雙向最大匹配算法——基於詞典規則的中文分詞(Java實現)
目錄
前言
這篇將使用Java實現基於規則的中文分詞算法,一個中文詞典將實現準確率高達85%的分詞結果。使用經典算法:正向最大匹配和反向最大匹配算法,然後雙劍合璧,雙向最大匹配。
一、中文分詞理論描述
根據相關資料,中文分詞概念的理論描述,我總結如下:
中文分詞是將一個漢字序列切分成一個一個單獨的詞,將連續的字序列按照一定的規範重新組合成詞序列的過程,把字與字連在一起的漢語句子分成若干個相互獨立、完整、正確的單詞,詞是最小的、能獨立活動的、有意義的語言成分。
中文分詞應用廣泛,是文本挖掘的基礎,在中文文本處理中意義重大,對於輸入的一段中文,成功的進行中文分詞,可以達到電腦自動識別語句含義的效果。目前,常用流行的以及分次效果好的工具庫包括:jieba、HanLP、LTP、FudanNLP等。
我們知道,調用工具方便容易,但是如果自己實現寫一個算法實現,那不是更加有成就感^_^。
接下來將一步步介紹最容易理解,最簡單,效果還很不錯的中文分詞算法,據說準確率能達到85%!!
二、算法描述
1、正向最大匹配算法
所謂正向,就是從文本串左邊正向掃描,取出子串與詞典進行匹配。
算法我分為兩步來理解:
假設初始化取最大匹配長度為MaxLen,當前位置pos=0,處理結果result=」」,每次取詞str,取詞長度len,待處理串segstr。
- len=MaxLen,取字符串0到len的子串,查找詞典,若匹配到則賦值str,加到result,在保證pos+len<=segstr.length()情況下,pos=pos+len,向後匹配,直到字符串掃描完成,結束算法。
- 若詞典未找到,若len>1,減小匹配長度同時len=MaxLen-1,執行步驟(1),否則,取出剩餘子串,執行步驟(1)。
算法代碼如下:
public void MM(String str, int len, int frompos) { if (frompos + 1 > str.length()) return; String curstr = ""; //此處可以設置斷點 int llen = str.length() - frompos; if (llen <= len)//句末邊界處理 curstr = str.substring(frompos, frompos + llen);//substring獲取的子串是下標frompos~frompos+llen-1 else curstr = str.substring(frompos, frompos + len); if (dict.containsKey(curstr)) { result = result + curstr + "/ "; Len = MaxLen; indexpos = frompos + len; MM(str, Len, indexpos); } else { if (Len > 1) { Len = Len - 1; } else { result = result + str + "/ "; frompos = frompos + 1; Len = MaxLen; } MM(str, Len, frompos); } }
從算法代碼看出,很容易理解,細節部分在於邊界處理。
測試一下,我輸入文本,“我愛自然語言處理,讚賞評論收藏我的文章是我的動力!趕緊關注!”
分詞結果:

2、反向最大匹配算法
反向,則與正向相反,從文本串末向左進行掃描。
假設初始化取最大匹配長度為MaxLen,當前位置pos為字符串尾部,處理結果result=」」,每次取詞str,取詞長度len,待處理串segstr。
- len=MaxLen,取字符串pos-len到pos的子串,查找詞典,若匹配到則賦值str,加到result,同時pos=pos-len,保證pos-len>=0,向前移動匹配,直到字符串掃描完成,結束算法。
- 若詞典未找到,若len>1,減小匹配長度同時len=MaxLen-1,執行步驟(1),否則,取出剩餘子串,執行步驟(1)。
算法邏輯類似,取相反方向處理。
public void RMM(String str, int len, int frompos) { if (frompos < 0) return; String curstr = ""; //此處可以設置斷點 if (frompos - len + 1 >= 0)//句末邊界處理 curstr = str.substring(frompos - len + 1, frompos + 1);//substring獲取的子串是下標frompos~frompos+llen-1 else curstr = str.substring(0, frompos + 1);//到達句首 if (dict.containsKey(curstr)) { RmmResult = curstr + "/ " + RmmResult; Len = MaxLen; indexpos = frompos - len; RMM(str, Len, indexpos); } else { if (Len > 1) { Len = Len - 1; } else { RmmResult = RmmResult + str + "/ "; frompos = frompos - 1; Len = MaxLen; } RMM(str, Len, frompos); } }
同樣,細節部分在於邊界處理,其他基本相同。
3、雙劍合璧
這裡所說的是正向與反向結合,實現雙向最大匹配。
雙向最大匹配算法,基於正向、反向最大匹配,對分詞結果進一步處理,比較兩個結果,做的工作就是遵循某些原則和經驗,篩選出兩者中更確切地分詞結果。原則如下:
- 多數情況下,反向最大匹配效果更好,若分詞結果相同,則返回RMM結果;
- 遵循切分最少詞原則,更大匹配詞為更好地分詞結果,比較之後返回最少詞的切分結果;
- 根據切分後詞長度的大小,選擇詞長度大者為最終結果。
具體也需要看開始給定的最大匹配長度為多少。以下代碼只實現了原則(1)、(2)。
public String BMM() throws IOException { String Mr = MM_Seg(); String RMr = RMM_Seg(); if (Mr.equals(RMr)) { return "雙向匹配相同,結果為:" + Mr; } else { List<String> MStr; List<String> RStr; MStr = Arrays.asList(Mr.trim().split("/")); RStr = Arrays.asList(RMr.trim().split("/")); if (MStr.size() >= RStr.size()) {//多數情況下,反向匹配正確率更高 return "雙向匹配不同,最佳結果為:" + RMr; } else return "雙向匹配不同,最佳結果為:" + Mr; } }
另外,這與使用的詞典大小有關,是否包含常用詞。
三、案例描述
如果上面還不能完全理解,下面的例子可以更好的理解算法執行過程。
正向最大匹配算法:
取MaxLen=3,SegStr=」對外經濟技術合作與交流不斷擴大」,maxNum=3,len=3,result=」」,pos=0,curstr=」」.
第一次,curstr=」對外經」,查找詞典,未找到,將len-1,得到curstr=」對外」,此時匹配到詞典,將結果加入result=」對外/ 」.pos=pos+len.
第二次,curstr=」經濟技」,查找詞典,未找到,將len-1,得到curstr=」經濟」,此時匹配到詞典,將結果加入result=」對外/ 經濟/ 」.pos=pos+len.
以此類推…
最後一次,邊界,pos=13,因為只剩下」擴大」兩個字,所以取出全部,查找詞典並匹配到,將結果加入result=」對外/ 經濟/ 技術/ 合作/ 與/ 交流/ 不斷/ 擴大/ 」.此時pos+1>SegStr.length(),結束算法。
反向最大匹配算法:
取MaxLen=3,SegStr=」對外經濟技術合作與交流不斷擴大」,maxNum=3,len=3,result=」」,pos=14,curstr=」」.
第一次,curstr=」斷擴大」,查找詞典,未找到,將len-1,得到curstr=」擴大」,此時匹配到詞典,將結果加入result=」擴大/ 」.pos=pos-len.
第二次,MaxLen=3,curstr=」流不斷」,查找詞典,未找到,將len-1,得到curstr=」不斷」,此時匹配到詞典,將結果加入result=」不斷/ 擴大/ 」.pos=pos-len.
以此類推…
最後一次,邊界,pos=1,因為只剩下」對外」兩個字,所以取出全部,查找詞典並匹配到,將結果加入result=」對外/ 經濟/ 技術/ 合作/ 與/ 交流/ 不斷/ 擴大/ 」.此時pos-1<0,結束算法。
四、JAVA實現完整代碼
除了分詞算法實現,還需要讀入詞典,對詞典進行預處理,具體如下:


package ex1; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import java.util.*; public class seg { String result; String RmmResult; String segstring; int MaxLen; int Len; int indexpos; Map<String, String> dict; public seg(String inputstr, int maxlen) {//構造函數 segstring = inputstr; MaxLen = maxlen; Len = MaxLen; indexpos = 0; result = ""; RmmResult = ""; dict = new HashMap<String, String>(); } public void ReadDic() throws FileNotFoundException, IOException { BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("chineseDic.txt"), "GBK")); String line = null; while ((line = br.readLine()) != null) { String[] words = line.trim().split(",");//詞典包含詞性標註,需要將詞與標註分開,放入列表 String word = words[0]; String cx = words[1]; dict.put(word, cx); } br.close(); } public String MM_Seg() throws IOException {//正向最大匹配算法 try { ReadDic();//讀入字典 MM(segstring, MaxLen, 0);//正向最大分詞 return result; } catch (IOException e) { return "Read Error!"; } } public void MM(String str, int len, int frompos) { if (frompos + 1 > str.length()) return; String curstr = ""; //此處可以設置斷點 int llen = str.length() - frompos; if (llen <= len)//句末邊界處理 curstr = str.substring(frompos, frompos + llen);//substring獲取的子串是下標frompos~frompos+llen-1 else curstr = str.substring(frompos, frompos + len); if (dict.containsKey(curstr)) { result = result + curstr + "/ "; Len = MaxLen; indexpos = frompos + len; MM(str, Len, indexpos); } else { if (Len > 1) { Len = Len - 1; } else { result = result + str + "/ "; frompos = frompos + 1; Len = MaxLen; } MM(str, Len, frompos); } } public String RMM_Seg() throws IOException {//正向最大匹配算法 try { ReadDic();//讀入字典 RMM(segstring, MaxLen, segstring.length() - 1);//正向最大分詞 return RmmResult; } catch (IOException e) { return "Read Error!"; } } public void RMM(String str, int len, int frompos) { if (frompos < 0) return; String curstr = ""; //此處可以設置斷點 if (frompos - len + 1 >= 0)//句末邊界處理 curstr = str.substring(frompos - len + 1, frompos + 1);//substring獲取的子串是下標frompos~frompos+llen-1 else curstr = str.substring(0, frompos + 1);//到達句首 if (dict.containsKey(curstr)) { RmmResult = curstr + "/ " + RmmResult; Len = MaxLen; indexpos = frompos - len; RMM(str, Len, indexpos); } else { if (Len > 1) { Len = Len - 1; } else { RmmResult = RmmResult + str + "/ "; frompos = frompos - 1; Len = MaxLen; } RMM(str, Len, frompos); } } public String BMM() throws IOException { String Mr = MM_Seg(); String RMr = RMM_Seg(); if (Mr.equals(RMr)) { return "雙向匹配相同,結果為:" + Mr; } else { List<String> MStr; List<String> RStr; MStr = Arrays.asList(Mr.trim().split("/")); RStr = Arrays.asList(RMr.trim().split("/")); if (MStr.size() >= RStr.size()) {//多數情況下,反向匹配正確率更高 return "雙向匹配不同,最佳結果為:" + RMr; } else return "雙向匹配不同,最佳結果為:" + Mr; } } public String getResult() { return result; } public static void main(String[] args) throws IOException, Exception { seg s = new seg("我愛自然語言處理,讚賞評論收藏我的文章是我的動力!趕緊關注!", 3); // String result = s.MM_Seg(); String result = s.RMM_Seg(); System.out.println(result); } }
View Code
五、組裝UI
我是用的開發軟件為是IDEA,一個方便之處可以拖動組件組裝UI界面。也可以自行寫JavaFX實現簡單布局。
這是簡單頁面的設計:
UI界面可以有更好的用戶體驗,通過UI界面的元素調用方法,減少每次測試運行算法腳本的繁瑣。
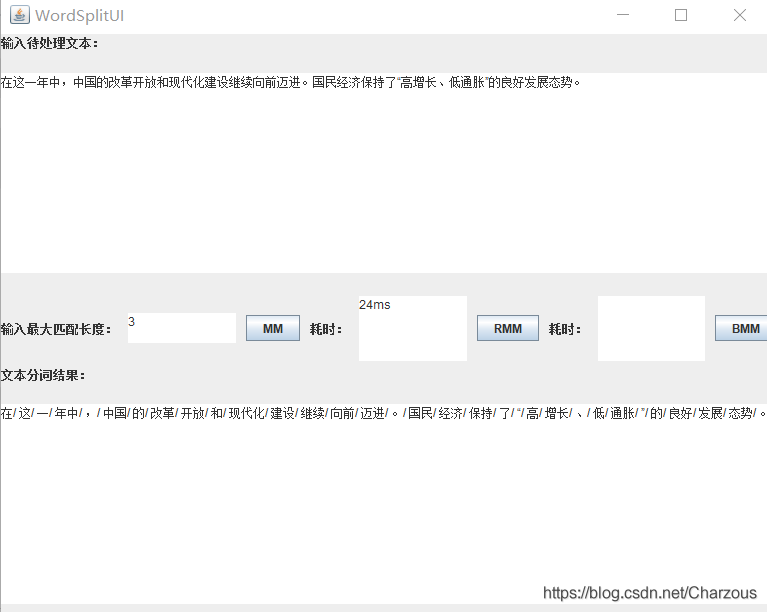
實驗演示:
每次可以觀察不同最大匹配長度分詞後的結果。
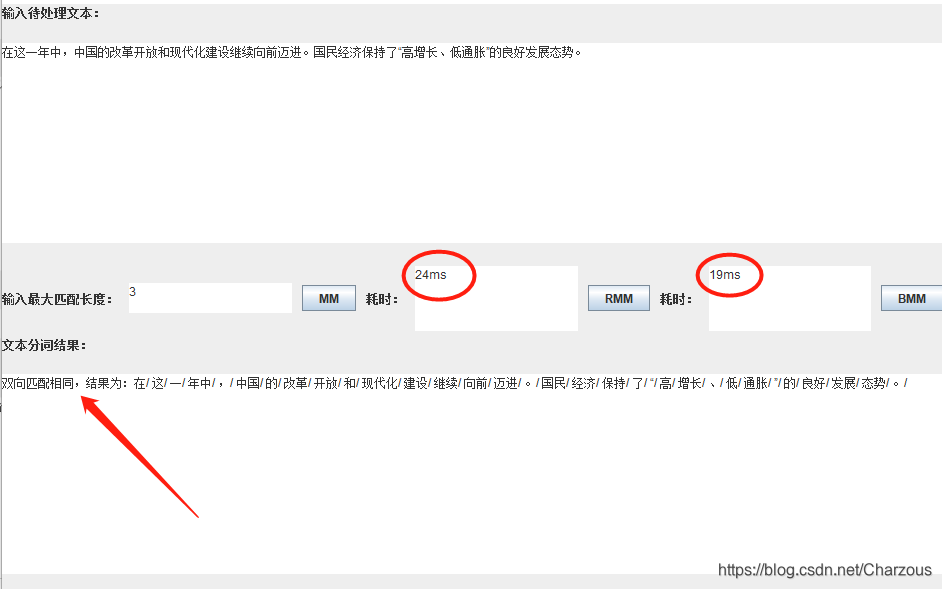
“年中”詞語解析:
在詞典中,是這樣的,可以發現滿足最大匹配。


雙向最大匹配算法,結果提示:
六、總結
這篇介紹了使用Java實現基於規則的中文分詞算法,使用經典算法:正向最大匹配和反向最大匹配算法,然後雙劍合璧,雙向最大匹配。最後設計簡單UI界面,實現稍微高效的中文分詞處理,結果返回。
- 雙向最大匹配算法原則,希望句子最長詞保留完整、最短詞數量最少、單字詞問題,目前只解決了句子切分最少詞問題。
- 正向反向匹配算法可以進一步優化結構,提高執行效率,目前平均耗時20ms。
- UI界面增加輸入輸出提示語,方便用戶使用,在正確的區域輸入內容。
- 將最大匹配長度設置為可輸入,實現每次可以觀察不同MaxLen得到的切分結果。
-
雙向最大匹配按鈕點擊之後,返回結果同時返回MM和RMM結果是否一樣的提示,方便查看。
我的博客園://www.cnblogs.com/chenzhenhong/p/13748042.html
我的CSDN博客: //blog.csdn.net/Charzous/article/details/108817914


