必須掌握的分佈式文件存儲系統—HDFS
HDFS(Hadoop Distributed File System)分佈式文件存儲系統,主要為各類分佈式計算框架如Spark、MapReduce等提供海量數據存儲服務,同時HBase、Hive底層存儲也依賴於HDFS。HDFS提供一個統一的抽象目錄樹,客戶端可通過路徑來訪問文件,如hdfs://namenode:port/dir-a/a.data。HDFS集群分為兩大角色:Namenode、Datanode(非HA模式會存在Secondary Namenode)
Namenode
Namenode是HDFS集群主節點,負責管理整個文件系統的元數據,所有的讀寫請求都要經過Namenode。
元數據管理
Namenode對元數據的管理採用了三種形式:
1) 內存元數據:基於內存存儲元數據,元數據比較完整
2) fsimage文件:磁盤元數據鏡像文件,在NameNode工作目錄中,它不包含block所在的Datanode 信息
3) edits文件:數據操作日誌文件,用於銜接內存元數據和fsimage之間的操作日誌,可通過日誌運算出元數據
fsimage + edits = 內存元數據
注意:當客戶端對hdfs中的文件進行新增或修改時,操作記錄首先被記入edit日誌文件,當客戶端操作成功後,相應的元數據會更新到內存元數據中
|
可以通過hdfs的一個工具來查看edits中的信息 bin/hdfs oev -i edits -o edits.xml 查看fsimage bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml |
元數據的checkpoint(非HA模式)
Secondary Namenode每隔一段時間會檢查Namenode上的fsimage和edits文件是否需要合併,如觸發設置的條件就開始下載最新的fsimage和所有的edits文件到本地,並加載到內存中進行合併,然後將合併之後獲得的新的fsimage上傳到Namenode。checkpoint操作的觸發條件主要配置參數:
|
dfs.namenode.checkpoint.check.period=60 #檢查觸發條件是否滿足的頻率,單位秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} #以上兩個參數做checkpoint操作時,secondary namenode的本地工作目錄,主要處理fsimage和edits文件的 dfs.namenode.checkpoint.max-retries=3 #最大重試次數 dfs.namenode.checkpoint.period=3600 #兩次checkpoint之間的時間間隔3600秒 dfs.namenode.checkpoint.txns=1000000 #兩次checkpoint之間最大的操作記錄 |
checkpoint作用
1. 加快Namenode啟動Namenode啟動時,會合併磁盤上的fsimage文件和edits文件,得到完整的元數據信息,但如果fsimage和edits文件非常大,這個合併過程就會非常慢,導致HDFS長時間處於安全模式中而無法正常提供服務。SecondaryNamenode的checkpoint機制可以緩解這一問題
2. 數據恢復Namenode和SecondaryNamenode的工作目錄存儲結構完全相同,當Namenode故障退出需要重新恢復時,可以從SecondaryNamenode的工作目錄中將fsimage拷貝到Namenode的工作目錄,以恢復Namenode的元數據。但是SecondaryNamenode最後一次合併之後的更新操作的元數據將會丟失,最好Namenode元數據的文件夾放在多個磁盤上面進行冗餘,降低數據丟失的可能性。
注意事項:
1. SecondaryNamenode只有在第一次進行元數據合併時需要從Namenode下載fsimage到本地。SecondaryNamenode在第一次元數據合併完成並上傳到Namenode後,所持有的fsimage已是最新的fsimage,無需再從Namenode處獲取,而只需要獲取edits文件即可。
2. SecondaryNamenode從Namenode上將要合併的edits和fsimage拷貝到自己當前服務器上,然後將fsimage和edits反序列化到SecondaryNamenode的內存中,進行計算合併。因此一般需要把Namenode和SecondaryNamenode分別部署到不同的機器上面,且SecondaryNamenode服務器配置要求一般不低於Namenode。
3. SecondaryNamenode不是充當Namenode的「備服務器」,它的主要作用是進行元數據的checkpoint
Datanode
Datanode作為HDFS集群從節點,負責存儲管理用戶的文件塊數據,並定期向Namenode彙報自身所持有的block信息(這點很重要,因為,當集群中發生某些block副本失效時,集群如何恢復block初始副本數量的問題)。
關於Datanode兩個重要的參數:
1. 通過心跳信息上報參數
|
<property> <name>dfs.blockreport.intervalMsec</name> <value>3600000</value> <description>Determines block reporting interval in milliseconds.</description> </property> |
2. Datanode掉線判斷時限參數
Datanode進程死亡或者網絡故障造成Datanode無法與Namenode通信時,Namenode不會立即把該Datanode判定為死亡,要經過一段時間,這段時間稱作超時時長。HDFS默認的超時時長為10分鐘30秒。如果定義超時時間為timeout,則超時時長的計算公式為:
timeout = 2 * heartbeat.recheck.interval(默認5分鐘) + 10 * dfs.heartbeat.interval(默認3秒)。
|
<property> <name>heartbeat.recheck.interval</name> # 單位毫秒 <value>2000</value> </property> <property> <name>dfs.heartbeat.interval</name> # 單位秒 <value>1</value> </property> |
HDFS讀寫數據流程
了解了Namenode和Datanode的作用後,就很容易理解HDFS讀寫數據流程,這個也是面試中經常問的問題。
HDFS寫數據流程

注意:
1.文件block塊切分和上傳是在客戶端進行的操作
2.Datanode之間本身是建立了一個RPC通信建立pipeline
3.客戶端先從磁盤讀取數據放到一個本地內存緩存,開始往Datanode1上傳第一個block,以packet為單位,Datanode1收到一個packet就會傳給Datanode2,Datanode2傳給Datanode3;Datanode1每傳一個packet會放入一個應答隊列等待應答
4.當一個block傳輸完成之後,客戶端會通知Namenode存儲塊完畢,Namenode將元數據同步到內存中
5. Datanode之間pipeline傳輸文件時,一般按照就近可用原則
a) 首先就近挑選一台機器
b) 優先選擇另一個機架上的Datanode
c) 在本機架上再隨機挑選一台
HDFS讀數據流程
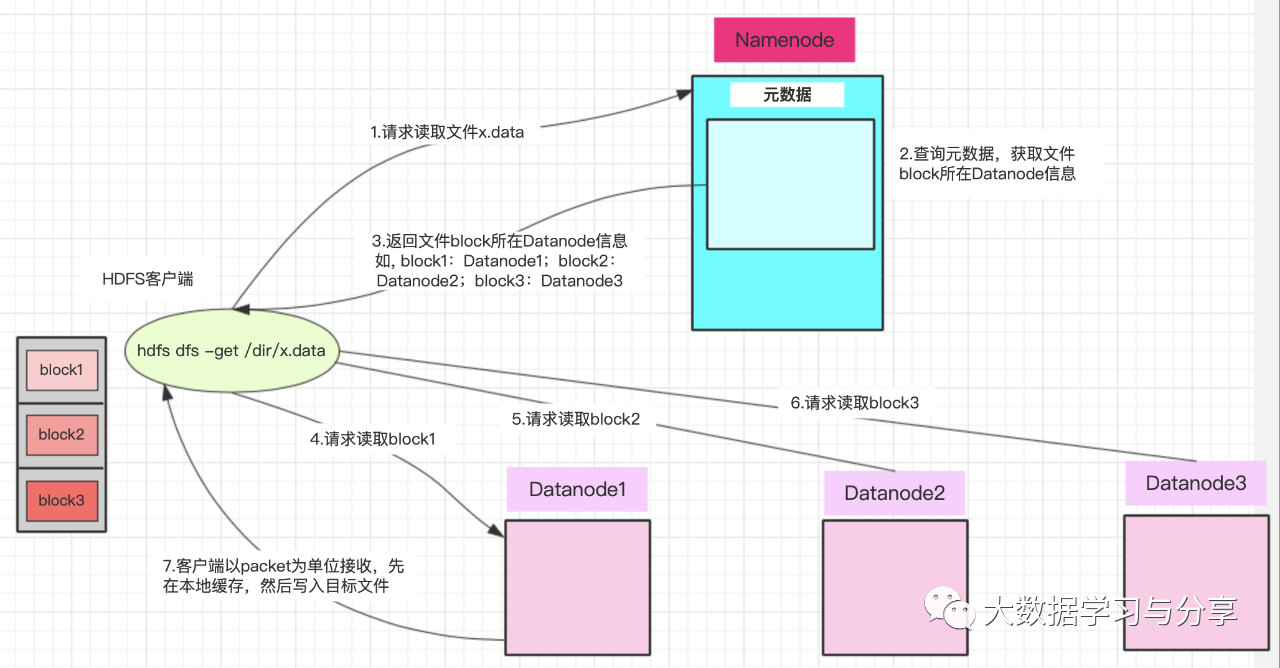
注意:
1. Datanode發送數據,是從磁盤裏面讀取數據放入流,以packet為單位來做校驗
2. 客戶端以packet為單位接收,先在本地緩存,然後寫入目標文件
客戶端將要讀取的文件路徑發送給namenode,namenode獲取文件的元信息(主要是block的存放位置信息)返回給客戶端,客戶端根據返回的信息找到相應datanode逐個獲取文件的block並在客戶端本地進行數據追加合併從而獲得整個文件
HDFS HA機制
HA:高可用,通過雙Namenode消除單點故障。
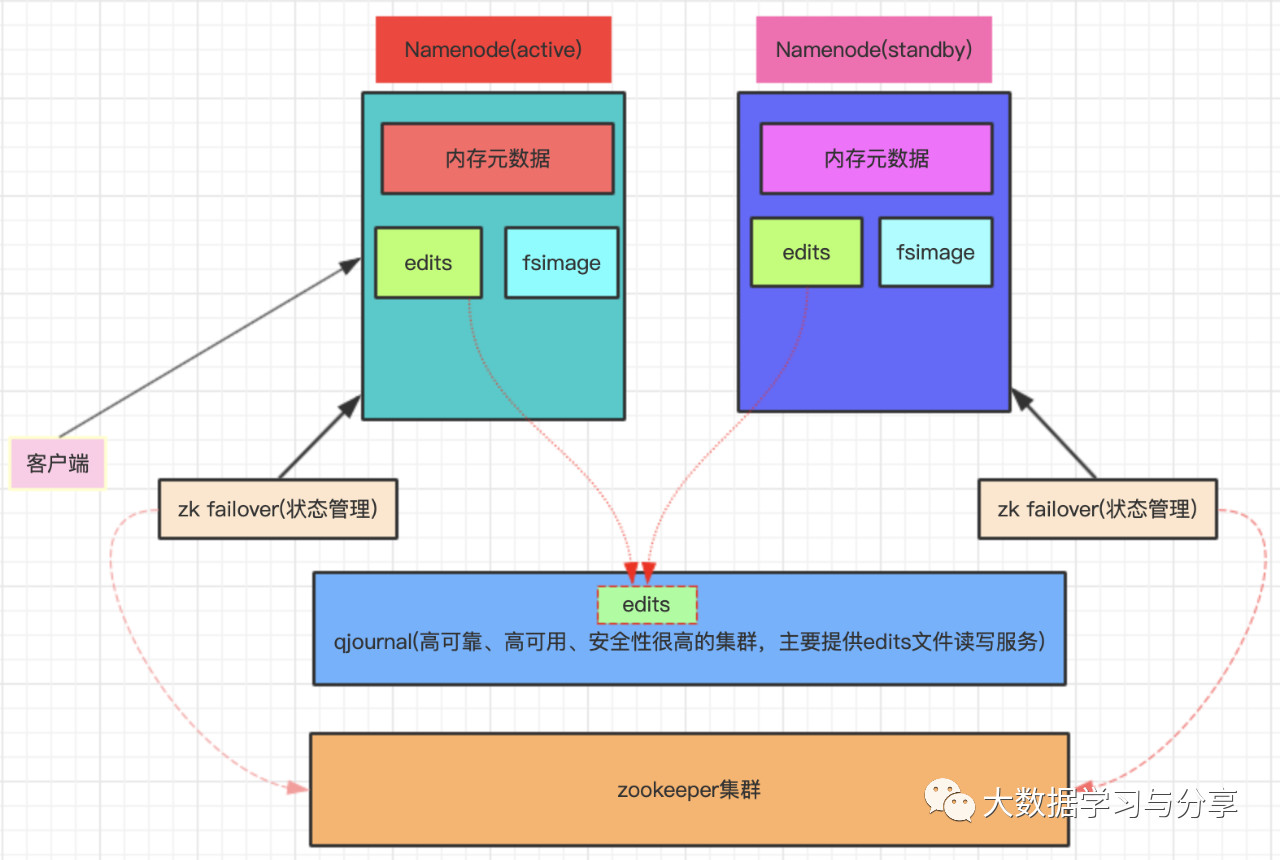
雙Namenode協調工作的要點:
1. 元數據管理方式需要改變
a) 內存中各自保存一份元數據
b) edits日誌只能有一份,只有active狀態的Namenode節點可以做寫操作
c) 兩個Namenode都可以讀取edits
d) 共享的edits放在一個共享存儲中管理(qjournal和NFS兩個主流實現,圖中以放在一個共享存儲中管理(qjournal和為例)
2. 需要一個狀態管理功能模塊
a) 實現了一個zk failover,常駐在每一個Namenode所在的節點
b) 每一個zk failover負責監控自己所在Namenode節點,利用zk進行狀態標識,當需要進行狀態切換時,由zk failover來負責切換,切換時需要防止brain split現象的發生
關注微信公眾號:大數據學習與分享,獲取更對技術乾貨


