拓撲排序就這麼回事
- 2020 年 9 月 17 日
- 筆記
前言
大家好,這裡是《齊姐聊算法》系列之拓撲排序問題。
Topological sort 又稱 Topological order,這個名字有點迷惑性,因為拓撲排序並不是一個純粹的排序算法,它只是針對某一類圖,找到一個可以執行的線性順序。
這個算法聽起來高大上,如今的面試也很愛考,比如當時我在面我司時有整整一輪是基於拓撲排序的設計。
但它其實是一個很好理解的算法,跟着我的思路,讓你再也不會忘記她。
有向無環圖
剛剛我們提到,拓撲排序只是針對特定的一類圖,那麼是針對哪類圖的呢?
答:Directed acyclic graph (DAG),有向無環圖。即:
- 這個圖的邊必須是有方向的;
- 圖內無環。
那麼什麼是方向呢?
比如微信好友就是有向的,你加了他好友他可能把你刪了你卻不知道。。。那這個朋友關係就是單向的。。
什麼是環?環是和方向有關的,從一個點出發能回到自己,這是環。
所以下圖左邊不是環,右邊是。
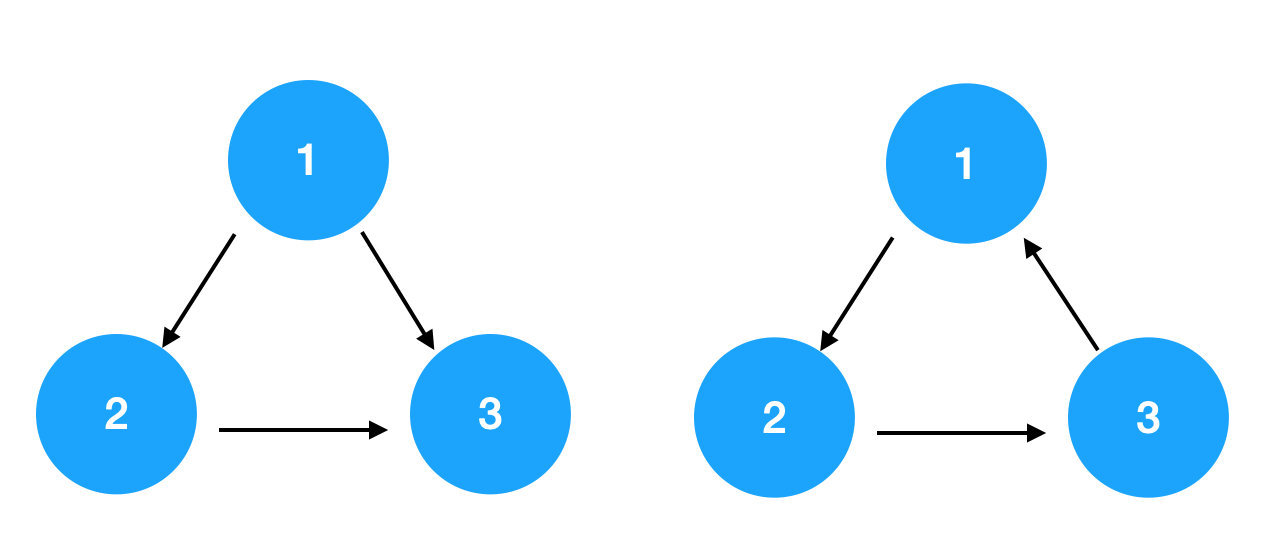
那麼如果一個圖裡有環,比如右圖,想執行 1 就要先執行 3,想執行 3 就要先執行 2,想執行 2 就要先執行 1,這成了個死循環,無法找到正確的打開方式,所以找不到它的一個拓撲序。
總結:
- 如果這個圖不是 DAG,那麼它是沒有拓撲序的;
- 如果是 DAG,那麼它至少有一個拓撲序;
- 反之,如果它存在一個拓撲序,那麼這個圖必定是 DGA.
所以這是一個充分必要條件。

拓撲排序
那麼這麼一個圖的「拓撲序」是什麼意思呢?
我們借用百度百科的這個課程表來說明。
| 課程代號 | 課程名稱 | 先修課程 |
|---|---|---|
| C1 | 高等數學 | 無 |
| C2 | 程序設計基礎 | 無 |
| C3 | 離散數學 | C1, C2 |
| C4 | 數據結構 | C3, C5 |
| C5 | 算法語言 | C2 |
| C6 | 編譯技術 | C4, C5 |
| C7 | 操作系統 | C4, C9 |
| C8 | 普通物理 | C1 |
| C9 | 計算機原理 | C8 |
這裡有 9 門課程,有些課程是有先修課程的要求的,就是你要先學了「最右側這一欄要求的這個課」才能再去選「高階」的課程。
那麼這個例子中拓撲排序的意思就是:
就是求解一種可行的順序,能夠讓我把所有課都學了。
那怎麼做呢?
首先我們可以用圖來描述它,
圖的兩個要素是頂點和邊,
那麼在這裡:
- 頂點:每門課
- 邊:起點的課程是終點的課程的先修課
畫出來長這個樣:
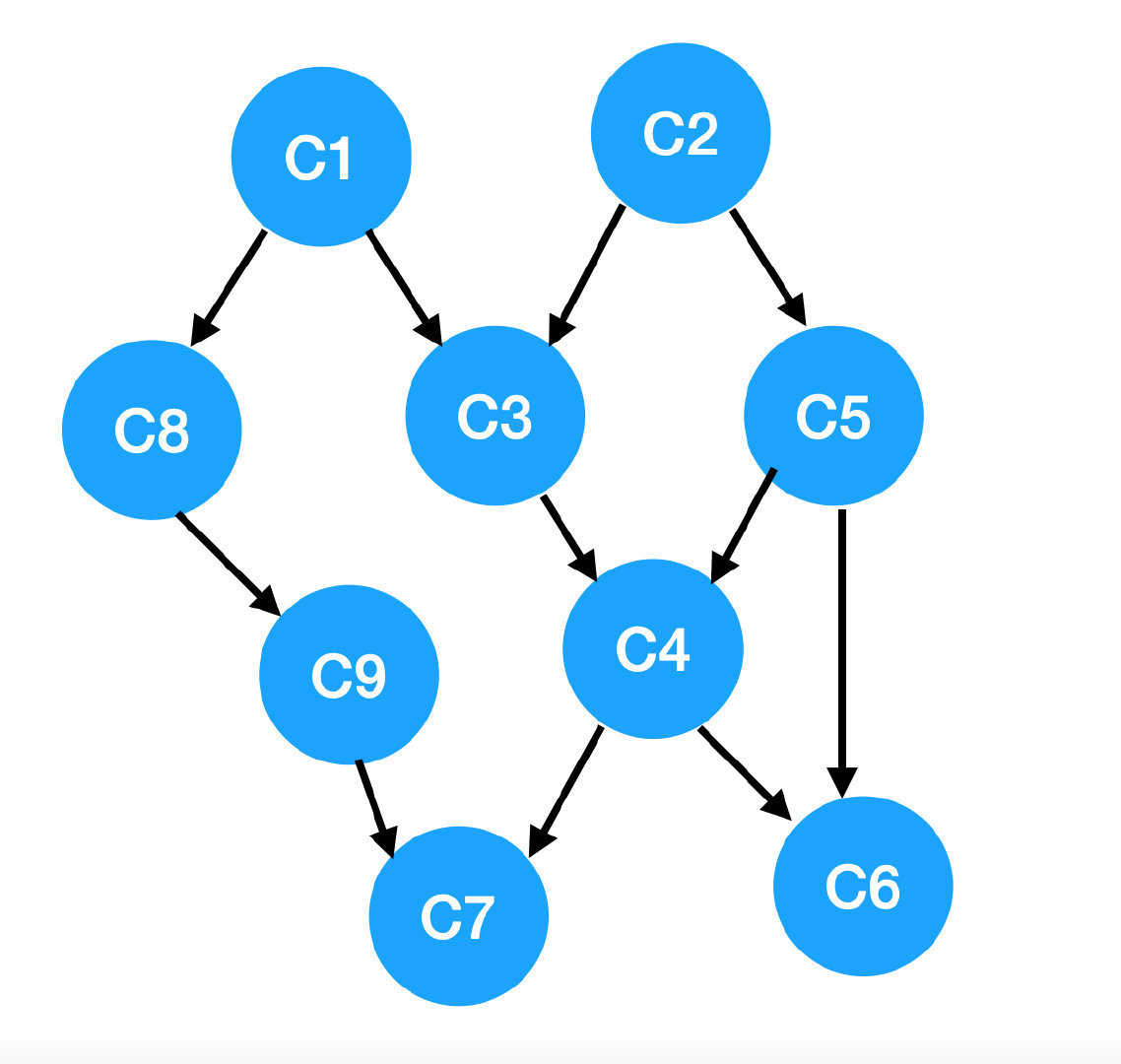
這種圖叫 AOV (Activity On Vertex) 網絡,在這種圖裡:
- 頂點:表示活動;
- 邊:表示活動間的先後關係
所以一個 AOV 網應該是一個 DAG,即有向無環圖,否則某些活動會無法進行。
那麼所有活動可以排成一個可行線性序列,這個序列就是拓撲序列。
那麼這個序列的實際意義是:
按照這個順序,在每個項目開始時,能夠保證它的前驅活動都已完成,從而使整個工程順利進行。
回到我們這個例子中:
-
我們一眼可以看出來要先學 C1, C2,因為這兩門課沒有任何要求嘛,大一的時候就學唄;
-
大二就可以學第二行的 C3, C5, C8 了,因為這三門課的先修課程就是 C1, C2,我們都學完了;
-
大三可以學第三行的 C4, C9;
-
最後一年選剩下的 C6, C7。
這樣,我們就把所有課程學完了,也就得到了這個圖的一個拓撲排序。
注意,有時候拓撲序並不是唯一的,比如在這個例子中,先學 C1 再學 C2,和先 C2 後 C1 都行,都是這個圖的正確的拓撲序,但這是兩個順序了。
所以面試的時候要問下面試官,是要求解任意解,還是列出所有解。
我們總結一下,
在這個圖裡的邊表示的是一種依賴關係,如果要修下一門課,就要先把前一門課修了。
這和打游戲裏一樣一樣的嘛,要拿到一個道具,就要先做 A 任務,再完成 B 任務,最終終於能到達目的地了。
算法詳解
在上面的圖裡,大家很容易就看出來了它的拓撲序,但當工程越來越龐大時,依賴關係也會變得錯綜複雜,那就需要用一種系統性的方式方法來求解了。
那麼我們回想一下剛剛自己找拓撲序的過程,為什麼我們先看上了 C1, C2?
因為它們沒有依賴別人啊,
也就是它的入度為 0.
入度:頂點的入度是指「指向該頂點的邊」的數量;
出度:頂點的出度是指該頂點指向其他點的邊的數量。
所以我們先執行入度為 0 的那些點,
那也就是要記錄每個頂點的入度。
因為只有當它的 入度 = 0 的時候,我們才能執行它。
在剛才的例子里,最開始 C1, C2 的入度就是 0,所以我們可以先執行這兩個。
那在這個算法里第一步就是得到每個頂點的入度。
Step0: 預處理得到每個點的入度
我們可以用一個 HashMap 來存放這個信息,或者用一個數組會更精巧。
在文中為了方便展示,我就用表格了:
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| 入度 | 0 | 0 | 2 | 2 | 1 | 2 | 2 | 1 | 1 |
Step1
拿到了這個之後,就可以執行入度為 0 的這些點了,也就是 C1, C2.
那我們把可以被執行的這些點,放入一個待執行的容器里,這樣之後我們一個個的從這個容器里取頂點就好了。
至於這個容器究竟選哪種數據結構,這取決於我們需要做哪些操作,再看哪種數據結構可以為之服務。
那麼首先可以把[C1, C2]放入容器中,
然後想想我們需要哪些操作吧!
我們最常做的操作無非就是把點放進來,把點拿出去執行了,也就是需要一個 offer 和 poll 操作比較高效的數據結構,那麼 queue 就夠用了。
(其他的也行,放進來這個容器里的頂點的地位都是一樣的,都是可以執行的,和進來的順序無關,但何必非得給自己找麻煩呢?一個常規順序的簡簡單單的 queue 就夠用了。)
然後就需要把某些點拿出去執行了。
【劃重點】當我們把 C1 拿出來執行,那這意味這什麼?
答:意味着「以 C1 為頂點」的「指向其他點」的「邊」都消失了,也就是 C1 的出度變成了 0.
如下圖,也就是這兩條邊可以消失了。
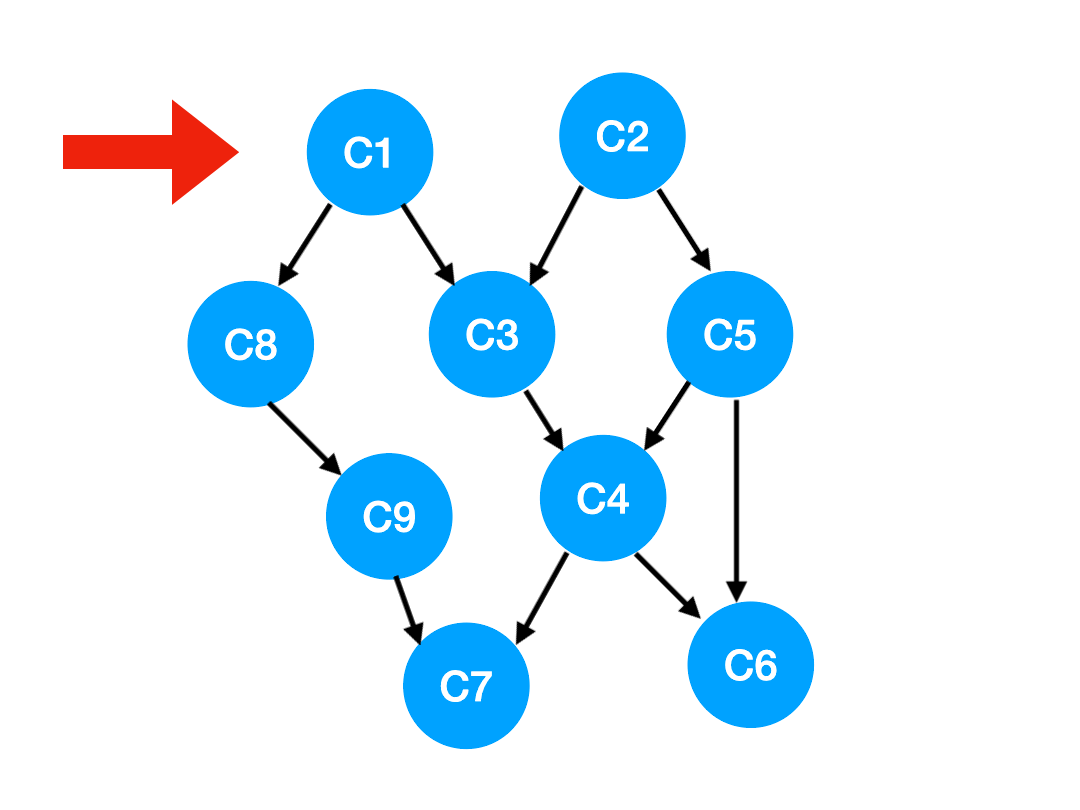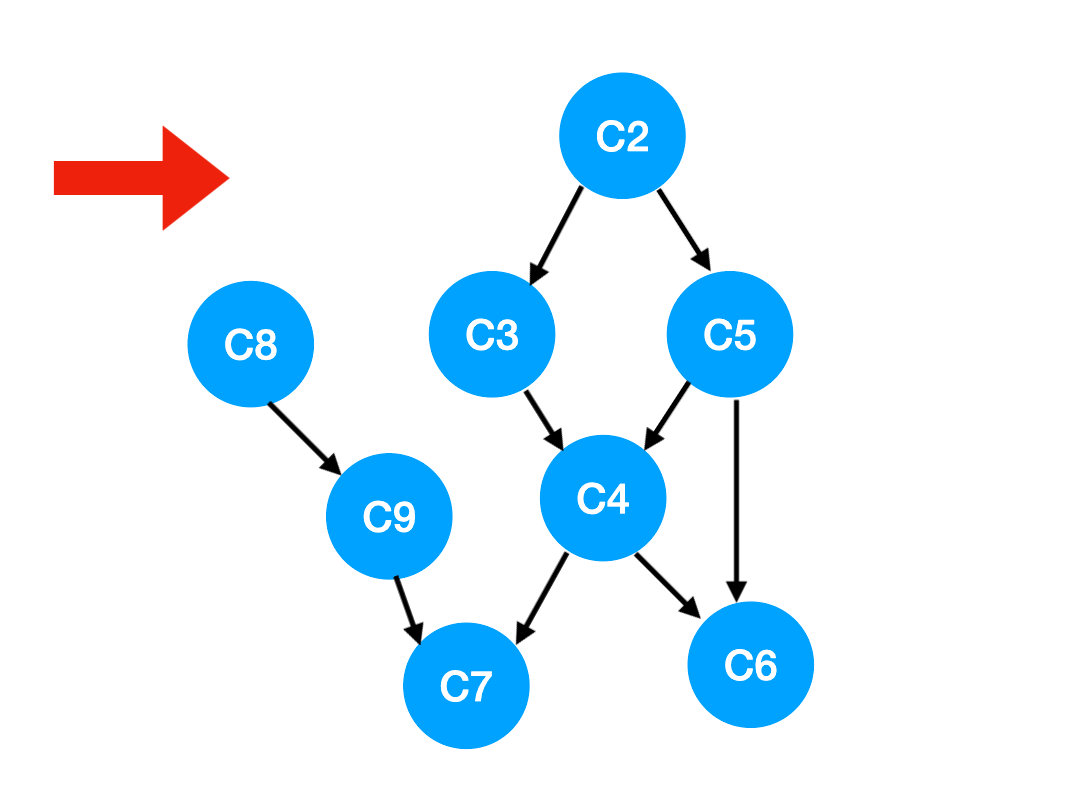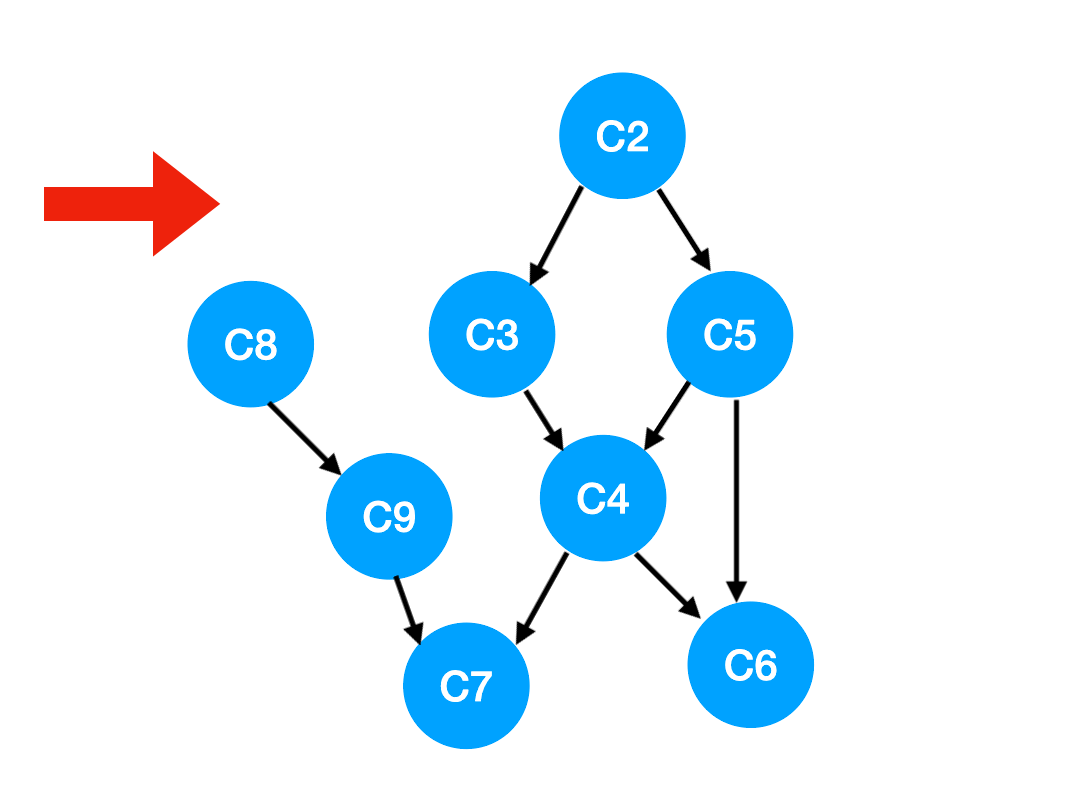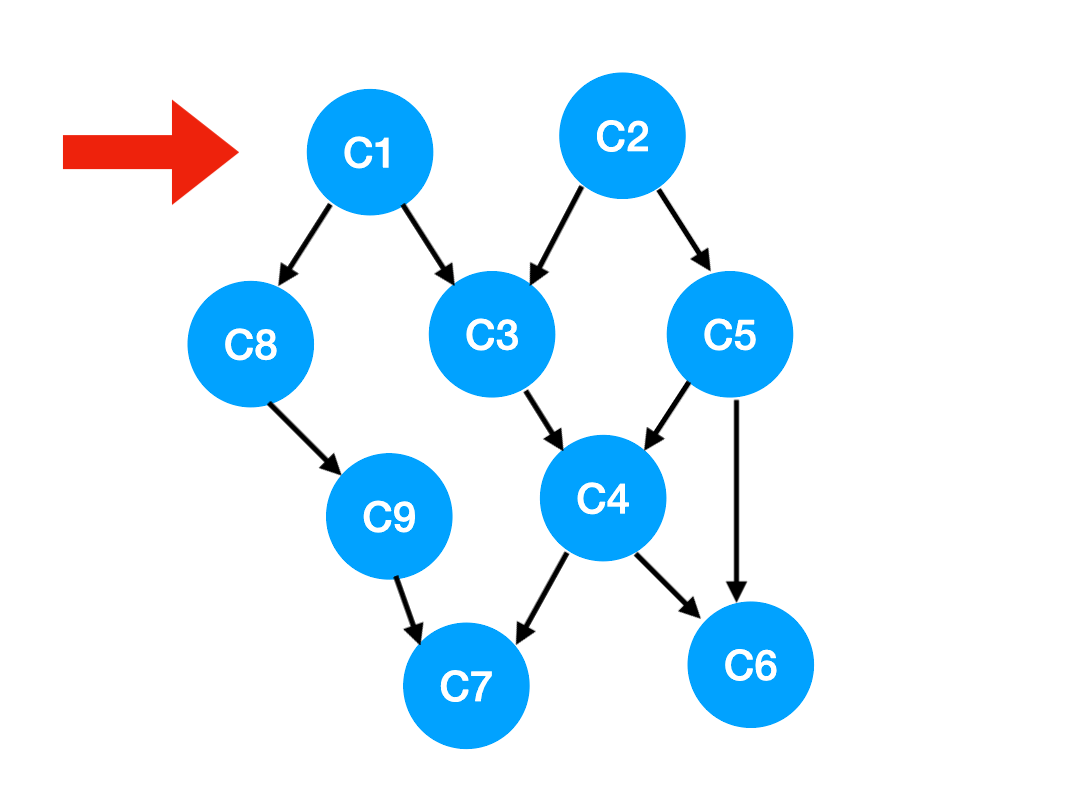
那麼此時我們就可以更新 C1 所指向的那些點也就是 C3 和 C8 的 入度 了,更新後的數組如下:
| C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|
| 入度 | 1 | 2 | 1 | 2 | 2 | 0 | 1 |
那我們這裡看到很關鍵的一步,C8 的入度變成了 0!
也就意味着 C8 此時沒有了任何依賴,可以放到我們的 queue 里等待執行了。
此時我們的 queue 里就是:[C2, C8].
Step2
下一個我們再執行 C2,
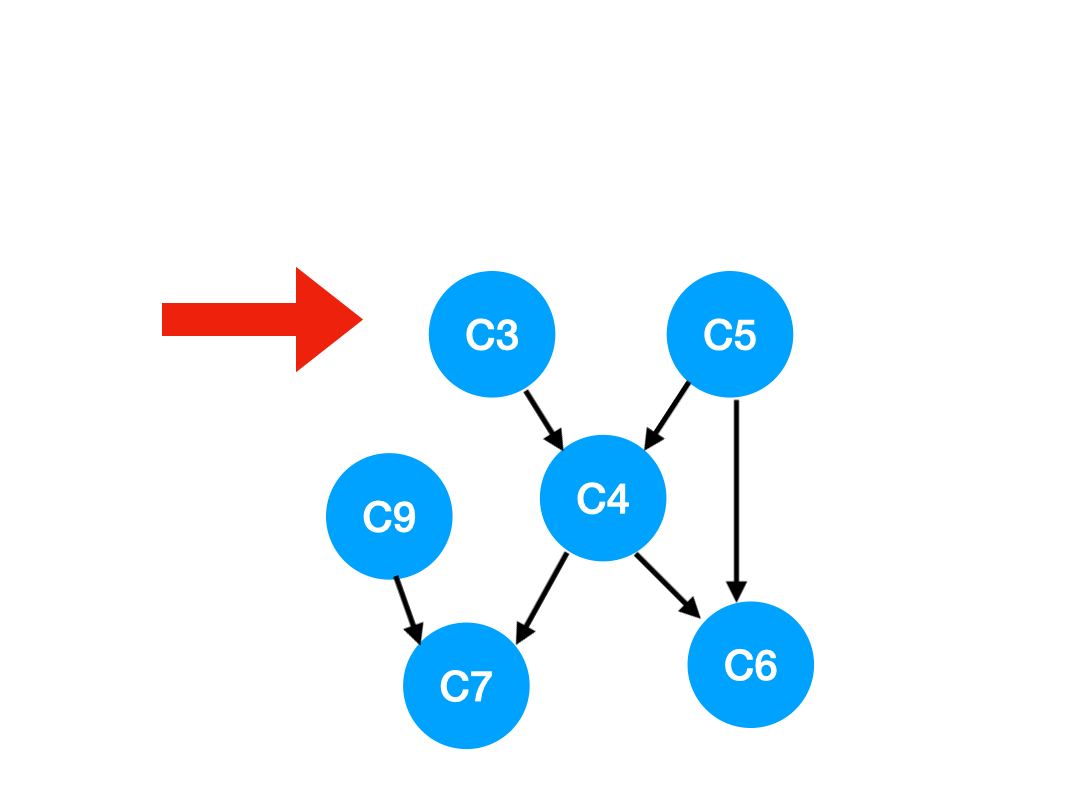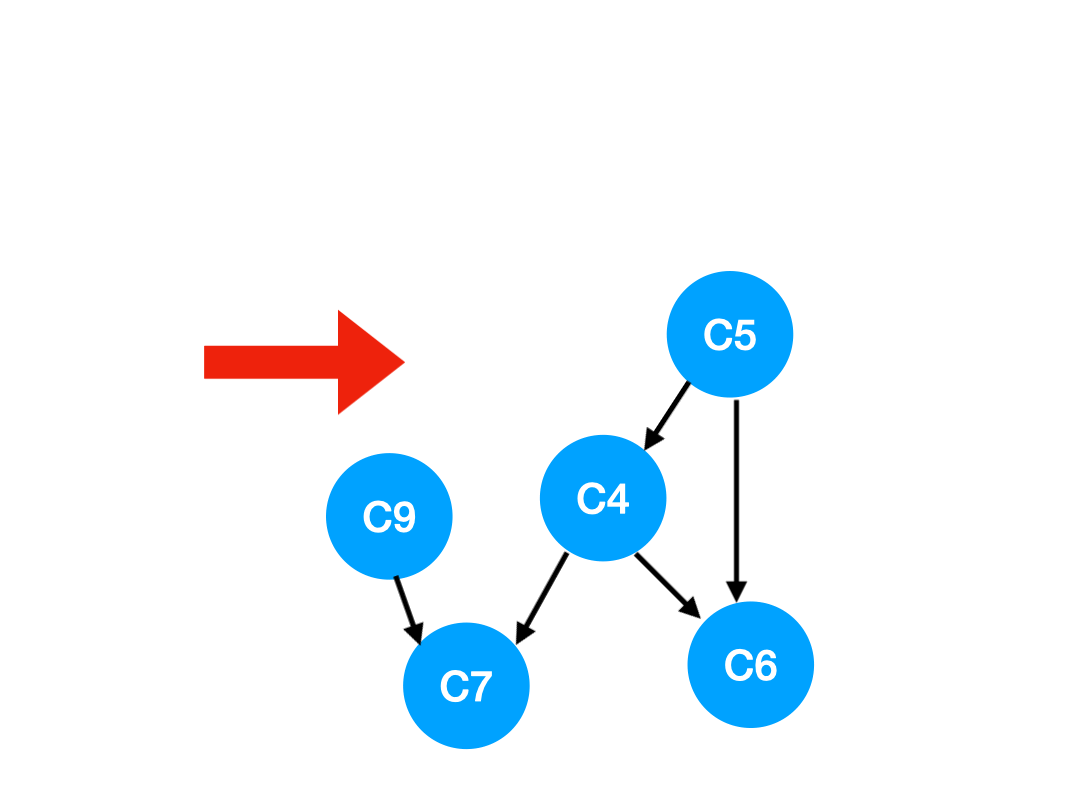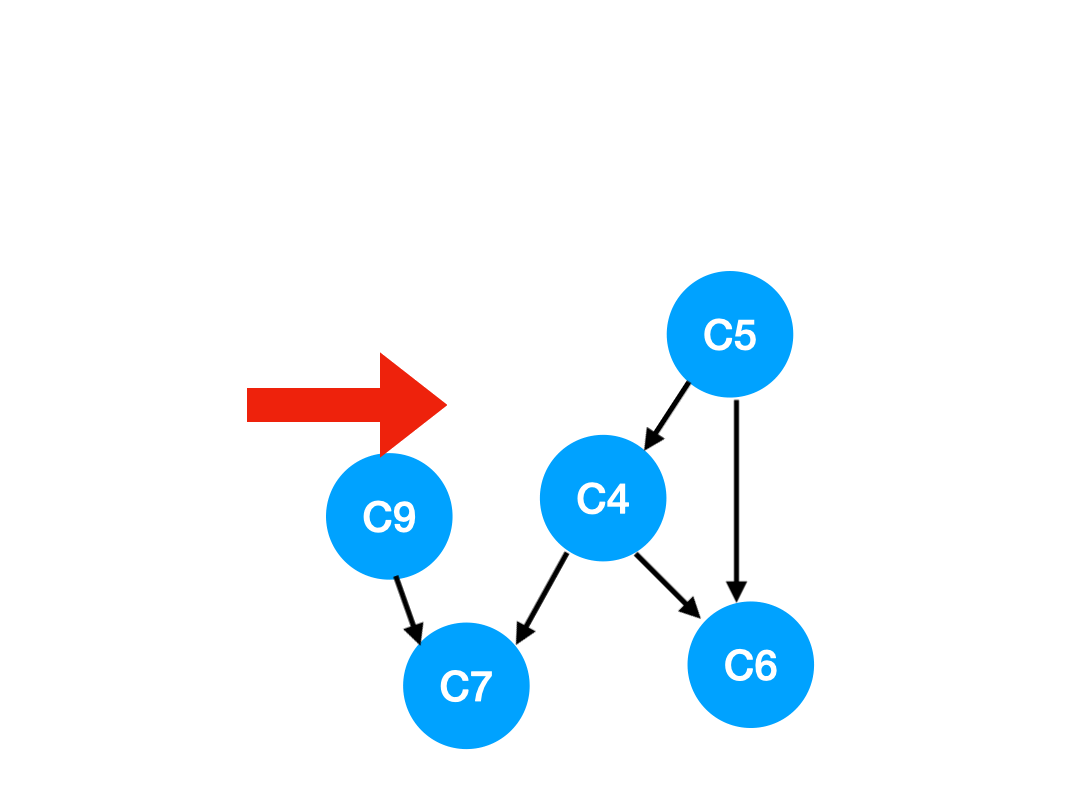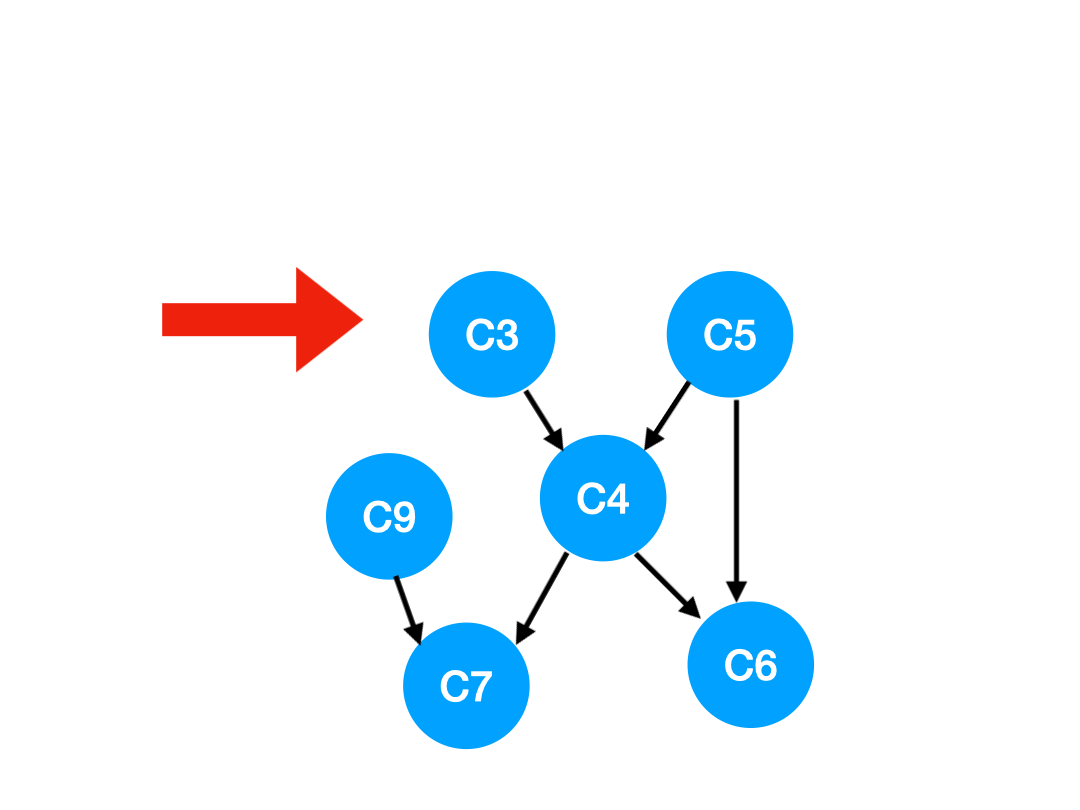
那麼 C2 所指向的 C3, C5 的 入度-1,
更新表格:
| C3 | C4 | C5 | C6 | C7 | C9 | |
|---|---|---|---|---|---|---|
| 入度 | 0 | 2 | 0 | 2 | 2 | 1 |
也就是 C3 和 C5 都沒有了任何束縛,可以放進 queue 里執行了。
queue 此時變成:[C8, C3, C5]
Step3
那麼下一步我們執行 C8,
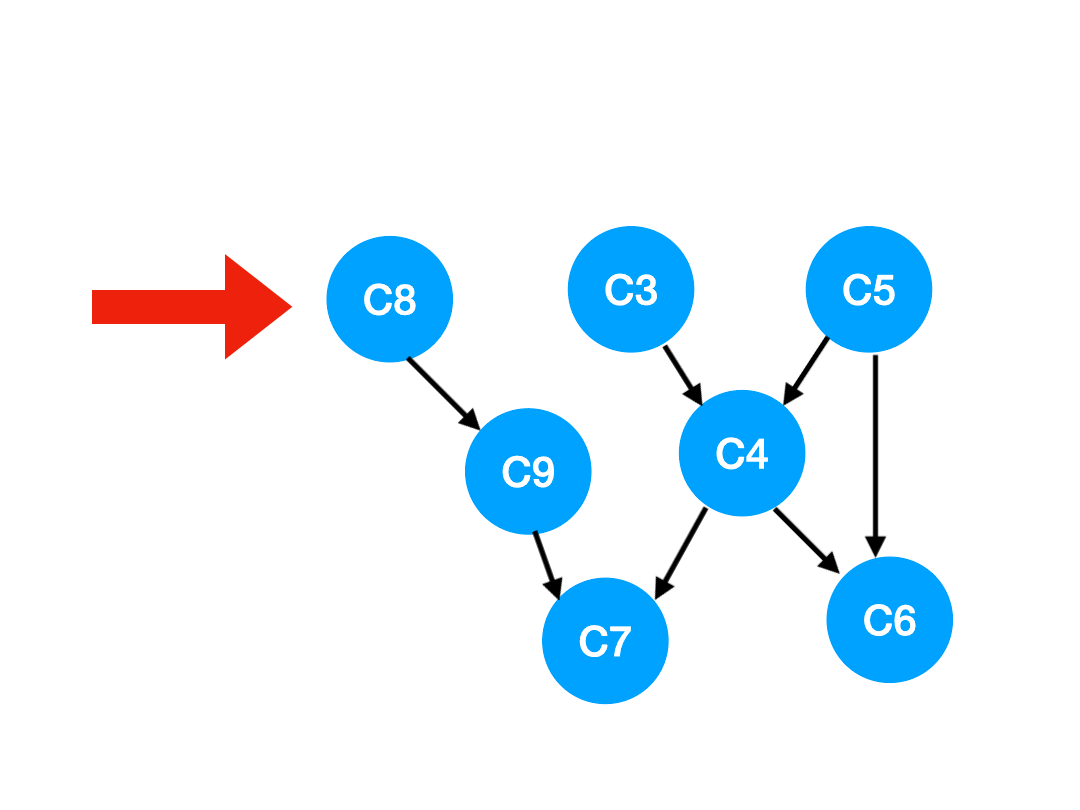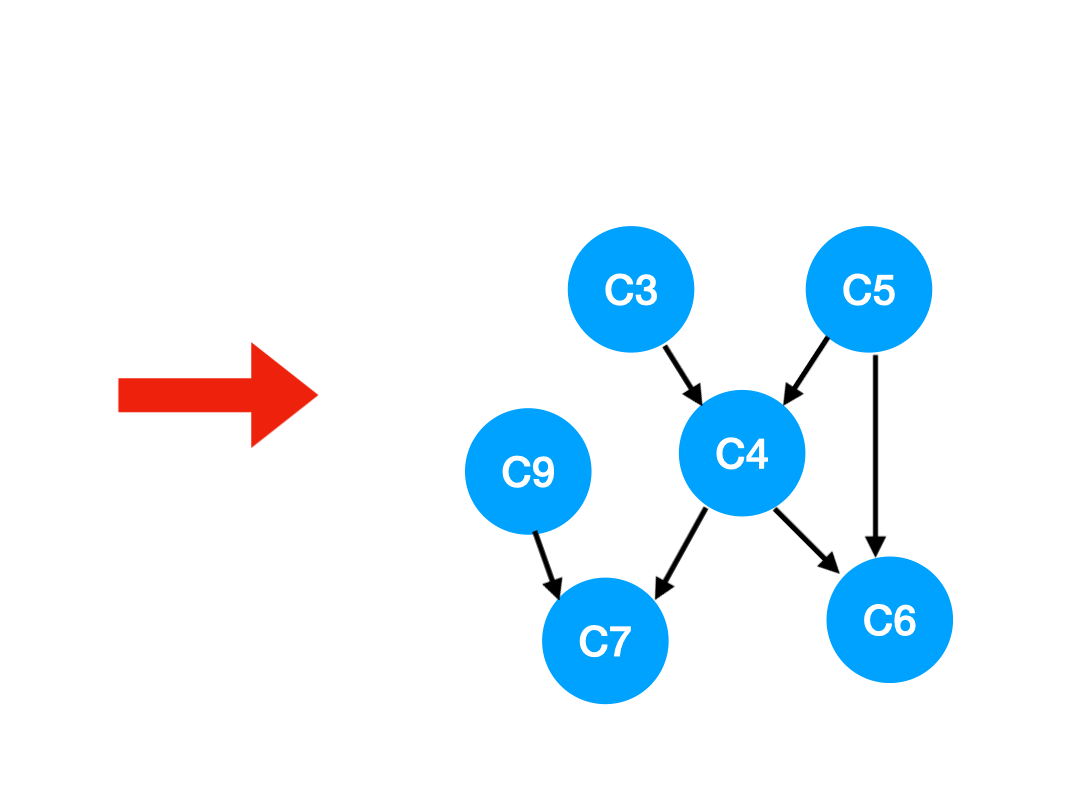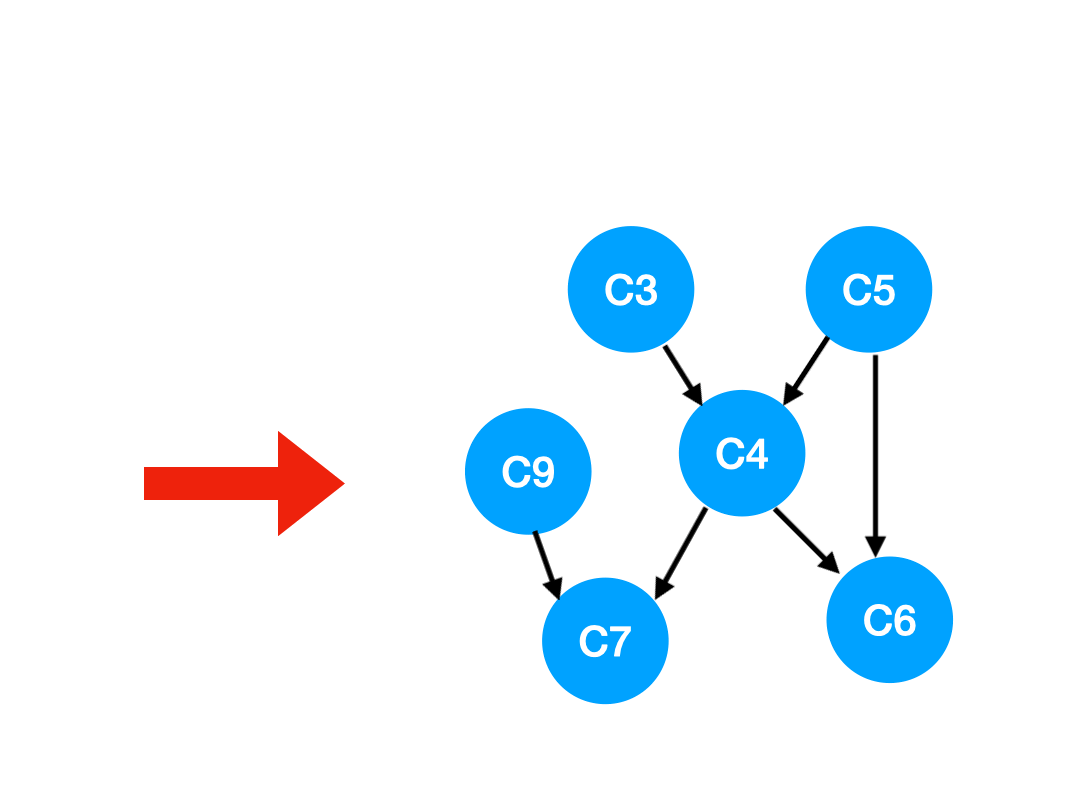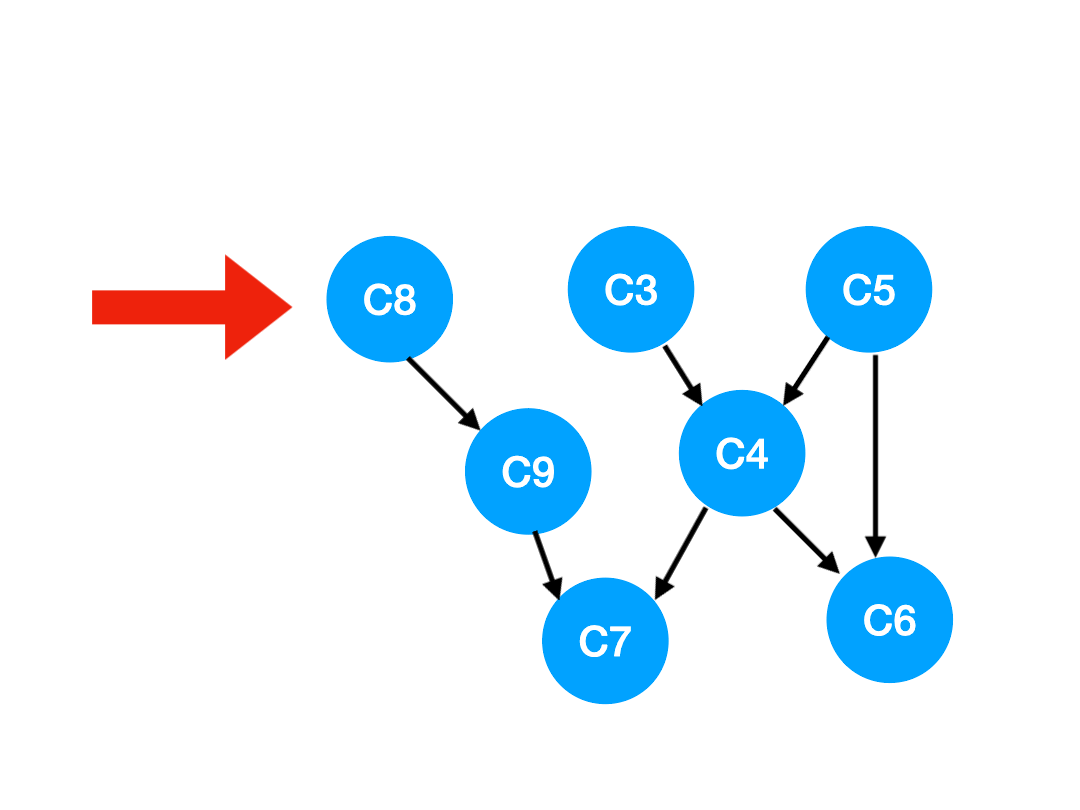
相應的 C8 所指的 C9 的入度-1.
更新表格:
| C4 | C6 | C7 | C9 | |
|---|---|---|---|---|
| 入度 | 2 | 2 | 2 | 0 |
那麼 C9 沒有了任何要求,可以放進 queue 里執行了。
queue 此時變成:[C3, C5, C9]
Step4
接下來執行 C3,
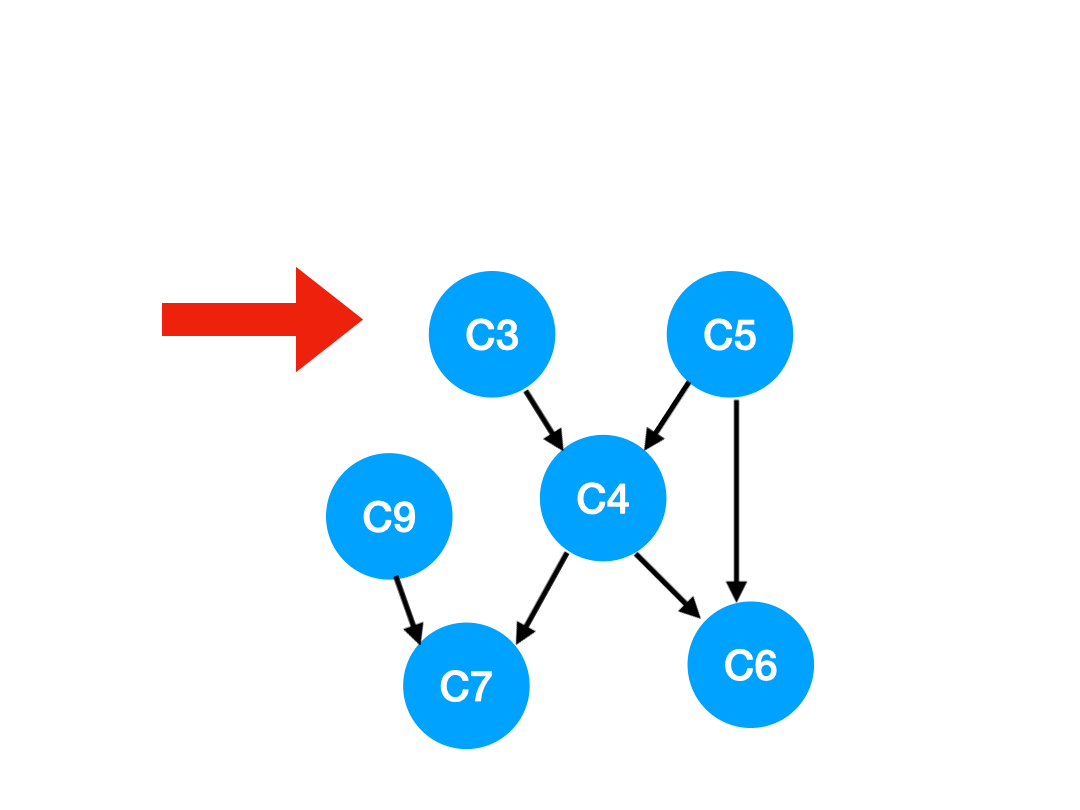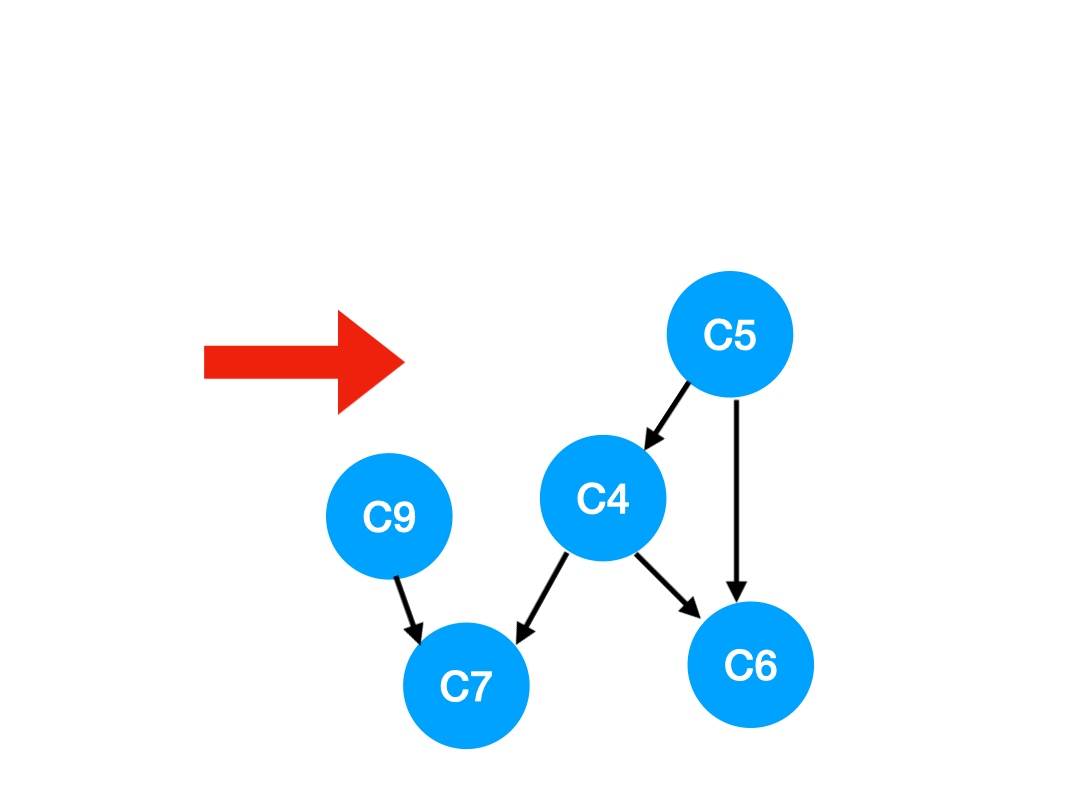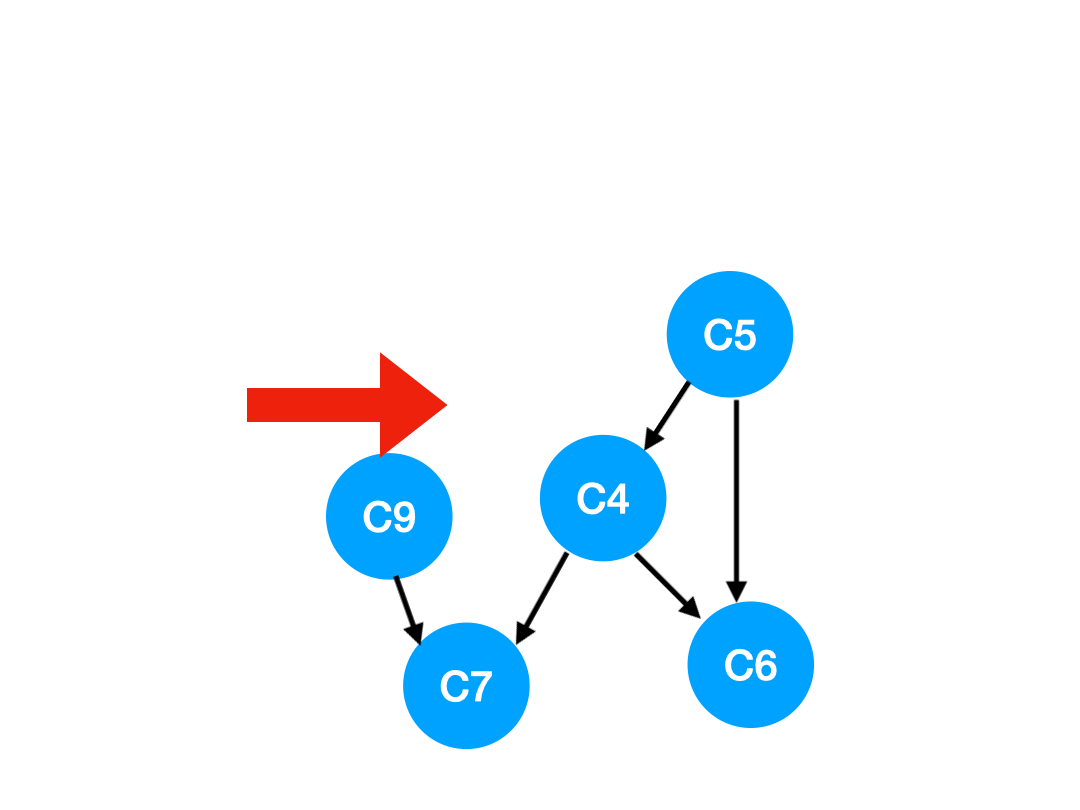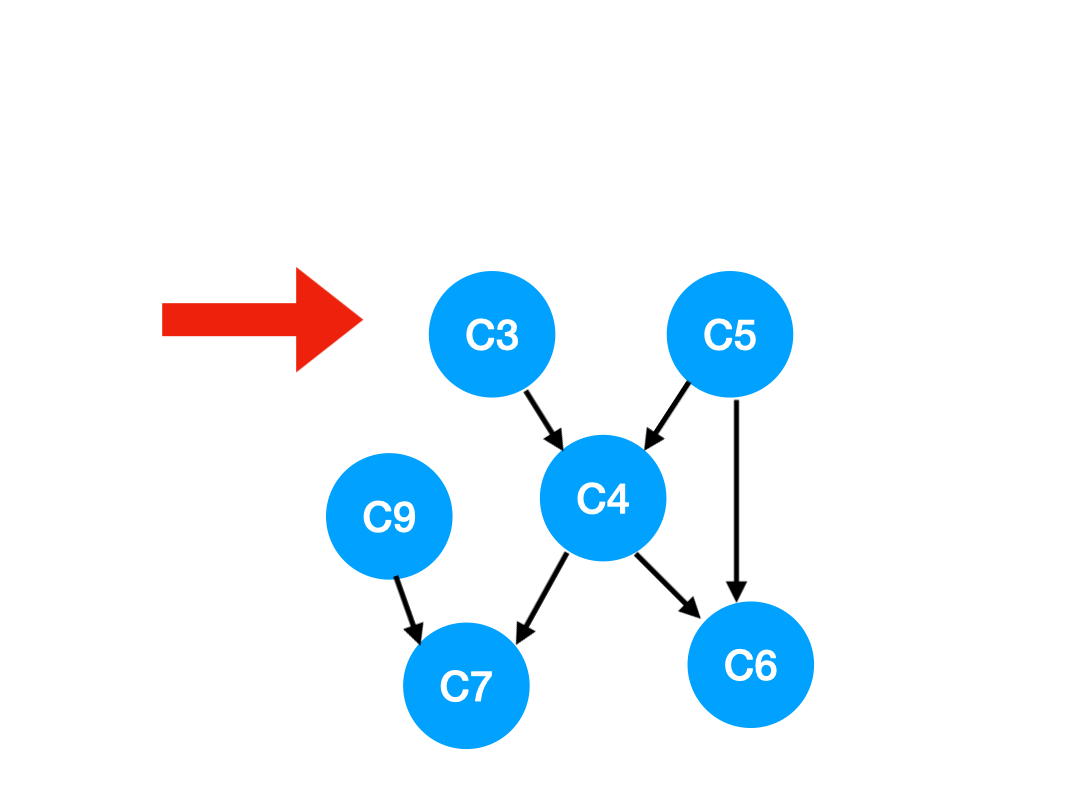
相應的 C3 所指的 C4 的入度-1.
更新表格:
| C4 | C6 | C7 | |
|---|---|---|---|
| 入度 | 1 | 2 | 2 |
但是 C4 的入度並沒有變成 0,所以這一步沒有任何點可以加入 queue.
queue 此時變成 [C5, C9]
Step5
再執行 C5,
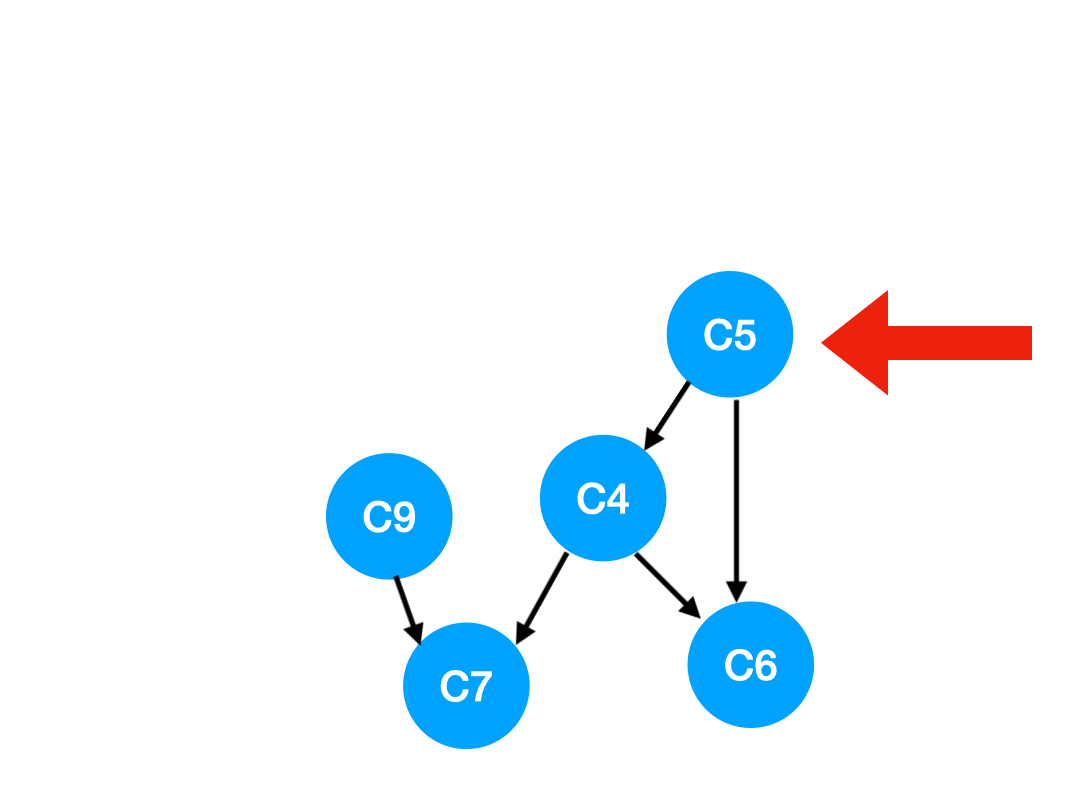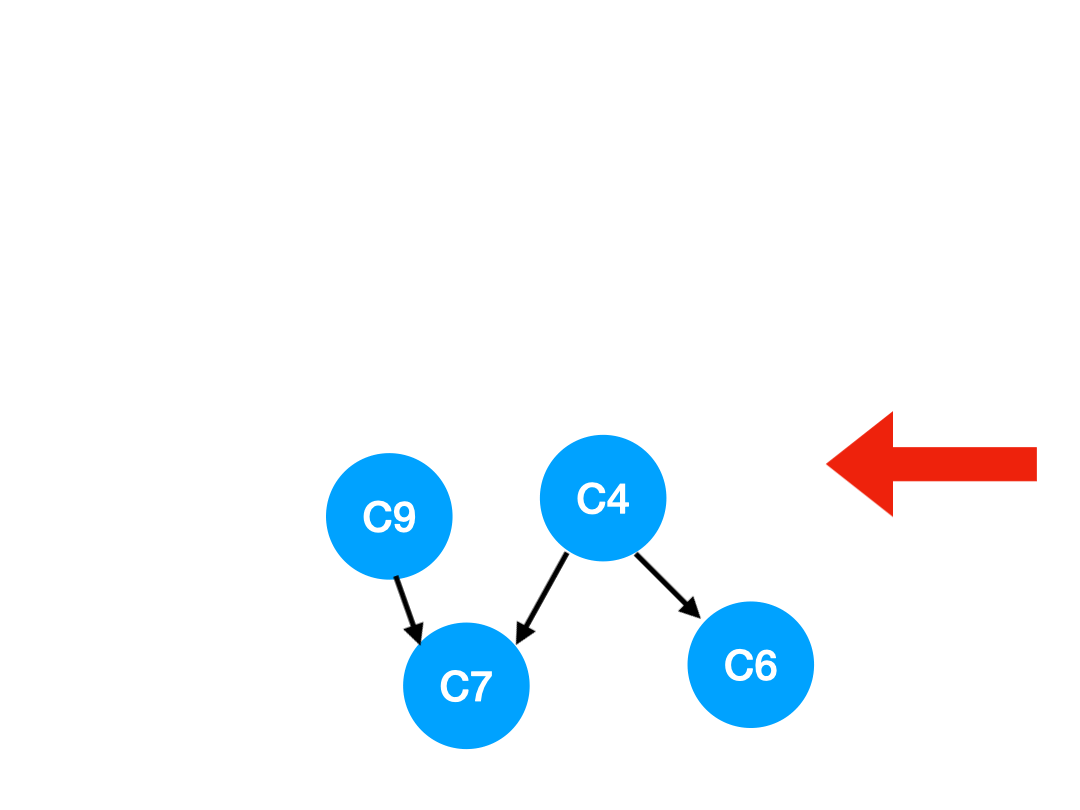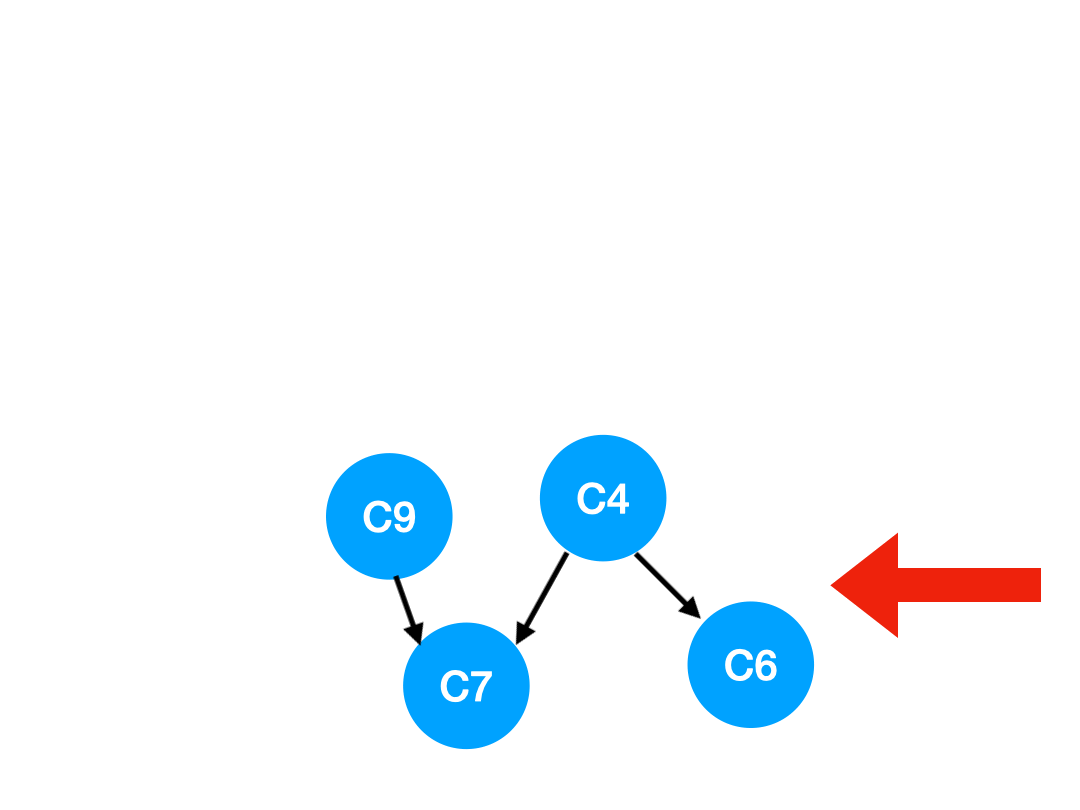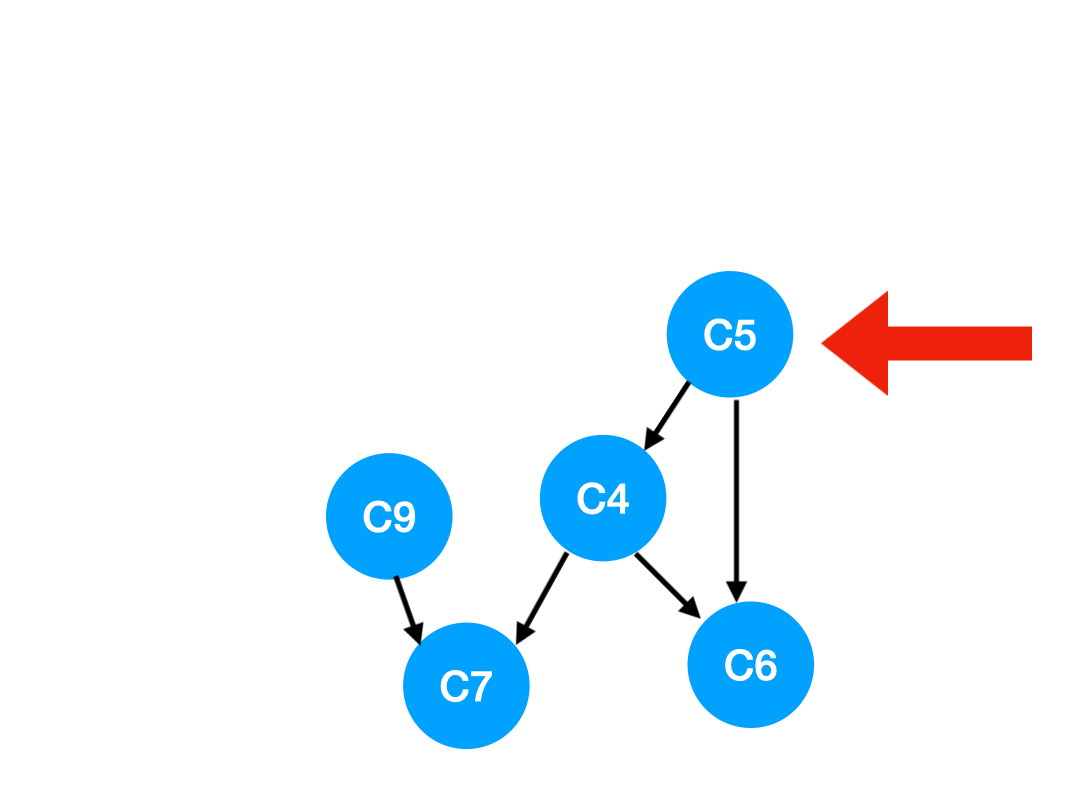
那麼 C5 所指的 C4 和 C6 的入度- 1.
更新表格:
| C4 | C6 | C7 | |
|---|---|---|---|
| 入度 | 0 | 1 | 2 |
這裡 C4 的依賴全都消失啦,那麼可以把 C4 放進 queue 里了:
queue = [C9, C4]
Step6
然後執行 C9,
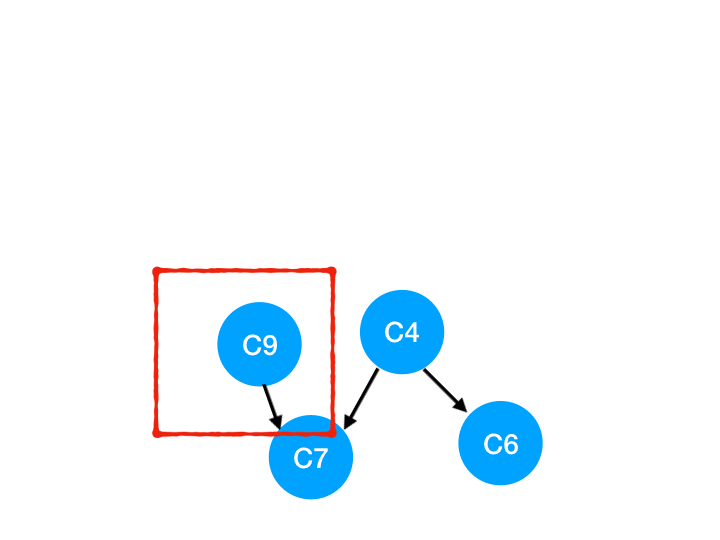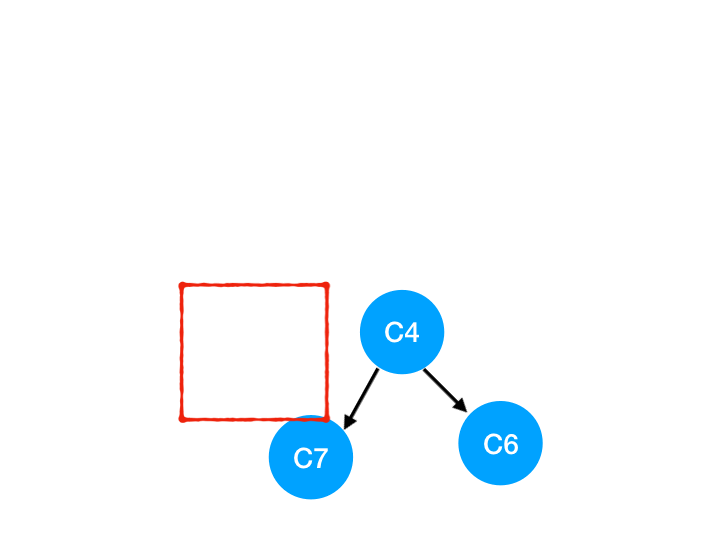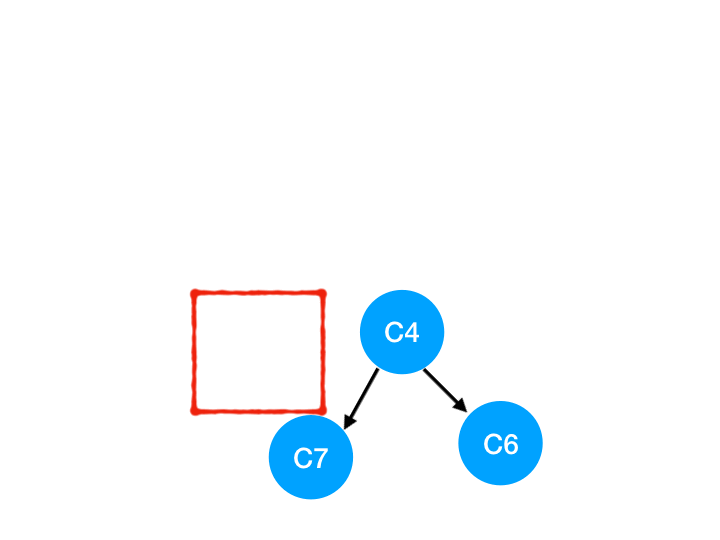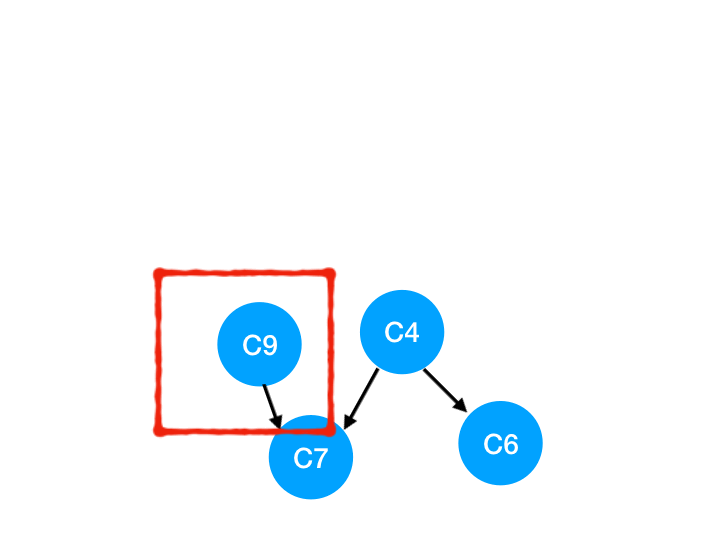
那麼 C9 所指的 C7 的入度- 1.
| C6 | C7 | |
|---|---|---|
| 入度 | 1 | 1 |
這裡 C7 的入度並不為 0,還不能加入 queue,
此時 queue = [C4]
Step7
接着執行 C4,
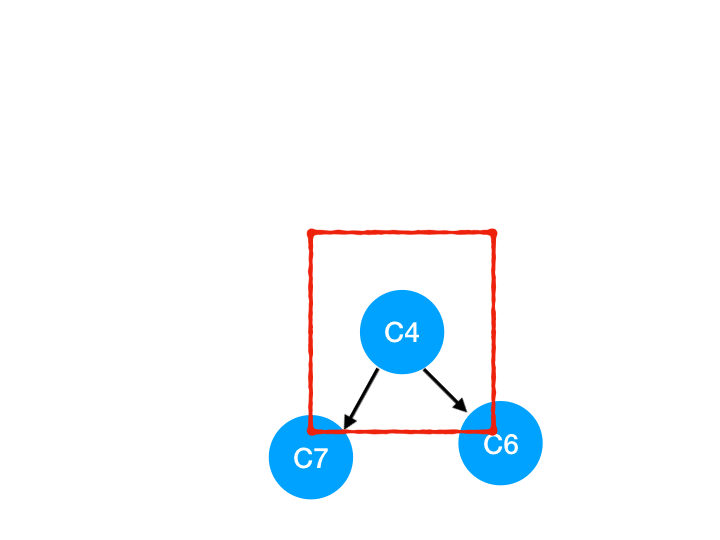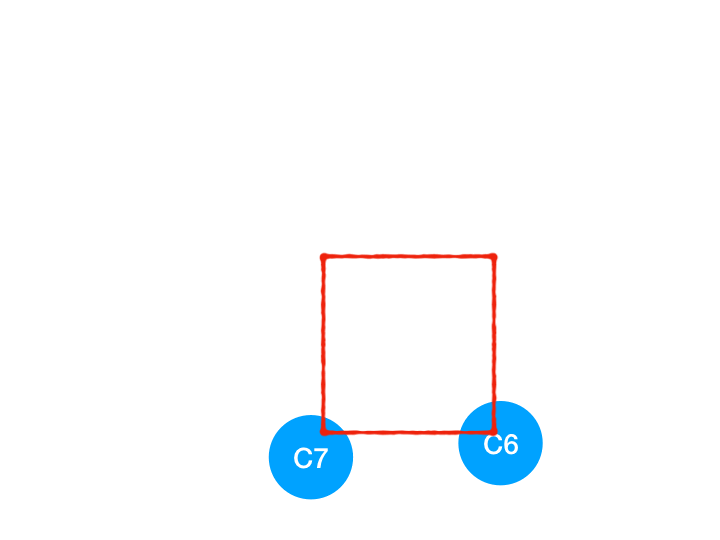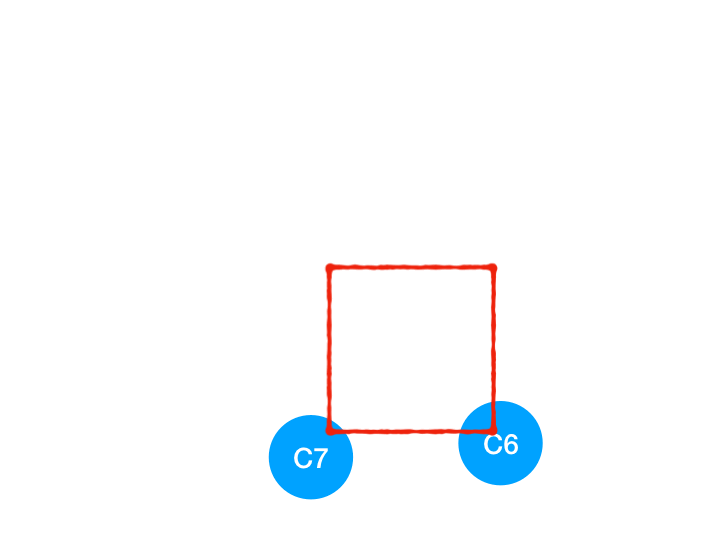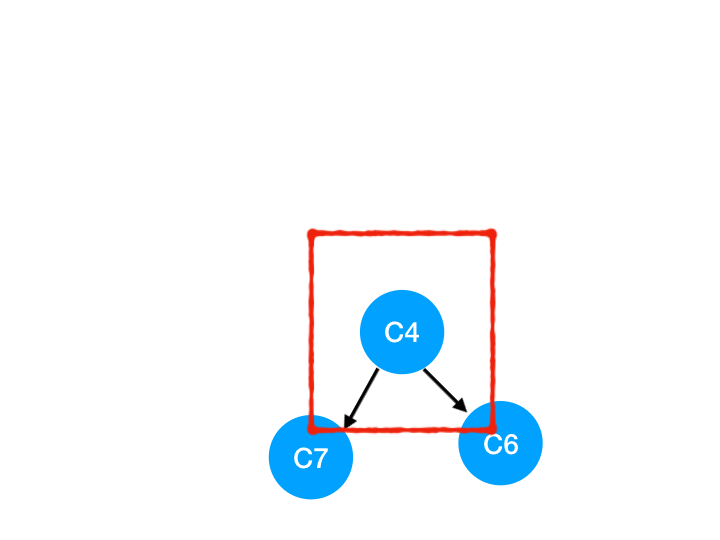
所以 C4 所指向的 C6 和 C7 的入度-1,
更新表格:
| C6 | C7 | |
|---|---|---|
| 入度 | 0 | 0 |
C6 和 C7 的入度都變成 0 啦!!把它們放入 queue,繼續執行到直到 queue 為空即可。
總結
好了,那我們梳理一下這個算法:
數據結構
這裡我們的入度表格可以用 map 來存放,關於 map 還有不清楚的同學可以看之前我寫的 HashMap 的文章哦~
Map: <key = Vertex, value = 入度>
但實際代碼中,我們用一個 int array 來存儲也就夠了,graph node 可以用數組的 index 來表示,value 就用數組裡的數值來表示,這樣比 Map 更精巧。
然後用了一個普通的 queue,用來存放可以被執行的那些 node.
過程
我們把入度為 0 的那些頂點放入 queue 中,然後通過每次執行 queue 中的頂點,就可以讓依賴這個被執行的頂點的那些點的 入度-1,如果有頂點的入度變成了 0,就可以放入 queue 了,直到 queue 為空。
細節
這裡有幾點實現上的細節:
當我們 check 是否有新的頂點的 入度 == 0 時,沒必要過一遍整個 map 或者數組,只需要 check 剛剛改動過的就好了。
另一個是如果題目沒有給這個圖是 DAG 的條件的話,那麼有可能是不存在可行解的,那怎麼判斷呢?很簡單的一個方法就是比較一下最後結果中的頂點的個數和圖中所有頂點的個數是否相等,或者加個計數器,如果不相等,說明就不存在有效解。所以這個算法也可以用來判斷一個圖是不是有向無環圖。
很多題目給的條件可能是給這個圖的 edge list,也是表示圖的一種常用的方式。那麼給的這個 list 就是表示圖中的邊。這裡要注意審題哦,看清楚是誰 depends on 誰。其實圖的題一般都不會直接給你這個圖,而是給一個場景,需要你把它變回一個圖。
時間複雜度
注意 ⚠️:對於圖的時間複雜度分析一定是兩個參數,面試的時候很多同學張口就是 O(n)…
對於有 v 個頂點和 e 條邊的圖來說,
第一步,預處理得到 map 或者 array,需要過一遍所有的邊才行,所以是 O(e);
第二步,把 入度 == 0 的點入隊出隊的操作是 O(v),如果是一個 DAG,那所有的點都需要入隊出隊一次;
第三步,每次執行一個頂點的時候,要把它指向的那條邊消除了,這個總共執行 e 次;
總:O(v + e)
空間複雜度
用了一個數組來存所有點的 indegree,之後的 queue 也是最多把所有的點放進去,所以是 O(v).
代碼
關於這課程排序的問題,Leetcode 上有兩道題,一道是 207,問你能否完成所有課程,也就是問拓撲排序是否存在;另一道是 210 題,是讓你返回任意一個拓撲順序,如果不能完成,那就返回一個空 array。
這裡我們以 210 這道題來寫,更完整也更常考一些。
這裡給的 input 就是我們剛剛說到的 edge list.
Example 1.
Input: 2, [[1,0]]
Output: [0,1]
Explanation: 這裡一共 2 門課,1 的先修課程是 0. 所以正確的選課順序是[0, 1].
Example 2.
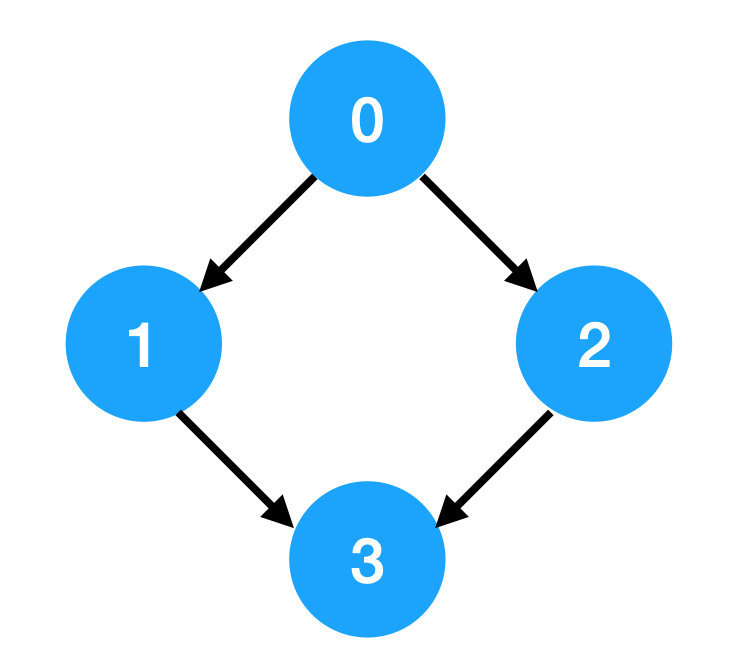
Input: 4, [[1,0],[2,0],[3,1],[3,2]]
Output: [0,1,2,3] or [0,2,1,3]
Explanation:這裡這個例子畫出來如下圖
Example 3.
Input: 2, [[1,0],[0,1]]
Output: null
Explanation: 這課沒法上了
class Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
int[] res = new int[numCourses];
int[] indegree = new int[numCourses];
// get the indegree for each course
for(int[] pre : prerequisites) {
indegree[pre[0]] ++;
}
// put courses with indegree == 0 to queue
Queue<Integer> queue = new ArrayDeque<>();
for(int i = 0; i < numCourses; i++) {
if(indegree[i] == 0) {
queue.offer(i);
}
}
// execute the course
int i = 0;
while(!queue.isEmpty()) {
Integer curr = queue.poll();
res[i++] = curr;
// remove the pre = curr
for(int[] pre : prerequisites) {
if(pre[1] == curr) {
indegree[pre[0]] --;
if(indegree[pre[0]] == 0) {
queue.offer(pre[0]);
}
}
}
}
return i == numCourses ? res : new int[]{};
}
}
另外,拓撲排序還可以用 DFS - 深度優先搜索 來實現,限於篇幅就不在這裡展開了,大家可以參考GeeksforGeeks的這個資料。
實際應用
我們上文已經提到了它的一個 use case,就是選課系統,這也是最常考的題目。
而拓撲排序最重要的應用就是關鍵路徑問題,這個問題對應的是 AOE (Activity on Edge) 網絡。
AOE 網絡:頂點表示事件,邊表示活動,邊上的權重來表示活動所需要的時間。
AOV 網絡:頂點表示活動,邊表示活動之間的依賴關係。
在 AOE 網中,從起點到終點具有最大長度的路徑稱為關鍵路徑,在關鍵路徑上的活動稱為關鍵活動。AOE 網絡一般用來分析一個大項目的工序,分析至少需要花多少時間完成,以及每個活動能有多少機動時間。
具體是怎麼應用分析的,大家可以參考這個視頻 的 14 分 46 秒,這個例子還是講的很好的。
其實對於任何一個任務之間有依賴關係的圖,都是適用的。
比如 pom 依賴引入 jar 包時,大家有沒有想過它是怎麼導進來一些你並沒有直接引入的 jar 包的?比如你並沒有引入 aop 的 jar 包,但它自動出現了,這就是因為你導入的一些包是依賴於 aop 這個 jar 包的,那麼 maven 就自動幫你導入了。
其他的實際應用,比如說:
- 語音識別系統的預處理;
- 管理目標文件之間的依賴關係,就像我剛剛說的 jar 包導入;
- 深度學習中的網絡結構處理。
如有其他補充,歡迎大家在評論區不吝賜教。
以上就是本文的全部內容了,拓撲排序是非常重要也是非常愛考的一類算法,面試大廠前一定要熟練掌握。
如果你喜歡這篇文章,記得給我點贊留言哦~你們的支持和認可,就是我創作的最大動力,我們下篇文章見!
我是小齊,紐約程序媛,終生學習者,每天晚上 9 點,雲自習室里不見不散!
更多乾貨文章見我的 Github: //github.com/xiaoqi6666/NYCSDE


