深入探討HBASE
HBASE基礎
1. HBase簡介
HBase是一個高可靠、高性能、面向列的,主要用于海量結構化和半結構化數據存儲的分佈式key-value存儲系統。
它基於Google Bigtable開源實現,但二者有明顯的區別:Google Bigtable基於GFS存儲,通過MAPREDUCE處理存儲的數據,通過chubby處理協同服務;而HBase底層存儲基於hdfs,可以利用MapReduce、Spark等計算引擎處理其存儲的數據,通過Zookeeper作為處理HBase集群協同服務。
2. HBase表結構
HBase以表的形式將數據最終存儲的hdfs上,建表時無需指定表中字段,只需指定若干個列簇即可。插入數據時,指定任意多個列到指定的列簇中。通過行鍵、列簇、列和時間戳可以對數據進行快速定位。
2.1 行鍵(row key)
HBase基於row key唯一標識一行數據,是用來檢索數據的主鍵。HBase通過對row key進行字典排序從而對表中數據進行排序。基於這個特性,在設計row key時建議將經常一起讀取的數據存儲在一起。
2.2 列簇(column family)
HBase中的表可以有若干個列簇,一個列簇下面可以有多個列,必須在建表時指定列簇,但不需要指定列。
一個列族的所有列存儲在同一個底層文存儲件中。
HBase對訪問控制、磁盤和內存的使用統計都是在列族層面進行的。列族越多,在取一行數據時所要參與IO、搜尋的文件就越多。所以,如果沒有必要,不要設置太多的列族,也不要修改的太頻繁。並且將經常一起查詢的列放到一個列簇中,減少文件的IO、尋址時間,提升訪問性能。
2.3 列(qualifier)
列可以是任意的位元組數組,都唯一屬於一個特定列簇,它也是按照字典順序排序的。
列名都以列簇為前綴,常見引用列格式:column family:qualifier,如city:beijing、city:shanghai都屬於city這個列簇。
列值沒有類型和長度限定。
2.4 Cell
通過{row key, column family:qualifier, version}可以唯一確定的存貯單元,cell中的數據全部以位元組碼形式存貯。
2.5 時間戳(timestamp)
每個cell都可以保存同一份數據的不同版本,不同版本的數據按照時間倒序排序,讀取時優先讀取最新值,並通過時間戳來索引。
時間戳的類型是64位整型,可以由客戶端顯式賦值或者由HBase在寫入數據時自動賦值(此時時間戳是精確到毫秒的當前系統時間),可以通過顯式生成唯一性的時間戳來避免數據版本衝突。
每個cell中,為了避免數據存在過多版本造成的的存貯、索引等管負擔,HBase提供了兩種數據版本回收方式(可以針對每個列簇進行設置):
1)保存數據的最新n個版本
2)通過設置數據的生命周期保存最近一段時間內的版本
將以上特點綜合在一起,就有了如下數據存取模式:SortedMap<RowKey,List<SortedMap<Column,List<Value,Timestamp>>>>第一個SortedMap代表那個表,包含一個列族集合List(多個列族)。列族中包含了另一個SortedMap存儲列和相應的值。
HBASE系統架構
下圖展現了HBase集群、內部存儲中的主要角色,以及存儲過程中與hdfs的交互:
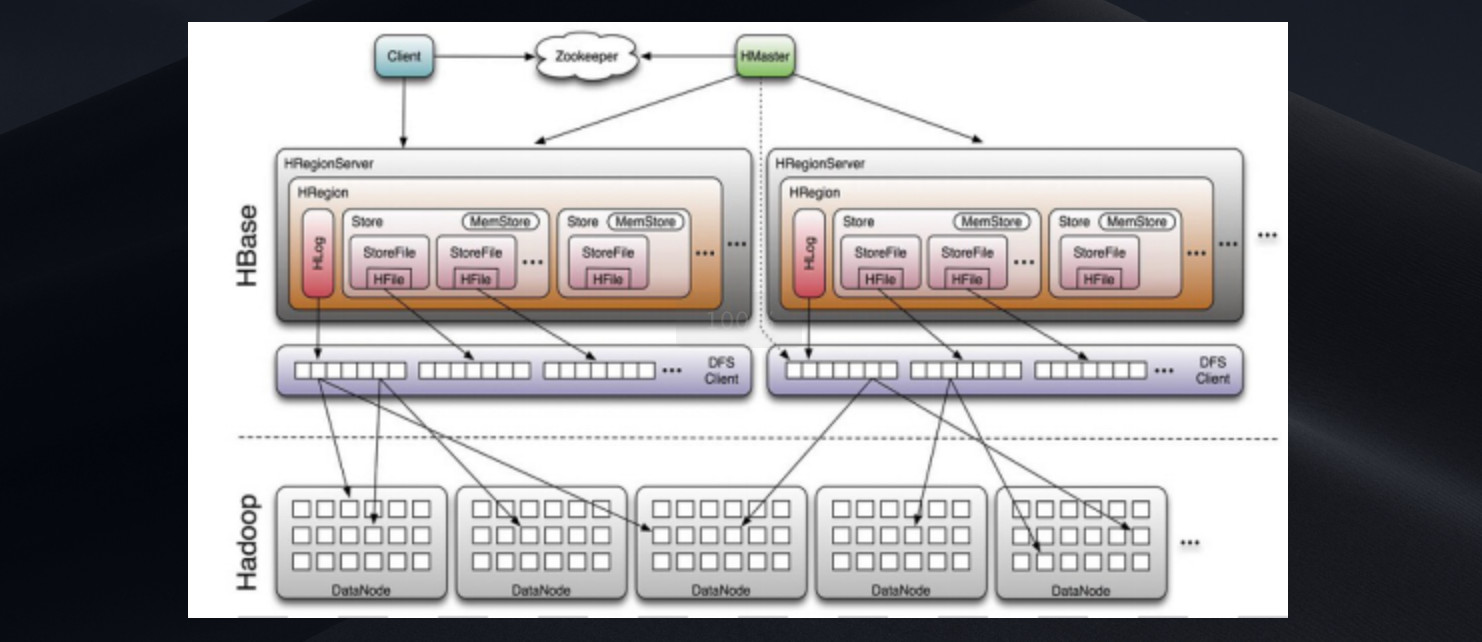
下面介紹一下HBase集群中主要角色的作用:
HMaster
HBase集群的主節點,可以配置多個,用來實現HA,主要作用:
1. 為RegionServer分配region
2. 負責RegionServer的負載均衡
3. 發現失效的RegionServer,重新分配它負責的region
4. hdfs上的垃圾文件回收(標記為刪除的且經過major compact的文件)
5. 處理schema更新請求
RegionServer(以下簡稱RS)
HBase集群的從節點,負責數據存儲,主要作用:
1. RS維護HMaster分配給它的region,處理對這些region的IO請求
2. RS負責切分在運行過程中變得過大的region
Zookeeper(以下簡稱ZK)
1. 通過選舉,保證任何時候,集群中只有一個active master(HMaster與RS啟動時會向ZK註冊)
2. 存貯所有region的尋址入口,如-ROOT-表在哪台服務器上
3. 實時監控RS的狀態,將RS的上下線信息通知HMaster
4. 存儲HBase的元數據,如有哪些table,每個table有哪些column family
client包含訪問HBase的接口,維護着一些緩存來加速對HBase的訪問,比如region的位置信息。
client在訪問HBase上數據時不需要HMaster參與(尋址訪問ZK和RS,數據讀寫訪問RS),HMaster主要維護着table和region的元數據信息,負載很低。
HBASE數據存儲
通過之前的HBase系統架構圖,可以看出:
1. HBase中table在行的方向上分割為多個region,它是HBase負載均衡的最小單元,可以分佈在不同的RegionServer上,但是一個region不能拆分到多個RS上
2. region不是物理存儲的最小單元region由一個或者多個store組成,每個store保存一個column family。每個store由一個memstore和多個storefile組成,storefile由hfile組成是對hfile的輕量級封裝,存儲在hdfs上。
3. region按大小分割,默認10G,每個表一開始只有一個region,隨着表中數據不斷增加,region不斷增大,當增大到一個閥值時,region就會劃分為兩個新的region。
當表中的數據不斷增多,就會有越來越多的region,這些region由HMaster分配給相應的RS,實現負載均衡。
HBase底層存儲基於hdfs,但對於為null的列並不佔據存儲空間,並且支持隨機讀寫,主要通過以下機制完成:
1. HBase底層存儲結構依賴了LSM樹(Log-structured merge tree)
2. 數據寫入時先寫入HLog,然後寫入memstore,當memstore存儲的數據達到閾值,RS啟動flush cache將memstore中的數據刷寫到storefile
3. 客戶端檢索數據時,先在client緩存中找,緩存中找不到則到memstore找,還找不到才會從storefile中查找
4. storefile底層以hfile的形式存儲到hdfs上,當storefile達到一定閾值會進行合併
5. minor合併和major合併小文件,刪棄做過刪除標記的數據
WAL log
即預寫日誌,該機制用於數據的容錯和恢復,每次更新都會先寫入日誌,只有寫入成功才會通知客戶端操作成功,然後RS按需自由批量處理和聚合內存中的數據。
每個HRegionServer中都有一個HLog對象,它負責記錄數據的所有變更,被同一個RS中的所有region共享。
HLog是一個實現預寫日誌的類,在每次用戶操作寫入memstore之前,會先寫一份數據到HLog文件中,HLog文件定期會滾動出新的,並刪除已經持久化到storefile中的數據的文件。
當RS意外終止後,HMaster會通過ZK感知到,HMaster首先會處理遺留的HLog文件,將其中不同region的日誌數據進行拆分,分別放到相應region的目錄下,然後再將失效的region重新分配,領取到這些region的HRegionServer在加載region的過程中,如果發現有歷史HLog需要處理,會”重放日誌”中的數據到memstore中,然後flush到storefile,完成數據恢復。
HLog文件就是一個普通的Hadoop Sequence File。
HBASE中LSM樹的應用
1. 輸入數據首先存儲在日誌文件 [文件內數據完全有序,按鍵排序]
2. 然後當日誌文件修改時,對應更新會被先保存在內存中來加速查詢
3. 數據經過多次修改,且內存空間達到設定閾值,LSM樹將有序的”鍵記錄”flush到磁盤,同時創建一個新的數據存儲文件。[內存中的數據由於已經被持久化了,就會被丟棄]
4. 查詢時先從內存中查找數據,然後再查找磁盤上的文件
5. 刪除只是「邏輯刪除」即將要刪除的數據或者過期數據等做刪除標記,查找時會跳過這些做了刪除標記的數據
6. 多次數據刷寫之後會創建許多數據存儲文件,後台線程會自動將小文件合併成大文件。合併過程是重寫一遍數據,major compaction會略過做了刪除標記的數據[丟棄]
7. LSM樹利用存儲的連續傳輸能力,以磁盤傳輸速率工作並能較好地擴展以處理大量數據。使用日誌文件和內存存儲將隨機寫轉換成順序寫
8. LSM樹對磁盤順序讀取做了優化
9. LSM樹的讀和寫是獨立的
HBASE尋址機制
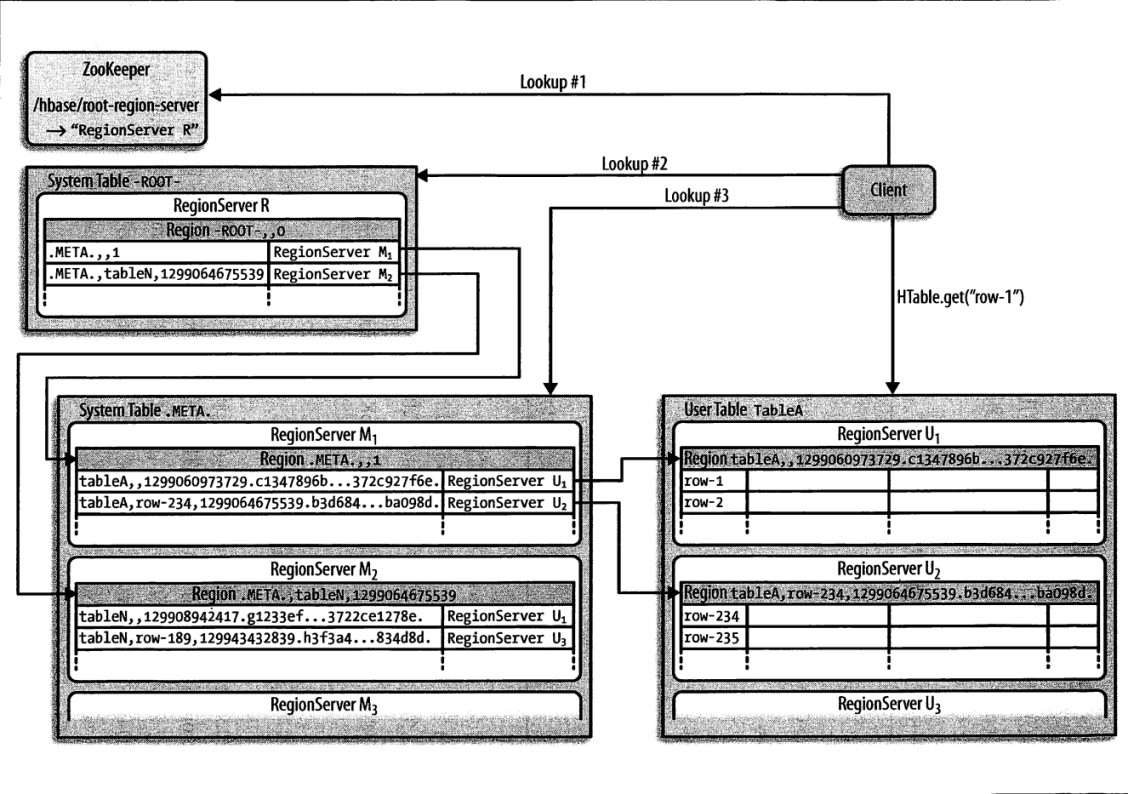
HBase提供了兩張特殊的目錄表-ROOT-和META表,-ROOT-表用來查詢所有的META表中region位置。HBase設計中只有一個root region即root region從不進行切分,從而保證類似於B+樹結構的三層查找結構:
第1層:zookeeper中包含root region位置信息的節點,如-ROOT-表在哪台regionserver上
第2層:從-ROOT-表中查找對應的meta region位置即.META.表所在位置
第3層:從META表中查找用戶表對應region位置
目錄表中的行健由region表名、起始行和ID(通常是以毫秒表示的當前時間)連接而成。HBase0.90.0版本開始,主鍵上有另一個散列值附加在後面,目前這個附加部分只用在用戶表的region中。
注意:
1. root region永遠不會被split,保證了最多需要三次跳轉,就能定位到任意region
2. META表每行保存一個region的位置信息,row key採用表名+表的最後一行編碼而成
3. 為了加快訪問,META表的全部region都保存在內存中
4. client會將查詢過的位置信息保存緩存起來,緩存不會主動失效,因此如果client上的緩存全部失效,則需要進行最多6次網絡來回,才能定位到正確的region(其中三次用來發現緩存失效,另外三次用來獲取位置信息)
關於尋址的幾個問題:
1. 既然ZK中能保存-ROOT-信息,那麼為什麼不把META信息直接保存在ZK中,而需要通過-ROOT-表來定位?
ZK不適合保存大量數據,而META表主要是保存region和RS的映射信息,region的數量沒有具體約束,只要在內存允許的範圍內,region數量可以有很多,如果保存在ZK中,ZK的壓力會很大。
所以,通過一個-ROOT-表來轉存到regionserver中相比直接保存在ZK中,也就多了一層-ROOT-表的查詢(類似於一個索引表),對性能來說影響不大。
2. client查找到目標地址後,下一次請求還需要走ZK —> -ROOT- —> META這個流程么?
不需要,client端有緩存,第一次查詢到相應region所在RS後,這個信息將被緩存到client端,以後每次訪問都直接從緩存中獲取RS地址即可。
但是如果訪問的region在RS上發生了改變,比如被balancer遷移到其他RS上了,這個時候,通過緩存的地址訪問會出現異常,在出現異常的情況下,client需要重新走一遍上面的流程來獲取新的RS地址。
minor合併和major合併
上文提到storefile最終是存儲在hdfs上的,那麼storefile就具有隻讀特性,因此HBase的更新其實是不斷追加的操作。
當一個store中的storefile達到一定的閾值後,就會進行一次合併,將對同一個key的修改合併到一起,形成一個大的storefile,當storefile的大小達到一定閾值後,又會對storefile進行split,劃分為兩個storefile。
由於對錶的更新是不斷追加的,合併時,需要訪問store中全部的storefile和memstore,將它們按row key進行合併,由於storefile和memstore都是經過排序的,並且storefile帶有內存中索引,合併的過程還是比較快的。
因為存儲文件不可修改,HBase是無法通過移除某個鍵/值來簡單的刪除數據,而是對刪除的數據做個刪除標記,表明該數據已被刪除,檢索過程中,刪除標記掩蓋該數據,客戶端讀取不到該數據。
隨着memstore中數據不斷刷寫到磁盤中,會產生越來越多的hfile小文件,HBase內部通過將多個文件合併成一個較大的文件解決這一小文件問題。
1. minor合併(minor compaction)
將多個小文件(通過參數配置決定是否滿足合併的條件)重寫為數量較少的大文件,減少存儲文件數量(多路歸併),因為hfile的每個文件都是經過歸類的,所以合併速度很快,主要受磁盤IO性能影響
2. major合併(major compaction)
將一個region中的一個列簇的若干個hfile重寫為一個新的hfile。而且major合併能掃描所有的鍵/值對,順序重寫全部數據,重寫過程中會略過做了刪除標記的數據(超過版本號限制、超過生存時間TTL、客戶端API移除等數據)
region管理
region分配
任何時刻,一個region只能分配給一個RS。
HMaster記錄了當前有哪些可用的RS。以及當前哪些region分配給了哪些RS,哪些region還沒有分配。當需要分配的新的region,並且有一個RS上有可用空間時,HMaster就給這個RS發送一個加載請求,把region分配給這個RS。RS得到請求後,就開始對此region提供服務。
region server上線
HMaster使用ZK來跟蹤RS狀態。當某個RS啟動時,會首先在ZK上的server目錄下建立代表自己的znode。由於HMaster訂閱了server目錄上的變更消息,當server目錄下的文件出現新增或刪除操作時,HMaster可以得到來自zookeeper的實時通知。因此一旦RS上線,HMaster能馬上得到消息。
region server下線
當RS下線時,它和ZK的會話斷開,ZK自動釋放代表這台server的文件上的獨佔鎖。HMaster就可以確定RS都無法繼續為它的region提供服務了(比如RS和ZK之間的網絡斷開了或者RS掛了),此時HMaster會刪除server目錄下代表這台RS的znode數據,並將這台RS的region分配給集群中還活着的RS
HMaster工作機制
HMaster上線
master啟動之後會做如下事情:
1. 從ZK上獲取唯一一個代表active master的鎖,用來阻止其它master成為active master
2. 掃描ZK上的server父節點,獲得當前可用的RS列表
3. 和每個RS通信,獲得當前已分配的region和RS的對應關係
4. 掃描.META.region的集合,得到當前還未分配的region,將它們放入待分配region列表
從上線過程可以看到,HMaster保存的信息全是可以從系統其它地方收集到或者計算出來的。
HMaster下線
由於HMaster只維護表和region的元數據,而不參與表數據IO的過程,HMaster下線僅導致所有元數據的修改被凍結(無法創建刪除表,無法修改表的schema,無法進行region的負載均衡,無法處理region上下線,無法進行region的合併,唯一例外的是region的split可以正常進行,因為只有region server參與),表的數據讀寫還可以正常進行。因此HMaster下線短時間內對整個HBase集群沒有影響。
HBASE容錯性
HMaster容錯配置
HA,當active master宕機時,通過ZK重新選擇一個新的active master。注意:
1. 無HMaster過程中,數據讀取仍照常進行
2. 無HMaster過程中,region切分、負載均衡等無法進行
RegionServer容錯
定時向ZK彙報心跳,如果一定時間內未出現心跳,比如RS宕機,HMaster將該RS上的region、預寫日誌重新分配到其他RS上
HBASE數據遷移和備份
1. distcp命令拷貝hdfs文件的方式
使用MapReduce實現文件分發,把文件和目錄的列表當做map任務的輸入,每個任務完成部分文件的拷貝和傳輸工作。在目標集群再使用bulkload的方式導入就實現了數據的遷移。
執行完distcp命令後,需要執行hbase hbck -repairHoles修復HBase表元數據。缺點在於需要停寫,不然會導致數據不一致,比較適合遷移歷史表(數據不會被修改的情況)
2. copytable的方式實現表的遷移和備份
以表級別進行遷移,其本質也是使用MapReduce的方式進行數據的同步,它是利用MapReduce去scan源表數據,然後把scan出來的數據寫到目標集群,從而實現數據的遷移和備份。
示例:./bin/hbase
org.apache.hadoop.hbase.mapreduce.CopyTable
-Dhbase.client.scanner.caching=300
-Dmapred.map.tasks.speculative.execution=false
-Dmapreduc.local.map.tasks.maximum=20
–peer.adr=zk_address:/hbase
hbase_table_name
這種方式需要通過scan數據,對於很大的表,如果這個表本身又讀寫比較頻繁的情況下,會對性能造成比較大的影響,並且效率比較低。
copytable常用參數說明(更多參數說明可參考hbase官方文檔)
startrow、stoprow:開始行、結束行
starttime:版本號最小值
endtime:版本號最大值,starttime和endtime必須同時制定
peer.adr:目標hbase集群地址,格式:hbase.zk.quorum:hbase.zk.client.port:zk.znode.parent
families:要同步的列族,多個列族用逗號分隔
3. replication的方式實現表的複製
類似MySQL binlog日誌的同步方式,HBase通過同步WAL日誌中所有變更來實現表的同步,異步同步。
需要在兩個集群數據一樣的情況下開啟複製,默認複製功能是關閉的,配置後需要重啟集群,並且如果主集群數據有出現誤修改,備集群的數據也會有問題。
4. Export/Import的方式實現表的遷移和備份
和copytable的方式類似,將HBase表的數據轉換成Sequence File並dump到hdfs,也涉及scan表數據。
和copytable不同的是,export不是將HBase的數據scan出來直接put到目標集群,而是先轉換成文件並同步到目標集群,再通過import的方式導到對應的表中。
示例:
在老集群上執行:./hbaseorg.apache.hadoop.hbase.mapreduce.Export test_tabNamehdfs://ip:port/test
在新集群上執行:./hbaseorg.apache.hadoop.hbase.mapreduce.Import test_tabName
hdfs://ip:port/test
這種方式要求需要在import前在新集群中將表建好。需要scan數據,會對HBase造成負載的影響,效率不高。
5. snapshot的方式實現表的遷移和備份
通過HBase快照的方式實現HBase數據的遷移和拷貝。
示例:
1. 在老集群首先要創建快照:
snapshot ‘tabName’, ‘snapshot_tabName’
2. ./bin/hbase
org.apache.hadoop.hbase.snapshot.ExportSnapshot
-snapshot snapshot_tabName-copy-from hdfs://src-hbase-dir/hbase
-copy-to hdfs://dst-hbase-dir/hbase
-mappers 30
-bandwidth 10
這種方式比較常用,效率高,也是最為推薦的數據遷移方式。
關注微信公眾號:大數據學習與分享,獲取更對技術乾貨


