分佈式事務之基本概念
- 2019 年 11 月 10 日
- 筆記
1 基礎概念
什麼是事務?舉個生活的例子 :你去小賣部買東西,“一手交錢,一手交貨“就是一個事務的例子,交錢和交貨必須全部成功,事務才算成功,任一個活動失敗,事務將撤銷所有已成功的活動。
明白上述例子,再來看事務的定義 :
事務可以看做是一次大的活動,它由不同的小活動組成,這些活動要麼全部成功,要麼全部失敗。
在計算機系統中,更多的是通過關係型數據庫來控制事務,這裡利用數據庫本身的事務特性來實現的,因此叫數據庫事務,由於應用主要靠關係數據庫來控制事務,而數據庫通常和應用在同一個服務器,所以基於關係型數據庫的事務又被稱為本地事務。
回顧一下數據庫事務的四大特性ACID:
A(Atomic):原子性,構成事務的所有操作,要麼都執行完成,要麼全部不執行,不可能出現部分成功部分失敗的情況。
C(Consistency):一致性,在事務執行前後,數據庫的一致性約束沒有被破壞。比如 :張三向李四轉100元,轉賬前和轉賬後的數據是正確狀態這叫一致性,如果出現張三轉出100元,李四賬戶沒有增加100元這就出現來數據錯誤,就沒有達到一致性。
I(Isolation):隔離性,數據庫中的事務一般都是並發的,隔離性是指並發的兩個事務的執行互不干擾,一個事務不能看到其他事務運行過程的中間狀態。通過配置事務隔離級別可以避免贓讀、重複讀等問題。
D(Durability):持久性,事務完成之後,該事務對數據的更改會被持久化到數據庫,且不會被回滾。
數據庫事務在實現時會將一次事務涉及的操作全部納入到一個不可分割的執行單元,該執行單元中的所有操作要麼都成功,要麼都失敗,只要其中任一操作執行失敗,都將導致整個事務的回滾。
隨着互聯網的快速發展,軟件系統由原來的單體應用轉變為分佈式應用,下圖描述來單體應用向微服務的演變: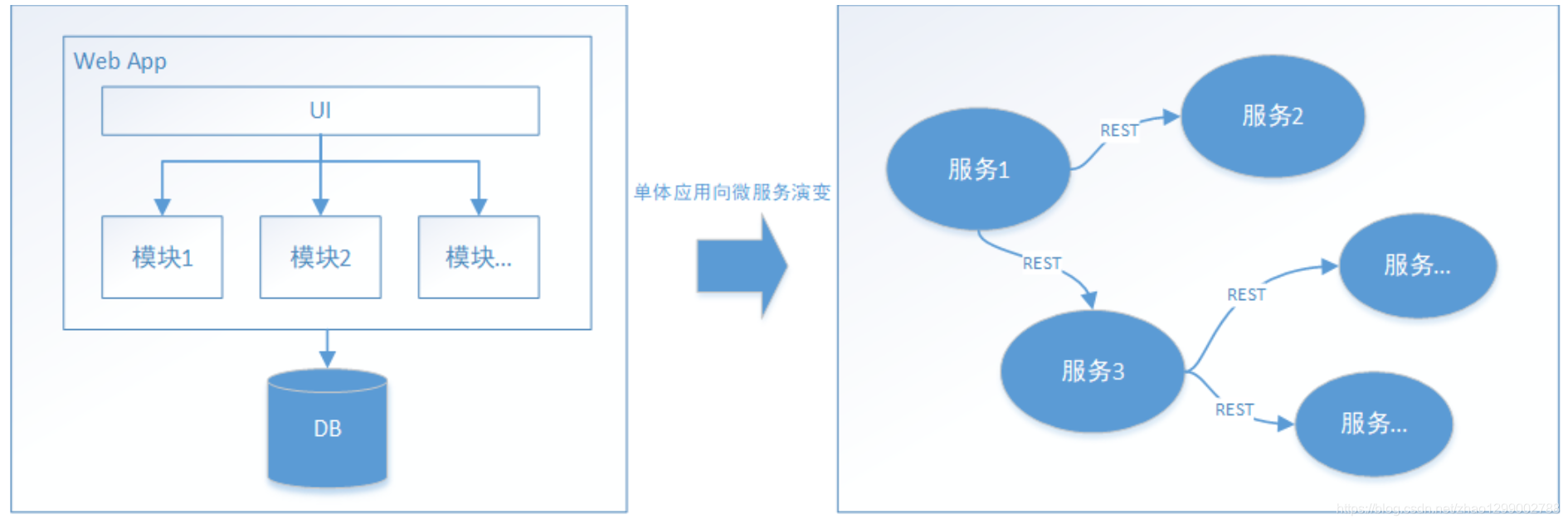
分佈式系統會把一個應用系統拆分為可獨立部署的多個服務,因此需要服務與服務之間遠程協作才能完成事務操作,這種分佈式系統環境下由不同的服務之間通過網絡遠程協作完成事務稱之為分佈式事務,例如用戶註冊送積分事務、創建訂單減庫存事務,銀行轉賬事務等都是分佈式事務。
我們知道本地事務依賴數據庫本身提供的事務特性來實現,因此以下邏輯可以控制本地事務 :
begin transaction; // 1. 本地數據庫操作 :張三減少金額 // 2. 本地數據庫操作 :李四增加金額 commit transation; 但是在分佈式環境下,會變成下邊這樣:
begin transaction; // 1. 本地數據庫操作 :張三減少金額 // 2. 遠程調用 :讓李四增加金額 commit transation; 可以設想,當遠程調用讓李四增加金額成功來,由於網絡問題遠程調用並沒有返回,此時本地事務提交失敗的回滾來張三減少金額的操作,此時張三和李四的數據就不一致了。
因此在分佈式架構的基礎上,傳統數據庫事務就無法使用了,張三和李四的賬戶不在一個數據庫中甚至不在一個應用系統里,實現轉賬事務需要通過遠程調用,由於網絡問題就會導致分佈式事務問題。
1、典型的場景就是微服務架構,微服務之間通過遠程調用完成事務操作。比如 :訂單微服務和庫存微服務,下單的同時訂單微服務請求庫存微服務減庫存。簡言之 :跨JVM進程產生分佈式事務。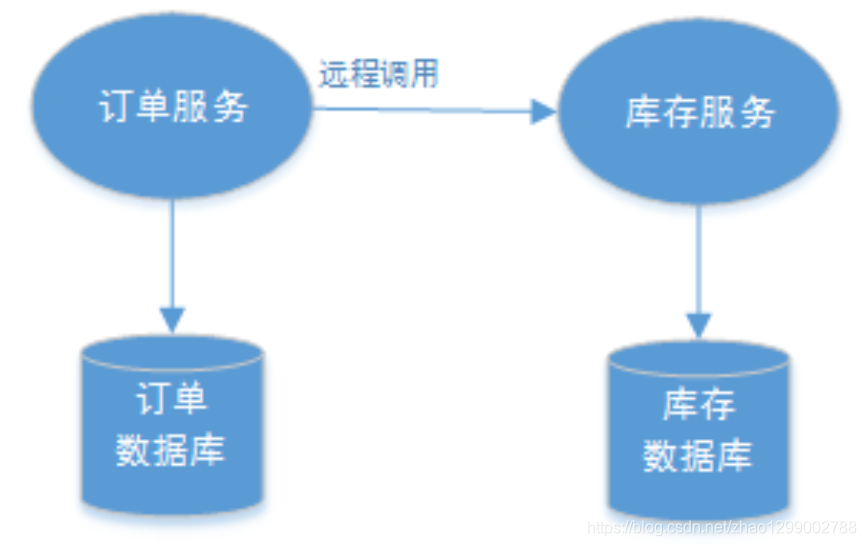
2、單體系統訪問多個數據庫實例,當單體系統需要訪問多個數據庫(實例)時就會產生分佈式事務。比如:用戶信息和訂單信息分別在兩個MySQL實例存儲,用戶管理系統刪除用戶信息,需要分別刪除用戶信息及用戶的訂單信息,由於數據分佈在不同的數據實例,需要通過不同的數據庫鏈接去操作數據,此時產生分佈式事務。簡言之 :跨數據庫實例產生分佈式事務。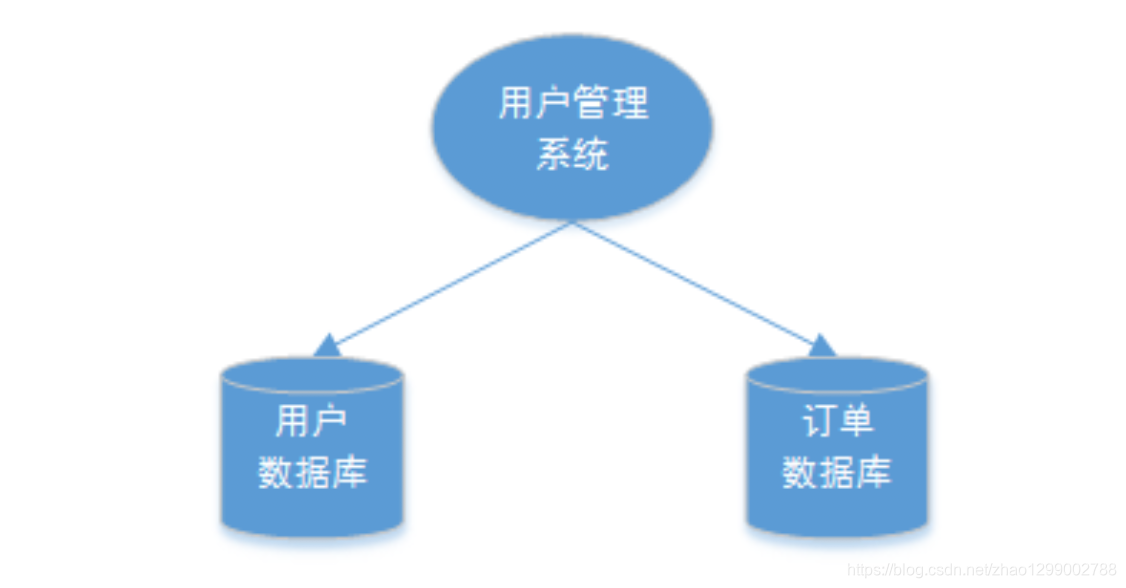
3、多服務訪問同一個數據庫實例,比如 :訂單微服務和庫存微服務即使訪問同一個數據庫也會產生分佈式事務,原因就是跨JVM進程,兩個微服務持有了不同的數據庫鏈接進行數據庫操作,此時產生分佈式事務。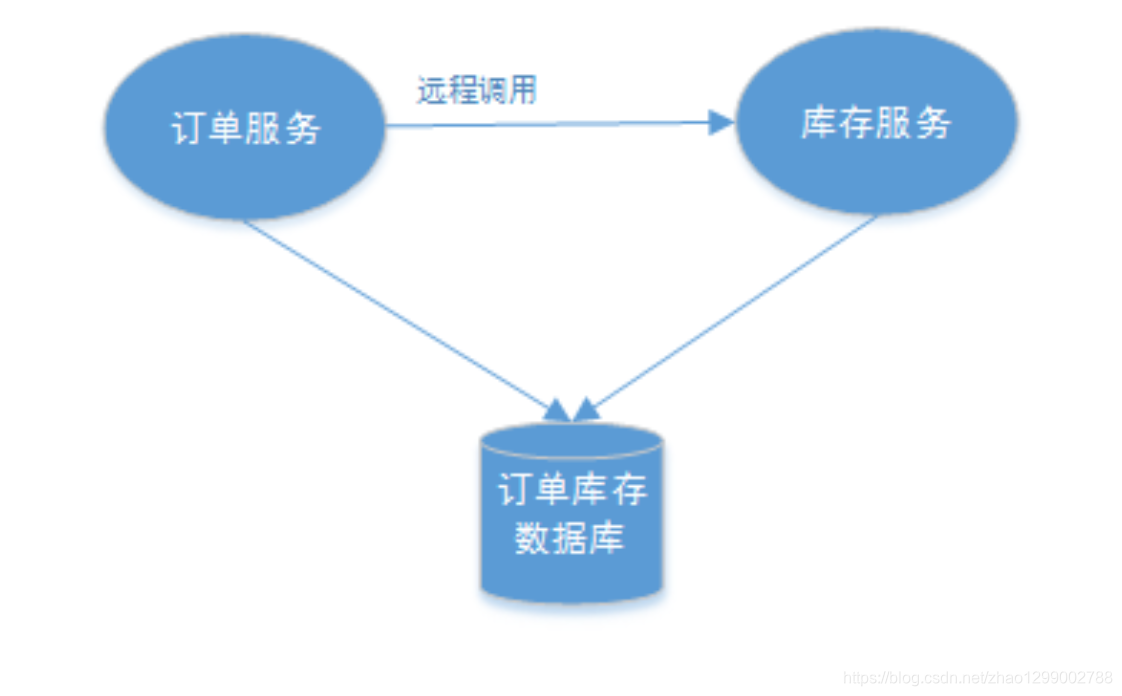
我們了解到分佈式事務的基礎概念。與本地事務不同的是,分佈式系統之所以叫分佈式,是因為提供服務的各個節點分佈在不同的機器上,相互之間通過網絡交互。不能因為有一點網絡問題就導致整個系統無法提供服務,網絡因素成為了分佈式事務的考量標準之一。因此分佈式事務需要更進一步的理論支持。
在了解分佈式事務控制解決方案之前先了解一些基礎理論,通過理論知識指導我們確定分佈式事務控制的目標,從而幫助我們理解解決方案。
CAP是Consistency、Availability、Parition tolerance三個詞語的縮寫,分別表示一致性、可用性、分區容忍性。
下邊我們分別來解釋 :
為了方便對CAP理論的理解,我們結合電商系統中的一些業務場景來理解CAP。
如下圖,是商品信息管理的執行流程 :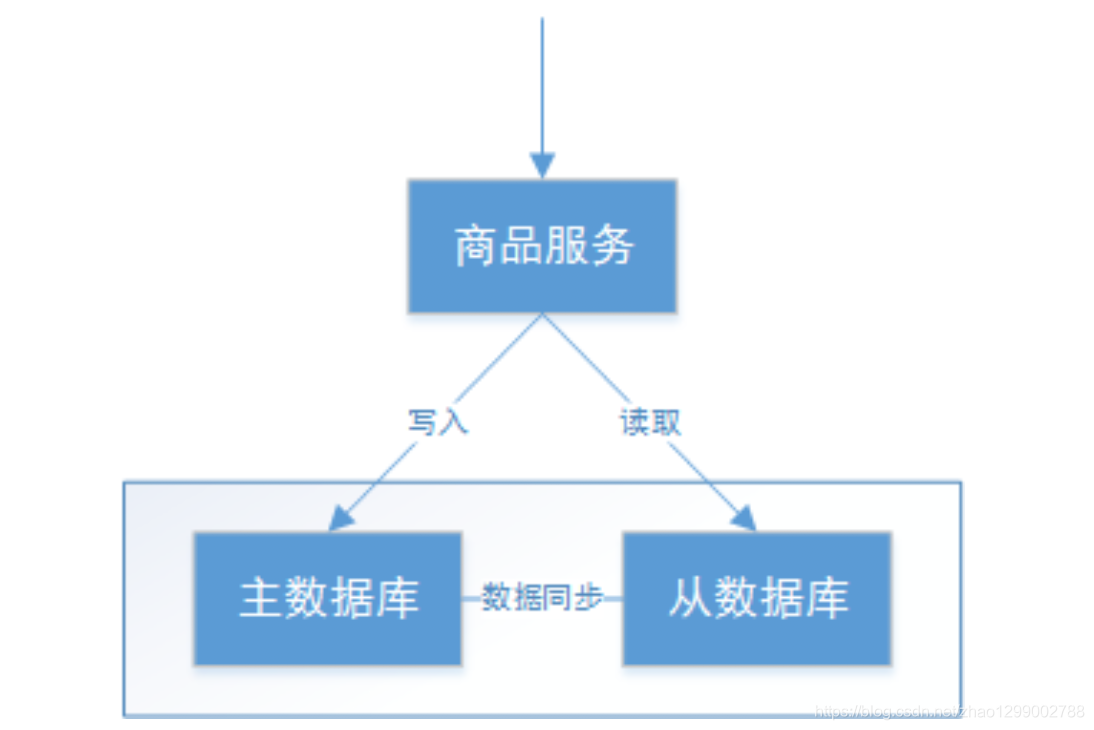
整體執行流程如下 :
1、商品服務請求主數據庫寫入商品信息(添加商品、修改商品、刪除商品)。
2、主數據庫向商品服務響應寫入成功。
3、商品服務請求從數據庫讀取商品信息。
C-Consistency :
一致性是指寫操作後的讀操作可以讀取到最新的數據狀態,當數據分佈在多個節點上,從任意節點讀取到的數據都是最新的狀態。
上圖中,商品信息的讀寫要滿足一致性就是要實現如下目標 :
1、商品服務寫入主數據庫成功,則向從數據庫查詢新數據也成功。
2、商品服務寫入主數據庫失敗,則向從數據庫查詢新數據也失敗。
如何實現一致性?
1、寫入主數據庫後要將數據同步到從數據庫。
2、寫入主數據庫後,在向從數據庫同步期間要將從數據庫鎖定,待同步完成後再釋放鎖,以免在新數據寫入成功後,向從數據庫查詢到舊的數據。
分佈式系統一致性的特點 :
1、由於存在數據同步的過程,寫操作的響應會有一定的延遲。
2、為了保證數據一致性會對資源暫時鎖定,待數據同步完成釋放鎖定資源。
3、如果請求數據同步失敗的節點則會返回錯誤信息,一定不會返回舊數據。
A-Availability:
可用性是指任何事務操作都可以得到響應結果,且不會出現響應超時或響應錯誤。
上圖中,商品信息讀取滿足可用性就是要實現如下目標 :
1、從數據庫接收到數據查詢的請求則立即能夠響應數據查詢結果。
2、從數據庫不允許出現響應超時或響應錯誤。
如何實現可用性?
1、寫入主數據庫後要將數據同步到從數據庫。
2、由於要保證從數據庫的可用性,不可將從數據庫中的資源進行鎖定。
3、即使數據還沒有同步過來,從數據庫也要返回要查詢的數據,哪怕是舊數據,如果連舊數據也沒有則可以按照約定返回一個默認信息,但不能返回錯誤或者響應超時。
分佈式系統可用性的特點 :
1、所有請求都有響應,且不會出現響應超時或響應錯誤。
P-Partition tolerance :
通常分佈式系統的各個節點部署在不同的子網,這就是網絡分區,不可避免的會出現由於網絡問題而導致節點之間通訊失敗,此時仍可對外提供服務,這叫分區容忍性。
上圖中,商品信息讀寫滿足分區容忍性就是要實現如下目標 :
1、主數據庫向從數據庫同步數據失敗不影響讀寫操作。
2、其一個節點掛掉不影響另一個節點對外提供服務。
如何實現分區容忍性?
1、盡量使用異步取代同步操作,例如使用異步方式將數據從主數據庫同步到從數據,這樣節點之間能有效的實現松耦合。
2、添加從數據庫節點,其中一個從節點掛掉其它從節點提供服務。
分佈式分區容忍性的特點 :
1、分區容忍性是分佈式系統具備的基本能力。
1、上邊商品管理的例子是否同時具備CAP呢?
在所有分佈式事務場景中不會同時具備CAP三特性,因為在具備了P的前提下C和A是不能共存的。
比如 :
下圖滿足了P即表示實現分區容忍 :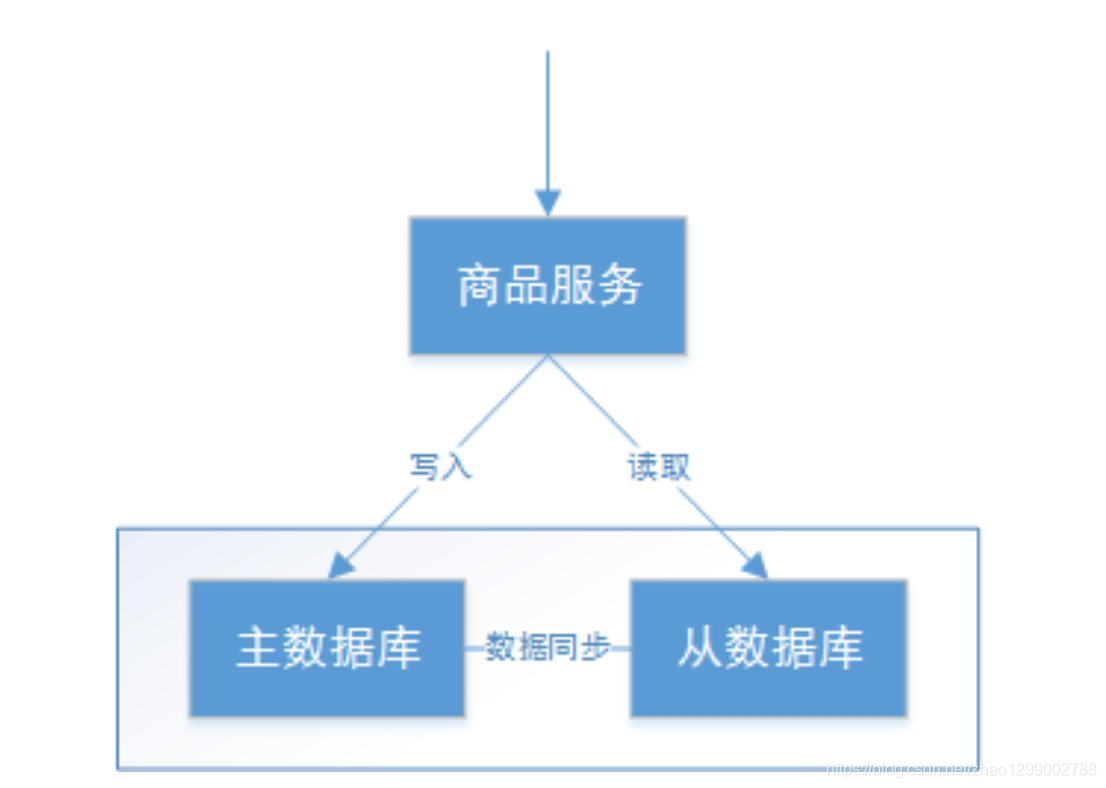
本圖分區容忍的含義是 :
1)主數據庫通過網絡向從數據同步數據,可以認為主從數據庫部署在不同的分區,通過網絡進行交互。
2)當主數據庫和從數據庫之間的網絡出現問題不影響主數據庫和從數據庫對外提供服務。
3)其一個節點掛掉不影響另一個節點對外提供服務。
如果要實現C則必須保證數據一致性,在數據同步的時候為防止向從數據庫查詢不一致的數據則需要將從數據庫數據鎖定,待同步完成後解鎖,如果同步失敗從數據庫要返回錯誤信息或超時信息。
如果要實現A則必須保證數據可用性,不管任何時候都可以向從數據庫查詢數據,則不會響應超時或返回錯誤信息。
通過分析發現在滿足P的前提下C和A存在矛盾性。
2、CAP有那些組合方式呢?
在生產中對分佈式事務處理時要根據需求來確定滿足CAP的那兩個方面。
1)AP:
放棄一致性,追求分區容忍性和可用性。這是很多分佈式系統設計時的選擇。
例如 :
上邊的商品管理,完全可以實現AP,前提是只要用戶可以接收所查詢的到數據在一定時間內不是最新的即可。
通常實現AP都會保證最終一致性,後面講的BASE理論就是根據AP來擴展的,一些業務場景 比如 :訂單退款,今日退款成功,明日賬戶到賬,只要用戶可以接受在一定時間內到賬即可。
2)CP:
放棄可用性,追求一致性和分區容錯性,我們的zookeeper其實就是追求的強一致性,又比如跨行轉賬,一次轉賬請求要等待雙方銀行系統都完成整個事務才算完成。
3)CA:
放棄分區容忍性,既不進行分區,不考慮由於網絡不通或節點掛掉的問題,則可以實現一致性和可用性。那麼系統將不是一個標準的分佈式系統,我們最常用的關係型數據就滿足了CA。
上邊的商品管理,如果要實現CA則架構如下 :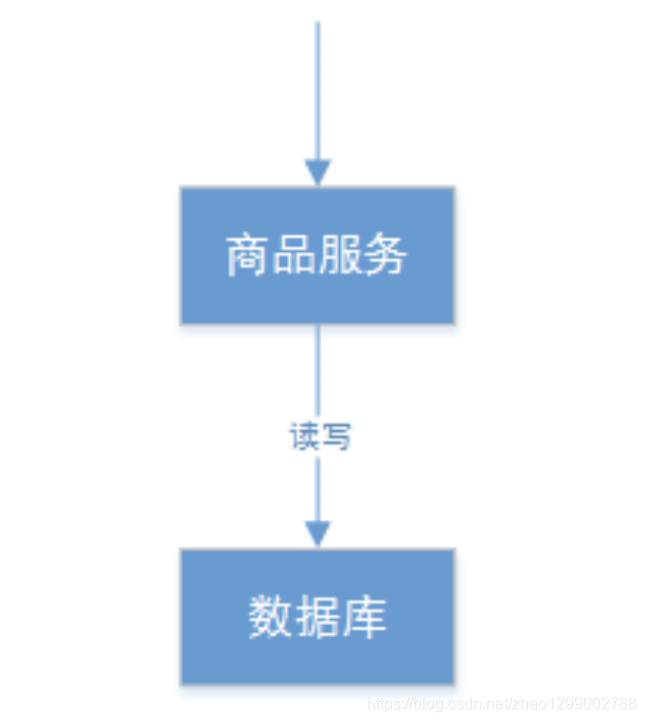
主數據庫和從數據庫中間不再進行數據同步,數據庫可以響應每次的查詢請求,通過事務隔離級別實現每個查詢請求都可以返回最新的數據。
通過上面的學習,CAP是一個已經被證實的理論 :一個分佈式系統最多只能同時滿足一致性(Consistency)、可用性(Availability)和分區容忍性(Partition tolerance)這三項中的兩項。它可以作為我們架構設計、技術選型的考量標準。對於多數大型互聯網應用的場景,節點眾多、部署分散,而且現在的集群規模越來越大,所以節點故障、網絡故障是常態,而且要保證服務可用性達到N個9(99.99.%),並要達到良好的響應性能來提高用戶體驗,因此一般都會做出如下選擇 :保證P和A,捨棄C強一致性,保證最終一致性。
1、理解強一致性和最終一致性
CAP理論告訴我們一個分佈式系統最多只能同時滿足一致性(Consistency)、可用性(Availability)和分區容忍性(Partition tolerance)這三項中的兩項,其中AP在實際應用中較多,AP既捨棄一致性,保證可用性和分區容忍性,但是在實際生產中很多場景都要實現一致性,比如前邊我們舉的例子,AP即捨棄一致性,保證可用性和分區容忍性,但是在實際產生中很多場景都要實現一致性,比如前邊我們覺得例子主數據庫向從數據庫同步數據,即使不要一致性,但是最終也要將數據同步成功來保證數據一致,這種一致性和CAP中的一致性不同,CAP中的一致性要求在任何時間查詢每個節點數據都必須一致,它強調的是強一致性,但是最終一致性是允許可以在一段時間內每個節點的數據不一致,但是經過一段時間每個節點的數據必須一致,它強調的是最終數據的一致性。
2、Base理論介紹
BASE是Basically Availbale(基本可用)、Soft state(軟狀態)和Eventually consistent(最終一致性)三個短語的縮寫。BASE理論是對CAP中AP的一個擴展,通過犧牲強一致性來獲得可用性,當出現故障允許部分不可用但要保證核心功能可用,允許數據在一段時間內是不一致的,但最終達到一致狀態。滿足BASE理論的事務,我們稱之為“柔性事務”。
- 基本可用 :分佈式系統在出現故障時,允許損失部分可用功能,保證核心功能可用。如電商網址交易付款出現問題來,商品依然可以正常瀏覽。
- 軟狀態:由於不要求強一致性,所以BASE允許系統中存在中間狀態(也叫軟狀態),這個狀態不影響系統可用性,如訂單中的“支付中”、“數據同步中”等狀態,待數據最終一致後狀態改為“成功”狀態。
- 最終一致性:最終一致是指的經過一段時間後,所有節點數據都將會達到一致。如訂單的“支付中”狀態,最終會變為“支付成功”或者“支付失敗”,使訂單狀態與實際交易結果達成一致,但需要一定時間的延遲、等待。

