關於數據存儲引擎結構,沒有比這篇更詳細的
摘要:常見存儲算法結構涵蓋:哈希存儲,B 、B+、B*樹存儲,LSM樹存儲引擎,R樹,倒排索引,矩陣存儲,對象與塊,圖結構存儲等等。
介紹
在存儲系統的設計中,存儲引擎屬於底層數據結構,直接決定了存儲系統所能夠提供的性能和功能。常見存儲算法結構涵蓋:哈希存儲,B 、B+、B*樹存儲,LSM樹存儲引擎,R樹,倒排索引,矩陣存儲,對象與塊,圖結構存儲等等。
哈希存儲引擎是哈希表的持久化實現,一般用於鍵值類型的存儲系統。而大多傳統關係型數據庫使用索引來輔助查找數據,用以加速對數據庫數據的訪問。考慮到經常需要範圍查找,因此其索引一般使用樹型結構。譬如MySQL、SQL Server、Oracle中,數據存儲與索引的基本結構是B-樹和B+樹。
主流的NoSQL數據庫則使用日誌結構合併樹(Log-structured Merge Tree)來組織數據。LSM 樹存儲引擎和B樹一樣,支持增、刪、改、隨機讀取以及順序掃描。通過批量轉儲技術規避磁盤隨機寫入問題,極大地改善了磁盤的IO性能,被廣泛應用於後台存儲系統,如Google Big table、Level DB,Facebook Cassandra系統,開源的HBase,Rocks dB等等。
……
一.哈希存儲
哈希存儲的基本思想是以關鍵字Key為自變量,通過一定的函數關係(散列函數或哈希函數),計算出對應函數值(哈希地址),以這個值作為數據元素的地址,並將數據元素存入到相應地址的存儲單元中。查找時再根據要查找的關鍵字採用同樣的函數計算出哈希地址,然後直接到相應的存儲單元中去取要找的數據元素。代表性的使用方包括Redis,Memcache,以及存儲系統Bitcask等。
基於內存中的Hash,支持隨機的增刪改查,讀寫的時間複雜度O(1)。但無法支持順序讀寫(指典型Hash,不包括如Redis的基於跳錶的ZSet的其它功能),在不需要有序遍歷時,性能最優。
1. 常用哈希函數
構造哈希函數的總的原則是儘可能將關鍵字集合空間均勻的映射到地址集合空間中,同時儘可能降低衝突發生的概率。
- 除留餘數法:H(Key)=key % p (p ≤ m)p最好選擇一個小於或等於m(哈希地址集合的個數)的某個最大素數。
- 直接地址法: H(Key) =a * Key + b;「a,b」是常量。
- 數字分析法
比如有一組key1=112233,key2=112633,key3=119033,分析數中間兩個數比較波動,其他數不變。那麼取key的值就可以是 key1=22,key2=26,key3=90。
- 平方取中法
- 摺疊法
比如key=135790,要求key是2位數的散列值。那麼將key變為13+57+90=160,然後去掉高位「1」,此時key=60。
2. 衝突處理方法
1) 開放地址法
如果兩個數據元素的哈希值相同,則在哈希表中為後插入的數據元素另外選擇一個表項。當程序查找哈希表時,如果沒有在第一個對應的哈希表項中找到符合查找要求的數據元素,程序就會繼續往後查找,直到找到一個符合查找要求的數據元素,或者遇到一個空的表項。
①.線性探測法
這種方法在解決衝突時,依次探測下一個地址,直到有空的地址後插入,若整個空間都找遍仍然找不到空餘的地址,產生溢出。Hi =( H(Key) + di ) % m ( i = 1,2,3,…,k , k ≤ m-1 )
地址增量 di = 1,2,…, m-1, 其中 i 為探測次數
②.二次探測法
地址增量序列為: di= 1^2,-1^2,2^2,-2^2 ,…,q^2,-q^2 (q≤ m/2)
Python字典dict的實現是使用二次探查來解決衝突的。
③.雙哈希函數探測法
Hi =( H(Key) + i * RH(Key) ) % m ( i=1,2,3,…, m-1)
H(Key) , RH(Key) 是兩個哈希函數,m為哈希表長度。先用第一個哈希函數對關鍵字計算哈希地址,一旦產生地址衝突,再用第二個函數確定移動的步長因子,最後通過步長因子序列由探測函數尋找空餘的哈希地址。H1= (a +b) % m, H2 = (a + 2b) % m, …, Hm-1= (a+ (m-1)*b) %m
2) 鏈地址法
將哈希值相同的數據元素存放在一個鏈表中,在查找哈希表的過程中,當查找到這個鏈表時,必須採用線性查找方法。
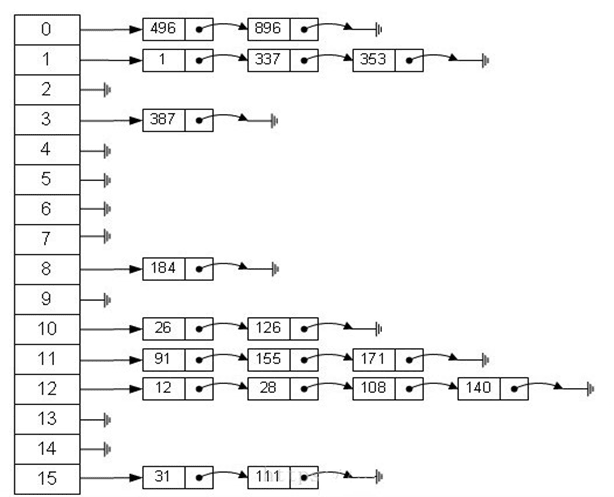
Hash存儲示例
假定一個待散列存儲的線性表為(32,75,29,63,48,94,25,46,18,70),散列地址空間為HT[13],採用除留餘數法構造散列函數和線性探測法處理衝突。
二.B 樹存儲引擎
B樹存儲引擎是B樹的持久化實現,不僅支持單條記錄的增、刪、讀、改操作,還支持順序掃描(B+樹的葉子節點間的指針)。相比哈希存儲引擎,B樹存儲引擎不僅支持隨機讀取,還支持範圍掃描。Mysql的MyISAM和InnoDB支持B-樹索引,InnoDB還支持B+樹索引,Memory支持Hash。
1. B-樹存儲
B-樹為一種多路平衡搜索樹,與紅黑樹最大的不同在於,B樹的結點可以有多個子節點,從幾個到幾千個。B樹與紅黑樹相似,一棵含n個結點的B樹的高度也為O(lgn),但可能比一棵紅黑樹的高度小許多,因為它的分支因子比較大。所以B樹可在O(logn)時間內,實現各種如插入,刪除等動態集合操作。
B-樹的規則定義:
1) 定義任意非葉子節點最多可以有M個兒子節點;且M>2;
2) 則根節點的兒子數為:[2,M];
3) 除根節點為的非葉子節點的兒子書為[M/2,M];
4) 每個結點存放至少M/2-1(取上整)且至多M -1 個關鍵字;(至少為2)
5) 非葉子結點的關鍵字個數 = 指向子節點的指針書 -1;
6) 非葉子節點的關鍵字:K[1],K[2],K[3],…,K[M-1;且K[i] < K[i +1];
7) 非葉子結點的指針:P[1], P[2], …, P[M];其中P[1]指向關鍵字小於K[1]的子樹,P[M]指向關鍵字大於K[M-1]的子樹,其它P[i]指向關鍵字屬於(K[i-1], K[i])的子樹;
8) 所有葉子結點位於同一層;
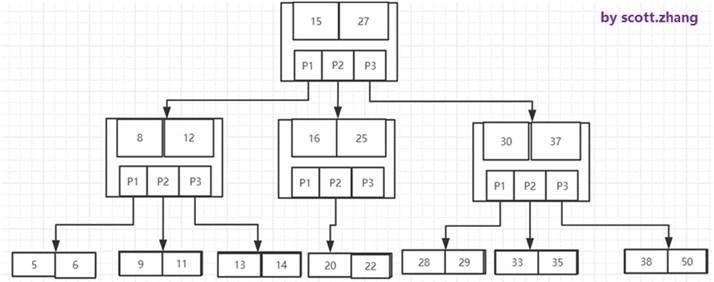
下圖是一個M為3的B-樹:
B-樹的搜索
從根結點開始,對結點內的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重複,直到所對應的兒子指針為空,或已經是葉子結點;
B-樹的特性
關鍵字集合分佈在整顆樹中,任何一個關鍵字出現且只出現在一個結點中;
所有結點都存儲數據,搜索有可能在非葉子結點結束;
搜索性能等價於在關鍵字全集內做一次二分查找,查詢時間複雜度不固定,與Key在樹中的位置有關,最好為O(1);
非葉子節點存儲了data數據,導致數據量很大的時候,樹的層數可能會比較高,隨着數據量增加,IO次數的控制不如B+樹優秀。
MongoDB 存儲結構
MongoDB是聚合型數據庫,而B-樹恰好Key和data域聚合在一起,所有節點都有Data域,只要找到指定索引就可以進行訪問,無疑單次查詢平均快於MySql。
MongoDB並不是傳統的關係型數據庫,而是以Json格式作為存儲的NoSQL,目的就是高性能、高可用、易擴展。
2. B+樹存儲
B樹在提高磁盤IO性能的同時並沒有解決元素遍歷的效率低下的問題。正是為了解決這個問題,B+樹應運而生。B+樹是對B樹的一種變形,本質還是多路平衡查找樹。B+樹只要遍歷葉子節點就可以實現整棵樹的遍歷。而且在數據庫中基於範圍的查詢是非常頻繁的,而B樹不支持這樣的操作(或者說效率太低)。RDBMS需要B+樹用以減少尋道時間,順序訪問較快。
B+樹通常被用於數據庫和操作系統的文件系統中。像NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系統都在使用B+樹作為元數據索引。B+樹的特點是能夠保持數據穩定有序,其插入與修改擁有較穩定的對數時間複雜度。B+樹元素為自底向上插入。
下圖是一棵高度為M=3的B+樹
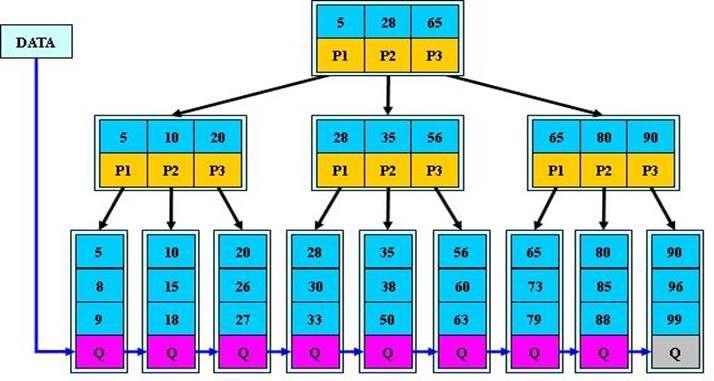
B+樹上有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即數據節點)之間是一種鏈式環結構。因此可以對B+樹進行兩種查找運算:一種是對於主鍵的範圍查找和分頁查找,另一種是從根節點開始,進行隨機查找。
與普通B-樹相比,B+樹的非葉子節點只有索引,所有關鍵字都位於葉子節點,這樣會使樹節點的度比較大,而樹的高度就比較低,從而有利於提高查詢效率。並且葉子節點上的數據會形成有序鏈表。
主要優點如下:
- 結構比較扁平,高度低(一般不超過4層),隨機尋道次數少;
- 有n棵子樹的結點中含有n個關鍵字,不用來保存數據,只用來索引。結點中僅含其子樹(根結點)中的最大(或最小)關鍵字。
- 數據存儲密度大,且都位於葉子節點,查詢穩定,遍歷方便;
- 葉子節點存放數值,按照值大小順序排序,形成有序鏈表,區間查詢轉化為順序讀,效率高。且所有葉子節點與根節點的距離相同,因此任何查詢效率都很相似。而B樹則必須通過中序遍歷才支持範圍查詢。
- 與二叉樹不同,B+樹的數據更新操作不從根節點開始,而從葉子節點開始,並且在更新過程中樹能以比較小的代價實現自平衡。
B+樹的缺點:
- 如果寫入的數據比較離散,那麼尋找寫入位置時,子節點有很大可能性不會在內存中,最終產生大量隨機寫,性能下降。下圖說明了這一點。
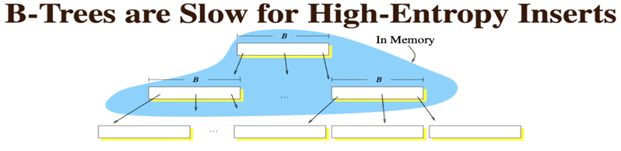
- B+樹在查詢過程中應該不會慢,但如B+樹已運行很長時間,寫入了很多數據,隨着葉子節點分裂,其對應的塊會不再順序存儲而變得分散,可能會導致邏輯上原本連續的數據實際上存放在不同的物理磁盤塊位置上,這時執行範圍查詢也會變成隨機讀,會導致較高的磁盤IO,效率降低。

譬如:數據更新或者插入完全無序時,如先插入0,後80000,然後200,然後666666,這樣跨度很大的數據時,由於不在一個磁盤塊中,就需先去查找到這個數據。數據非常離散,就意味着每次查找時,它的葉子節點很可能都不在內存中,此時就會出現性能的瓶頸。並且隨機寫產生的子樹的分裂等,產生很多的磁盤碎片,也是不太友好的一面。
可見B+樹在多讀少寫(相對而言)的情境下比較有優勢。當然,可用SSD來獲得成倍提升的讀寫速率,但成本相對較高。
B+樹的搜索
與B-樹基本相同,區別是B+樹只有達到葉子結點才命中(B-樹可在非葉子結點命中),其性能也等價於在關鍵字全集做一次二分查找。
B+樹的特性
非葉子結點相當於是葉子結點的索引(稀疏索引),葉子結點相當於是存儲(關鍵字)數據的數據層;B+樹的葉子結點都是相鏈的,因此對整棵樹的遍歷只需要一次線性遍歷葉子結點即可。而且由於數據順序排列並且相連,所以便於區間查找和搜索。而B-樹則需要進行每一層的遞歸遍歷。相鄰的元素可能在內存中不相鄰,所以緩存命中性沒有B+樹好。
比B-樹更適合實際應用中操作系統的文件索引和數據庫索引
1) 磁盤讀寫代價更低
B+樹的內部結點並沒有指向關鍵字具體信息的指針。因此其內部結點相對B樹更小。如果把所有同一內部結點的關鍵字存放在同一盤塊中,那麼盤塊所能容納的關鍵字數量也越多。一次性讀入內存中的需要查找的關鍵字也就越多。相對來說IO讀寫次數也就降低了。
舉個例子,假設磁盤中的一個盤塊容納16bytes,而一個關鍵字2bytes,一個關鍵字具體信息指針2bytes。一棵9階B-tree(一個結點最多8個關鍵字)的內部結點需要2個盤快。而B+樹內部結點只需要1個盤快。當需要把內部結點讀入內存中的時候,B樹就比B+樹多一次盤塊查找時間。
2)查詢效率更加穩定
由於非葉子結點並不是最終指向文件內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查找必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。
MySQL InnoDB
InnoDB存儲引擎中頁大小為16KB,一般表的主鍵類型為INT(佔用4位元組)或long(8位元組),指針類型也一般為4或8個位元組,也就是說一個頁(B+樹中的一個節點)中大概存儲16KB/(8B+8B)=1K個鍵值(K取估值為10^3)。即一個深度為3的B+樹索引可維護10^3 * 10^3 * 10^3=10億條記錄。
在數據庫中,B+樹的高度一般都在2~4層。MySql的InnoDB存儲引擎在設計時是將根節點常駐內存的,也就是說查找某一鍵值的行記錄時最多只需要1~3次磁盤I/O操作。
數據庫中的B+樹索引可以分為聚集索引(clustered index)和輔助索引(secondary index)。聚集索引的B+樹中的葉子節點存放的是整張表的行記錄數據。輔助索引與聚集索引的區別在於輔助索引的葉子節點並不包含行記錄的全部數據,而是存儲相應行數據的聚集索引鍵,即主鍵。當通過輔助索引來查詢數據時,InnoDB存儲引擎會遍歷輔助索引找到主鍵,然後再通過主鍵在聚集索引中找到完整的行記錄數據。

3. B*樹存儲
B+樹的一種變形,在B+樹的基礎上將索引層以指針連接起來,使搜索取值更加快捷。如下圖(M=3)
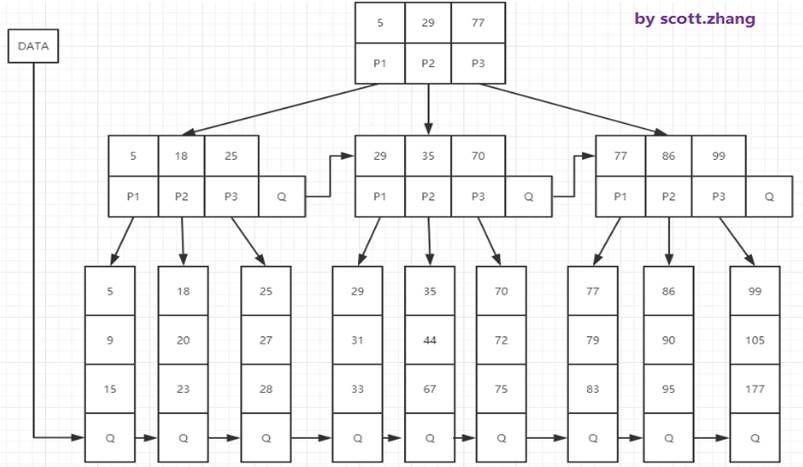
相對B+樹的變化,如下:
- B*樹定義了非葉子結點關鍵字個數至少為(2/3)*M,即塊的最低使用率為2/3代替B+樹的1/2,將結點的最低利用率從1/2提高到2/3;
- B+樹的分裂:當一個結點滿時分配一個新的結點,並將原結點中1/2的數據複製到新結點,最後在父結點中增加新結點的指針;B+樹的分裂隻影響原結點和父結點,而不影響兄弟結點,所以它不需指向兄弟的指針;
- B*樹的分裂:當一個結點滿時,如它的下一個兄弟結點未滿,那麼將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最後修改父結點中兄弟結點的關鍵字(因兄弟結點的關鍵字範圍改變),如兄弟也滿了,則在原結點與兄弟結點之間增加新結點,並各複製1/3數據到新結點,最後在父結點增加新結點的指針.
相對於B+樹,B*樹分配新結點的概率比B+樹要低,空間利用率、查詢速率也有所提高。
三.LSM樹存儲引擎
數據庫的數據大多存儲在磁盤上,無論是機械硬盤還是固態硬盤(SSD),對磁盤數據的順序讀寫速度都遠高於隨機讀寫。大量的隨機寫,導致B樹在數據很大時,出現大量磁盤IO,速度越來越慢,基於B樹的索引結構是違背上述磁盤基本特點的—需較多的磁盤隨機讀寫。於是,基於日誌結構的新型索引結構方法應運而生,主要思想是將磁盤看作一個大的日誌,每次都將新的數據及其索引結構添加到日誌的最末端,以實現對磁盤的順序操作,從而提高索引性能。
對海量存儲集群而言,LSM樹也是作為B+樹的替代方案而產生。當今很多主流DB都使用了LSM樹的存儲模型,包括LevelDB,HBase,Google BigTable,Cassandra,InfluxDB, RocksDB等。LSM樹通過儘可能減少寫磁盤次數,實際落地存儲的數據按key劃分,形成有序的不同文件;結合其「先內存更新後合併落盤」的機制,盡量達到順序寫磁盤,儘可能減少隨機寫;對於讀則需合併磁盤已有歷史數據和當前未落盤的駐於內存的更新。LSM樹存儲支持有序增刪改查,寫速度大幅提高,但隨機讀取數據時效率低。
LSM樹實際不是一棵樹,而是2個或者多個樹或類似樹的結構的集合。
下圖為包含2個結構的LSM樹
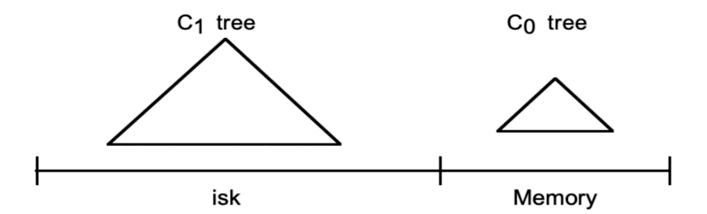
在LSM樹中,最低一級即最小的C0樹位於內存,而更高級的C1、C2…樹都位於磁盤裡。數據會先寫入內存中的C0樹,當它的大小達到一定閾值之後,C0樹中的全部或部分數據就會刷入磁盤中的C1樹,如下圖所示。
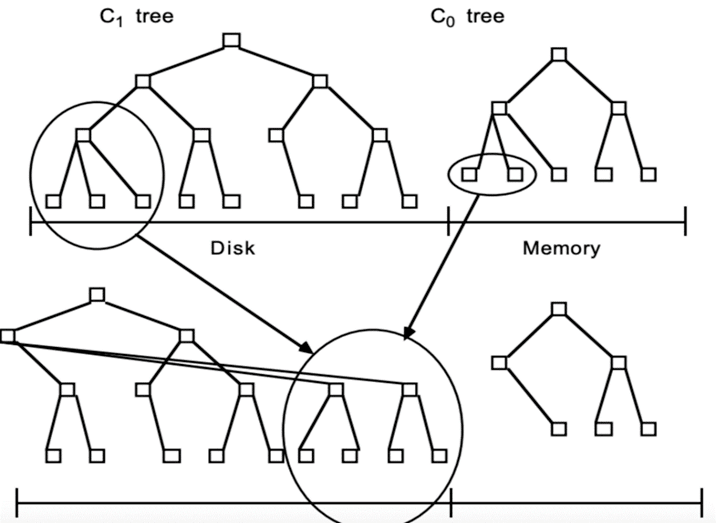
由於內存讀寫速率比外存要快非常多,因此數據寫入C0樹的效率很高。且數據從內存刷入磁盤時是預排序的,也就是說,LSM樹將原本隨機寫操作轉化成了順序寫操作,寫性能大幅提升。不過,它的tradeoff就是犧牲了一部分讀性能,因為讀取時需將內存中數據和磁盤中的數據合併。總體上講這種權衡還是值得的,因為:
- 可以先讀取內存中C0樹的緩存數據。內存效率高且根據局部性原理,最近寫入的數據命中率也高。
- 寫入數據未刷到磁盤時不會佔用磁盤的I/O,不會與讀取競爭。讀取操作就能取得更長的磁盤時間,變相地彌補了讀性能差距。
在實際應用中,為防止內存因斷電等原因丟失數據,寫入內存的數據同時會順序在磁盤上寫日誌,類似於預寫日誌(WAL),這就是LSM這個詞中Log一詞的來歷。另外,如有多級樹,低級的樹在達到大小閾值後也會在磁盤中進行合併,如下圖所示。


1. Leveldb/Rocksdb
基本描述
1) 對數據,按key劃分為若干level,每個level對應若干文件,包括存在於內存中和落盤的。文件內key都有序,同級的各個文件之間一般也有序,level0對應於內存中的數據(0.sst),後面依次是1、2、3、…的各級文件(默認到level6)。
2) 寫時,先寫對應內存的最低level的文件,這也是快的一個原因。內存的數據也是被持久化的,達到一定大小後被合併到下一級文件落盤。
3) 落盤後的各級文件也會定期進行排序加合併,合併後數據進入下一層level;這樣的寫入操作,大多數都是對一個頁順序的寫,或者申請新頁寫,而不再是隨機寫。
Rocksdb Compact
Compact是個很重要的步驟,下面是rocksdb的compact過程:
Rocksdb的各級文件組織形式:
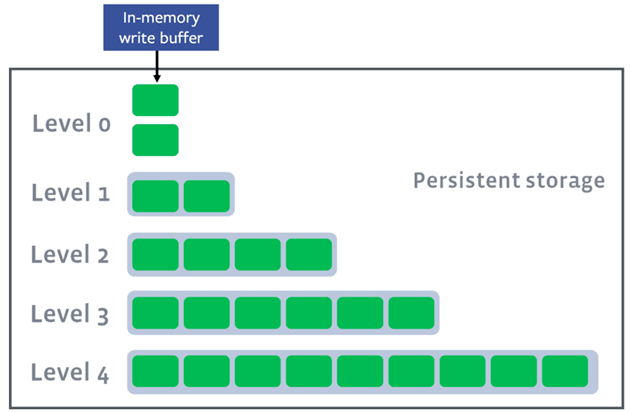
各級的每個文件,內部都按key有序,除了內存對應的level0文件,內部文件之間也是按key有序;這樣查找一個key,很方便二分查找。
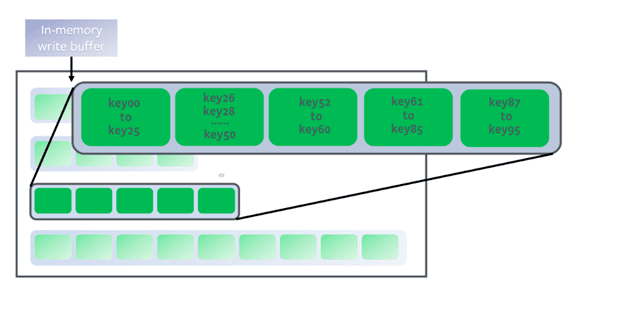
然後,當每一級的數據到達一定閾值時,會觸發排序歸併,簡單說,就是在兩個level的文件中,把key有重疊的部分,合併到高層level的文件里
這個在LSM樹里叫數據壓縮(compact);

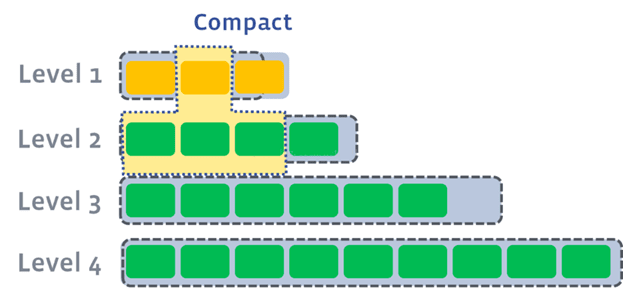
對於Rocksdb,除了內存level0到level1的compact,其他各級之間的compact可以並行;通常設置較小的level0到level1的compact閾值,加快這一層的compact。良好的歸併策略的配置,使數據儘可能集中在最高層(90%以上),而不是中間層,這樣有利於compact的速度;另外,對於基於LSM樹的讀,需要在各級文件中二分查找,磁盤IO也不少,此外還需要關注level0里的對於這個key的操作,比較明顯的優化是,通過Bloomfilter略掉肯定不存在該key的文件,減少無謂查找;
2. HBase LSM
說明:本小節需事先了解HBase的讀寫流程及MemStore。
MemStore作為列族級別的寫入和讀取緩存,它就是HBase中LSM樹的C0層。它未採用樹形結構來存儲,而是採用了跳錶(一種替代自平衡BST二叉排序樹的結構)。MemStore Flush的過程,也就是LSM樹中C0層刷寫到C1層的過程,而LSM中的日誌對應到HBase自然就是HLog了。
HBase讀寫流程簡圖
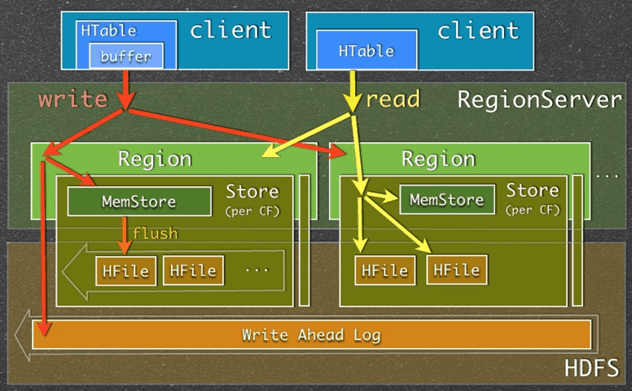
HFile就是LSM樹中的高層實現。從邏輯上來講,它是一棵滿的3層B+樹,從上到下的3層索引分別是Root index block、Intermediate index block和Leaf index block,對應到下面的Data block就是HFile的KeyValue結構。HFile V2索引結構的圖示如下:

HFile過多會影響讀寫性能,因此高層LSM樹的合併即對應HFile的合併(Compaction)操作。合併操作又分Minor和Major Compaction,由於Major Compaction涉及整個Region,對磁盤壓力很大,因此要盡量避免。
布隆過濾器(Bloom Filter)
是保存在內存中的一種數據結構,可用來驗證「某樣東西一定不存在或者可能存在」。由一個超長的二進制位數組和一系列的Hash函數組成,二進制位數組初始全部為0,當有元素加入集合時,這個元素會被一系列Hash函數計算映射出一系列的值,所有的值在位數組的偏移量處置為1。如需判斷某個元素是否存在於集合中,只需判斷該元素被Hash後的值在數組中的值,如果存在為0的則該元素一定不存在;如果全為1則可能存在,這種情況可能有誤判。

HBase為了提升LSM結構下的隨機讀性能而引入布隆過濾器(建表語句中可指定),對應HFile中的Bloom index block,其結構圖如下。

通過布隆過濾器,HBase能以少量的空間代價,換來在讀取數據時非常快速地確定是否存在某條數據,效率進一步提升。
LSM-樹的這種結構非常有利於數據的快速寫入(理論上可接近磁盤順序寫速度),但不利於讀,因為理論上讀的時候可能需要同時從memtable和所有硬盤上的sstable中查詢數據,這樣顯然會對性能造成較大影響。為解決這個問題,LSM-樹採取以下主要相關措施。
- 定期將硬盤上小的sstable合併(Merge或Compaction)成大的sstable,以減少sstable的數量。且平時的數據更新刪除操作並不會更新原有的數據文件,只會將更新刪除操作加到當前的數據文件末端,只有在sstable合併的時候才會真正將重複的操作或更新去重、合併。
- 對每個sstable使用布隆過濾器,以加速對數據在該sstable的存在性進行判定,從而減少數據的總查詢時間。
SSTable(Sorted String Table)
當內存中的MemTable達到一定大小,需將MemTable轉儲(Dump)到磁盤中生成SSTable文件。由於數據同時存在MemTable和可能多個SSTable中,讀取操作需按從舊到新的時間順序合併SSTable和內存中的MemTable數據。
SSTable 中的數據按主鍵排序後存放在連續的數據塊(Block)中,塊之間也有序。接着,存放數據塊索引,由每個Block最後一行的主鍵組成,用於數據查詢中的Block定位。接着存放布隆過濾器和表格的Schema信息。最後存放固定大小的Trailer以及Trailer的偏移位置。
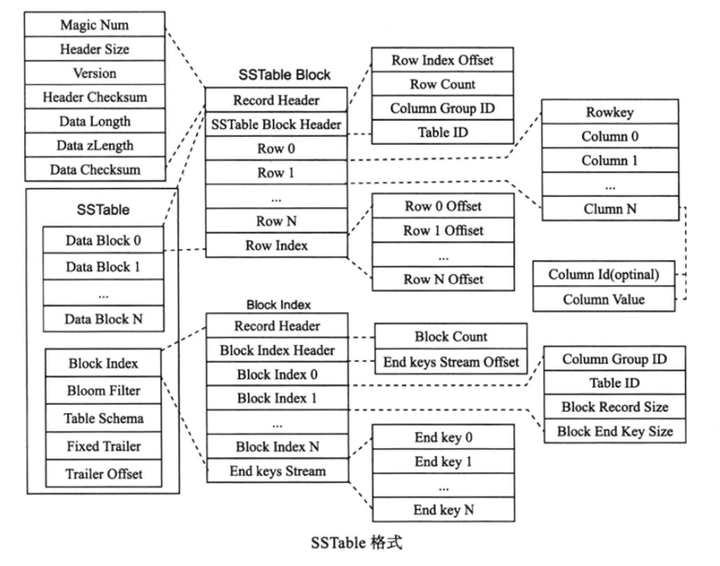
本質上看,SSTable是一個兩級索引結構:塊索引以及行索引。分為稀疏格式和稠密格式。對於稀疏格式,某些列可能存在也可能不存在,因此每一行只存儲包含實際值的列,每一列存儲的內容為:<列ID,列值>; 而稠密格式中每一行都需存儲所有列,每一列只需存儲列值,不需存儲列ID,列ID可從表格Schema中獲取。
… …
3. 圖庫ArangoDB LSM
ArangoDB採用RocksDB做底層存儲引擎,RocksDB使用LSM-Tree數據結構。

存儲的格式非常類似JSON,叫做VelocyPack格式的二進制格式存儲。
(1)文檔被組織在集合中。
(2)有兩種集合:文檔(V),邊集合(E)
(3)邊集合也是以文檔形式存儲,但包含兩個特殊的屬性_from和_to,被用來創建在文檔和文檔之間創建關係
索引類型
· Primary Index,默認索引,建立字段是_key或_id上,一個哈希索引
· Edge Index,默認索引,建立在_from、_to上,哈希索引;不能用於範圍查詢、排序,弱於OrientDB
· Hash Index,自建
· Skiplist Index,有序索引,
o 用於快速查找具有特定屬性值的文檔,範圍查詢以及按索引排序,順序返迴文檔。
o 用於查找,範圍查詢和排序。補全範圍查詢的缺點。
· Persistent Index,RocksDB的索引。
o 持久性索引是具有持久性的排序索引。當存儲或更新文檔時,索引條目將寫入磁盤。
o 使用持久性索引可能會減少集合加載時間。
· Geo Index,可以在集合中的一個或多個屬性上創建其他地理索引。
· Fulltext Index,全文索引
四.R樹的存儲結構
R樹是B樹在高維空間的擴展,是一棵平衡樹。每個R樹的葉子結點包含了多個指向不同數據的指針,這些數據可以是存放在硬盤中,也可存在內存中。根據R樹的這種數據結構,當需進行一個高維空間查詢時,只需要遍歷少數幾個葉子結點所包含的指針,查看這些指針指向的數據是否滿足即可。這種方式使得不必遍歷所有數據即可獲得答案,效率顯著提高。
下圖是R樹的一個簡單實例:
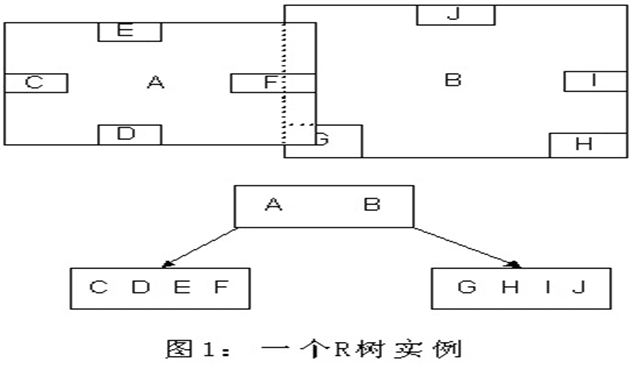
R樹運用空間分割理念,採用一種稱為MBR(Minimal Bounding Rectangle)的方法,在此譯作「最小邊界矩形」。從葉子結點開始用矩形將空間框起來,結點越往上,框住的空間就越大,以此對空間進行分割。
以二維空間舉例,下圖是Guttman論文中的一幅圖:
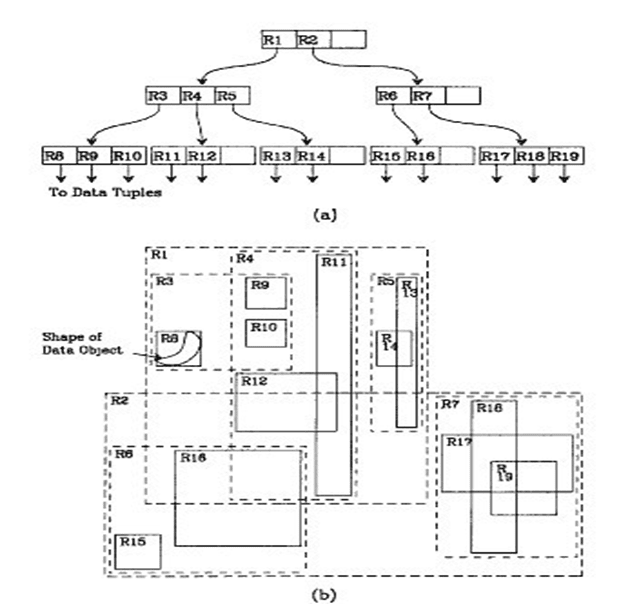
1) 首先假設所有數據都是二維空間下的點,圖中僅僅標誌了R8區域中的數據,也就是那個shape of data object。別把那一塊不規則圖形看成一個數據,把它看作是多個數據圍成的一個區域。為了實現R樹結構,用一個最小邊界矩形恰好框住這個不規則區域,這樣就構造出了一個區域:R8。R8的特點很明顯,就是正好框住所有在此區域中的數據。其他實線包圍住的區域,如R9,R10,R12等都是同樣道理。這樣一共得到了12個最最基本的最小矩形。這些矩形都將被存儲在子結點中。
2) 下一步操作就是進行高一層次的處理,發現R8,R9,R10三個矩形距離最為靠近,因此就可以用一個更大的矩形R3恰好框住這3個矩形。
3) 同樣,R15,R16被R6恰好框住,R11,R12被R4恰好框住,等等。所有最基本的最小邊界矩形被框入更大的矩形中之後,再次迭代,用更大的框去框住這些矩形。
用地圖和餐廳的例子來解釋,就是所有的數據都是餐廳所對應的地點,先把相鄰的餐廳劃分到同一塊區域,劃分好所有餐廳之後,再把鄰近的區域劃分到更大的區域,劃分完畢後再次進行更高層次的劃分,直到劃分到只剩下兩個最大的區域為止。要查找的時候就方便了。
然後就可以把這些大大小小的矩形存入R樹中。根結點存放的是兩個最大的矩形,這兩個最大的矩形框住了所有的剩餘的矩形,當然也就框住了所有的數據。下一層的結點存放了次大的矩形,這些矩形縮小了範圍。每個葉子結點都是存放的最小的矩形,這些矩形中可能包含有n個數據。
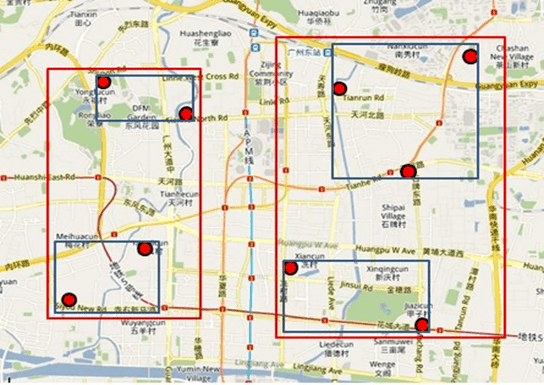
查詢特定的數據
以餐廳為例,假設查詢廣州市天河區天河城附近一公里的所有餐廳地址
1) 打開地圖(即整個R樹),先選擇國內還是國外(根結點);
2) 然後選擇華南地區(對應第一層結點),選擇廣州市(對應第二層結點);
3) 再選擇天河區(對應第三層結點);
4) 最後選擇天河城所在的那個區域(對應葉子結點,存放有最小矩形),遍歷所有在此區域內的結點,看是否滿足要求即可。
其實R樹的查找規則跟查地圖很像,對應下圖:
一棵R樹滿足如下性質:
1) 除非它是根結點之外,所有葉子結點包含有m至M個記錄索引(條目)。作為根結點的葉子結點所具有的記錄個數可以少於m。通常,m=M/2。
2) 對於所有在葉子中存儲的記錄(條目),I是最小的可以在空間中完全覆蓋這些記錄所代表的點的矩形(此處所說「矩形」是可擴展到高維空間)。
3) 每一個非葉子結點擁有m至M個孩子結點,除非它是根結點。
4) 對於在非葉子結點上的每一個條目,i是最小的可在空間上完全覆蓋這些條目所代表的店的矩形(同性質2)
5) 所有葉子結點都位於同一層,因此R樹為平衡樹。
說明:
葉子結點的結構,數據形式為: (I, tuple-identifier),tuple-identifier表示的是一個存放於數據庫中的tuple,也就是一條記錄,是n維的。I是一個n維空間的矩形,並可恰好框住這個葉子結點中所有記錄代表的n維空間中的點。I=(I0,I1,…,In-1)。
R樹是一種能夠有效進行高維空間搜索的數據結構,已被廣泛應用在各種數據庫及其相關的應用中。但R樹的處理也具局限性,它的最佳應用範圍是處理2至6維的數據,更高維的存儲會變得非常複雜,這樣就不適用。近年來,R樹也出現了很多變體,R*樹就是其中的一種。這些變體提升了R樹的性能,如需更多了解,可以參考相關文獻。
應用示例
地理圍欄(Geo-fencing)是LBS(Location Based Services)的一種應用,就是用一個虛擬的柵欄圍出一個虛擬地理邊界,當手機進入、離開某個特定地理區域,或在該區域內活動時,手機可以接收自動通知和警告。譬如,假設地圖上有三個商場,當用戶進入某個商場的時候,手機自動收到相應商場發送的優惠券push消息。地理圍欄應用非常廣泛,當今移動互聯網主要app如美團、大眾點評、手淘等都可看到其應用身影。
五.倒排索引存儲
對Mysql來說,採用B+樹索引,對Elasticsearch/Lucene來說,是倒排索引。倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地講,正向索引是通過key找value,反向索引則是通過value找key。
Elasticsearch是建立在全文搜索引擎庫Lucene基礎上的搜索引擎,它隱藏了Lucene的複雜性,提供一套簡單一致的RESTful API。Elasticsearch的倒排索引其實就是Lucene的倒排索引。
1. Lucene 的倒排索引
倒排索引,通過Term搜索到文檔ID。首先想想看,世界上那麼多單詞,中文、英文、日文、韓文 … 如每次搜索一個單詞都要全局遍歷一遍,明顯不行。於是有了對單詞進行排序,像B+樹一樣可在頁里實現二分查找。光排序還不行,單詞都放在磁盤,磁盤IO慢的不得了,大量存放內存會導致內存爆了。
下圖:通過字典把所有單詞都貼在目錄里。
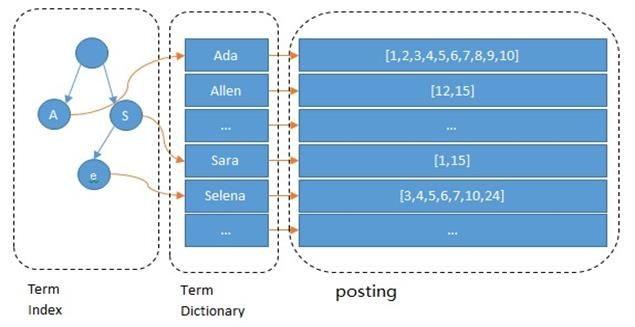
Lucene的倒排索引,增加了最左邊的一層「字典樹」term index,它不存儲所有的單詞,只存儲單詞前綴,通過字典樹找到單詞所在的塊,也就是單詞的大概位置,再在塊里二分查找,找到對應的單詞,再找到單詞對應的文檔列表。
假設有多個term,如:Carla,Sara,Elin,Ada,Patty,Kate,Selena。找出某個特定term,可通過排序後以二分查找方式,logN次磁盤查找得到目標,但磁盤隨機讀操作較昂貴(單次Random access約10ms)。所以盡量少的讀磁盤,可把一些數據緩存到內存。但term dictionary太大,於是就有了term index.通過trie樹來構建index;
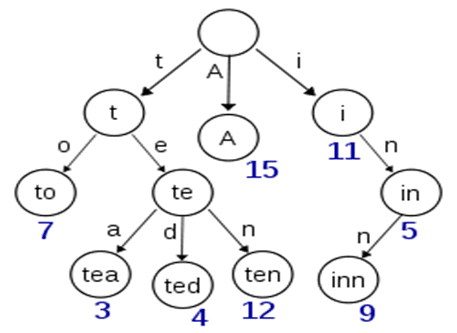
通過term index可快速定位term dictionary的某個offset,從這個位置再往後順序查找。再加上一些壓縮技術(FST),term index 的尺寸可以只有所有term尺寸的幾十分之一,使得用內存緩存整個term index變成可能。
FST Tree
一種有限狀態轉移機,優點:1)空間佔用小。通過對詞典中單詞前綴和後綴的重複利用,壓縮了存儲空間;2)查詢速度快。O(len(str))的查詢時間複雜度。
示例:對「cat」、 「deep」、 「do」、 「dog」 、「dogs」這5個單詞進行插入構建FST(必須已排序),得到如下一個有向無環圖。
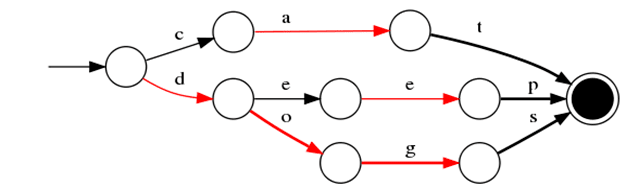
FST壓縮率一般在3倍~20倍之間,相對於TreeMap/HashMap的膨脹3倍,內存節省就有9倍到60倍!
2. 與MySQL檢索對比
MySQL只有term dictionary,以B-樹排序的方式存儲在磁盤上。檢索一個term需若干次random access磁盤操作。而Lucene在term dictionary的基礎上添加了term index來加速檢索,以樹的形式緩存在內存中。從term index查到對應term dictionary的block位置後,再去磁盤上找term,大大減少磁盤的random access次數。
Term index在內存中是以FST(finite state transducers)的壓縮形式保存,其特點是非常節省內存。Term dictionary在磁盤上是以分block的方式保存的,一個block內部利用公共前綴壓縮,比如都是Ab開頭的單詞就可以把Ab省去。這樣term dictionary可比B-樹更節約空間。
3. 聯合索引結構及檢索
給定多個查詢過濾條件,如」age=18 AND gender=女」就是把兩個posting list做一個「與」的合併。對於MySql來說,如果給age和gender兩個字段都建立了索引,查詢時只會選擇其中最selective的來用,然後另一個條件是在遍歷行的過程中在內存中計算之後過濾掉。那如何聯合使用兩個索引呢?兩種辦法:
- 使用skip list數據結構,同時遍歷gender和age的posting list,互相skip;
- 使用bitset數據結構,對gender和age兩個filter分別求出 bitset,對兩個bitset做AND操作。
PostgreSQL從8.4版本開始支持通過bitmap聯合使用兩個索引,就是利用bitset數據結構來做的。一些商業的關係型數據庫也支持類似聯合索引的功能。
ES支持以上兩種的聯合索引方式,如果查詢的filter緩存到了內存中(以bitset形式),那麼合併就是兩個bitset的AND。如果查詢的filter沒有緩存,那麼就用skip list的方式去遍歷兩個on disk的posting list。
1) 利用Skip List合併
即使對於排過序的鏈表,查找還是需要進行通過鏈表的指針進行遍歷,時間複雜度很高依然是O(n),這個顯然不能接受。是否可以像數組那樣,通過二分法查找,但由於在內存中的存儲的不確定性,不能這麼做。但可結合二分法思想,跳錶就是鏈表與二分法的結合。跳錶是有序鏈表。
- 鏈表從頭節點到尾節點都是有序的
- 可以進行跳躍查找(形如二分法),降低時間複雜度
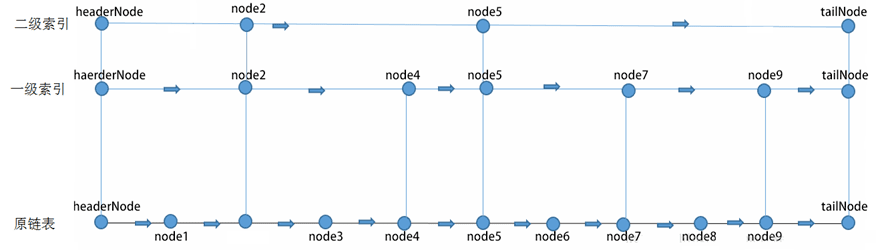
說明:在上圖中如要找node6節點
1) 第一次比較headerNode->next[2]的值,即node5的值。顯然node5小於node6,所以,下一次應從第2級的node5開始查詢,令targetNode=targetNode->next[2];
2) 第二次應該比較node5->next[2]的值,即tailNode的值。tailNode的值是最大的,所以結果是大於,下一次應從第1級的node5開始查詢。這裡從第2級跳到第1級。但沒有改變targetNode。
3) 第三次應該比較node5->next[1]的值,即node7的值。因node7大於node6,所以,下一次應該從第0級的node5開始查詢。這裡從第1級跳到第0級。也沒有改變targetNode。
4) 第四次應該比較node5->next[0]的值,即node6的值。這時相等,結束。如果小於,targetNode往後移,改變targetNode=targetNode->next[0],如果大於,則沒找到,結束。因為這已經是第0級,沒法再降了。
考慮到頻繁出現的term,如gender里的男或女。如有1百萬個文檔,那性別為男的posting list里就會有50萬個int值。用FOR編碼進行壓縮可極大減少磁盤佔用,對於減少索引尺寸有非常重要的意義。當然MySql B-樹里也有類似的posting list,是未經這樣壓縮的。因為FOR的編碼有解壓縮成本,利用skip list,除了跳過了遍歷的成本,也跳過了解壓縮這些壓縮過的block的過程,從而節省了CPU。
Frame Of Reference
以下三個步驟組成了Frame Of Reference(FOR)壓縮編碼技術
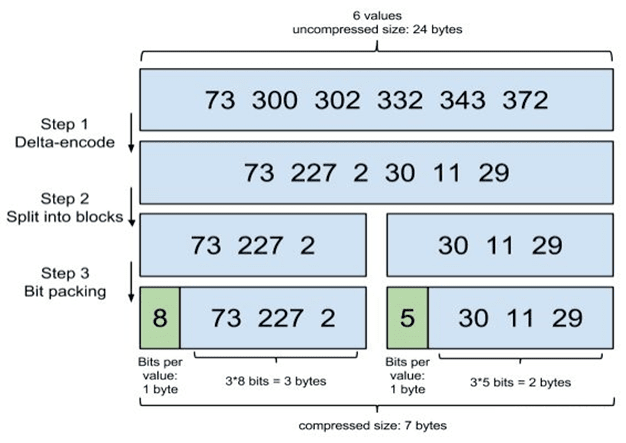
Step 1:增量編碼
Step 2:分割成塊
Lucene每個塊是256個文檔ID,每個塊增量編碼後每個元素都不會超過256(1 byte).為方便演示,圖中假設每個塊是3個文檔ID。
Step 3:按需分配空間
對於第一個塊 [73, 227, 2],最大元素是227,需要 8 bits,那給這個塊的每個元素,都分配8 bits的空間。但對於第二個塊[30,11,29],最大才30,只需5bits,那給每個元素只分配5bits空間。這一步可說是精打細算,按需分配。
2) 利用bitset合併
Bitset是一種很直觀的數據結構,posting list如:[1,3,4,7,10]對應的bitset就是:[1,0,1,1,0,0,1,0,0,1], 每個文檔按照文檔id排序對應其中的一個bit。Bitset自身就有壓縮的特點,其用一個byte就可以代表8個文檔。所以100萬個文檔只需要12.5萬個byte。但考慮到文檔可能有數十億之多,在內存里保存bitset仍然是很奢侈的事情。且對於每一個filter都要消耗一個bitset,比如age=18緩存起來的話是一個bitset,18<=age<25是另外一個filter,緩存起來也要一個bitset。所以需要一個數據結構:
- 可以壓縮地保存上億個bit代表對應的文檔是否匹配filter;
- 壓縮的bitset仍然可以很快地進行AND和OR的邏輯操作。
Roaring Bitmap
Lucene使用這個數據結構,其壓縮思路其實很簡單,與其保存100個0,佔用100個bit,還不如保存0一次,然後聲明這個0重複了100遍。
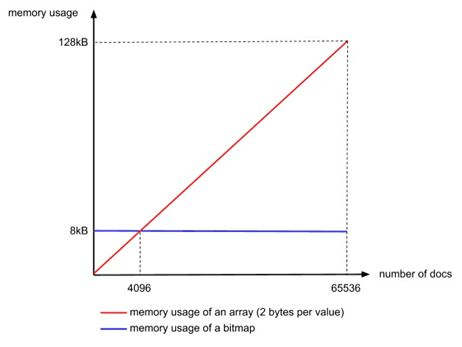
bitmap不管有多少文檔,佔用的空間都一樣。譬如一個數組裏面只有兩個文檔ID:[0, 65535],表示[1,0,0,0,….(很多個0),…,0,0,1],需要65536個bit,也就是65536/8=8192 bytes。而用Integer數組只需2*2bytes=4 bytes。可見在文檔數量不多時使用Integer數組更節省內存。算一下臨界值,無論文檔數量多少,bitmap都需要8192bytes,而Integer數組則和文檔數量成線性相關,每個文檔ID佔2bytes,所以8192/2=4096,當文檔數量少於4096時用Integer數組,否則用bitmap.
4. 存儲文檔的減少方式
一種常見的壓縮存儲時間序列的方式是把多個數據點合併成一行。Opentsdb支持海量數據的一個絕招就是定期把很多行數據合併成一行,這個過程叫compaction。類似的vivdcortext使用MySql存儲的時候,也把一分鐘的很多數據點合併存儲到MySql的一行以減少行數。
ES可實現類似優化,那就是Nested Document。可把一段時間的很多個數據點打包存儲到一個父文檔里,變成其嵌套的子文檔。這樣可把數據點公共的維度字段上移到父文檔里,而不用在每個子文檔里重複存儲,從而減少索引的尺寸。

存儲時,無論父文檔還是子文檔,對於Lucene來說都是文檔,都會有文檔Id。但對於嵌套文檔來說,可以保存起子文檔和父文檔的文檔id是連續的,且父文檔總是最後一個。有這樣一個排序性作為保障,那麼有一個所有父文檔的posting list就可跟蹤所有的父子關係。也可以很容易地在父子文檔id之間做轉換。把父子關係也理解為一個filter,那麼查詢檢索的時候不過是又AND了另外一個filter而已。
使用了嵌套文檔之後,對於term的posting list只需要保存父文檔的docid就可,可以比保存所有的數據點的doc id要少很多。如可在一個父文檔里塞入50個嵌套文檔,那posting list可變成之前的1/50。
… … …
六.對象與塊存儲
本章節描述,以Ceph 分佈式存儲系統為參考。
1. 對象存儲結構
在文件系統一級提供服務,只是優化了目前的文件系統,採用扁平化方式,棄用了目錄樹結構,便於共享,高速訪問。
對象存儲體系結構定義了一個新的、更加智能化的磁盤接口OSD。OSD是與網絡連接的設備,包含存儲介質,如磁盤或磁帶,並具有足夠智能可管理本地存儲的數據。計算結點直接與OSD通信,訪問它存儲的數據,不需要文件服務器的介入。對象存儲結構提供的性能是目前其它存儲結構難以達到的,如ActiveScale對象存儲文件系統的帶寬可以達到10GB/s。
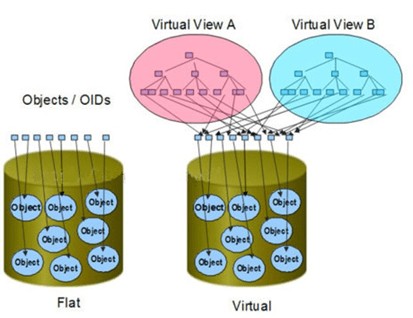
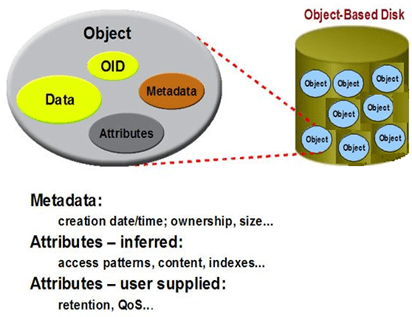
對象存儲的結構包括元數據服務器(控制節點MDS)和數據存儲服務器(OSD),兩者進行數據的存儲,還需客服端進行存儲的服務訪問和使用。
2. 塊設備存儲
塊存儲技術的構成基礎是最下層的硬件存儲設備,可能是機械硬盤也可能是固態硬盤。一個操作系統下可以獨立控制多個硬件存儲設備,但這些硬件存儲設備的工作相對獨立,通過操作系統命令看到的也是幾個獨立的設備文件。通過陣列控制層的設備可以在同一個操作系統下協同控制多個存儲設備,讓後者在操作系統層被視為同一個存儲設備。
典型設備:磁盤陣列,硬盤,虛擬硬盤,這種接口通常以QEMU Driver或者Kernel Module的方式存在,接口需要實現Linux的Block Device的接口或者QEMU提供的Block Driver接口,如Sheepdog,AWS的EBS,阿里雲的盤古系統,還有Ceph的RBD(RBD是Ceph面向塊存儲的接口)。
- 可通過Raid與LVM等手段對數據提供了保護;
- 多塊廉價的硬盤組合起來,提高容量;
- 多塊磁盤組合出來的邏輯盤,提升讀寫效率。
Ceph的RBD(RADOS Block Device)使用方式:先創建一個塊設備,然後映射塊設備到服務器,掛載後即可使用。
七.矩陣的存儲結構
說明:本章節以矩陣存儲為重心,而非矩陣的運算。
矩陣具有元素數目固定以及元素按下標關係有序排列等特點,所以在使用高級語言編程時,一般是用二維數組來存儲矩陣。數據庫表數據是行列存儲,可視為矩陣的應用形式。矩陣的存儲包括完全存儲和稀疏存儲方式。
1. 常規&特殊矩陣形態
常規矩陣形態
採用二維數組來存儲,可按行優先或列優先的形式記錄。
特殊矩陣形態
特殊矩陣指的是具有許多相同元素或零元素,並且這些元素的分佈有一定規律性的矩陣。這種矩陣如果還使用常規方式來存儲,就會產生大量的空間浪費,為了節省存儲空間,可以對這類矩陣採用壓縮存儲,壓縮存儲的方式是把那些呈現規律性分佈的相同元素只分配一個存儲空間,對零元素不分配存儲空間。
1) 對稱矩陣
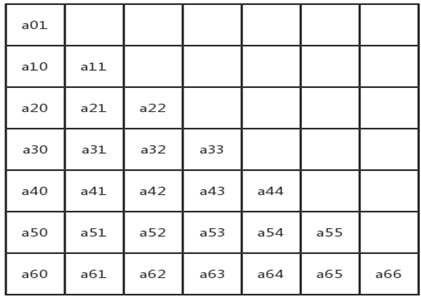
對於矩陣中的任何一個元素都有aij=aji 1≤i,j≤n這樣的矩陣就叫對稱矩陣。也就是上三角等於下三角。對於對稱矩陣的存儲方式是存儲上三角或者下三角加對角線,假設一個n階對稱方陣,如果全部存儲使用的存儲空間是n*n,壓縮存儲則是n(n+1)/2,對角線元素為n個,除了對角線之外為n*n-n,需要存儲的元素(n*n-n)/2,加上對角線上的元素後結果就是n(n+1)/2。假設存儲一個n階對稱矩陣,使用sa[n(n+1)/2]來存儲,那麼sa[k]與ai,j的關係是:
當i>=j時,k= i(i-1)/2+j-1
當i<j 時,k =j(j-1)/2+i-1
2) 三角矩陣
上三角或下三角全為相同元素的矩陣。可用類似於對稱矩陣的方式存儲,再加上一個位置用來存儲上三角或者下三角元素就好。
a[i][j]=a[0][0] + (i* (i+1) /2+j) *size;
size為每個數據所佔用的存儲單元大小。
3) 帶狀對角矩陣
矩陣中所有非0元素集中在主對角線為中心的區域中。下圖為3條對角線區域,其他區域的元素都為0。除了第一行和最後一行僅2個非零元素,其餘行都是3個非零元素,所以所需的一維空間大小為:3n – 2;

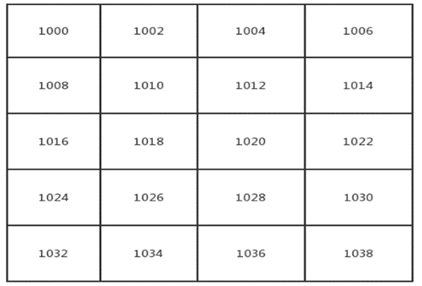
a[i][j]的內存地址=a00首地址+ ((3 * i -1) + (j-i+1)) * size;(size為每個數據所佔用的存儲單元大小)。比如首地址為1000,每個數據佔用2個存儲單元,那麼a45在內存中的地址=1000+13 * 2=1026;
2. 稀疏矩陣及壓縮
由於特殊矩陣中非零元素的分佈是有規律的,所以總是可以找到矩陣元素與一維數組下標的對應關係,但還有一種矩陣,矩陣中大多數元素都為0,一般情況下非零元素個數只佔矩陣元素總數的5%以下,且元素的分佈無規律,這樣的矩陣稱為稀疏矩陣。
三元組順序法
如果採用常規方法存儲稀疏矩陣,會相當浪費存儲空間,因此只存儲非零元素。除了存儲非零元素的值之外,還需要同時存儲非零元素的行、列位置,也就是三元組(i,j,aij)。矩陣元素的存儲順序並沒有改變,也是按列的順序進行存儲。


三元組也就是一個矩陣,一個二維數組,每一行三個列,分別為行號、列號、元素值。由於三元組在稀疏矩陣與內存地址間扮演了一個中間人的角色,所以稀疏矩陣進行壓縮存儲後,便失去了隨機存取的特性。
行邏輯鏈接的順序表
為了隨機訪問任意一行的非零元,這種方式需要一個數組指向每一行開始元素(非零元素)的位置。這種方式適合矩陣相乘。
十字鏈表法
當矩陣中元素非零元個數和位置在操作過程中變化較大時,就不宜採用順序存儲結構來表示三元組的線性表。如在進行加減操作時,會出現非零元變成零元的情況,因此,就適合用十字鏈表來存儲。
十字鏈表的結構有五個域,一個數據域存放矩陣元,i、j 域分別存放該非零元所在的行、列。還有right、down域,right指向右邊第一個矩陣元的位置,down用來指向下面第一個矩陣元的位置。然後建立兩個數組,分別指向每行/列的第一個元素。十字鏈表在圖中也有應用,用來存儲圖。

八.圖結構存儲
圖通常用來表示和存儲具有「多對多」關係的數據,是數據結構中非常重要的一種結構。
1. 鄰接矩陣結構
圖的鄰接矩陣存儲方式是用兩個數組來表示圖。一個一維數組存儲圖中頂點信息,一個二維數組(鄰接矩陣)存儲圖中的邊或弧的信息。
設圖G有n個頂點,則鄰接矩陣是一個n*n的方陣,定義為:
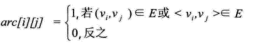
無向圖
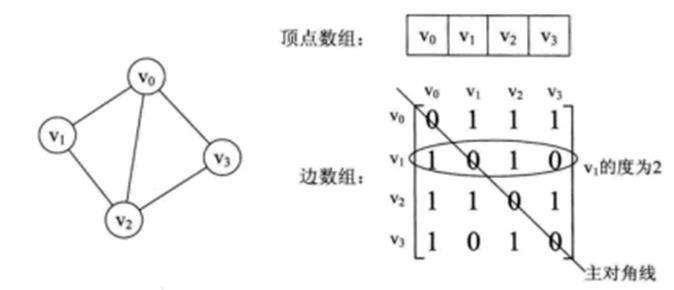
1)基於鄰接矩陣容易判斷任意兩頂點是否有邊無邊;
2)某個頂點的度就是這個頂點vi在鄰接矩陣中第i行或(第i列)的元素和;
3)vi的所有鄰接點就是矩陣中第i行元素,如arc[i][j]為1就是鄰接點;
n個頂點和e條邊的無向網圖的創建,時間複雜度為O(n + n2 + e),其中對鄰接矩陣的初始化耗費了O(n2)的時間。
有向圖
有向圖講究入度和出度,頂點vi的入度為1,正好是第i列各數之和。頂點vi的出度為2,即第i行的各數之和。
若圖G是網圖,有n個頂點,則鄰接矩陣是一個n*n的方陣,定義為:
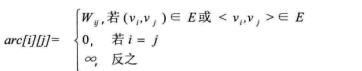
wij表示(vi,vj)上的權值。無窮大表示一個計算機允許的、大於所有邊上權值的值,也就是一個不可能的極限值。
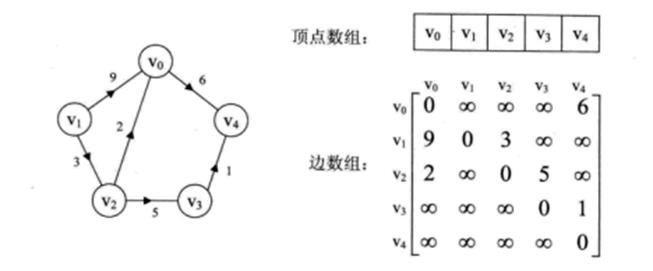
下面左圖是一個有向網圖,右圖是其鄰接矩陣。
2. 鄰接表結構
鄰接矩陣是不錯的一種圖存儲結構,但對邊數相對頂點較少的圖存在對存儲空間的極大浪費。因此,找到一種數組與鏈表相結合的存儲方法稱為鄰接表。鄰接表的處理方法:
1)圖中頂點用一個一維數組存儲,當然,頂點也可用單鏈表來存儲,不過數組較容易的讀取頂點的信息。
2)圖中每個頂點vi的所有鄰接點構成一個線性表,由於鄰接點的個數不定,所以用單鏈表存儲,無向圖稱為頂點vi的邊表,有向圖則稱為頂點vi作為弧尾的出邊表。
例如,下圖就是一個無向圖的鄰接表的結構。
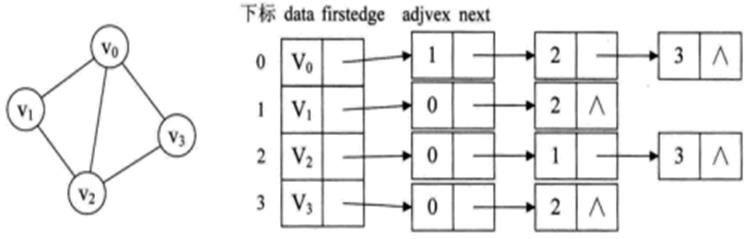
從圖中可以看出,頂點表的各個結點由data和firstedge兩個域表示,data是數據域,存儲頂點的信息,firstedge是指針域,指向邊表的第一個結點,即此頂點的第一個鄰接點。邊表結點由adjvex和next兩個域組成。adjvex是鄰接點域,存儲某頂點的鄰接點在頂點表中的下標,next則存儲指向邊表中下一個結點的指針。
對於帶權值的網圖,可以在邊表結點定義中再增加一個weight的數據域,存儲權值信息即可,如下圖所示。
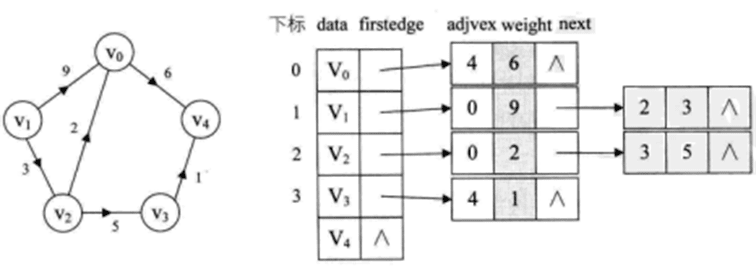
對於無向圖,一條邊對應都是兩個頂點,所以在循環中,一次就針對i和j分佈進行插入。本算法的時間複雜度,對於n個頂點e條邊來說,容易得出是O(n+e)。
3. 十字鏈表存儲
對於有向圖來說,鄰接表是有缺陷的。關心了出度問題,想了解入度就必須要遍歷整個圖才知道,反之,逆鄰接表解決了入度卻不了解出度情況。而十字鏈表存儲方法可把鄰接表和逆鄰接表結合。
重新定義頂點表結點結構,如下所示

其中firstin表示入邊表頭指針,指向該頂點的入邊表中第一個結點,firstout表示出邊表頭指針,指向該頂點的出邊表中的第一個結點。
重新定義邊表結構,如下所示

其中tailvex是指弧起點在頂點表的下表,headvex是指弧終點在頂點表的下標,headlink是指入邊表指針域,指向終點相同的下一條邊,taillink是指邊表指針域,指向起點相同的下一條邊。還可增加一個weight域來存儲權值。
比如下圖,頂點依然是存入一個一維數組,實線箭頭指針的圖示完全與鄰接表相同。就以頂點v0來說,firstout指向的是出邊表中的第一個結點v3。所以v0邊表結點hearvex=3,而tailvex其實就是當前頂點v0的下標0,由於v0隻有一個出邊頂點,所有headlink和taillink都是空的。
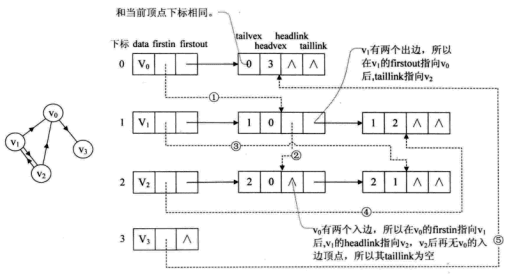
虛線箭頭的含義。它其實就是此圖的逆鄰接表的表示。對於v0來說,它有兩個頂點v1和v2的入邊。因此它的firstin指向頂點v1的邊表結點中headvex為0的結點,如上圖圓圈1。接着由入邊結點的headlink指向下一個入邊頂點v2,如上圖圓圈2。對於頂點v1,它有一個入邊頂點v2,所以它的firstin指向頂點v2的邊表結點中headvex為1的結點,如上圖圓圈3。
十字鏈表的好處就是因為把鄰接表和逆鄰接表整合在一起,這樣既容易找到以v為尾的弧,也容易找到以v為頭的弧,因而較易求得頂點的出度和入度。除了結構複雜一點外,其實創建圖算法的時間複雜度和鄰接表相同,因此在有向圖應用中,十字鏈表是非常好的數據結構模型。
九.分佈式圖存儲
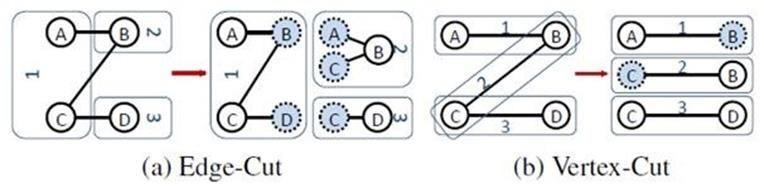
分佈式圖(巨型圖)的存儲總體上有邊分割和點分割兩種方式,目前業界廣泛接受並使用的存儲方式為點分割,點分割在處理性能上要高於邊分割。
- 邊分割(Edge-Cut):每個頂點都存儲一次,但有的邊會被打斷分到兩台機器上。這樣做的好處是節省存儲空間;壞處是對圖進行基於邊的計算時,對於一條兩個頂點被分到不同機器上的邊來說,要跨機器通信傳輸數據,內網通信流量大。
- 點分割(Vertex-Cut):每條邊只存儲一次,都只會出現在一台機器上。鄰居多的點會被複制到多台機器上,增加了存儲開銷,同時會引發數據同步問題。好處是可以大幅減少內網通信量。
雖然兩種方法互有利弊,但現在是點分割佔上風,各種分佈式圖計算框架都將自己底層的存儲形式變成了點分割。主要原因有以下兩個。
1) 磁盤價格下降,存儲空間不再是問題,而內網通信資源無突破性進展,集群計算時內網帶寬是寶貴的,時間比磁盤更珍貴。這點類似於常見的空間換時間的策略。
2) 在當前應用場景中,絕大多數網絡都是「無尺度網絡」,遵循冪律分佈,不同點的鄰居數量相差非常懸殊。而邊分割會使那些多鄰居的點所相連的邊大多數被分到不同的機器上,這樣的數據分佈會使得內網帶寬更加捉襟見肘,於是邊分割存儲方式被漸漸拋棄。
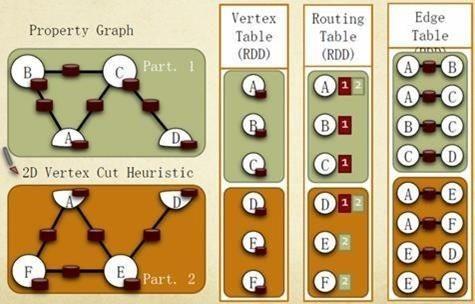
1. GraphX存儲模式
借鑒PowerGraph,使用點分割方式存儲圖,用三個RDD(Resilient Distributed Dataset,彈性分佈式數據集)存儲圖數據信息:
VertexTable(id, data): id為Vertex id,data為Edge data
EdgeTable(pid, src, dst, data):pid為PartionId,src為原頂點id,dst為目的頂點id
RoutingTable(id, pid):id為Vertex id,pid為Partion id
點分割存儲實現如下圖所示:
2. 超大規模圖存儲
超大規模圖(數十億點,數百億邊)存儲,需要分佈式的存儲架構。在圖加載時,整張圖在圖處理引擎內部被切分為多個子圖,每個計算節點被分配1個或幾個子圖進行加載。
一張有向圖的基本元素是頂點和邊,一般都具有類型和權重,邊是有向的,一條邊由:起點、終點、類型三者標識,即相同的兩點之間可以同時具有多條不同類型的邊。下面是一個簡單的帶權異構屬性圖示例:
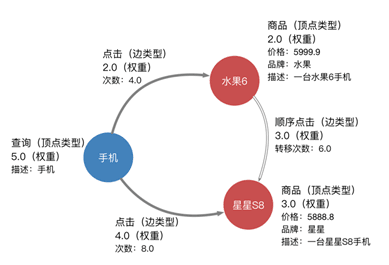
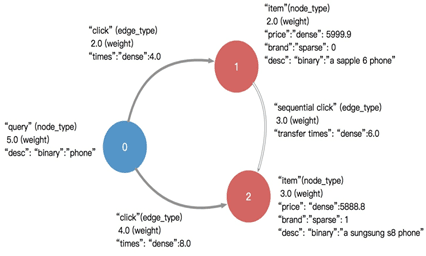
頂點以uint64標識,頂點類型、邊類型,以及點邊上的三種屬性均採用字符串描述。對於例子中的圖,需要將點邊歸類編號,得到一張可以識別的圖。
圖數據JSON格式
JSON文件由兩大部分組成,點和邊,分別存儲在JSON對象的「nodes」、「edges」中。每個節點對象包含了節點的id,type,weight以及name,type和value屬性信息字段。每個邊對象則包含這個邊相關聯的起點和終點id:src和dst,和邊相關的屬性信息。
點和邊屬性索引
- 全局hash索引:全局採樣過濾精確匹配某種屬性的點和邊。適用於全局採樣負例的時候,加上過濾條件,只採樣滿足條件的負例。支持的查詢有:eq,not_eq,in,not_in。
- 全局range索引:全局採樣過濾某種屬性在某個範圍內的點和邊。適用於全局採樣負例時,加上過濾條件採樣滿足條件的負例。支持:eq,not_eq,ge,le,gt,lt,in,not_in
- 鄰居索引: 採樣某個點的滿足某種屬性的鄰居節點。適用於鄰居採樣的時候,加上過濾條件,只採樣滿足條件的鄰居節點。支持的查詢與全局range索引相同。
圖數據二進制生成
將JSON文件轉化為分佈式圖引擎加載所需要的二進制格式,包括分片個數等。
… 廣告搜索場景:圖嵌入,向量化最近鄰檢索網絡結構
… …
最 後
當今的計算機以運算器為中心,I/O設備與存儲器間的數據傳送都要經過運算器。相對處理器的速度來說,IO設備就慢多了。就SSD來說,IO也是遠低於RAM的讀寫速率。IO讀寫的耗時常常成為性能的瓶頸點,所以要減少IO次數,且隨着數據量增加,IO次數穩定是數據存儲引擎的核心要務。當然了,CPU等指標也是很重要的。
文中倒排索引存儲章節介紹了Lucene如何實現倒排索引的關鍵技術,如何精打細算每一塊內存、磁盤空間、如何用詭譎的位運算加快處理速度,但往高處思考,再類比一下MySql就會發現,雖然都是索引,但實現機制卻截然不同。
很多業務、技術上要解決的問題,大都可以抽象為一道算法題,複雜問題簡單化。每種數據存儲引擎都有自己要解決的問題(或者說擅長的領域),對應的就有自己的數據結構,而不同的使用場景和數據結構,需要引入不同的索引,才能起到最大化加快查詢、檢索的目的。
… ……


