基於k8s的集群穩定架構
前言
我司的集群時刻處於崩潰的邊緣,通過近三個月的掌握,發現我司的集群不穩定的原因有以下幾點:
1、發版流程不穩定
2、缺少監控平台【最重要的原因】
3、缺少日誌系統
4、極度缺少有關操作文檔
5、請求路線不明朗
總的來看,問題的主要原因是缺少可預知的監控平台,總是等問題出現了才知道。次要的原因是服務器作用不明朗和發版流程的不穩定。
解決方案
發版流程不穩定
重構發版流程。業務全面k8s化,構建以kubernetes為核心的ci/cd流程。
發版流程
有關發版流程如下:
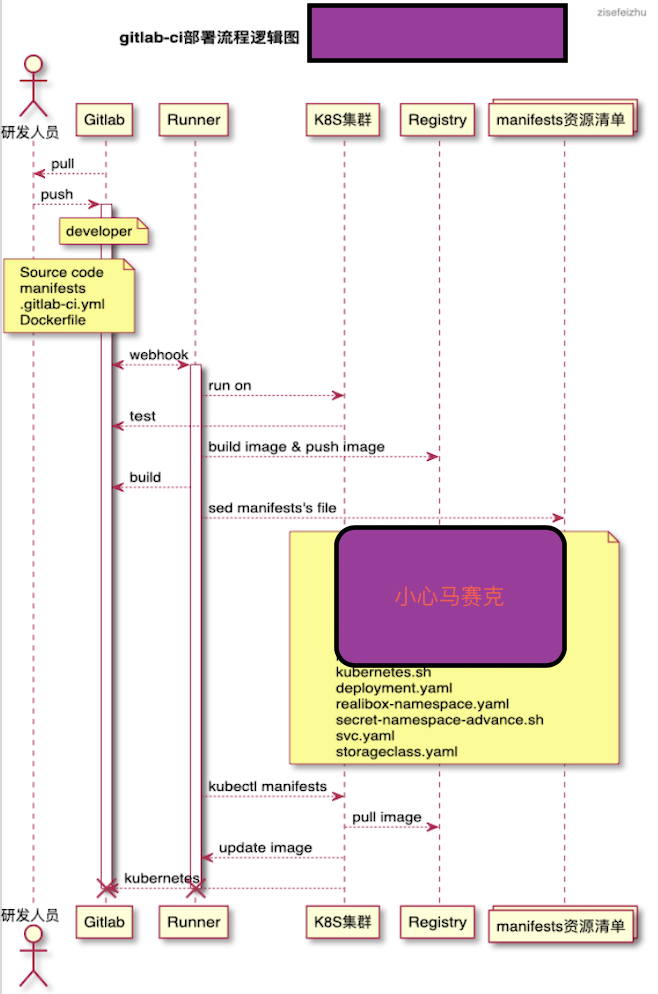
淺析:研發人員提交代碼到developer分支(時刻確保developer分支處於最新的代碼),developer分支合併到需要發版環境對應的分支,觸發企業微信告警,觸發部署在k8s集群的gitlab-runner pod,新啟runner pod 執行ci/cd操作。在這個過程中需要有三個步驟:測試用例、打包鏡像、更新pod。第一次部署服務在k8s集群環境的時候可能需要:創建namespace、創建imagepullsecret、創建pv(storageclass)、創建deployment(pod controller)、創建svc、創建ingress、等。其中鏡像打包推送阿里雲倉庫和從阿里雲倉庫下載鏡像使用vpc訪問,不走公網,無網速限制。流程完畢,runner pod 銷毀,gitlab 返回結果。
需要強調的一點是,在這裡的資源資源清單不包含configmap或者secret,牽扯到安全性的問題,不應該出
現在代碼倉庫中,我司是使用rancher充當k8s多集群管理平台,上述安全問題在rancher的dashboard中由運維來做的。
服務部署邏輯圖
有關服務部署邏輯圖如下:
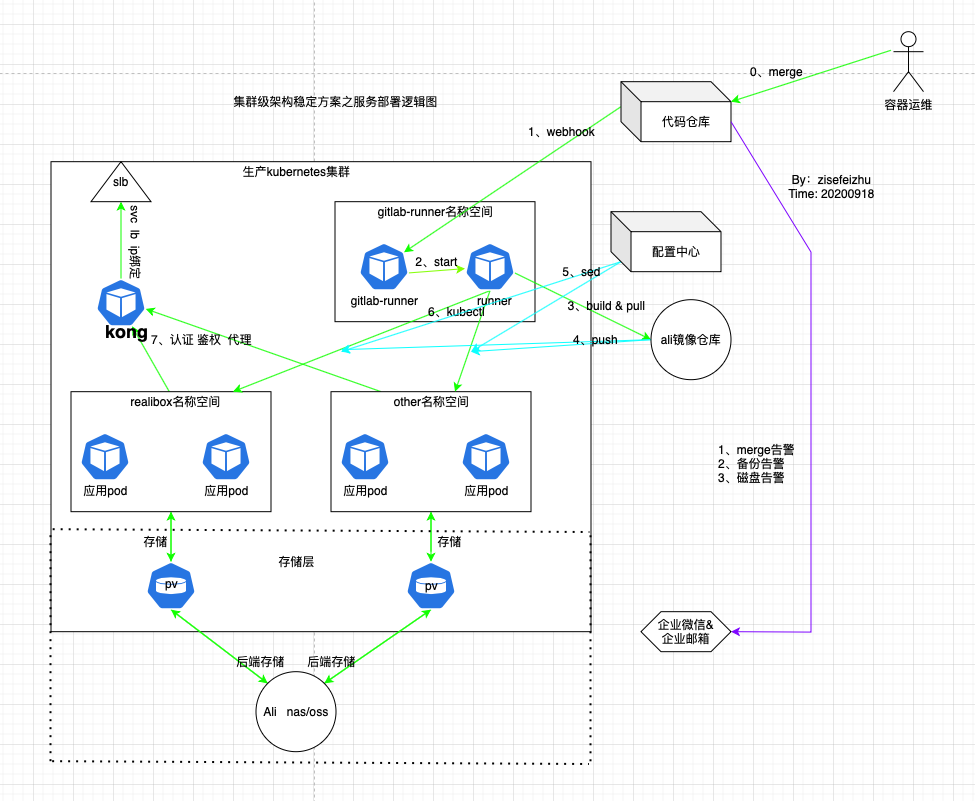
根據發版流程的淺析,再根據邏輯圖可以明確發版流程。在這裡看到我司使用的是kong代替nginx,做認證、鑒權、代理。而slb的ip綁定在kong上。0,1,2屬於test job;3屬於build job;4,5,6,7屬於change pod 階段。並非所有的服務都需要做存儲,需要根據實際情況來定,所以需要在kubernetes.sh里寫判斷。在這裡我試圖使用一套CI應用與所有的環境,所以需要在kubernetes.sh中用到的判斷較多,且.gitlab-ci.yml顯得過多。建議是使用一個ci模版,應用於所有的環境,畢竟怎麼省事怎麼來。還要考慮自己的分支模式,具體參考://www.cnblogs.com/zisefeizhu/p/13621797.html
缺少監控預警平台
構建可信賴且符合我司集群環境的聯邦監控平台,實現對幾個集群環境的同時監控和預故障告警,提前介入。
監控預警邏輯圖
有關監控預警邏輯圖如下:
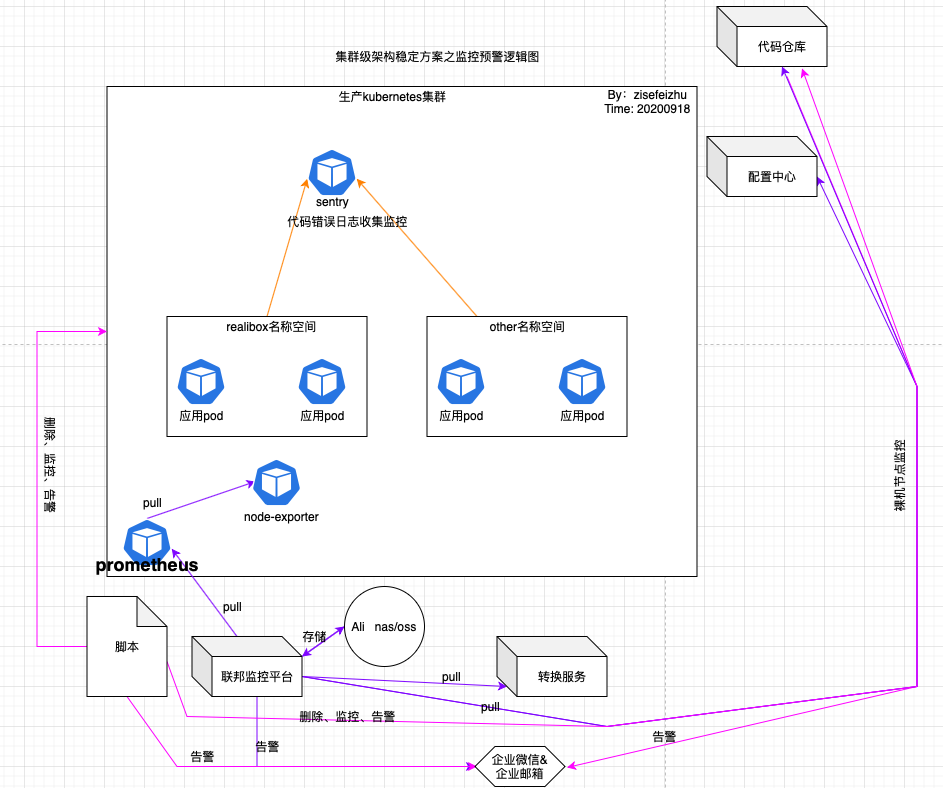
淺析:總的來說,我這裡使用到的監控方案是prometheus➕shell腳本或go腳本➕sentry。使用到的告警方式是企業微信或者企業郵箱。上圖三種顏色的線代表三種監控方式需要注意。腳本主要是用來做備份告警、證書告警、抓賊等。prometheus這裡採用的是根據prometheus-opertor修改的prometheus資源清單,數據存儲在nas上。sentry嚴格的來講屬於日誌收集類的平台,在這裡我將其歸為監控類,是因為我看中了其收集應用底層代碼的崩潰信息的能力,屬於業務邏輯監控, 旨在對業務系統運行過程中產生的錯誤日誌進行收集歸納和監控告警。
注意這裡使用的是聯邦監控平台,而部署普通的監控平台。
聯邦監控預警平台邏輯圖
多集群聯邦監控預警平台邏輯圖如下:
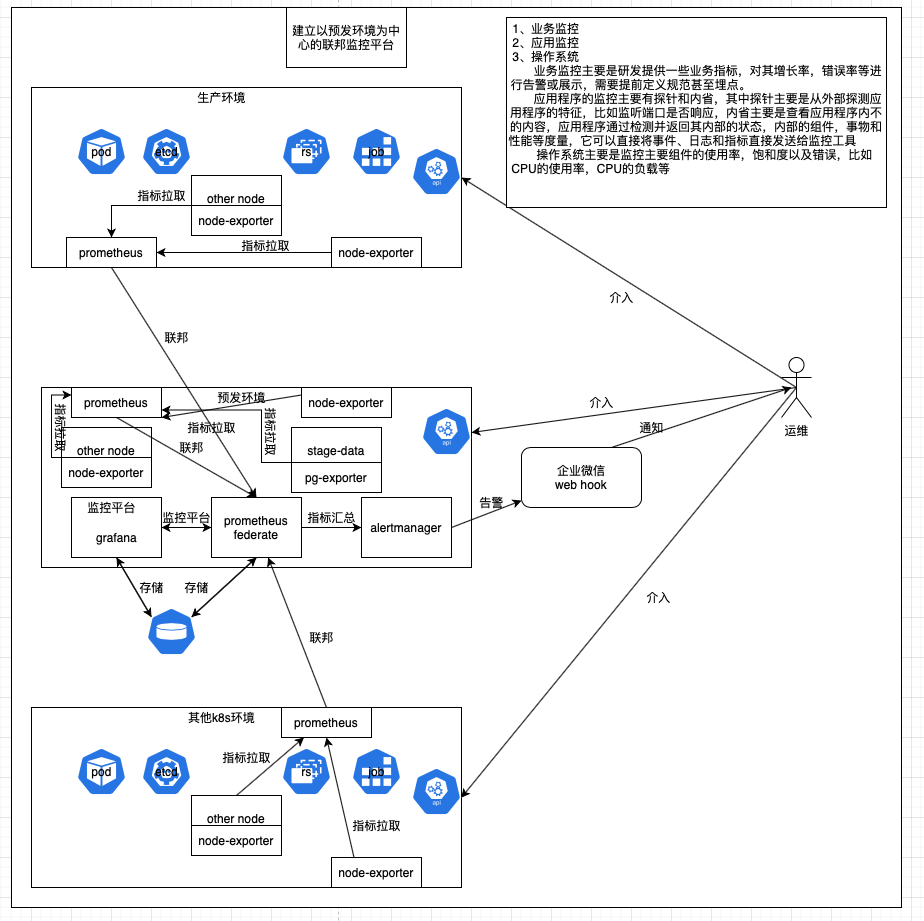
因為我司有幾個k8s集群,如果在每個集群上都部署一套監控預警平台的話,管理起來太過不便,所以這裡我採取的策略是使用將各監控預警平台實行一個聯邦的策略,使用統一的可視化界面管理。這裡我將實現三個級別餓監控:操作系統級、應用程序級、業務級。對於流量的監控可以直接針對kong進行監控,模版7424。
缺少日誌系統
隨着業務全面k8s化進程的推進,對於日誌系統的需求將更加渴望,k8s的特性是服務的故障日誌難以獲取。建立可觀測的能過濾的日誌系統可以降低對故障的分析難度。
有關日誌系統邏輯圖如下:
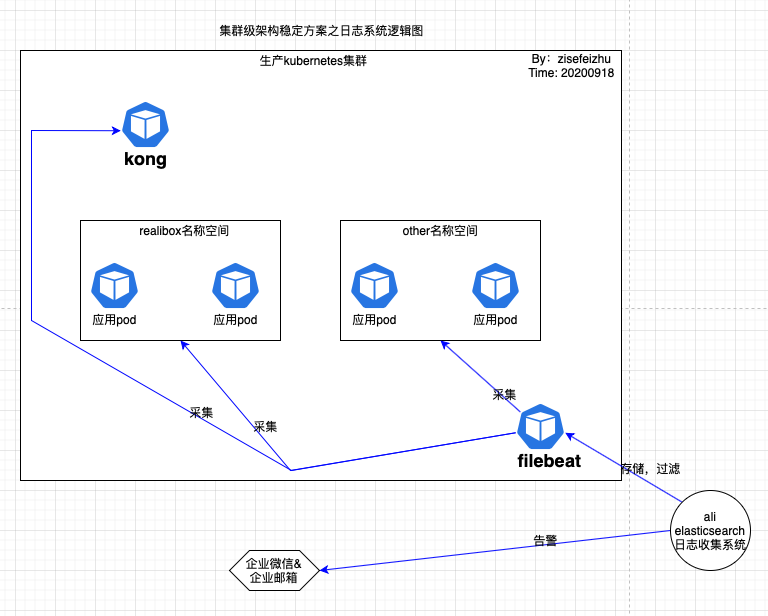
淺析:在業務全面上k8s化後,方便了管理維護,但對於日誌的管理難度就適當上升了。我們知道pod的重啟是有多因素且不可控的,而每次pod重啟都會重新記錄日誌,即新pod之前的日誌是不可見的。當然了有多種方法可以實現日誌長存:遠端存儲日誌、本機掛載日誌等。出於對可視化、可分析等的考慮,選擇使用elasticsearch構建日誌收集系統。
極度缺少有關操作文檔
建立以語雀–> 運維相關資料為中心的文檔中心,將有關操作、問題、腳本等詳細記錄在案,以備隨時查看。
淺析因安全性原因,不便於過多同事查閱。運維的工作比較特殊,安全化、文檔化是必須要保障的。我認為不論是運維還是運維開發,書寫文檔都是必須要掌握的,為己也好,為他也罷。文檔可以簡寫,但必須要含苞核心的步驟。我還是認為運維的每一步操作都應該記錄下來。
請求路線不明朗
根據集群重構的新思路,重新梳理集群級流量請求路線,構建具備:認證、鑒權、代理、連接、保護、控制、觀察等一體的流量管理,有效控制故障爆炸範圍。
請求路線邏輯圖如下:
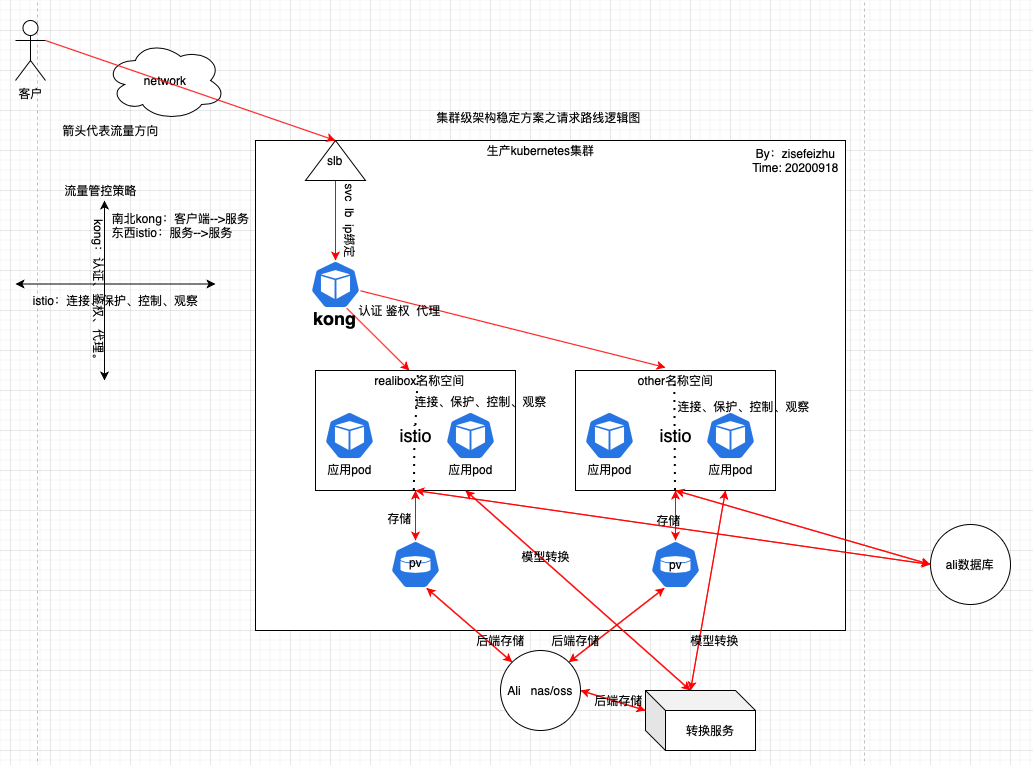
淺析:客戶訪問//www.cnblogs.com/zisefeizhu 經過kong網關鑒權後進入特定名稱空間(通過名稱空間區分項目),因為服務已經拆分為微服務,服務間通信經過istio認證、授權,需要和數據庫交互的去找數據庫,需要寫或者讀存儲的去找pv,需要轉換服務的去找轉換服務…… 然後返迴響應。
總結
綜上所述,構建以:以kubernetes為核心的ci/cd發版流程、以prometheus為核心的聯邦監控預警平台、以elasticsearch為核心的日誌收集系統、以語雀為核心的文檔管理中心、以kong及istio為核心的南北東西流量一體化服務,可以在高平發,高可靠性上做到很好保障。
附:總體架構邏輯圖
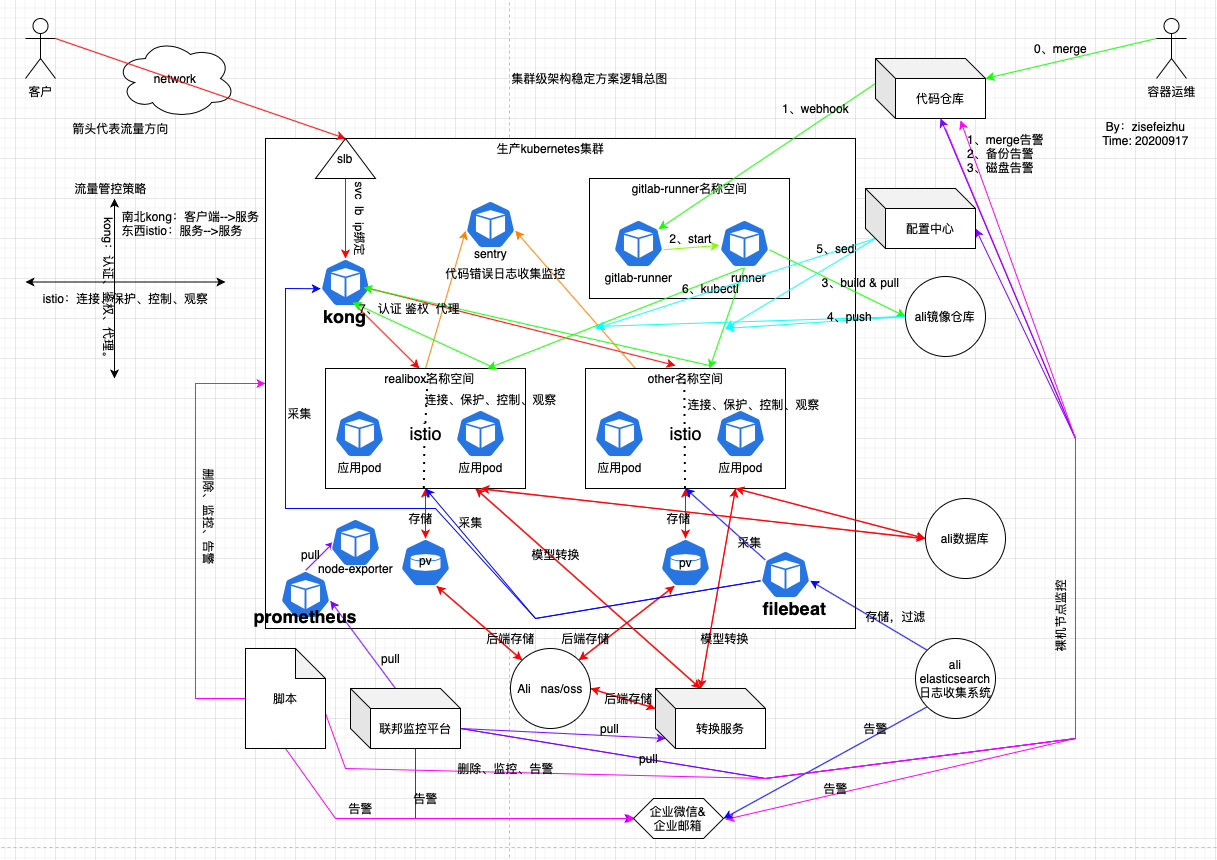
註:請根據箭頭和顏色來分析。
淺析:上圖看着似乎過於混亂,靜下心來,根據上面的拆分模塊一層層分析還是可以看清晰的。這裡我用不同顏色的連線代表不同模塊的系統,根據箭頭走還是蠻清晰的。
根據我司目前的業務流量,上述功能模塊,理論上可以實現集群的維穩。私認為此套方案可以確保業務在k8s集群上穩定的運行一段時間,再有問題就屬於代碼層面的問題了。這裡沒有使用到中間件,倒是使用到了緩存redis不過沒畫出來。我規劃在上圖搞定後再在日誌系統哪裡和轉換服務哪裡增加個中間件kafka或者rq 看情況吧。


