MYSQL 那些事
1.一條update語句
1.先通過引擎找到對應的行數據,並加鎖2.對行數據進行修改並調用引擎接口修改這條數據,然後釋放鎖(此時並沒有把數據在磁盤上做出修改)3.redo log在內存中生成這條update的日誌,通過innodb_flush_log_trx_commit 參數判斷是否flush(持久化到磁盤),並告知mysql執行器完成操作4.執行器生成binlog並持久化到磁盤5.執行器調用引擎提交事務接口,redo log狀態變為commit狀態完成整個更新操作。2.redo log
redo log buffer:物理上是Mysql進程內存FSPage cache:寫入磁盤但沒有持久化,物理上是在文件系統page cache中hard disk 持久化到磁盤3.刷臟頁
Mysql在記錄redo log的時候會先將數據寫入到內存中,然後通過flush將內存中的數據寫入磁盤中。在此期間會產生臟數據頁導致內存和磁盤的數據不一致。
這時候mysql就需要刷臟數據頁。即是第一點的第六小點的動作:使用一個後台線程智能地刷新這些變更到數據文件
1.當記錄redo log的內存滿了,會停止寫入redo log操作,然後進行刷臟頁工作2.寫入日誌太多,發現分配的內存不夠,這時候需要淘汰一部分數據頁,坐刷臟頁工作3.mysql空閑時會進行刷臟頁工作
需要注意的是:
在flush過程中如果存在讀入的數據頁沒有內存的時候,需要到緩衝池中申請數據頁。當數據頁不足首先將最久不使用的數據從內存中淘汰,如果是臟數據頁還得先進行刷盤才能復用。
4. checkpoint (跟第二點的刷臟頁對應)
1.縮短數據庫的恢復時間;
2.緩衝池不夠用時,將臟頁刷新到磁盤;
3.重做日誌不可用時,刷新臟頁。
-
當數據庫發生宕機時,數據庫不需要重做所有的日誌,因為Checkpoint之前的頁都已經刷新回磁盤。數據庫只需對Checkpoint後的重做日誌進行恢復,這樣就大大縮短了恢復的時間。
-
當緩衝池不夠用時,根據LRU算法會溢出最近最少使用的頁,若此頁為臟頁,那麼需要強制執行Checkpoint,將臟頁也就是頁的新版本刷回磁盤。
-
寫入日誌太多,發現分配的內存不夠,這時候需要停止redo log寫入然後淘汰一部分數據頁,做刷臟頁操作,然後移動checkpoint 位置
checkpoint 分為兩類:
- Sharp Checkpoint
Sharp Checkpoint 發生在數據庫關閉時將所有的臟頁都刷新回磁盤,這是默認的工作方式,即參數innodb_fast_shutdown=1
但是若數據庫在運行時也使用Sharp Checkpoint,那麼數據庫的可用性就會受到很大的影響。故在InnoDB存儲引擎內部使用Fuzzy Checkpoint進行頁的刷新,即只刷新一部分臟頁,而不是刷新所有的臟頁回磁盤。
- Fuzzy Checkpoint
1、Master Thread Checkpoint
以每秒或每十秒的速度從緩衝池的臟頁列表中刷新一定比例的頁回磁盤,這個過程是異步的,此時InnoDB存儲引擎可以進行其他的操作,用戶查詢線程不會阻塞。
2、FLUSH_LRU_LIST Checkpoint
因為InnoDB存儲引擎需要保證LRU列表中需要有差不多100個空閑頁可供使用。在InnoDB1.1.x版本之前,需要檢查LRU列表中是否有足夠的可用空間操作發生在用戶查詢線程中,顯然這會阻塞用戶的查詢操作。倘若沒有100個可用空閑頁,那麼InnoDB存儲引擎會將LRU列表尾端的頁移除。如果這些頁中有臟頁,那麼需要進行Checkpoint,而這些頁是來自LRU列表的,因此稱為FLUSH_LRU_LIST Checkpoint。
而從MySQL 5.6版本,也就是InnoDB1.2.x版本開始,這個檢查被放在了一個單獨的Page Cleaner線程中進行,並且用戶可以通過參數innodb_lru_scan_depth控制LRU列表中可用頁的數量,該值默認為1024,如:
+———————–+——-+
| Variable_name | Value |
+———————–+——-+
| innodb_lru_scan_depth | 1024 |
+———————–+——-+
Fuzzy Checkpoint生命周期如下:Innodb每次取最老的modified page(last checkpoint)對應的LSN,再將此臟頁的LSN作為Checkpoint點記錄到日誌文件,意思就是「此LSN之前的LSN對應的日誌和數據都已經flush到redo log。
當mysql crash的時候,Innodb掃描redo log,從last checkpoint開始apply redo log到磁盤,直到last checkpoint對應的LSN等於Log flushed up to對應的LSN,則恢復完成
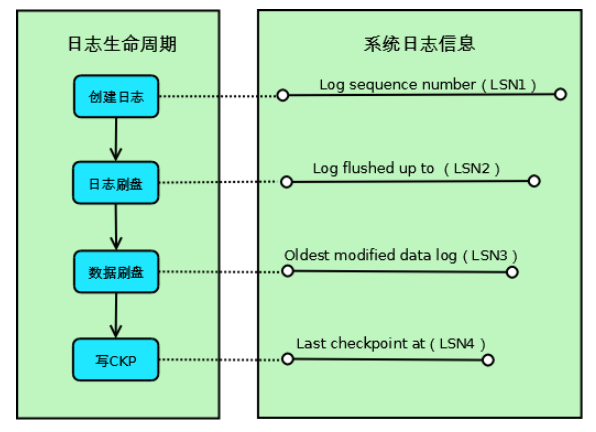
-
Log sequence number(LSN1):當前系統LSN最大值,新的事務日誌LSN將在此基礎上生成(LSN1+新日誌的大小);
-
Log flushed up to(LSN2):當前已經寫入日誌文件的LSN;
-
Oldest modified data log(LSN3):當前最舊的臟頁數據對應的LSN,寫Checkpoint的時候直接將此LSN寫入到日誌文件;
-
Last checkpoint at(LSN4):當前已經寫入Checkpoint的LSN;
如上圖所示,Innodb的一條事務日誌共經歷4個階段:
-
創建階段:事務創建一條日誌;
-
日誌刷盤:日誌寫入到磁盤上的日誌文件;
-
數據刷盤:日誌對應的臟頁數據寫入到磁盤上的數據文件;
-
寫CKP:日誌被當作Checkpoint寫入日誌文件
3、Async/Sync Flush Checkpoint
指的是重做日誌文件不可用的情況,這時需要強制將一些頁刷新回磁盤,而此時臟頁是從臟頁列表中選取的。若將已經寫入到重做日誌的LSN記為redo_lsn,將已經刷新回磁盤最新頁的LSN記為checkpoint_lsn,則可定義:
checkpoint_age = redo_lsn – checkpoint_lsn
再定義以下的變量:
async_water_mark = 75% * total_redo_log_file_size
sync_water_mark = 90% * total_redo_log_file_size
若每個重做日誌文件的大小為1GB,並且定義了兩個重做日誌文件,則重做日誌文件的總大小為2GB。那麼async_water_mark=1.5GB,sync_water_mark=1.8GB。則:
當checkpoint_age<async_water_mark時,不需要刷新任何臟頁到磁盤;
當async_water_mark<checkpoint_age<sync_water_mark時觸發Async Flush,從Flush列表中刷新足夠的臟頁回磁盤,使得刷新後滿足checkpoint_age<async_water_mark;
checkpoint_age>sync_water_mark這種情況一般很少發生,除非設置的重做日誌文件太小,並且在進行類似LOAD DATA的BULK INSERT操作。此時觸發Sync Flush操作,從Flush列表中刷新足夠的臟頁回磁盤,使得刷新後滿足checkpoint_age<async_water_mark
可見,Async/Sync Flush Checkpoint是為了保證重做日誌的循環使用的可用性。在InnoDB 1.2.x版本之前,Async Flush Checkpoint會阻塞發現問題的用戶查詢線程,而Sync Flush Checkpoint會阻塞所有的用戶查詢線程,並且等待臟頁刷新完成。從InnoDB 1.2.x版本開始——也就是MySQL 5.6版本,這部分的刷新操作同樣放入到了單獨的Page Cleaner Thread中,故不會阻塞用戶查詢線程
5.WAL
WAL機制(Write-Ahead-Logging),主要講了數據在操作的時候先進行寫日誌,然後再將數據寫入磁盤的過程
6.binlog
事務提交時,執行器將binlog cache完整事務寫入binlog中,並清空binlog cache。
整個寫入過程分為兩步 write和fsync
write:指把日誌寫入到文件系統page cache,並沒有寫入磁盤中,速度快fsync:將數據持久化到磁盤,該過程佔用磁盤IOPS。7.事務兩階段提交
1.Storage Engine(InnoDB) transaction prepare階段:存儲引擎的準備階段,寫redo-buffer然後根據參數羅盤redo log
2.Binary log日誌提交:寫binlog並落盤.
3.Storage Engine(InnoDB)內部提交把事務狀態標記為已提交
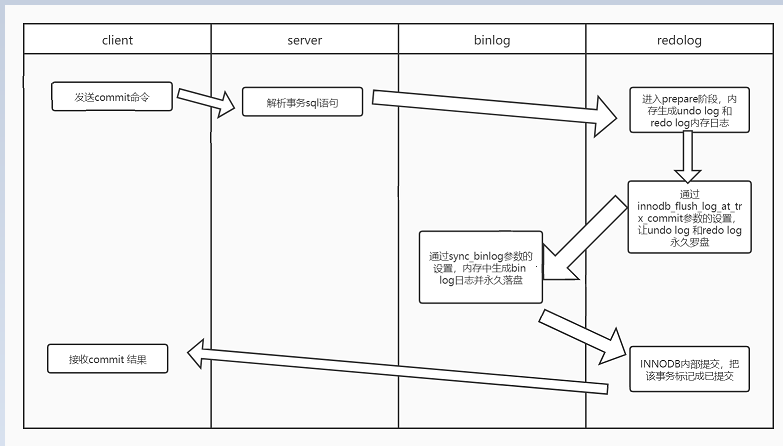
8.Crash recovery
如果數據庫異常後宕機重啟後會通過Crash recovery來恢復
sync_binlog=1 和 innoDB_flush_log_at_trx_commit = 1 稱之為雙1
雙1模式可以保證提交後的事務不會丟失,即crash-safe。
在做Crash recovery時:分為以下3種情況
- binlog有記錄,redolog狀態commit:正常完成的事務,不需要恢復;
- binlog有記錄,redolog狀態prepare:在binlog寫完提交事務之前的crash,恢復操作:提交事務。(因為之前沒有提交)
- binlog無記錄,redolog狀態prepare:在binlog寫完之前的crash,恢復操作:回滾事務(因為crash時並沒有成功寫入數據庫)
9.組提交
mysql 5.7開始默認開啟組提交。
1. 要保證順序必須是提交加入到隊列的順序(binlog_order_commits保證)。
2. 如果有新的事務提交,此時隊列為空,則可以加入到FLUSH隊列中。不過,因為此時FLUSH臨界區正在被佔用,所以新事務組必須要等待。
3. 給每個事務分配sequence_number,如果是第一個事務,則將這個組的last_committed設置為sequence_number-1.
4. 將帶着last_committed與sequence_number的GTID事件FLUSH到Binlog文件中。
5. 將當前事務所產生的Binlog內容FLUSH到Binlog文件中。
組提交之redo log
多個同時處於prepare階段的事務生成各自的redo log 會一起刷盤。假設2WTPS,並不需要4W次刷盤。也會在binlog中生成相同的last_commited(表示事務提交的時候,上次事務提交的編號).這些事務稱之為1個事務組。
其實每一個組的last_committed值,都是上一個組中事務的sequence_number最大值,也是本組中事務sequence_number最小值減1。同時這兩個值的有效作用域都在文件內,只要換一個文件(flush binary logs),這兩個值就都會從0開始計數。上述的last_committed和sequence_number代表的就是所謂的LOGICAL_CLOCK
組提交之binlog
為了增加一組事務中的事務數量,提高刷盤收益,MySQL使用兩個參數控制獲取隊列事務組的時機:
binlog_group_commit_sync_delay=N:在等待N μs後,開始事務刷盤(圖中Sync binlog)
binlog_group_commit_sync_no_delay_count=N:如果隊列中的事務數達到N個,就忽視binlog_group_commit_sync_delay的設置,直接開始刷盤(圖中Sync binlog)
組提交可以有效減低iops。 儘管上面兩個參數都關閉,也會開啟組提交。因為redo log組提交不由這兩個參數控制。
10. 並行複製
MySQL 5.7的並行複製基於一個前提,即所有已經處於prepare階段的事務,都是可以並行提交的。這些當然也可以在從庫中並行提交,因為處理這個階段的事務,都是沒有衝突的,該獲取的資源都已經獲取了。反過來說,如果有衝突,則後來的會等已經獲取資源的事務完成之後才能繼續,故而不會進入prepare階段。
一個組提交(group commit)的事務都是可以並行回放,因為這些事務都已進入到事務的prepare階段,則說明事務之間沒有任何衝突(否則就不可能提交)。
- binlog_order_commits會影響提交行為。如果設置為ON,那麼此時提交就變為串行操作了,就以隊列的順序為提交順序。而這也是LOGICAL_CLOCK並行複製的基礎。因為order commit使得所有的事務分了組,並且有了序列號,從庫拿到這些信息之後,就可以根據序號放心大膽地做分發了。
- slave_parallel_workers 從庫並行複製得線程數
- slave_parallel_type: logical_clock 表示以事務組提交的方式並行複製。database 表示以不同database的方式並行複製


