構建企業級數據湖?Azure Data Lake Storage Gen2實戰體驗(下)
- 2019 年 11 月 3 日
- 筆記
相較傳統的重量級OLAP數據倉庫,“數據湖”以其數據體量大、綜合成本低、支持非結構化數據、查詢靈活多變等特點,受到越來越多企業的青睞,逐漸成為了現代數據平台的核心和架構範式。
作為微軟Azure上最新一代的數據湖服務,Data Lake Storage Gen2的發佈,將雲上數據湖的能力和體驗提升上了一個新的台階。在前面的文章中,我們已分別介紹了其基本使用和大數據集群掛載的場景。作為本系列的下篇,讓我們繼續深度體驗之旅。
ADLS Gen2體驗:數據湖共享
在企業中,一個龐大的數據湖往往需要被共享。比如數據湖通常會被劃分為多個區域,這些區域最好能夠被各自對應的計算集群所訪問以進行不同的計算任務。這也充分體現了計算存儲分離的理念,是雲計算的架構精髓。那麼ADLS Gen2能否支持這一重要場景呢?
答案是肯定的。對於各計算集群而言,不妨淡化它自己的“本地”存儲,轉為考慮集群是否能夠讀取訪問遠端的數據湖實例——在這樣的思路下,就可以設立一個統一而獨立的數據湖實例,被多個計算集群共享,同時按目錄進行權限設置和數據隔離。數據湖的生命周期可獨立於計算集群的創建和銷毀,在需要時作為外部數據被引用和訪問就可以了。
接下來我們以前篇文章創建的HDInsight Spark集群為例,繼續數據湖共享的實戰驗證。微軟的一段文檔告訴了我們如何讓HDInsight集群訪問“外部”的ADLS Gen2:
To add a secondary Data Lake Storage Gen2 account, at the storage account level, simply assign the managed identity created earlier to the new Data Lake Storage Gen2 storage account that you wish to add.
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-use-data-lake-storage-gen2
看起來頗為容易,只需要將代表集群的identity賦予相應的ADLS Gen2權限即可。注意這裡的權限粒度事實上可以設置得非常細緻,精確到目錄乃至文件層級,這正是我們需要的。
接下來我們來構建和實驗這樣一個常見的重要場景:原始數據位於數據湖的區域一中,由集群1的spark程序來進行處理,並將處理後的數據落地到同一數據湖的區域二中;集群2則利用hive來對區域二中的處理後數據進行查詢。注意這裡由於計算存儲進行了分離,數據處理和查詢集群都可以是無狀態的,無工作負載時可以關閉,也能夠隨時創建或橫向擴展。
我們先來準備共享數據湖,在系列上篇中已經創建的存儲賬號cloudpickerdlg2中新建一個文件系統datalakefs-shared用於共享數據。隨後在其中分別建立zone-rawdata和zone-processed兩個文件夾,並在zone-rawdata文件夾中存放入前面使用過的小說《雙城記》文本文件ATaleOfTwoCities.txt:
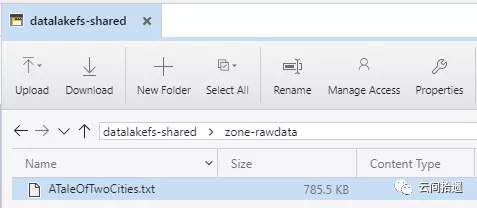
接下來,為使Spark集群順利訪問這個中央數據湖中的數據,我們只需對之前創建的spark-cluster-identity分別對兩個文件夾進行授權。這裡為zone-rawdata賦予讀權限,對於zone-processed賦予讀寫權限: 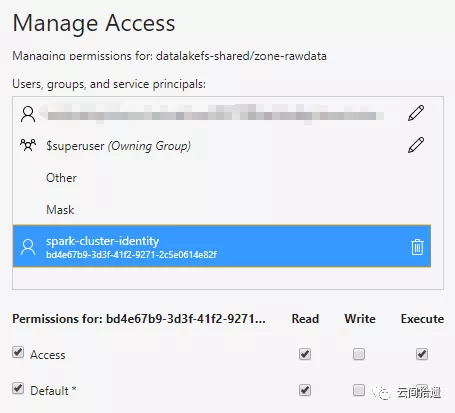
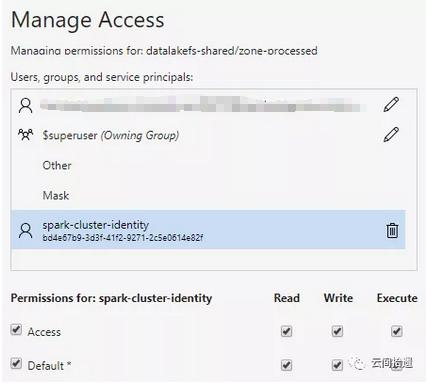
隨後,我們就可以復用系列中篇里的Spark集群來訪問這個遠端的數據湖了。再次祭出Jupyter Notebook進行數據處理,並將Spark的處理結果以parquet形式寫入zone-processed:
val domain = "abfss://[email protected]/" val book = spark.sparkContext.textFile(domain + "zone-rawdata/ATaleOfTwoCities.txt") val wordCounts = book.flatMap(l => l.split(" ")).map(w => (w, 1)).reduceByKey((a,b) => a+b).map( { case (w, c) => (w, c, w.length) } ) val wordCountsWithSchema = spark.createDataFrame(wordCounts).toDF("word", "count", "word_length") wordCountsWithSchema.write.parquet(domain + "zone-processed/ATaleOfTwoCities.parq")
運行之後可以看到,結果集parquet文件已經位於zone-processed中了。
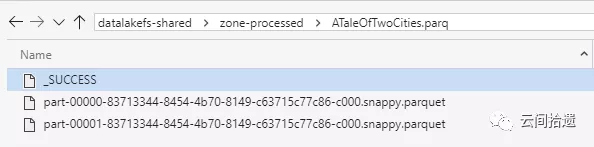
接下來我們進行考慮查詢數據湖的部分,可以創建一個獨立的Hive查詢集群並指向數據湖上的處理結果。在Azure上有一個專門為高性能在線查詢優化的HDInsight大數據集群類型,被稱為Interactive Query,其中使用了Hive LLAP,很適合我們的場景。我們不妨就部署它作為查詢集群。

在此我們略去建立Hive LLAP集群的詳細過程,其步驟與建立Spark集群類似,按照Wizard的提示逐步選取即可。需要注意的是,我們也相應地需要為查詢者創建一個對應的身份hive-cluster-identity,並將這個hive-cluster-identity設置為查詢集群的身份。 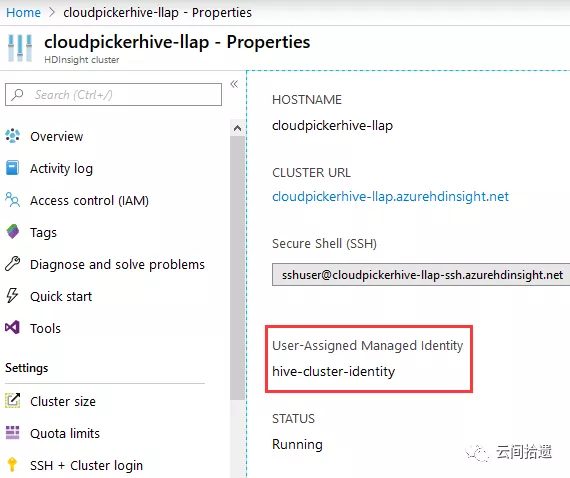
在共享數據湖datalakefs-shared方面無需和查詢集群發生直接關聯,只要把待讀取的路徑(zone-processed文件夾)向hive-cluster-identity開放讀取權限即可:

然後就可以在Hive集群上用SQL來進行數據湖查詢了:
--創建外部表指向數據湖中parquet數據 create external table WordsOnDataLake( word string, count int, word_length int ) STORED AS PARQUET LOCATION 'abfss://[email protected]/zone-processed/ATaleOfTwoCities.parq'; -- 立刻就能直接查詢數據湖上數據,例如按單詞長度分組聚合統計 select word_length, sum(count) as total_count from WordsOnDataLake group by word_length order by total_count desc limit 10;
最後順利地跑出了結果:
+--------------+--------------+--+ | word_length | total_count | +--------------+--------------+--+ | 3 | 31667 | | 4 | 24053 | | 2 | 22800 | | 5 | 15942 | | 6 | 12133 | | 7 | 9624 | | 8 | 6791 | | 9 | 4716 | | 1 | 4434 | | 0 | 4377 | +--------------+--------------+--+ 10 rows selected (4.295 seconds)
可以看到Hive LLAP順利地讀取了遠端數據湖的數據,而且速度頗為可觀,數秒內就返回了結果。如果關閉LLAP模式而採用傳統方式執行(將hive.llap.execution.mode設為none),筆者實驗下來同樣的查詢需要25秒左右才能完成。
在實際場景中,Hive LLAP集群可以始終保持在線,以便應對隨時到來的查詢請求;而負責ETL的Spark集群則可按需啟動,計算任務完成後關閉。這樣的設計既充分利用了共享數據湖的架構,也體現了雲端按需伸縮啟停的特點。
總結
數據湖是近年流行的架構思維,有助於提高數據服務能力的靈活性,也為企業跨領域統一大數據平台的構建提供了指導範式和落地支撐。
因此,公有雲巨頭們紛紛為數據湖構建提供及增強了對應的產品線,本系列文章聚焦的Azure Data Lakge Storege Gen2即是其中傑出代表。通過三篇文章的層層深入,我們既分析了產品功能,又結合應用場景進行了POC驗證。實踐證明,ADLS Gen2能夠成為構建企業級數據湖的堅實基礎和可靠保障。
最後,我們使用一張架構圖來作為全文的收束,它很好地總結了ADLS Gen2的能力、定位及與周邊系統的關係: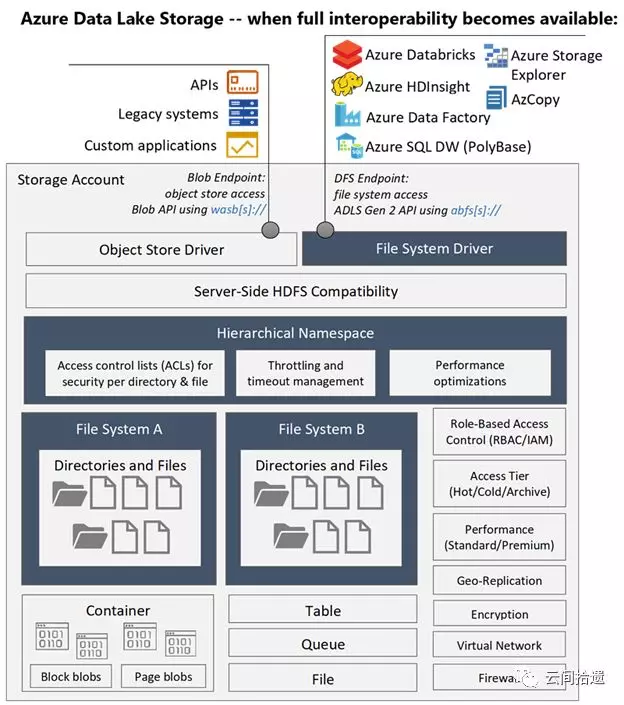
(圖片來自https://www.blue-granite.com/blog/10-things-to-know-about-azure-data-lake-storage-gen2)
從現在開始,就請考慮利用ADLS Gen2和相關配套雲服務,來構建你自己的數據湖吧!
相關文章:
構建企業級數據湖?Azure Data Lake Storage Gen2實戰體驗(上)
構建企業級數據湖?Azure Data Lake Storage Gen2實戰體驗(中)
“雲間拾遺”專註於從用戶視角介紹雲計算產品與技術,堅持以實操體驗為核心輸出內容,同時結合產品邏輯對應用場景進行深度解讀。歡迎掃描下方二維碼關注“雲間拾遺”微信公眾號。



