從CPU緩存看緩存的套路
一、前言
不同存儲技術的訪問時間差異很大,從 計算機層次結構 可知,通常情況下,從高層往底層走,存儲設備變得更慢、更便宜同時體積也會更大,CPU 和內存之間的速度存在着巨大的差異,此時就會想到計算機科學界中一句著名的話:計算機科學的任何一個問題,都可以通過增加一個中間層來解決。
二、引入緩存層
為了解決速度不匹配問題,可以通過引入一個緩存中間層來解決問題,但是也會引入一些新的問題。現代計算機系統中,從硬件到操作系統、再到一些應用程序,絕大部分的設計都用到了著名的局部性原理,局部性通常有如下兩種不同的形式:
時間局部性:在一個具有良好的時間局部性的程序當中,被引用過一次的內存位置,在將來一個不久的時間內很可能會被再次引用到。
空間局部性:在一個具有良好的空間局部性的程序當中,一個內存位置被引用了一次,那麼在不久的時間內很可能會引用附近的位置。
有上面這個局部性原理為理論指導,為了解決二者速度不匹配問題就可以在 CPU 和內存之間加一個緩存層,於是就有了如下的結構:
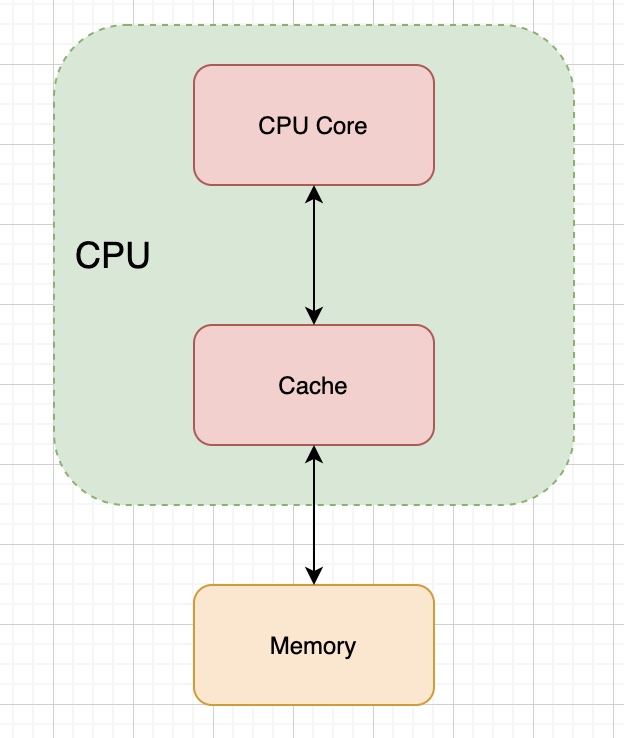
三、何時更新緩存
在 CPU 中引入緩存中間層後,雖然可以解決和內存速度不一致的問題,但是同時也面臨著一個問題:當 CPU 更新了其緩存中的數據之後,要什麼時候去寫入到內存中呢?,比較容易想到的一個解決方案就是,CPU 更新了緩存的數據之後就立即更新到內存中,也就是說當 CPU 更新了緩存的數據之後就會從上到下更新,直到內存為止,英文稱之為write through,這種方式的優點是比較簡單,但是缺點也很明顯,由於每次都需要訪問內存,所以速度會比較慢。還有一種方法就是,當 CPU 更新了緩存之後並不馬上更新到內存中去,在適當的時候再執行寫入內存的操作,因為有很多的緩存只是存儲一些中間結果,沒必要每次都更新到內存中去,英文稱之為write back,這種方式的優點是 CPU 執行更新的效率比較高,缺點就是實現起來會比較複雜。
上面說的在適當的時候寫入內存,如果是單核 CPU 的話,可以在緩存要被新進入的數據取代時,才更新內存,但是在多核 CPU 的情況下就比較複雜了,由於 CPU 的運算速度超越了 1 級緩存的數據 I\O 能力,CPU 廠商又引入了多級的緩存結構,比如常見的 L1、L2、L3 三級緩存結構,L1 和 L2 為 CPU 核心獨有,L3 為 CPU 共享緩存。
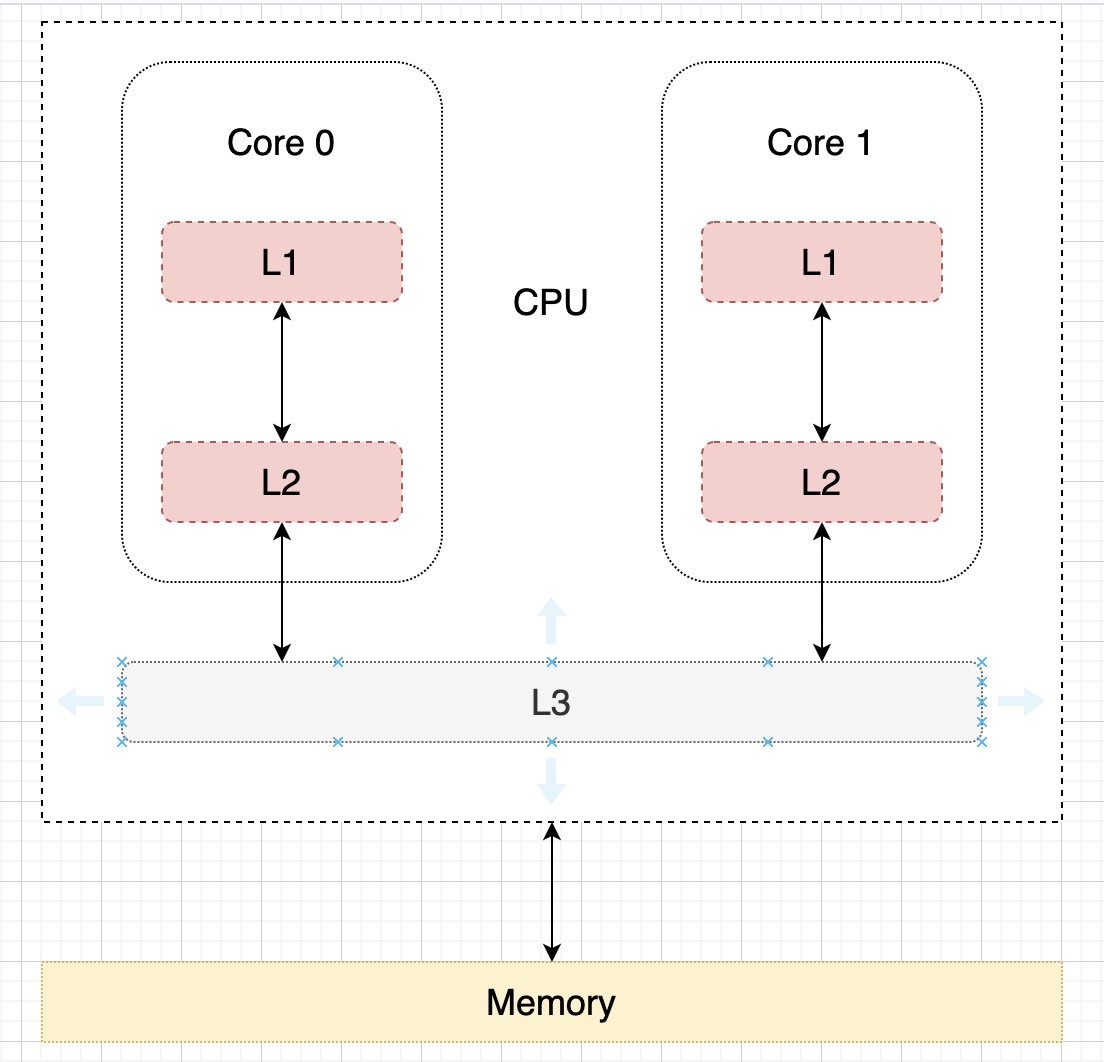
如果現在分別有兩個線程運行在兩個不同的核 Core 1 和 Core 2 上,內存中 i 的值為 1,這兩個分別運行在兩個不同核上的線程要對 i 進行加 1 操作,如果不加一些限制,兩個核心同時從內存中讀取 i 的值,然後進行加 1 操作後再分別寫入內存中,可能會出現相互覆蓋的情況,解決的方法相信大家都能想得到,第一種是只要有一個核心修改了緩存的數據之後,就立即把內存和其它核心更新。第二種是當一個核心修改了緩存的數據之後,就把其它同樣複製了該數據的 CPU 核心失效掉這些數據,等到合適的時機再更新,通常是下一次讀取該緩存的時候發現已經無效,才從內存中加載最新的值。
四、緩存一致性協議
不難看出第一種需要頻繁訪問內存更新數據,執行效率比較低,而第二種會把更新數據推遲到最後一刻才會更新,讀取內存,效率高(類似於懶加載)。 緩存一致性協議(MESI) 就是使用第二種方案,該協議主要是保證緩存內部數據的一致,不讓系統數據混亂。MESI 是指 4 種狀態的首字母。每個緩存存儲數據單元(Cache line)有 4 種不同的狀態,用 2 個 bit 表示,狀態和對應的描述如下:
| 狀態 | 描述 | 監聽任務 |
|---|---|---|
| M 修改 (Modified) | 該 Cache line 有效,數據被修改了,和內存中的數據不一致,數據只存在於本 Cache 中 | Cache line 必須時刻監聽所有試圖讀該緩存行相對就主存的操作,這種操作必須在緩存將該緩存行寫回主存並將狀態變成 S(共享)狀態之前被延遲執行 |
| E 獨享、互斥 (Exclusive) | 該 Cache line 有效,數據和內存中的數據一致,數據只存在於本 Cache 中 | Cache line 必須監聽其它緩存讀主存中該緩存行的操作,一旦有這種操作,該緩存行需要變成 S(共享)狀態 |
| S 共享 (Shared) | 該 Cache line 有效,數據和內存中的數據一致,數據存在於很多 Cache 中 | Cache line 必須監聽其它緩存使該緩存行無效或者獨享該緩存行的請求,並將該 Cache line 變成無效 |
| I 無效 (Invalid) | 該 Cache line 無效 | 無監聽任務 |
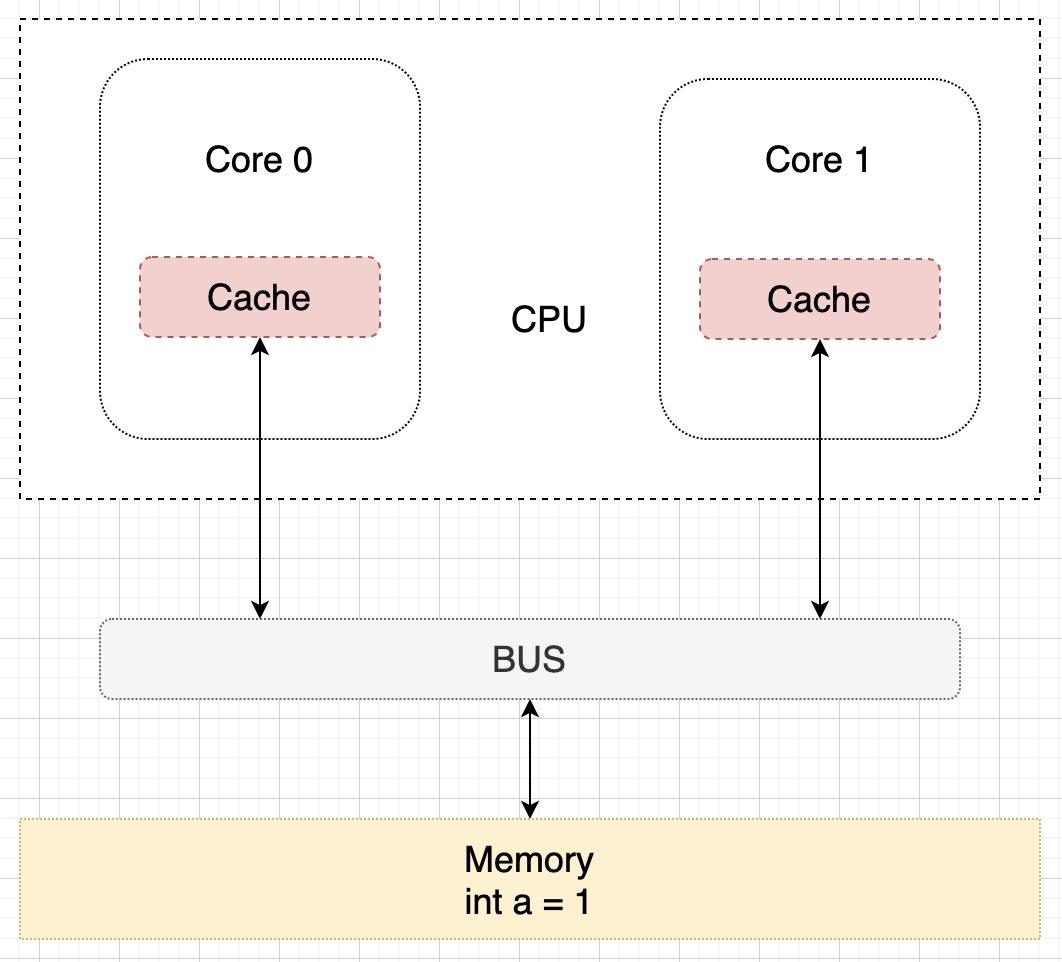
下面看看基於緩存一致性協議是如何進行讀取和寫入操作的, 假設現在有一個雙核的 CPU,為了描述方便,簡化一下只看其邏輯結構:
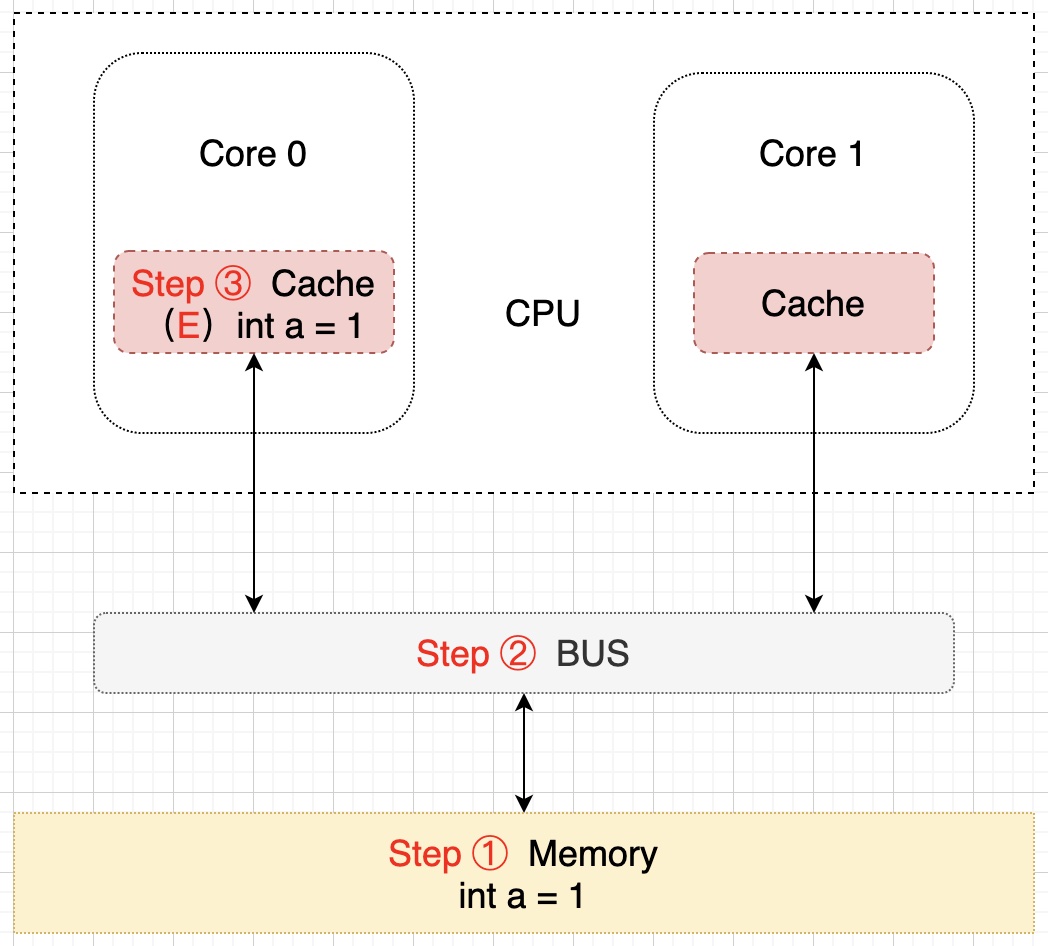
單核讀取步驟:Core 0 發出一條從內存中讀取 a 的指令,從內存通過 BUS 讀取 a 到 Core 0 的緩存中,因為此時數據只在 Core 0 的緩存中,所以將 Cache line 修改為 E 狀態(獨享),該過程用示意圖表示如下:
雙核讀取步驟:首先 Core 0 發出一條從內存中讀取 a 的指令,從內存通過 BUS 讀取 a 到 Core 0 的緩存中,然後將 Cache line 置為 E 狀態,此時 Core 1 發出一條指令,也是要從內存中讀取 a,當 Core 1 試圖從內存讀取 a 的時候, Core 0 檢測到了發生地址衝突(其它緩存讀主存中該緩存行的操作),然後 Core 0 對相關數據做出響應,a 存儲於這兩個核心 Core 0 和 Core 1 的緩存行中,然後設置其狀態為 S 狀態(共享),該過程示意圖如下:
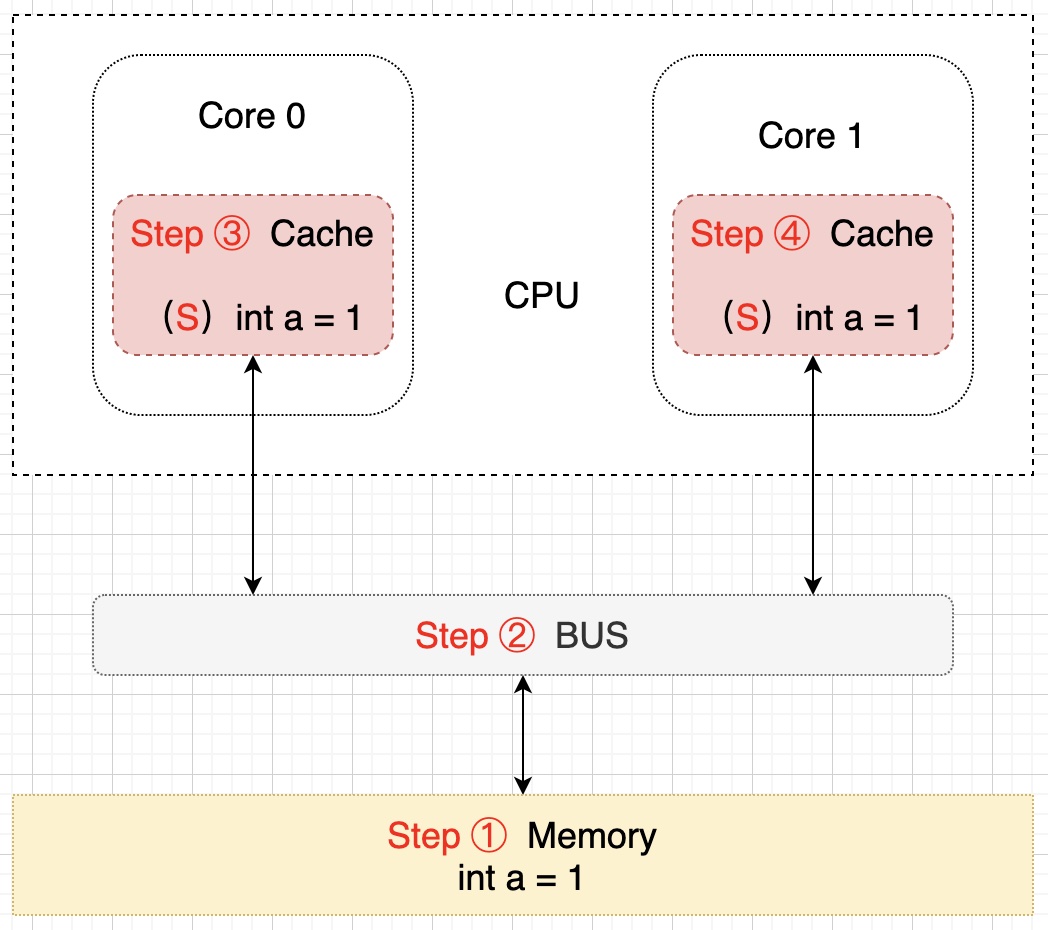
假設此時 Core 0 核心需要對 a 進行修改了,首先 Core 0 會將其緩存的 a 設置為 M(修改)狀態,然後通知其它緩存了 a 的其它核 CPU(比如這裡的 Core 1)將內部緩存的 a 的狀態置為 I(無效)狀態,最後才對 a 進行賦值操作。該過程如下所示:
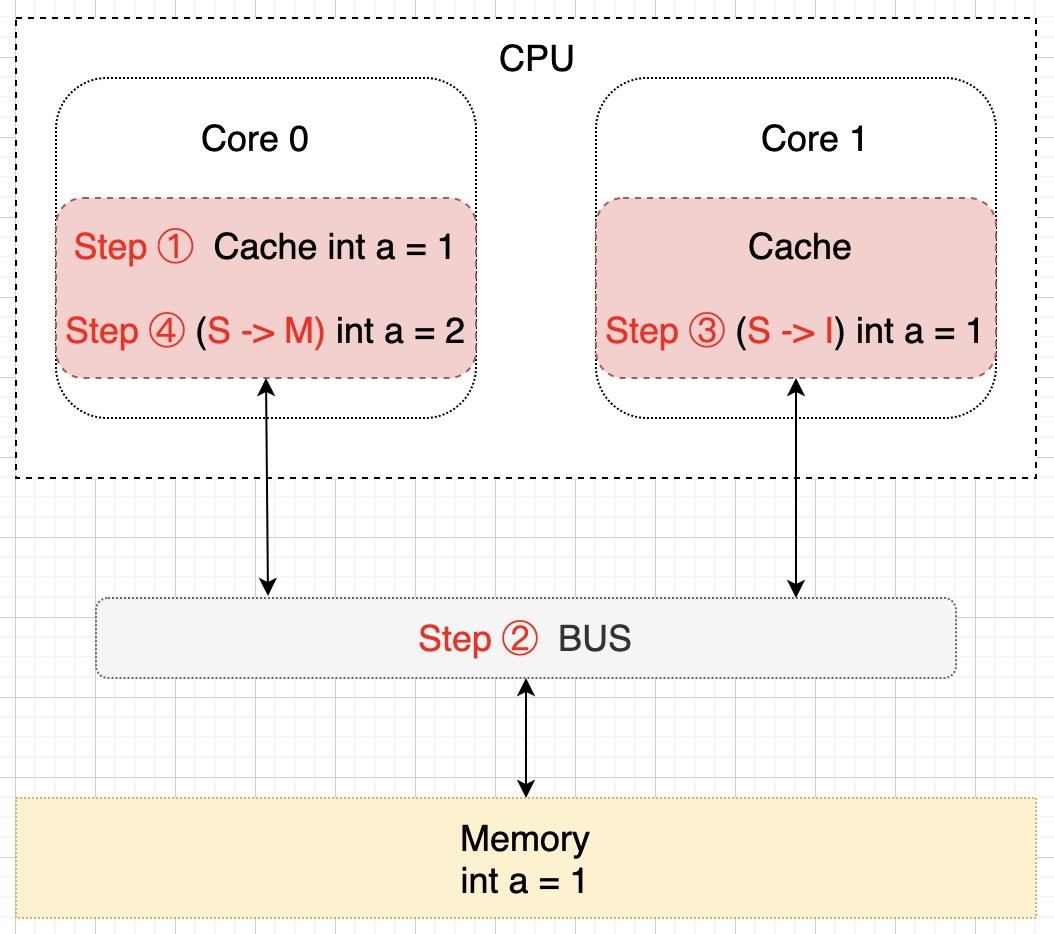
細心的朋友們可能已經注意到了,上圖中內存中 a 的值(值為 1)並不等於 Core 0 核心中緩存的最新值(值為 2),那麼要什麼時候才會把該值更新到內存中去呢?就是當 Core 1 需要讀取 a 的值的時候,此時會通知 Core 0 將 a 的修改後的最新值同步到內存(Memory)中去,在這個同步的過程中 Core 0 中緩存的 a 的狀態會置為 E(獨享)狀態,同步完成後將 Core 0 和 Core 1 中緩存的 a 置為 S(共享)狀態,示意圖描述該過程如下所示:
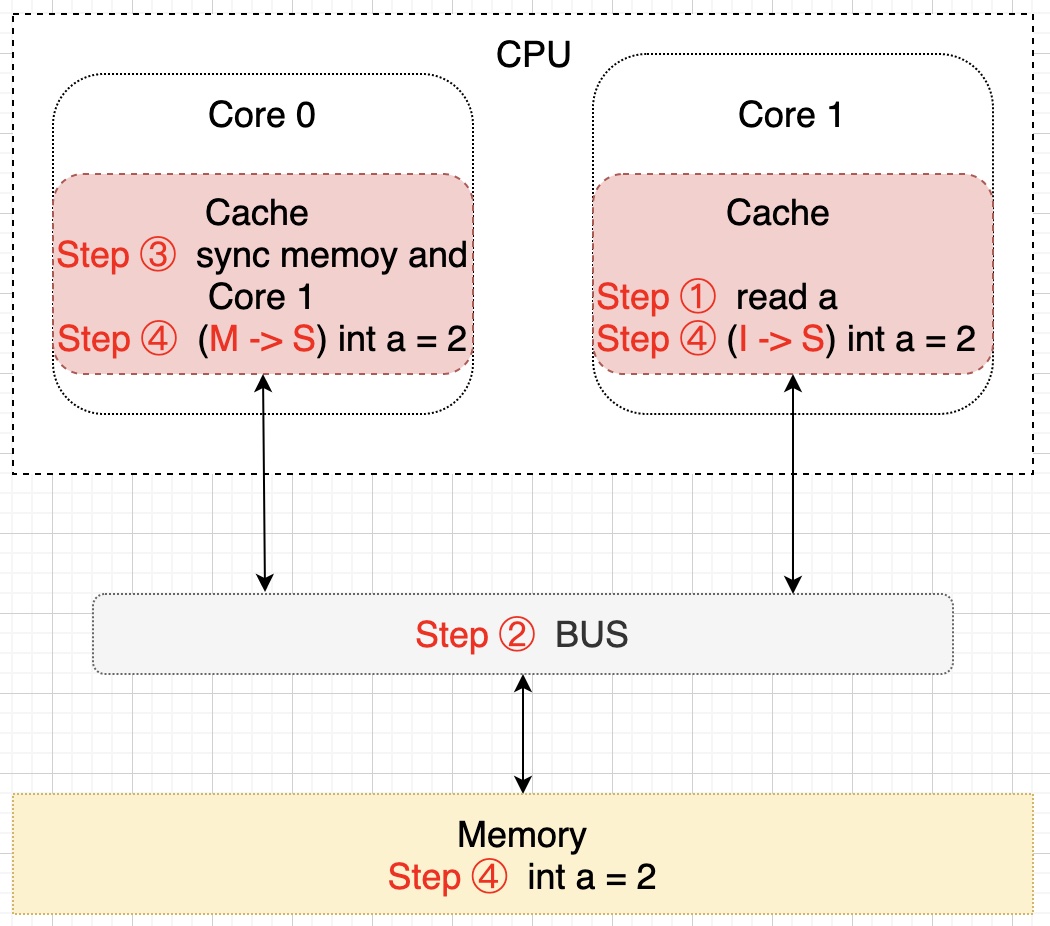
至此,變量 a 在 CPU 的兩個核 Core 0 和 Core 1 中回到了 S(共享)狀態了,以上只是簡單的描述了一下大概的過程,實際上這些都是在 CPU 的硬件層面上去保證的,而且操作比較複雜。
五、總結
現在很多一些實現緩存功能的應用程序都是基於這些思想設計的,緩存把數據庫中的數據進行緩存到速度更快的內存中,可以加快我們應用程序的響應速度,比如我們使用常見的 Redis 數據庫可能是採用下面這些策略:① 首先應用程序從緩存中查詢數據,如果有就直接使用該數據進行相應操作後返回,如果沒有則查詢數據庫,更新緩存並且返回。② 當我們需要更新數據時,先更新數據庫,然後再讓緩存失效,這樣下次就會先查詢數據庫再回填到緩存中去,可以發現,實際上底層的一些思想都是相通的,不同的只是對於特定的場景可能需要增加一些額外的約束。基礎知識才是技術這顆大樹的根,我們先把根栽好了,剩下的那些枝和葉都是比較容易得到的東西了。


