深入理解Nginx及使用Nginx實現負載均衡
- 2019 年 10 月 3 日
- 筆記
前言:
最近在部署項目時要求實現負載均衡,有趣的是發現網上一搜全部都是以下類似的配置文件
upstream localhost{ server 127.0.0.1:8080 weight=1; server 127.0.0.1:8081 weight=1; } server { listen 80; server_name localhost; location / { proxy_pass http://localhost; index index.html index.htm index.jsp; } }
所以打算來看看Nginx內部原理,這篇博客主要介紹Nginx如何實現反向代理以及在Nginx中負載均衡的參數使用
一、正向代理與反向代理
正向代理是代理客戶端,也就是客戶端能真正接觸到的,比如訪問外網時需要使用VPN軟件,在這個軟件中用戶可以選擇連接哪裡的服務器。
反向代理則是代理服務端,用戶感知不到,只是客戶端把請求發到服務端的端口時,Nginx監聽到了便把該端口的請求轉發到不同的服務器上。就以上面配置文件來講解,當在網址中輸入http://localhost:80/時(不加80一樣時默認進入80端口,這裡為了表示清楚),而後Nginx監聽到80端口的請求之後,就會查找對應的location來執行。由上面的配置文件我們可以看出是將請求轉發到了不同的端口。這是在服務器中執行的,用戶不可見。
而服務端中我們最常使用的反向代理的工具就是Nginx。
二、Nginx內部基本架構
nginx在啟動後以daemon的方式在後台運行,會有一個master進程和多個worker進程。
master進程:主要用來管理worker進程,包含:接收來自外界的信號,向各worker進程發送信號,監控worker進程的運行狀態,當worker進程退出後(異常情況下),會自動重新啟動新的worker進程。
worker進程:處理基本的網絡事件了。多個worker進程之間是對等的,他們同等競爭來自客戶端的請求,各進程互相之間是獨立的。一個請求,只可能在一個worker進程中處理,一個worker進程,不可能處理其它進程的請求。worker進程的個數是可以設置的,一般我們會設置與機器cpu核數一致,或者直接設置參數worker_processes auto;

所以Nginx基本的架構就如下:
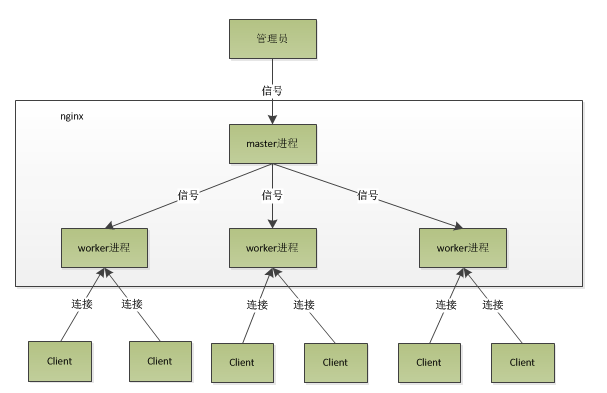
當我們輸入./nginx -s reload,就是來重啟nginx,./nginx -s stop,就是來停止nginx的運行,這裏面是如何做到的?執行命令時,我們是啟動一個新的nginx進程,而新的nginx進程在解析到reload參數後,就知道我們的目的是控制nginx來重新加載配置文件了,它會向master進程發送信號。master進程在接到信號後,會先重新加載配置文件,然後再啟動新的worker進程,並向所有老的worker進程發送信號,告訴他們可以光榮退休了。新的worker在啟動後,就開始接收新的請求,而老的worker在收到來自master的信號後,就不再接收新的請求,並且在當前進程中的所有未處理完的請求處理完成後,再退出。所以使用上面命令重啟Nginx的時候服務是不中斷的。
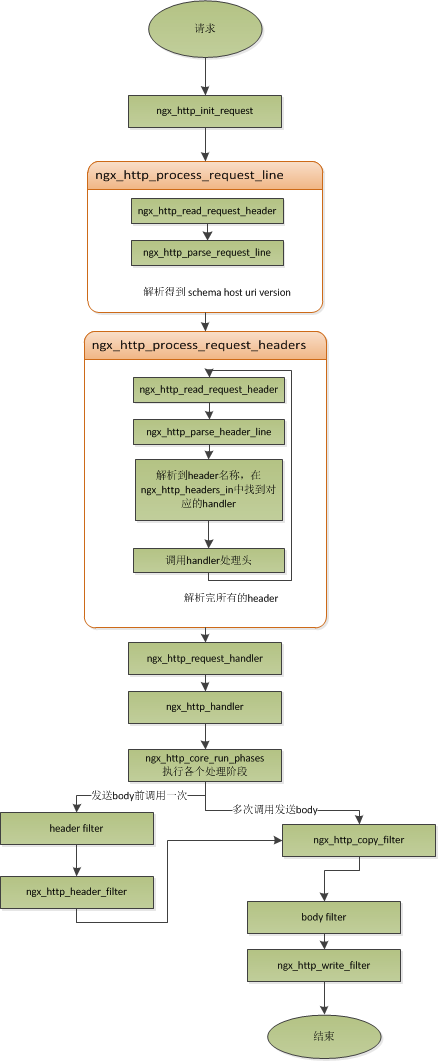
三、Nginx如何處理客戶端請求
首先來解釋一下上面的架構圖:每個worker進程都是從master進程分支過來的,在master進程裏面,先建立好需要監聽的socket之後,然後再分支出多個worker進程。所有worker進程的listenfd(socket中listenfd是指客戶端連接本機時的fd,是用來和客戶端通信用的)會在新連接到來時變得可讀,為保證只有一個進程處理該連接,所有worker進程在註冊listenfd讀事件前搶accept_mutex,搶到互斥鎖的那個進程註冊listenfd讀事件,在讀事件里調用accept接受該連接。
在Nginx中worker進程之間是平等的,每個進程,處理請求的機會也是一樣的。當Nginx監聽80端口時,一個客戶端的連接請求過來,每個進程都有可能處理這個連接,上面說到是每個worker進程都會去搶注listenfd讀事件。當一個worker進程在accept這個連接之後,就開始讀取請求,解析請求,處理請求,產生數據後,再返回給客戶端,最後才斷開連接,這樣一個完整的請求就是這樣的了。這裡需要注意的是一個請求,完全由worker進程來處理,而且只在一個worker進程中處理。
下面兩幅流程圖能很好的幫我們理解

四、Nginx如何處理事件並且實現高並發
Nginx內部採用了異步非阻塞的方式來處理請求,也就是說,Nginx是可以同時處理成千上萬個請求的。
異步非阻塞:當一個網絡請求過來時,我們並不依賴於這個請求才能做後續操作,那麼這個請求就是異步操作,也就是調用者在沒有得到結果之前同樣可以執行後續的操作。非阻塞就是當前進程/線程沒有得到請求調用的結果時也不會妨礙到進程/線程後續的操作。可以看出異步和非阻塞的對象是不同的。
回到Nginx中,首先,請求過來,要建立連接,然後再接收數據,接收數據後,再發送數據。具體到系統底層,就是讀寫事件,而當讀寫事件沒有準備好時,必然不可操作,如果不用非阻塞的方式來調用,那就得阻塞調用了,事件沒有準備好,那就只能等了,等事件準備好了,再繼續。而阻塞調用會進入內核等待,cpu就會讓出去給別人用了,對單線程的worker來說,顯然不合適,當網絡事件越多時,大家都在等待,cpu空閑下來沒人用,cpu利用率自然上不去了,更別談高並發了。而非阻塞就是,事件沒有準備好,馬上返回EAGAIN,告訴調用者,事件還沒準備好,過會再來。過一會,再來檢查一下事件,直到事件準備好了為止,在這期間,Nginx可以處理其他調用者的讀寫事件。但是雖然不阻塞了,但Nginx得不時地過來檢查一下事件的狀態,Nginx可以處理更多請求了,但帶來的開銷也是不小的。所以,才會有了異步非阻塞的事件處理機制,具體到系統調用就是像select/poll/epoll/kqueue這樣的系統調用。它們提供了一種機制,讓你可以同時監控多個事件,以epoll為例子,當事件沒準備好時,放到epoll裏面,事件準備好了,Nginx就去讀寫,當讀寫返回EAGAIN時,就將它再次加入到epoll裏面。這樣,只要有事件準備好了,Nginx就可以去處理它,只有當所有事件都沒準備好時,才在epoll裏面等着。這樣便實現了所謂的並發處理請求,但是線程只有一個,所以同時能處理的請求當然只有一個了,只是在請求間進行不斷地切換而已,切換也是因為異步事件未準備好,而主動讓出的。這裡的切換是沒有任何代價,你可以理解為循環處理多個準備好的事件,事實上就是這樣的。與多線程相比,這種事件處理方式是有很大的優勢的,不需要創建線程,每個請求佔用的內存也很少,沒有上下文切換,事件處理非常的輕量級。並發數再多也不會導致無謂的資源浪費(上下文切換)。更多的並發數,只是會佔用更多的內存而已。現在的網絡服務器基本都採用這種方式,這也是nginx性能高效的主要原因。
五、Nginx負載均衡的算法及參數
round robin(默認):輪詢方式,依次將請求分配到後台各個服務器中,適用於後台機器性能一致的情況,若服務器掛掉,可以自動從服務列表中剔除
weight:根據權重來分發請求到不同服務器中,可以理解為比例分發,性能較高服務器分多點請求,較低的則分少點請求
IP_hash:根據請求者ip的hash值將請求發送到後台服務器中,保證來自同一ip的請求被轉發到固定的服務器上,解決session問題
upstream localhost { ip_hash; server 127.0.0.1:8080; server 127.0.0.1:8080; }
上面是最基本的三種算法,我們還可以通過改變參數來自行配置負載均衡
upstream localhost{ ip_hash; server 127.0.0.1:9090 down; server 127.0.0.1:8080 weight=2; server 127.0.0.1:6060; server 127.0.0.1:7070 backup; }
參數列表如下:
| down | 表示單前的server暫時不參與負載 |
| weight | 默認為1.weight越大,負載的權重就越大 |
| max_fails | 允許請求失敗的次數默認為1.當超過最大次數時,返回proxy_next_upstream 模塊定義的錯誤 |
| fail_timeout | max_fails次失敗後,暫停的時間 |
| backup | 其它所有的非backup機器down或者忙的時候,請求backup機器。所以這台機器壓力會最輕 |
參考:
