程序員,你應該知道的數據結構之哈希表
- 2019 年 10 月 3 日
- 筆記
哈希表簡介
哈希表也叫散列表,哈希表是一種數據結構,它提供了快速的插入操作和查找操作,無論哈希表總中有多少條數據,插入和查找的時間複雜度都是為O(1),因為哈希表的查找速度非常快,所以在很多程序中都有使用哈希表,例如拼音檢查器。
哈希表也有自己的缺點,哈希表是基於數組的,我們知道數組創建後擴容成本比較高,所以當哈希表被填滿時,性能下降的比較嚴重。
哈希表採用的是一種轉換思想,其中一個中要的概念是如何將鍵或者關鍵字轉換成數組下標?在哈希表中,這個過程有哈希函數來完成,但是並不是每個鍵或者關鍵字都需要通過哈希函數來將其轉換成數組下標,有些鍵或者關鍵字可以直接作為數組的下標。我們先來通過一個例子來理解這句話。
我們上學的時候,大家都會有一個學號1-n號中的一個號碼,如果我們用哈希表來存放班級裏面學生信息的話,我們利用學號作為鍵或者關鍵字,這個鍵或者關鍵字就可以直接作為數據的下標,不需要通過哈希函數進行轉化。如果我們需要安裝學生姓名作為鍵或者關鍵字,這時候我們就需要哈希函數來幫我們轉換成數組的下標。
哈希函數
哈希函數的作用是幫我們把非int的鍵或者關鍵字轉化成int,可以用來做數組的下標。比如我們上面說的將學生的姓名作為鍵或者關鍵字,這是就需要哈希函數來完成,下圖是哈希函數的轉換示意圖。
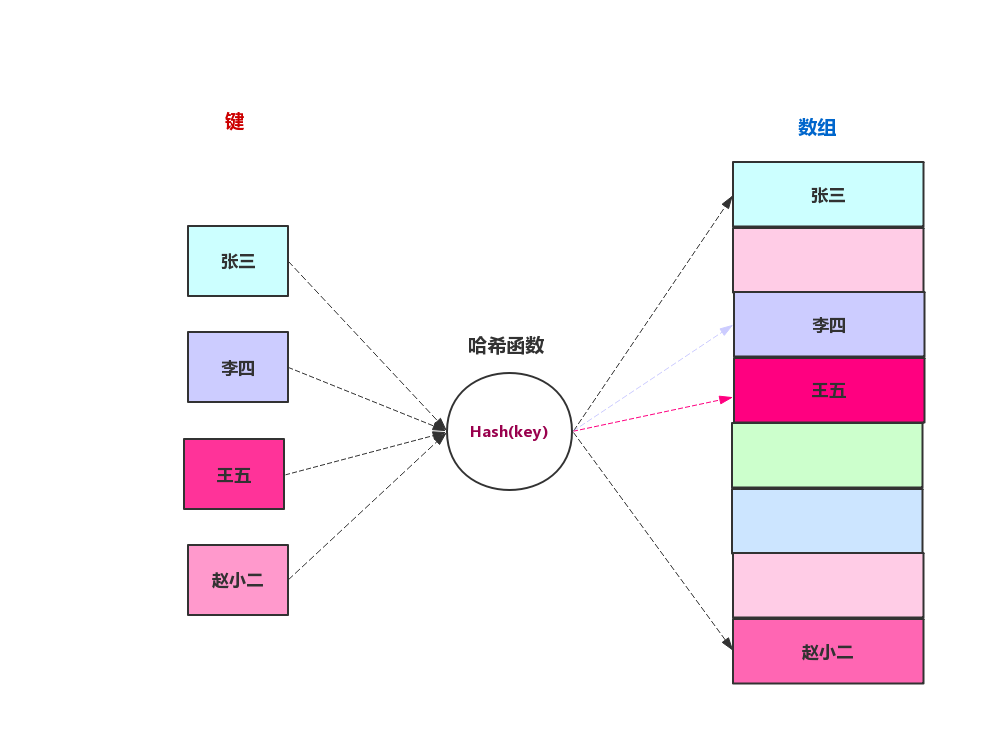
哈希函數的寫法有很多中,我們來看看HashMap中的哈希函數
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }HashMap中利用了hashCode來完成這個轉換。哈希函數不管怎麼實現,都應該滿足下面三個基本條件:
- 散列函數計算得到的散列值是一個非負整數
- 如果 key1 = key2,那 hash(key1) == hash(key2)
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一點:因為數組的下標是從0開始,所以哈希函數生成的哈希值也應該是非負數
第二點:同一個key生成的哈希值應該是一樣的,因為我們需要通過key查找哈希表中的數據
第三點:看起來非常合理,但是兩個不一樣的值通過哈希函數之後可能才生相同的值,因為我們把巨大的空間轉出成較小的數組空間時,不能保證每個數字都映射到數組空白處。所以這裡就會才生衝突,在哈希表中我們稱之為哈希衝突
哈希衝突
哈希衝突是不可避免的,我們常用解決哈希衝突的方法有兩種開放地址法和鏈表法
開放地址法
在開放地址法中,若數據不能直接存放在哈希函數計算出來的數組下標時,就需要尋找其他位置來存放。在開放地址法中有三種方式來尋找其他的位置,分別是線性探測、二次探測、再哈希法
線性探測
線性探測的插入
在線性探測哈希表中,數據的插入是線性的查找空白單元,例如我們將數88經過哈希函數後得到的數組下標是16,但是在數組下標為16的地方已經存在元素,那麼就找17,17還存在元素就找18,一直往下找,直到找到空白地方存放元素。我們來看下面這張圖
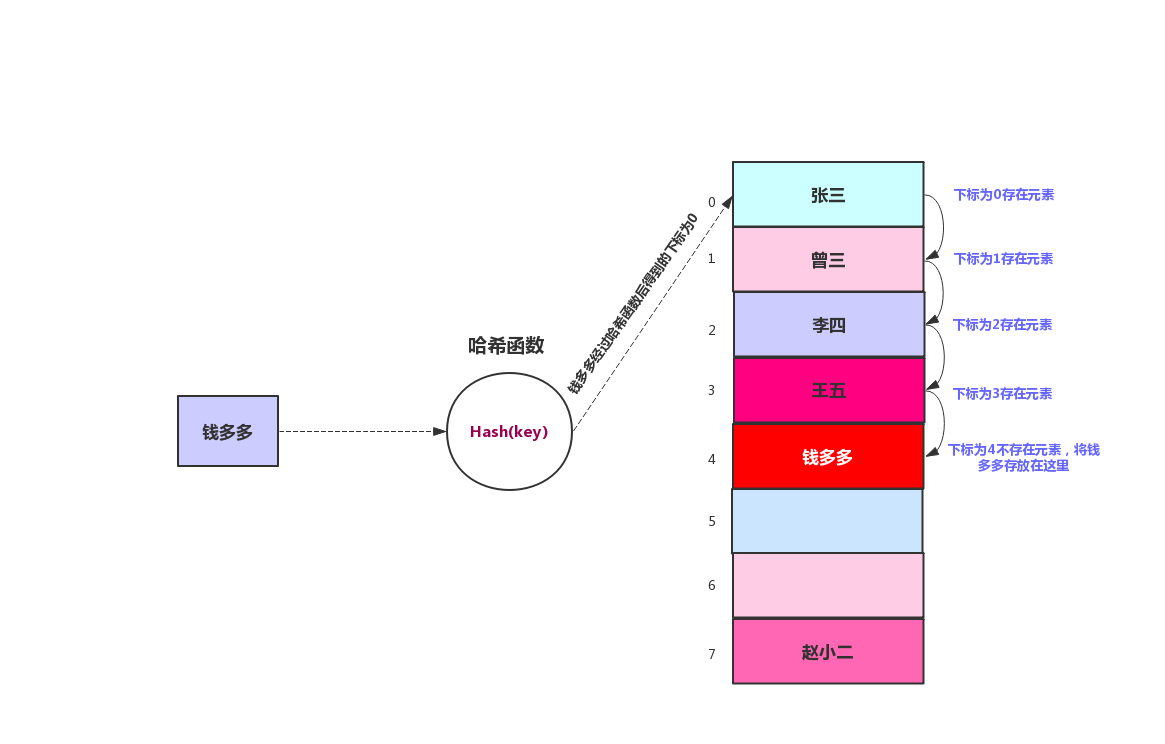
我們向哈希表中添加一個元素錢多多,錢多多經過哈希函數後得到的數組下標為0,但是在0的位置已經有張三了,所以下標往前移,直到下標4才為空,所以就將元素錢多多添加到數組下標為4的地方。
線性探測哈希表的插入實現起來也非常簡單,我們來看看哈希表的插入代碼
/** * 哈希函數 * @param key * @return */ private int hash(int key) { return (key % size); } /** * 插入 * @param student */ public void insert(Student student){ int key = student.getKey(); int hashVal = hash(key); while (array[hashVal] !=null && array[hashVal].getKey() !=-1){ ++hashVal; // 如果超過數組大小,則從第一個開始找 hashVal %=size; } array[hashVal] = student; }測試插入
public static void main(String[] args) { LinearProbingHash hash = new LinearProbingHash(10); Student student = new Student(1,"張三"); Student student1 = new Student(2,"王強"); Student student2 = new Student(5,"張偉"); Student student3 = new Student(11,"寶強"); hash.insert(student); hash.insert(student1); hash.insert(student2); hash.insert(student3); hash.disPlayTable(); }按照上面學習的線性探測知識,student和student2哈希函數得到的值應該都為1,由於1已經被student佔據,下標為2的位置被student1佔據,所以student2只能存放在下標為3的位置。下圖為測試結果。

線性探測的查找
線性探測哈希表的查找過程有點兒類似插入過程。我們通過散列函數求出要查找元素的鍵值對應的散列值,然後比較數組中下標為散列值的元素和要查找的元素。如果相等,則說明就是我們要找的元素;否則就順序往後依次查找。如果遍歷到數組中的空閑位置,還沒有找到,就說明要查找的元素並沒有在哈希表中。
線性探測哈希表的查找代碼
/** * 查找 * @param key * @return */ public Student find(int key){ int hashVal = hash(key); while (array[hashVal] !=null){ if (array[hashVal].getKey() == key){ return array[hashVal]; } ++hashVal; hashVal %=size; } return null; }線性探測的刪除
線性探測哈希表的刪除相對來說比較複雜一點,我們不能簡單的把這一項數據刪除,讓它變成空,為什麼呢?
線性探測哈希表在查找的時候,一旦我們通過線性探測方法,找到一個空閑位置,我們就可以認定哈希表中不存在這個數據。但是,如果這個空閑位置是我們後來刪除的,就會導致原來的查找算法失效。本來存在的數據,會被認定為不存在。?
因此我們需要一個特殊的數據來頂替這個被刪除的數據,因為我們的學生學號都是正數,所以我們用學號等於-1來代表被刪除的數據。
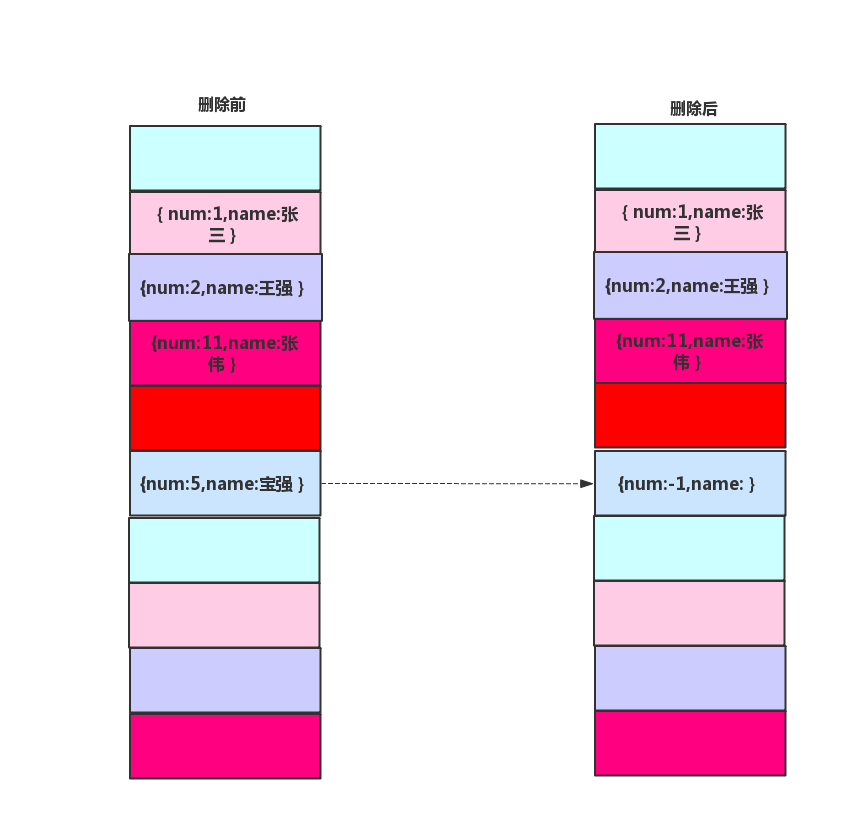
這樣會帶來一個問題,如何在線性探測哈希表中做了多次操作,會導致哈希表中充滿了學號為-1的數據項,使的哈希表的效率下降,所以很多哈希表中沒有提供刪除操作,即使提供了刪除操作的,也盡量少使用刪除函數。
線性探測哈希表的刪除代碼實現
/** * 刪除 * @param key * @return */ public Student delete(int key){ int hashVal = hash(key); while (array[hashVal] !=null){ if (array[hashVal].getKey() == key){ Student temp = array[hashVal]; array[hashVal]= noStudent; return temp; } ++hashVal; hashVal %=size; } return null; }二次探測
在線性探測哈希表中,數據會發生聚集,一旦聚集形成,它就會變的越來越大,那些哈希函數後落在聚集範圍內的數據項,都需要一步一步往後移動,並且插入到聚集的後面,因此聚集變的越大,聚集增長的越快。這個就像我們在逛超市一樣,當某個地方人很多時,人只會越來越多,大家都只是想知道這裡在幹什麼。
二次探測是防止聚集產生的一種嘗試,思想是探測相隔較遠的單元,而不是和原始位置相鄰的單元。在線性探測中,如果哈希函數得到的原始下標是x,線性探測就是x+1,x+2,x+3……,以此類推,而在二次探測中,探測過程是x+1,x+4,x+9,x+16,x+25……,以此類推,到原始距離的步數平方,為了方便理解,我們來看下面這張圖
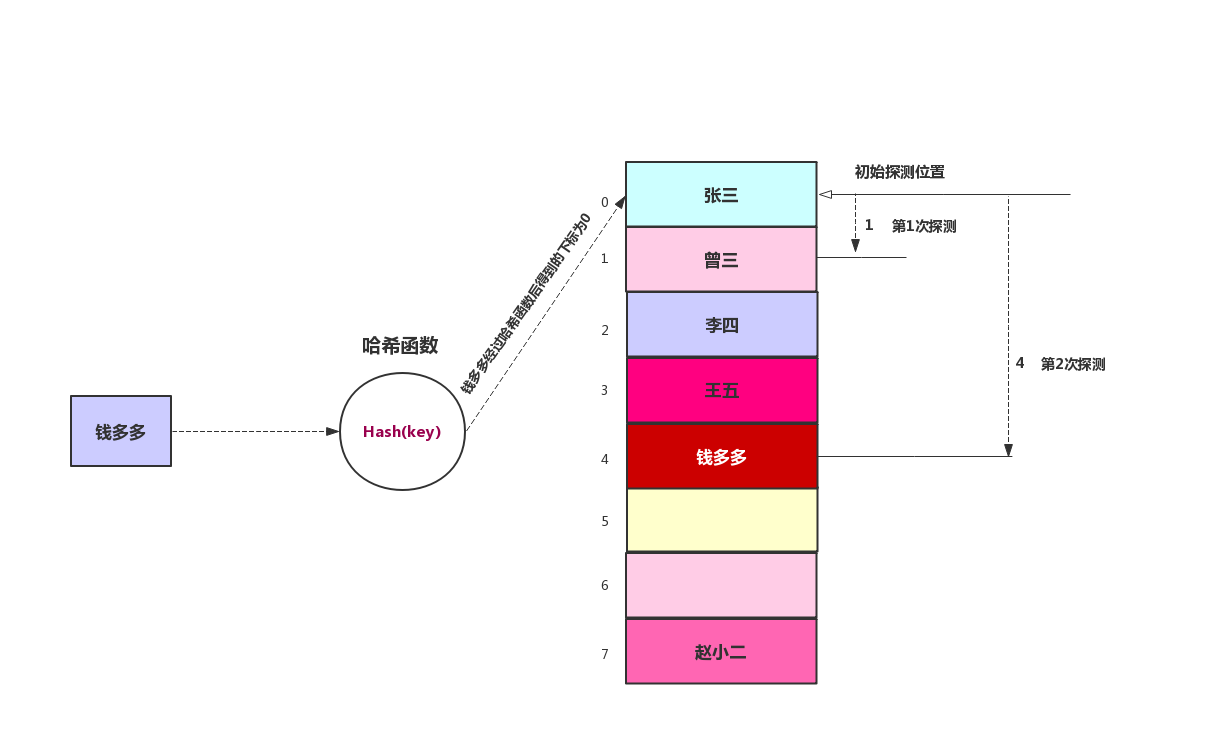
還是使用線性探測中的例子,在線性探測中,我們從原始探測位置每次往後推一位,最後找到空位置,在線性探測中我們找到錢多多的存儲位置需要經過4步。在二次探測中,每次是原始距離步數的平方,所以我們只需要兩次就找到錢多多的存儲位置。
二次探測的問題
二次探測消除了線性探測的聚集問題,這種聚集問題叫做原始聚集,然而,二次探測也產生了新的聚集問題,之所以會產生新的聚集問題,是因為所有映射到同一位置的關鍵字在尋找空位時,探測的位置都是一樣的。
比如講1、11、21、31、41依次插入到哈希表中,它們映射的位置都是1,那麼11需要以一為步長探測,21需要以四為步長探測,31需要為九為步長探測,41需要以十六為步長探測,只要有一項映射到1的位置,就需要更長的步長來探測,這個現象叫做二次聚集。
二次聚集不是一個嚴重的問題,因為二次探測不怎麼使用,這裡我就不貼出二次探測的源碼,因為雙哈希是一種更加好的解決辦法。
雙哈希
雙哈希是為了消除原始聚集和二次聚集問題,不管是線性探測還是二次探測,每次的探測步長都是固定的。雙哈希是除了第一個哈希函數外再增加一個哈希函數用來根據關鍵字生成探測步長,這樣即使第一個哈希函數映射到了數組的同一下標,但是探測步長不一樣,這樣就能夠解決聚集的問題。
第二個哈希函數必須具備如下特點
- 和第一個哈希函數不一樣
- 不能輸出為0,因為步長為0,每次探測都是指向同一個位置,將進入死循環,經過試驗得出
stepSize = constant-(key%constant);形式的哈希函數效果非常好,constant是一個質數並且小於數組容量
我們將上面的添加改變成雙哈希探測,示意圖如下:
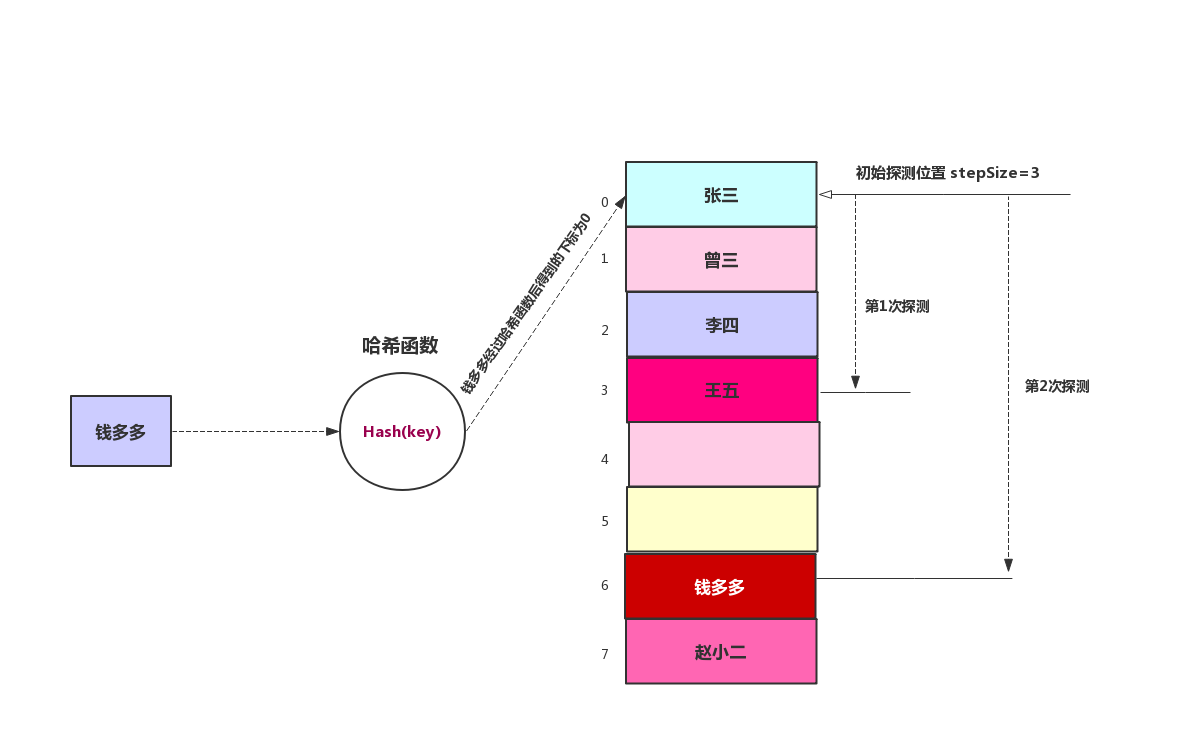
雙哈希的哈希表寫起來來線性探測差不多,就是把探測步長通過關鍵字來生成
添加第二個哈希函數
/** * 根據關鍵字生成探測步長 * @param key * @return */ private int stepHash(int key) { return 7 - (key % 7); }雙哈希的插入
/** * 雙哈希插入 * * @param student */ public void insert(Student student) { int key = student.getKey(); int hashVal = hash(key); // 獲取步長 int stepSize = stepHash(key); while (array[hashVal] != null && array[hashVal].getKey() != -1) { hashVal +=stepSize; // 如果超過數組大小,則從第一個開始找 hashVal %= size; } array[hashVal] = student; }雙哈希的查找
/** * 雙哈希查找 * * @param key * @return */ public Student find(int key) { int hashVal = hash(key); int stepSize = stepHash(key); while (array[hashVal] != null) { if (array[hashVal].getKey() == key) { return array[hashVal]; } hashVal +=stepSize; hashVal %= size; } return null; }雙哈希的刪除
/** * 雙哈希刪除 * * @param key * @return */ public Student delete(int key) { int hashVal = hash(key); int stepSize = stepHash(key); while (array[hashVal] != null) { if (array[hashVal].getKey() == key) { Student temp = array[hashVal]; array[hashVal] = noStudent; return temp; } hashVal +=stepSize; hashVal %= size; } return null; }雙哈希的實現比較簡單,但是雙哈希有一個特別高的要求就是表的容量需要是一個質數,為什麼呢?
為什麼雙哈希需要哈希表的容量是一個質數?
假設我們哈希表的容量為15,某個關鍵字經過雙哈希函數後得到的數組下標為0,步長為5。那麼這個探測過程是0,5,10,0,5,10,一直只會嘗試這三個位置,永遠找不到空白位置來存放,最終會導致崩潰。
如果我們哈希表的大小為13,某個關鍵字經過雙哈希函數後得到的數組下標為0,步長為5。那麼這個探測過程是0,5,10,2,7,12,4,9,1,6,11,3。會查找到哈希表中的每一個位置。
使用開放地址法,不管使用那種策略都會有各種問題,開放地址法不怎麼使用,在開放地址法中使用較多的是雙哈希策略。
鏈表法
開放地址法中,通過在哈希表中再尋找一個空位解決衝突的問題,還有一種更加常用的辦法是使用鏈表法來解決哈希衝突。鏈表法相對簡單很多,鏈表法是每個數組對應一條鏈表。當某項關鍵字通過哈希後落到哈希表中的某個位置,把該條數據添加到鏈表中,其他同樣映射到這個位置的數據項也只需要添加到鏈表中,並不需要在原始數組中尋找空位來存儲。下圖是鏈表法的示意圖。
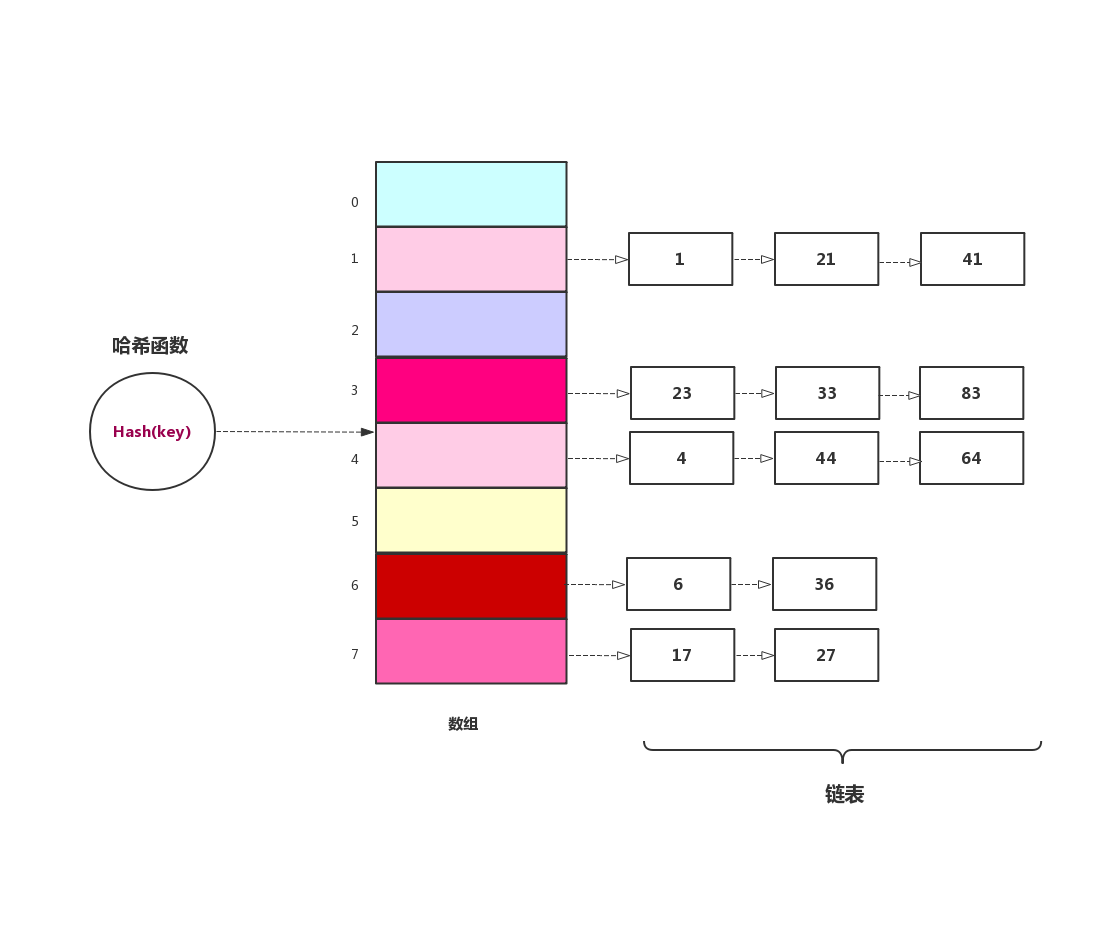
鏈表法解決哈希衝突代碼比較簡單,但是代碼比較多,因為需要維護一個鏈表的操作,我們這裡採用有序鏈表,有序鏈表不能加快成功的查找,但是可以減少不成功的查找時間,因為只要有一項比查找值大,就說明沒有我們需要查找的值,刪除時間跟查找時間一樣,有序鏈表能夠縮短刪除時間。但是有序鏈表增加了插入時間,我們需要在有序鏈表中找到正確的插入位置。
有序鏈表操作類
public class SortedLinkList { private Link first; public SortedLinkList(){ first = null; } /** *鏈表插入 * @param link */ public void insert(Link link){ int key = link.getKey(); Link previous = null; Link current = first; while (current!=null && key >current.getKey()){ previous = current; current = current.next; } if (previous == null) first = link; else previous.next = link; link.next = current; } /** * 鏈表刪除 * @param key */ public void delete(int key){ Link previous = null; Link current = first; while (current !=null && key !=current.getKey()){ previous = current; current = current.next; } if (previous == null) first = first.next; else previous.next = current.next; } /** * 鏈表查找 * @param key * @return */ public Link find(int key){ Link current = first; while (current !=null && current.getKey() <=key){ if (current.getKey() == key){ return current; } current = current.next; } return null; } public void displayList(){ System.out.print("List (first-->last): "); Link current = first; while (current !=null){ current.displayLink(); current = current.next; } System.out.println(" "); } }鏈表法哈希表插入
在鏈表法中由於產生哈希沖的元素都存放在鏈表中,所以鏈表法的插入非常簡單,只需要在對應下標的鏈表中添加一個元素即可。
/** * 鏈表法插入 * * @param data */ public void insert(int data) { Link link = new Link(data); int key = link.getKey(); int hashVal = hash(key); array[hashVal].insert(link); }鏈表法哈希表查找
/** * 鏈表法-查找 * * @param key * @return */ public Link find(int key) { int hashVal = hash(key); return array[hashVal].find(key); }鏈表法哈希表刪除
鏈表法中的刪除就不需要向開放地址法那樣將元素置為某個特定值,鏈表法中只需要找到相應的鏈表將這一項直接移除。
/** * 鏈表法-刪除 * * @param key */ public void delete(int key) { int hashVal = hash(key); array[hashVal].delete(key); }哈希表的效率
在哈希表中執行插入和搜索操作都可以達到O(1)的時間複雜度,在沒有哈希衝突的情況下,只需要使用一次哈希函數就可以插入一個新數據項或者查找到一個已經存在的數據項。
如果發生哈希衝突,插入和查找的時間跟探測長度成正比關係,探測長度取決於裝載因子,裝載因子是用來表示空位的多少
裝載因子的計算公式:
裝載因子 = 表中已存的元素 / 表的長度
裝載因子越大,說明空閑位置越少,衝突越多,散列表的性能會下降。
開放地址法和鏈表法的比較
如果使用開放地址法,對於小型的哈希表,雙哈希法要比二次探測的效果好,如果內存充足並且哈希表一經創建,就不再修改其容量,在這種情況下,線性探測效果相對比較好,實現起來也比較簡單,在裝載因子低於0.5的情況下,基本沒有什麼性能下降。
如果在創建哈希表時,不知道未來存儲的數據有多少,使用鏈表法要比開放地址法好,如果使用開放地址法,隨着裝載因子的變大,性能會直線下降。
當兩者都可以選時,使用鏈表法,因為鏈表法對應不確定性更強,當數據超過預期時,性能不會直線下降。
哈希表在JDK中有不少的實現,例如HahsMap、HashTable等,對哈希表感興趣的可以閱讀本文後去查看JDK的相應實現,相信這可以增強你對哈希表的理解。
如果您發現文中錯誤,還請多多指教。歡迎關注個人公眾號,一起交流學習。
最後
打個小廣告,金九銀十跳槽季,平頭哥給大家整理了一份較全面的 Java 學習資料,歡迎掃碼關注微信公眾號:「平頭哥的技術博文」領取,祝各位升職加薪。

