CSAPP =2= 信息的表示和處理
思維導圖
預計閱讀時間:30min

閱讀書籍 《深入理解計算機系統 第五版》
參考視頻 【精校中英字幕】2015 CMU 15-213 CSAPP 深入理解計算機系統 課程視頻
參考文章 《深入理解計算機系統(2.1)—信息的存儲與值的計算》
《深入理解計算機系統(2.2)—布爾代數以及C語言上的位運算》
《深入理解計算機系統(2.3)—整數的表示方式精解》無符號與補碼編碼(重要)》
《深入理解計算機系統(2.4)—C語言的有符號與無符號、二進制整數的擴展與截斷》
《深入理解計算機系統(2.5)—二進制整數的加、減法運算(重要)》
《深入理解計算機系統(2.6)—二進制整數的乘、除法運算(重要)【困難度高】》
《深入理解計算機系統(2.7)—二進制浮點數,IEEE標準(重要)》
《深入理解計算機系統(2.8)—浮點數的舍入,Java中的舍入例子以及浮點數運算(重要)》
原文鏈接 《旻天Clock:CSAPP =2= 信息的表示和處理》://zhuanlan.zhihu.com/p/220185200
先出幾道題考考各位道友:
- 《問》在對精度有嚴格要求的程序中,為什麼禁止使用浮點型,精度為什麼會丟失?《、問》《答》《、答》
- 《問》如何不使用 if/else 來實現返回數字絕對值的方法(注意考慮整型和浮點型兩種)《、問》》《答》《、答》
- 《問》為什麼 (3.14 + 1e10) – 1e10 != 3.14 + (1e10 – 1e10)《、問》《答》《、答》
二、信息的表示和處理
通過上一章 CSAPP =1= 計算機系統漫遊 的學習,相信各位道友已經對計算機系統的硬件和軟件有了一些了解。
同時也知道應用程序在計算機中是以二進制的形式存儲和傳遞的。
但光靠 0 和 1 這兩個數字又是如何表示各種錯綜複雜的程序的呢?明明我們更習慣十進制,又為何要發明二進制呢?為啥不是三進制、五進制的?
再抄一段左瀟龍大神的引言:
我們很難想像,0 和 1 這兩個再簡單不過的數字,給計算機科學帶來了徹底的改變。對於無法與人腦相比的計算機來說,簡單的 0 和 1 卻是最適合它們的數字。
不過同樣的二進制往往代表不同的含義,它們必須被賦予上下文,才能有具體的含義。比如,如果知道二進制是要表示布爾類型,那麼我們就知道 1 是 true,0 是 false。
對於二進制所表示的
數字來說,主要有三種,即無符號、補碼以及浮點數。不過計算機對於固定類型的二進制數字往往都有位數限制,比如 int 類型使用四個位元組,因此對於無符號整數只能表示 0 ~ 4294967296(2^32,42億+),再大的數字就沒法表示了(溢出)。
而對於有符號整數,產生的溢出結果就更是會超出預期了。
而浮點數就是二進制世界中的科學計數法,但它也有自己的限制,比如開始的 (3.14 + 1e10) – 1e10 != 3.14 + (1e10 – 1e10)。
下面就請帶着這些興趣,來了解信息在計算機中的表示和處理吧。
2.1 信息的存儲
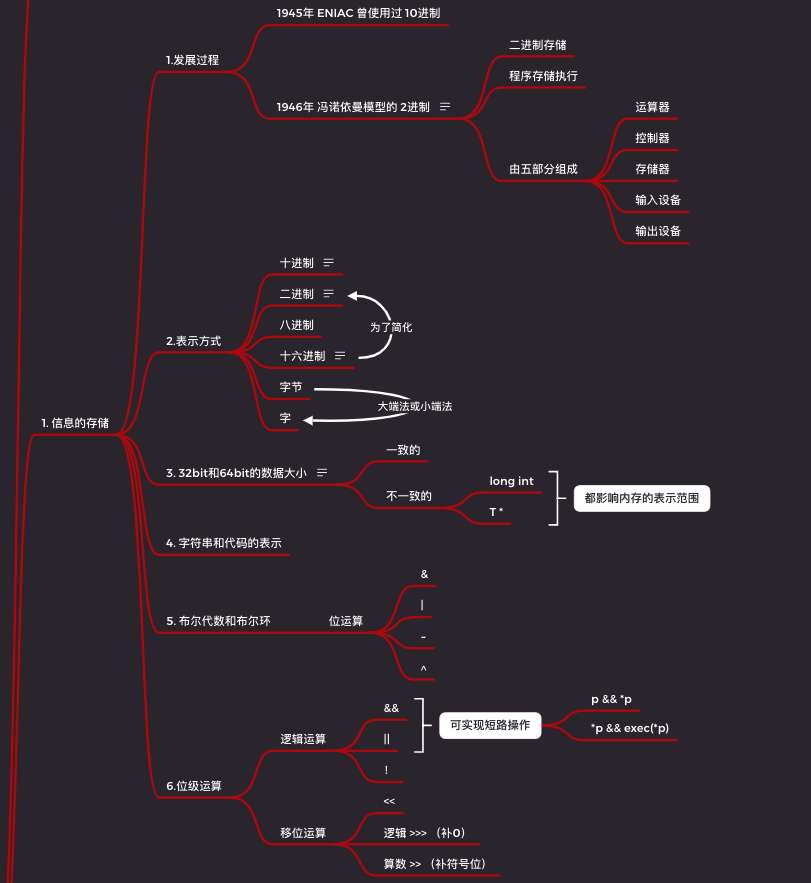
2.1.1 二進制的發展過程
在 1945年,世界上曾出現過一款 十進制 計算機。
但因為二值信號更容易在計算機中表示、存儲和傳輸,如紙帶的有孔和無孔,導線上的高電壓和低電壓。而且基於二值信號的電子電路非常的簡單可靠,造價也更加經濟。
所以在 1946 年,馮諾依曼模型誕生。馮諾依曼模型有以下三個特點:
- 計算機的數值編碼採用二進制;
- 計算機應該按照程序順序執行;
- 計算機由(運算器、控制器、存儲器、輸入設備、輸出設備)五個部分組成。
2.1.2 數據在計算機的表示形式
二進制
在物理上是利用二極管的特性,使二極管的兩端產生不同的高低電壓。
而邏輯上就採用0和1來對應上面所說的高低電壓,1表示高電壓0表示低電壓。
十六進制
二進制表示法太長還不直觀,而四位一組正好可以用一種叫做十六進制的模式表示。
這樣一個位元組的表示範圍就從 00000000 ~ 11111111 變成了 0x00 ~ 0xFF。
位元組
大多數計算機使用 8 個位(bit)的塊取名為位元組(byte),用來作為內存分配和尋址的最小單位。
而上章中操作系統(OS)會將存儲器抽象為一個巨大的位元組數組,稱為虛擬存儲器。數組的下標稱為地址(address)。而所有可能地址的集合就稱之為虛擬地址空間。
編譯器和運行時系統的一個任務就是將存儲空間劃分為更容易管理的單元,來存放不同的程序對象,如程序的代碼、數據。
例如:C中的一個指針的值(不論類型)都是某個或某幾個位元組塊中第一個位元組的虛擬地址。而C編譯器會把指針和類型關聯,這樣C編譯器就可以根據指針值的類型,生成不同的機器級代碼,來訪問指針指向處向下相鄰的幾個位元組了。
儘管C編譯器維護着這個類型信息,但生成的機器級程序(彙編)並沒有關於數據類型的信息。
字
每台計算機都有一個字長(word size),指明長整數和指針的數據位長。
因為虛擬地址就是以這樣的字來編碼的,所以字長決定的最重要系統參數就是可表示的虛擬地址最大值。
2.1.3 數據大小
由於計算機位數的不同,會造成在數據類型的存儲上,採用的位數略有不同,下表是在32位和64位機器下,C語言當中的數字數據類型需要的位數。
C 聲明 32 bit機器 64位機器
--------------------------------------------
char 1 1
short int 2 2
int 4 4
long int 4 8
T * 4 8
float 4 4
double 8 8
程序員應該盡量的使自己的程序可以兼容更多類型的機器,這被稱作可移植性。而提高可移植性的一方面就是使程序對不同機器的數據類型大小不敏感。
2.1.4 尋址和位元組順序
對於跨越多個位元組的程序對象(程序對象指令、數據或者控制信息等,是程序當中對象的統稱)來說,我們需要制定兩個規則,才能唯一確定一個程序對象的值。比如對於 int 類型的值 0x01234567 來說,如果我們要根據虛擬內存地址去獲取這個整數值,那麼需要確定:
- 這個 int 的 起始虛擬地址 是多少
- 這四個位元組的排列順序是
01 23 45 67(看着順眼的大端法) 還是67 45 23 01(看着奇怪的小端法)
計算機通常會把需要多個位元組存放的對象放在相鄰的一段空間內,並把地址最小的位元組地址來代表對象地址。如:
0x100 0x101 0x102 0x103
01 23 45 67
而大多數時候,機器的位元組順序是不可見也不用關心的,但有幾種情況例外:
- 當小端法機器的數據要發送給大端法機器時(或情況對調),字里的位元組就成了反序的了。所以為了避免這個問題,網絡應用程序的代碼編寫必須遵守相應的網絡標準,以確保發送方機器將它的內部表示轉換成網絡標準,接受方在將網絡標準轉為自己的內部表示。
- 檢查機器級程序時,對表示整數數據的位元組順序有嚴格要求。
- 當編寫規避正常的類型系統的程序時,如強制類型轉換時。
強制類型轉換
計算機在解釋一個數據類型的值時主要有四個因素:
- 位排列規則(大端或者小端)
- 起始位置
- 數據類型的位元組數
- 數據類型的解釋方式
如,在大端法的機器上,起始位置為 0x100 的位置有個值為 0x61FFFFFF 的整數對象。
對於特定的系統來說,位排列規則和起始位置已經確定,而後兩種因素可以通過強制類型轉換來改變。
假如代碼如下:
#include <stdio.h>
int main(){
unsigned int x = 0x61FFFFFF;
int *p = &x;
char *cp = (char *)p;
printf("%c\n",*cp); # print a, 因為 a 的 ASCII 編碼為 61
}
2.1.5 表示字符串
C 中的字符串被編碼為一個以 null (也就是零0)結尾的字符數組,而每個字符又是由某種標準編碼表示,比較常見的編碼有 ASCII、GBK、UTF-8 等。
各編碼的來歷和區別,可以看我的另一篇文章《計算機編碼的發展史》
如果我們打印一個 ASCII 字符串如 「12345」 的位元組編碼,可以得到結果 「31 32 33 34 35 00」,並且在任何系統都是這些值和這個順序。因而,文本數據比二進制數據具有更強的移植性。
2.1.6 表示代碼
源代碼
源代碼對於機器而言就是文本數據,上面我們說了,文本數據具有很強的移植性。
二進制代碼
不同機器類型使用不同的且不兼容的指令和編碼方式。即便處理器支持相同的機器級指令,也不一定會完全是二進制兼容的。二進制代碼很少能在不同的機器和操作系統組合之間移植。
即便是 JVM 這種的虛擬機(或叫解釋器)也不能做到絕對的二進制重用。因為 JVM 只是將
.class這種特殊的二進制轉化為真正底層處理器可執行的機器指令。
2.1.7 布爾代數和環
因為二進制值是計算機編碼、存儲和執行的核心,所以圍繞數值 0 和 1 已經演化了非常豐富且有趣的數學知識體系。
布爾代數
這起源於 1850 年左右,喬治丶布爾的工作,他將二進制的 1 和 0 翻譯為邏輯值 TRUE(真)和 FALSE(假),並設計出一種代數來研究命題邏輯的屬性,因此這套理論被稱為 「布爾代數」。
我們不需要去徹底的了解這個知識體系,但是裏面定義了幾種二進制的運算,卻是我們在平時的編程過程當中也會遇到的。
下面是展示了四種最基本的二進制運算:
非 ~
-------------------
0 1
1 0
與 & 0 1
-------------------
0 0 0
1 0 1
或 | 0 1
-------------------
0 0 1
1 1 1
異或 ^ 0 1
-------------------
0 0 1
1 1 0
同時這種運算可以擴展到 N 位二進制上,形成集合的四種運算 補集、交集、並集、差集:
假如有兩個集合如下:
a = [01101001] ==集合抽象==> {0, 3, 5, 6}
b = [01010101] ==集合抽象==> {0, 2, 4, 6}
則對於運算有:
操作 描述 二進制表示 集合表示
---------------------------------------------------------
~a 對a集合求補集 [10010110] {1, 2, 4, 7}
a&b 求a、b集合的交集 [01000001] {0, 6}
a|b 求a、b集合的並集 [01111101] {0, 2, 3, 4, 5, 6}
a^b 求a、b集合的差集 [00111100] {2, 3, 4, 5}
布爾環
布爾環的概念就更加的偏向數學了,這裡我也只是了解了個大概。不過這裡有一個概念一定要了解,不然之後的二進制運算就會迷糊了。
什麼是模數運算?
一個代數就是被定義為一組元素、一些關鍵運算和一些重要元素的環,比如二進制的<{0,1}, ~, &, |, ^, 0, 1>。
而模數運算也構成了一個環,對於模數 n,代數環表示為 <Zn, +n, -n, *n, 0, 1>,其中各部分定義如下:
Zn = {0, 1, ---, n-1}
A +n B = (A + B) mod n
A *n B = (A * B) mod n
如果是整數運算,直觀上可以感受到 A + B 在大於 n 的情況下顯然不等於 (A + B) mod n,而模數運算就認為他們是相等的,這也就是二進制產生溢出時結果偏離直覺的情況了。
除了數學家,還有誰關心布爾環呢?
當播放髒的或損壞的 CD 時,為了對錯位糾錯會利用糾錯算法,而這算法的核心理論就是布爾環了。
2.1.8 C 中的位級運算
在C語言中,也支持位運算,而它的計算方式就是布爾代數中的位運算。
非、與、或、異或
我們最常使用的是掩碼方式。
比如我們知道一個整數 x = 0x76543210,如果我們想取得這個整數的最後兩個位元組的整數值 0x10 的話,就可以採用位運算。就像下面這樣。
0x76543210
& 0x000000FF
Out 0x00000010
在比如我們想實現一個對整數參數的交換函數,C的源碼如下:
void swap(int *x, int *y) # 初始 x = a, y = b
{ # 技巧 a ^ a = 0
*x = *x ^ *y; # 此時 x = a ^ b
*y = *x ^ *y; # 此時 y = x ^ b = a ^ b ^ b = a ^ 0 = a
*x = *x ^ *y; # 此時 x = x ^ a = a ^ b ^ a = 0 ^ b = b
}
邏輯運算
C語言中的邏輯運算有||、&&和!,這比較容易與剛才的|,&和~搞混。邏輯運算比較特別,在這種運算的結果中認為所有非 0 的數值都是 true,而為 0 的則為 false。
!0x41 (true) = 0x00 (false)
!!0x41 (true) = 0x01 (true)
0x105 (01101001) & 0x85 (01010101) = 0x65 (01000001)
0x105 (true) && 0x85 (true) = 0x01 (true)
同時邏輯運算有短路的特性,利用指針的短路特性可以寫出更優雅的代碼,如 p && *p,如果 p 沒有值(0,null)就是 false,那 && 就不會計算後面的語句了,因為表達式一定是 false,這樣就可以避免空指針的問題。
移位運算
移位運算分為兩種,左移和右移。
對於一個n位的二進制數[Xn-1, Xn-2, —, Xn]來說,如果將它進行左移運算,則 x << k = [X(n-1-k), X(n-2-k), ---, X0, 0, ---, 0],等於丟棄了左側 k 個最高位,右側補 0。
而對於右移運算與左移是類似的,只不過為了照顧有符號數,分為了邏輯右移和算數右移。
- 對於邏輯右移來說,
x >> k=[0, ---, 0, Xn-1, Xn-2, ---, Xk] - 而對於算術右移來說,
x >> k=[Xn-1, ---, Xn-1, Xn-1, Xn-2, ---, Xk]。
需要注意的是,
x >> k應該是x >> (k mod n)的簡寫,什麼意思呢?比如:
對於八位的二進制00000001 << 7 == 10000000,這沒有問題。
但00000001 << 8 == 00000001 << (8 mod 8) == 00000001
2.2 整數的表示
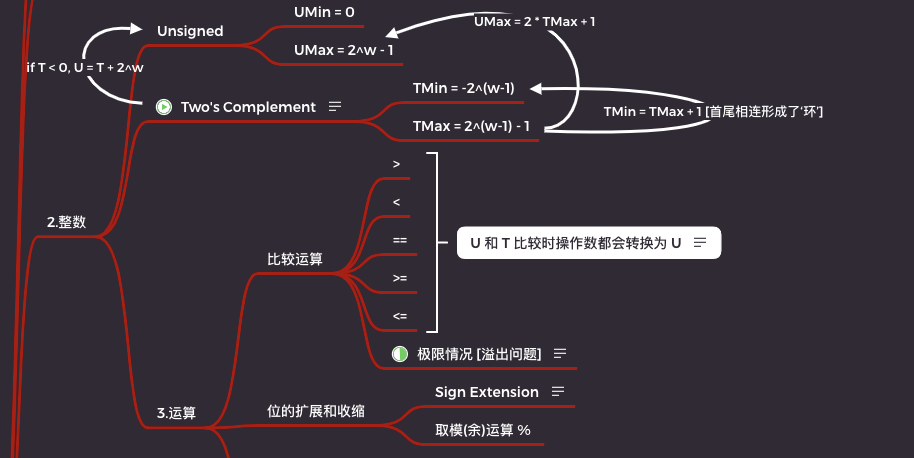
上面我們已經了解了數據在計算機中的表示,以及基於 0 和 1 產生的數學理論學科布爾代數和布爾環。
接下來我們就來深入的學習一下計算機是如何表示一個整數的。
2.2.1 整型數據類型
整數分為有範圍的整數(有符號數)和有範圍的非負整數(無符號數)兩種。
還是以C語言為例,八種整數類型的表示範圍如下圖所示:
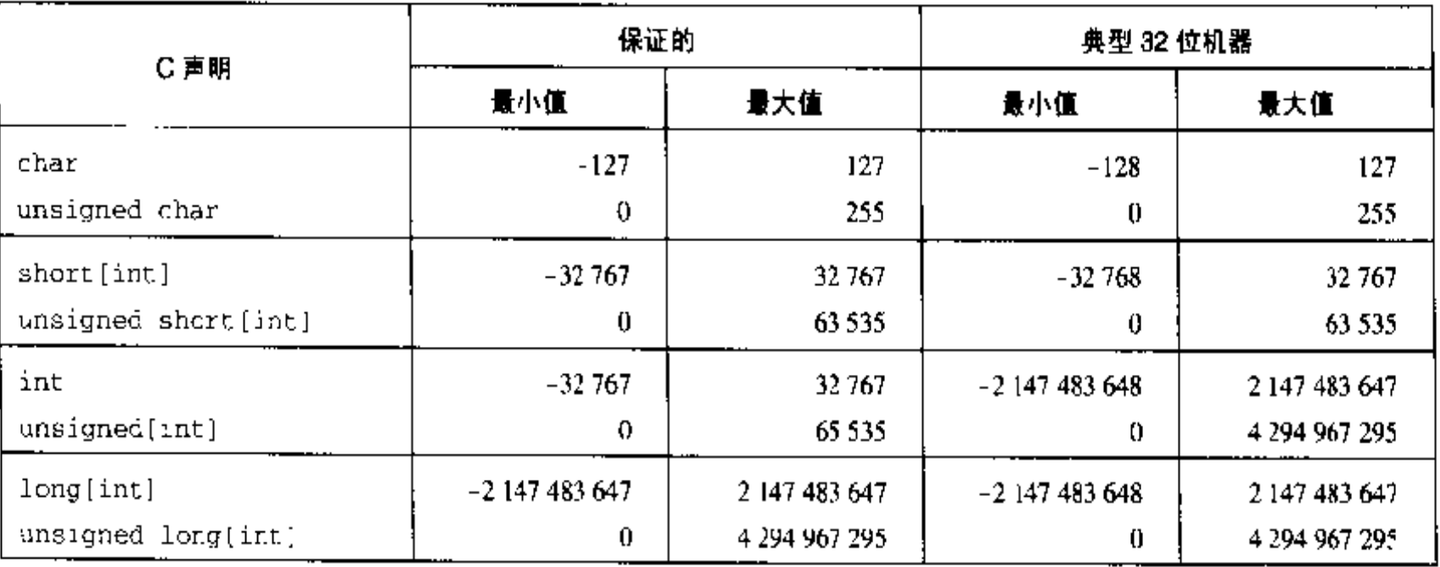
這裡可以說一個小技巧,
2 ^ 10 = 1024這個大家肯定早已爛熟於心。所以可以估計2 ^ 10 = 10 ^ 3, 也就是二進制:十進制 = 10:3。
那麼 int 是 4 位元組 32 位長度,所以表示範圍大約就是2 ^ (2+30) = 4 * (2^30) = 4 * (10^9)。
2.2.2 無符號和補碼
無符號整數
從上面可以看到每一種整數類型都可以加 unsigned 關鍵字,來表示一個非負整數,也就是無符號數。
對於一個 w 位的二進制來說,它的無符號表示為以下形式:

看不懂公式不要緊,但是大家應該都知道二進制轉十進制步驟是:
二進制 11101011
用集合表示為 {7, 6, 5, 3, 1, 0}
則十進制為 (2^7) + (2^6) + (2^5) + 0 + (2^3) + 0 + (2^1) + (2^0)
因此我們可以看出無符號整數的最大值就是全集,也就是全是 1 的時候,得到的最大值我們用 UMax 表示。對於 w 位的二進制,表示的十進制值為 (2^w)-1。
而最小值不用說了,就是二進制全 0 時表示的十進制 0。
原碼整數
可以看出無符號整數是無法表示負數的,這在科學且嚴謹的計算機中是無法接受的。因此我們需要像個辦法表示負數,那就是把最高位定義為符號位,0 表示整數、1 表示負數,其餘位的意義不變。
但原碼錶示又產生了新的問題:
- 表示的 0 有兩種情況,+0(0000) 和 -0(1000)
- +1(0001) 和 -1(1001) 相加等於 -2(1010)
反碼整數
接着為了解決原碼的問題,又引入了反碼的概念。反碼比原碼稍微麻煩一點,但概念還是十分簡單,就是先用0+無符號表示正數,然後1+按位取反表示相應的負數。
比如 5(0101) + -5(1010) = -0(1111)
不同通過上面例子我們也看到了,正負 0 的問題還是沒有解決
補碼整數
重頭戲來了,補碼是什麼,在學校老師可能是這麼描述:
補碼正數= 反碼正數= 如:+1 = 0001
補碼負數= 反碼負數+1= 如:-1 = 1110 + 1 = 1111
這麼描述沒毛病,而且簡單粗暴,但實際上,他最先的定義是這樣的:
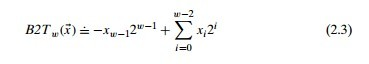
意思就是最高位的十進制含義取反,這聽着好像沒有老師總結的規律好,但是我們看例子:
二進制 11101011
用集合表示為 {-7, 6, 5, 3, 1, 0}
則十進制為 -(2^7) + (2^6) + (2^5) + 0 + (2^3) + 0 + (2^1) + (2^0)
也就是沒有什麼取反,沒有加一,還是無符號數的那一套,只不過對最高位相減,可以更快的明白當初前輩們設計的初衷,更快的將補碼轉為十進制。
作為目前還在廣泛使用的二進制整數表示方式,我就在多說一點吧。參考 補碼是誰發明的,它的最初作用是什麼?
補碼出現就是為了解決三個重要問題:1. 表示負數;2. 不要雙 0 問題產生的二義性;3. 可以用加法來代替減法。
先來回顧一下數學裏面的加法。首先畫一個數軸,在有限集合里它會是一段線段:

所以表示 1 + 2 = 3 是因為在 1 處的一個點移動兩個單位到了 3 處。
減法也是相同的道理。
而表示 4 + 4 = 8 會因為線段不夠長而無法表示,但會知道這個值為 7 + 1,如果延伸數軸即可表示。
而計算機所能表示的數軸是不能無限延伸的,結合我們之前學習的布爾環可知,它不像是一個線段,更應該是一個如下的環:
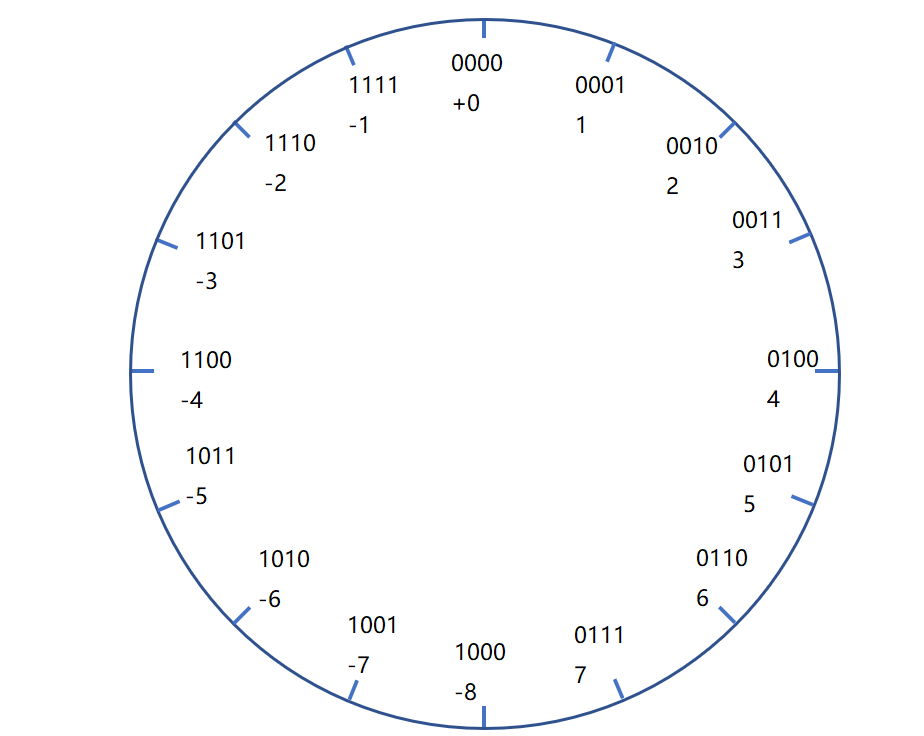
同樣表示 1 + 2 = 3 ,假如在 1 處的一個點順時針(加法)移動兩個單位到了 3 處。
而表示 4 + 4 = -8 會因為環結構停在 -8 處,這也就是所謂的正溢出了。
同時也能看出對於補碼最小值 TMin = -2^(w-1),而 TMax 比 Tmin 的絕對值少 1(因為給了0),所以 TMax = 2^(w-1) - 1
總結
所以總結一下發展過程,不要去記規則,而是去想像當初因為什麼目的去這樣設計:
無符號數 => 原碼 => 反碼 => 補碼
簡單有用 => 雙 0 問題 => 雙 0 問題 => 能加能減
沒有負數 => 能加不能減
2.2.3 補碼和無符號的轉換
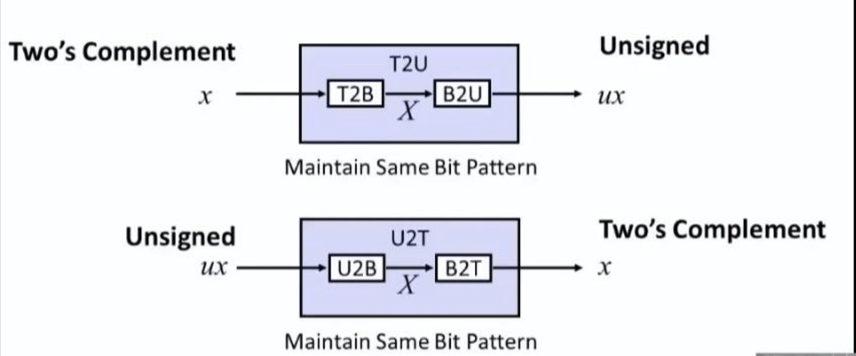
關於轉換很簡單,就是按照原始規則先轉為二進制,再按照目標規則轉為十進制即可。
簡單總結一下規則:
- 補碼的正數和無符號正數表示一樣;
- 補碼的負數等於無符號數
-2^w。T(1110) = U(8+4+2) - 2^4 = U(14) - 16 = T(-2) - UMax = Tmax * 2 + 1
關於總結三,我再詳細說一下。比如
TMax = 0111,UMax = 1110 + 1,而0111 -> 1110是什麼關係,不就是左移一位(乘2)了嗎!
2.2.4 C中的有符號數和無符號數
儘管 C 標準沒有指定使用哪種有符號數編碼(原碼、反碼、補碼),但幾乎所有機器都使用二進制補碼編碼。而 C 中的大多數數字都是有符號的,如果想創建一個無符號常量,則必須在後綴加上字符 U 或者 u。
C 允許兩者之間的轉換,原則上二進制位表示保持不變,解釋方式改變,相當於我們上面說的轉換規則。
轉換一般發生在強制類型轉換時,分為顯示和隱式的情況,如:
int tx, ty
unsigned ux, uy
# 顯示類型轉換
tx = (int) ux;
uy = (unsigned) ty;
# 隱式類型轉換
tx = ux
uy = ty
注意,當一個表達式中同時出現有符號和無符號兩種時,那麼 C 會隱含的將有符號數強制轉化為無符號數處理,也就是負數會變成非負的。
參數1 操作符 參數2 結果 原理
0 == 0U 1 (true) -
-1 < 0U 0 (false) T(-1) = UMax > 0U
UMax/2 > TMin-1 0 (false) TMin = UMax/2, TMin = UMax/2 - 1 < UMax/2
TMax > (int)UMax/2 0 (false) int(UMax/2) = 溢出TMin < TMax
所以,在以後我們需要跨類型比較的時候,可以將極限和特殊值帶入表達式,這將更容易得到驗證結果。如將 0、Tmin、Tmax、UMax 等帶入表達式。
2.2.5 位數擴展
當我們將一個短整型的變量轉換為整型變量時,就涉及到了位的擴展,此時由兩個位元組擴充為四個位元組。
擴展的高位就是補充符號位。對於正數而言,高位補 0 明顯不會對值造成改變。
而對於負數,高位補符號位 1,雖然不明顯,但確實結果值也沒變化。
下面我來分析一下原因:
假如原本的二進制為: 1100 = -8 + 4 = -4
先擴展一位到五位後為: 11100 = -16 + 8 + 4 = -4
看兩次不同,其實 -16 + 8 = -8,和擴展前是一樣的。
2.2.6 位數截斷
正所謂「由奢入簡易,由簡入奢難」。位數擴展概念簡單還不會影響表示結果,但位數截斷卻會對表示結果造成很大影響。
截斷和擴展相反,它是將一個多位二進制序列截斷至較少的位數,也就是與擴展是相反的過程。
回憶一下之前的布爾代數或者上面的補碼環。所以對於位數的截斷就是一個取模運算。
2.2.7 關於有符號和無符號的建議
可以看到在進行強制類型轉換的時候,可能會出現與直覺不相符的情況,而這些不相符的情況很容易導致程序錯誤。
舉例1:
int arr[] = [1,2,3,4,5]
unsigned i
for(i=4; i >= 0; i--){
# i 到 0 之後不會停止循環,而是會變成 UMax
print(arr[i])
}
舉例2:
int arr[] = [1,2,3,4,5]
int i
for(i=1; sizeof(arr) - i >= 0; i++){
print(arr[i-1])
}
sizeof 會返回一個 unsigned,結果和例子1產生相同bug。
避免這種錯誤的一個有效辦法就是不使用無符號數,實際上除了C以外,很少有語言支持無符號整數。
2.3 整數運算
剛入門的程序員有時會發現神奇的一幕,兩個正數相加竟然得到了一個負數。
而且移項操作有時也不可靠了,如 x > y 但 x-y < 0。
而這些問題或者說特性就是計算機運算的有效性造成的,雖然現在的高級編程語言已經很少出現這種問題了,但理解計算機在二進制運算上的細微之處能夠幫助我們寫出更可靠的代碼。
2.3.1 無符號加法
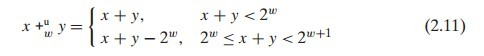
無符號的加法相對簡單,只要理解了前面對 位數截斷 的概念即可。而需要截斷的表達式就是所謂的 溢出。
溢出在我們的數學認知上是違反常理的,但對計算機而言,它是沒出錯的。這點一定要記得,因為之後我們還會遇到正溢出、負溢出和乘法溢出的問題。
2.3.2 二進制補碼加法
對於補碼的加減法,我們在前面的補碼環處已經介紹了,這裡不做過多介紹。我重點說一下溢出的問題。
- 正溢出:兩個正數相加,理想值為正數,結果卻返回了負數。
- 負溢出:兩個負數相加,理想值為負數,結果卻返回了正數。
2.3.3 二進制補碼的非
對於補碼中除 TMin 以外的每個值 x,都有唯一的一個加法逆元 -x,使 x + (-x) = 0。((TMin) 沒有對應的加法逆元,因為補碼的正負集合不是對稱的)。
那麼二進制又是如何實現 ~ 運算得到逆元的呢?先記着結論吧,還是老師教的 取反加一。比如 -2(1110) 的逆元為 2(0010)。
如何得來的呢?我有個新的驗證思路,就是利用截斷和溢出原理。
假如 x=-2(1110),而為了產生溢出並溢出後結果為0,則需要出現一個 1111 + 1 = 10000 截斷得 0000。
1111 是全集,減去 x 的集合,得到的就是補集(x取反)。
所以 x 的逆元就是我們常聽的 取反加一。
因為很多 CPU 只有加法器是沒有減法器的,而他們實現減法的方式就是將減法轉為加逆元的方式,雖然多了一步操作,卻省了一部分減法器的空間和造價。
2.3.4 無符號乘法
無符號乘法在概念上還算簡單:

要知道兩個 w 位的無符號數相乘,那麼最大可能需要 2w 位來表示,再結合之前說的 截斷 的原因和目的,就得出了這個結論。
2.3.5 二進制補碼乘法
這裡是我看的最懵的一部分了,這裡我就大概的說說自己的思路。首先公式是:
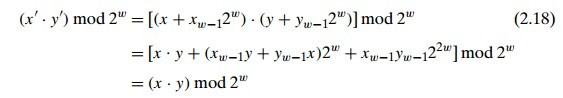
x’ 表示無符號數 T2U(x),則有 x' = x + 符號位 * (2^w),再按上圖推導,可得 無符號數的乘積取模等於補碼的乘積取模。
上面的結論也意味着機器可以使用一種乘法指令來進行有符號無符號兩種乘法指令集和硬件。
2.3.6 乘以 2 的冪
記得我們剛學乘法的時候,老師教我們 a * b 等於 b 個 a 相加。計算機雖然不會傻到真的一遍遍把 a 相加 b 次,但對於老式乘法器,也會消耗至少 12 個時鐘周期完成一次乘法。
而新式乘法器已經大大改進只需要 3 個時鐘周期即可完成一次乘法運算。
不過聰明的編譯器可以通過移位和加減法來優化乘法,只需要 2 個甚至 1 個(乘以2次冪)時鐘周期即可完成一次優化乘法。
證明過程如下:
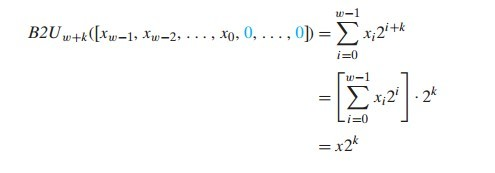
我們舉個例子:對於 x * 17,我們可以計算 x * 16 + x = (x << 4) + x ,這樣算下來的話,我們只需要一次移位和一次加法就可以搞定這個乘法運算。
而對於x * 14,則可以計算 x * 8 + x * 4 + x * 2 = (x << 3) + (x << 2) + (x << 1) 。
更快的方式我們可以這麼計算,x * 16 – x * 2 = (x << 4) – (x << 1) 。
2.3.7 除以 2 的冪
在大多數機器上,整數的除法會比乘法更慢,需要30甚至更多的時鐘周期。而且即便是現代計算機,除法也依舊很慢。
除以2的冪也可以使用右移運算來實現。無符號要邏輯右移 >>>,補碼要算數右移 >>。
我們應該知道,兩個整數如果無法整除,計算機會返回一個近似整數,而不是小數或浮點數,這就是除法的舍入問題。
舍入
對於二進制補碼的除法,對結果總是向 0 舍入的。
對於無符號除法,除以2^k等價於右移k位,如:
a = 17 = 00010001
b = 8 = 00001000 = 2 ^ 3
a/b = 2 = 00000010 = 00010001 >> 3
因為對正數而言,向下舍入就等於截斷或者取模運算。補碼的正數部分和無符號數同理。
但對於補碼的負數部分就有些麻煩了,如果我們還是單純的右移代替除法,則:
a = -17 = 11101111
b = 8 = 00001000 = 2 ^ 3
a/b = -3 = 11111101 = 11101111 >> 3
目標 = -2 = 11111110
因為對於負數而言,截斷等於向下取整,而不是向零舍入,為了補救這個問題,計算機的大佬們引入了一個新的概念偏置。也就是通過在移位之前「偏置」這個值,來修正不合適的舍入。
先來驗證一下偏置的可行性,先定義兩個符號 ┌向上取整┐ 和 └向下取整┘。則我們有 ┌x/y┐ = └(x+y-1)/y┘ 。
這一過程的證明不難理解,我們假設x = ky + r(我們考慮餘數 r > 0 且 r < y,此時會有舍入發生),則有 └(x+y-1)/y┘ = └(ky+r+y-1)/y┘ = k + └(r+y-1)/y┘ = k + 1
再拿之前的例子驗證一下:
a = -17 = 11101111
b = 8 = 00001000 = 2 ^ 3
偏置 = b-1 = 00000111 = 7
a+偏置 = -17+8 = 11110110 = -9
(a+偏置)/b = -2 = 11111110 = 11110110 >> 3
目標 = -2 = 11111110
2.4 浮點
之前我們已經學習了如何用二進制表示整數,整數可以解決計算機中很大一部分存儲、表示、運算的問題了,但還沒有辦法表示更精確的小數,這對嚴謹的計算機科學是不能接受的。
對原碼進行一點點的擴展即可表示小數,也就是二進制小數,但它有着很多的局限性卻有着很小的表示範圍。
而浮點數表示法可以更好的表示小數。但當時每個計算機製造商都有一套自己的浮點數標準,這給程序的可移植性造成了很大的困擾。有需求就有創新,最終在1985年左右,浮點數標準 IEEE-754 就應運而生了。
下面讓我們來具體的學習一下 IEEE 浮點。
2.4.1 二進制小數
儘管現在計算機中幾乎沒有使用二進制小數編碼來表示十進制小數的情況了,但並不妨礙我們了解一下小數編碼的進化史,而且學習 IEEE 也需要知道二進制小數的轉換規則。
二進制小數的表達式是這樣的:
舉例說明二進制轉換十進制的過程:
二進制小數 0101.101
過程 (2^2) + (2^0) + (2^-1) + (2^-3)
結果 5 + 5/8
明明很簡單的表示過程,為什麼最後沒有計算機廠商使用呢?因為:
- 表示精度有限,如 1/3、1/5 就只能表示近似值。
- 表示範圍有限,之前我們知道 float 和 double 的表示位數只有 32 和 64 位,如果採用這種小數表示法,並把小數點放到位數中間,那麼會使原來的表示範圍減少指數倍。
2.4.2 IEEE 浮點表示
假如用8位來表示 3.5,並規定小數點在第四位和第五位中間,那麼二進制表示位0011.1000。但想要表示 16.5 就不行了,因為整數位不夠了。
如果明知小數表示 0.5 只需要一位,那向小數部分借兩位給整數部分不就可以了,如010000.10,而浮點數(浮動的小數點)就是這麼產生的。
不過計算機的前輩們,為了獲得更好的二進制數軸和更大的表示範圍、表示精度,不會直接按照上面簡陋的浮動小數點來定義 IEEE 標準。
IEEE 標準就好比二進制界的科學計數法,比如還是 16.5 = 1.65 * (10^1),二進制就是 01.000010 >> 4。
按照科學計數法每一個浮點數可以表示為 V = (-1)s * M * (2^E)
- 符號位s:正為0 負為1,如上例的 0
- 底數位M:是一個二進制小數,如上例的 1.00001
- 指數位E:是二進制無符號整數減去偏置值所得的差,可以是負哦
上面是表示情況,IEEE 規定了三個區域來編碼上面的三種表示數。
- 符號區域s:左側第一個符號位直接編碼了符號位s
- 底數區域frac:frac = (默認不表示的
0.或1.) + 底數值M + (補位0) - 指數區域exp:指數E加偏置值的和表示的無符號二進制數
最後再說一下浮點數表示的三種精度:
表示精度 符號位 底數區域位數 指數區域位數
單精度 1 23 8
雙精度 1 52 11
擴展精度 1 15 64
偏置
《問》為什麼 exp 不用補碼錶示正負,而是要採用無符號數加偏置值方式?《、問》
《答》使用無符號數,是為了保證 exp 可以在正負之間和最小到最大之間保持持續遞增。而這種遞增狀態也會體現到表示的 浮點數上。
同時為了保證指數 0 可以在中位數處,所以偏置值是 2^(k-1)-1,最後的 -1 使的最終 的指數 E 的正數比負數多 1。
如 exp = 1010,則 -6 <= E <= 7,因為 0000 和 1111 是非規範數,另作他用。
《、答》
2.4.3 數值示例
IEEE 表示數會產生四種情況,每種有不同的十進制轉換公式,不過都很簡單:
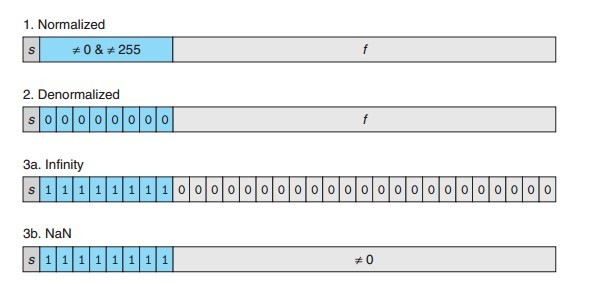
1. 規格化值
情況:當指數區域exp既不是全0也不是全1時
底數M:M = 1 + FRAC,FRAC 是 frac 區域表示的二進制小數
指數E:E = EXP - Bias,EXP 是 exp 區域表示的無符號整數,偏置值 Bias=2^(k-1)-1,k 為 exp 位數
舉例:
Bias = 2^(4-1)-1 = 7
位表示 EXP EXP-Bias FRAC M Value
0 0001 000 1 -6 0/8 8/8 8/8 * (2^-6) = 8/512
0 0001 001 1 -6 1/8 9/8 9/8 * (2^-6) = 9/512
...
0 0111 000 7 0 0 8/8 1 * (2^0) = 1
...
0 1110 111 14 7 7/8 15/8 15/8 * (2^7) = 240
2. 非規格化值
情況:當指數區域exp全0時
底數M:M = 0 + FRAC,只有 FRAC,為了實現更小的精度,並且提供了對浮點 0 的支持
指數E:E = 1 - Bias,對於非規格化值,不需計算 EXP,直接用 1 – Bias,實現數字的平滑過渡到規格化值
舉例:
Bias = 2^(4-1)-1 = 7
位表示 EXP EXP-Bias FRAC M Value
0 0000 000 0 -6 0/8 0/8 +0.0
0 0000 001 0 -6 1/8 1/8 1/8 * (2^-6) = 1/512
...
0 0000 111 0 -6 7/8 7/8 7/8 * (2^-6) = 7/512
對比 7/512 和 8/512 就可以發現為什麼非規格化值的 M = 0 + FRAC,而E = 1 - Bias。因為這樣
- 可以提供浮點0.0值
- 可以獲得更小的表示精度
- 正好保證了最大的非規格化值和最小的規格化值接軌。
3. 特殊數值-無窮大
情況:當指數區域exp全1,並且底數區域全0時
底數M:全0
指數E:全1
舉例:
0 1111 000 正無窮
1 1111 000 負無窮
4. 特殊數值-非數字
情況:當指數區域exp全1,並且底數區域也全1時
底數M:非0
指數E:全1
舉例:
0 1111 001
1 1111 010
總結
當 IEEE 以上面四種情況表示時,會產生如下的數軸分佈:

這樣的數軸分佈也就意味着,浮點數之間,可以按照無符號編碼的風格比較,因為浮點數是按編碼單調上升的。
最後在來個完整的例子:
定義一個值:float F = 15123.0
它的二進制:11101101101101
科學計數法:1.1101101101101 * 2^13
為了額外獲得一位數字表示,我們永遠使底數 M 的正數部分隱式的為 1
則 M = (1.)1101101101101
按照精度補全0,補全的 M 稱為 frac = 1101101101101 0000000000
指數 E = 13
偏置值 Bias = 2^(8-1)-1 = 127
則 exp = 13 + 127 = 140
二進制為:10001100
加上符號位 s 是正為 0
所以最終結果是 s + exp + frac
0 10001100 1101101101101 0000000000
2.4.4 舍入
之前我們已經提到過,有很多小數是二進制浮點數無法準確表示的,因此就難免會遇到舍入的問題。這一點其實在我們平時的計算當中會經常出現,就比如之前我們提到過的0.3,它就是無法用浮點小數準確表示的。
我們一般想有一種系統的辦法, 能夠找到「最接近的」匹配值,它可以用期望的浮點形式表示出來,這就是「舍入」的任務。
不同於十進制簡單的四捨五入,浮點數的舍入更豐富一點,有四種方式,分別是++向偶數舍入++、++向零舍入++、++向上舍入++以及++向下舍入++。
向上舍入:向上找到最接近且可表示的浮點數
向下舍入:向下找到最接近且可表示的浮點數
向零舍入:大於零時向下舍入,小於零時向上舍入,總之就是盡量去靠近零
向偶數舍入:平時向接近值舍入,但當要舍入的精度正好位於兩個可能值中間時,會向偶數值舍入。
舉例:
方式 1.40 1.60 1.50 -1.50 2.50
向上舍入 2.00 2.00 2.00 -1.00 3.00
向下舍入 1.00 1.00 1.00 -2.00 2.00
向零舍入 1.00 1.00 1.00 -1.00 2.00
向偶舍入 1.00 2.00 2.00* -2.00* 2.00*
主要關注最下面的一列向偶數舍入,對於1.40和1.60因為不是正好位於舍入精度的中間 *.50(二進制末尾為1的),因此向最接近的值舍入。而對於後三列,都是在向偶數舍入(使二進制末尾為0)。所以可以簡單的記為 四捨六入五取偶。
偶數舍入是默認的舍入方式,在統計中使用可以最大程度的抵消誤差。
2.4.5 浮點運算
在IEEE標準中,制定了關於浮點數的運算規則,就是我們將把兩個浮點數運算後的精確結果的舍入值,作為我們最終的運算結果。正是因為有了這一個特殊點,就會造成浮點數當中,很多運算不滿足我們平時熟知的一些運算特性。
比如加法的結合律,也就是a + b + c = a + (b + c) 的結果就不是定值,如最開始我們說的例子「為什麼 (3.14 + 1e10) - 1e10 != 3.14 + (1e10 - 1e10)」。因為對於 1e10 來說,3.14 實在太小了,如果低精度的處理器緩存了 3.14 + 1e10 的結果,代表3.14的底數就會被舍入。
對於不連續甚至會出現巨大差異的情況使用浮點數會造成問題,如果把你的餘額和馬雲的財富放到一起,你的餘額就會被舍入。
2.4.6 C語言中的浮點
C 提供了兩種不同的浮點數據類型:float 和 double。
強制轉換
當 float 或 double 強制轉換到 int 時,會對小數部分截斷,僅保留整數部分;
當 int 強制轉換到 float 時,int 原有 32 位表示整數,而 float 只有 23 位表示底數,所以可能發生舍入;
而 int 強制轉換到 double 時,因為 double 有更大的範圍,所以可以保留全部精度數值。
當 double 強制轉換到 float 時,可能會溢出為正無窮或者負無窮,也可能像 int 一樣被舍入。
擴展精度陷阱
前面我們已經知道 IA32 處理器的浮點寄存器為了獲得更高的計算精度,所以使用了一種特殊的 80 位擴展精度格式,這比在存儲器中的 float 和 double 提供了更大的表示範圍和精度。
然而當把擴展寄存器中的浮點存入到存儲器中時,不可避免的會發生舍入,這在某些時候,會產生非常奇特的結果。如下例子:
double recip(int denom)
{
return 1.0/(double) denom;
}
void do_nothing(){}
void test(int denom)
{
double d1, d2;
int t1, t2;
d1 = recip(denom);
d2 = recip(denom);
t1 = d1 == d2;
printf("test print t1: d1 %f %c= d2 %f\n", d1, t1?'=':'!', d2);
do_nothing();
t2 = d1 == d2;
printf("test print t2: d1 %f %c= d2 %f\n", d1, t2?'=':'!', d2);
}
上面的例子代碼非常簡單,也好像一眼就知道了輸出,do_nothing() 就如同它的名字一樣什麼也沒做,而 t1 和 t2 也是由相同的表達式生成的,我們預計它們是一樣的。
然而,當帶有優化選項 「-O2」 編譯,並用參數 10 去運行這個程序時,得到了如下結果:
test print t1: d1 0.100000 != d2 0.100000
test print t2: d1 0.100000 == d2 0.100000
而出現不同的原因,就是因為後計算的 d2 當時還存放在浮點寄存器中,擁有更高的精度,也就和已經從寄存器存到存儲器中的 d1 有了差異。
當調用任意函數包括 do_nothing 時,會報錯寄存器,也就使 d2 也保存到了存儲器中,所以造成了現在的輸出結果。
以上問題只是多年前的 IA32 和 GCC 的一個Bug,各位道友只需知道這麼一種情況,無須較真。如果真的出現類似情況,可以給 GCC 加上參數
-ffloat-store強制保存浮點寄存器到存儲器。
總結
計算機將信息編碼為bit(位),8位組織成一個 byte(位元組)。計算機中有不同的數據類型,分別佔用不同的位元組。
有不同的編碼方式用來表示字符串、代碼、整數和小數。他們都依賴於布爾代數和布爾環的理論基礎。
大多數機器對整數使用二進制補碼編碼,而對浮點數使用 IEEE 編碼。在位級上理解這些編碼,並且理解算數運算的數學特性,對於編寫安全穩定可移植的程序是很重要的。
無符號和補碼之間的強制類型轉換隻是改變了十進制的解釋方式,而 IEEE 和整數之間的轉換就會導致舍入和溢出問題。
對於數字的運算,要時刻小心結果溢出,不過溢出的結果也是有遵循特定規則的。對於數字的乘除法,CPU的需要的時鐘周期明顯大於加減法,所以編譯器會利用移位操作對乘除法進行優化。
完
《本章完》,期待各位道友指出文章的不足之處。
轉載請註明出處~~

