想買保時捷的運維李先生學Java性能之 垃圾收集算法
- 2020 年 10 月 29 日
- 筆記
- 李先生以運維角度學Java性能
前言
從原來只知道-Xms、-Xmx是設置內存的,到現在稍微理解了一些堆內存等Java虛擬機的一些知識。明白了技術這一個東西還是得要有輸入才能實踐,原理與實踐要相輔相成,後續把JVM的監控好好總結一下。以前做了很多的關於JVM方面的監控,僅僅只是做了,但是不知道是什麼意思,不知道怎麼分析。
垃圾收集算法

一、標記(清除算法)
最基礎的收集算法是”標記-清除”(Mark-Sweep)算法,算法分為”標記”和”清除”兩個階段。首先標記出所有需要回收的對象,在標記完成後統一回收所有被標記的對象。
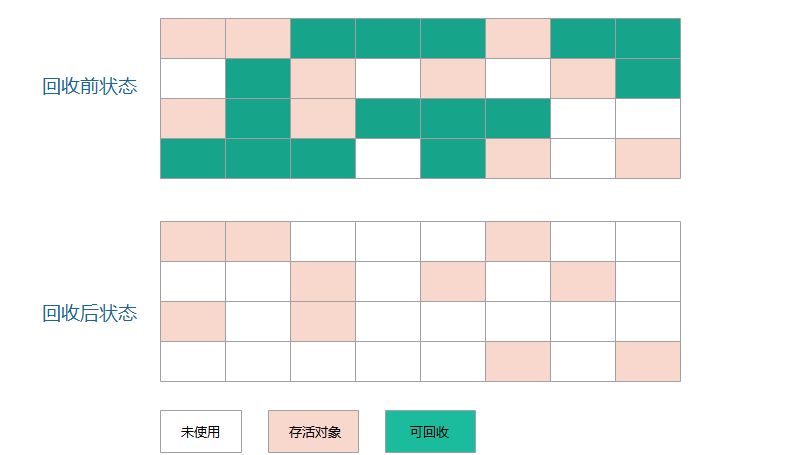
不足點:
1)效率問題,標記和清除兩個過程的效率都不高。
2)空間問題,標記清除後會產生大量不連續的內存碎片,空間碎片太多會導致以後再程序運行過程中需要分配較大的對象時,無法找到足夠的連續內存而不得不提前觸發另一次的垃圾收集動作。
2、複製算法
將可用內存按容量劃分為相等的兩塊,每次只使用其中的一塊。當這一塊的內存用完了,就將還存活着的對象複製到另一塊上面,然後再把已使用過的內存空間一次清理掉。這樣使得每次都是對整個半區進行內存回收,內存分配時也就不用考慮內存碎片等複雜情況,只要移動堆指針,按順序分配即可,實現簡單,運行高效。
不足:將內存縮小為了原來的一半,成本太高。

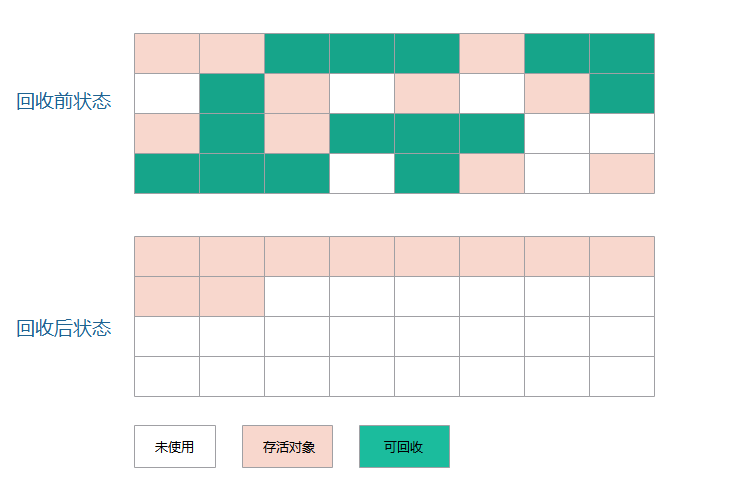
3、複製收集
複製收集算法在對象存活率較高時就要進行較多的複製操作,效率將會變低。更關鍵的是,不過不想浪費50%的空間,就需要有額外的空間進行擔保分配,以應對被使用的內存中所有對象都100%存活的極端情況,所以在老年代一般不能直接選用這種算法。
根據老年代的特點,提出了「標記-整理」(Mark-Compact)算法,標記過程仍然與「標記-清除」算法一樣,但後續步驟不是直接對可回收對象進行清理,而是所讓所有存活的對象都向一端移動,然後直接清理掉端邊界以外的內存。
4、分代回收
當前商業虛擬機的垃圾收集都採用「分代收集」(Generational Collection)算法,這種算法並沒有什麼新的思想,只是根據對象存活的周期將內存劃分為幾塊。一般把Java堆劃分為新生代和老年代,這樣可以根據各個年代的特點採用最適當的收集算法。
1)在新生代中,每次收集時都發現有大量對象死去,只有少量存活,就可以選用複製算法,只需要付出少量存活對象的複製成本就可以完成收集。
2)老年代中因為對象存活率高、沒有額外的空間進行擔保,就必須使用「標記-清理」或「標記-整理」算法來進行回收。

