機器學習筆記P1(李宏毅2019)
- 2019 年 11 月 5 日
- 筆記
該片博客將介紹機器學習課程by李宏毅的前兩個章節:概述和回歸。
視屏鏈接1-Introduction
視屏鏈接2-Regression
該課程將要介紹的內容如下所示:
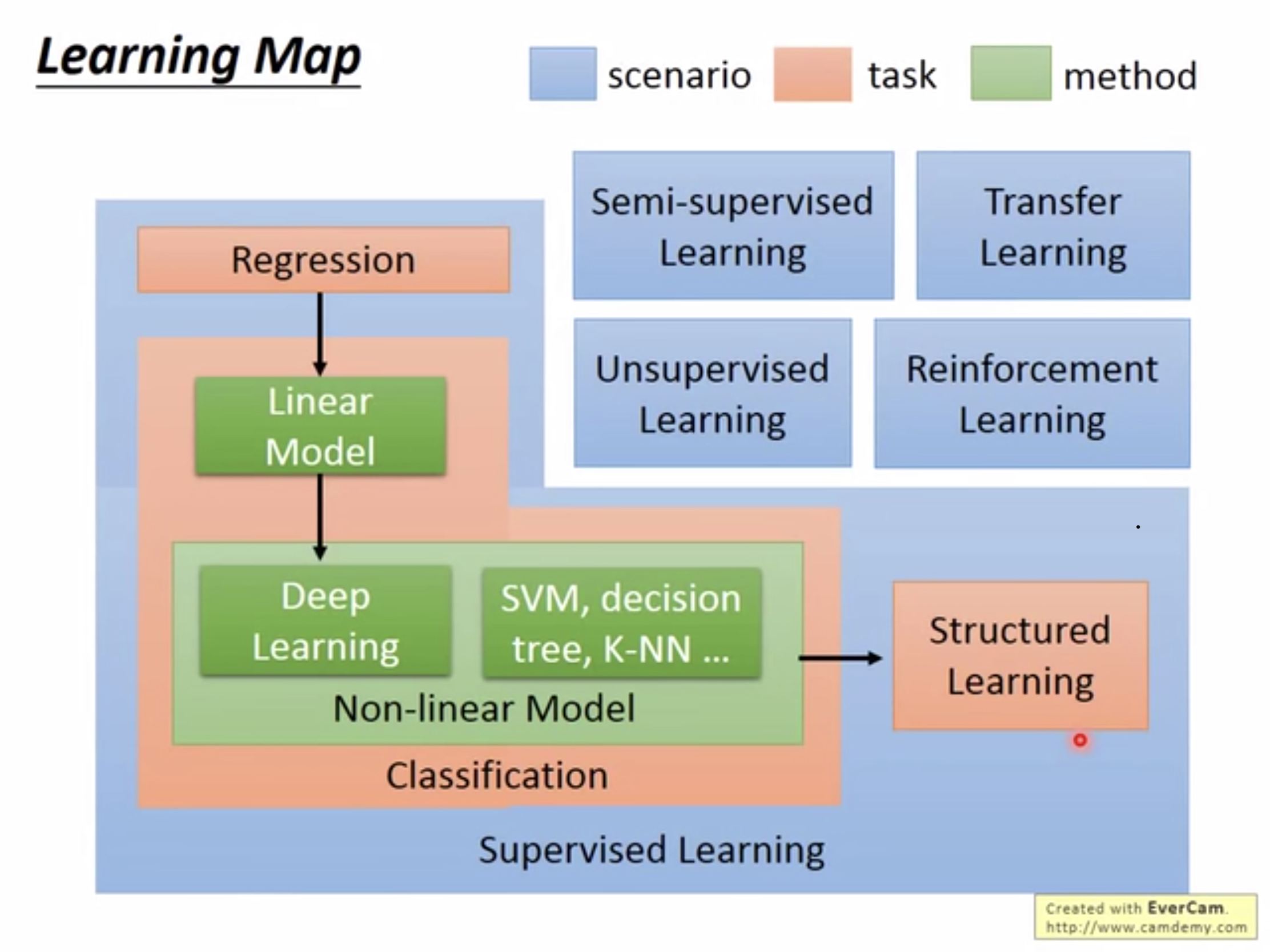
從最左上角開始看:
Regression(回歸):輸出的目標是一個數值。如預測明天的PM2.5數值。
接下來是Classification(分類):該任務的目標是將數據歸為某一類,如進行貓狗分類。
在分類任務中,將涉及線性和非線性的模型。其中,非線性的模型包含了Deep-Learning,SVM,決策樹,K-NN等等。
結構化學習相對於回歸或者分類來說,輸出的是一個向量,結構化學習的輸出可以是圖像、語句、樹結構等等。目前最火的的GAN就是一個典型的結構化學習樣例。
回歸、分類和結構化學習可以歸為有監督任務,除此之外還有半監督任務以及無監督任務。
有監督模型對於模型的輸入全部都是有標籤的數據,半監督模型對於模型的輸入,部分是有標籤的數據,部分是沒有標籤的數據。無監督模型對於模型的輸入全部都是沒有標籤的數據。
除此之外,因為手動對數據進行標註的代價很大,因此可以考慮將其他領域以及訓練好的模型遷移到自己的任務中來,這叫做遷移學習。
目下,還有另外一個當下很火的技術叫做Reinforcement Learning(增強學習)。增強學習和監督學習的主要區別是:在有監督學習中,我們會對數據給出標籤,然後拿模型得到的結果與結果進行對比,將結果進行一些處理之後用來優化模型。而在增強學習中,我們不會給模型正確的答案,取而代之的是我們會給模型一個分數,以此來表示模型結果的好壞程度。在增強學習中,模型並不知道為什麼不好,只知道最終的結果評分。
(Regression)回歸
對於一個回歸問題,我們假設已經有的數據為(x),其對應的真實標籤為(hat y)。我們需要尋找一組函數(f(.))以使得(f(x))儘可能相等或者接近真實值(hat y)。我們將函數值定義為(y),則有(y=f(x)=b+wx)。其中,(b,w,x)均為向量,代表着數據的某個特徵。同時,我們將(w)稱為權重,(b)稱為偏差。我們的目標就是找到這樣的一組(f(.))使得,任意給出一個數據(x),都有(y=hat y)。我們將這樣的一組函數(f(.))稱之為模型(Model)。因為(b)和(w)可以取得任意值,我們很難人工去設定這樣的一組參數,所以我們可以先讓它們取得一組隨機值,然後通過損失函數((loss))來將參數進行調整優化。我們可以簡單的將損失函數定義為:
[ L(w, b) = sum_{i=1}^{i=n}{(hat y^i-(b+w*x^i))^2} ]
公式中的(n)表示樣本個數,同時我們使用了平方差來作為損失函數,當然也可以選取其它的形式。這樣,我們可以通過最小化損失函數值來優化模型參數。
為了最小化損失函數,我們可以使用梯度下降法。通過梯度下降法,我們每次更新參數之前都首先計算一下模型中的各個參數對(loss)的影響程度,選擇能夠使得(loss)下降最快的方向來更新參數。這樣,我們就能夠快速地優化模型。
在這個過程中,我們會計算參數(w)和(b)對於(loss)的微分,這可以簡單地視作有一個有一條曲線是(loss)和(w)的關係曲線,(loss)隨着(w)的變化而變化,計算微分就算為了計算沿着曲線的切線。 當切線的斜率為負數時,顯然將(w)沿着該方向改變會使得(loss)變小。
在此,我們將參數更新的公式設置為:
[ w^{k+1} =w^k – eta frac{dL}{dw}|_{w=w^k} ]
其中(eta)為學習率,是一個超參數。對於偏差(b)的優化也是進行同樣的處理。
經過一定輪數的參數更新之後,(frac{dL}{dw})將會趨近於0,這時候,我們認為模型性能已經達到了最佳。但是需要注意的是,這種方法很容易就會使得模型陷入局部最小而無法達到全局最小的情形。當然,對於凸優化是完全不存在這個問題的,因為它的局部極小點就是全局最小點。
詳細參數對於損失的計算公式為:
已知:
[ L(w, b) = sum_{k=1}^{n}(hat y^k – (b + w*x^k))^2 ]
則:
[ frac{dL}{dw} = 2sum_{k=1}^{n}(hat y^k – (b + w*x^k))(-x^k) ]
[ frac{dL}{db} = -2sum_{k=1}{n}{(hat y^k – (b+w*x^k))} ]
為了使我們的模型能夠很好的擬合訓練集數據,我們總是會有很多的方法,最簡單的就是直接增大模型的複雜度,比如,將線性的規則更新為二次、三次的函數等等,即我們能夠很容易地使得模型能夠很好的擬合訓練集數據,只要我們的模型夠複雜。然而,我們更想要看到的情況是,我們模型在測試集或者說在模型沒有見到過的數據集合上會表現出良好的性能。過為複雜的模型有更大的可能性出現對於訓練集過擬合的情況,當兩個模型都能很好地擬合訓練集時,我們總是偏向於選擇複雜度低的模型。
模型的過擬合是很難避免的,我們也能夠使用很多方法來降低過擬合,提高模型的泛化能力。如:
正則化(Regularization)
正則化就是更改(loss)函數,以約束模型的複雜度,公式如下:
[ L = sum_{k=1}^n (hat y^k- (b + sum w_kx_k))^2 + lambda sum(w_k)^2 ]
後面的項即為用於約束模型複雜度的項。可以看到,我們期望(w_k)越小越好。當參數值較小且接近於0的時候,對應的曲線是比較平滑的,這時候,當輸入的數據出現變化時,輸出對於這些變化是比較不敏感的。這個(lambda)值越大,表明我們越希望參數值更小。顯然,這也是一個需要我們進行嘗試的超參數。