據類型或數據中缺少行。
3. Numpy.genfromtxt()
我們將使用數據集,即第一個示例中使用的數據集「 100 Sales Records.csv」,以證明其中可以包含多種數據類型。
讓我們跳到代碼。

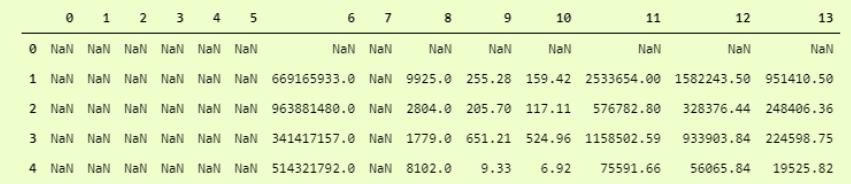
為了更清楚地看到它,我們可以以數據框格式看到它,即
這是什麼?哦,它已跳過所有具有字符串數據類型的列。怎麼處理呢?
只需添加另一個 dtype 參數並將dtype 設置 為None即可,這意味着它必須照顧每一列本身的數據類型。不將整個數據轉換為單個dtype。

然後輸出

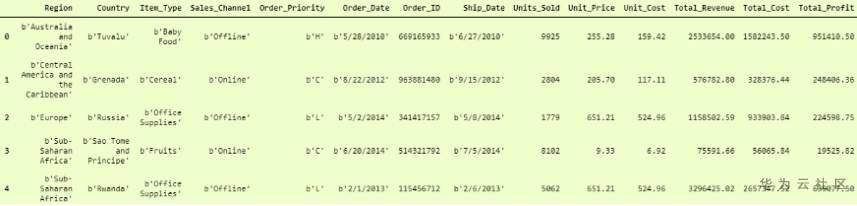
比第一個要好得多,但是這裡的「列」標題是「行」,要使其成為列標題,我們必須添加另一個參數,即 名稱 ,並將其設置為 True, 這樣它將第一行作為「列標題」。
即

我們可以將其打印為

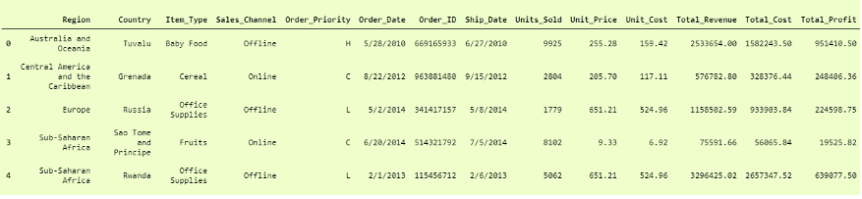
4. Pandas.read_csv()
Pandas是一個非常流行的數據操作庫,它非常常用。read_csv()是非常重要且成熟的 功能 之一,它 可以非常輕鬆地讀取任何 .csv 文件並幫助我們進行操作。讓我們在100個銷售記錄的數據集上進行操作。
此功能易於使用,因此非常受歡迎。您可以將其與我們之前的代碼進行比較,然後進行檢查。

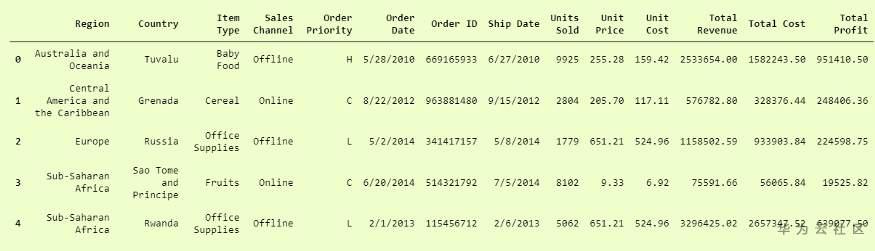
你猜怎麼著?我們完了。這實際上是如此簡單和易於使用。Pandas.read_csv肯定提供了許多其他參數來調整我們的數據集,例如在我們的 convertcsv.csv 文件中,我們沒有列名,因此我們可以將其讀取為
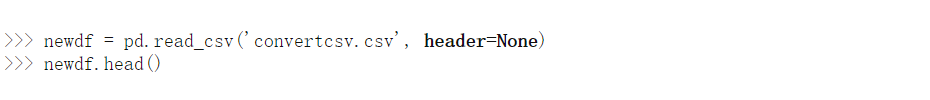
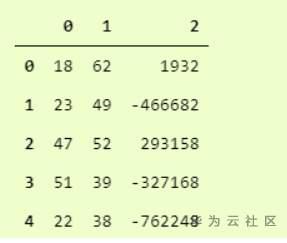
我們可以看到它已經讀取了沒有標題的 csv 文件。您可以在此處查看官方文檔中的所有其他參數 。
5. Pickle
如果您的數據不是人類可以理解的良好格式,則可以使用pickle將其保存為二進制格式。然後,您可以使用pickle庫輕鬆地重新加載它。
我們將獲取100個銷售記錄的CSV文件,並首先將其保存為pickle格式,以便我們可以讀取它。

這將創建一個新文件 test.pkl ,其中包含來自 Pandas 標題的 pdDf 。
現在使用pickle打開它,我們只需要使用 pickle.load 函數。

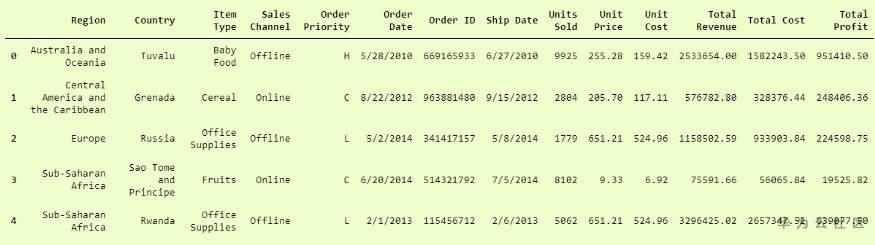
在這裡,我們已成功從pandas.DataFrame 格式的pickle文件中加載了數據 。
本文分享自華為雲社區《Python加載數據的5種不同方式》,原文作者:一隻無腦程序員


