滴滴導航若干關鍵功能的技術突破與實踐
- 2020 年 10 月 13 日
- 筆記


桔妹導讀:滴滴導航是滴滴出行旗下基於豐富的交通大數據和領先的算法策略,面向網約車及自駕場景而打造的一款技術領先的地圖產品。伴隨着海量網約車司機每日8小時+的導航使用,產品積累了大量的反饋並持續優化打磨。在這個過程中,為了給用戶帶來更好的地圖導航體驗,團隊一直在積極探索技術上的突破和實踐,並取得了一定的成果。今天,我們將會對其中的MJO三維全景導航(行業唯一)、導航主輔路偏航識別及深度學習在端上抓路應用這三個技術點給大家展開講解。
1. MJO三維全景導航
▍1.1 應用背景
對於絕大多數駕駛者使用2D導航地圖,都會出現立交上認錯路口,高速上錯過匝道,不知何時該併線的問題。路口圖形誘導的出現,一定程度上緩解了路口偏航的問題。業內通俗幾種做法,如下圖:

從左到右順序:
- 實景圖:基於現實建模,但是只展示了一個角度的圖像,成本過高。
- 模式圖:1對多的映射關係,跟現實路口形態道路彎曲度差異會很大。
- 矢量大圖:基於2d道路屬性製作,算法驅動可以上量。
- 街景大圖:路口和街景圖像做掛接,然後疊加引導箭頭。依賴街景採集成本巨大。
- 衛星大圖:路口真實但只有2D視角。
上述所有方案都只能靜態展示,而且不能精確區分車道。滴滴地圖中的MJO導航技術,通過加入與實景圖同級別的精細場景模型,準確表達複雜橋區的層次穿越關係。極大地降低了讀圖成本。
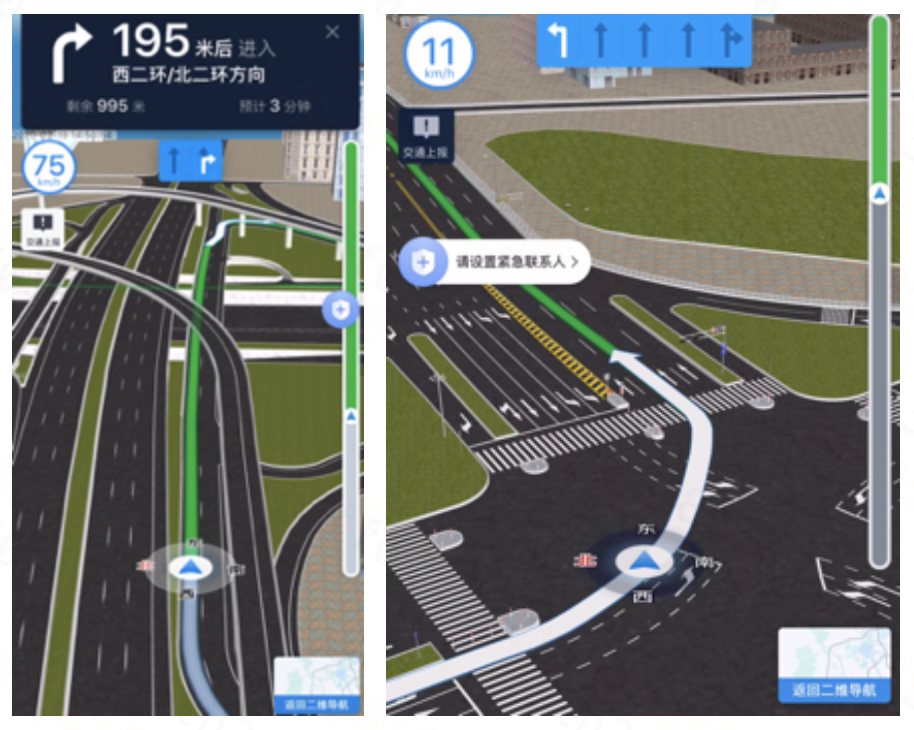
三維全景導航的技術難點在於模型複雜度高,數據量較大,相比2D導航地圖需要更多的CPU和GPU資源支持。為了在更廣泛的設備上實現該功能,需要大幅優化資源的內存、CPU及GPU消耗。
▍1.2 數據壓縮
較大的模型尺寸帶來了網絡傳輸的壓力,對數據壓縮提出了較高的要求。原始數據全國總量高達41G,無法適應移動端的內存需求。性能攻堅階段,團隊融合了多種壓縮技術進行優化:
- 紋理壓縮
- 提取共享資源
- 模型壓縮
- 格式二進制轉換
- 次要模型過濾
▍1.3 Metal/Vulkan技術
滴滴渲染引擎引入了下一代的圖形API,Metal及Vulkan技術。蘋果宣稱Metal可以提供10倍於OpenGL的性能,而Vulkan則是由khronos組織提出的開放標準,可以支持Apple以外的平台。對比傳統的OpenGL ES技術,Metal/Vulkan更加貼近底層硬件,可以更精確地控制GPU,有着更好的線程模型。Metal和Vulkan可以支持更多的draw calls,非常適合應用於MJO這種模型數量較多的場景。通過適配Metal/Vulkan,解決了渲染引擎中shared context的兼容問題,提高了多線程加載的性能,對整體性能和穩定性都有了較大的提升。▍1.4 渲染性能優化由於模型數據量較大,數據加載耗時,使用傳統的加載方式會造成明顯的卡頓問題,影響用戶體驗。通過利用Metal/OpenGL ES/Vulkan的多線程技術,資源加載使用了獨立的加載線程。加載過程對渲染線程沒有直接影響,使程序更加流暢。渲染場景的管理採用了八叉樹技術,用於快速選取可見元素,降低渲染負載。對比順序遍歷的O(N)複雜度,八叉樹降到了O(logN)。
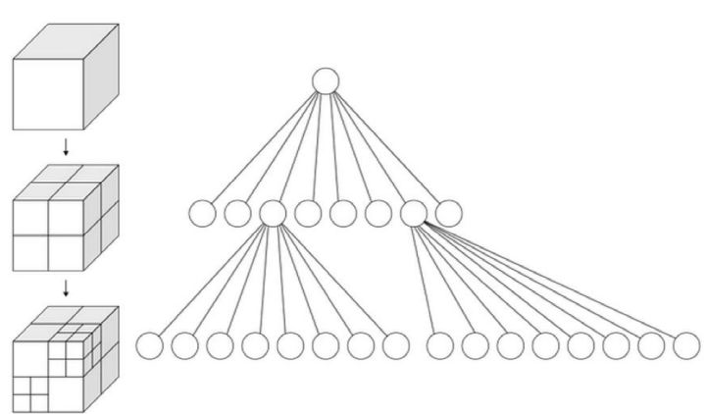
MJO原始模型粒度較細,一個橋區包含2000多個模型,如果直接進行渲染會造成draw call數量過多,每個draw call都會產生額外的消耗。通過材質合併模型後,draw calls降低到40多個,大幅降低了渲染和內存消耗。

▍1.5 導航實現
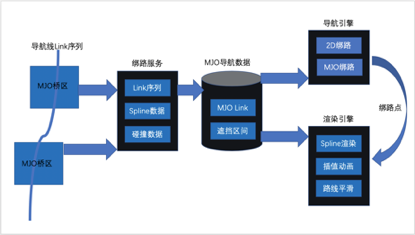
MJO導航雖然提供了高精度的道路模型和車道級的導航線數據,但由於移動端設備並不包含高精度的定位設備,需要利用現有的2D導航邏輯,將GPS點映射到MJO的導航線上。具體步驟如下:
-
根據2D導航的link序列過濾出經過MJO橋區的部分
-
綁路服務計算映射出的MJO link序列並拼裝MJO導航線
-
MJO導航線和GPS點傳入導航引擎,計算出MJO中的綁路點
-
MJO導航線傳入渲染引擎,經過Bezier插值進行平滑處理並渲染
-
綁路點在導航線上進行投影得到3D高度,並插值成平滑移動的動畫進行渲染
 其中平滑算法使用了Bezier插值,p1 p4是曲線端點,p2 p3用於控制形狀,t是插值參數。
其中平滑算法使用了Bezier插值,p1 p4是曲線端點,p2 p3用於控制形狀,t是插值參數。
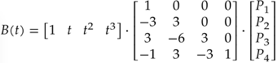
導航線由多個點構成,端點可以從導航線中直接得到。中間的2個控制點需要進行計算。這裡的技術要點是保證連接兩段線的切向一致(C1連續),在平滑的同時保證曲率不要過分偏離端點。團隊通過優化參數和算法,得到了比較滿意的效果。
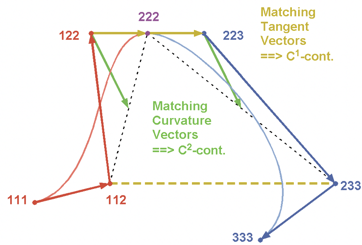
▍1.6 總結
MJO涉及了多種渲染及建模相關的技術,範圍廣難度高。團隊在有限的人力和時間預算條件下,攻克了多個技術難點,實現了一套完整的動畫誘導方案。極大地降低了駕駛過程的瞬時讀圖成本,有效地緩解了複雜路口的偏航問題。
2. 滴滴主輔路偏航識別的應用實踐
偏航是車輛實際行駛路線偏離了原定規劃路線的行為,而偏航識別用以確定車輛是否偏航,對偏航重新規划行駛路線。主輔路作為特殊的道路場景,其由於平行的特殊性,導致主輔路偏航較一般偏航更具有挑戰性。本文將介紹滴滴在主輔路偏航識別上的一些探索和實踐。
▍2.1 應用背景
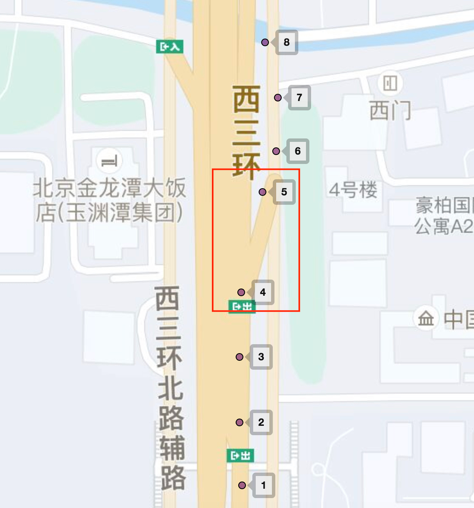
偏航是車輛實際行駛路線偏離了原定規劃路線的行為,如圖1所示,紅色的是規劃路線,帶偏航的點是車輛gps點,整體軌跡上來看車輛已經偏離了規劃路線,則為偏航。
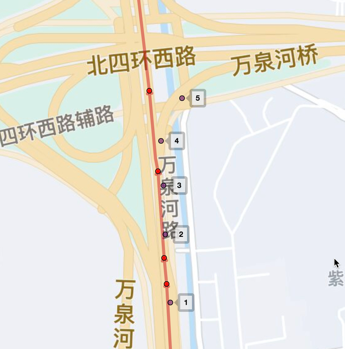
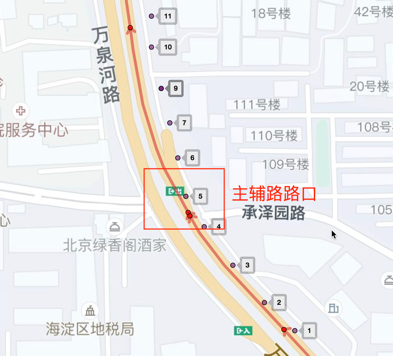
而主輔路偏航場景如圖2所示,車輛在圖中紅框路口處車輛由主路切換到了輔路,則為一次主輔路偏航。
▍2.2 主輔路偏航識別難點
偏航識別作為典型的二分類問題,通常會使用有監督學習的模型求解。由於主輔路的特殊性,有監督學習的標籤就成為整個技術方案的難點。
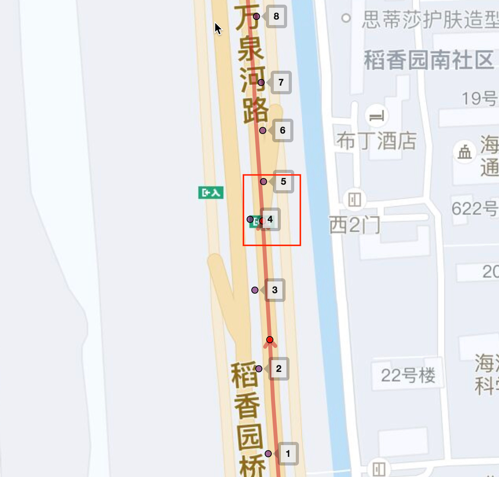
圖3 主輔路軌跡如圖3的軌跡,車輛在主輔路附近有一個偏移動作,但是單純從軌跡上很難辨別車輛是切換了個車道還是有主輔路切換,無法單純從軌跡上是無法獲得真值。因此,需要引入額外的信息,而滴滴擁有廣大司機上報的圖像數據就是一個很好的補充。除了標籤這個核心問題外,還有一些主要問題:
- GPS點漂移:GPS點受信號強弱等影響,會出現位置偏差。主輔路場景下,主輔路之間距離不會很遠,則GPS的位置偏差會更容易造成誤判。
- 路網形狀偏差:地圖數據往往用有向線段表示客觀道路,但是數據探查錄入等原因,和客觀世界道路位置形狀會有偏差,給識別帶來難度。
為了解決以上問題,提升用戶主輔路偏航上的體驗,我們提出了一種基於圖像識別的主輔路偏航識別系統。
▍2.3 技術方案
2.3.1 整體方案設計
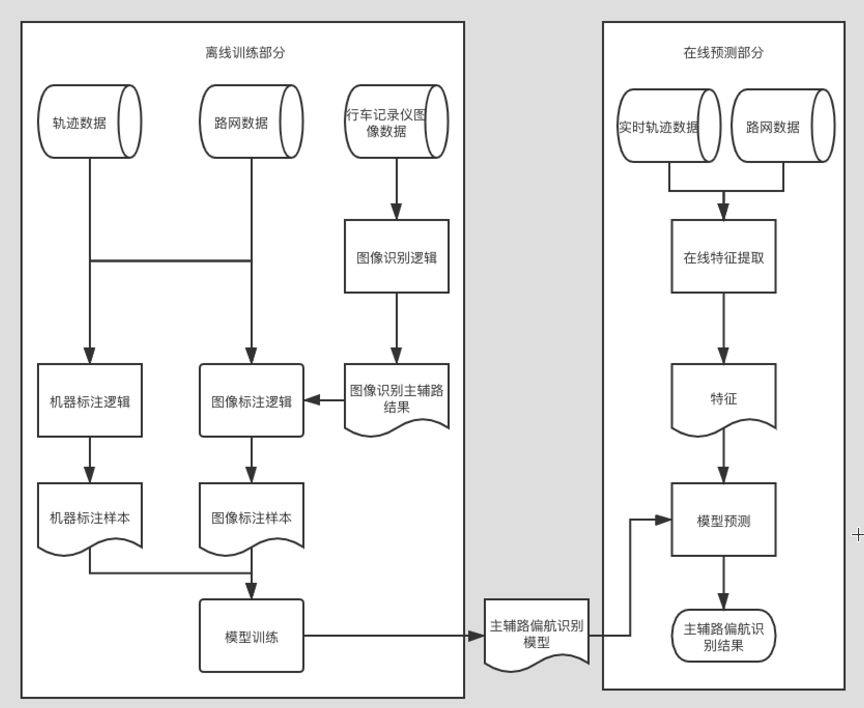
整體方案如圖4,主輔路偏航識別整體方案涉及到左側的離線模型訓練部分和在右側線預測部分,其中離線訓練主要包括:
- 機器標註邏輯 根據軌跡和路網連通性進行標註的樣本。由於存在路網連通性的約束,因此標註結果準確率高,但是路型覆蓋會有局限
- 圖像標註邏輯 根據司機上報圖像識別車輛在行為(車輛在主路/在輔路,或序列模型識別主輔路切換動作),結合軌跡和路網數據生成樣本。因為不受路網形態約束,因此路型覆蓋會更全;但是由於需要對路面圖像進行圖像識別,依賴圖像識別的準確率,存儲和計算成本較高
- 模型訓練 將機器標註樣本和圖像標註樣本進行合併後進行訓練,由於圖像標註樣本成本更高,所以會對圖像樣本用一些上採樣方式。
在線預測部分就是標準的線上預測流程,不做過多贅述。
2.3.2 機器標註邏輯
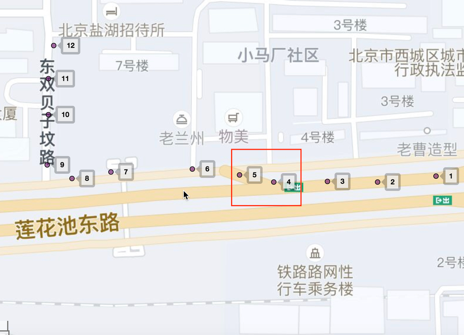
機器標註邏輯是根據軌跡和路網連通性進行標註的邏輯。如圖5所示,軌跡有拐入「東雙貝子墳路」,但是主路根據路網連通性是不可能拐入的,因此可以推斷在紅框路口處,車輛從主路切換到了輔路。通過路網連通性的規則能很容易的篩出這類樣本,且這類樣本準確性極高。
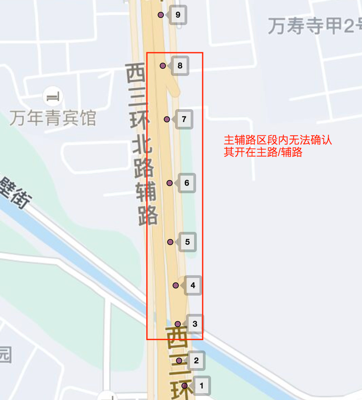
但是機器標註邏輯的局限也很明顯,就是諸如圖6的軌跡,機器標註是無法確認紅框的主輔路區間內車輛是開在主路或輔路的。以北京的軌跡為例,機器標註能處理的路口小於30%,如果僅使用這部分樣本進行訓練,會因樣本有偏導致效果不理想。
2.3.3 圖像標註邏輯
滴滴擁有司機上報的圖像數據,可以根據圖像識別司機行為(車輛在主路/在輔路,或主輔路切換動作),再結合軌跡和路網數據,生成圖像標註集合。

如上圖是一個圖像數據示例,序號表示其序列關係,由圖所示,車輛由輔路切換到了主路。圖像識別使用了兩套邏輯:
- 單圖識別序列中對每張圖片進行識別,給出其分類結果,類別包括:高架上主路、高架下主路、高架下輔路、主路、輔路。然後根據序列的分類結果,只要有類別的連續性變化視為切換行為,如序列(主路、主路、輔路、輔路)就可以視為切換。
- 序列識別根據圖片序列識別是否有主輔路切換動作。採用端到端的注意力與類別層級融合損失約束模型進行特徵學習與計算;為了更好的利用序列的語義信息,將主輔路單圖特徵集成到序列模型中,進行序列約束,識別序列結果。
序列模型準確率更高,但是對於圖像序列要求較高(比如時間間隔不能太長);單圖識別的召回更高,但是在有遮擋或高架下場景表現不好。將兩個模型的結果進行融合,引入司機軌跡、路網數據得到最終的圖像標註結果。圖像標註結果的準確率在93%以上。
2.3.4 模型訓練
由於線上只能使用到軌跡和路網的數據,因此使用特徵主要分為以下幾類:
- 點特徵:GPS點的特徵,包括坐標、速度、方向等
- 道路(link)特徵:包括道路屬性(國道等)、車道數、道路方向等
- 點-link特徵:包括點方向同道路方向角度差、點到道路的距離等
- 序列特徵:包括當前點同上一個點的角度差、距離差,以及累計角度變化等
同時,針對GPS點信號不準確漂移的情況,使用卡爾曼濾波對原始GPS點位移,減少個別點漂移對於模型的影響;針對整段軌跡漂移,使用Frechet距離衡量其形狀相似度,加入到特徵中。針對路網形狀偏差,使用歷史軌跡統計的方式(熱力圖),對原始路網進行平移、彎曲等形狀變化。偏航是典型的二分類問題,初版模型使用Xgboost快速上線,目前在進行Wide&Deep和LSTM等模型的嘗試。
2.3.5 效果評估
隨機抽取了2000個司機上報的圖像數據,對經過的主輔路路口進行人工標註其主輔路切換行為,為人工標註集。同時,人工只根據軌跡信息進行判定軌跡行為,識別拐彎的準確率92%、召回率91%。形成這類問題的主要原因是估計漂移,如圖7的軌跡,人工如果只根據軌跡判斷,會認為車輛在路口由主路切換到輔路,但是根據圖像可以確認其一直在主路上。
在人工標註集上的識別拐彎的準確率88%、召回率89%,接近人工只根據軌跡的判定的准召,但是還有一定提升空間。
▍2.4 總結
主輔路偏航作為偏航識別里的特殊類型,由於其平行的特殊性,給識別帶來了較大的挑戰。本文介紹了滴滴在主輔路偏航識別上的一些探索和實踐,藉助滴滴的數據優勢,建立了一套依賴圖像識別的主輔路偏航真值標註體系,並在最後主輔路偏航識別取得了預期的效果。
3. 深度學習在偏航引擎前端的探索和實踐
▍3.1 導讀
導航作為地圖出行的核心場景,根據起終點、路線數據及路況信息為用戶定製出行方案。導航為用戶提供規劃路徑,但現實出行中充滿變數,用戶隨時可能有意或無意中偏離原始規劃路線。這個時候,及時且智能化的提示顯得尤為重要。偏航引擎,負責實時跟蹤用戶位置,檢測用戶是否偏離規劃路線,並提供及時可靠的偏航提醒,發起新的路線規劃請求等;在實際行駛的過程中,偏航提示對用戶必不可少,其準確率和及時性對用戶體驗至關重要。
▍3.2 傳統偏航算法
傳統偏航算法,通常基於地圖匹配(map matching)和垂直場景下的特定規則來進行偏航判定。
地圖匹配是將一系列有序的用戶或者交通工具的位置關聯到地圖路網上的過程。因為GPS給定的用戶位置往往會有誤差,如果不進行地圖匹配,可能並不會顯示在路網上。在實際應用中,基於隱馬爾可夫模型(HMM)的地圖匹配就有比較良好的效果。
偏航判定基於地圖匹配的結果(匹配到特定路網的置信度),以及當前GPS狀態信息(位置,方位角,速度,精度等),GPS與匹配點及規劃路線之間的關係,同時依據GPS歷史軌跡特徵,判定用戶是否偏離規劃路線。
傳統的偏航判定往往基於大量人工編碼的規則。通常情況下,由於GPS的可靠性並不穩定,偏航準確性與靈敏性存在一定的互斥關係。
為了同時提升兩方面的指標,常常需要針對特定場景進行特定的優化。如在軌跡質量較高的時候,可以提高偏航的靈敏度;在軌跡質量較低的情況下,為了提升準確率,相應的降低偏航靈敏度。
另外,由於低質量的GPS在不同的行駛狀態下會展現出不同的軌跡特徵,我們也可以根據規劃路線的特徵(如直行,轉彎,掉頭等),結合GPS軌跡特徵(減速,掉頭,精度降低等),在垂直場景下設置不同的偏航閾值。
▍3.3 移動端應用深度學習模型
3.3.1 為什麼引入深度學習
傳統偏航判定中,無論是軌跡質量,還是規則編寫都具有較大的局限性。軌跡質量常常依賴於一系列固定的數學公式,難以融入大量GPS特徵進行綜合考量,其準確性和召回率不盡如人意。偏航規則隨着產品迭代日漸複雜化,變得難以維護,特別是面對人員迭代,更是難以處理。基於偏航判定問題的特徵,我們嘗試在端上引入深度學習模型。通過自動化的模型學習,為偏航判定提供更加統一和簡單的特徵指標,簡化編碼邏輯和維護代價,提升偏航準確性和靈敏度。
3.3.2 移動端應用深度學習算法的限制
-
推算性能
由於前端機型種類繁多,性能參差不齊。考慮兼容性,做模型推算時往往中低端機型為準。採用相關算法庫需要針對arm處理器做相應的優化。 -
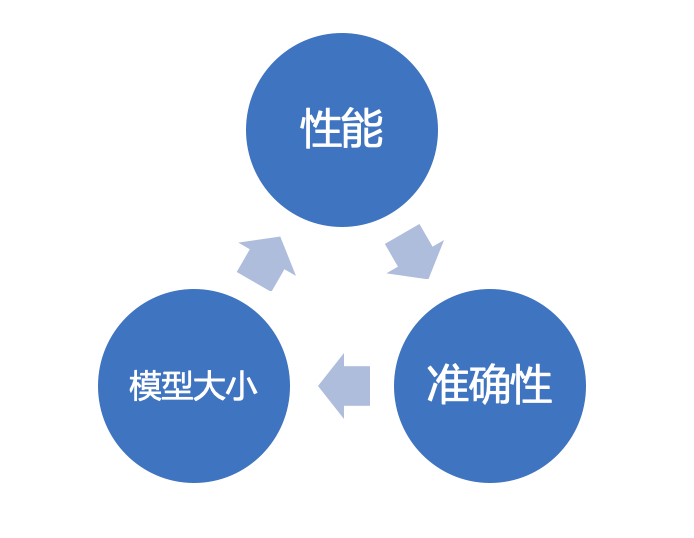
模型大小
移動端特別是地圖對App大小通常較為敏感。深度學習的應用需要引入算法庫及模型文件,如果使用開源庫文件,可能需要做適當的剪裁;或者根據最終引入的模型結構定製相應的算法庫,從而控制庫文件大小。另外,針對不同的模型類型、深度及輸入特徵,模型大小會產生較大的變化,最終選擇的模型可能並非最好,但綜合而言最為合適即可(比如200k模型比100k模型準確率提升0.2%,可能我們仍然會選擇100k模型)。 -
算法限制
使用特定第三方算法庫如tensorflow lite,不支持部分運算符等。事實上,移動端應用深度學習也是一個多方權衡的過程,最終的目標是實現性能,模型大小,準確性等指標的理想平衡。
▍3.4 GPS軌跡質量模型
前面提到,軌跡質量對於高靈敏度的偏航判定尤為重要。但基於規則的方法能夠提取的高質量GPS軌跡,在保證準確率的前提下,召回率往往較低。在偏航場景下,利用深度學習的方式來做質量判定,我們需要重新定義該問題。
3.4.1 問題定義及樣本標準
如果以GPS偏離路線的距離或角度來認定軌跡質量的優劣,標準會變得比較模糊。如此一來會大大增加樣本的採集的難度和統一性。此外,軌跡質量的判定與偏航判定不具有相關性,最終能否對偏航指標帶來提升存在很大的不確定性。
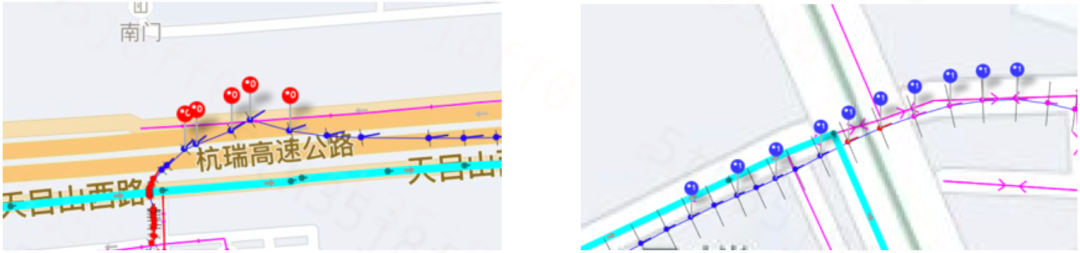
從偏航判定的角度出發,我們認為在人工校驗下:
-
發生誤偏航的GPS點,其軌跡質量基本是不可靠的(以上左圖)。
-
偏航靈敏度較低,但足以判定為偏航的情形,其軌跡質量是可靠的(以上右圖)。
-
為排除干擾,將GPS點聚集等不影響偏航判定的情形,歸類為其它;
於是我們的問題轉化為簡單的多分類問題。
3.4.2 特徵工程
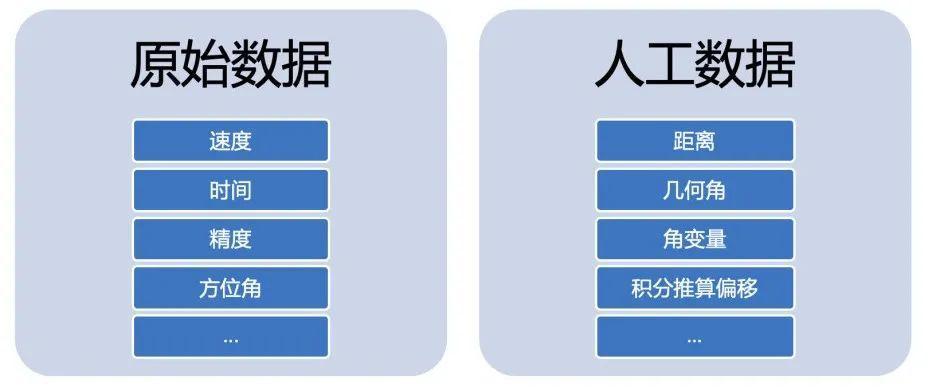
GPS軌跡質量模型中,我們提取了兩類樣本特徵。分別為原始GPS屬性(速度,時間,方位角,精度等),和人工屬性(距離,幾何角,角變量,積分推算偏移等)。部分人工屬性的提取雖然不能提升模型的準確率上限(比如在特定模型下適當增加神經元數量,可以以較少的屬性達到較多屬性的準確率),但卻能降低模型複雜度,從而降低模型大小,提升性能。這對於移動端而言是非常有益的。
對於低重要度的特徵,最終做了刪除,從而降低模型大小。例如我們發現方位角的重要度在實際模型訓練中不如角變量。推測方位角本身的不連續性(0 = 2pi)可能對模型訓練是一種干擾。
對於異常值,做了基本的數據清洗,如無效的速度值,無效的方位角;對於不足的GPS序列長度,用0進行填充(但需要額外注意起點屬性)等。
3.4.3 模型選擇、訓練與效果
DNN:只需要相對簡單的算法實現,引入較小的模型庫。然而GPS軌跡數據具有典型的時間序列特徵,在4萬樣本下,應用利用DNN模型調參優化後,訓練結果準確率最高達到91%。Bad case中存在大量時間不敏感的情形,最典型的情形就是——軌跡由差轉優時,判定結果未能及時轉變為高質量。
CNN:這裡可以嘗試兩種實現方式,一種是通過生成bitmap進行識別,然而GPS跨度不確定性較高,方向性不易表達,在實現上具有一定困難。第二種將序列化數據轉化為二維數組,C模型能夠識別出前後時間戳之間的變化特徵,但並不能保留更長的時間的變化特徵。最終訓練出的準確率在93%左右。另外,CNN模型應用在移動端有一個明顯的缺點,即模型尺寸一般較大。
LSTM(長短期記憶網絡):一種特殊的RNN模型,相比前述模型對軌跡質量序列判定有明顯優勢。在軌跡質量由好轉差,或由差轉好的識別上具有非常高的靈敏度,使用128個unit能夠達到97%的準確率。缺點是LSTM模型訓練速度相對較慢,算法庫實現相對複雜。
最終我們選擇了使用LSTM模型。使用LSTM的訓練結果,準確率大幅提升。在剩餘3%的錯誤樣例中,很多軌跡在形態上表現出較高的真實性,但卻無法同路網進行匹配。理論上通過引入路網屬性能夠上帶來準確率的進一步提升,然而這種數據的耦合脫離了軌跡質量判定的初衷——服務於偏航引擎專家系統,而非直接用於偏航判定。對此我們將會在最後進行更詳細的介紹。
3.4.4 移動端性能優化
模型推算性能對於移動端尤為重要。偏航場景下,GPS更新頻繁,選擇在必要的時候進行模型推算能夠避免不必要的計算開銷。通常我們會計算當前GPS點與規劃路線的偏離度,只有偏離度大於閾值時才會進行軌跡質量判定。
▍3.5 基於深度學習的專家系統探索
軌跡質量模型作為偏航判定的重要依據,能夠以較小的代價移植到移動端。如果不考慮前端性能及數據限制,我們完全可以定義整個偏航判定問題,訓練相應的偏航模型。然而偏航場景種類繁多,過於複雜,訓練出一套通用的偏航模型需要大量的數據,充足的路網信息,和較大的模型存儲,這對於移動端而言不太現實。
傳統偏航算法類似於實現一套基於規則的偏航專家系統。推算過程依賴了大量複雜的規則,這些規則難以概括和抽象為更簡單的模塊,算法的優化和維護都比較困難。因此我們考慮將偏航場景重新細化分類,依據不同的場景訓練相應的偏航模型。例如軌跡質量較差的直行或轉彎路線,能夠分別能訓練出不同的模型。用這些模型替代原有的複雜規則,對移動端而言,可移植性及可控性都會更好。這種基於深度學習的專家系統,是我們接下來完善優化偏航算法的重要方向。
本文作者




延伸閱讀



內容編輯 | Charlotte
聯繫我們 | DiDiTech@didiglobal.com

滴滴技術 出品