一次flume exec source採集日誌到kafka因為單條日誌數據非常大同步失敗的踩坑帶來的思考
- 2019 年 11 月 7 日
- 筆記
本次遇到的問題描述,日誌採集同步時,當單條日誌(日誌文件中一行日誌)超過2M大小,數據無法採集同步到kafka,分析後,共踩到如下幾個坑。
1、flume採集時,通過shell+EXEC(tail -F xxx.log 的方式) source來獲取日誌時,當單條日誌過大超過1M時,source端無法從日誌中獲取到Event。
2、日誌超過1M後,flume的kafka sink 作為生產者發送給日誌給kafka失敗,kafka無法收到消息。
以下針對踩的這兩個坑做分析,flume 我使用的是1.9.0版本。 kafka使用的是2.11-2.0.0版本
問題一、flume採集時,通過shell+EXEC(tail -F xxx.log 的方式) source來獲取日誌時,當單條日誌過大超過1M時,source端無法從日誌中獲取到Event。flume的配置如下:
...... agent.sources = seqGenSrc ...... # For each one of the sources, the type is defined agent.sources.seqGenSrc.type = exec #agent.sources.seqGenSrc.command = tail -F /opt/logs/test.log|grep businessCollection|awk -F '- {' '{print "{"$2}' agent.sources.seqGenSrc.command = tail -F /opt/logs/test.log|grep businessCollection agent.sources.seqGenSrc.shell = /bin/bash -c agent.sources.seqGenSrc.batchSize = 1 agent.sources.seqGenSrc.batchTimeout = 90000 ......
原因:採用shell+EXEC方式的時候,flume的源碼中使用的是如下的方式來獲取日誌
private Process process = null; //使用這種方式來執行命令。 process = Runtime.getRuntime().exec(commandArgs); //讀取日誌 reader = new BufferedReader( new InputStreamReader(process.getInputStream(), charset));
在一行日誌超過1M後,這個代碼就假死了,一直宕住,導致無法獲取到數據。
針對這個問題處理方式:
方式一:修改源碼的實現方式。(1.9.0的源碼 對應的是源碼中的flume-ng-core 項目中的org.apache.flume.source.ExecSource.java 這個類)
//process的採用如下方式獲和執行命令,就改一行代碼。增加.redirectErrorStream(true)後,輸入流就都可以獲取到,哪怕超過1M process = new ProcessBuilder(commandArgs).redirectErrorStream(true).start();
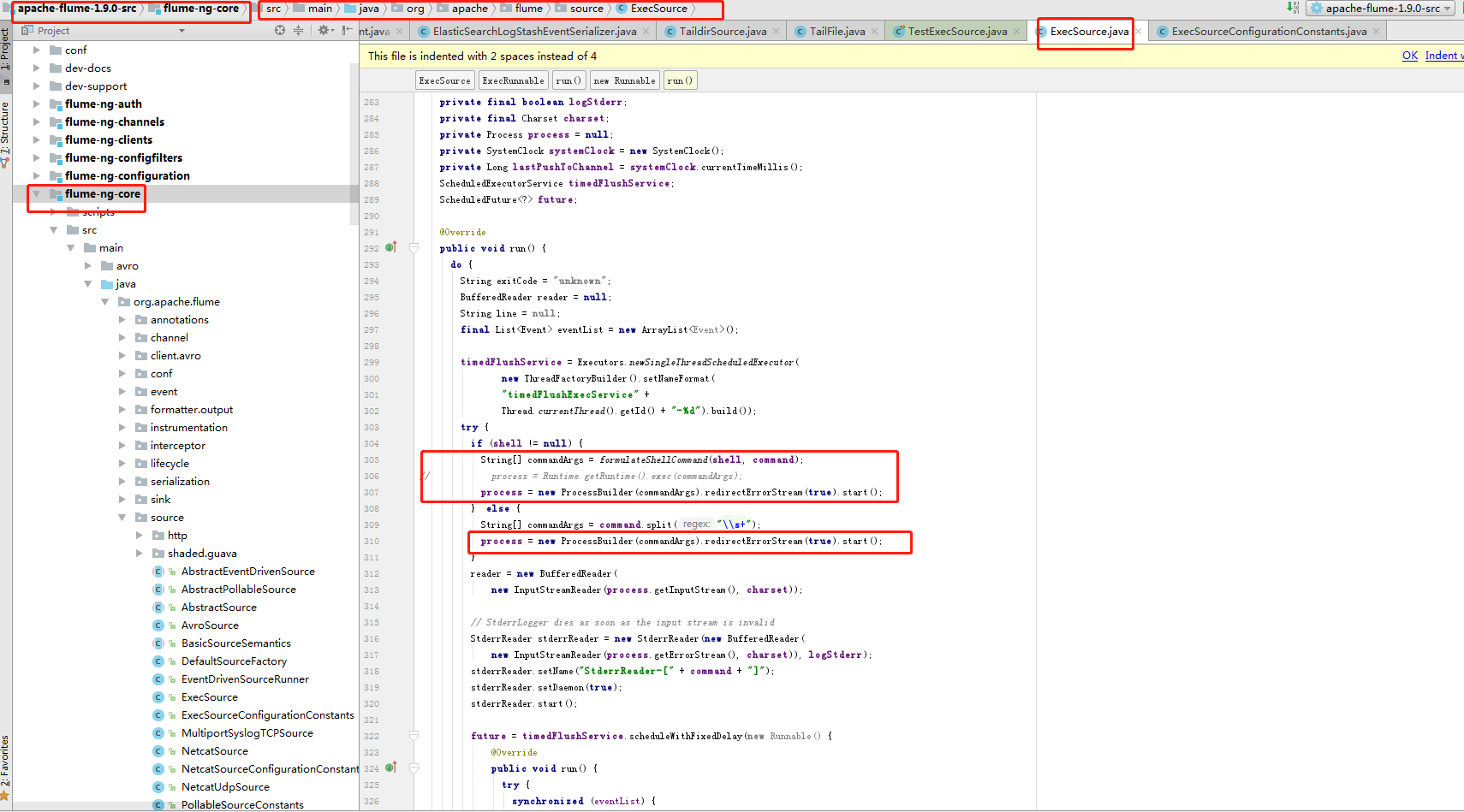
修改完成後,重新打包編譯,然後將生成的jar包替換原來老的jar包。
方式二:放棄EXECSource,使用TAILDIR Source。 使用這個source時,對應的配置如下:
...... agent.sources = seqGenSrc ...... # For each one of the sources, the type is defined agent.sources.seqGenSrc.type = TAILDIR agent.sources.seqGenSrc.positionFile = ./taildir_position.json agent.sources.seqGenSrc.filegroups = seqGenSrc agent.sources.seqGenSrc.filegroups.seqGenSrc = /opt/logs/test.log agent.sources.seqGenSrc.fileHeader = false agent.sources.seqGenSrc.batchSize = 1 ......
建議採用TAILDIR Source 比較好,這個可以對多個日誌進行監控和採集,而且日誌採集時會記錄日誌採集位置到positionFile 中,這樣日誌採集不會重複。EXEC SOURCE在重啟採集時數據會重複採集,還需要其他的方式去避免重複採集
問題二、日誌超過1M後,flume的kafka sink 作為生產者發送給日誌給kafka失敗,kafka無法收到消息
原因:kafka 在默認情況下,只能接收1M大小以內的消息,在沒有做自定義設置時。所以單條消息大於1M後是無法處理的。
處理方式如下:
1)、修改kafka 服務端server.properties文件,做如下設置(修改大小限制)
# The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=502400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=502400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 message.max.bytes=5242880 replica.fetch.max.bytes=6291456
2)、修改producer.properties,做如下設置(修改大小限制)
# the maximum size of a request in bytes max.request.size= 9242880
3)、java代碼中在初始化kafka 生產者時,也需要指定max.request.size= 9242880
Properties properties = new Properties(); ... properties.put("max.request.size", 5242880); ... KafkaProducer<Object,Object> kafkaProducer = new KafkaProducer<Object,Object>(properties);
4)、消費者在消費kafka數據時,也需要注意設置消費消息的大小限制
Properties properties = new Properties(); ... properties.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 6291456); ... KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
對於flume不了的同學,可以看flume 1.9中文版用戶指南:https://www.h3399.cn/201906/700076.html