機器閱讀理解(看各類QA模型與花式Attention)
- 2019 年 11 月 7 日
- 筆記
目錄
簡介
機器閱讀理解(Machine Reading Comprehension)為自然語言處理的核心任務之一,也是評價模型理解文本能力的一項重要任務,其本質可以看作是一種句子關係匹配任務,其具體的預測結果與具體任務有關。
記錄一下之後用來實踐的數據集:
閱讀理解任務具有多種類別:單項/多項選擇、完形填空以及抽取式問答。百度發佈的DuReader機器閱讀理解數據集涵蓋了以上三種任務類型,因此選擇用來實踐也是非常合適的。
DuReader數據集的樣本可用一個四維數組表示:{q, t, D, A},其中q表示問題,t表示問題類型,D表示文檔集合,A表示答案集合。一半的樣本來源於百度搜索引擎,一半來源於百度知道。下圖展示了DuReader數據集的不同類型樣本。(這裡記錄一下數據集,之後要是出了實踐代碼這裡再補上)

經典模型概述
這裡記錄一下比較經典的機器閱讀理解模型,或者說記錄一下各種花式 Attention,想要了解細節的小夥伴也可以去看看原文,這裡也都附上了鏈接。
Model 1: Attentive Reader and Impatient Reader
原文鏈接:Teaching Machines to Read and Comprehend
這篇文章提出的模型有三個:The Deep LSTM Reader、The Attentive Reader 和 The Impatient Reader。最主要的貢獻還是 Attentive Reader 和 Impatient Reader 這兩個模型,這兩個模型也是機器閱讀理解一維匹配模型和二維匹配模型的開山鼻祖。
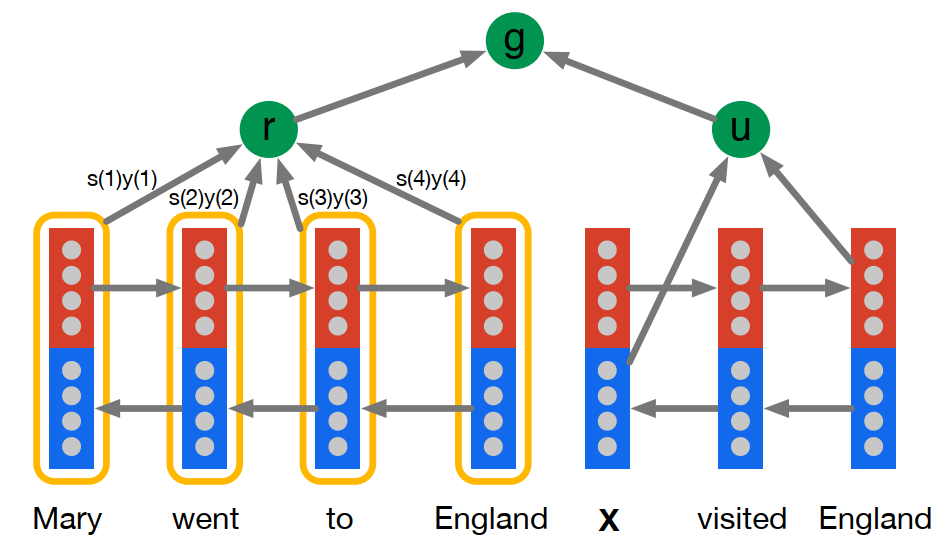
Attentive Reader 的基本結構如上圖所示,實際上也比較簡單,就是一個簡單的細粒度注意力機制在機器閱讀理解任務中的經典應用。
- u 是問題 q 在經過雙向 LSTMs 編碼後的最後一個前向輸出狀態和最後一個後向輸出狀態的拼接。
[u = overrightarrow{y_{q}}(|q|)||overleftarrow{y_{q}}(1)] - (y_d(t)) 是文檔 d 中 第 t 個詞經過雙向 LSTMs 編碼後的前向輸出狀態和後向輸出狀態的拼接。
[y_d(t) = overrightarrow{y_{d}}(t)||overleftarrow{y_{d}}(t)] - 將文檔 d 的單詞表示(y_d(t))作為Key,將問題表示 u 作為 Query,輸入一個注意力層,得到問題對文檔的注意力加權表徵 r。
[m(t) = tanh{(W_{ym}y_d(t)+W_{um}u)} \ s(t) propto exp{(W^mathrm{T}_{ms}m(t))}\ r = y_ds] - 模型最後將文檔表示 r 和問題表示 u 通過一個非線性函數進行結合進行判斷。
[g^{AR}(d,q) = tanh{(W_{rg}r+W_{ug}u)}]
Impatient Reader 就是在 Attentive Reader 的一種變體,模型結構如下圖所示:
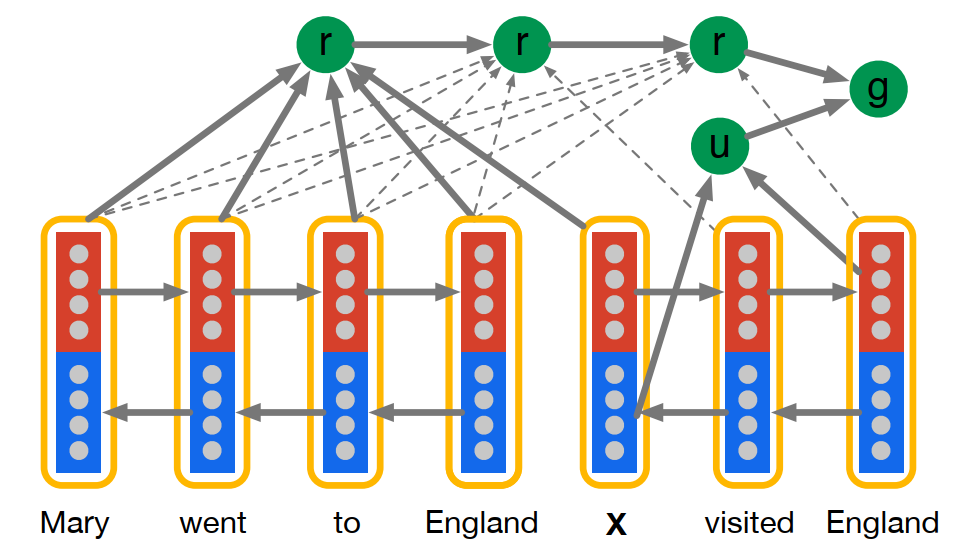
由上圖可知,我們可以總結出以下幾點區別:
-
Impatient Reader 在計算注意力的時候,將每個單詞當作一個單獨的 Query 從而計算該單詞對於 doc 中每個詞的注意力加權表徵,並用非線性變換將所有的 r 進行反覆累積(單詞的重閱讀能力),即:
[y_q(i) = overrightarrow{y_{q}}(i)||overleftarrow{y_{q}}(i)\m(i,t) = tanh{(W_{dm}y_d(t)+W_{rm}r(i-1)+W_{qm}y_q(i))}, 1leq i leq |q|\ s(i,t) propto exp{(W^mathrm{T}_{ms}m(i,t))}\r(0) = r_0\ r(i) = y^mathrm{T}_ds(i)+tanh{(W_{rr}r(i-1))}, 1leq i leq |q|] -
最後將最後一個文檔表示 r(|q|) 和問題表示 u 進行非線性組合用於答案預測。
[g^{IR}(d,q) = tanh{(W_{rg}r(|q|)+W_{qg}u)}]
介紹了模型結構之後,我們就可以從兩個模型的區別來總結一下一維匹配模型與二維匹配模型的區別:
- 所謂的一維匹配模型,即將問題直接編碼為一個固定長度的向量,在計算注意力分數的時候,等效於直接計算文檔 d 每個詞在特定問題上下文向量中作為答案的概率,也正是在計算問題向量 Q 與文檔各個詞的匹配關係中形成的一維線性結構,我們可以將其稱為一維匹配模型;
- 二維匹配模型,直接輸出問題 Q 每一個詞的編碼,計算注意力的時候,計算文檔 Q 中每一個詞對 D 中每一個詞的注意力,即形成了一個詞 – 詞的二維匹配結構。由於二維匹配模型將問題由整體表達語義的一維結構轉換成為按照問題中每個單詞及其上下文的語義的二維結構,明確引入了更多細節信息,所以整體而言模型效果要稍優於一維匹配模型。
Model 2: Attentive Sum Reader
原文鏈接:Text Understanding with the Attention Sum Reader Network
這篇文章的模型主題基本與 Attentive Reader 十分類似,是一種一維匹配模型,主要是在最後的 Answer 判斷應用了一種 Pointer Sum Attention 機制,模型結構如下圖所示:
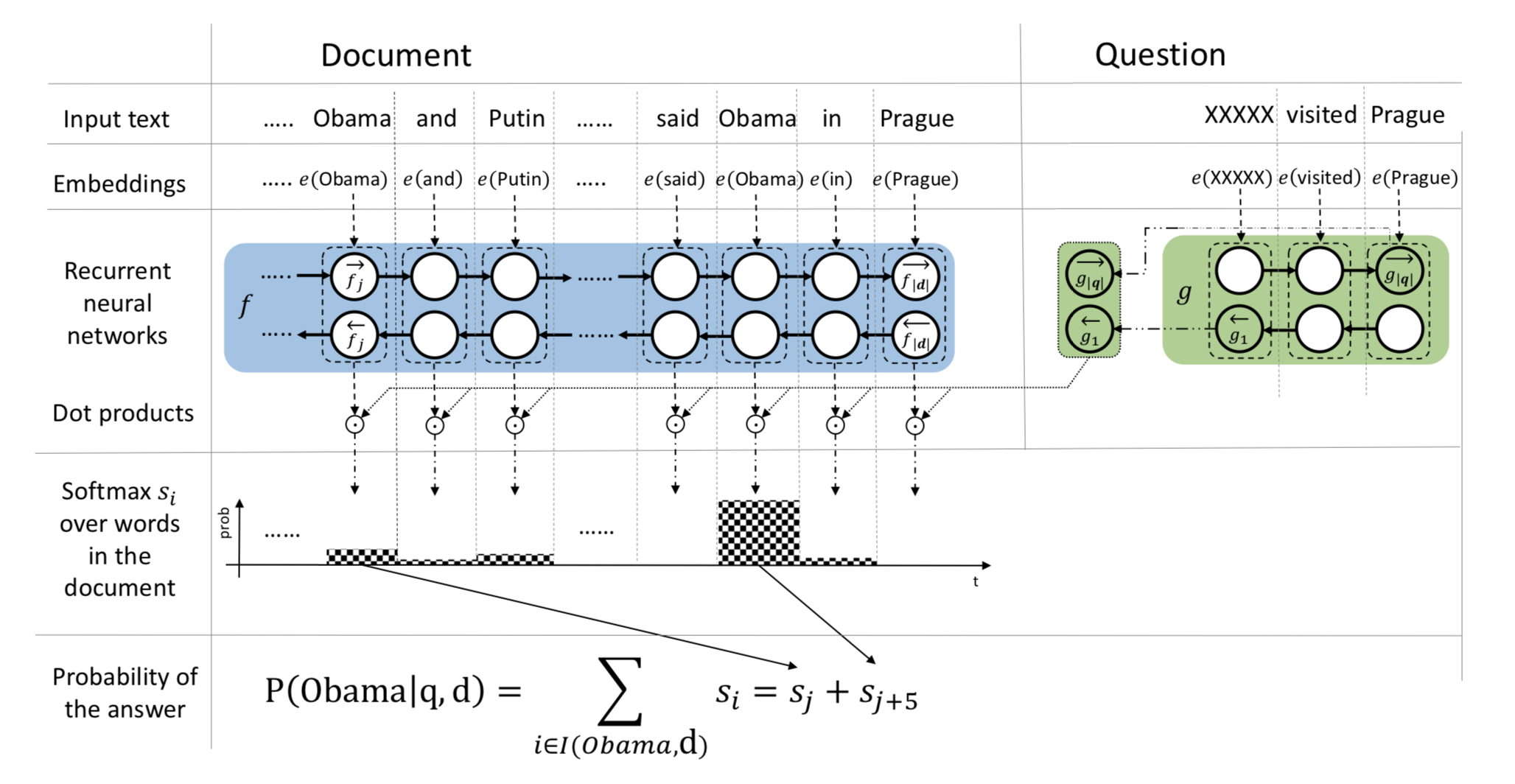
對該模型做一個簡單的解釋:
- 與 Attentive Reader 一樣,應用兩個RNN(該文中為GRU)對 Document 和 Question 分別進行編碼
- Attention層應用的是 Dot Attention,相對於 Attentive Reader 參數更少,即注意力權重
[s(i,t) propto exp{f_i(d) cdot g(q)}] - 我們之前提到過,一維匹配模型的注意力分數等效於直接文檔 d 中每個詞在特定問題上下文向量中作為答案的概率,該模型的做法就是,在得到每個詞Softmax歸一化之後的分數後,將同類型的詞的分數累加,得分最高的詞即為答案(即作者提到的Pointer Sum Attention)
[P(w|q, d) = sum_{i in I(w, d)}s_i]
這樣一個將注意力分數累加的操作將受到一個詞出現次數的影響,通常,出現次數越多的詞越可能成為問題的答案,這樣是否是合理的呢?實驗數據表明這樣的假設確實是合理的。該模型的結構以及Attention的求解過程明顯比 Attentive Reader 更簡單,卻取得了更好的效果,這也意味着並不是越複雜的模型效果會更好,簡單的結構在合適的場景下能取得非常好的結果。
Model 3: Stanford Attentive Reader
該模型同樣是對 Attentive Reader 的改進,屬於一種一維匹配模型,我們先來看看熟悉的模型結構:

模型主體這裡就不講了,主要記錄一下其與 Attentive Reader 不一樣的部分:
-
注意力計算方式為bilinear(較點積的方式更靈活):
[alpha_i = softmax(q^TW_sp_i)\o = sum_ialpha_ip_i] -
得到注意力加權輸出(o)之後,然後直接用(o)進行分類預測,而 Attentive Reader 是用輸出與 query 又做了一次非線性處理之後才預測的,實驗證明移除非線性層不會傷害模型性能。
-
原來的模型考慮所有出現在詞彙表V中的詞來做預測。而該模型只考慮出現在文本中的實體(進一步減少參數)
上述三點中,第一點是比較重要的,而後面兩點都是對模型的一個簡化處理。
Model 4: AOA Reader
原文鏈接:Attention-over-Attention Neural Networks for Reading Comprehension
AOA Reader 屬於是一種二維匹配模型,該論文的亮點是將另一種注意力嵌套在現有注意力之上的機制,即注意力過度集中機制,其主要模型結構如下圖所示:
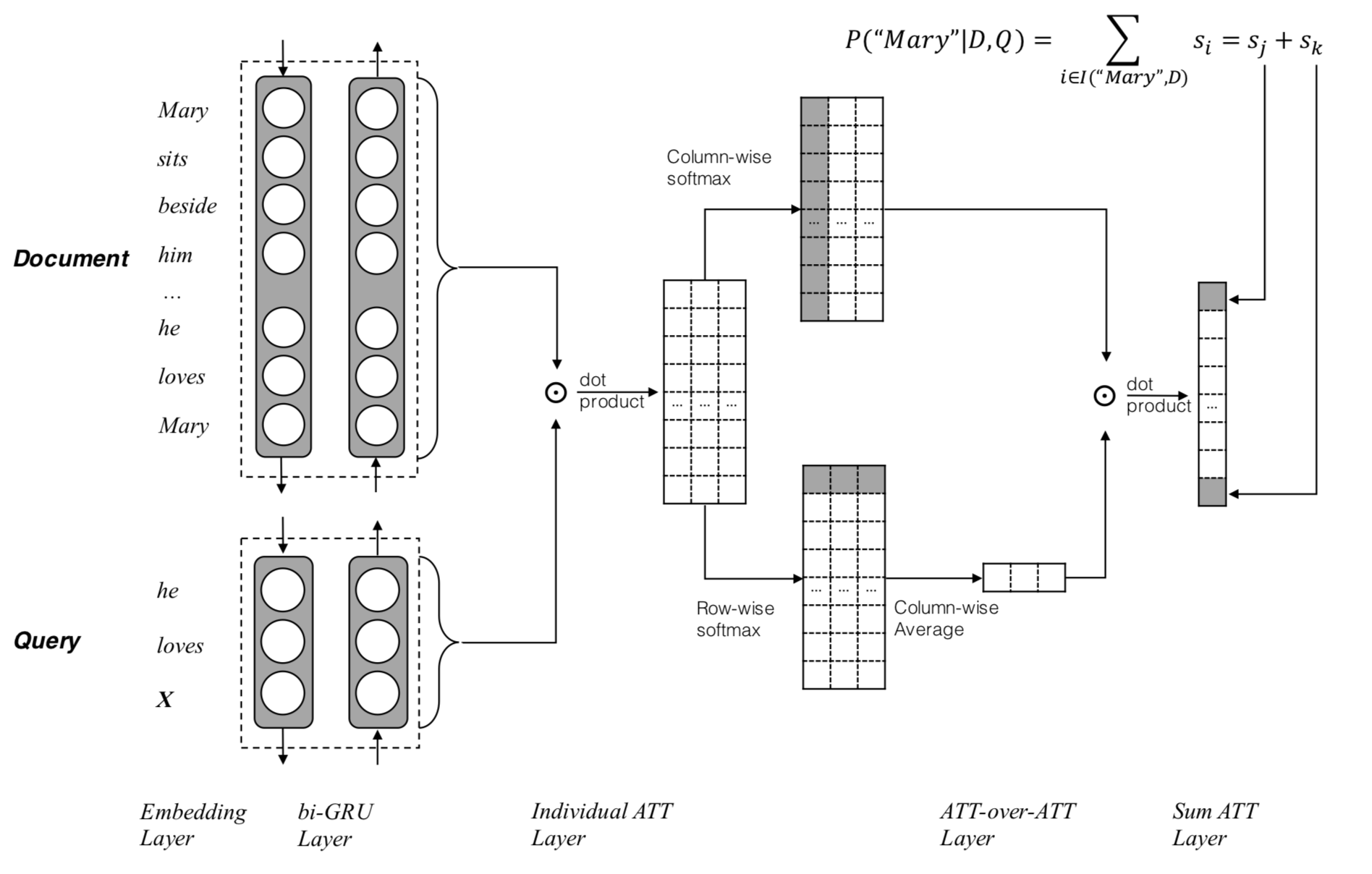
-
利用雙向GRU對 Document 和 Query分別編碼,得到編碼後的隱藏層表徵,即
[e(x) = W_e cdot x, where x in D, Q\ overrightarrow{h_s}(x) = overrightarrow{GRU}(e(x))\ overleftarrow{h_s(x)} = overleftarrow{GRU}(e(x))\ h_s(x) = [overrightarrow{h_s}(x); overleftarrow{h_s}(x)]] -
利用pair-wise matching matrix來計算得到注意力匹配分數:
[M(i,j)=h_{doc}(i)^T ·h_{query}(j)] -
在列方向上進行 Softmax 歸一化,注意上一個公式,每一列表示 query 一個詞對 doc 所有詞的注意力分數大小,得到所謂的 query-to-document attention
[alpha(t) = softmax(M(1, t), …, M(|D|, t))\ alpha = [alpha(1), alpha(2), …, alpha(|Q|)]] -
在行的方向進行 Softmax 歸一化,得到 document-to-query attention
[beta(t) = softmax(M(t, 1), …, M(t, |Q|))] -
將 document-to-query attention 作平均得到最終的 query-level attention:
[beta = frac{1}{n}sum_{t=1}^{|D|}beta (t)] -
最後,用每個query-to-document attention和剛剛得到的query-level attention做點乘,得到document中每個詞的score。
[s = alpha^Tbeta] -
與Attentive Sum Reader類似,最後預測答案詞的方式是將同類型的詞的分數累加,得分最高的詞即為答案,下式中,V為詞表:
[P(w|q, d) = sum_{i in I(w, d)}s_i, w in V] -
對於損失函數,我們可以直接最大化正確詞的概率分數即可,下式中,A為標註答案詞:
[L = sum_i log(p(x)), x in A]
Model 5: Match-LSTM and Answering Point
Match-LSTM:Learning Natural Language Inference with LSTM
Pointer Networks:Pointer Networks
Match-LSTM and Answering Point:Machine Comprehension Using Match-LSTM and Answer Pointer
由論文標題可知,該論文利用 Match-LSTM 以及 Answer Pointer 模型來解決機器閱讀理解問題,Match-LSTM也屬於二維匹配模型的一種,注意力求解方法我們下面再詳細介紹,該論文的主要貢獻在於將Pointer Net中指針的思想首次應用於閱讀理解任務中。首先,我們分別看看兩個模型的結構:
Match-LSTM
Match-LSTM最初提出是用於解決文本蘊含任務的。文本蘊含任務的目標是,給定一個 premise(前提),根據此 premise 判斷相應的 hypothesis(假說)正確與否,如果從此 premise 能夠推斷出這個 hypothesis,則判斷為 entailment(蘊含),否則為 contradiction(矛盾)。文本蘊含任務也可以看作是句子關係判斷任務的一種。
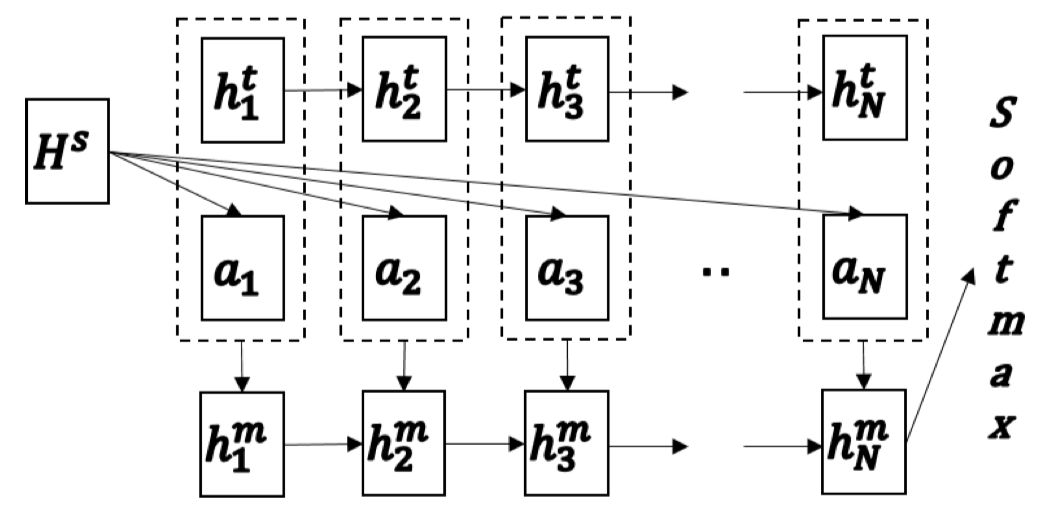
模型的主要結構如上圖所示,圖中,(H^S)為 premise 經過LSTM編碼後的隱藏層表徵,同理,(h_k^t)為 hypothesis 中第 (k) 個詞的隱藏層表徵。整個模型的計算如下:
- 得到兩個表徵之後,同樣是 Attention 操作(詳細的Attention計算方法參考原文)得到 hypothesis 對於 premise 每個詞注意力加權輸出(a_k)
- 將注意力加權輸出與 hypothesis 對應位置詞的隱藏層拼接(m_k=[a_k;h_k^t]),再將其通過一個長度為(N)的LSTM,得到一個 hypothesis 整合注意力向量的隱藏表徵,用最後一個時刻的隱藏層向量(h_N^m)預測最後結果。
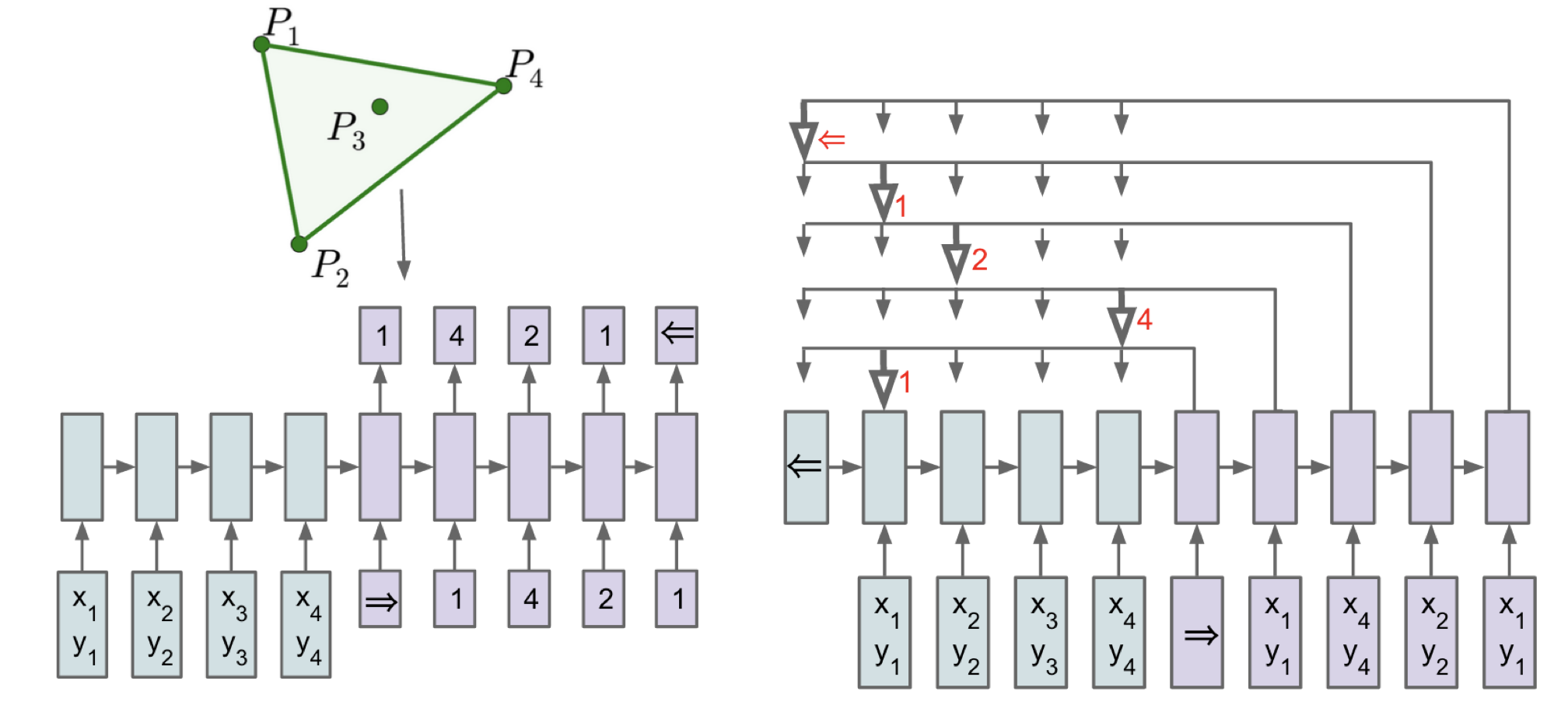
Pointer Net
Pointer Net的提出解決了一類特殊問題:如果生成的輸出序列中的字符必然出現於輸入序列,則我們可以採用Pointer Net的結構來得到輸出,而不需要事先規定固定詞表。這類模型在文本摘要任務中得到了廣泛的應用,主要思路如下圖所示:

對於左邊的傳統模型,如果給定的詞彙表已經限定,則模型無法預測大於4的數字,而對於右邊的Ptr-Net,我們不需要給定詞彙表,只需要在預測的時候每一步都指向輸入序列中權重最大的那個元素,由於輸出序列完全來自於輸入序列,則解空間完全可以隨着輸入序列變化。而我們在求 Attention 過程中的 Softmax 分數,正是每一個輸出位置對輸入序列的注意力大小,直接將最大分數的位置作為該輸出位置的指針即可。
Match-LSTM and Answering Point
將兩者結合起來,在機器閱讀理解任務中,可以將 question 當作 premise,將 passage 當作 hypothesis,整個模型的思路如下:
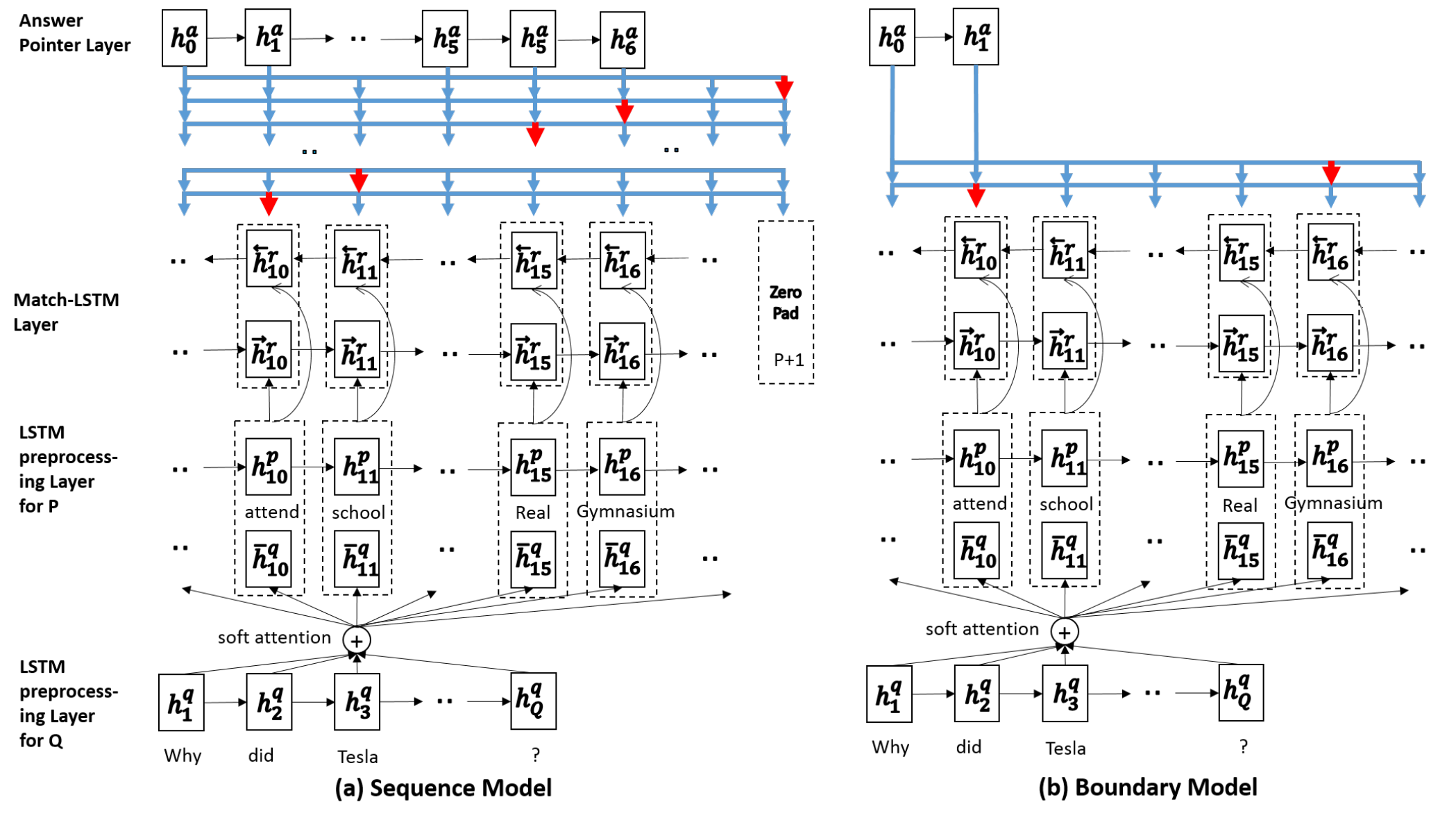
- 首先針對 question 以及 passage 用 LSTM 進行預編碼
- 對編碼過後的向量輸入到之前提到的Match-LSTM中,只是最後一層長度為 (N) 的 LSTM 改為了雙向LSTM,得到雙向LSTM的隱藏輸出(H^r),可以將其看作 passage 對 question 的初步 Attention 編碼結果
- 作者採用了兩種 Answer Point Layer 模型輸出預測結果
- Sequence Model:考慮到生成的答案在 passage 中不是連續存在的,因此預測的是一個答案標記序列
- 首先,使用注意機制再次獲得一個注意力權重向量,其中(beta_{k, j})是從段落中選擇第 j 個字符作為第 k 個答案字符的概率,(beta_{k,P+1})表示答案在段落第 k 個字符結束的概率,(beta_{k})將其按行 Softmax 得到第 k 個答案字符對段落中所有字符的注意力分數:
[F_k=tanh(Vwidetilde{H}^r+(W^ah^a_{k-1} + b^a)otimes e_{P+1})\beta_{k}=softmax(v^TF_k+cotimes e_{P+1})] - 上式中(widetilde{H}^r in mathbb{R}^{2l times (P +1)})為(H^r)與零向量的結合,((cdot otimes e_Q))表示將左邊的向量複製(Q)次(相當於廣播),(h_{k-1}^a in mathbb{R}^l)是LSTM的第k-1位置的隱藏向量,LSTM如下定義:
[h_k^a=overrightarrow{LSTM}(widetilde{H}^rbeta^T_k, h_{k-1}^a)] - 針對我們得到的(beta _{k,j}),我們可以將其表徵為 passage 中選擇第 j 個字符作為第 k 個答案字符的概率,即(p(a_k=j|a_1,a_2,…,a_{k-1},H^r)=beta _{k,j}),因此生成答案序列的概率為:
[p(a|H^r)=prod _kp(a_k|a_1,a_2,..a_{k-1},H^r)] - 損失函數可以直接定義為最小化答案字符位置概率的負數,即
[-sum _{n=1}^Nlogp(a_n|P_n,Q_n)]
- 首先,使用注意機制再次獲得一個注意力權重向量,其中(beta_{k, j})是從段落中選擇第 j 個字符作為第 k 個答案字符的概率,(beta_{k,P+1})表示答案在段落第 k 個字符結束的概率,(beta_{k})將其按行 Softmax 得到第 k 個答案字符對段落中所有字符的注意力分數:
- Boundary Model:其與 Sequence Model 非常類似,只是默認生成的答案在 passage 中是連續存在的,因此只需要預測開始位置,且在已知開始位置的基礎上預測一個結束位置即可,即:
[p(a|H^r)=p(a_s|H^r)p(a_e|a_s,H^r)]
- Sequence Model:考慮到生成的答案在 passage 中不是連續存在的,因此預測的是一個答案標記序列
Model 5: BiDAF
原文鏈接:Bidirectional Attention Flow for Machine Comprehension
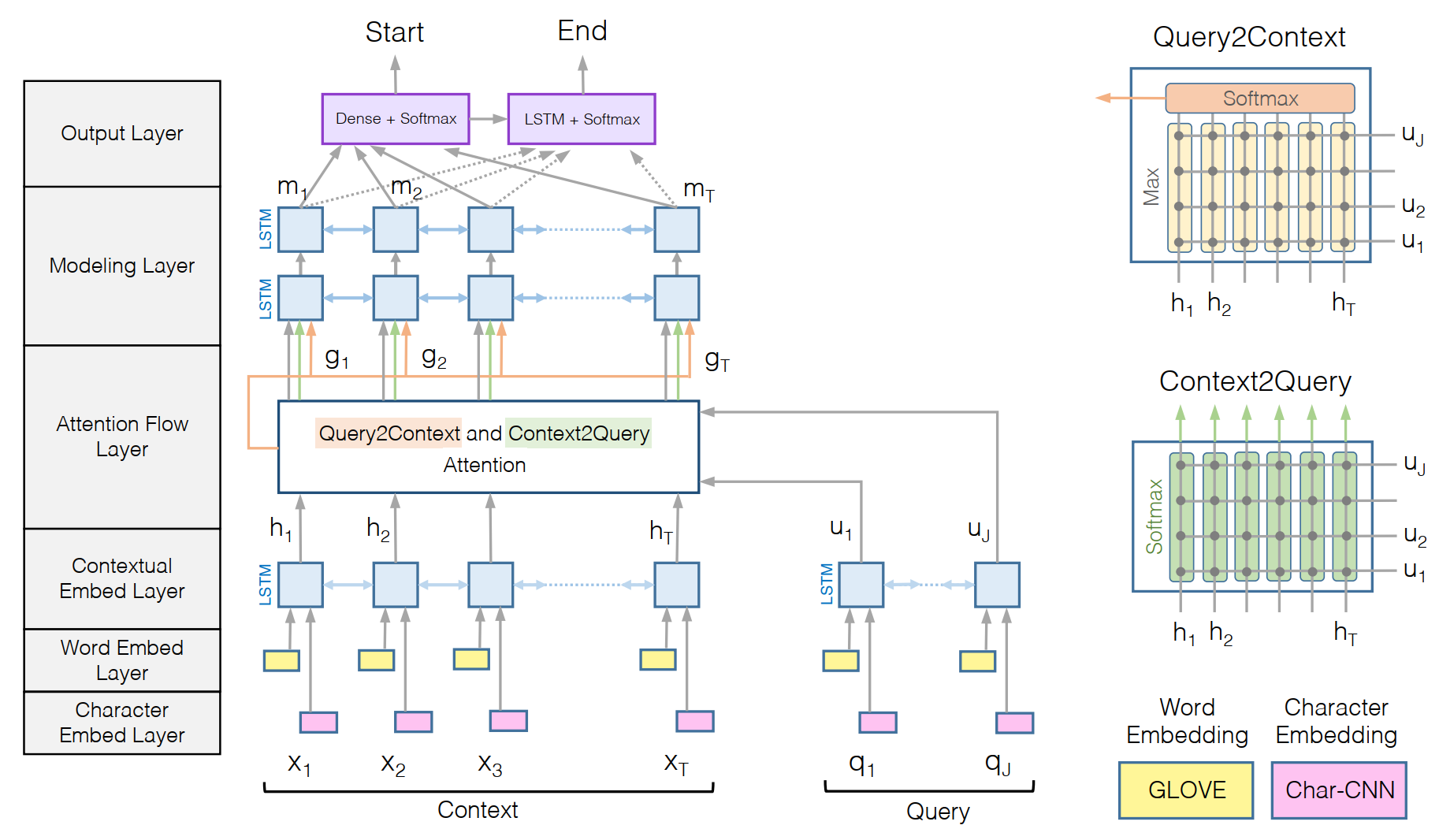
在 Match-LSTM 提出之後,question-aware 表徵的構造方式開始出現在各個論文之中。該論文中的 Attention 計算主要有以下三個特徵;
- 為典型的二維匹配模型,在詞-詞的層面上求 Attention 矩陣,計算了 query-to-context(Q2C) 和 context-to-query(C2Q)兩個方向的 attention 信息,最後構造出 qurry-aware 的 Context 表示
- 在每一個時刻,僅僅對 query 和當前時刻的 context paragraph 進行計算,並不直接依賴上一時刻的 attention,使得每次的attention計算更關注當前時刻的文本,不受過去信息的影響
模型結構如上圖所示,由圖可知,模型主要有以下幾個部分:
-
字符嵌入層:字符嵌入層負責將每個單詞映射到高維向量空間。使用卷積神經網絡(CNN)在字符級別上對每個單詞進行編碼,該卷積網絡的應用原理參考Kim在2014年發表的TextCNN。CNN的輸出在整個寬度上被max-pooled,以獲得每個單詞的固定大小向量。
-
詞嵌入層:使用預訓練的 Glove 詞向量。並將字符嵌入層得到的詞向量與預訓練詞向量拼接之後,輸入一個2層的Highway層,得到整合之後的詞表徵。
-
上下文嵌入層:使用BiLSTM對 Context 和 Query 分別進行編碼。值得注意的是,上述這三層提取了三個不同粒度的特徵對 Context 以及 Query 進行編碼,得到矩陣 (H in R^{2dtimes T}) 和 (U in R^{2d times J})。
- 注意力流層:該層是該模型最重要的部分。注意力流層負責鏈接與融合query和context的信息。和以前流行的attention機制不一樣,我們的模型不會把query和context變成一個單一的特徵向量,而是將每個時間步的attention向量都與之前層的嵌入向量,一起輸入modeling層。這可以減少因為early summarization引起的信息損失。其具體操作如下:
- 該層的輸入是 Context 的表徵 (H) 和 Query 的表徵 (U),輸出為 query-aware 的 Context 表徵,以及之前的上下文嵌入。
- 在該層中,計算了兩個方向上的 Attention,context-to-query 和 query-to-context
- 首先,構造一個共享相似度矩陣:
[S_{tj} = alpha (H_{:t}, U_{:j}) in R^{T*J}\ alpha(h, u) = w^T_{(S)}(h;u;h cdot u)] - 接下來,使用得到的共享相似度矩陣 (S) 來計算兩個方向上的注意力大小
- context-to-query attention:計算 query 上的一個詞對 context 上的每個詞的注意力大小(相關性),與 AOA 模型中的做法有點類似,對行方向進行歸一化,再對 query 進行注意力加權,包含所有query信息:
[a_t = softmax(S_{t:}) in R^J\ hat{U}_{:t} = sum _{j} a _{tj}U _{:j} in R^{2d times T}] - query-to-context attention(Q2C): 計算 context 上的一個詞對 query 上的每個詞的注意力(相關性),這些 context words 對回答問題很重要。直接取相關性矩陣每一列的最大值,再將其進行softmax歸一化,對 context 加權,並在列方向上迭代T次,最後得到的矩陣維度為(hat{H}in R^{2d*T}),包含所有的context信息,即:
[b = softmax(max_{col}(S)) in R^T\ hat{h} = sum_tb_tH_{:t} in R^{2d}]
- context-to-query attention:計算 query 上的一個詞對 context 上的每個詞的注意力大小(相關性),與 AOA 模型中的做法有點類似,對行方向進行歸一化,再對 query 進行注意力加權,包含所有query信息:
- 將 Context 表徵 (H) 與 Attention 表徵進行整合為(G),整合方式如下,得到的矩陣中每一列可視為 Context 中每一個詞的 query-aware 表示:
[G_{:t} = beta (H_{:t}, hat{U}_{:t}, hat{H}_{:t}) in R^{d_G}]
上式中,(d_G)為(beta)的輸出維度,論文中對(beta)取如下定義:
[beta(h, hat{u}, hat{h}) = [h;hat{u};h cdot hat{u};hcdothat{h}]in R^{8d times T}]
-
建模層:這一層的輸入為之前得到的(G),Context 的 query-aware 表示。這一層可以看作利用 Bi-LSTM 對含 Context 及 Query 信息的矩陣G進行進一步的信息提取,得到輸出矩陣大小為(M in R^{2dtimes T}),將其用於預測答案。
- 輸出層:對於問答任務,該層採用指針的方式來預測輸出,即僅預測答案在 Context 中的開始位置以及結束位置。
- Start:直接將 (G) 與 (M) 拼接之後,輸入一個全聯接層進行預測,即
[p^1 = softmax(w^T_{(p^1)}[G;M])] - Stop:將 (M) 通過另一個 BiLSTM 得到 (M^2) 然後與 (G) 拼接,通過全聯接層預測,即
[p^2 = softmax(w^T_{(p^2)}[G;M^2])]
- Start:直接將 (G) 與 (M) 拼接之後,輸入一個全聯接層進行預測,即
-
損失函數為開始和結束位置的交叉熵之和,與 Match-LSTM 中的 Boundary Model 類似。
Model 6: R-NET
原文鏈接:R-NET: MACHINE READING COMPREHENSION WITH SELF-MATCHING NETWORKS

R-Net主要是在 Match-LSTM 的基礎上進行的,的主要結構如上圖所示,結構已經非常清楚了,主要包括Encoding Layer,Gated Matching Layer,Self-Matching Layer,Boundary Prediction Layer四個部分,我們先把結構展開講一下,再對該論文的貢獻進行總結。
-
Question and Passage Encoder:該層將Word Embedding 以及 Character Embedding 拼接,在輸入一個雙向GRU對 Question 以及 Passage 進行編碼,即
[u^Q_t = BiRNN_Q(u^Q_{t−1}; [e^Q_t ; c^Q_t])\ u^P_t = BiRNNP (u^P_{t−1}; [e^P_t ; c^P_t])] -
Gated Attention-based Recurrent Networks:論文提出了一種門限注意力循環網絡來將 Question 的信息整合到 Passage 的表徵中,它是基於注意力的循環網絡的一種變體,具有一個附加的門來確定段落中有關問題的信息的重要性。由 Question 與 Passage 的表徵 (u^Q_t, u^P_t) 得到 Sentence-Pair 表徵 (v^P_t):
[v^P_t = RNN(v^P_{t-1}, c_t)]其中,(c_t = att(u^Q, [u^P, v^P_{t-1}])),可以將其看作一個注意力池化向量,具體計算如下:
[s_t^j = v^T tanh(W_u^Qu^Q_j + W_u^P u^P_t + W_v^P v_{t−1}^P)\ a^t_i = exp(s^t_i)/sum^m_{j=1}exp(s^t_j) \ c_t = sum^m_{i=1}a^t_iu^Q_i]則得到的每一個 Sentence-Pair 向量都動態整合了整個問題的匹配信息,借鑒 Match-LSTM 的思想,將 Passage 的表徵輸入到最後的RNN中,得到 Question-aware Passage 表徵 :
[v^P_t = RNN(v^P_{t-1}, [u^P_t, c_t])]
為了動態判斷輸入向量與 Question 的相關性,還額外加入一個門機制,對RNN的輸入進行控制,因此將其稱為 Gated Attention-based Recurrent Networks:
[[u_t^P, c_t]^* = g_t cdot [u_t^P, c_t]\ g_t = sigmoid(W_g[u_t^P, c_t])] -
Self-Matching Attention:上一層輸出的 Question-aware 表徵確定了段落中與問題相關的重要部分,但這種表徵的一個重要問題是其很難包含上下文信息,然而一個答案的確定很多時候都是很依賴於上下文的。為了解決這個問題,論文提出了 Self-Matching Attention,其動態地收集整個段落的信息給段落當前的詞語,把與當前段落詞語相關的信息和其匹配的問題信息編碼成段落表示:
[h^P_t = BiRNN(h_{t-1}^P, [v_t^P, c_t])]這裡的(c_t = att(v^P ; v_t^P ))為對整個 Passage 的自注意力池化:
[s^t_j = v^Ttanh(W_v^P v_j^P + W_v^{tilde{P}}v_t^P )\ a^t_i = exp(s^t_i)/sum^n_{j=1}exp(s^t_j)\ c_t = sum^n_{i=1}a^t_iv_i^P]同樣,對([v_t^P, c_t])增加與上一層輸入同樣的門控機制,來自適應控制 RNN 的輸入。
- Output Layer:該模型同樣利用 Point Network 的結構來直接預測答案的起始位置和輸出位置。
-
根據給定段落表示,把 Attention 權重分數作為一個 Pointer 來選取答案在段落中的起始位置,也就是基於初始語境信息,計算段落中每個詞語的 Attention 權重,權重最高的作為起始位置:
[s^t_j = v^Ttanh(W_h^P h_j^P + W_h^{a}h_{t-1}^a)\ a^t_i = exp(s^t_i)/sum^n_{j=1}exp(s^t_j)\ p^t = argmax(a_1^t, …, a_n^t)]上式中,(h^a_{t-1}) 為 Point Network 最後的隱藏狀態
-
在得到起始位置之後,用注意力分數對 Self-Matching 的 Passage 表徵進行加權,然後利用之前的Question Attention-Pooling表徵,作為RNN的初識狀態,對加權後的Passage 表徵進行再處理,得到新的語境,新的語境信息計算方式如下:
[c_t = sum^n_{i=1}a^t_ih^P_i\ h^a_t = RNN(h^a_{t-1}; c_t)] -
當預測開始位置的時候,將對 Question 的表徵使用 Attention-Pooling的向量作為 Pointer Network 的初始語境。
[s_j = v^Ttanh(W_u^Q u_j^Q + W_V^{Q}V_r^Q )\ a_i = exp(s_i)/sum^m_{j=1}exp(s_j)\ r_Q = sum^m_{i=1}a_iu_i^Q]上式中(V_r^Q)為參數向量
-
-
同樣選擇交叉熵作為模型的損失函數
了解了模型的主要結構,我們來看看該模型的創新點在什麼地方:
- 首先,提出了一種gated attention-based recurrent network,也就是在經典的attention-based recurrent networks上額外增加了門機制,這樣做的主要原因是針對閱讀理解的問題,段落中的每個單詞的重要性是不同的。通過門機制,模型根據段落與問題的相關程度,賦予了段落中不同詞的重要程度,掩蓋了段落中不相關的部分。
- 由於RNN本身只能存儲有限段落信息,一個候選答案通常不知道段落的其餘部分的信息,提出了 Self-Matching 機制這種機制,用整個段落的信息動態完善段落表示,使後續網絡能夠更好地預測答案。
Model 7: QANet
原文鏈接:QANET
深度可分離卷積:Xception: Deep Learning with Depthwise Separable Convolutions
DCN:Dynamic Connection Network for Question Answering
最後一個模型QANet,是預訓練模型發佈之前排名最優的一個閱讀理解模型了,其與之前模型明顯的不同就是,拋棄了RNN,只使用 CNN 和 Self-Attention 完成編碼工作,使得速度與準確率大大贈強。模型的主要結構如下圖(左)所示

該模型與大多與之模型的結構都是相同的,,由五個部分組成:Embedding layer, Embedding encoder layer, Context-query attention layer, Model encoder layer 和 Output layer。其中,整個模型中使用相同的編碼器塊(圖右),僅改變每個塊的卷積層數,該編碼器塊主要由如下幾個特點:
- 編碼器塊中的每一層都使用了 Layernorm 和殘差鏈接
- 每個編碼器塊的輸入位置都加入了 Transformer 中定義的 Position Embedding
- Self-Attention 採用了 Transformer 中的多頭注意力機制
- 編碼器塊中的卷積網絡並不是簡單的卷積網絡,而是深度可分離卷積層((depthwise separable convolutions),該結構由更好的泛化能力,且有更少的參數和更低的計算量
- 對於普通的卷積核卷積,輸入矩陣維度為 (N_{in} times N_{in} times C_{in}),假設卷積核大小為(N_{k}times N_{k} times C_{in}),輸出通道數為 (C_{out}) ,則需要的參數為 (N_k times N_k times C_{in} times C_{out})
- 對於深度可分離卷積,則使用 (C_{in}) 個 (N_k times N_k times 1) 的卷積核分別卷積每個通道,然後使用(C_{out}) 個 (1 times 1 times C_{in}) 的一維卷積整合多通道信息,整體參數只有 (C_{in} times (N_k times N_k + C_{out}))個參數
下面來看看整體結構:
- Input Embedding Layer:與之前的模型處理類似,也是整合詞向量以及字符向量的方式來得到詞表徵。
- 對於詞嵌入,利用預訓練的GloVe詞向量來初始化,並在訓練的過程中固定,而對於OOV詞,將其初隨機初始化之後加入訓練。
- 對於字符向量,將每個字符都初始化為200維的可訓練向量,每個詞都固定到16的長度,則每個詞的字符向量表示為字符向量矩陣的最大池化表示,從而將其映射到 200 的固定長度。最後的詞表徵為詞向量與字符向量表徵拼接([x_w;x_c]) 通過一個 Highway 的輸出向量。
-
Embedding Encoder Layer:編碼層就是編碼器塊堆疊形成的,此處的編碼器塊層數為1,將 Input Embedding Layer 輸出的長度為 500 的向量 映射為一個長度為 128 的向量。
-
Context-Query Attention Layer:我們用 C 和 Q 分別表示編碼後的 Context 和 Question,根據二維匹配模型,首先計算出 C 和 Q 的相似矩陣 (S in R^{n times m}),然後對其進行 Softmax 歸一化,得到 Context 中每個詞對 Question 所有詞的注意力分數,再將歸一化後的矩陣 (bar{S}) 對問題表徵 Q 進行加權,從而得到問題的context-to-query attention表徵:
[A=S cdot Q^T in R^{ntimes d}]相似度矩陣的計算方法也是比較傳統的方法:
[f(q, c) = W_0[q; c; q cdot c]]另外,作者還借鑒了當時高性能的模型中求解雙向注意力的方法(如BiDAF),計算了上下文的 query-to-context attention 表徵,計算方式借鑒的是 DCN 中的計算方法,首先對相似度矩陣 (S) 進行列歸一化,得到 Question 的每個詞對 Context 所有詞的注意力分數 (bar{bar{S}}) ,則 query-to-context attention 表徵為
[B=bar{S} cdot bar{bar{S}}^T cdot C^T in R^{mtimes d}] -
Model Encoder Layer:這部分繼續沿用了與 BiADF 中類似的結構,輸入為 Contest 的 query-aware 表徵 ([c, a, c cdot a, c cdot b]) ,其中 (a, b) 為矩陣 (A, B) 中的一行。而編碼器塊處了卷積層數為2,總的塊數是7以外,其餘與 Embedding Encoder Layer 中的結構相同,總共堆疊3組編碼器塊(共有 3*7 個Encoder Block)。
-
Output layer:這一層同樣沿用與 BiADF 類似的結構,僅僅答案開始以及結束的位置進行預測。
[p^1=softmax(W_1[M_0;M_1])\ p^2=softmax(W_2[M_0;M_2])]
其中,(W_1, W_2) 均為可訓練矩陣,而(M_0, M_1, M_2) 分別為3組編碼器塊的輸出 -
損失函數同樣為交叉熵。當然,通過改變輸出層的網絡結構,該模型能夠適應其他類型的閱讀理解任務,如單項多項選擇等。
總結
如果你看到了這裡,就會發現 QANet 基本融合之前所有模型的優點,從而得到了當時的最優效果(即使模型性能之後還是被預訓練模型吊打),在這篇文章的基礎上,最後我們總結一下機器閱讀理解模型的一些已被證實的十分有效的技巧:
- 利用 Highway 結構對詞向量以及字符向量的整合
- 編碼器 CNN 以及 Transformer 的並行能力以及信息提取能力已經可以完全代替LSTM,且CNN可用深度可分離卷積網絡,大大較少參數
- 既然使用了 CNN 和 Transformer,位置編碼則是必不可少的
- 通過對相關矩陣進行 Softmax 歸一化的方法得到雙向注意力,再整合為包含問題信息的上下文表徵,是一個十分高效的模型編碼方式
- 對於答案為上下文中某一個文段的問題,目前最優的方法是 Pointer Network 中指針位置預測的方法
參考鏈接
https://zhuanlan.zhihu.com/p/22671467
https://zhuanlan.zhihu.com/p/52977813
https://zhuanlan.zhihu.com/p/53132772
https://zhuanlan.zhihu.com/p/53324276
https://zhuanlan.zhihu.com/p/21349199
https://zhuanlan.zhihu.com/p/48959800
https://blog.csdn.net/zhang2010hao/article/details/88387493
https://zhuanlan.zhihu.com/p/53626872
https://zhuanlan.zhihu.com/p/35229701
https://zhuanlan.zhihu.com/p/61502862
https://zhuanlan.zhihu.com/p/58961139