serverless在微店node領域的探索應用
- 2019 年 10 月 3 日
- 筆記
背景
目前微店中台團隊為了滿足公司大部分產品、運營以及部分後端開發人員的嘗鮮和試錯的需求,提供了一套基於圖形化搭建的服務端接口交付方案,利用該方案及提供的系統可生成一副包含運行時環境定義可立即運行的工程代碼,最後,通過 「某種serverless平台」 實現生成後代碼的部署、CI、運行、反向代理、進程守、日誌上報、進程分組擴容等功能。
這樣,產品和運營人員可基於此種方式搭建的接口配合常用的cms系統實現簡單查詢需求如活動大促的自主「研發」上線,代碼的可靠性、穩定性由中台研發側提供的「某種serverless平台」保障,有效支撐了多個業務快速上線,節省後端開發人員的人力與硬件資源的開銷(大多數需求下,nodejs業務對虛擬機的資源開銷小於java業務)。
接口搭建系統
此處並不講解接口搭建系統的原理與實現,只說明其與上文提到的 「某種serverless平台」 的關係。
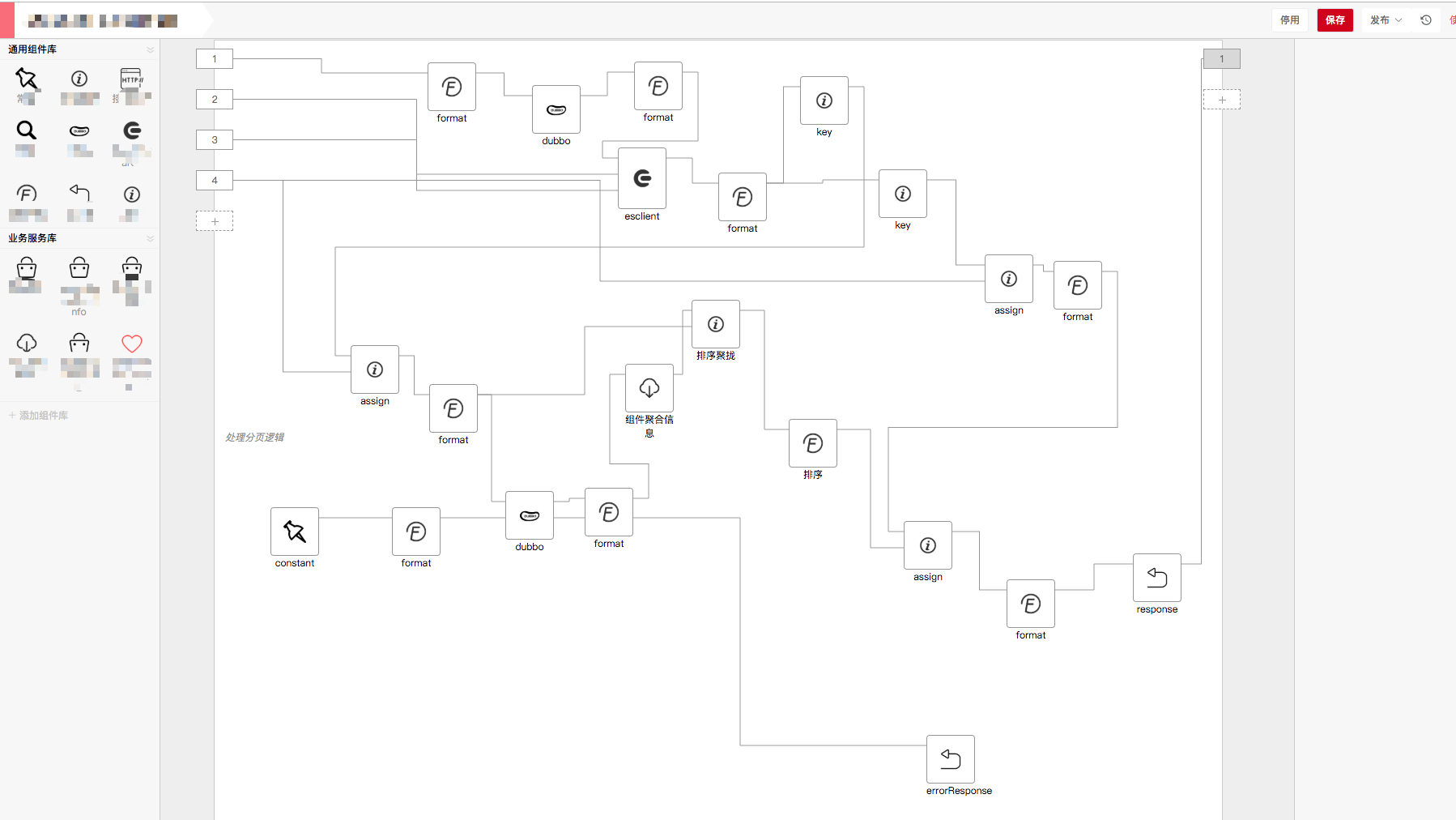
這是系統的全貌,部分細節由於敏感信息而省略。平台使用方可基於每個功能組件搭建出一套複雜的業務流,在搭建階段,提供在線debug和日誌功能,可用於排錯;在部署CI階段,可集成不同的運行時平台,既可以是自主實現的運行時,也可是第三方雲平台;在運行階段,通過使用agentool工具實時監控當前服務的性能,並可通過traceId一覽請求在各系統的全貌。
serverless方案
本節以資源隔離粒度為度量,介紹了我對三種serverless方案的取捨以及最終為何選擇了隔離程度更高的kubeless雲平台。
基於函數隔離的Parse Server方案
Parse Server提供了基礎功能:基於類與對象的權限控制、基於document的nosql存儲、簡易的用戶身份認證、基於hook的自定義邏輯等,但經過筆者的調查與論證,最終並沒有採用類似單進程下基於函數隔離的Parse Server及類似方案,這有幾點原因:
- Parse Server方案很重,額外引入了非常多不需要的功能,如權限控制、認證、存儲等
- 服務隔離級別低,多個服務在一個進程運行,多個服務會在libuv層互相搶佔CPU,互相影響對方的業務處理
- 水平擴容難度大,針對單個服務的擴容無法做到
- 底層基於express框架,無法滿足運行時接口調用鏈路的trace追蹤
- 當多個服務同時引入不同的資源如db、es或者服務創建的對象足夠多時,會存在Parse Server主進程溢出的風險,畢竟64位機的node堆內存是有1.4GB上限的,儘管這個上限是可配置的
- Parser Server發佈的接口需通過其client調用,這在公司商用情況下需要做許多額外的配置才能滿足
基於進程隔離的super-agent方案
為了解決多個服務搶佔libuv的問題,我選擇了自主研發的 super-agent方案,通過其名稱便可知它是一個超級代理,但它不僅是代理,還是一個具有極簡功能且可靠的發佈系統和運行時容器;它是一個分佈式應用,節點間功能劃分明確;它同時提供實時調試功能。
super-agent是一個多角色分佈式系統,它即可以看做node容器,也可看成serverless的node實現,它以進程為粒度管理服務。它分為「協調者」和「參與者」,協調者實現 應用CI部署、啟動、進程維護與管理和反向代理功能,參與者實現 業務請求代理、接受協調者調度。
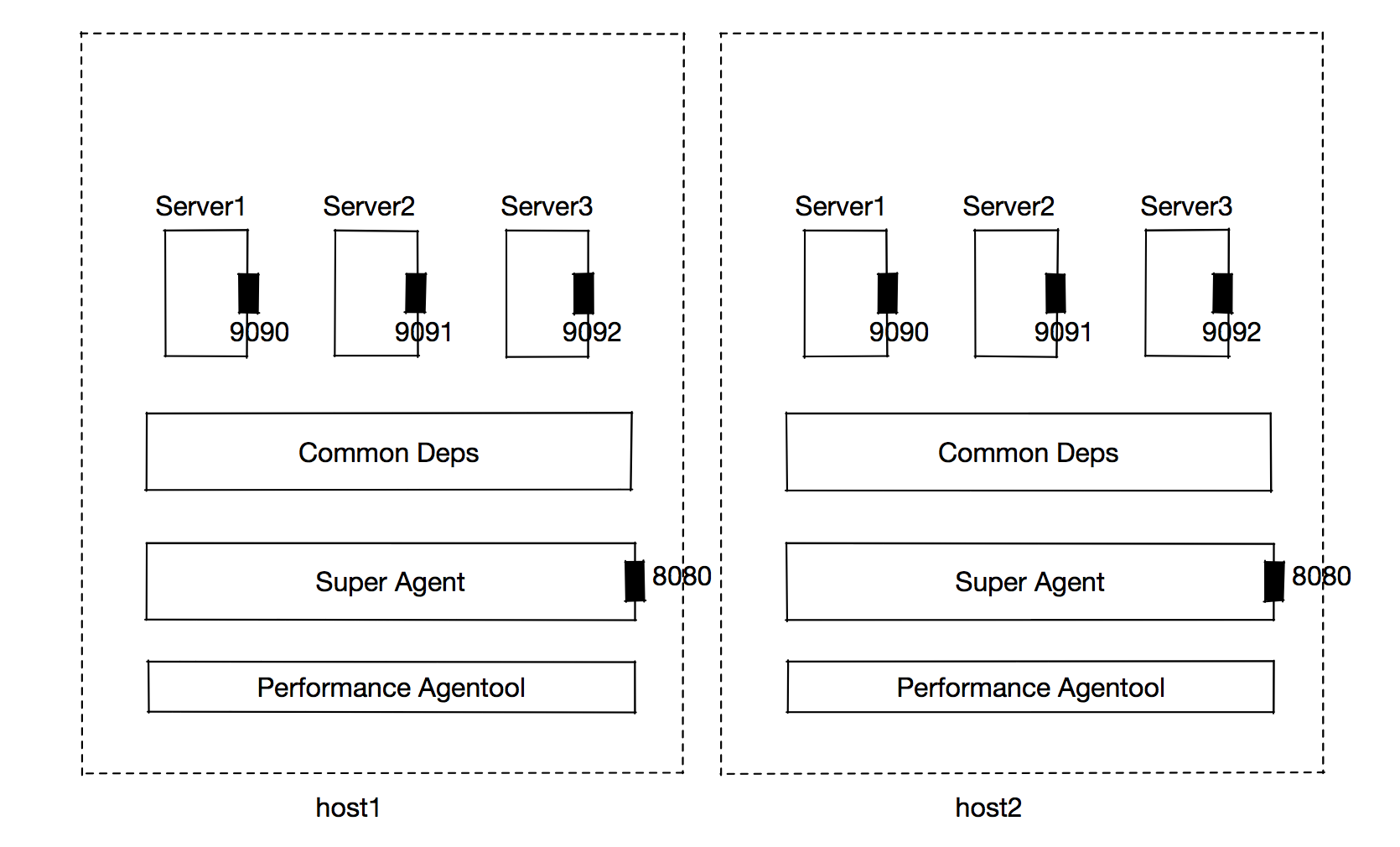
在super-agent架構中,端口是區分服務的唯一標識,端口對客戶端而言是透明的,這層端口資源的隔離由super-agent來做掉,因此多個服務可避免在libuv層的互相競爭,提供水平擴容的可能性。
反向代理
super-agent最核心的功能在於反向代理。由於每個服務都被包裝成有單獨端口的獨立HTTP應用,因此當用戶請求流量經過前端轉發層後進入super-agent,由其根據相關規則做二次轉發,目前支持基於 「路徑、端口」規則的轉發。
部署
後端應用部署需要進行 「優雅降級、流量摘除、健康檢查、應用初始化完畢檢查、流量導入、所有參與節點的部署狀態查詢」 等步驟,需要妥善處理;同時,協調者負責協調眾多參與節點全部完成部署操作,這是一個分佈式事務,需要做好事務出錯後的相關業務補償。
關於流量
上圖並未畫出節點角色的區別,實際上只有參與者節點才真正接受用戶請求。
協調者流量全部來自於內部系統,包括接受 「接口搭建系統」調用或者其他系統實現的dashboard服務;同時其會向參與者發送相關信令信息,如部署、擴容、下線、debug等。
參與者流量來自於內部系統和外部流量,其中大部分來自於外部流量。內部流量則承載協調者的信令信息。
水平擴容
服務的水平擴容重要性不言而喻。super-agent方案中,協調者負責管理服務的擴容與邏輯分組。
此處的服務是通過服務搭建平台通過拖拽生成的nodejs代碼,它是一個包含複雜業務邏輯的函數,可以是多文件。具體的,super-agent通過將該服務包裝成一個HTTP服務在單獨的進程中執行。因此,如果要對服務進行水平擴容,提供多種策略的選擇:
- 默認每台虛擬機或物理機一個服務進程,總體上N個機器N個服務進程
- 擴容時默認每台機器再fork一個服務進程,N機器2*N個服務進程
- 為了更充分利用資源,可為每台機器劃分為邏輯組,同時選擇在某幾個組的機器單獨擴容
這些策略對下游應用透明,只需選擇相關策略即可。
水平擴容的缺點:每台虛擬機或物理機資源有上限,一個正常的node進程最多消耗1.4GB內存,計算資源共享,在一台8C16G的虛擬機上,最多可同時運行16個服務。及時通過分組擴容的方式,每當擴展新的虛擬機或物理機,都需要由super-agent根據分組信息實現進程守護,同時每次服務CI部署也同樣如此。運維管理上需要配合非常清晰明了的dashboard後台才能快速定位問題,這點在多服務的問題上尤其突出。
在線調試
super-agent提供消息機制,由搭建平台中組件開發人員使用提供的serverless-toolkit工具debug相關邏輯,最終可在super-agent的協調者後台查看實時debug結果。
總結
super-agent是符合常規的基於業務進程隔離的解決方案,它有效的支撐了微店的幾個活動及產品,雖然峰值QPS不高(100左右),但它也論證了super-agent的穩定性及可靠性(線上無事故,服務無重啟,平穩升級)。
但是,super-agent仍然存在幾個問題,它讓我們不得不另覓他法:
- 日常運維困難,需要開發一系列後台系統輔助運維,這需要不少人力成本
- 這是一個典型的一機多應用場景,當部署super-agent時會對運行其上的服務有所影響(重啟),儘管這個影響並不影響用戶訪問(此時流量已摘除),但仍然是個風險點
- 水平擴容實現繁瑣,當下掉某幾台參與節點時會帶來不少影響
基於內核namespace隔離的kubeless方案
基於kubeless的方案則是隔離最為徹底的解決方法,kubeless是建立在K8s之上的serverless框架,因此它可以利用K8s實現一些非常有用的特性:
- 敏捷構建 – 能夠基於用戶提交的源碼迅速構建可執行的函數,簡化部署流程;
- 靈活觸發 – 能夠方便地基於各類事件觸發函數的執行,並能方便快捷地集成新的事件源;
- 自動伸縮 – 能夠根據業務需求,自動完成擴容縮容,無須人工干預。
其中,自動伸縮則解決了 super-agent 的痛點。
kubeless中與我們緊密相關的有兩個概念:「function和runtime」 ,function是一個統稱,它包括運行時代碼、依賴以及其他配置文件;runtime則定義運行時依賴的環境,是一個docker鏡像。
若要接入kubeless平台,我們需要解決如下幾個問題:
- 開發自定義運行時,滿足商用需求,如trace、日誌分片、上報採集
- 自定義構建鏡像,實現ts編譯
- 基於yaml的function創建、更新、刪除流程探索,並自動化
- function部署,包括流量摘除、流量導入、業務健康檢查
- 中間件日誌、業務日誌、trace日誌隔離與掛載
- function運行時用戶權限問題
- 水平擴容探索與嘗試
- 資源申請規範指定與部署規範約定
因此,前進的道路仍然很曲折,而且很多需求需要自己從源碼上去尋找解決方法。
一些說明
kubeless實現的serverless體系中,function所在pod中的所有容器共享網絡和存儲namespace,但是默認外網是不可訪問k8s集群的所有pods,因此需要通過一層代理實現請求的轉發,這就是「Service」。Service負責服務發現及轉發(iptables四層),因此在Kubeless或者K8s中不會直接通過pod IP來訪問服務,而是通過Service轉發四層流量完成。Service有K8s分配的cluserIp,clusterIp是集群內部虛擬IP,無法被外部尋址,而是通過Kube-Proxy在容器網絡之上又抽象了一層虛擬網絡,Kube-Proxy負責Service的路由與轉發(關於kube-proxy細節,請看參考資料)。
Service後端對應是一個或多個pods,這些pods中的一個容器則運行相同的業務代碼。那麼流量是如何路由至Service上來呢?這就涉及到Service的「發佈」,常用的是Ingress。Ingress包括HTTP代理服務器和ingress controller,代理服務器負責將請求按照規則路由至對應Service,這層需要Kube-Proxy實現虛擬網絡的路由;ingress controller負責從K8s API拉取最新的HTTP匹配規則。
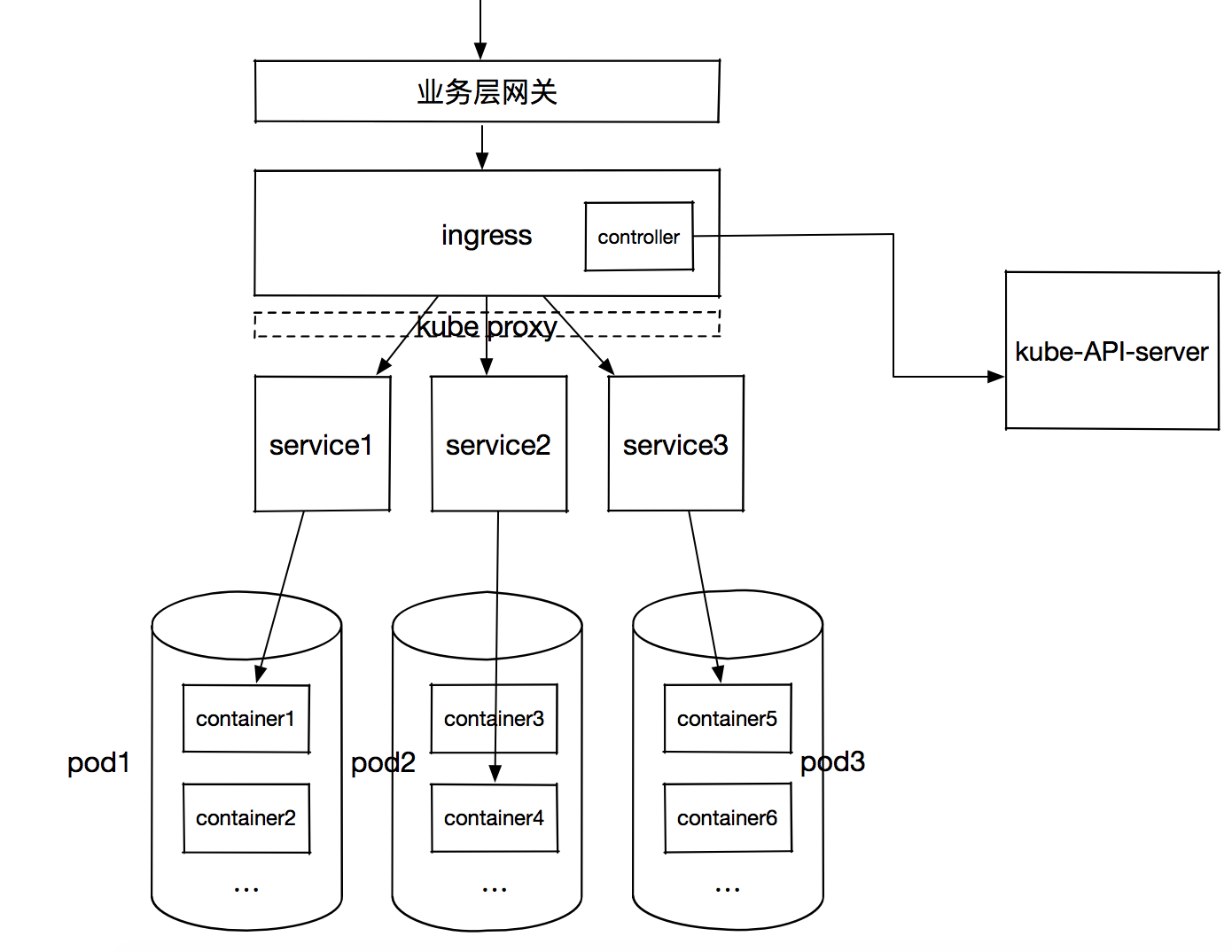
問題解決
- 自定義鏡像:這裡的鏡像包括兩部分:構建鏡像和運行時鏡像。運行時鏡像需要解決宿主代碼的魯棒性,以及提供 livenessProbe、readinessProbe、metric接口實現;構建鏡像則負責構建階段的操作,如編譯、依賴安裝、環境變量注入等操作。具體編寫可參考 implement runtime images。
- 構建鏡像參考1
- 關於function的CRUD操作,筆者先通過命令行走通整個流程後,又切換成基於yaml的配置文件啟動,使用yaml啟動好處在於:a,可使用kubeless自帶的流量導入與摘除策略 b,水平擴容簡單 c,命令簡單 d,配置文件模板化,自動化
- 部署策略由於涉及到業務特點,此處不詳細介紹
- 日誌的掛載是必要的,否則pod一旦重啟,容器內的所有日誌全部丟失。儘管會存在日誌收集的操作,可是日誌收集進程大多數都是異步進行,因此會存在丟失日誌的情況。因此,必須通過掛載volumn的形式在K8s node上映射文件。但在這過程中會出現權限的問題,這在下一點說明
- 權限問題在於kubeless將function的執行權限設置為非root。這是安全且符合常理的設定,但有時function需要root權限,這需要修改K8s的security context配置,需要謹慎處理
- 水平擴容基於K8s的HPA組件完成,目前支持基於CPU和QPS等指標進行擴容,目前筆者並未專門測試這項內容,因為它足夠可靠
- 資源申請的指定需要符合每個公司的實際情況以及業務特點,以node技術棧為例,pod中每個容器設置1C2GB的內存符合實際情況;而至於部署規範,則要兼顧運行時容器的特點,合理配置K8s的node與pod、function的對應關係
總結
運行在kubeless 中的函數和運行在super-agent的代碼沒有什麼不同,可是周邊的環境準備可大大不同。為了讓kubeless中的function可以接入公司內部中間件服務,筆者費了不少功夫,主要集中在日誌及收集部分。好在事在人為,解決的辦法總是多於失敗的方法。
進度
目前,super-agent方案已承載了10+個線上應用或活動,穩定運行4個月,資源使用率符合預期;
kubeless方案還未正式接入流量,等待進一步做相關異常測試。
參考
kubeless介紹
security-context
kube-proxy
