無所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]
- 2020 年 10 月 6 日
- 筆記
- Embeddinig
這一節我們來聊聊不定長的文本向量,這裡我們暫不考慮有監督模型,也就是任務相關的句子表徵,只看通用文本向量,根據文本長短有叫sentence2vec, paragraph2vec也有叫doc2vec的。這類通用文本embedding的應用場景有很多,比如計算文本相似度用於內容召回, 用於聚類給文章打標等等。前兩章我們討論了詞向量模型word2vec和Fasttext,那最簡單的一種得到文本向量的方法,就是直接用詞向量做pooling來得到文本向量。這裡pooling可以有很多種, 例如
- 文本所有單詞,詞向量 average pooling
- 文本所有單詞,詞向量 TF-IDF weighted average pooling
- 文本提取關鍵詞,詞向量 average pooling
- 文本提取關鍵詞,詞向量 weighted average pooling
想了解細節的可以看下REF[3,5],但基於word2vec的文本向量表達最大的問題,也是詞袋模型的局限, 就是向量只包含詞共現信息,忽略了詞序信息和文本主題信息。這個問題在短文本上問題不大,但對長文本的影響會更大些。於是在word2vec發表1年後還是Mikolov大大,給出了文本向量的另一種解決方案PV-DM/PV-DBOW。下面例子的完整代碼見 github-DSXiangLi-Embedding-doc2vec
模型
PV-DM 訓練
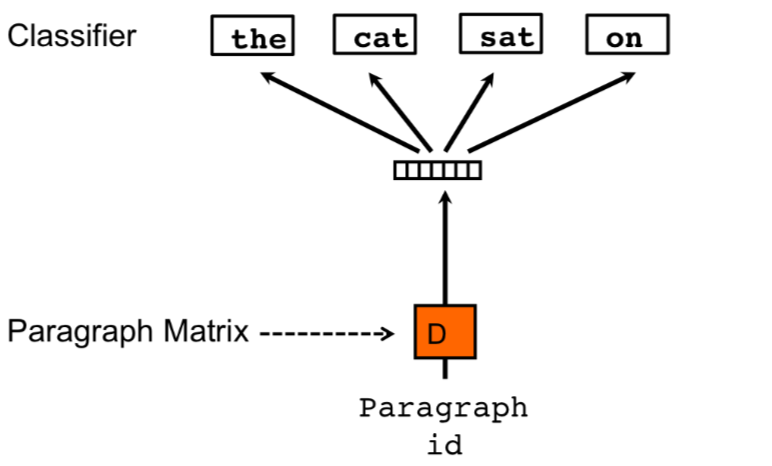
在CBOW的基礎上,PV-DM加入了paragraph-id,每個ID對應訓練集一個文本,可以是一句話,一個段落或者一條新聞對應。paragraph-id和詞一樣通過embedding矩陣得到唯一的對應向量。然後以concat或者average pooling的方式和CBOW設定窗口內的單詞向量進行融合,通過softmax來預測窗口中間詞。

這個paragraaph-id具體做了啥嘞?這裡需要回顧下word2vec的word embedding是如何通過back propogation得到的。不清楚的可以來這裡回顧下喲無所不能的Embedding 1. Word2vec模型詳解&代碼實現
第一步hidden->output更新output embedding矩陣,在CBOW里h只是window_size內詞向量的平均,而在PV-DM中,\(h\)包含了paragraph-id映射得到的文本向量,這個向量是整個paragraph共享的,所以在窗口滑動的時候會保留部分paragraph的主題信息,這部分信息會用於output embedidng的更新。
v_{w^{‘}j}^{(new)} &= v_{w^{‘}j}^{(old)} – \eta \cdot e_j \cdot h
\end{align}
\]
第二步input->hidden更新input embedding矩陣, 前一步學到的主題信息會反過來用於input embedding的更新,讓同一個paragraph里的單詞都學到部分主題信息。而paragraph-id本身對應的向量在每個滑動窗口都會被更新一次,更新用到之前paragraph的信息和窗口內的詞向量信息。
v_{w_I}^{(new)} &= v_{w_I}^{(old)} – \eta \cdot \sum_{j=1}^V e_j \cdot v_{w^{‘}j}
\end{align}
\]
之前有看到把paragraph-id對應向量的信息說成上下文信息,但感覺會有點高估PV-DM的效果,因為這裡依舊停留在詞袋模型,並沒有考慮真正考慮到詞序信息。只是通過不同paragraph對應不同的向量,來區分相同單詞在不同主題內的詞共現信息的差異,更近似於從概率到條件概率的改變。而paragrah-id對應的vector,感覺更多是以比較玄妙的方式得到的加權的word embedding。
PV-DBOW訓練
PV-DBOW和Skip-gram的結構近似,skip-gram是中間詞預測上下文, PV-DBOW則是用paragraph對應向量來預測文本中的任意詞彙。和上面的PV-DM相比,也就是進一步省略了window內的詞彙,所以優點就是訓練所需內存佔用會更少。
作者表示多數情況下PV-DM都要比PV-DBOW要好。不過二者一起使用,得到兩個文本向量後做concat,再用於後續的監督學習效果最好。
模型預測
doc2vec和word2vec一個明顯的區別,就是對樣本外的文本向量是需要重新訓練的。以PV-DM為例,在infer階段,我們會把單詞的input embedding,output embedding,以及bias都freeze,只對樣本外的document embedding進行訓練,因此doc2vec的預測部分是相對耗時的,因為也需要一定數量的epochs來保證樣本外的document embedding收斂。這個特點部分降低了doc2vec在實際應用中的可用性。
Gensim實踐
這裡我們基於Gensim提供的word2vec和doc2vec模型,我們分別對搜狗新聞文本向量的建模,對比下二者在文本向量和詞向量相似召回上的差異。
訓練集測試集對比
上面提到Doc2vec用PV-DM訓練會得到訓練集的embedding,對樣本外文本則需要重新訓練得到預測值。基於doc2vec這個特點,我們來對比下同一個文本,訓練的embedding和infer的 embedding是否存在差異。代碼里我們默認樣本內文本可以通過傳入tag得到,這個和gensim的TaggedDocument邏輯一致,而樣本外文本需要直接傳入分詞tokens。所以只需把訓練樣本從token傳入,再按相似度召回最相似的文本即可。這裡infer的epochs和訓練epochs一致.

在以上的結果中,我們發現同一文本,樣本內和樣本外的cosine相似度高達0.98,雖然infer和訓練embedding不完全一致,但顯著高於和其他文本的相似度。這個測試不能用來衡量模型的準確性,但可以作為sanity check。
文本向量對比
我們對比下Doc2vec和Word2vec得到的文本向量,在召回相似文本上的表現。先看短文本,會發現word2vec和doc2vec表現相對一致,召回的相似文本一致,因為對短文本來說上下文信息的影響會小。

在長文本上(文本太長不方便展示,詳見JupyterNotebook),word2vec和doc2vec差異較明顯,但在隨機選取的幾個case上,並不能明顯感知到doc2vec在長文本上的優勢,當然這可能和模型參數選擇有關。
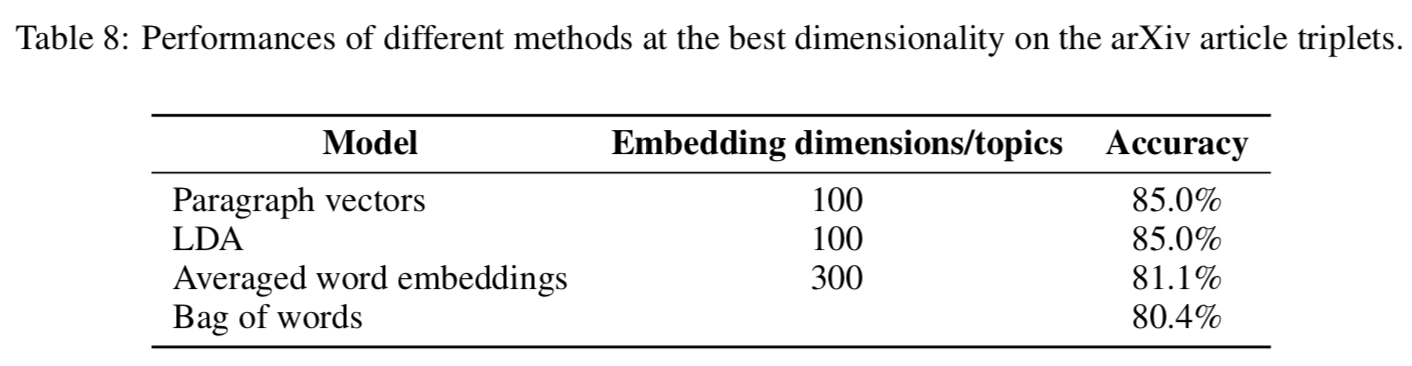
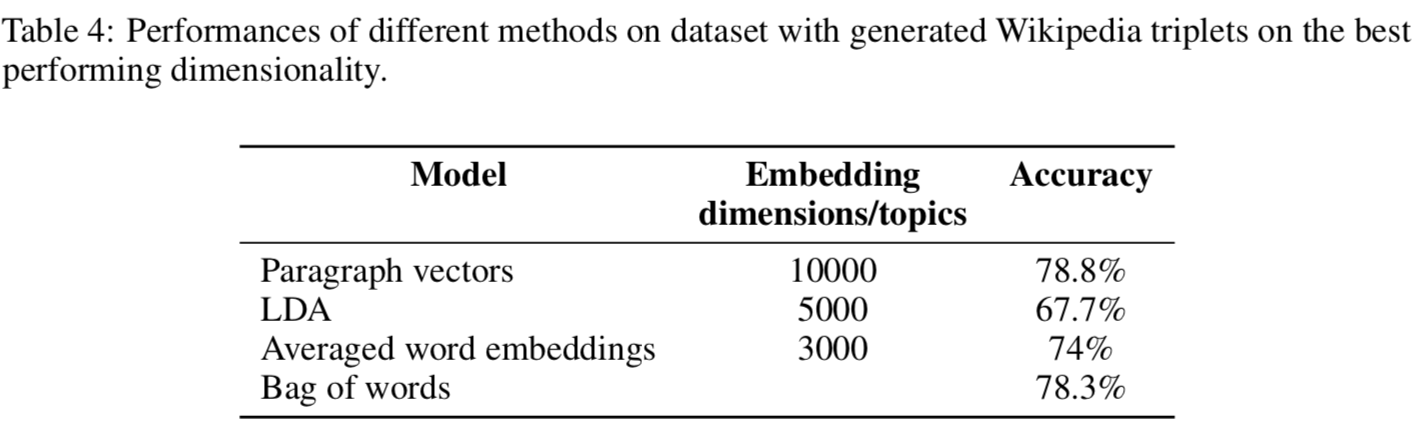
對此更有說服力的應該是Google【Ref2】對幾個文本向量模型在wiki和arivx數據集的召回對比,他們分別對比了LDA,doc2vec,average word embedding和BOW。 雖然doc2vec在兩個數據集的準確度都是最高的。。。算了把accuracy放上來大家自己感受下吧。。。doc2vec的優勢真的並不明顯。。。再一看呦呵最佳embedding size=10000,莫名有一種大力出奇蹟的感覺。。。
詞向量對比
考慮我們用的PV-DM建模在訓練文本向量的同時也會得到詞向量,這裡我們對比下在相同corpus,相同參數的word2vec和doc2vec得到的詞向量的差異。
考慮北京今年雨水多到的讓我以為到了江南,我們來看下下雨類詞彙召回的top10相似的詞,由上到下按詞頻從高到低排序。

比較容易發現對於高頻詞,Doc2vec和word2vec得到的詞向量相似度會更接近,也比較符合邏輯因為高頻詞會在更多的doc中出現,因此受到document vector的影響會更小(被平均)。而相對越低頻的詞,doc2vec學到的詞向量表達,會帶有更多的主題信息。如果說word2vec是把語料里所有的document混在一起訓練得到general的詞向量表達,doc2vec更類似於學到conditional的詞向量表達。所以脫離當前語料,doc2vec的詞向量實用價值比較玄學,因為不太說的清楚它到底是學到的了啥。
整體看來PV-DM/DBOW沒有特別眼前一亮的感覺,不過畢竟是14年的論文了,這只是文本表徵的冰山一角,後面還能扯出一系列的encoder-decoder,transformer框架啥的。預知後事如何,咱慢慢往後瞧着~
無所不能的embedding系列👇
//github.com/DSXiangLi/Embedding
無所不能的Embedding 1. Word2vec模型詳解&代碼實現
無所不能的Embedding 2. FastText詞向量&文本分類
Reference
- Quoc V. Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. [Google]
- Andrew M Dai, Christopher Olah, Quov. 2015. Document Embedding with Paragraph Vectors[Google]
- Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017. A simple but tough-to-beat baseline for sentence embeddings .
- Han Jey Lau and Timothy Baldwin. 2016. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding[IBM]
- Craig w. 2019. Improving a tf-idf weighted document vector embedding.tripAdvisor
- //radimrehurek.com/gensim/models/doc2vec.html
- //zhuanlan.zhihu.com/p/50443871
- //www.bookstack.cn/read/huaxiaozhuan-ai/spilt.7.142adbd00f395138.md#fdu4nj
- //supernlp.github.io/2018/11/26/sentreps/
- //d0evi1.com/paragraph2vec/


