小白也能看懂的Redis教學基礎篇——朋友面試被Skiplist跳躍表攔住了
各位看官大大們,雙節快樂 !!!
這是本系列博客的第二篇,主要講的是Redis基礎數據結構中ZSet(有序集合)底層實現之一的Skiplist跳躍表。
不知道那些是Redis基礎數據結構的看官們,可以翻閱我的上一篇文章:
小白也能看懂的REDIS教學基礎篇——REDIS基礎數據結構

今天我朋友突然找到我,說他面試被刷了。
我一臉吃驚,忙問到:怎麼了,倒在什麼題上了。
朋友說:面試官說,你說你了解Redis的基礎數據結構,那我問問你,你知道什麼是Skiplist跳躍表嗎?講講它是一種什麼樣的數據結構。它有什麼優勢和缺陷,它是如何插入和刪除的?
我:那你怎麼回答的?
我朋友:我就說Redis不是只有五種基本數據結構 字符串(strings),列表(lists), 字典(dictht),集合(sets), 有序集合(ZSet)嗎?然後人家就讓我回家等通知了。
我:…
我朋友:怎麼了,你怎麼一副無語的表情。

我:哎,還是由我來給你科普一下吧。
Skiplist 跳躍表是跳錶出自 William Pugh 於1989年發表的論文《Skip Lists: A Probabilistic Alternative toBalanced Trees 》。
在論文中 William Pugh 寫到;

譯文大意為:
跳躍表:平衡樹的概率替代方案
跳躍列表是一種可以代替平衡樹的數據結構。跳躍列表使用概率平衡,而不是嚴格的強制平衡,因此在跳躍列表中插入和刪除的算法比平衡樹的算法簡單得多,速度也快得多。
註:平衡樹(Balance Tree) 指的是,任意節點的子樹的高度差都小於等於1。常見的符合平衡樹的有,B樹(多路平衡搜索樹)、AVL樹(二叉平衡搜索樹)。
看到這裡,看官們是不是一頭霧水?先不要急,讓我們來看看跳躍表的完整結構圖。

看到這的看官是不有種想罵人的衝動?心裏在想,這是個什麼玩意,比平衡樹還複雜。

//跳錶 typedef struct zskiplist{ //頭結點和尾節點的指針 struct skiplistNode *header, *tail; //表中節點的數量 unsigned long length; //表中層數最大的節點層數 int level; }; //跳錶節點 typedef struct zskiplistNode{ //後退指針 struct zskiplistNode *backward; //分值 double score; //成員對象 robj *obj; //層 struct zskiplistLevel{ //前進指針 struct zskiplistNode *forward; //跨度 unsigned int span; } level[]; };
- skiplistNode *header, *tail 指向首尾節點的指針。
- long length 表中節點的總數。
- int level 所有節點中層數最高的節點的層數。
- zskiplistNode *backward 後退指針,用來從尾部開始遍歷到首節點。
- double score 分值,元素的排位分值。
- robj *obj 元素的對象指針。
- zskiplistNode *forward 前進指針指向該層下一個元素的指針。
- int span 跨度,用於記錄兩個節點之間的距離,跨度越大證明兩個節點離得越遠,在查找某個節點的過程中,將跨度累加,就是這個節點在跳躍表中的排位rank。
層是跳躍表節點的精髓和核心所在,跳躍表節點的level數組可以包含多個層元素。每個層元素都包含一個指向其他節點的指針,程序可以通過這些層來快速查找其他節點。一般來說,層數量越多,查找其他元素的速度就越快。
但是一個元素在插入時,他的層是怎麼獲得的呢?我們來看下面這個方法(此方法是仿照論文中的描述,用java實現的)。
/** * 獲取層級 * @param maxLevel 最大支持的層級數 * @return */ private int randomLevel(int maxLevel){ int lvl = 1; /** * 這裡是關鍵 Math.random() > (0.5D) 等於true 的概率是 1/2 * 所以 lvl = 1 的概率是 1/2 lvl = 2 的概率 是 (1/2)*(1/2) = 1/4 * lvl = 3 的概率是 (1/2)*(1/2)*(1/2) = 1/8 從這裡可以看出 lvl 越大概率越低 */ for(;Math.random() > (0.5D) && lvl < maxLevel;){ lvl += 1; } return lvl; }
從這個方法可以看出,對於每次新插入的元素,都要調用這個隨機算法獲得元素的層級。這裡也正好對應了文章開頭,論文中的話:跳躍列表使用概率平衡,而不是嚴格的強制平衡。
從概率上來說,期望的目標是分配到lv 1 是50%的概率,分配到lv 2 是百分之25%的概率,分配到lv 3 是12.5% 以此類推。Redis的跳躍表共有32層,可以容納 2^32 個元素,在Redis標準源碼中
元素的晉陞幾率只有25%,也就是上面代碼中 0.5D 這個其實應該是 0.25D。所以Redis中的跳躍表更加扁平化,層高相對不高,這就帶來一個問題,層高不高的話,跨度就小,查找元素需要遍歷的次數也就相應的增加了。
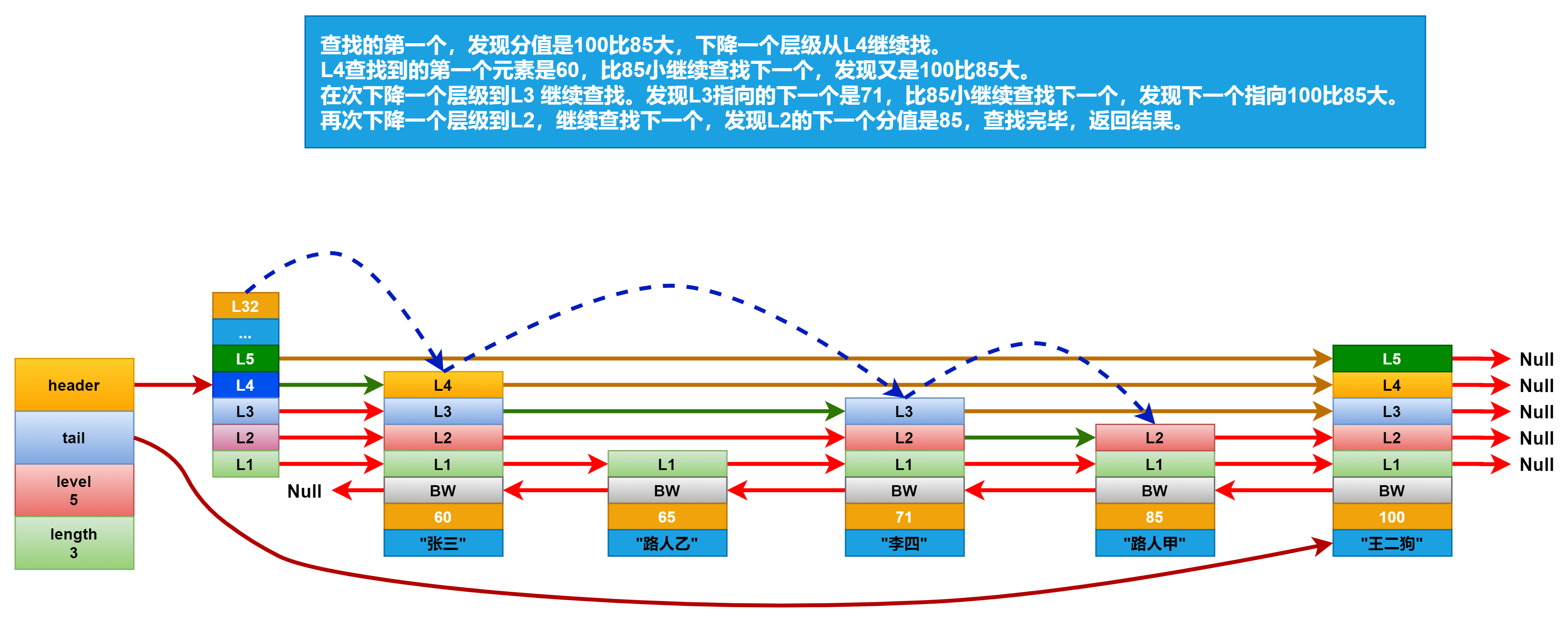
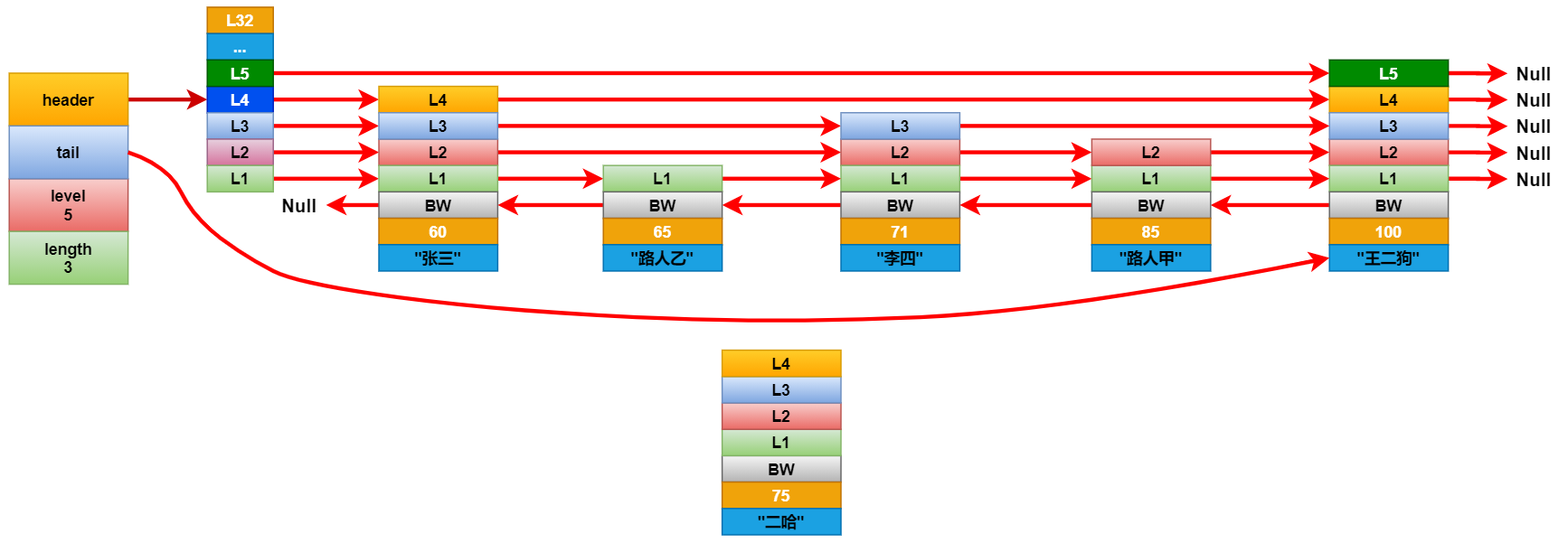
查找元素:
跳越表的元素查找是從header 的第 zskiplist.level(表中層數最大的節點層數) 層開始遍歷的。他先會判斷最高層指向的下一個元素,是否是要找的元素,如果不是,判斷是不是比要找的元素小,
如果比要找的元素小,就繼續查找下一個。如果比要找的元素大,就向下走一個層級,比如一開始是lv 5,如果找到的元素比要找的元素大,就下降一個層級,到lv 4 繼續找。以此類推,直到找到期望的元素為止。
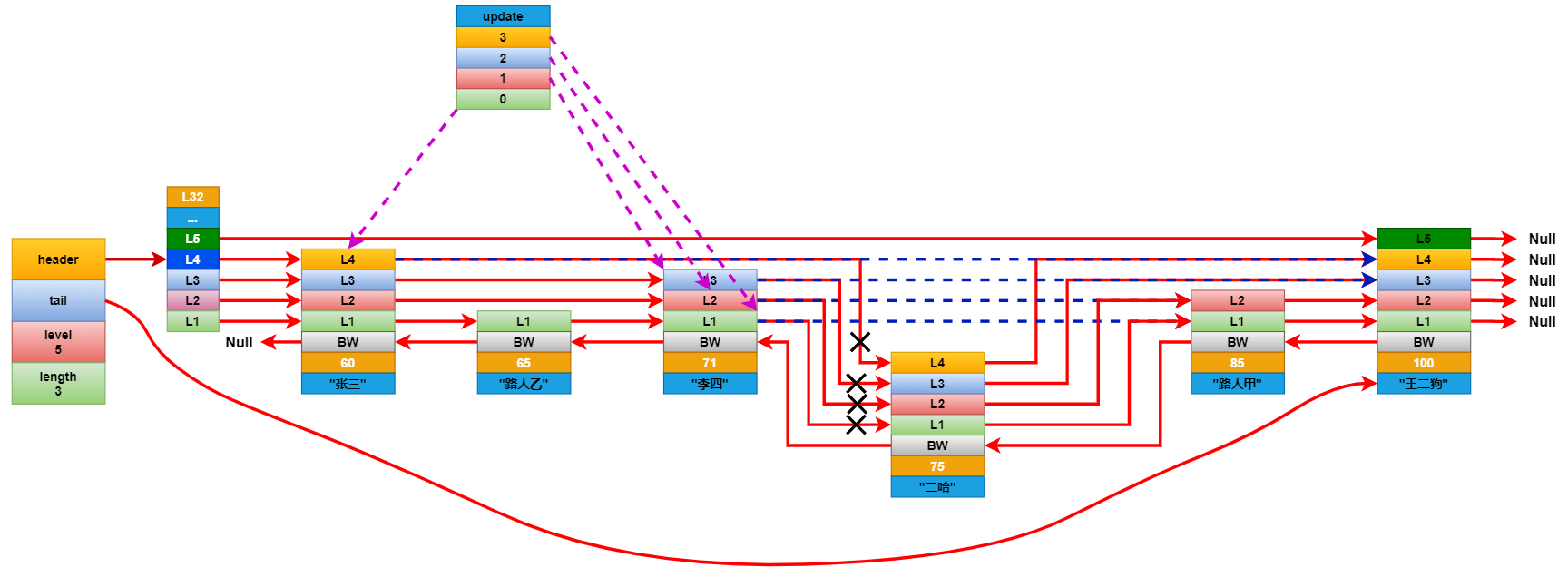
現在我們要查找分數為85分的學生,查找路徑如下圖所示
插入元素:
創建一個新的元素節點。然後在調用 randomLevel 獲取節點層級。

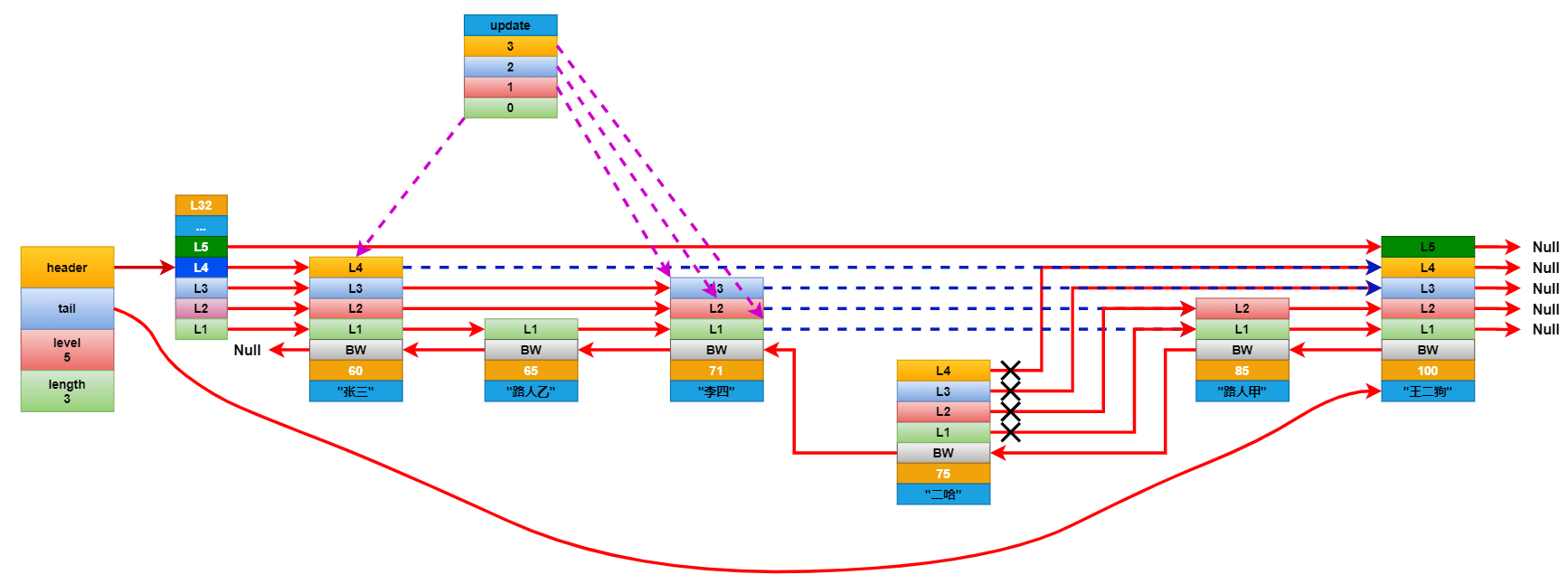
想要插入元素,就要先查找到所有元素中分值僅小於插入元素的分值的原數。比如要在上面的列表中插入一個分數為75分的學生二哈,就要先查找到分數僅小於75分的學生。在查找的時候還要記錄下要更新的層級。如二哈這個節點擁有L4就要記錄下據距他最近的L4,L3,L2,L1。

將新增節點每個層的前進指針連接到它對應的要更新層的前進指針指向的下一個節點。然後遍歷要更新的層數組,斷開這些層的前進指針,並將它連接到新增的幾點上。這裡基本和鏈表是一樣的更新方式。最後更新後退節點。
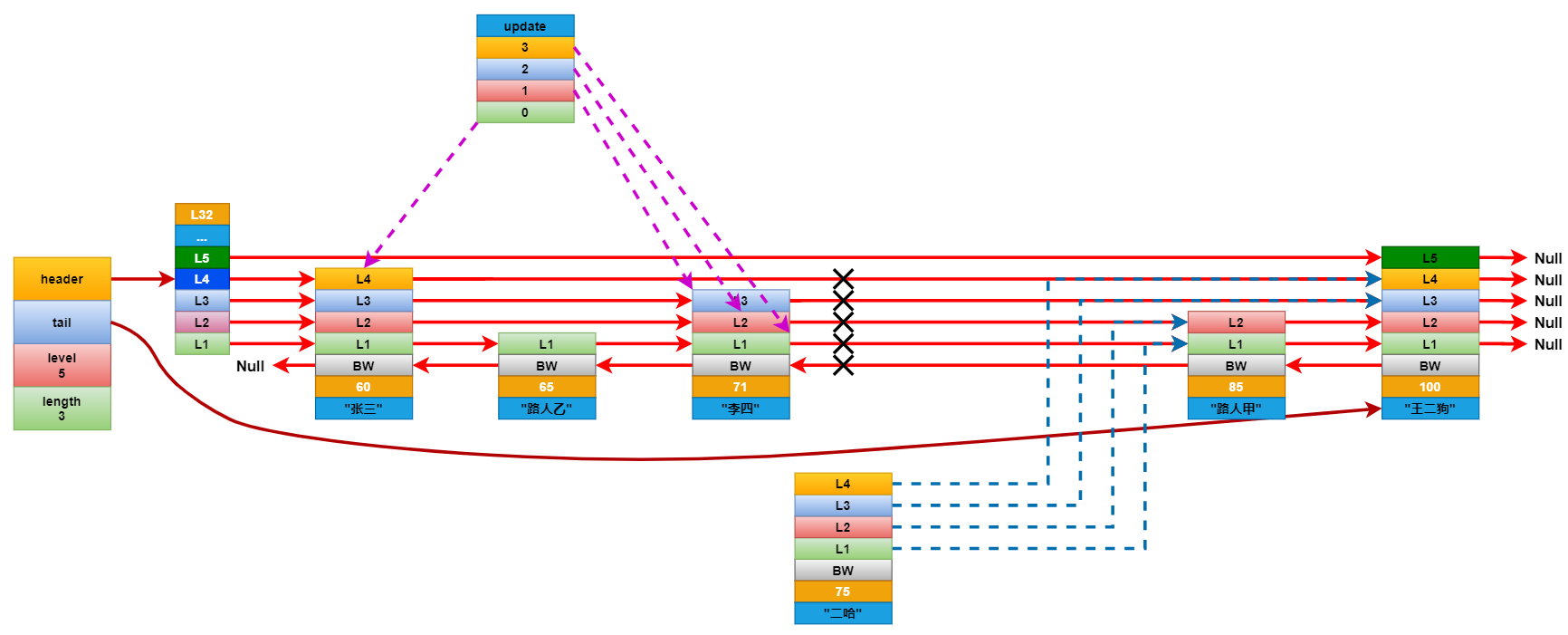
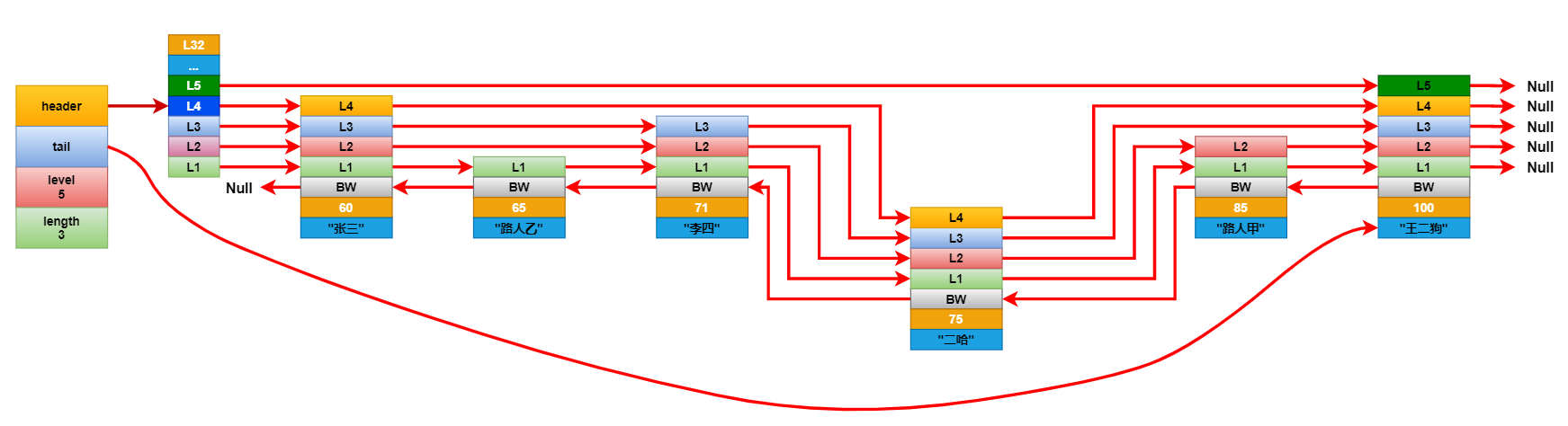
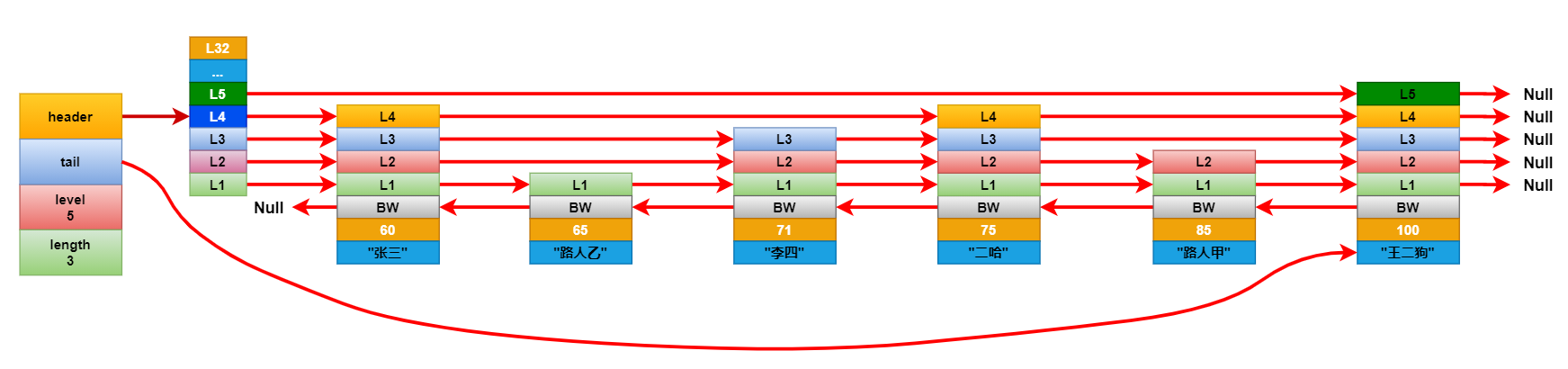
連接更新完成後,看看新增節點的層級是否大於跳躍表中記錄的節點最大層級高度,如果大於就將跳躍表的最大層級高度更新成新節點的層級高度。
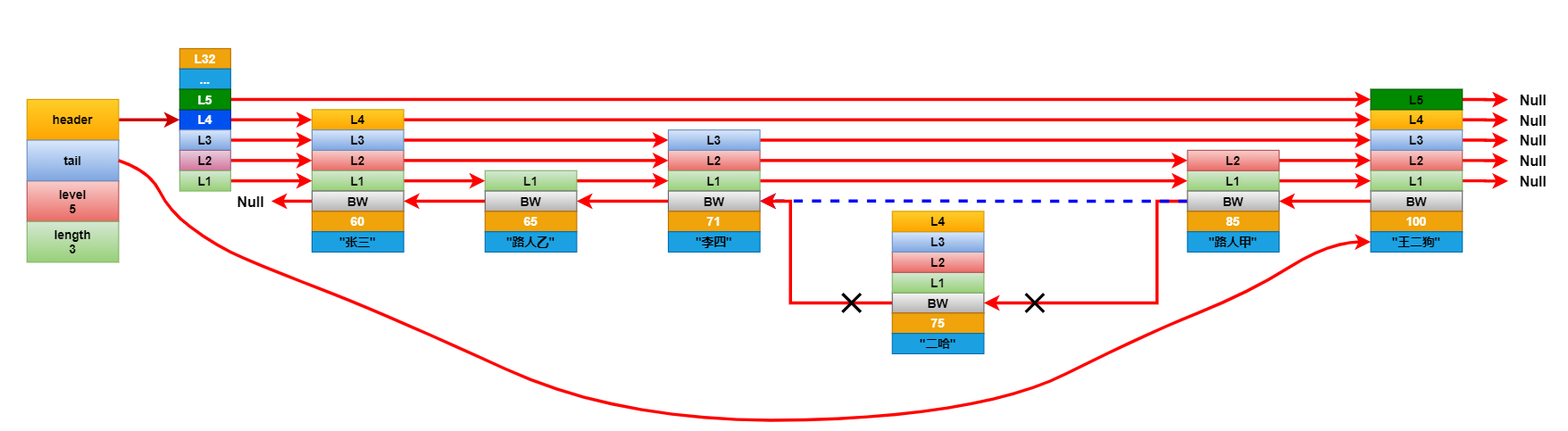
刪除元素:
刪除節點過程和插入類似,都需要先把這個節點找出,然後對於每個相關節點重排一下向前向後指針,同時還要注意更新下跳躍表中記錄的最大層級高度。

更新元素:
當我們調用ZSet的zadd方法時,如果該元素不存在,就執行正常的插入過程。如果元素已經存在了,如果要更新分值,則Redis會先刪除原先的元素,在插入新的元素。如果不用更新分值,Redis會直接更新節點上的元素數據(這是在5.0以後的改動,之前的是不論跟不跟新都直接先刪除在插入)。
參考書籍:
《Reids設計與實現》
《Redis深度歷險——核心原理與應用實踐》
創作不易,如果轉載請註明出處,小編在此感謝各位看官。


