Hadoop4-HDFS分佈式文件系統原理
- 2019 年 11 月 15 日
- 筆記
一、簡介
1、分佈式文件系統鋼結構
分佈式文件系統由計算機集群中的多個節點構成,這些節點分為兩類:
主節點(MasterNode)或者名稱節點(NameNode)
從節點(Slave Node)或者數據節點(DataNode)


2、HDFS能夠帶來什麼好處
兼容廉價的硬件設備
流數據讀寫
大數據集
簡單的文件模型
強大的跨平台兼容性
3、局限性
不適合低延遲數據訪問
無法高效存儲大量小文件
不支持多用戶寫入節任意修改文件
二、概念
1、塊
HDFS默認一個塊64MB,一個文件被分成多個塊,以塊為存儲單位,2.x新版本中是128MB
塊的大小遠大於普通文件系統,可以最小化尋找開銷
HDFS採用抽象的塊概念可以帶來一下幾個明顯的好處:
支持大規模文件存儲:文件以塊為單位進行存儲,一個大規模文件可以被分拆成若干各文件塊,不同文件塊被分發到不同節點,因此,一個文件的大小不會受到單個節點存儲容量限制,可以遠大於網絡中任意節點的存儲容量
簡化系統設計:簡化了存儲管理,因為文件塊大小固定,這樣可以非常容易算出一個幾點可以存儲多少塊,其次方便了元數據的管理,元數不需要和文件塊一起存儲,可以由其他系統負載管理元數據
適合數據備份:每個文件塊都可以冗餘存儲到多個節點上,提高了系統容錯和可用性
2、名稱節點
名稱節點負責管理分佈式文件系統的命令空間(Namespace),保存了兩個核心的數據結構,即Fslmage和EditLog
Fslmage用於維護文件系統樹以及文件樹中所有的文件和文件夾的元數據
操作日誌文件EditLog中記錄了所有針對文件的創建、刪除、重命名等操作
名稱節點記錄了每個文件中個板塊所在的數據節點的位置信息


3、Fslmage文件
Fslmage文件包含文件系統中所有目錄和文件inode的序列化形式,每個inode是一個文件或目錄的元數據內部表示,並包含此類信息:文件的複製等級、修改和訪問時間、訪問權限、塊大小以及組成文件的塊。對於目錄,則存儲修改時間、權限和配額元數據
Fslmage文件沒有記錄塊存儲在哪個數據節點。而是由名稱節點把這些映射保留在內存中,當數據節點加入HDFS集群時,數據節點會把自己所包含的塊列表告知給名稱節點,此後會定期執行這種告知操作,以確保名稱節點的塊映射時最新的
4、名稱節點的啟動過程
1)啟動名稱節點—》將FsImage文件—》加載到內存—》執行EditLog—》同步—》內存中的元數據客戶可讀
2)內存與元數據映射完成—》創建新的Fslmage文件+空的Editlog文件
說明:名稱節點起來後,HDFS中的更新操作會重新寫到Editlog文件中,因為Fslmage文件一般都很大(GB級別的很常見),如果所有的更新操作都往Fslmage文件中添加,這樣會導致系統運行的十分緩慢,但是,如果往EditLog文件裏面寫就不會這樣,因為EditLog要小很多,每次執行寫操作之後,且在向客戶端發送成功代碼之前,edits文件都需要同步更新
5、名稱節點運行期間EditLog不斷變大的問題
運行期間HDFS的所有操作—》寫到EditLog—》時間(久而久之)—》EditLog文件將變得非常大
對運行中HDFS影響不大,但是一旦重啟Fslmage裏面的所有內容映像到內存中,然後在一條一條執行EditLog,當EditLog文件非常大的時,就會導致名稱節點啟動非常緩慢,並且此期間是安全模式,無法提供寫操作,影響用戶使用
解決此問題就需要SecondaryNameNode第二名稱節點
6、第二名稱節點SecondaryNameNode
1)它用來保存名稱節點中對HDFS元數據信息的備份,並減去名稱節點重啟的時間,一般是單獨運行在一台機器上
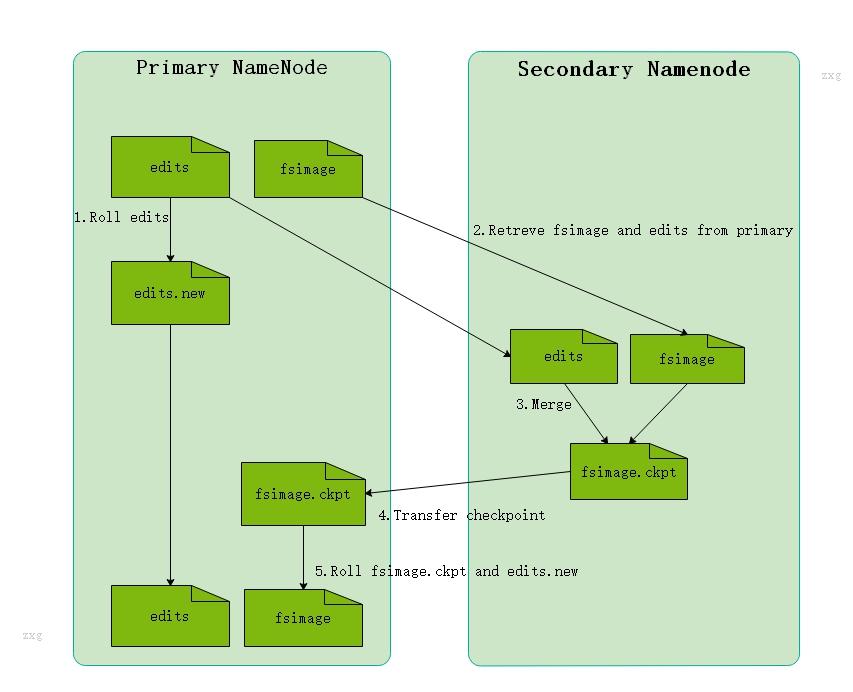

2)SecondaryNameNode工作情況
1、SecondaryNameNode定期於NameNode通信,請求停止使用EditLog文件,暫時將新的寫操作寫到要給新的文件edit.new,此操作瞬間完成,上層寫日誌函數感覺不到差別
2、SecondaryNameNode通過HTTP GEt從NameNode上獲取FsImage/EditLog文件下載到本地的相應目錄下
3、SecondaryNameNode將下載的Fslmage載入內存然後一條條執行EditLog中的操作,使得內存中的Fslmage保持最新,這個就是EditLog和FsImage文件合併
4、SecondaryNameNode執行完合併會通過post方式將新的FsImage文件發送到NameNode節點
5、NameNode將從SecondaryNameNode接收到的新的FsImage替換就的FsImage文件,同時將edit.new替換EditLog文件,這時EditLog就變小了
7、數據節點DataNode
數據分佈在各節點,數據節點負責數據的存儲和讀取,會根據客戶端或名稱節點的調度進行數據的存儲和檢索,並且向名稱節點定期發送所存儲的塊的列表
三、體系結構
HDFS採用了主從(M/S)結構模型,名稱節點作為中心服務器,管理文件系統的命名空間即客戶端文件的訪問。數據節點負責進行客戶端的讀/寫請求,在名稱節點的調度嚇進行數據的創建、刪除、複製操作
1、命名空間
HDFS的命名空間包含目錄、文件、塊
HDFS使用傳統的分級文件體系,因此,可以像使用普通文件系統一樣,創建/刪除目錄和文件,及在目錄間轉移重命名等
2、通信協議
HDFS通信協議都是構建在TCP/IP協議基礎之上
客戶端通過一個可配置端口向名稱節點發起tcp鏈接,並使用客戶端協議與名稱節點進行交互
名稱節點和數據節點間使用數據節點協議進行交互
客戶端與數據節點的交互是通過RPC(Remote Procedure Call)來實現的。在設計上,名稱節點不會主動發起RPC,而是響應來自客戶端和數據節點的RPC請求
3、客戶端
客戶端就是用戶操作HDFS的方式,HDFS在部署時都提供了客戶端
HDFS客戶端時一個庫,包括HDFS文件系接口,這些接口隱藏了HDFS實現中的大部分複雜性
嚴格來說客戶端並不是HDFS的一部分
客戶端支持打開、讀寫、寫入等常見的操作,並且提供了類似shell的命令行方式來訪問HDFS中的數據
HDFS也提供了Java API,作為應用程序訪問文件系統的客戶端編程接口
4、局限性
HDFS只設置了一個名稱節點,這樣做的好處時簡化系統設計,但是也帶了局限性:
1)命名空間的限制:名稱節點時保持在內存中,因此名稱節點能夠容納對象(文件、塊)的個數會收到內存大小限制
2)性能瓶頸:整個分佈式文件系統的吞吐量,受限單個名稱節點的吞吐量
3)隔離問題:由於集群中只有一個名稱節點,只有一個命名空間,因此,無法對不同應用程序進行隔離
4)集群的可用性:一旦唯一的名稱節點發送故障,整個集群不可用
四、存儲原理
1、冗餘數據保存
HDFS採用了多副本方式對數據進行冗餘,多副本方式優點:
1)加快數據傳輸速度
2)容易檢查數據錯誤
3)保證數據可靠性


2、數據存取策略
1)數據存放
第一個副本:放在上傳文件的數據節點,如果集群外提交,隨機選一台磁盤不太滿、cpu不太忙的節點
第二個副本:放置在與第一個副本不同的機架的節點上
第三個副本:與第一個副本相同機架的其他節點上
更多副本:隨機
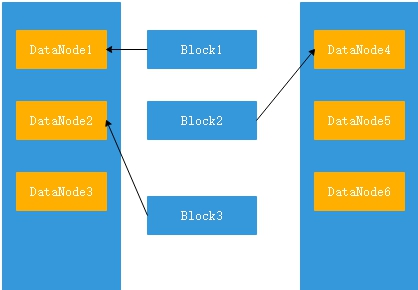

3、數據讀寫
hdfs提供了一個API可以確定一個數據節點所屬的機架ID,客戶端也可以調用API獲取自己所屬機架ID
當客戶端讀取數據時,名稱節點獲得數據塊不同的位置列表,列表中包含了副本所在數據節點,發現某個數據數據庫副本對應的機架ID和客戶端對應機架ID相同,就優先選擇該副本讀取數據,如沒有就隨機讀取
4、容錯-數據錯誤與恢復
HDFS具有較高的容錯性,可以兼容廉價硬件,它把依你高見出錯看作一種常態,還有機制檢測數據錯誤和自動恢復,容錯性主要由名稱節點出錯、數據節點出錯、數據出錯。
1)名稱節點出錯
回顧:Fslmage,Editlog
如果整個兩個文件損壞,那麼HDFS實例將失效
hdfs提供SecondaryNameNode,將會備份這兩個文件,在必要的時候Fslmage,Editlog數據進行恢復
2)數據節點出錯
心跳信息定期向名稱節點報告自己狀態,如果出問題,就會被標記為宕機,節點上的數據被標記不可讀,名稱節點將不會給他們發送任何I/O請求
如出現問題,一些數據節點不可用可能會導致一些數據庫副本數量小於冗餘因子,名稱節點會定期進行檢測,一旦發生這種情況會啟動數據冗餘複製,為它生成新的副本
HDFS和其他分佈式文件系統最大的區別就是可以調整冗餘數據位置
3)數據出錯
由網絡磁盤等錯誤的因素都會導致數據錯誤,客戶端讀取到數據後都會進行md5/sha1對數據進行校驗,以確定讀取到正確的數據
在創建文件時,客戶端會對每個文件進行信息摘錄,並把這些信息寫入到一個路徑的隱藏文件
客戶端讀取文件時,先讀取信息摘錄,然後利用該信息進行校驗,如果出錯,客戶端就會請求到另外的節點讀取,並向名稱節點報告,名稱節點會定期檢測並且重新複製
五、數據讀取過程
1、讀取文件


簡單流程就是:打開文件–》獲取數據塊信息–》讀取請求–》讀取數據–》獲取數據塊信息–》讀取數據–》關閉文件
2、寫數據過程
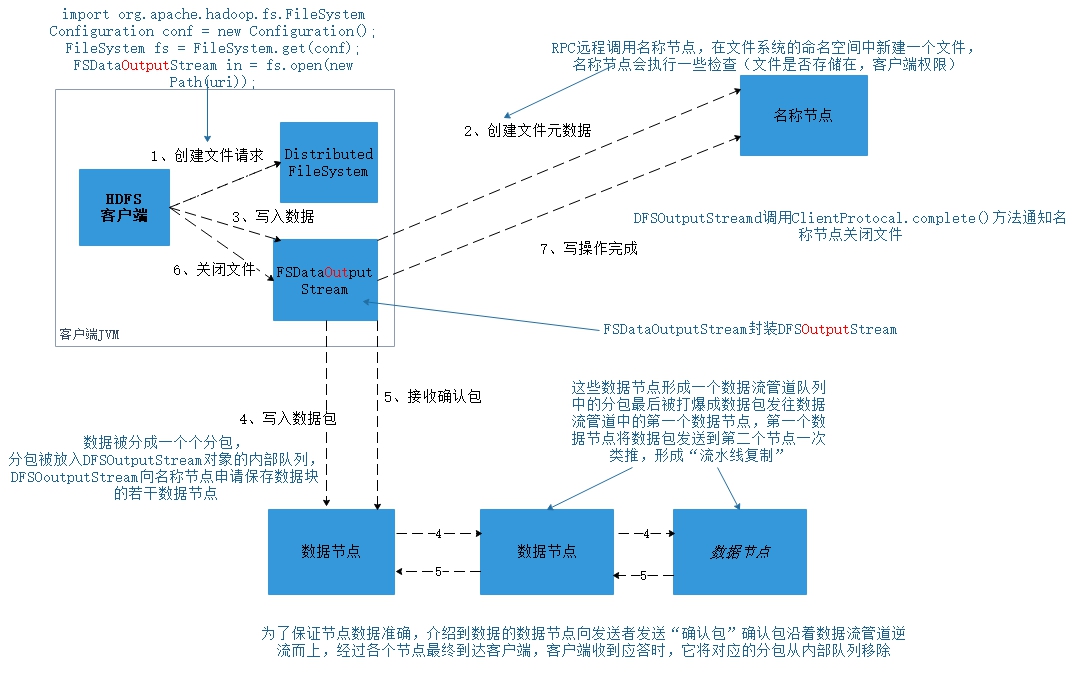

簡單流程:創建文件–》創建文件元數據–》寫入數據–》–》寫入數據包–》接收確認包–》關閉文件–》寫操作完成
完全參考學習:http://dblab.xmu.edu.cn/blog/290-2/
轉載請註明出處:https://www.cnblogs.com/zhangxingeng/p/11819418.html




