《Java 8 in Action》Chapter 6:用流收集數據
- 2019 年 10 月 3 日
- 筆記
1. 收集器簡介
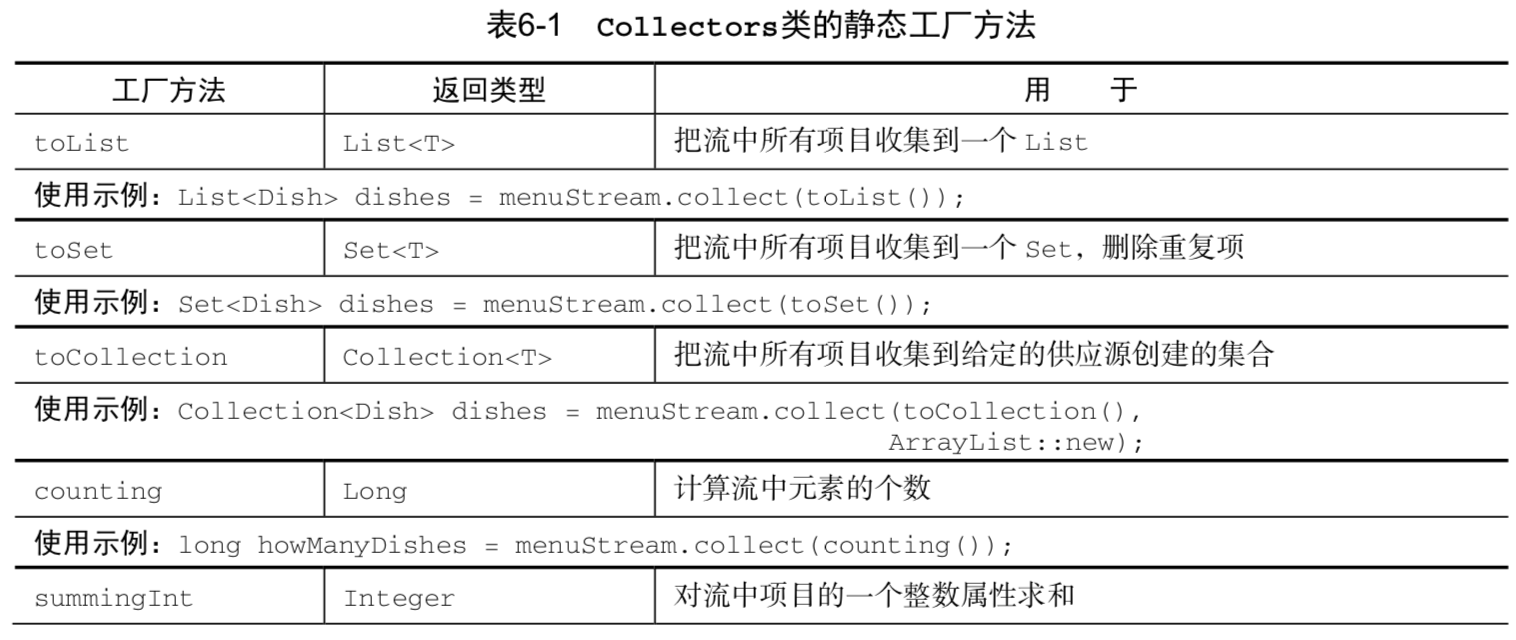
collect() 接收一個類型為 Collector 的參數,這個參數決定了如何把流中的元素聚合到其它數據結構中。Collectors 類包含了大量常用收集器的工廠方法,toList() 和 toSet() 就是其中最常見的兩個,除了它們還有很多收集器,用來對數據進行對複雜的轉換。
指令式代碼和函數式對比:
要是做多級分組,指令式和函數式之間的區別就會更加明顯:由於需要好多層嵌套循環和條件,指令式代碼很快就變得更難閱讀、更難維護、更難修改。相比之下,函數式版本只要再加上 一個收集器就可以輕鬆地增強
預定義收集器,也就是那些可以從Collectors類提供的工廠方法(例如groupingBy)創建的收集器。它們主要提供了三大功能:
- 將流元素歸約和匯總為一個值
- 元素分組
- 元素分區
2. 使用收集器
在需要將流項目重組成集合時,一般會使用收集器(Stream方法collect 的參數)。再寬泛一點來說,但凡要把流中所有的項目合併成一個結果時就可以用。這個結果可以是任何類型,可以複雜如代表一棵樹的多級映射,或是簡單如一個整數。
3. 收集器實例
3.1 流中最大值和最小值
Collectors.maxBy和 Collectors.minBy,來計算流中的最大或最小值。這兩個收集器接收一個Comparator參數來比較流中的元素。你可以創建一個Comparator來根據所含熱量對菜肴進行比較:
System.out.println("找出熱量最高的食物:"); Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))); collect.ifPresent(System.out::println); System.out.println("找出熱量最低的食物:"); Optional<Dish> collect1 = DataUtil.genMenu().stream().collect(Collectors.minBy(Comparator.comparingInt(Dish::getCalories))); collect1.ifPresent(System.out::println);3.2 匯總求和
Collectors類專門為匯總提供了一個工廠方法:Collectors.summingInt。它可接受一個把對象映射為求和所需int的函數,並返回一個收集器;該收集器在傳遞給普通的collect方法後即執行我們需要的匯總操作。舉個例子來說,你可以這樣求出菜單列表的總熱量:
Integer collect = DataUtil.genMenu().stream().collect(Collectors.summingInt(Dish::getCalories)); System.out.println("總熱量:" + collect); Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summingDouble(Double::doubleValue)); System.out.println("double和:" + collect1); Long collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summingLong(Long::longValue)); System.out.println("long和:" + collect2);3.3 匯總求平均值
Collectors.averagingInt,averagingLong和averagingDouble可以計算數值的平均數:
Double collect = DataUtil.genMenu().stream().collect(Collectors.averagingInt(Dish::getCalories)); System.out.println("平均熱量:" + collect); Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.averagingDouble(Double::doubleValue)); System.out.println("double 平均值:" + collect1); Double collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.averagingLong(Long::longValue)); System.out.println("long 平均值:" + collect2);3.4 匯總合集
你可能想要得到兩個或更多這樣的結果,而且你希望只需一次操作就可以完成。在這種情況下,你可以使用summarizingInt工廠方法返回的收集器。例如,通過一次summarizing操作你可以就數出菜單中元素的個數,並得到熱量總和、平均值、最大值和最小值:
IntSummaryStatistics collect = DataUtil.genMenu().stream().collect(Collectors.summarizingInt(Dish::getCalories)); System.out.println("int:" + collect); DoubleSummaryStatistics collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summarizingDouble(Double::doubleValue)); System.out.println("double:" + collect1); LongSummaryStatistics collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summarizingLong(Long::longValue)); System.out.println("long:" + collect2);3.5 連接字符串
joining工廠方法返回的收集器會把對流中每一個對象應用toString方法得到的所有字符串連接成一個字符串。
String collect = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining());請注意,joining在內部使用了StringBuilder來把生成的字符串逐個追加起來。幸好,joining工廠方法有一個重載版本可以接受元素之間的分界符,這樣你就可以得到一個都好分隔的名稱列表:
String collect1 = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining(","));4. 廣義的歸約匯總
所有收集器,都是一個可以用reducing工廠方法定義的歸約過程的特殊情況而已。Collectors.reducing工廠方法是所有這些特殊情況的一般化。
它需要三個參數:
- 第一個參數是歸約操作的起始值,也是流中沒有元素時的返回值,所以很顯然對於數值和而言0是一個合適的值。
- 第二個參數就是你在6.2.2節中使用的函數,將菜肴轉換成一個表示其所含熱量的int。
- 第三個參數是一個BinaryOperator,將兩個項目累積成一個同類型的值。這裡它就是對兩個int求和。
下面兩個是相同的操作:
Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))); Optional<Dish> mostCalorieDish = menu.stream().collect(reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));5. 分組
用Collectors.groupingBy工廠方法返回的收集器就可以輕鬆地完成任務:
Map<Dish.Type, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType));給groupingBy方法傳遞了一個Function(以方法引用的形式),它提取了流中每 一道Dish的Dish.Type。我們把這個Function叫作分類函數,因為它用來把流中的元素分成不同的組。分組操作的結果是一個Map,把分組函數返回的值作為映射的鍵,把流中所有具有這個分類值的項目的列表作為對應的映射值。
5.1 多級分組
要實現多級分組,我們可以使用一個由雙參數版本的Collectors.groupingBy工廠方法創建的收集器,它除了普通的分類函數之外,還可以接受collector類型的第二個參數。那麼要進行二級分組的話,我們可以把一個內層groupingBy傳遞給外層groupingBy,並定義一個為流中項目分類的二級標準:
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect( Collectors.groupingBy(Dish::getType, Collectors.groupingBy(dish -> { if (dish.getCalories() <= 400) { return CaloricLevel.DIET; } else if (dish.getCalories() <= 700) { return CaloricLevel.NORMAL; } else return CaloricLevel.FAT; })) );5.2 按子組收集數據
傳遞給第一個groupingBy的第二個收集器可以是任何類型,而不一定是另一個groupingBy。例如,要數一數菜單中每類菜有多少個,可以傳遞counting收集器作為groupingBy收集器的第二個參數:
Map<Dish.Type, Long> collect2 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType, Collectors.counting()));還要注意,普通的單參數groupingBy(f)(其中f是分類函數)實際上是groupingBy(f, toList())的簡便寫法。
把收集器返回的結果轉換為另一種類型,你可以使用 Collectors.collectingAndThen工廠方法返回的收集器,接受兩個參數:要轉換的收集器以及轉換函數,並返回另一個收集器。
Map<Dish.Type, Dish> collect3 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType, Collectors.collectingAndThen( Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)), Optional::get )));這個操作放在這裡是安全的,因為reducing收集器永遠都不會返回Optional.empty()。
常常和groupingBy聯合使用的另一個收集器是mapping方法生成的。這個方法接受兩個參數:一個函數對流中的元素做變換,另一個則將變換的結果對象收?起來。其目的是在累加之前對每個輸入元素應用一個映射函數,這樣就可以讓接受特定類型元素的收?器適應不同類型的對象。我們來看一個使用這個收集器的實際例子。比方說你想要知道,對於每種類型的Dish, 菜單中都有哪些CaloricLevel。
Map<Dish.Type, Set<CaloricLevel>> collect4 = DataUtil.genMenu().stream().collect(Collectors.groupingBy( Dish::getType, Collectors.mapping( dish -> { if (dish.getCalories() <= 400) { return CaloricLevel.DIET; } else if (dish.getCalories() <= 700) { return CaloricLevel.NORMAL; } else return CaloricLevel.FAT; }, Collectors.toSet() ) ));6. 分區
分區是分組的特殊情況:由一個謂詞(返回一個布爾值的函數)作為分類函數,它稱分類函數。分區函數返回一個布爾值,這意味着得到的分組Map的鍵類型是Boolean,於是它最多可以 分為兩組——true是一組,false是一組。例如,如果想要把菜按照素食和非素食分開:
Map<Boolean, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.partitioningBy(Dish::isVegetarian)); System.out.println(collect.get(true)); partitioningBy 工廠方法有一個重載版本,可以像下面這樣傳遞第二個收集器: Map<Boolean, Map<Dish.Type, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect(Collectors.partitioningBy( Dish::isVegetarian, Collectors.groupingBy(Dish::getType) ));分區看作分組一種特殊情況。
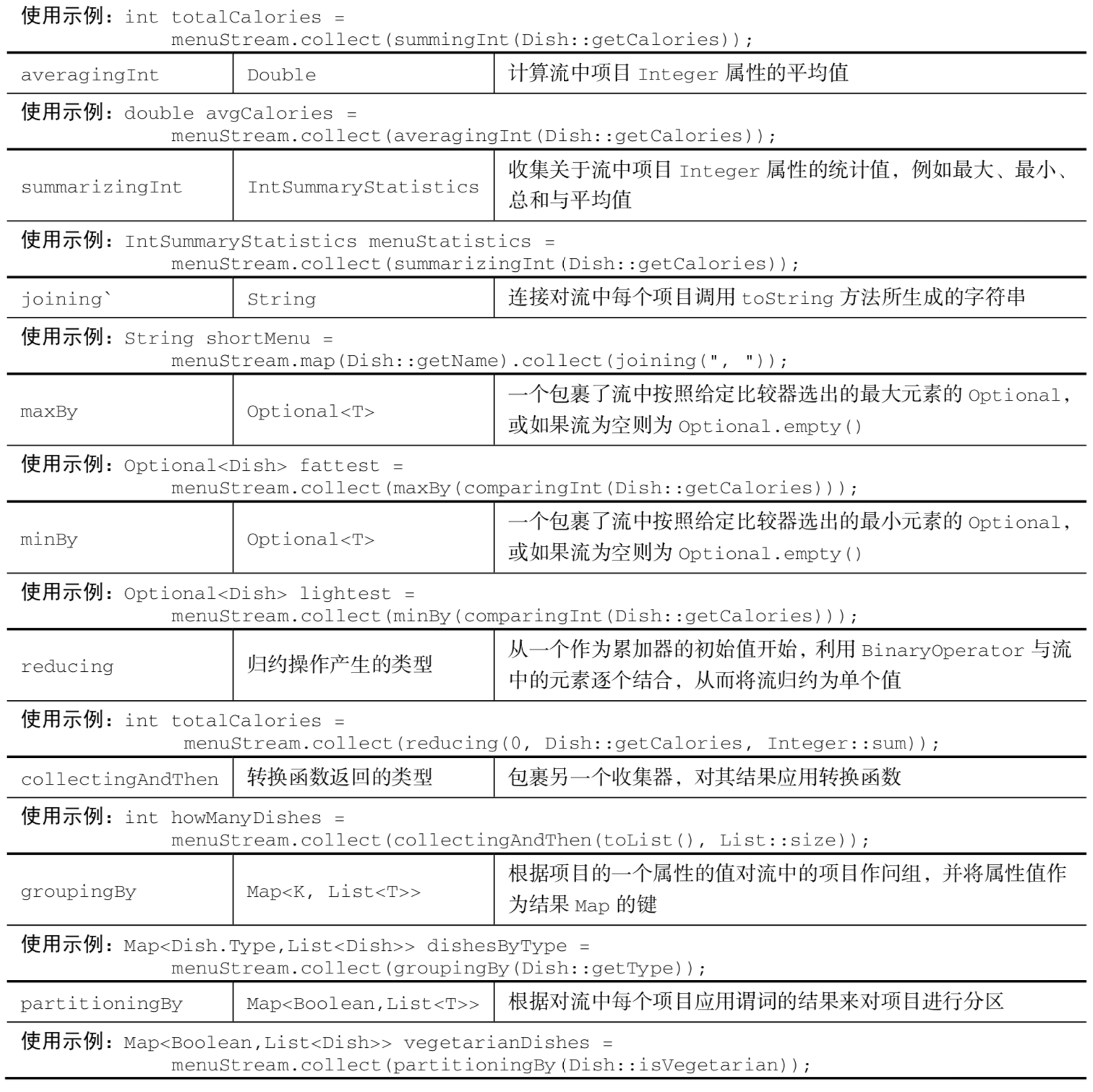
7. Collectors類的靜態工廠方法
8. 收集器接口
public interface Collector<T, A, R> { Supplier<A> supplier(); BiConsumer<A, T> accumulator(); Function<A, R> finisher(); BinaryOperator<A> combiner(); Set<Characteristics> characteristics(); }本列表適用以下定義:
- T是流中要收集的項目的泛型。
- A是累加器的類型,累加器是在收集過程中用於累積部分結果的對象。
- R是手機操作得到的對象(通常但並不一定是集合)的類型。
8.1 建立新的結果容器:supplier方法
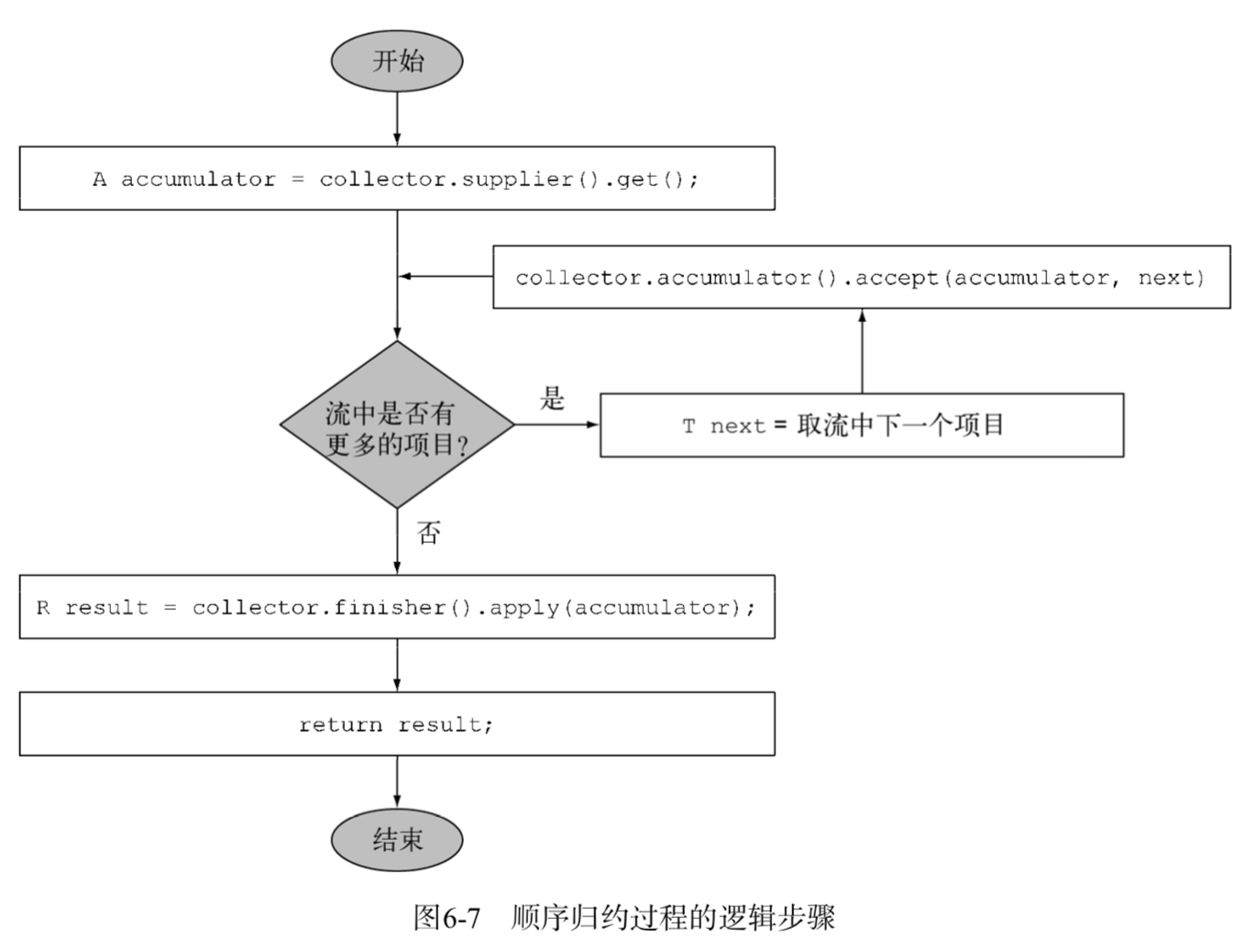
supplier方法必須返回一個結果為空的Supplier,也就是一個無參數函數,在調用時它會創建一個空的累加器實例,供數據收集過程使用。
8.2 將元素添加到結果容器:accumulator方法
accumulator方法會返回執行歸約操作的函數。當遍歷到流中第n個元素時,這個函數執行時會有兩個參數:保存歸約結果的累加器(已收集了流中的前n-1個項目),還有第n個元素本身。該函數將返回void,因為累加器是原位更新,即函數的執行改變了它的內部狀態以體現遍歷的元素的效果。
8.3 對結果容器應用最終轉換:finisher方法
在遍歷完流後,finisher方法必須返回在累積過程的最後要調用的一個函數,以便將累加器對象轉換為整個集合操作的最終結果。
順序歸約過程的邏輯步驟:
8.4 合併兩個結果容器:combiner方法
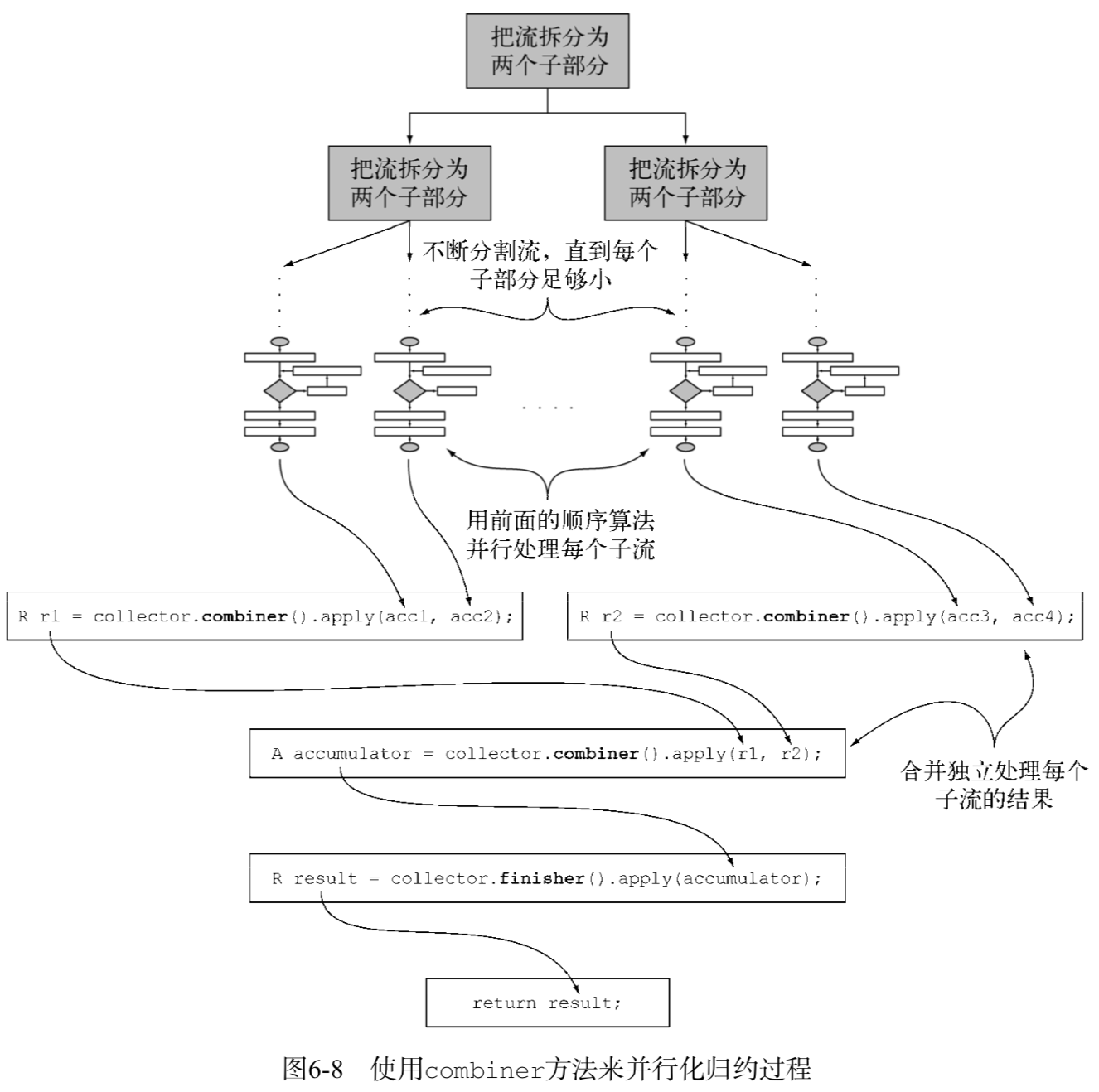
四個方法中的最後一個——combiner方法會返回一個供歸約操作使用的函數,它定義了對流的各個子部分進行並行處理時,各個子部分歸約所得的累加器要如何合併:
- 原始流會以遞歸方式拆分為子流,直到定義流是否需要進一步拆分的一個條件為非(如果分佈式工作單位太小,並行計算往往比順序計算要慢,而且要是生成的並行任務比處理器內核數多很多的話就毫無意義了)。
- 現在,所有的子流都可以並行處理,即對每個子流應用圖6-7所示的順序歸約算法。
- 最後,使用收集器combiner方法返回的函數,將所有的部分結果兩兩合併。這時會把原始流每次拆分時得到的子流對應的結果合併起來
8.5 characteristics方法
最後一個方法——characteristics會返回一個不可變的Characteristics集合,它定義了收集器的行為——尤其是關於流是否可以並行歸約,以及可以使用哪些優化的提示。
Characteristics是一個包含三個項目的枚舉。
- UNORDERED——歸約結果不受流中項目的遍歷和累積順序的影響。
- CONCURRENT——accumulator函數可以從多個線程同時調用,且該收集器可以並行歸約流。如果收集器沒有標為UNORDERED,那它僅在用於無序數據源時才可以並行歸約。
- IDENTITY_FINISH——這表明完成器方法返回的函數是一個恆等函數,可以跳過。這種情況下,累加器對象將會直接用作歸約過程的最終結果。這也意味着,將累加器A不加檢查地轉換為結果R是安全的。
9. 小結
- collect是一個終端操作,它接受的參數是將流中元素累積到匯總結果的各種方式(稱為收集器)。
- 預定義收集器包括將流元素歸約和匯總到一個值,例如計算最小值、最大值或平均值。這些收集器總結在表6-1中。
- 預定義收集器可以用groupingBy對流中元素進行分組,或用partitioningBy進行分區。
- 收集器可以高效地複合起來,進行多級分組、分區和歸約。
- 你可以實現Collector接口中定義的方法來開發你自己的收集器。
資源獲取
- 公眾號回復 : Java8 即可獲取《Java 8 in Action》中英文版!
Tips
- 歡迎收藏和轉發,感謝你的支持!(๑•̀ㅂ•́)و✧
- 歡迎關注我的公眾號:莊裡程序猿,讀書筆記教程資源第一時間獲得!

