11 . Nginx核心原理講解-01
前言
/*
本文內容絕大多數來自陶輝.
陶輝,杭州智鏈達數據有限公司 CTO 兼聯合創始人,著有《深入理解 Nginx:模塊開發與架構解析》一書。
10 余年互聯網一線工作經驗,畢業於西安交通大學計算機科學與技術專業,
先後在華為中央軟件部、騰訊 QQ 空間、思科中國 CRDC、阿里雲飛天團隊工作。
研究方向為介於 Iaas 和PaaS 間的彈性計算,多年以來專註於 Nginx 的定製化應用,
對 Nginx 的設計與特性有深刻認識,實戰經驗豐富,編寫過許多優秀的 Nginx 模塊並應用於企業級產品中,
同時撰寫了大量關於 Nginx 的技術文章。擅長 Linux 下高性能服務器的開發,以及分佈式環境下海量數據存儲的設計開發。
*/
Nginx原理
Nginx組成
/*
Nginx二進制可執行文件
由各模塊源碼編譯出的一個文件
Nginx配置文件
控制Nginx的行為
Access.log訪問日誌
記錄每一條http請求信息
Error.log錯誤日誌
定位問題
*/
Nginx進程結構
/*
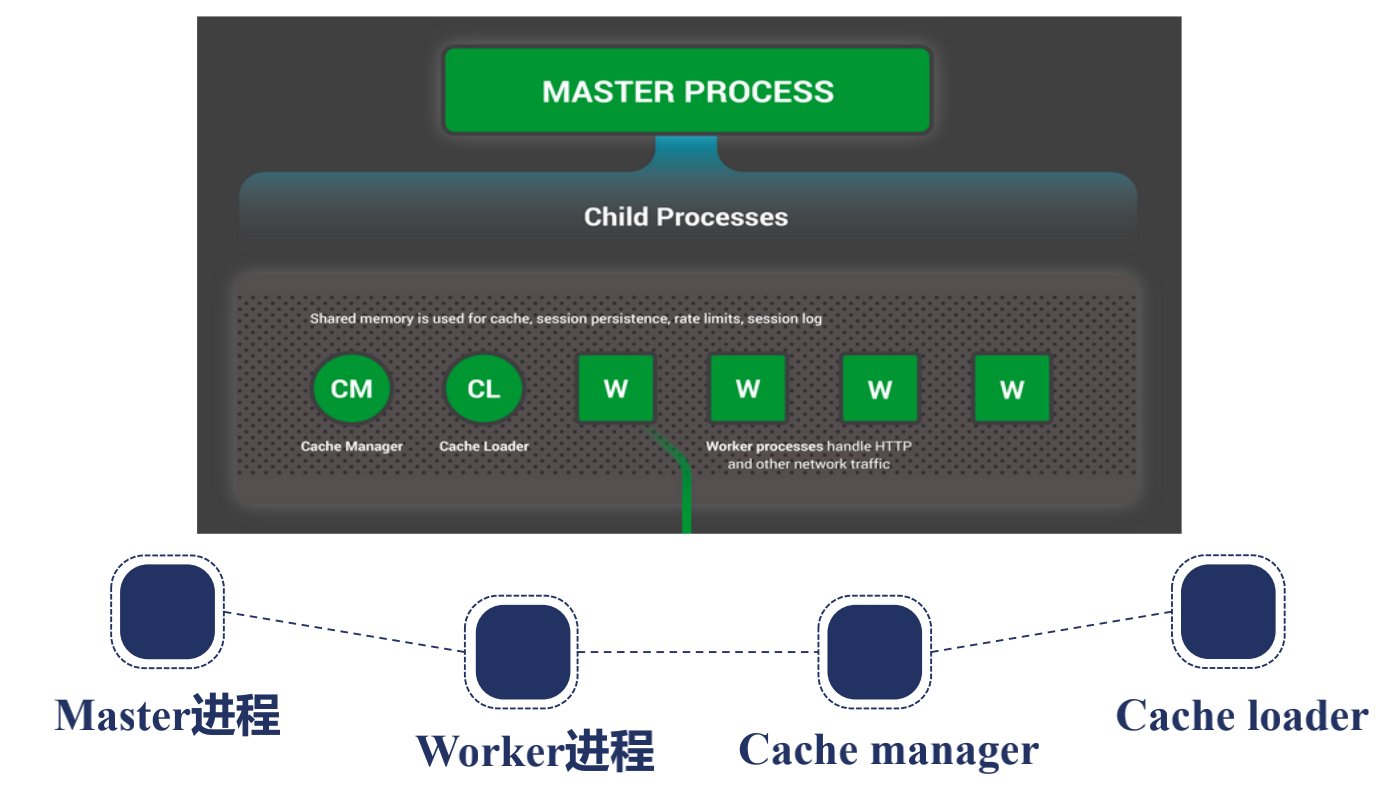
有兩種進程結構,一種是單進程的,一般測試,調試,開發用,生產環境一般都是多進程,因為生產環境要保證Nginx足夠健壯,發揮多核特性,一般默認是是多進程.
他的進程架構一般是有一個父進程, 叫Master進程,他有很多子進程,分為兩類,一個是Work進程,一個是Cache進程.
nginx做他的進程設計也是考慮到高可用高可靠,讓第三方模塊不會在master加入功能設計,雖然nginx允許第三方模塊,
但一般不會這樣做,master一般做worker進程管理,所有的worker進程是處理真正請求的,
master是監控worker是不是在工作,熱部署,重新載入配置文件,緩存就是在多個worker共享,
還要在CacheManager,CacheLoader共享,為後端代理動態請求緩存使用的,CacheLoaer做緩存載入,緩存管理
進程間通信是通過共享內存解決的
*/
nginx之所以用多進程不用單進程因為:
要保證高可靠性,高可用性,當nginx啟用了多線程時候,因為線程之間是共享一個內存地址空間的,所以當某一個第三方模塊引發一個地址空間導致的段錯誤,在地址越界錯誤時,整個nginx會掛掉,多進程則不會.
Nginx請求處理流程
/*
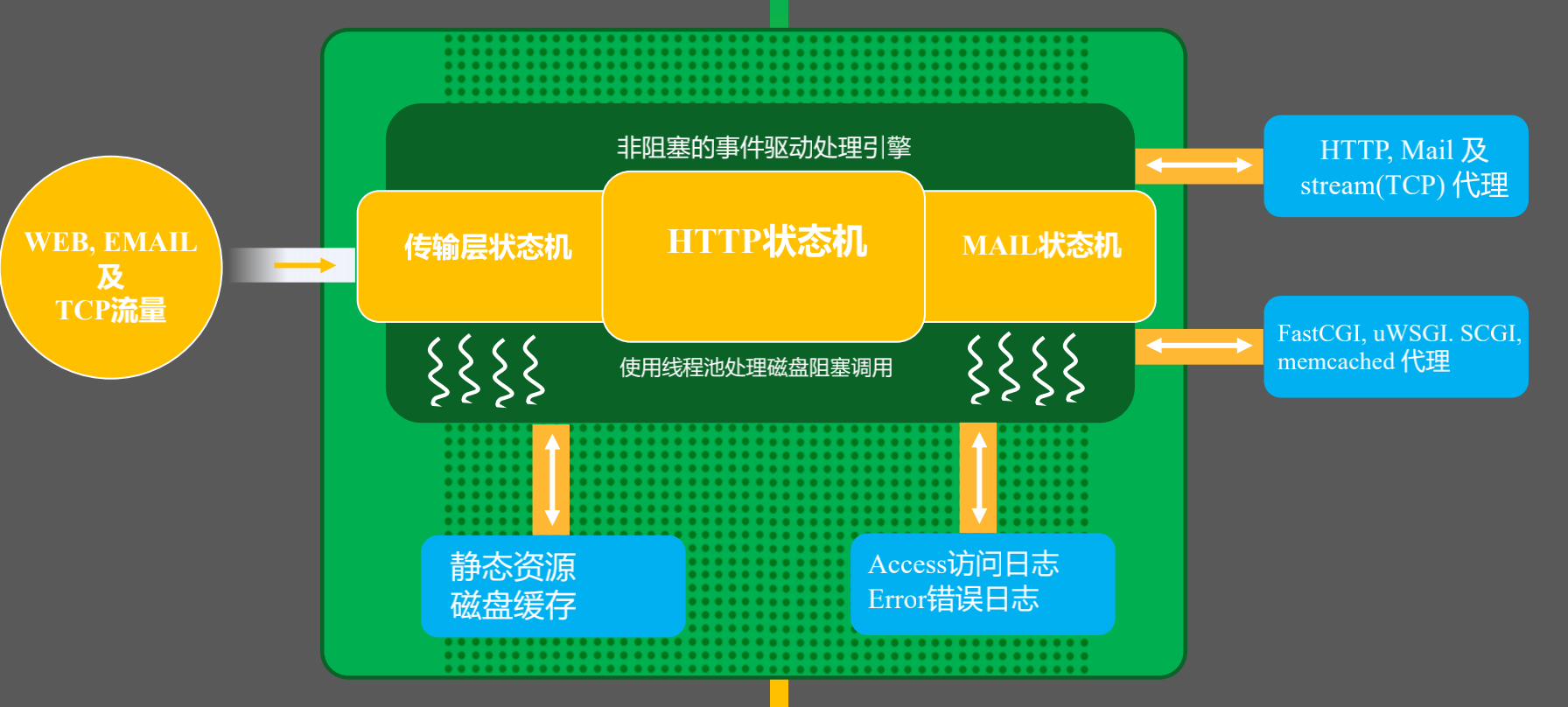
從Nginx內部看,有Web,EMAIL,TCP流量,分別有三種狀態機,傳輸層狀態機,HTTP狀態機,MAIL狀態機,
之所以叫狀態機是因為他使用的非阻塞事件驅動處理,epoll,一般使用異步處理引擎要使用狀態機才能將請求正確識別和處理,
所以我們在解析請求的時候分別走需要訪問靜態資源他就會找到靜態資源,但會出現當內存不足以完全緩存所有文件信息,sedfile,io會退化成阻塞的IO操作,所以這裡會有一個線程池處理,
反向代理就會做磁盤緩存,請求完成會將日誌記錄在access,error,也可以遠程到其他服務器.
更多的時候,Nginx作為反向代理,負載均衡的,通過協議級傳輸到後面服務器,也可以通過應用層,fastcgi,uwsgi代理到應用服務器.
*/
信號管理Nginx的父子進程
/*
Master進程
監控worker進程
CHLD
管理worker進程
接受信號
TERM,INT 立刻停止Nginx
QUIT 優雅停止Nginx,但是不要對用戶發送立刻結束連接向TCP reset的報文
HUP 重載配置文件
USR1 重新打開日誌文件
USR2 這兩個信號需要kill找到master的pid才能發送,上面可以直接nginx 發送信號
WINCH
Worker進程
接受信號
TERM,INT
QUIT
USR1
WINCH
nginx命令行
reload: HUP
reopen: USR1
stop: TERM
quit: QUIT
*/
Nginx reload的原理

/*
1. 向master進程發送HUP信號(reload命令)
2. master進程檢驗配置與法是否正確.
3. master進程打開新的監聽端口.
4. master進程用新配置啟動新的worker子進程.
5. master進程向老worker子進程發送QUIT信號.
6. 老worker進程關閉監聽句柄,處理完當前連接後結束進程.
*/
Nginx熱升級流程
/*
1. 將舊Nginx文件換成新Nginx文件(注意備份)
2. 向master進程發送USR2信號
3. master進程修改pid文件名,加後綴.oldbin
4. master進程用新Nginx文件啟動新Master進程
5. 向老master進程發送WINCH信號,關閉老worker
6. 回滾: 向老master發送HUP,向新master發送QUIT
*/
不停機載入新配置文件

worker進程優雅的關閉
/*
1. 設置定時器: worker_shutdown_timeout
2. 關閉監聽句柄
3. 關閉空閑連接
4. 在循環中等待全部連接關閉
5. 退出進程
*/
Nginx平滑升級流程
# 在上面源碼編譯安裝Nginx1.14的基礎上升級到1.16
wget //nginx.org/download/nginx-1.16.0.tar.gz
tar xf nginx-1.16.0.tar.gz -C /usr/local/src/
cd /usr/local/src/nginx-1.16.0/
./configure --prefix=/usr/local/nginx116 --with-http_stub_status_module --with-http_ssl_module --user=nginx --group=nginx
make && make install
# 備份原來老的Nginx文件,主要是為了回退
cp ./nginx/sbin/nginx ./nginx/sbin/nginx.bak
# 將新版的Nginx二進制文件替換已安裝的Nginx的二進制文件
cp nginx116/sbin/nginx nginx/sbin/nginx -rf
./nginx/sbin/nginx -v
# nginx version: nginx/1.16.0
# 給Nginx舊的主進程發送一個USR2信號,讓新主進程和舊進程同時工作.
# 再發一個Winch給舊的主進程號讓子進程退出,如果主進程還在,方便回滾
kill -USR2 17522
版本回滾
cp nginx.bak ./nginx/sbin/nginx -rf
# 發送HUP信號喚醒舊版本
kill -HUP `cat /usr/local/nginx/logs/nginx.pid.oldbin `
# 關閉新版本的主進程和Worker進程
kill -USR2 24148
kill -WINCH 24148
[root@test1 local]# ./nginx/sbin/nginx -v
# nginx version: nginx/1.14.2
網絡收發與Nginx事件間對應關係
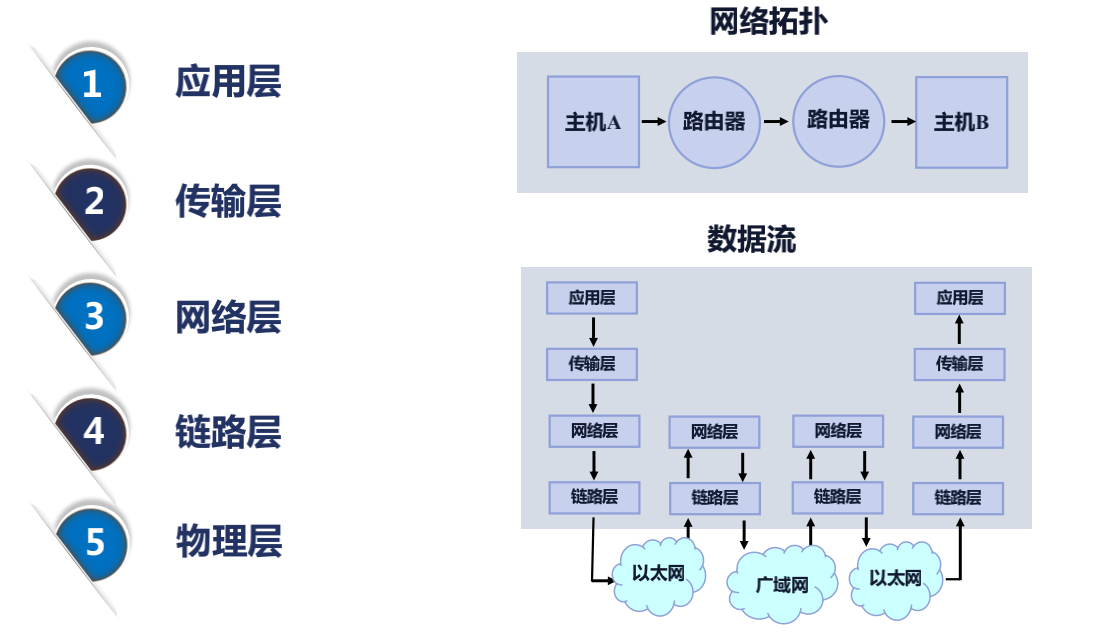
接下來看上面這張圖,比如主機 A 就是一台家裡的筆記本電腦,那麼主機 B 就是一台服務器,上面跑着 Nginx 服務。從主機 A 發送一個 HTTP 的 GET 請求到主機 B,這樣的一個過程中主要經歷了哪些事件?通過上圖數據流部分可以看出:
/*
應用層發送了一個GET請求 -> 到了傳輸層,這一步主要做一件事,就是瀏覽器打開一個端口,在windows的任務管理器可以看到這一點,
他會把這個端口記下來以及把Nginx打開的端口如80或者443記到傳輸層--> 然後網絡層會記下我們主機所在的IP和目標主機,也就是Nginx所在服務器公網IP-->
到鏈路層以後--> 經過以太網-->到達家裡的路由器(網絡層),家裡的路由器會記錄所在運營商下一段的IP --> 通過廣域網 --> 跳轉到主機B所在的機器中 -->
報文會經過鏈路層 --> 網絡層 --> 到傳輸層, 在傳輸層操作系統就知道給那個打開了80或者443進程,
這個進程自然就是Nginx --> 那麼Nginx在他的HTTP狀態機裏面(應用層)就會處理這個請求.
*/
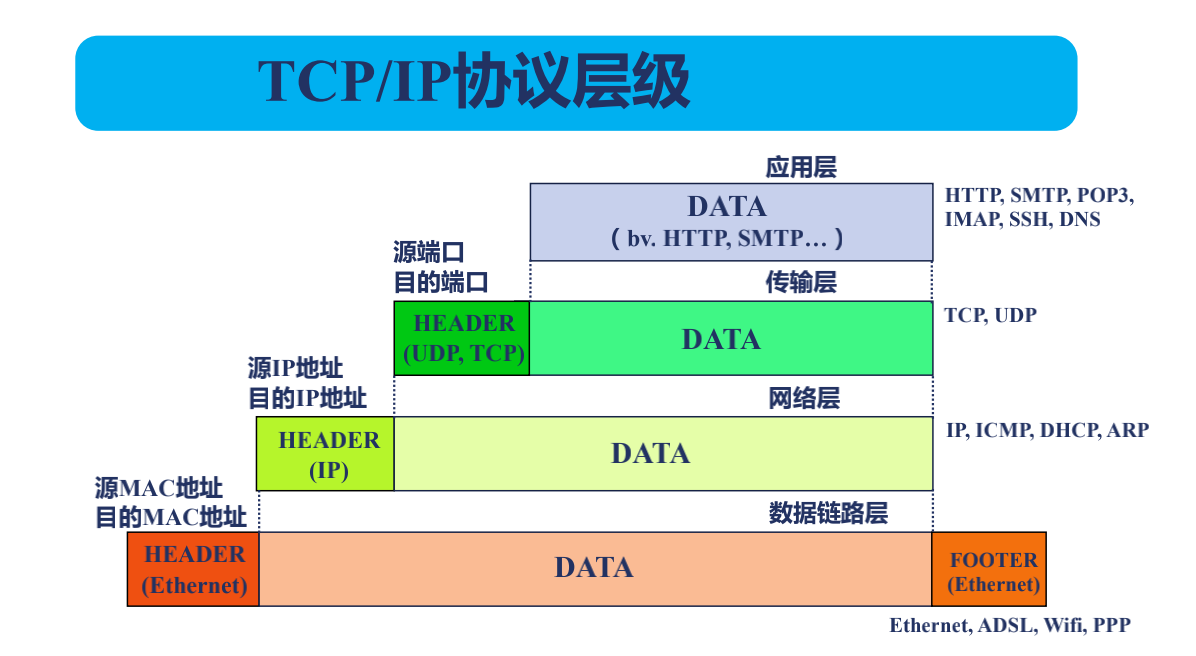
TCP流與報文
/*
數據鏈路層會在數據的前面Header部分和Footer部分添加上源MAC地址和源目的地址 -->
到了網絡層則是Nginx的公網地址(目的IP地址)和瀏覽器的公網地址(源IP地址) -->
到了TCP層(傳輸層),指定了Nginx打開的端口(目的端口)和瀏覽器打開的端口(源端口) -->
然後應用層就是HTTP協議了.
這就是一個報文,也就是說我們發送的HTTP協議會被切割成很多小的報文,在網絡層切割叫MTU,以太網的每個MTU是1500位元組;
在TCP層(傳輸層)會考慮中間每個環節最大的一個MTU值,這個時候往往每個報文只有幾百位元組,
這個報文我們稱為MSS,所以每收到一個MSS小於這麼大小的一個報文其實就是一個網絡事件.
這個時候,我們來看下TCP協議是怎樣和我們日常調用的一些接口(比如Accept,Read,Write,Close)是怎樣關聯在一起的?
*/
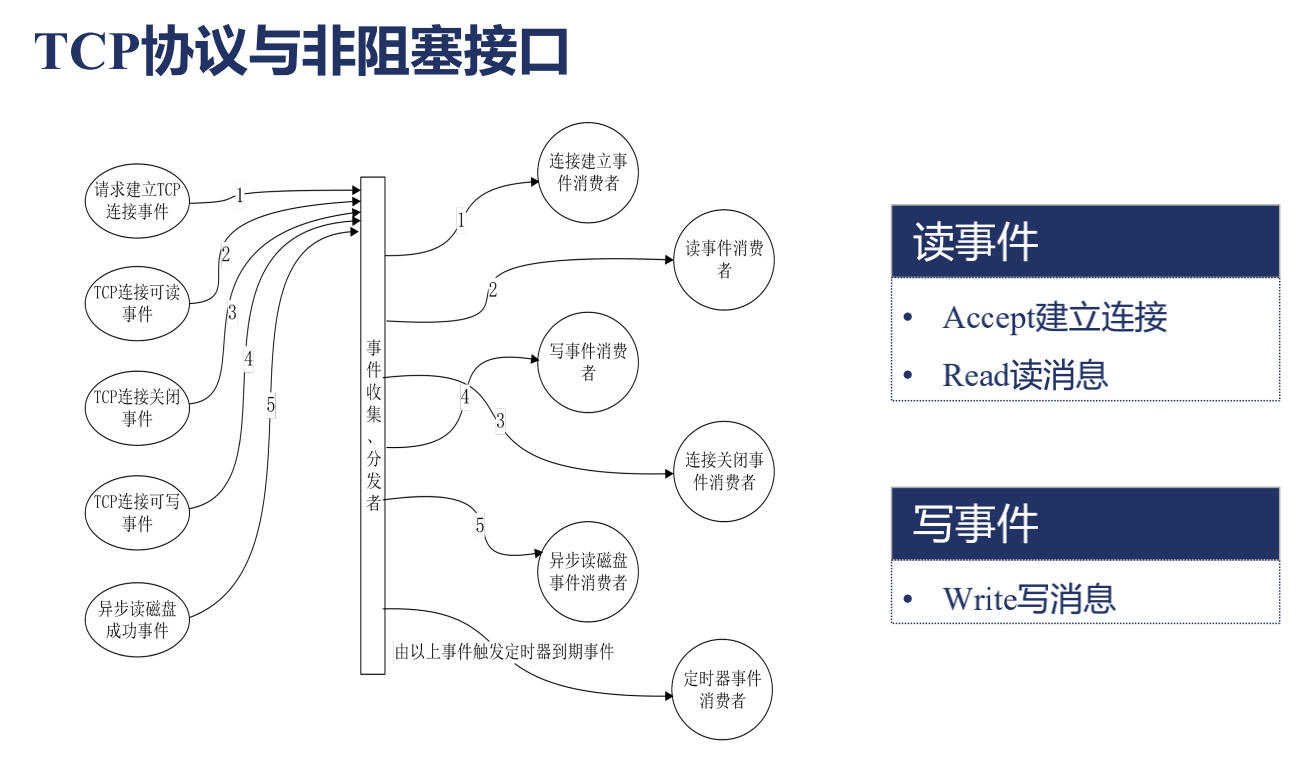
請求建立TCP連接事件實際上是發送了一個TCP報文,通過上面第二部分講解的那樣的一個流程到達了Nginx,對應的是讀事件,因為對於Nginx來說,我讀到了一個報文,所以就是Accept建立鏈接事件.
如果是TCP鏈接可讀事件,就是發送了一個消息,對於Nginx也是一個讀事件,就是Read讀消息.
如果是對端(也就是瀏覽器)主動地關掉了,相當於 windows 操作系統會去發送一個要求關閉鏈接的一個事件,對於 Nginx 來說還是一個讀事件,因為他只是去讀取一個報文。
那什麼是寫事件呢?當我們的瀏覽器需要向瀏覽器發送響應的時候,需要把消息寫到操作系統中,要求操作系統發送到網絡中,這就是一個寫事件。
像這樣的一些網絡讀寫事件,通常在 Nginx 中或者任何一個異步事件的處理框架中,他會有個東西叫事件收集、分發器。會定義每類事件處理的消費者,也就是說事件是一個生產者,是通過網絡中自動的生產到我們的 Nginx 中的,我們要對每種事件建立一個消費者。比如連接建立事件消費者,就是對 Accept 調用,HTTP 模塊就會去建立一個新的連接。還有很多讀消息或者寫消息,在 HTTP 狀態機中不同的時間段會調用不同的方法也就是每個消費者處理。
以上就是一個事件分發、消費器,包括 AIO 像異步讀寫磁盤事件,還有定時器事件,比如是否超時(workershutdowntimeout)。
Nginx事件循環
/*
當Nginx剛剛啟動時,在等待事件部分,也就是打開了80或443端口,這個時候在等待新的時間進來,比如新的客戶端連上了nginx向我們發起了連接,
此步往往對應epoll的epoll wait方法,這個時候的Nginx其實是處於sleep這樣一個進程狀態的,當操作系統收到了一個建立TCP連接的握手報文時並且處理完握手流程後,
操作系統就會通知epoll wait這個阻塞方法,告訴他可以往下走了,同時喚醒Nginx worker進程.
接着往下走之後,會去找操作系統索要事件,操作系統會把他準備好的事件,放到事件隊列中,從這個事件隊列中可以獲取到需要處理的事件,
比如建立連接或者收到一個TCP請求報文
*/
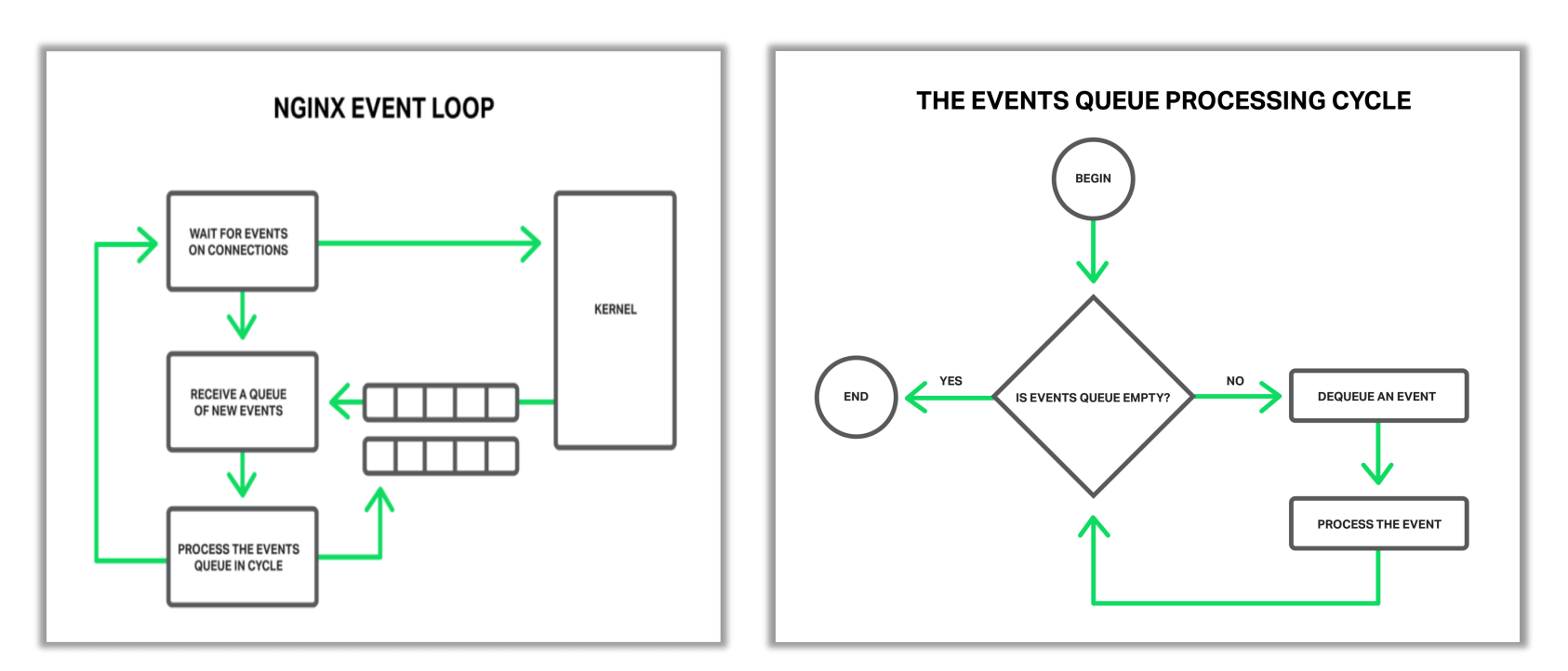
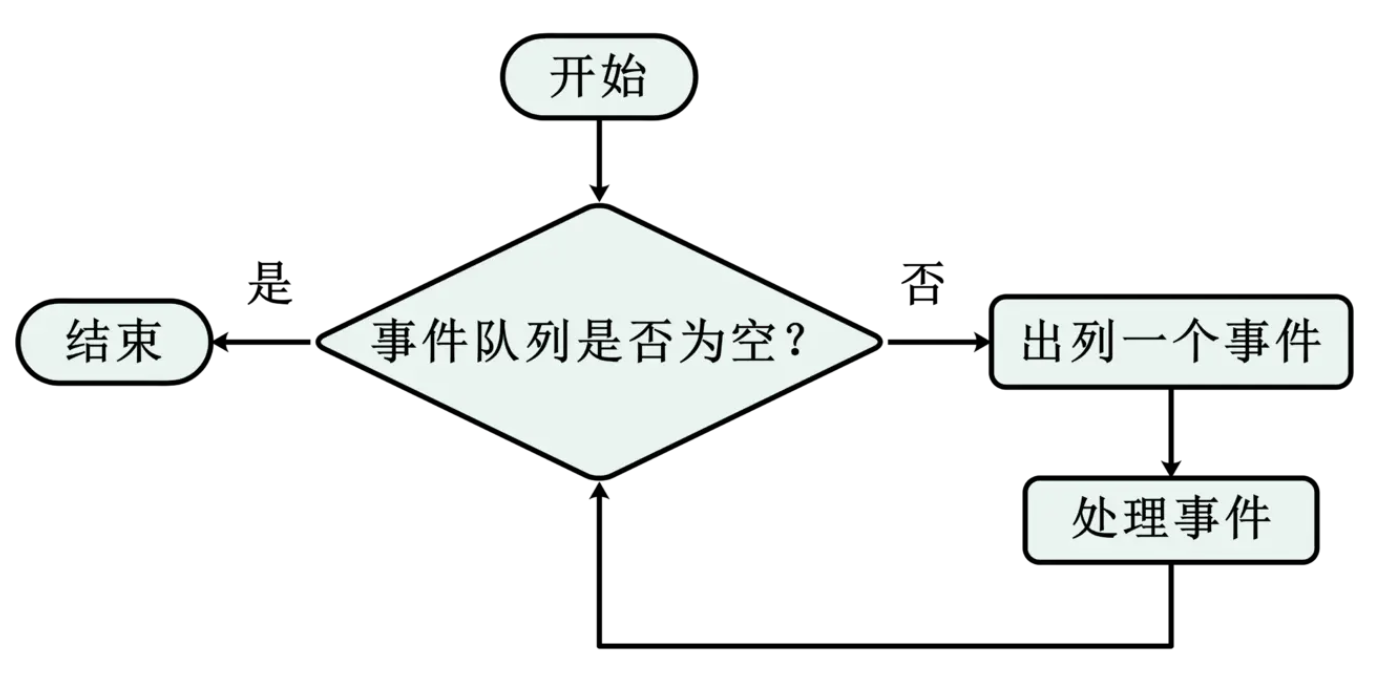
取出以後就會進行循環處理事件,如上就是處理事件的一個循環:當發現隊列中不為空,就把事件取出來開始處理事件;在處理事件的過程中,可能又生成新的事件,比如說發現一個連接新建立了,可能要添加一個超時時間,比如默認的 60 秒,也就是說 60 秒之內如果瀏覽器不向 Nginx 發送請求的話,Nginx 就會把這個連接關掉;又比如說當 Nginx 發現已經收完了完整的 HTTP 請求以後,可以生成 HTTP 響應了,那麼這個生成響應是需要 Nginx 可以向操作系統的寫緩存中心裏面去把響應寫進去,要求操作系統儘快的把這樣一段響應內容發到瀏覽器上,也就是說可能在處理過程中可能會產生新的事件,就是循環處理事件部分指向的事件隊列部分,等待下一次來處理。
如果所有的事件都處理完成以後呢,又會返回到等待事件部分。
在學習了 Nginx 事件循環後,我們再去理解,有時候使用一些第三方模塊,這些第三方模塊可能會做大量的 CPU 運算,這樣的計算任務會導致處理一個事件的時間非常的長;在上面的一個流程圖中,可以看到會導致隊列中的大量事件會長時間得不到處理,從而引發惡性循環,也就是他們的超時時間可能到了;大量的 CPU、Nginx 的任務都消耗在處理連接不正常的斷開,所以 Nginx 不能容忍有些第三方模塊長時間的消耗大量的 CPU 進行計算任務就是這樣一個原因。我們可以看到像 GZIP 這樣的模塊,他們都不會在一次使用大量的 CPU 而是分段使用,這些都與 Nginx 的事件循環有關的
應用場景優缺點
應用場景

// 1.靜態請求
// 2.反向代理
// 3.負載均衡
// 4.資源緩存
// 5.安全防護
// 6.訪問限制IP
// 7.訪問認證
/*
核心主要是以下三個應用:
靜態資源服務: 通過本地文件系統提供服務
反向代理服務: Nginx的強大性能,緩存,負載均衡
API: OpenResty
*/
優點
/* 1.功能模塊少
2.代碼模塊少
3.高可靠,熱部署,可擴展.
4.BSD許可證.
是一個給於使用者很大自由的協議,BSD 代碼鼓勵代碼共享,但需要尊重代碼作者的著作權。
BSD由於允許使用者修改和重新發佈代碼,也允許使用或在BSD代碼上開發商業軟件發佈和銷售,
因此是對商業集成很友好的協議。而很多的公司企業在選用開源產品的時候都首選BSD協議,
因為可以完全控制這些第三方的代碼,在必要的時候可以修改或者二次開發。
5.CPU親和
CPU親和是一種把CPU核心跟nginx工作進程綁定在一起,把每個worker進程固定在一個CPU上執行,減少切換CPU的cache miss,獲得更好的性能。
6.事件驅動模型.(此處很有可能被細問,最好研究清楚)
*/
Nginx同類型產品
Tengine
/*
Tengine是由淘寶網發起的Web服務器項目,他在Nginx的基礎上,針對大量訪問網站的需求,
增加了很多高級功能和特性,Tengine的性能和穩定性已經在大型網站如淘寶網,天貓商城得到了很好的檢驗,
他的目標就是打造一個高效,穩定,安全易用的平台.
*/
OpenResty
/*
這個開源Web平台主要由章亦春維護,2011年之前由淘寶贊助,後來12-16由美國的CloudFlare公司提供支持,
目前由OpenResty軟件基金會和OpenRest lnc公司提供支持.
因為大部分Nginx模塊都是由軟件包的維護者開發,所以可以確保這些模塊及其他組件可以很好的一起工作.
因為Nginx模塊開發非常難,而他把nginx的事件驅動,非以lua語言開發然後提供給開發者,兼具高性能開發效率提升特點.
*/
Epoll的優劣與原理
epoll與poll比較
/*
epoll存儲活躍的連接,每次只處理活躍的連接數量佔比很小
poll是每次將所有的連接交給操作系統去遍歷,找出活躍的連接,因此連接越多,耗時越長
*/
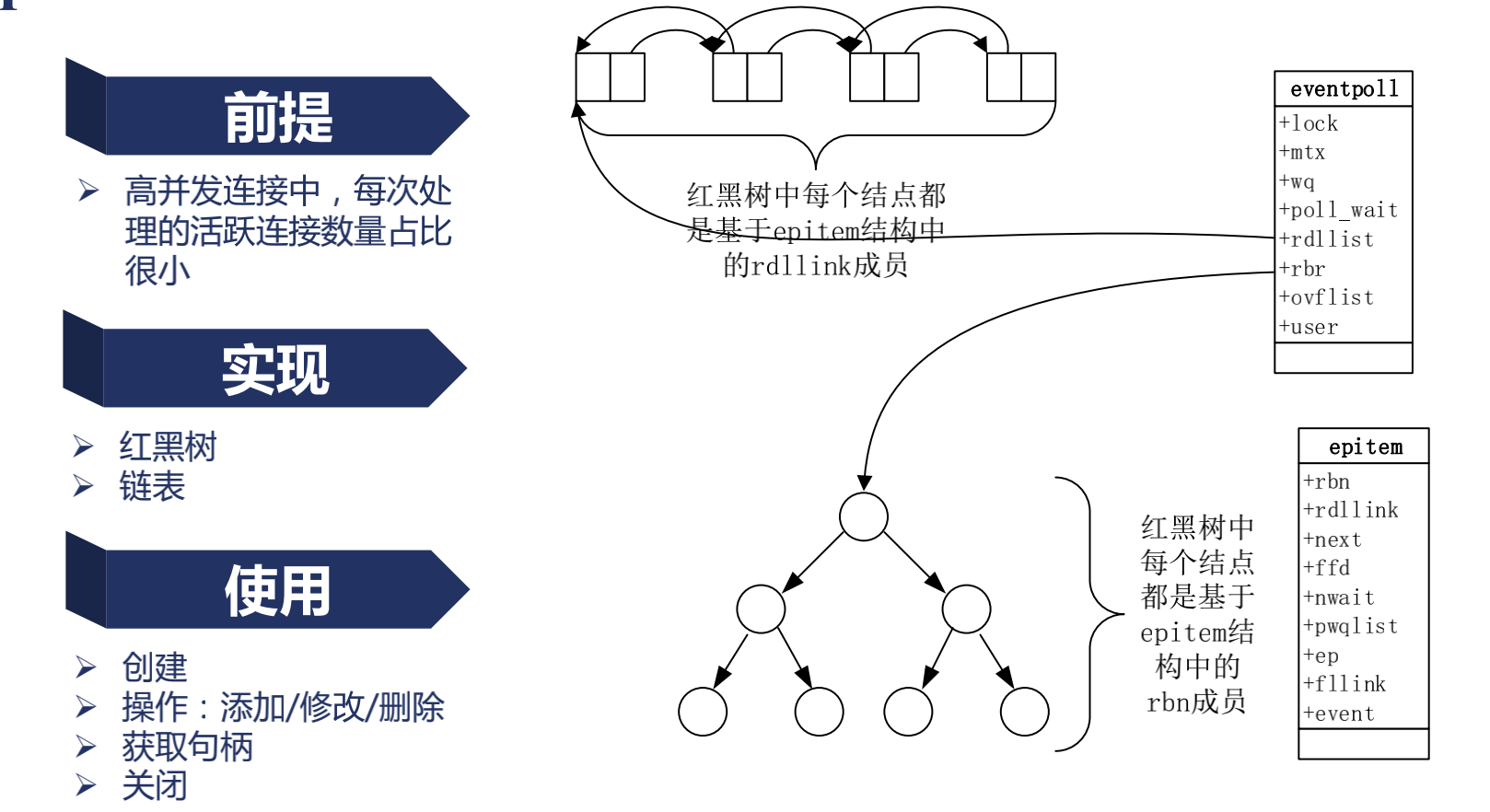
epoll如何實現只處理活躍連接
/*
epoll實現了eventpoll數據結構
數據結構中rdlist將活躍連接存儲在鏈表中,當網卡發送報文時,增加節點,當讀取一個事件後,鏈表刪除節點,需要得到活躍連接就只需要遍歷鏈表
數據結構中rdr使用紅黑樹(自平衡二叉樹)將事件存儲,例如:當有讀事件時,就新增節點,事件複雜度為log
*/
Nginx模塊
模塊分類
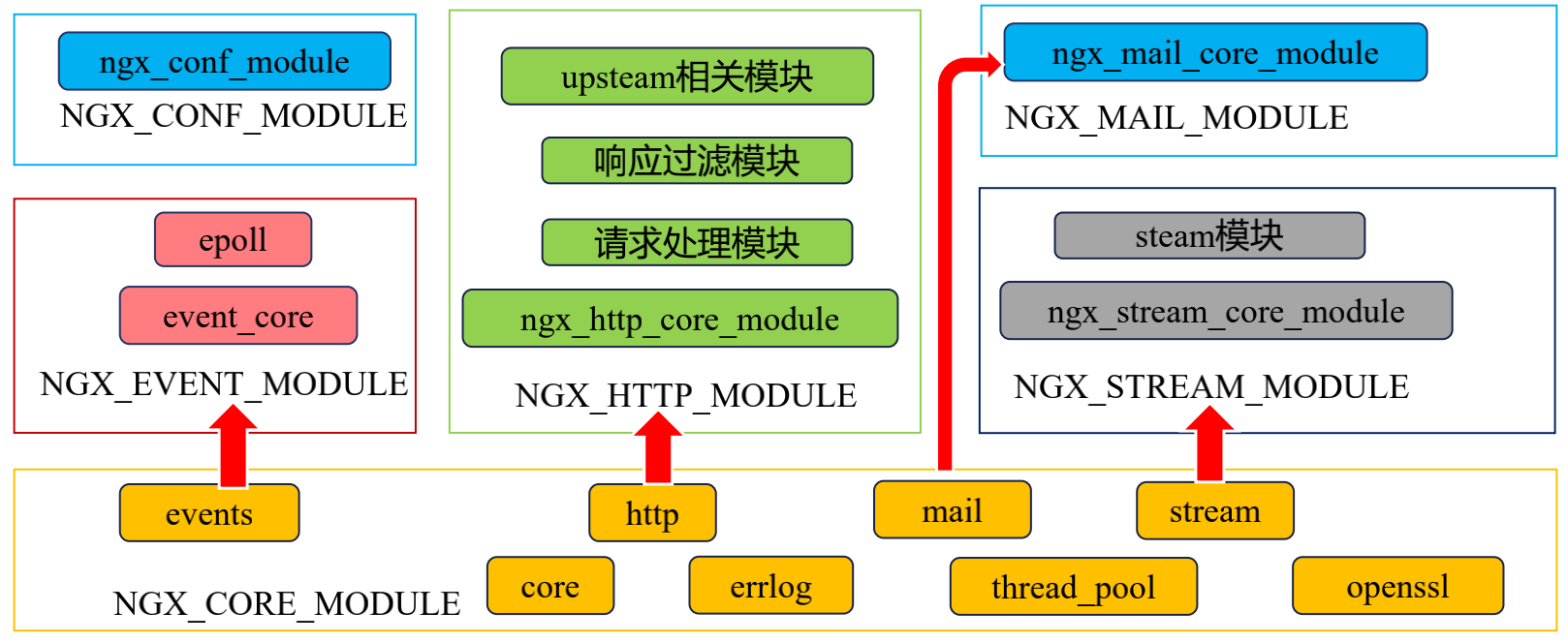
/*
核心模塊:
HTTP模塊: 用來發佈http web服務網站的模塊
event模塊: 用來處理nginx,訪問請求,並進行恢復.
mail模塊: 負責郵箱處理和發佈的.
基礎模塊:
HTTP Access模塊: 用來進行虛擬主機發佈訪問模塊,起到記錄訪問日誌;
HTTP FastCGI模塊: 用於和PHP程序進行交互的模塊,負責將來訪問nginx的php請求轉發到後端的PHP上.
HTTP Proxy模塊: 配置反向代理轉發的模塊,負責向後端傳遞參數.
HTTP Rewrite模塊: 支持Rewrite規則重寫,支持域名跳轉.
第三方模塊:
HTTP Upstream Request Hash模塊: 利用hash算法進行負載均衡的模塊.
HTTP Access Key模塊: http請求訪問校驗模塊
Limit_req模塊: http請求限制模塊
Upstream check module: 檢測後端負載轉發的模塊.
*/
Nginx如何通過連接池處理網絡請求
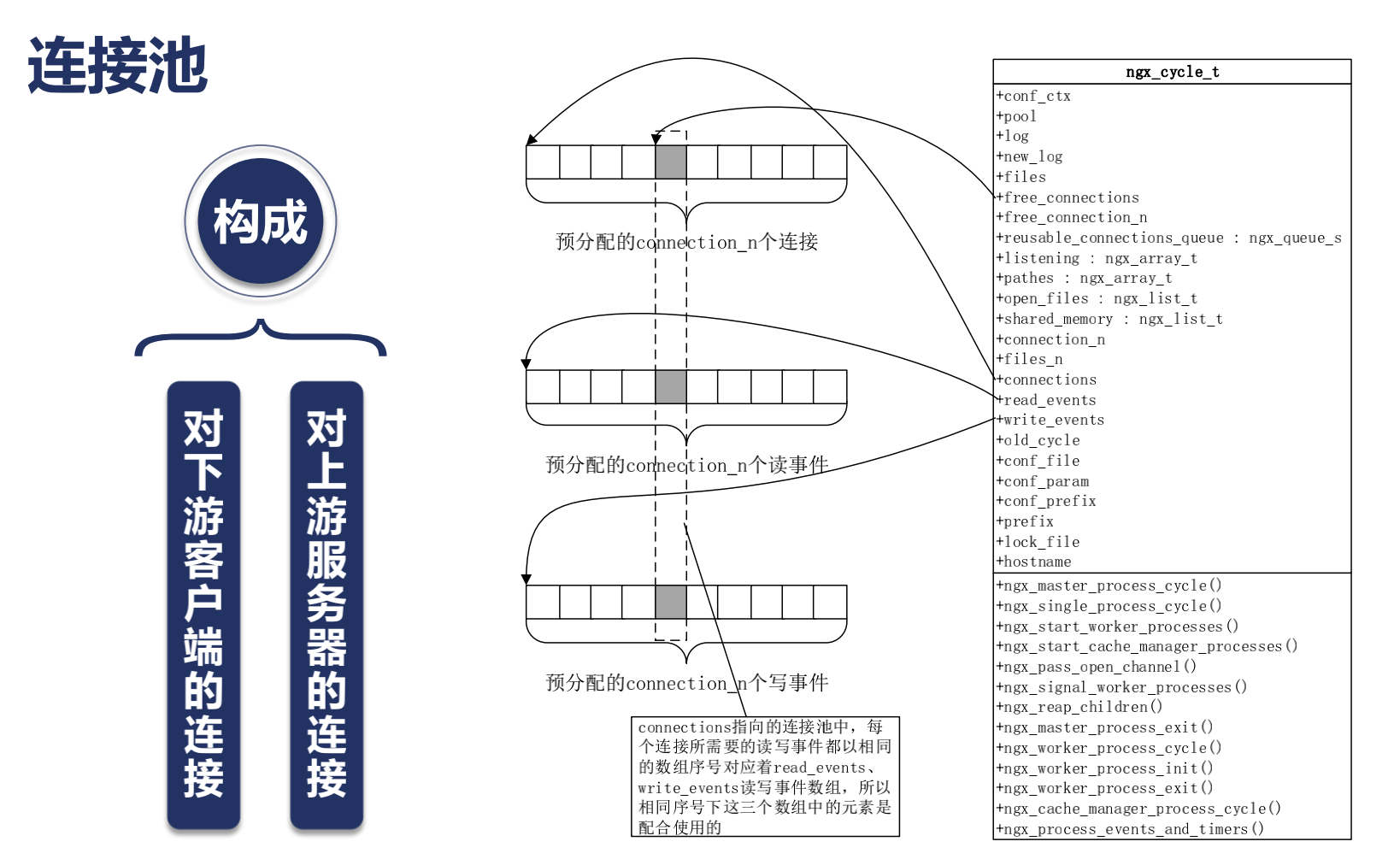
/*
每一個worker進程裏面都有一個獨立的ngx_cycle_t這樣一個數據結構;
現在不要對他裏面的細節來糾結,這裡三個主要的數組要看一下:
*/
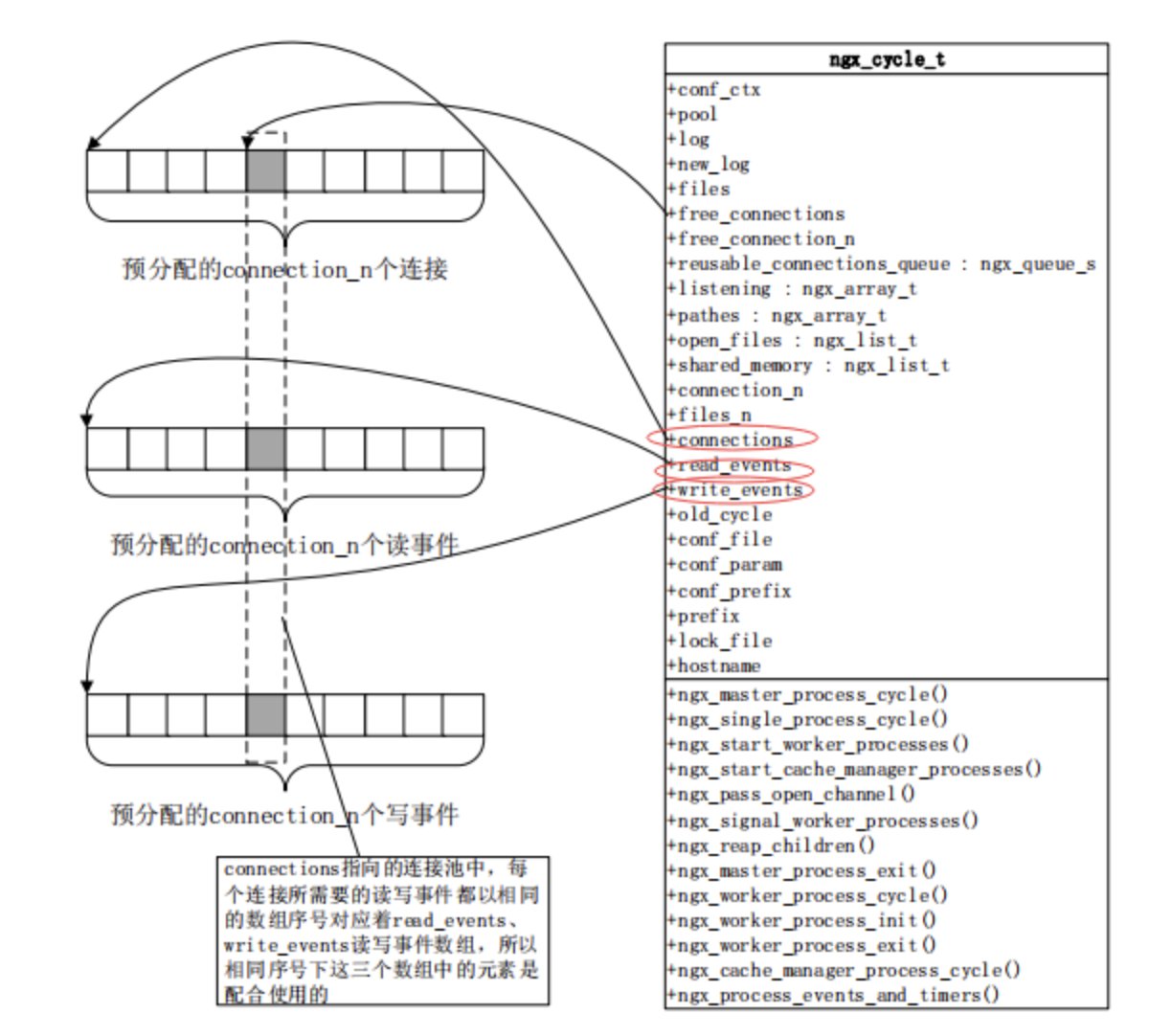
/*
其中connections這就是我們所謂的連接池,他指向我們這個數組有多大尼,可以看下有一個配置項:
*/
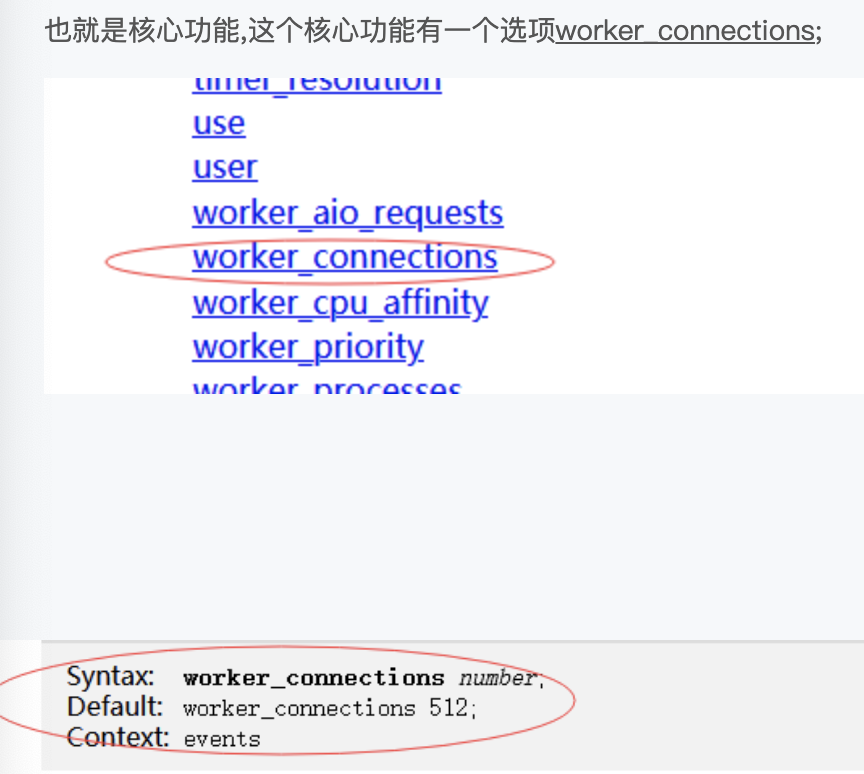
默認會有一個512大小的數組,這裡的每一個數組就是一個連接,可以看到512其實是非常小的,因為我們nginx動則處理萬,十萬,百萬級的計算,所以我們往往是需要去修改的;而且官方提示很清楚,這個連接不止去用於客戶端的連接,也用於面向上有服務器的連接,所以如果我們做反向代理的時候,每個客戶端意味着消耗我們兩個connections;
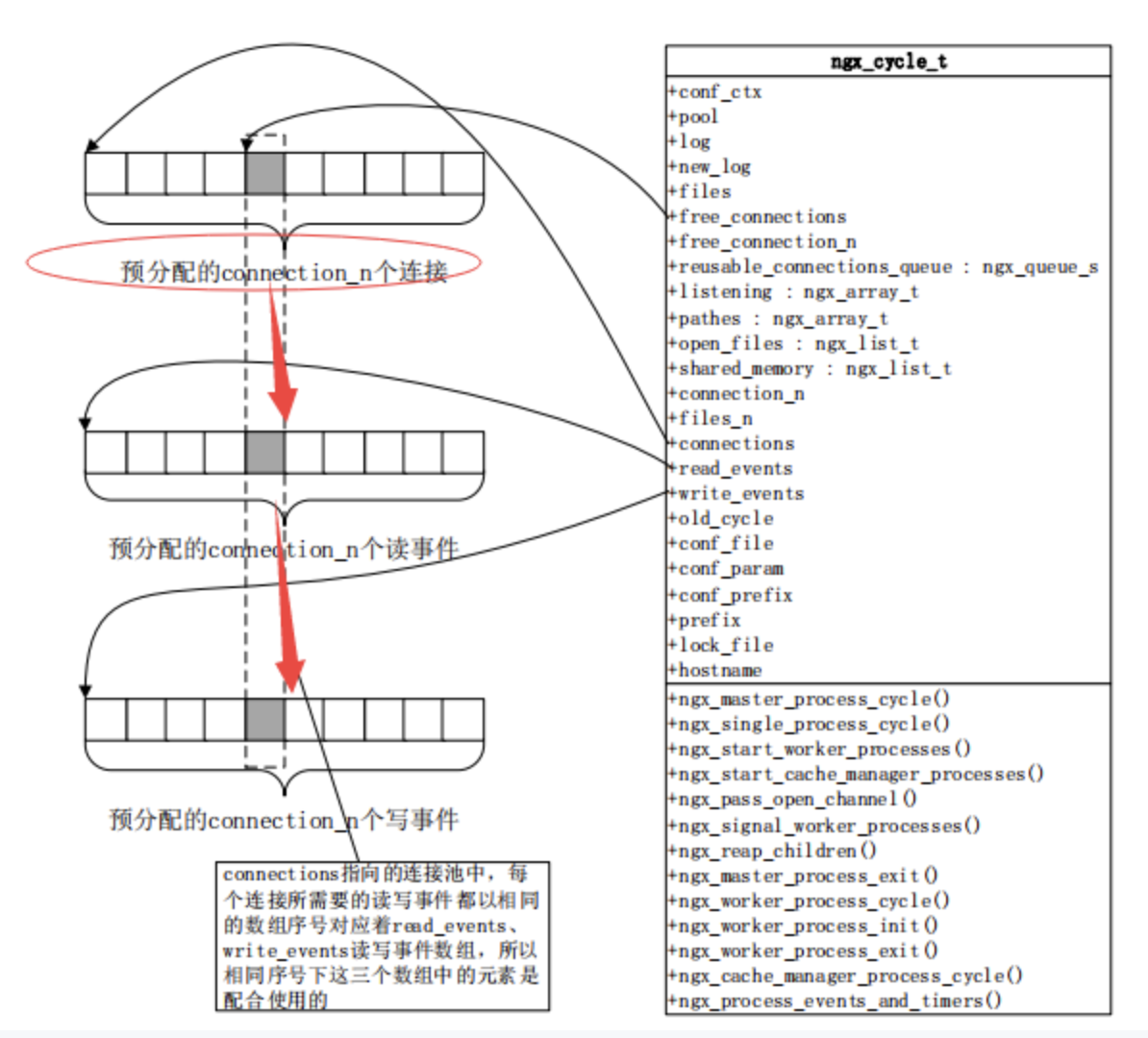
每一個連接自動的對應一個讀事件和一個寫事件,所以在ngx_cycle_t中還有個write_event_s;它們指向的數組的大小也跟worker_connections這個配置是一樣的;所以connections連接事件,讀事件,寫事件是通過序號對應起來的;所以我們在考慮nginx能夠釋放多大性能的時候,首先要保證worker_connections足夠我們使用;但是worker_connections所指向的數組,同時影響了我們所打開的內存,當我們配置了更大的worker_connections的時候,也就意味着nginx使用了更大的內存;所以每一個connections連接到底使用了多大的內存尼? 我們可以看一下,每一個ngx_connection_s這樣的一個結構體在64位操作系統中它佔用的位元組數大約是232位元組;具體會因nginx版本不同,可能會有微小的差異; 每一個ngx_connection_s這樣的一個結構體它對應着兩個事件,一個讀事件,一個寫事件,我們之前談到網絡事件談到了它的許多特性; 那麼在nginx中每一個事件對應一個結構體叫做ngx_event_s;每個事件對應的結構體它所對應的位元組數是96位元組; 所以我們在使用一個連接的時候它大概消耗的位元組為(232+96)*2;我們的worker_connections配置的越大,那麼初始化的時候就會預分配這麼多的內存;
ngx_event_s裏面有哪些成員尼?
這裡我們比較關注的是handler這是一個回調方法;也就是說很多第三方模塊會把這個handler設置為自己的實現;這裡還有個timer,也就是說當我們對http請求做讀超時和寫超時時候等等設置的時候,其實是在操作讀事件和寫事件中的tmer;這個timer其實就是nginx實現超時定時器,也就是基於rbtree中的紅黑樹去實現的結構體;這裡定時器其實也是可配的,這裡我們看下它的配置;
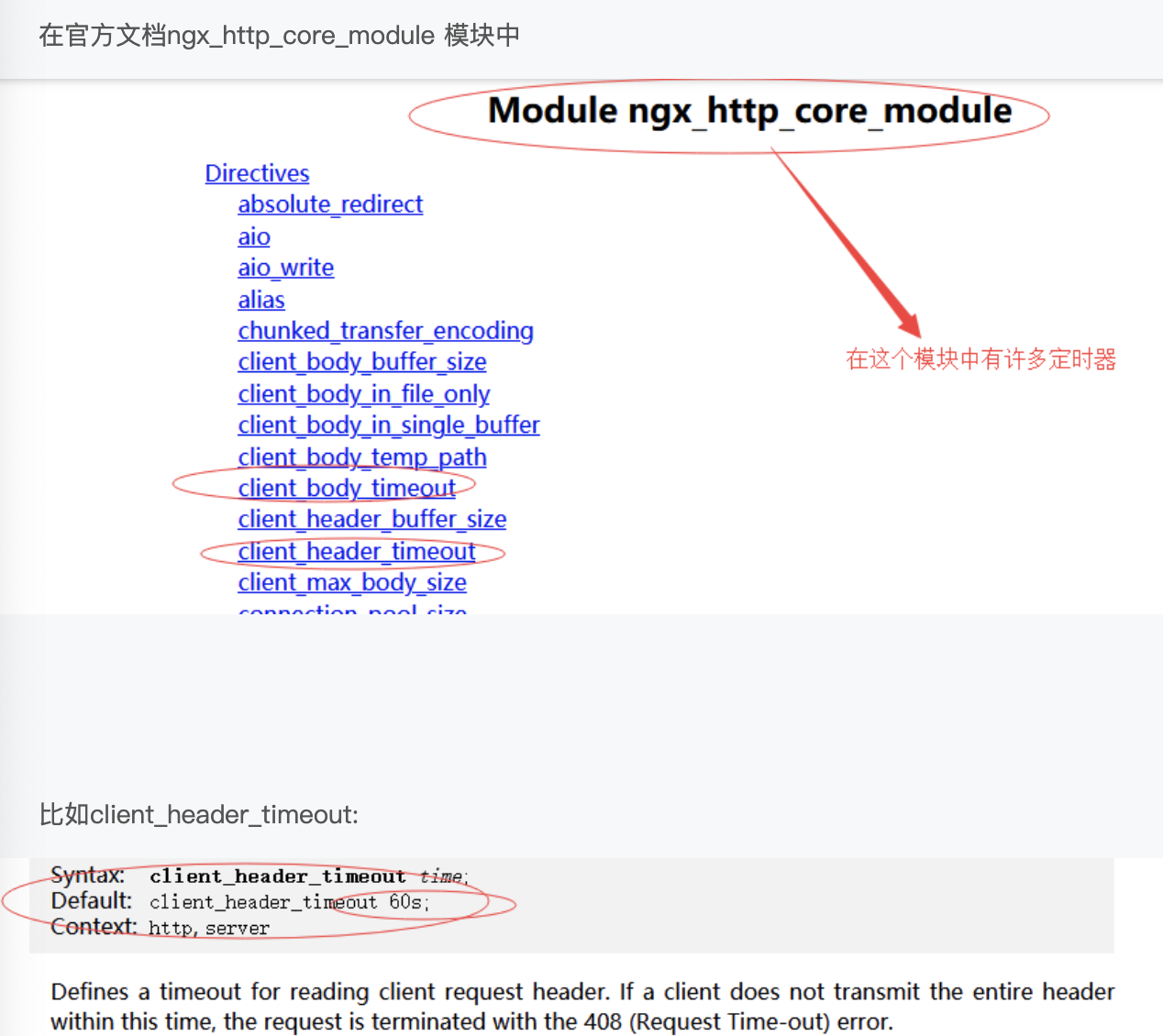
默認設置為60s,其實這個60s也就是在我們剛剛某個連接上,在準備讀它的header時,我們在它的讀事件上添加個60s的定時器;
當多個事件形成隊列的時候我們可以使用ngx_queue_t;
我們再來看下ngx_connections_s 每個連接有些什麼樣的成員?
read 和 write分別是它的讀寫事件;
recv和send是它的一個抽象的操作系統的底層方法;怎麼樣發送和接受;
這裡還有一個變量叫sent (off_t:表示無符號的整型)它表示這個連接上已經發送了多少位元組,也就是在配置中經常使用到的
$bytes_sent還是在ngx_http_core_module 模塊中 我們先找到它的內置變量;

$bytes_sent:它表示向客戶端發送了多少位元組;通常在access.log記錄nginx處理了哪些請求中我們可以記錄這麼一個變量,我們在ngixn.conf配置中添加了這麼一個變量
小結
/*
當我們需要配置高並發的nginx的時候,必須把connections的數目配置的足夠大,而每個connections將對應兩個event,
都會消耗一定的內存,還有nginx的許多結構體中,它們的一些成員和我們的內置變量是可以對應起來的;
*/
內存池對性能的影響
如果你開發過nginx的第三方模塊,雖然我們在寫C語言代碼,但是不需要關心內存的釋放,如果你現在在配置一些罕見場景的nginx的時候,你可能會需要去修改nginx在請求和連接上初始分配的內存池大小,但是nginx官方上推薦通常不需要修改這樣的配置,那麼我們究竟要不要修改這些內存池的大小尼?
下面我們來看下 內存池 究竟是怎麼運轉的?
在上講中我們看到一個結構體ngx_connection_s也就是每一個連接需要這麼一個結構體;而這個結構體中,有一個成員變量pool;
它對應着這個連接所使用的內存池
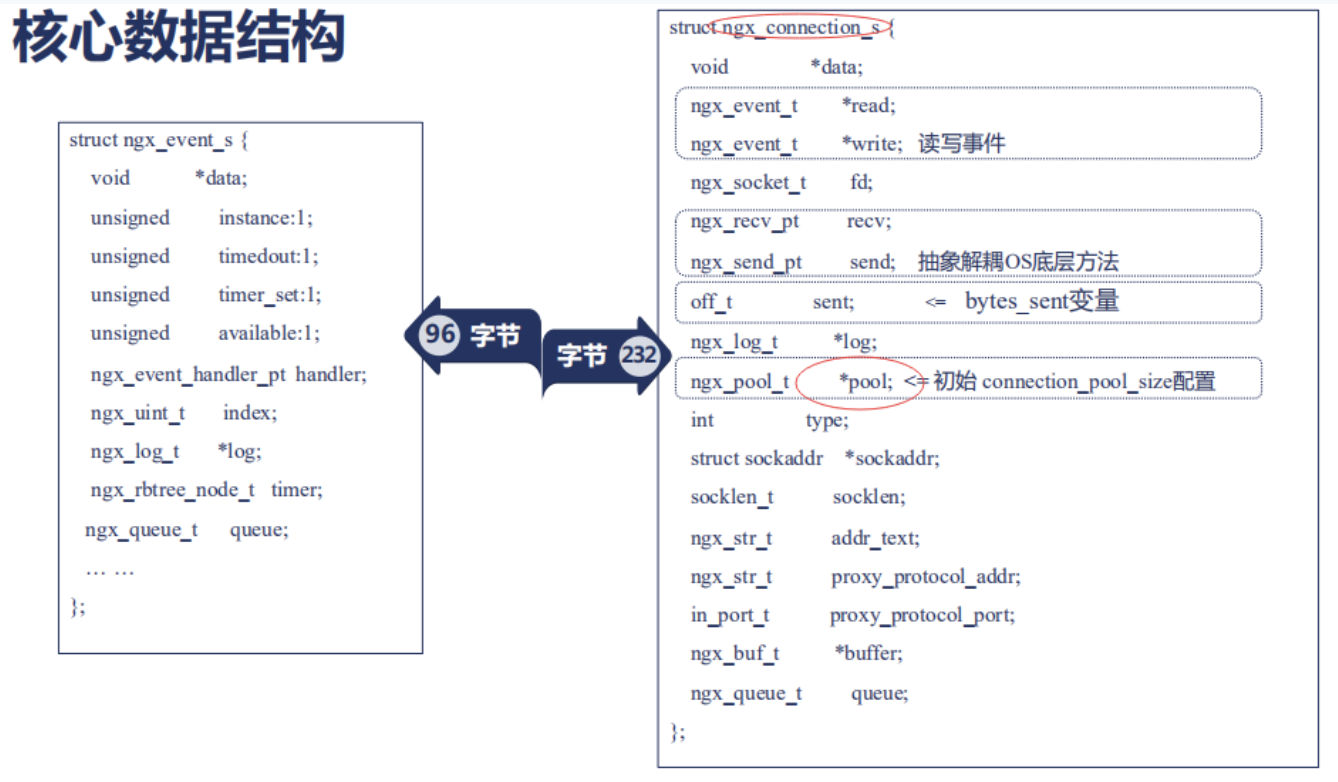
這個內存池可以通過一個變量connection_pool_size配置來定義,那麼為什麼我們需要內存池尼?
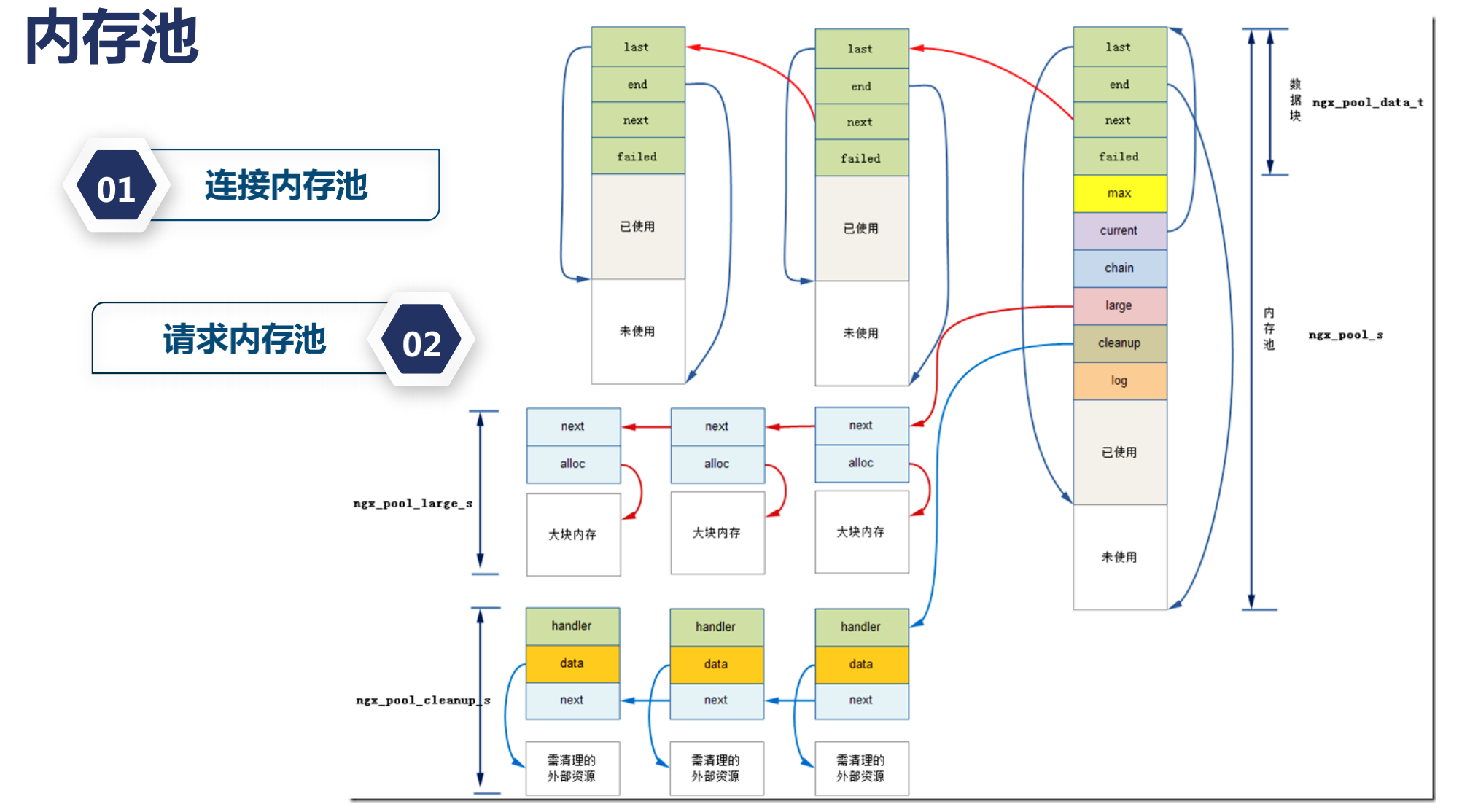
如果有一些工具的話,我們會發現,nginx它所產生的內存碎片是非常小的;這就是內存池的一個功勞,那麼內存池尼它會把內存提前分配好一批,而且當我們使用小塊內存的時候,每次我們使用的小塊內存的時候,它會使用last,end,next,failed一個個連接在一起,每次我們使用的東西比較小的時候尼,在第二次再分配小塊內存,它還會再進行連接一起,這樣就大大減少了我們的內存碎片,當然當我們分配大塊內存的時候尼,會走操作系統的 alloc模塊.
對於Nginx有什麼好處尼?
因為它主要在處理WEB請求,WEB請求特別是對http請求;它有兩個非常明顯的特點就是每當我們有個tcp連接的時候,這個tcp連接上面可能會有很多http請求;也就是所謂的http keepalive請求,連接沒有關閉;執行完一條請求以後 還負責執行另外一條請求;那麼有一些內存尼 我為連接分配一次就夠了;比如說我去讀取每一個請求的前1k位元組;在連接內存池上我分配一次;只要這個連接不關閉,那麼這個1k的內存我永遠不要釋放;什麼時候需要釋放尼?連接關閉的時候我再釋放,沒有任何問題;
請求內存池尼?每一個http請求我開始分配的時候尼,我不知道分配多大,但是http請求特別是http1.1而言,通常我們會分配4k大小的內存;因為我們的url或者header需要分配這麼多;如果沒有內存池尼,我們可能需要頻繁的分配(小塊的分配);而分配內存池尼,我們是有代價的;如果我們一次性的分配較多的內存尼,就沒有這樣的問題;而請求執行完畢以後,哪怕連接我們還可以復用;我們也可以把請求內存池給銷毀;而這樣所有的nginx第三方模塊開發者就不需要去關注你村什麼時候去釋放;它只需要關注它是從請求內存池裏面申請分配的內存;還是從連接內存池裡申請分配的內存;只要這個邏輯講的通;比如說請求結束以後,連接人想繼續使用,你可以在連接內存池裡分配;
可以看下具體例子: ngx_http_core_module這個模塊
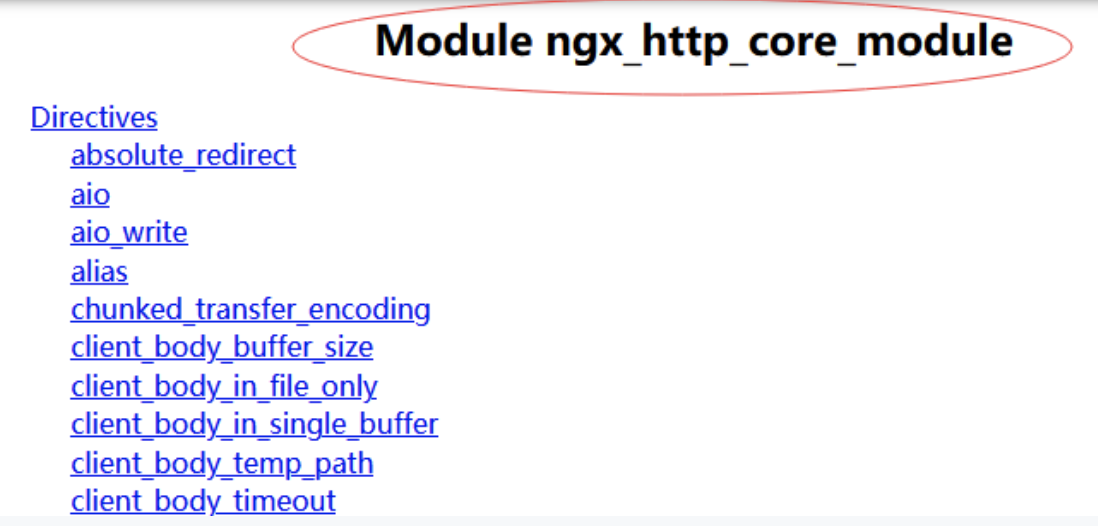
裏面有個connection_pool_size點開以後他默認是256或512
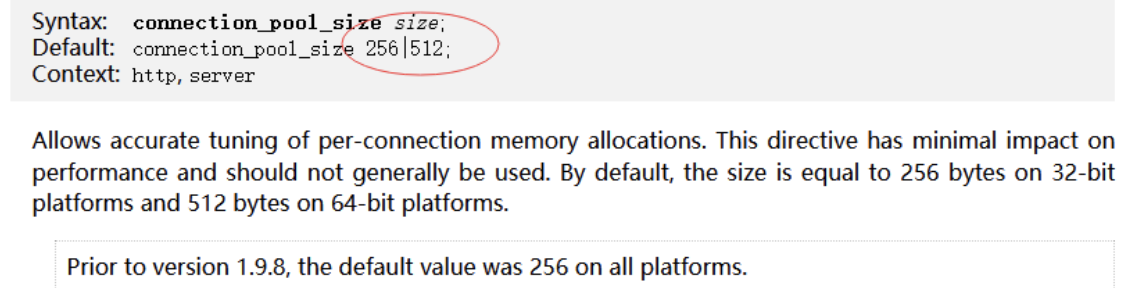
這跟我們的操作系統位數有關的.
內存池配置512並不是代表這裡我們只能分配512的位元組.
當我們分配的內存超過預分配大小時候,還是可以繼續分配的,這裡只是說我們提前預分配了足夠大小的空間可以減少我分配內存的次數.
那麼我們再看另外一個配置叫request_pool_size
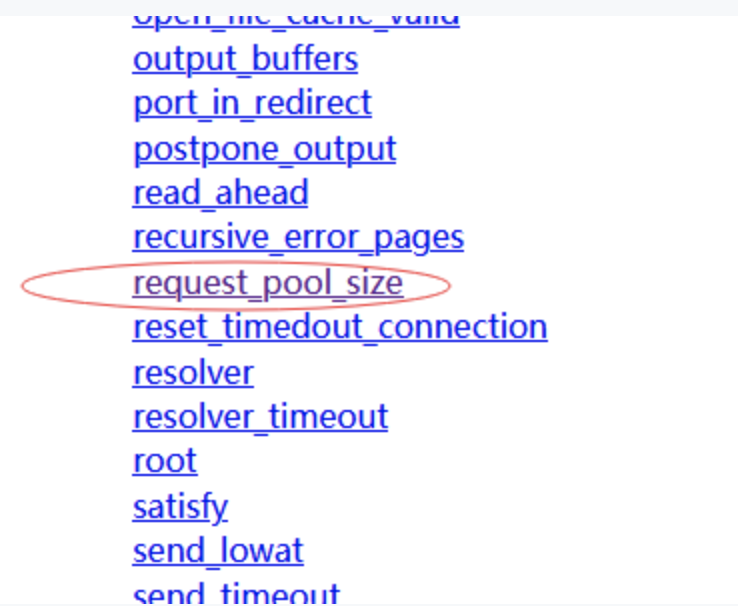

也就是每一個請求的內存池的大小,我們這裡可以看到他的默認大小是4k; 為什麼會差距這麼大尼?
之所以會差距8倍,那是因為對連接而言,它需要保存的上下文信息非常的少;它只需要幫助後面的請求,讀取最初一部分位元組就行了,而對於請求而言,我們需要保存大量的上下文信息,比如說所有讀取到的url或者header我需要保存下來,url通常還比較長,所以我們需要4k的大小;當然官方文檔中說 它對性能的影響比較小,如果我們在極端場景下,如果你的url特別大,可以考慮把這個值分配的更大,通常來說你是很小內存的,url特別小,header也非常少,可以考慮將這個值降低一些,這樣nginx消耗的內存會小一些;也意味着可以做更大並發量的請求;
總結
以上我們介紹了內存池的原理,以及請求內存池和連接內存池,它們的配置代表了怎麼樣的意義,內存池對減少我們內存碎片,對第三方模塊的快速開發,是有很大意義的;可能有些第三方模塊不當使用了內存池,比如本該在請求內存池裡分配內存,卻在連接內存池裡連接內存;可能會導致內存的延期釋放,導致nginx的內存無謂的增加;這需要我們注意;
nginx共享內存

nginx的進程間的通訊方式主要有兩種
1 . 第一種是信號,之前我們在說如何管理Nginx的過程中已經有比較詳細的介紹過了:
2 . 共享內存: 如果需要做數據的同步,只能通過共享內存,所謂共享內存,也就是我們打開了一塊內存,比如說10M,一整塊0到10M之間,多個worker進程之間可以同時的訪問他; 包括讀取和寫入,那麼為了使用好這樣一個共享內存就會引入另外兩個問題;第一個問題就是鎖, 因為多個worker進程同時操作一塊內存,一定會存在競爭關係;所以我們需要加鎖,在Nginx的鎖中,在早期,它還有基於信號量的鎖,信號量是nginx比較久遠的進程同步方式,它會導致你的進程進入休眠狀態;也就是發送了主動切換;而現在大多數操作系統版本中,nginx所使用的鎖都是自旋鎖,而不會基於信號量;自旋鎖也就是說當這個鎖的條件沒有滿足比如說,這塊內存現在被1號worker進程使用,2號worker進程需要去獲取鎖的時候,只要1號進程沒有釋放鎖,2號進程會一直請求這把鎖,就好像如果是基於信號量的早期的nginx鎖,那麼假設這把鎖鎖住了一扇門,如果worker進程1已經拿到了這把鎖進到屋裡,worker進程2是試圖拿鎖,敲門,發現裏面已經有人了,那麼worker進程2就會就地休息;等待worker進程1從門裡出來以後通知它,而自旋鎖不一樣,那麼worker進程2發現屋裡已經有worker進程1了;它就會一直持續的去敲門,所以使用自旋鎖要求所有的nginx模塊,必須快速地使用共享內存,也就是快速的取得鎖以後,快速的釋放鎖,一旦發現有第三方模塊不遵守這樣的規則,就可能會導致出現死鎖或者說性能下降的問題;那麼有了這樣的一塊共享內存;會引入第二個問題;因為一整塊共享內存是往往是給許多對象同時使用的;如果我們在模塊中手動的去編寫,分配把這些內存給到不同的對象,這是非常繁瑣的;所以這個時候 我們使用了Slab內存管理器;
那麼Nginx那些模塊使用了共享內存尼?
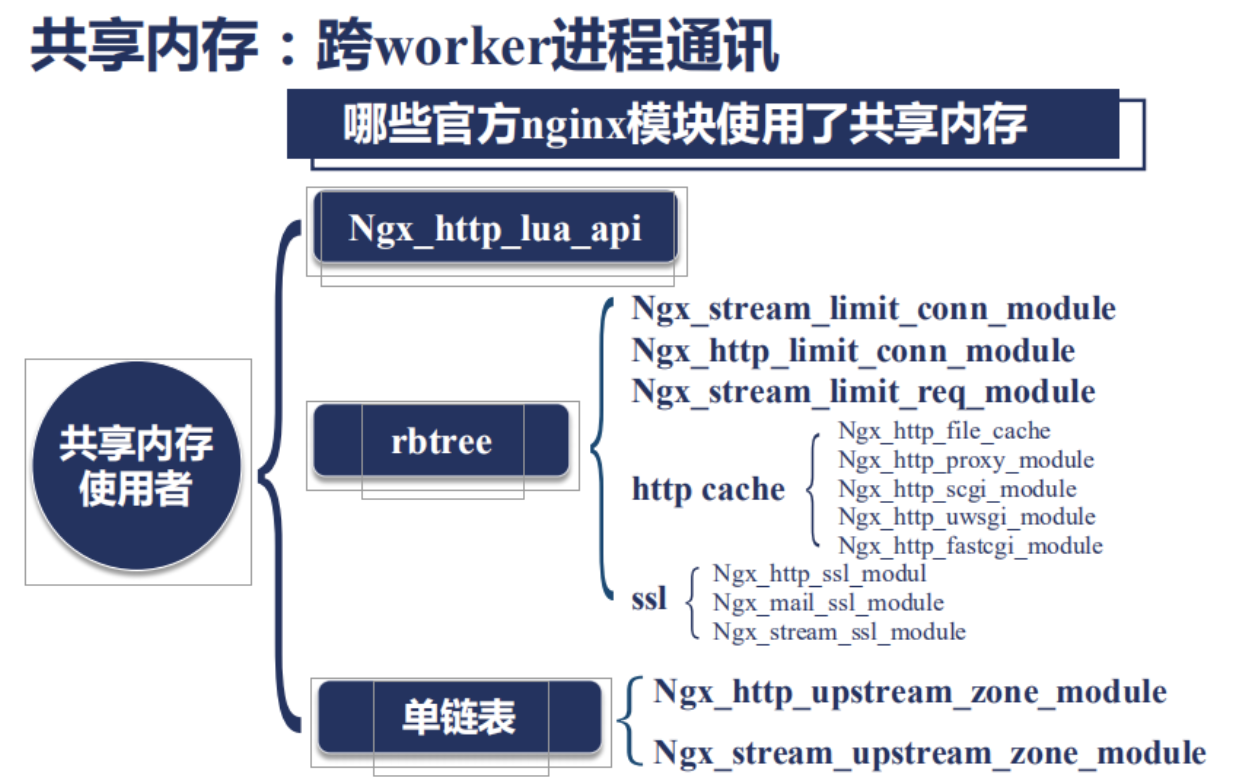
使用共享內存主要使用了兩種數據結構:
1 . Rbtree: 紅黑樹, 比如我們想做限速和流控等等場景時,我們是不能容忍在內存中做的, 否則一個worker進程對某一個用戶觸發了流控,而其他worker進程還不知道,所以我們只能在共享內存中做; 紅黑樹有一個特點: 就是他的插入刪除非常的快,當然也可以做遍歷,所以如下模塊有一個特點: 需要做快速的插入和刪除:

比如我發現了一個客戶端我對他限速,限速如果達到了,我需要他從我的數據結構容器中移除,都需要非常的快速.
那麼第二個常用的數據結構是單鏈表,也就是說我只需要把這些共享的元素串聯起來就可以了,比如:

我們來看個非常複雜的例子就是: ngx_http_lua_api
ngx_http_lua_api 這個模塊其實是openresty的核心模塊;openresty在這個模塊中定義了一個SDK,這個SDK叫lua_shared_dict;當這個指令出現的時候,它會分配一塊共享內存;比如說這裡我們分了10m;這個共享內存會有一個名稱叫做 dogs;

接下來我們在lua代碼中,比如content_by_lua_block;對應着我們nginx收到了 set這個url的時候;需要做一些什麼樣的事情,我們首先從dogs共享內存中取出;然後設置了一個key-value; Jim-8;然後向客戶端返回我已存儲;
然後在get請求中我們把Jim的值8取出來;返回給用戶;
那麼在這一段代碼中尼,我們同時使用了我們剛剛使用的紅黑樹和單鏈表 那麼這個lua_shared_dict dogs 10m中使用紅黑樹來保存每一個key-value;紅黑樹中每一個節點就是Jim它的value就是8;那麼為什麼我還需要一個鏈表尼?是因為這個10m是有限的;當我們的Lua代碼涉及到了我們的應用業務代碼;很容易就超過了10m的限制;當我們出現10m限制的時候尼,會有很多種處理方法;比如讓它寫入失敗;但是lua_shared_dict 採用了另外一種實現方式它用lru淘汰;也就是我最早set,最早get 長時間不用的那一個節點;比如前面還有Jim等於7或者等於6的節點;會優先被淘汰掉;當已經達到10m的最大值時;所以這個lua_shared_dict同時滿足了紅黑樹和鏈表;
共享內存是nginx跨worker進程通訊的最有效的手段;只要我們需要讓一段業務邏輯在多個worker進程中同時生效;比如很多在做集群的流控上;那麼必須使用共享內存;而不能在每一個worker內存中去操作;
Slab管理器
剛剛我們談到nginx不同的worker進程間需要共享信息的時候,需要通過共享內存;我們也談到了共享內存上可以使用鏈表或者紅黑樹這樣的數據結構;但是每一個紅黑樹上有許多節點;每一個節點你都需要分配內存去存放;那麼怎麼樣把一整塊共享內存切割成一小塊給紅黑樹上的每一個節點使用尼?
下面我們來看下Slab內存分配管理是怎麼樣應用於共享內存上的;首先我們來看下Slab內存管理是怎麼樣的一種形式;
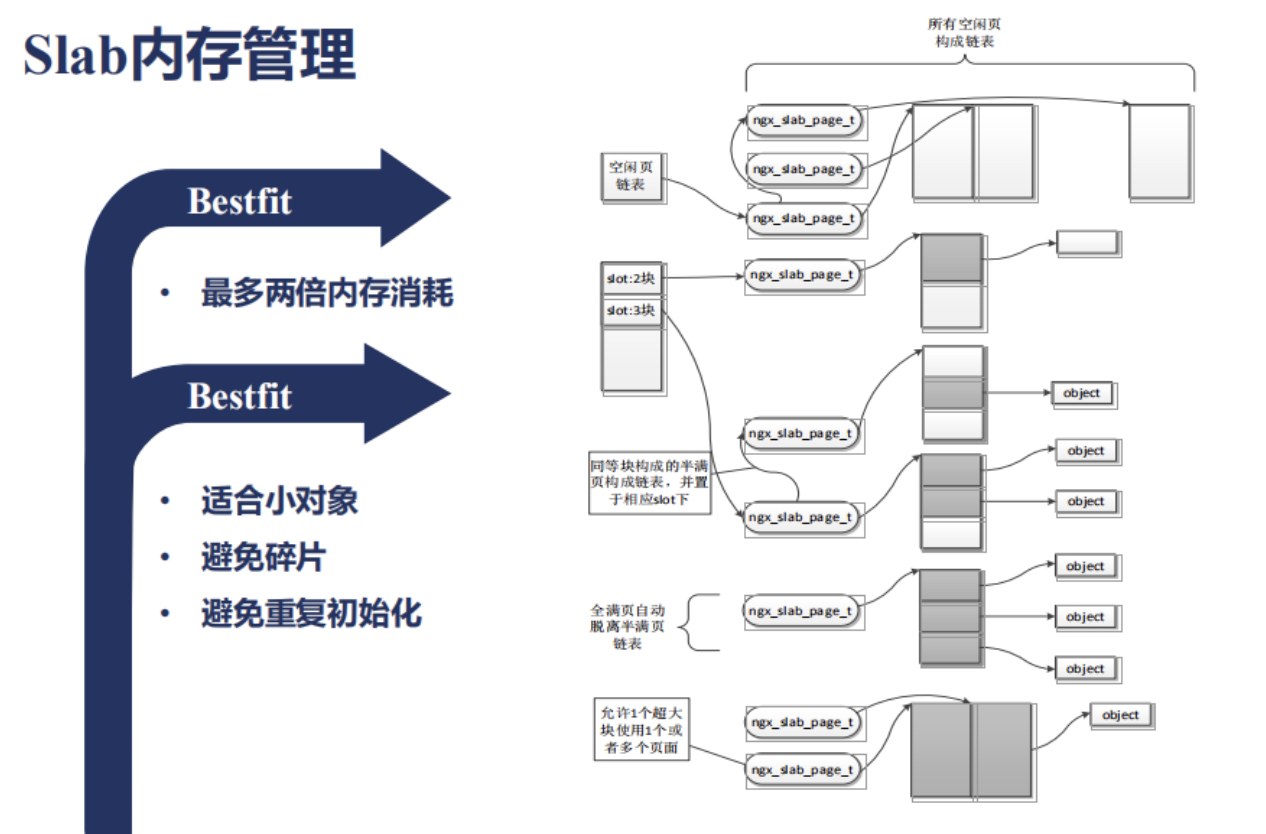
它首先會把整塊的共享內存分為很多頁面;那麼每個頁面例如4k;會切分為很多slot;比如32位元組是一種slot;64位元組又是一種slot;128位元組又是一種slot;那麼這些slot是以乘2的方式向上增長的;如果現在有一個51位元組需要分配的內存會放到哪裡尼?會放於小於它最大的一個slot的一個環節;比如說64位元組;所以上圖中slot就是指向不同大小的塊;所以這樣的一種數據結構尼 它有一個特點;會有內存的浪費的;就像我們剛剛所說的;51位元組它會用64位元組來存放;那麼其它的13位元組就浪費了;那麼最多會有多少內存消耗尼?會有兩倍;這種使用的方式叫做Bestfit;Bestfit這種分配內存的方式有什麼好處尼?它適合小對象;如果我們要分配的對象的內存非常小,比如小於一個頁面的大小,就非常合適;因為它很少有碎片,那麼每分配一塊內存,就會沿着還未分配的空白的地方繼續使用就可以了;當一個頁面使用滿以後,我再拿一個空白的頁面繼續給此類slot大小的內存繼續使用就可以.那麼有時候我分配在某段內存上的數據結構它是固定的,甚至需要初始化;那麼這樣的話,原先的數據結構都還在;當我重複使用的話,也避免了初始化;Slab內存管理中,我們怎麼做數據的監控和統計尼?
那麼tng上有一個模塊叫做slab_stat;slab_stat可以幫我們看不同的slot;
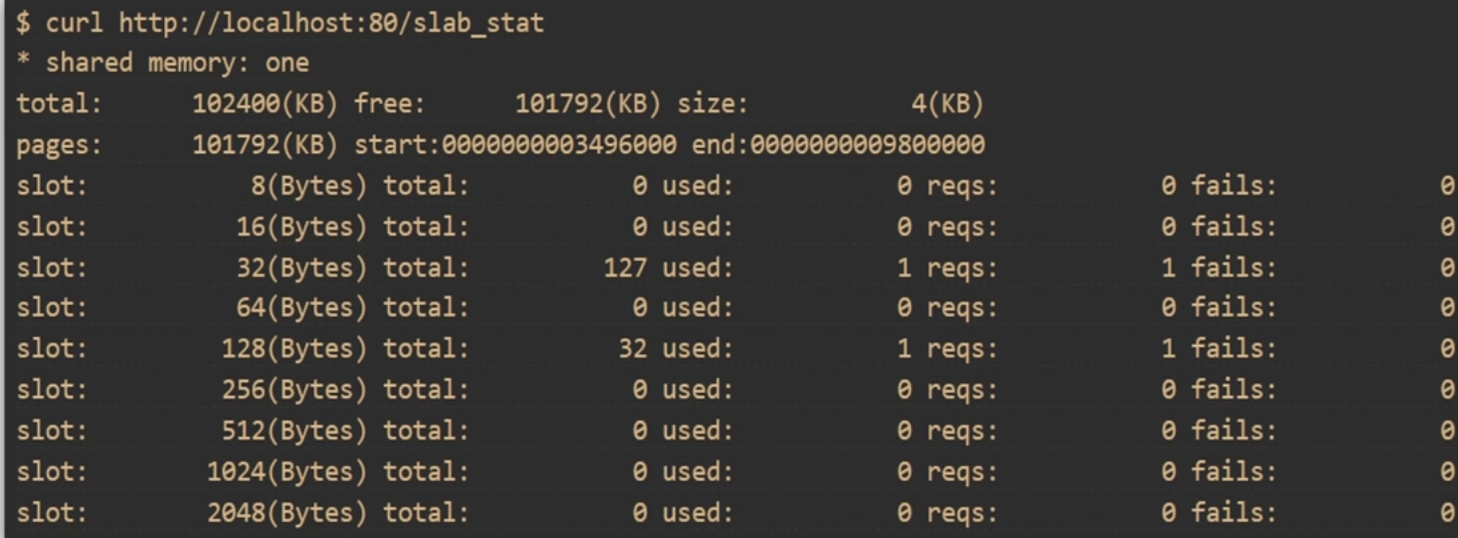
比如說:8位元組 16 位元組 。。。。等等;
一共目前分配了多少,使用了多少,有多少個請求在訪問,失敗了多少次,這個對我們來監控Slab是非常有用處的;
下面我們來看下怎麼樣在openresty的場景下去使用tng上的slab_stat這個模塊;
首先我們打開tengine的頁面 //tengine.taobao.org/document/ngx_slab_stat.html
但是會發現在這個模塊上沒有github的地址;也就是說它沒有作為一個獨立的模塊提供出來;那這個時候該怎麼辦尼?
那麼tengine怎麼下載下來?從download里;
[root@server ~]# wget //tengine.taobao.org/download/tengine-2.2.3.tar.gz
[root@server ~]# tar xf tengine-2.2.3.tar.gz
[root@server ~]# cd openresty-1.13.6.2/
[root@server openresty-1.13.6.2]# ./configure --add-module=../tengine-2.2.3/modules/ngx_slab_stat/
[root@server openresty-1.13.6.2]# make
[root@server openresty-1.13.6.2]# cp build/nginx-1.13.6/objs/nginx /usr/local/openresty/nginx/sbin/nginx
nginx.conf
[root@server nginx]# cat conf/nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
lua_shared_dict dogs 10m;
server {
listen 8090;
server_name localhost;
location = /slab_stat{
slab_stat;
}
location /set {
content_by_lua_block {
local dogs = ngx.shared.dogs
dogs:set("Jim",8)
ngx.say("STORED");
}
}
location /get {
content_by_lua_block {
local dogs = ngx.shared.dogs
ngx.say(dogs:get("Jim"));
}
}
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
測試
[root@server nginx]# curl localhost:8090/set
STORED
[root@server nginx]# curl localhost:8090/get
8
[root@server nginx]# curl localhost:8090/slab_stat
* shared memory: dogs
total: 10240(KB) free: 10168(KB) size: 4(KB)
pages: 10168(KB) start:00007F7A4C7FE000 end:00007F7A4D1EE000
slot: 8(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 16(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 32(Bytes) total: 127 used: 1 reqs: 1 fails: 0
slot: 64(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 128(Bytes) total: 32 used: 2 reqs: 2 fails: 0
slot: 256(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 512(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 1024(Bytes) total: 0 used: 0 reqs: 0 fails: 0
slot: 2048(Bytes) total: 0 used: 0 reqs: 0 fails: 0
/*
配置項寫完,把nginx啟動看他的執行效果;
每一個slot及其slot對應的大小; 分配了多少個,使用了多少個,失敗了多少個.
所謂分配就是10m是一個非常大的內存,他會劃分很多歌頁面; 對於比較小的比如32位元組,一個頁面可以有128個, 這裡127可用,已經使用了一個.
*/
總結
/*
以上我們介紹了Slab內存的使用方法; slab使用了Bestfit思想,他也是Linux操作系統經常使用的內存分配方式;
那麼通暢我們在使用共享內存時, 都需要使用slab_stat去分配相應的內存給對象,再使用上層的數據結構維護這些數據對象;
*/
哈希表的max_size與bucket_size如何配置
nginx容器
/*
數組
鏈表
隊列
哈希表
紅黑樹
基數樹
*/
哈希表
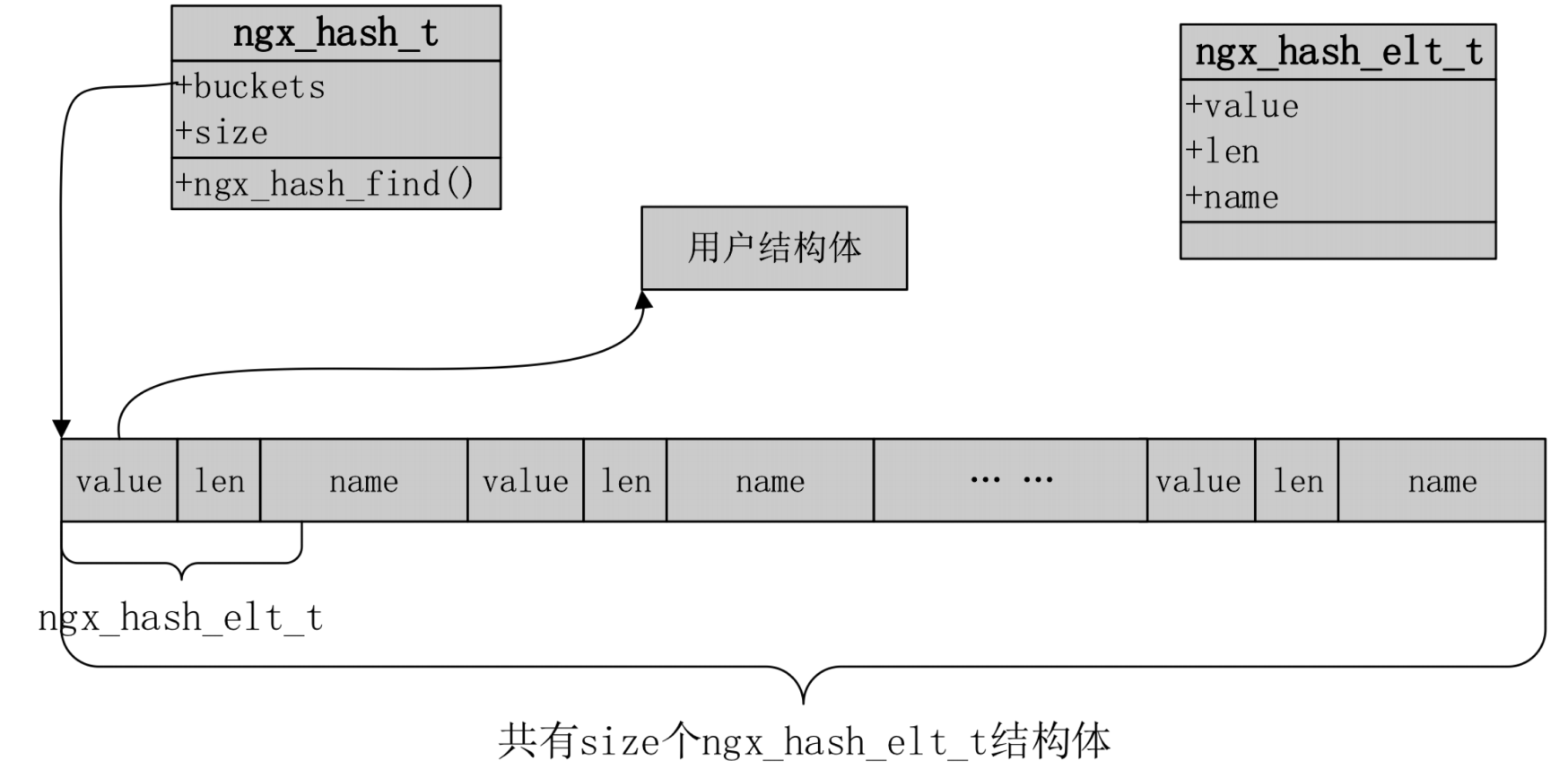
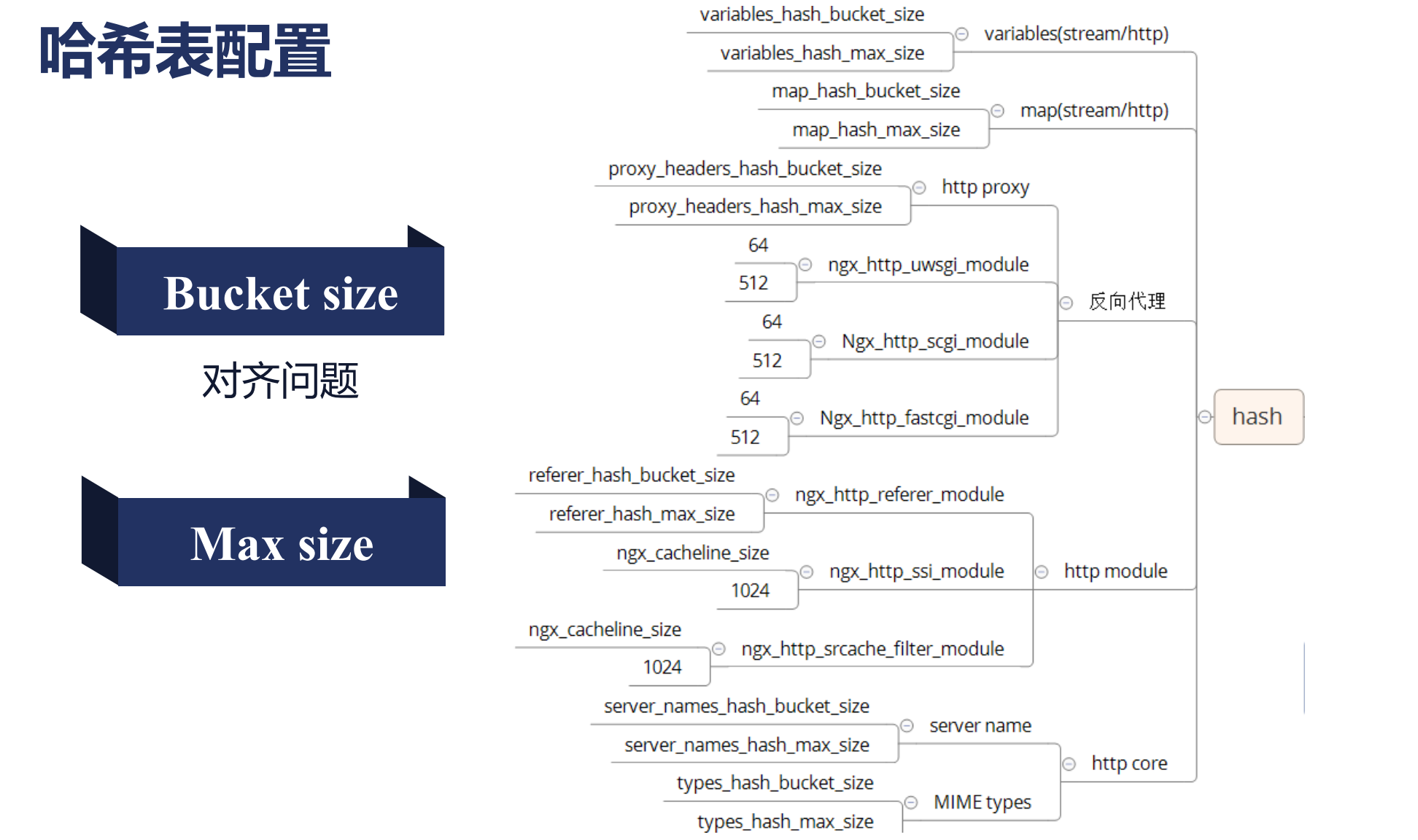
nginx哈希表僅用於靜態不變的內容,nginx啟動時候就能確定這個哈希表裏面有多少個元素,所以,當使用哈希表這些模塊會暴露出bucketsize,maxsize, 我們的bucketsize僅僅控制了最大哈希表bucketsize的個數,而不是實際個數, max size意義在於限制最大化的使用.
nginx紅黑樹
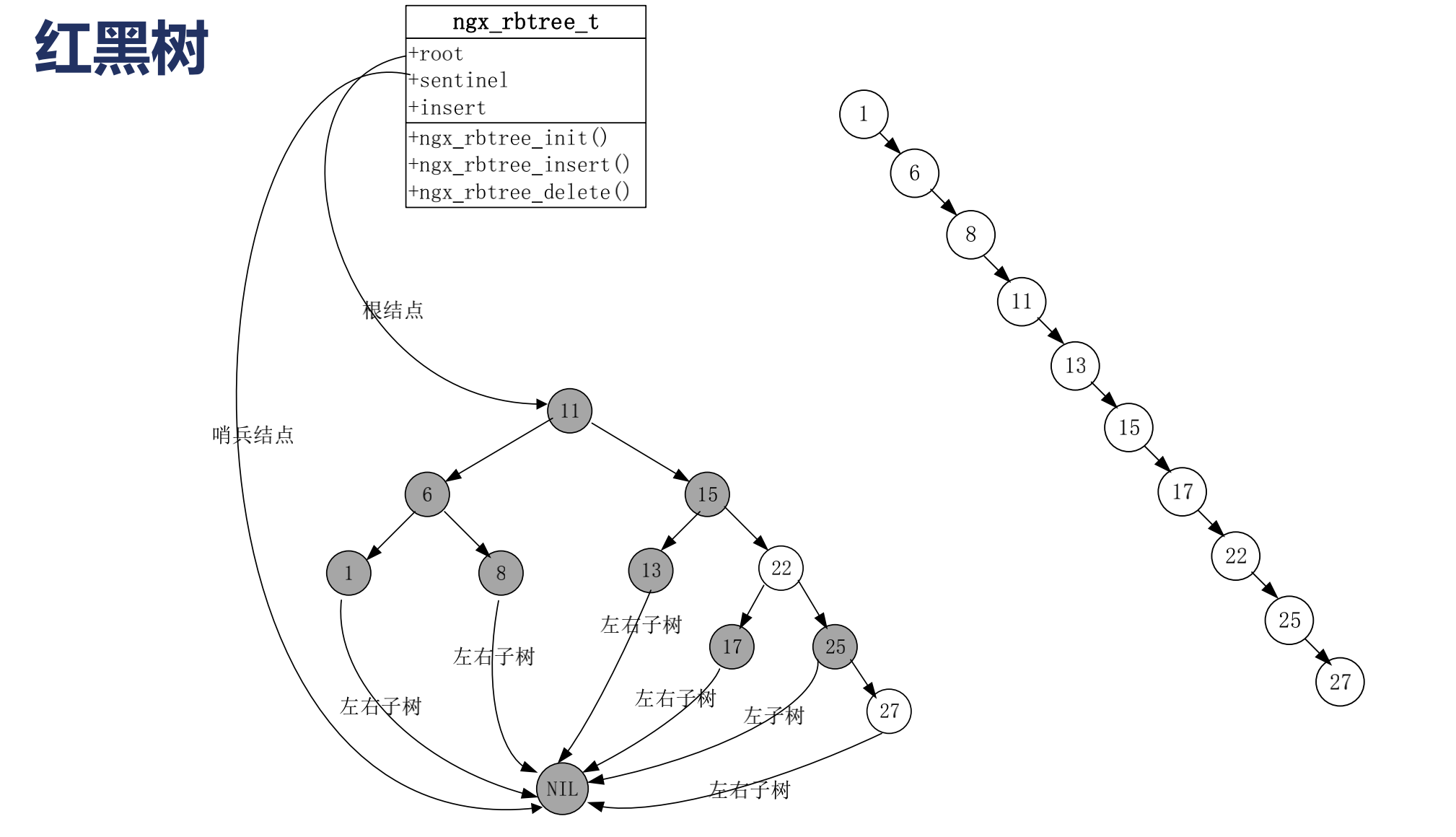
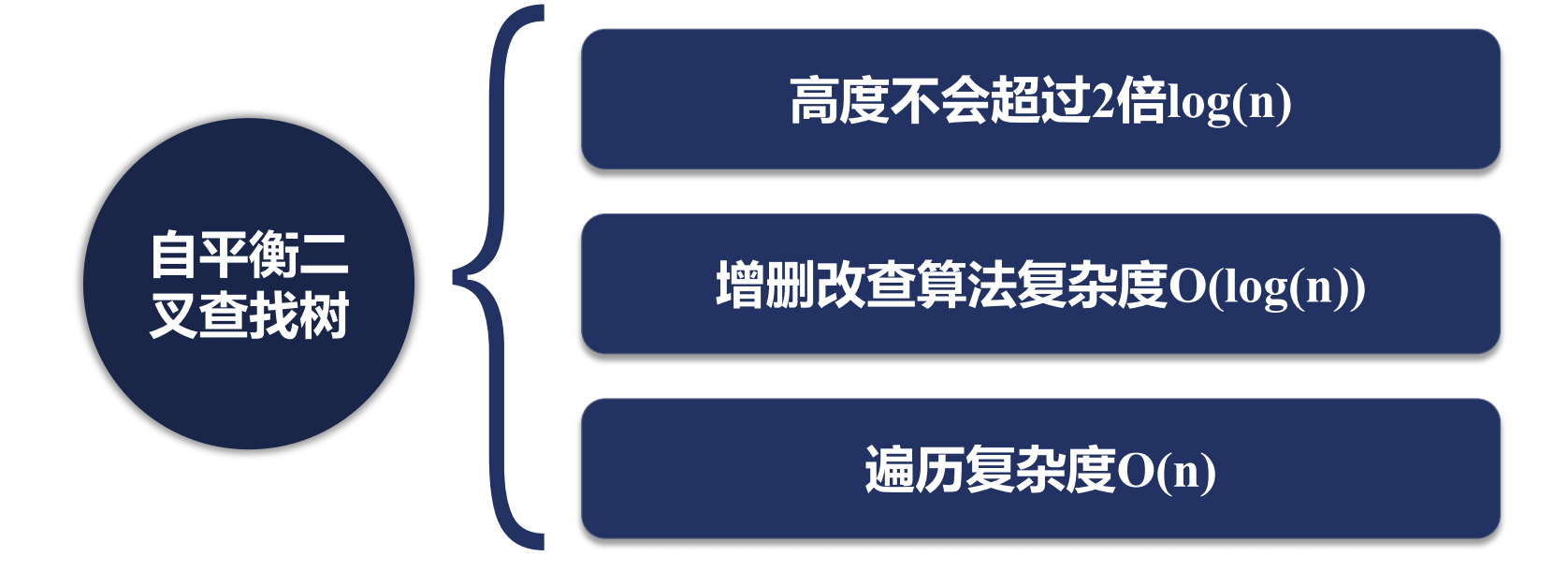

/*
nginx內存中會大量使用紅黑樹,它是一個二叉樹.同時是一個查找二叉樹,他有可能退化為一個鏈表,
使用了紅黑樹的模塊,再增刪改查是非常快的.
*/
nginx動態模塊提升運維效率
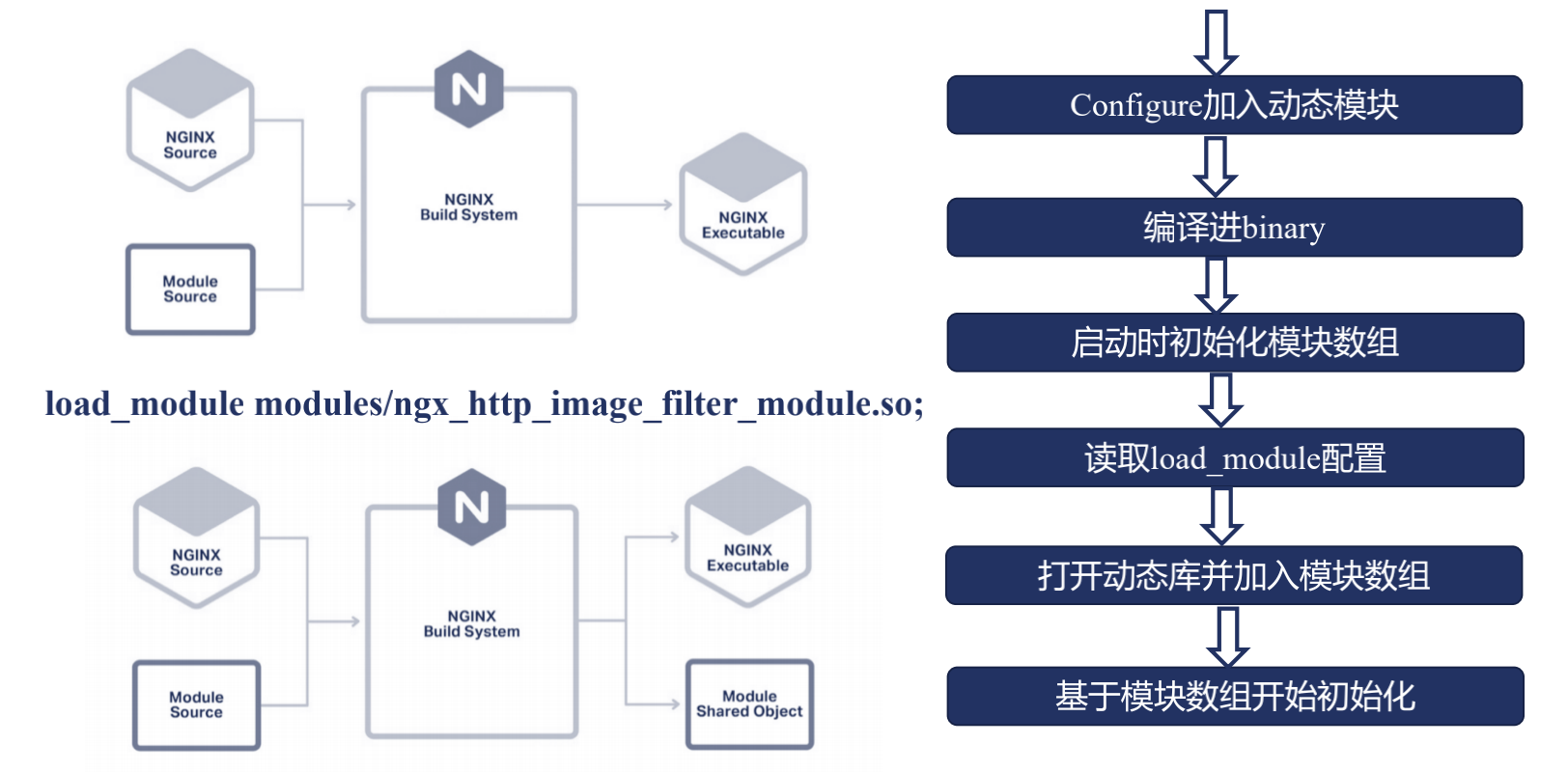
我們在使用動態模塊之前,先來看下在不適用動態模塊的方法里,我們是怎麼樣使用Nginx;
首先我們在下載完nginx的源代碼,提供了一個叫config的腳本,以及在源代碼中介紹的auto目錄;這裡都在幫助nginx在建立編譯系統;那麼nginx源代碼中提供了很多官方模塊,但我們也可能添加許多的第三方模塊,不管是官方模塊還是第三方模塊,這些模塊的源碼都會和Nginx的框架源碼放到一起,進行編譯,最後編譯出一個nginx可執行文件;那麼這是不使用動態模塊的一種方式;
那麼使用了動態模塊尼?
我們在編譯的時候,指定了某些模塊,使用動態模塊的方式去編譯;那麼最後尼,除了生成nginx的二進制可執行文件,還會生成一個動態庫,也就是我們指定了模塊的那個動態庫;
動態庫和靜態庫有什麼區別?
靜態庫: 是直接把所有源代碼編譯進最終的二進制可執行文件中;
動態庫: 在nginx二進制可執行文件里,只保留了他的位置或者說地址,那麼我們需要這個動態庫的功能時尼, 由nginx的可執行文件去調用這個動態庫,再去完成這樣的功能, 所以這裡好處就表現為僅僅需要修改某一個模塊或者升級這個模塊功能時,特別是我們nginx編譯了大量第三方模塊,那麼這個時候,我們僅僅重新編譯這個動態庫,而不用去替換我的二進制文件,因為這裡很有可能會漏了或者多編譯進一些nginx模塊或者參數使用了錯誤, 而我編譯出新的動態庫以後,我只要替換掉這個動態庫,然後nginx -s reload一遍; 我就可以使用新的模塊功能了.
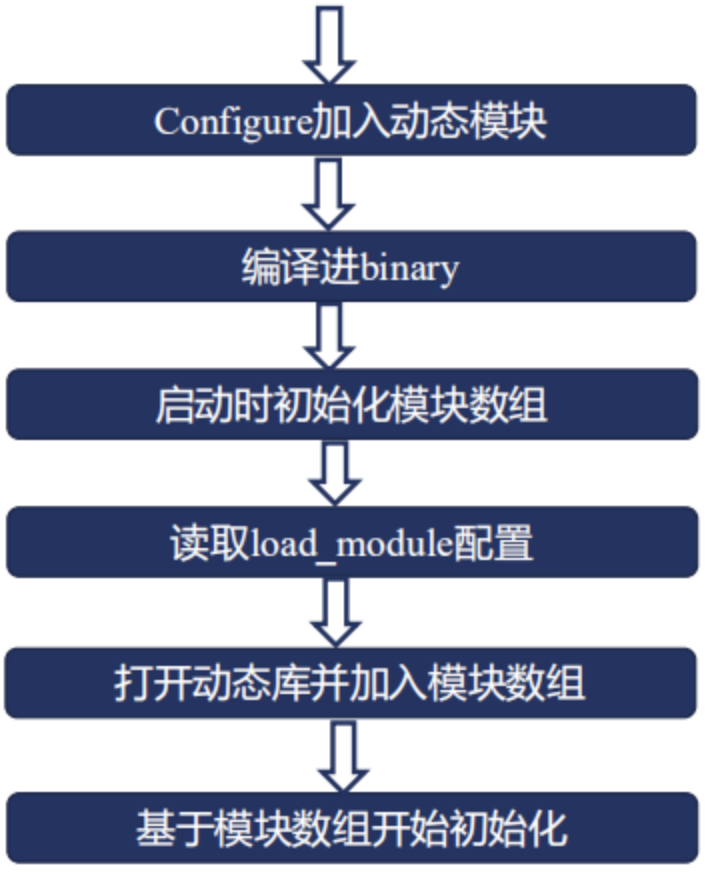
具體使用時候,分為6個步驟
1 . 首先,要在nginx源代碼加入configure加入動態模塊必須指明這個模塊是使用動態模塊方式編譯進nginx; 這裡有一個潛台詞,不是所有的nginx模塊都可以以動態模塊的方式加入到nginx中;只有一些模塊才可以以動態模塊的方式加入;
2 . 開始執行make,編譯出binary;
3 . 到第三步的時候,也就是說我們開始啟動nginx了;啟動nginx的時候尼我們去讀ngx_module里的數組;
4 . 讀到模塊數組中尼,我們發現了使用了一個動態模塊,接下來我們會看到一個nginx的conf中加入的一個配置項,這個配置項叫load_module配置;指明了這個 動態模塊所在的路徑;
5 . 那麼接下來我們就可以在nginx的進程中打開這個動態庫加入模塊數組,
6 . 最後再進行一個初始化的過程(基於模塊數組進程初始化);
這是動態模塊的一個工作流程,下面為一個簡單演示:
Example
[root@server nginx-1.14.2]# yum -y install libxml2 libxml2-dev yum -y install libxslt-devel gd-devel
[root@server nginx-1.14.2]# ./configure --prefix=/usr/local/nginx --with-http_image_filter_module=dynamic
[root@server nginx-1.14.2]# make
[root@server nginx-1.14.2]# mkdir /usr/local/nginx/modules
[root@server nginx-1.14.2]# cp objs/ngx_http_image_filter_module.so /usr/local/nginx/modules/
# 修改配置
[root@server nginx]# head -5 conf/nginx.conf
user root;
load_module modules/ngx_http_image_filter_module.so;
worker_processes 1;
events {
worker_connections 1024;
server {
listen 80;
server_name localhost;
location / {
root html;
image_filter resize 130 130;
}
}
# 重啟服務
[root@server nginx]# ./sbin/nginx -s reload
# 圖片變小了,說明image_filte模塊已經生效了;
# 使用了動態模塊,不需要刪除nginx 二進制文件,進行熱升級了,可以減少我們出錯的效率,但是並非所有的模塊都支持動態模塊的加載;