BERT模型詳解
- 2020 年 10 月 20 日
- 筆記
- Deep Learning, nlp
1 簡介
- BERT全稱Bidirectional Enoceder Representations from Transformers,即雙向的Transformers的Encoder。是谷歌於2018年10月提出的一個語言表示模型(language representation model)。
1.1 創新點
- 預訓練方法(pre-trained):
- 用Masked LM學習詞語在上下文中的表示;
- 用Next Sentence Prediction來學習句子級表示。
1.2 成功
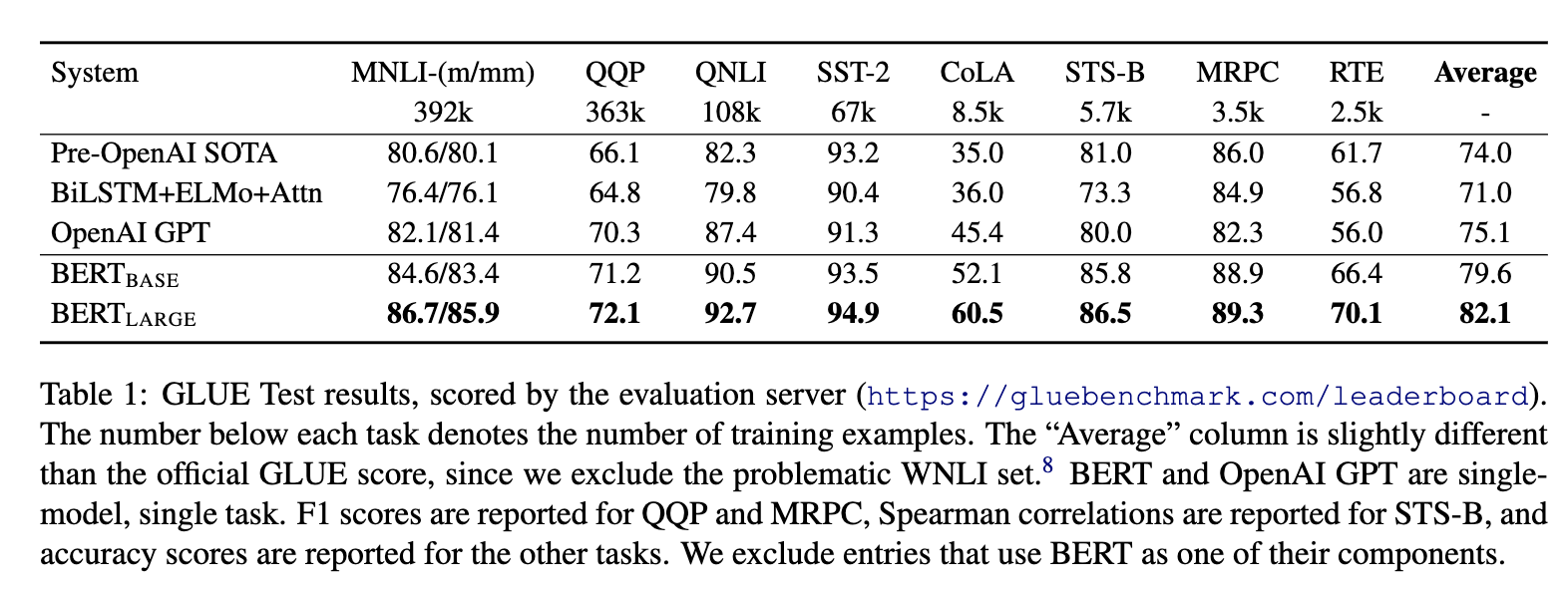
- 強大,效果好。出來之時,在11種自然語言處理任務上霸榜。

2 模型
2.1 基本思想
-
Bert之前的幾年,人們通過DNN對語言模型進行「預訓練」,得到詞向量,然後在一些下游NLP任務(問題回答,自然語言推斷,情感分析等)上進行了微調,取得了很好的效果。
-
對於下游任務,通常並不是直接使用預訓練的語言模型,而是使用語言模型的副產物–詞向量。實際上,預訓練語言模型通常是希望得到「每個單詞的最佳上下文表示」。如果每個單詞只能看到自己「左側的上下文」,顯然會缺少許多語境信息。因此需要訓練從右到左的模型。這樣,每個單詞都有兩個表示形式:從左到右和從右到左,然後就可以將它們串聯在一起以完成下游任務了。
-
綜上,從直覺上講,如果可以訓練一個高度雙向的語言模型,那將非常棒。
2.2 建模目標
可以和同是雙向的ELMo對比一下:
- ELMo:
- \(P(w_i|w_1, w_2, …, w_{i-1})\) 和 \(P(w_i|w_{i+1}, w_{i+2},…,w_n)\)作為目標函數,獨立訓練處兩個representation然後拼接。
- BERT的目標函數:
- \(P(w_i|w_1, …, w_{i-1}, w_{i+1},…,w_n)\)以此訓練LM。
2.3 詞嵌入(Embedding)
–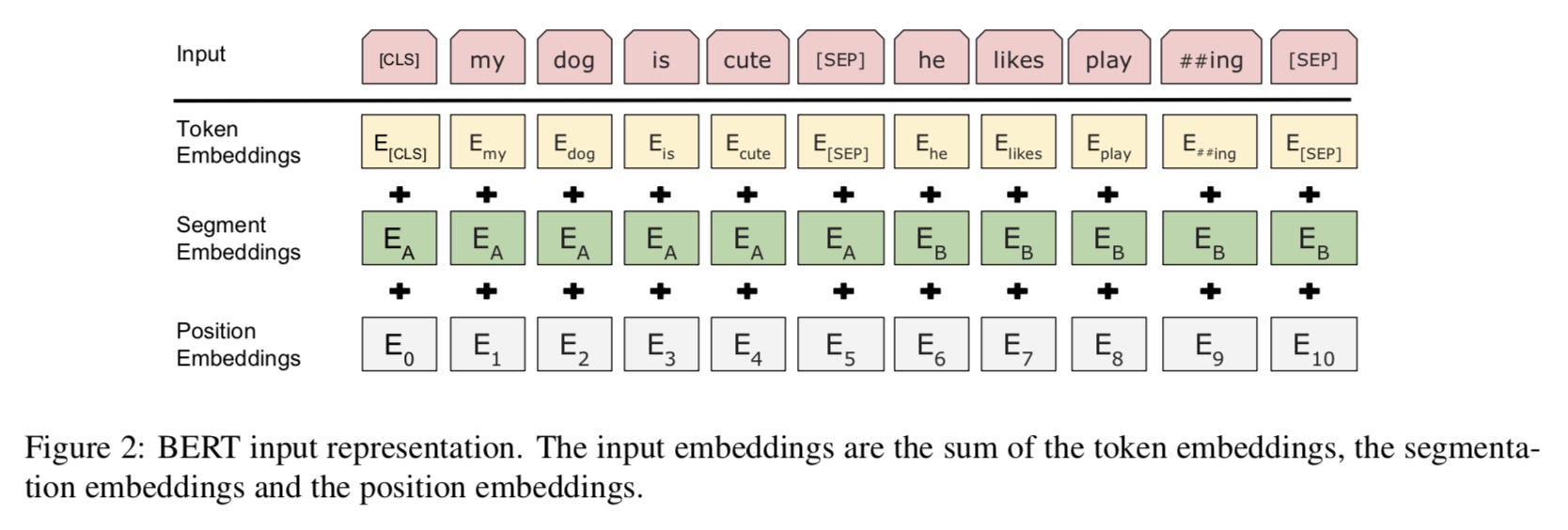
- Bert的Embedding由三種Embedding求和而成。
- Token Embeddings 是指的詞(字)向量。第一個單詞是CLS標誌,可以用於之後的分類任務。????
- Segment Embeddings用來區別兩種句子,預訓練除了LM,還需要做判斷兩個句子先後順序的分類任務。
- Position Embeddings和Transformer的Position Embeddings不一樣,在Transformer中使用的是公式法在bert這裡是通過訓練得到的。
2.4 預訓練任務(Pre-training Task)
2.4.1 Task 1: Masked LM
-
在將單詞序列輸入給 BERT 之前,每個序列中有 15% 的單詞被 [MASK] token 替換。然後模型嘗試基於序列中其他未被 mask 的單詞的上下文來預測被mask的原單詞。最終的損失函數只計算被mask掉那個token。
-
如果一直用標記[MASK]代替(在實際預測時是碰不到這個標記的)會影響模型,具體的MASK是有trick的:
-
隨機mask的時候10%的單詞會被替代成其他單詞,10%的單詞不替換,剩下80%才被替換為[MASK]。作者沒有說明什麼原因,應該是基於實驗效果?
-
要注意的是Masked LM預訓練階段模型是不知道真正被mask的是哪個詞,所以模型每個詞都要關注。
-
訓練技巧:序列長度太大(512)會影響訓練速度,所以90%的steps都用seq_len=128訓練,餘下的10%步數訓練512長度的輸入。
-
具體實現注意:
- i) 在encoder的輸出上添加一個分類層。
- ii) 用嵌入矩陣乘以輸出向量,將其轉換為詞彙的維度。
- iii) 用softmax計算詞彙表中每個單詞的概率。
-
BERT的損失函數只考慮了mask的預測值,忽略了沒有掩蔽的字的預測。這樣的話,模型要比單向模型收斂得慢,不過結果的情境意識增加了。
2.4.2 Task 2: Next Sentence Prediction
- LM存在的問題是,缺少句子之間的關係,這對許多NLP任務很重要。為預訓練句子關係模型,bert使用一個非常簡單的二分類任務:將兩個句子A和B鏈接起來,預測原始文本中句子B是否排在句子A之後。
- 具體訓練的時候,50%的輸入對在原始文檔中是前後關係,另外50%中是從語料庫中隨機組成的,並且是與第一句斷開的。
- 為了幫助模型區分開訓練中的兩個句子,輸入在進入模型之前要按以下方式進行處理:
- 在第一個句子的開頭插入 [CLS] 標記,在每個句子的末尾插入 [SEP] 標記。
- 將表示句子 A 或句子 B 的一個句子 embedding 添加到每個 token 上,即前文說的Segment Embeddings。
- 給每個token添加一個位置embedding,來表示它在序列中的位置。
- 為了預測第二個句子是否是第一個句子的後續句子,用下面幾個步驟來預測:
- 整個輸入序列輸入給 Transformer 模型用一個簡單的分類層將[CLS]標記的輸出變換為 2×1 形狀的向量。
- 用 softmax 計算 IsNextSequence 的概率
- 在訓練BERT模型時,Masked LM和 Next Sentence Prediction 是一起訓練的,目標就是要最小化兩種策略的組合損失函數。
2.5 微調(Fine-tunning)
- 對於不同的下游任務,我們僅需要對BERT不同位置的輸出進行處理即可,或者直接將BERT不同位置的輸出直接輸入到下游模型當中。具體的如下:
- 對於情感分析等單句分類任務,可以直接輸入單個句子(不需要[SEP]分隔雙句),將[CLS]的輸出直接輸入到分類器進行分類
- 對於句子對任務(句子關係判斷任務),需要用[SEP]分隔兩個句子輸入到模型中,然後同樣僅須將[CLS]的輸出送到分類器進行分類
- 對於問答任務,將問題與答案拼接輸入到BERT模型中,然後將答案位置的輸出向量進行二分類並在句子方向上進行softmax(只需預測開始和結束位置即可)
- 對於命名實體識別任務,對每個位置的輸出進行分類即可,如果將每個位置的輸出作為特徵輸入到CRF將取得更好的效果。
- 對於常規分類任務中,需要在 Transformer 的輸出之上加一個分類層
3 優缺點
3.1 優點
- 效果好,橫掃了11項NLP任務。bert之後基本全面擁抱transformer。微調下游任務的時候,即使數據集非常小(比如小於5000個標註樣本),模型性能也有不錯的提升。
3.2 缺點
作者在文中主要提到的就是MLM預訓練時的mask問題:
- [MASK]標記在實際預測中不會出現,訓練時用過多[MASK]影響模型表現
- 每個batch只有15%的token被預測,所以BERT收斂得比left-to-right模型要慢(它們會預測每個token)
- BERT的預訓練任務MLM使得能夠藉助上下文對序列進行編碼,但同時也使得其預訓練過程與中的數據與微調的數據不匹配,難以適應生成式任務
- BERT沒有考慮預測[MASK]之間的相關性,是對語言模型聯合概率的有偏估計
- 由於最大輸入長度的限制,適合句子和段落級別的任務,不適用於文檔級別的任務(如長文本分類)
4 參考文獻
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 11 Oct 2018 (v1), last revised 24 May 2019 (v2)
- //www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/
- //zhuanlan.zhihu.com/p/46652512

