Azure Data Factory(一)入門簡介
一,引言
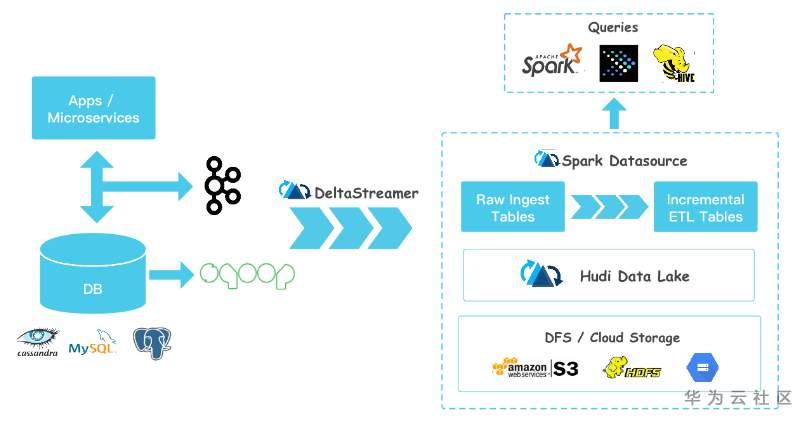
今天分享一個新的Azure 服務—–Azure Data Factory(Azure 數據工廠),怎麼理解,參考根據官方解釋—–數據工廠解釋:大數據需要可以啟用協調和操作過程以將這些巨大的原始數據存儲優化為可操作的業務見解的服務。 Azure 數據工廠是為這些複雜的混合提取-轉換-加載 (ETL)、提取-加載-轉換 (ELT) 和數據集成項目而構建的託管雲服務。
說簡單點,Azure Data Factory 可以創建和計劃數據驅動型工作,也就是 Pineline,從不同的數據源(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)中提取數據,進行加工處理,進行複雜計算後,將這些有價值的數據可以歸檔,存儲到不同的目標源(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)
二,正文
Azure Data Factory 中的Pipeline 通常執行以下三個步驟:
1,連接,收集:連接,收集是指在構建 pipeline 時需要有數據源,然後再將數據源中提取出來的數據進行加工處理,通過使用 Data Factory 中的 pipeline ,添加 「Activites」 操作,將數據從本地和雲的源數據存儲移到雲的集中數據存儲進行進一步的分析。
2,轉換和擴充:將DataSet 中收集到的數據源的數據,可以使用一些其他的服務,例如 DataB ,Machine Learning進行數據處理,轉化,可以將這些數據轉化成有價值的,可信的生產環境的數據
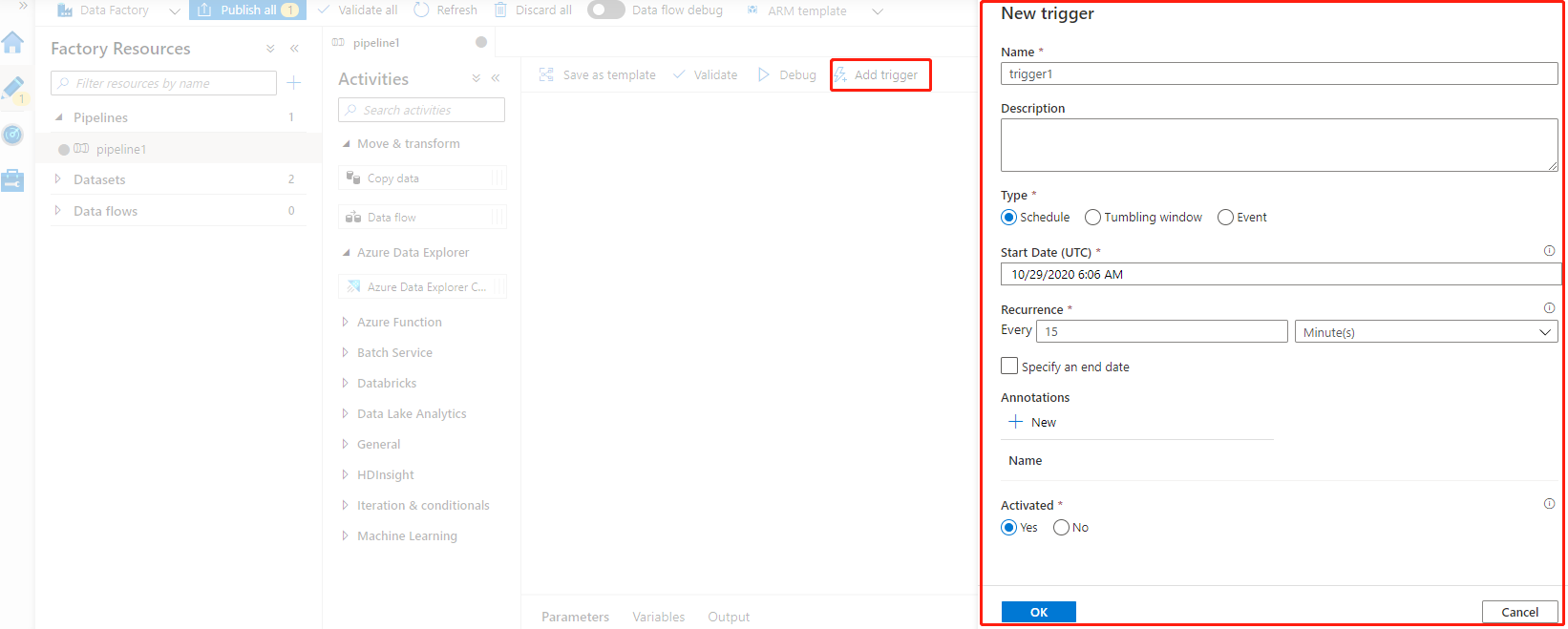
3,發佈:這裡的發佈,並不是指代碼的發佈,而是指手動觸發將轉化、處理好的數據傳送到目標源,同時可以設置Trgger ,定時執行發佈計劃。
Azure Data Factory 中一些關鍵組件:
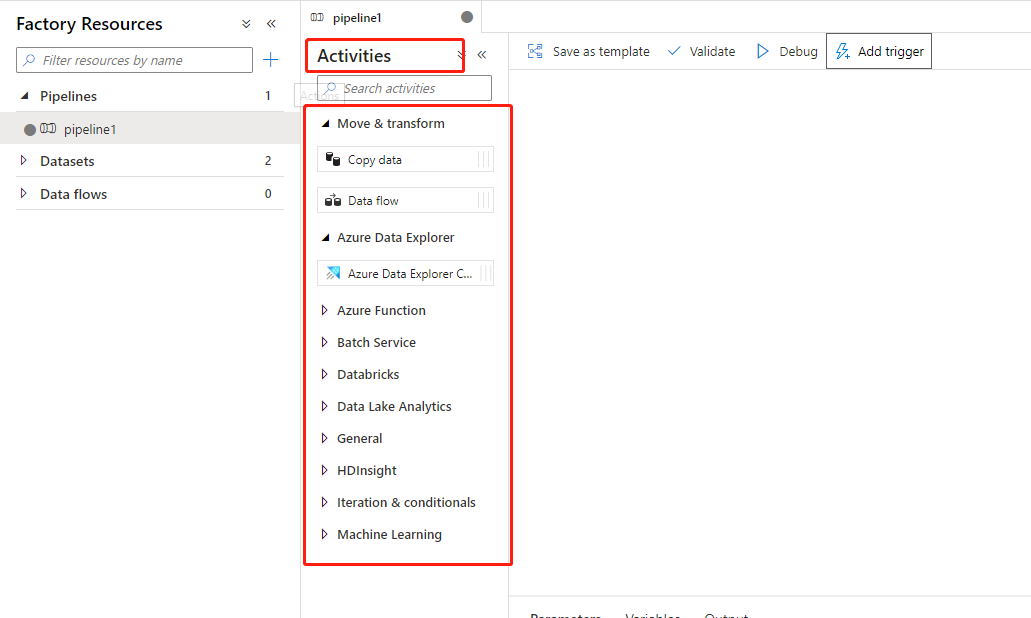
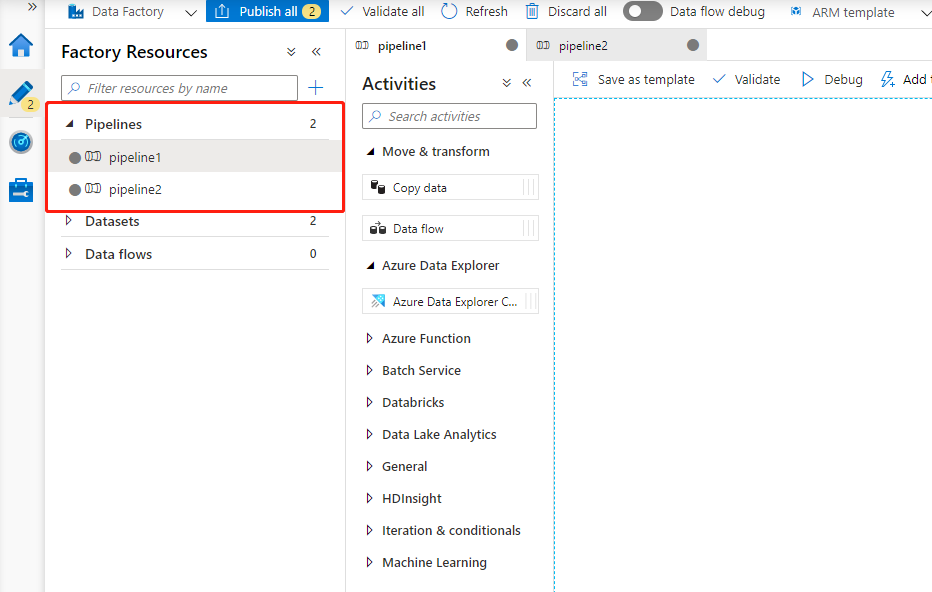
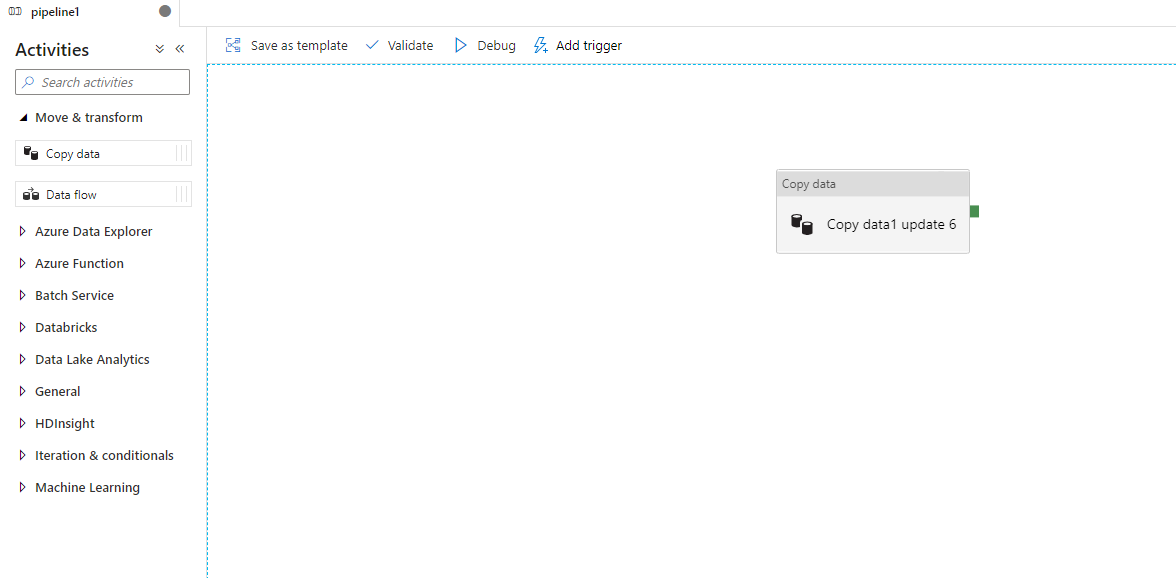
1,pipeline:這裡的 pipeline 要和Azure DevOps 中的 pipeline 概念上有些類似,它是指我們的Azure Data Factory 可以包含一個或者多個 pipeline 。pipeline是有多個Activites組成,來執行一項任務的。如下圖所示,這裡顯示多個pipeline。
2,Activities:一個pipeline 可以有多個 Activities,這些是對數據執行的一些動作,例如 複製數據,如下圖,當前 Pipeline 中包含了一個 Copy data
3,datasets(數據集):簡單理解,就是包含了 數據源、目標源。數據集可識別不同數據存儲(如表、文件、文件夾和文檔)中的數據,使用零個或多個 “datset” 作為輸入,一個或多個 “dataset” 作為輸出。
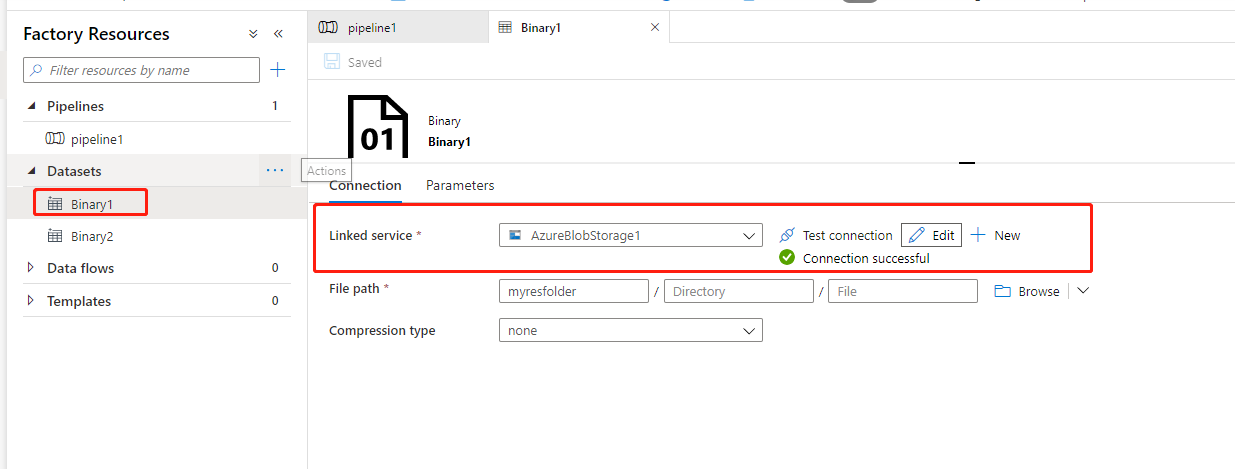
4,linked services:鏈接服務就好比鏈接字符串,密鑰等信息,用於定義Azure Data Factory 鏈接到外部資源時所需喲啊的連接信息,如下圖鏈接服務指鏈接到Azure Storage Account 所需要的連接字符串。
同時,點擊 「Test connection」 進行測試,是否可以正常連接。
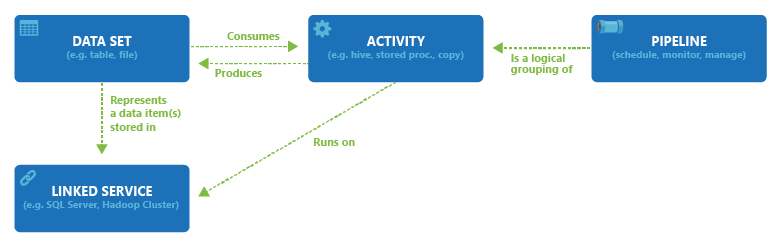
Data Factory 中 Data Set,Activity,Linked Service,Pipeline 直接的關係
Azure Data Factory不存儲任何數據。我們可以使用它用於創建數據驅動型工作流,在支持的數據存儲之間協調數據的移動(創建一個包含 pipiline 的 Data Factory,將數據從 Blob1 存儲移動到 Blob2 存儲)。 它還可以用於在其他區域或本地環境中通過計算服務來處理數據。 它還允許使用編程方式及 UI 機制來監視和管理工作流。
三,結尾
今天只是對 Azure Data Factory 有一個初步的認識,以及可以用來做什麼,下一篇文章實際創建Aure Data Factory,通過創建 pipeline 配置將 storage1 的數據複製到 storage2 中。
參考資料:Azure Data Factory(英文),Azure Data Factory(中文)
作者:Allen
版權:轉載請在文章明顯位置註明作者及出處。如發現錯誤,歡迎批評指正。