面經手冊 · 第10篇《掃盲java.util.Collections工具包,學習排序、二分、洗牌、旋轉算法》

作者:小傅哥
博客://bugstack.cn
沉澱、分享、成長,讓自己和他人都能有所收穫!

一、前言
算法是數據結構的靈魂!
好的算法搭配上合適的數據結構,可以讓代碼功能大大的提升效率。當然,算法學習不只是刷題,還需要落地與應用,否則到了寫代碼的時候,還是會for循環+ifelse。
當開發一個稍微複雜點的業務流程時,往往要用到與之契合的數據結構和算法邏輯,在與設計模式結合,這樣既能讓你的寫出具有高性能的代碼,也能讓這些代碼具備良好的擴展性。
在以往的章節中,我們把Java常用的數據結構基本介紹完了,都已收錄到:跳轉 -> 《面經手冊》,章節內容下圖;

那麼,有了這些數據結構的基礎,接下來我們再學習一下Java中提供的算法工具類,Collections。
二、面試題
謝飛機,今天怎麼無精打採的呢,還有黑眼圈?
答:好多知識盲區呀,最近一直在努力補短板,還有面經手冊里的數據結構。
問:那數據結構看的差不多了吧,你有考慮 過,數據結構里涉及的排序、二分查找嗎?
過,數據結構里涉及的排序、二分查找嗎?
答:二分查找會一些,巴拉巴拉。
問:還不錯,那你知道這個方法在Java中有提供對應的工具類嗎?是哪個!
答:這!?好像沒注意過,沒用過!
問:去吧,回家在看看書,這兩天也休息下。
飛機悄然的出門了,但這次面試題整體回答的還是不錯的,面試官決定下次再給他一個機會。
三、Collections 工具類
java.util.Collections,是java集合框架的一個工具類,主要用於Collection提供的通用算法;排序、二分查找、洗牌等算法操作。
從數據結構到具體實現,再到算法,整體的結構如下圖;

1. Collections.sort 排序
1.1 初始化集合
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");
1.2 默認排列[正序]
Collections.sort(list);
// 測試結果:[3, 4, 7, 8, 9]
1.3 Comparator排序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
- 我們使用
o2與o1做對比,這樣會出來一個倒敘排序。 - 同時,
Comparator還可以對對象類按照某個字段進行排序。 - 測試結果如下;
[9, 8, 7, 4, 3]
1.4 reverseOrder倒排
Collections.sort(list, Collections.<String>reverseOrder());
// 測試結果:[9, 8, 7, 4, 3]
Collections.<String>reverseOrder()的源碼部分就和我們上面把兩個對比的類調換過來一樣。c2.compareTo(c1);
1.5 源碼簡述
關於排序方面的知識點並不少,而且有點複雜。本文主要介紹 Collections 集合工具類,後續再深入每一個排序算法進行講解。
Collections.sort
集合排序,最終使用的方法:Arrays.sort((E[]) elementData, 0, size, c);
public static <T> void sort(T[] a, int fromIndex, int toIndex,
Comparator<? super T> c) {
if (c == null) {
sort(a, fromIndex, toIndex);
} else {
rangeCheck(a.length, fromIndex, toIndex);
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, fromIndex, toIndex, c);
else
TimSort.sort(a, fromIndex, toIndex, c, null, 0, 0);
}
}
- 這一部分排序邏輯包括了,舊版的歸併排序
legacyMergeSort和TimSort排序。 - 但因為開關的作用,
LegacyMergeSort.userRequested = false,基本都是走到TimSort排序 。 - 同時在排序的過程中還會因為元素的個數是否大於
32,而選擇分段排序和二分插入排序。這一部分內容我們後續專門在排序內容講解
2. Collections.binarySearch 二分查找
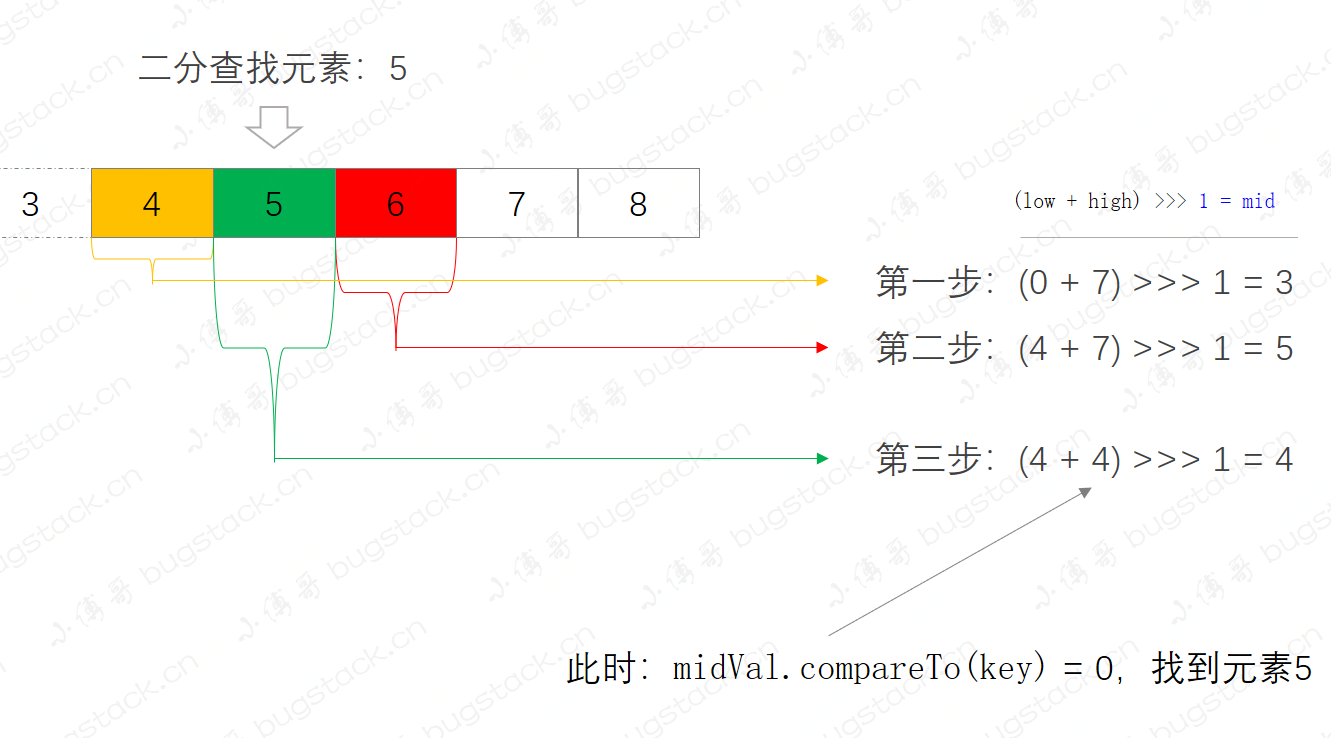
- 看到這張圖熟悉嗎,這就是集合元素中通過二分查找定位指定元素5。
- 二分查找的前提是集合有序,否則不能滿足二分算法的查找過程。
- 查找集合元素5,在這個集合中分了三部;
- 第一步,
(0 + 7) >>> 1 = 3,定位list.get(3) = 4,則繼續向右側二分查找。 - 第二步,
(4 + 7) >>> 1 = 5,定位list.get(5) = 6,則繼續向左側二分查找。 - 第三步,
(4 + 4) >>> 1 = 4,定位list.get(4) = 5,找到元素,返回結果。
- 第一步,
2.1 功能使用
@Test
public void test_binarySearch() {
List<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
list.add("7");
list.add("8");
int idx = Collections.binarySearch(list, "5");
System.out.println("二分查找:" + idx);
}
- 此功能就是上圖中的具體實現效果,通過
Collections.binarySearch定位元素。 - 測試結果:
二分查找:4
2.2 源碼分析
Collections.binarySearch
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
這段二分查找的代碼還是蠻有意思的,list instanceof RandomAccess 這是為什麼呢?因為 ArrayList 有實現 RandomAccess,但是 LinkedList 並沒有實現這個接口。同時還有元素數量閾值的校驗 BINARYSEARCH_THRESHOLD = 5000,小於這個範圍的都採用 indexedBinarySearch 進行查找。那麼這裡其實使用 LinkedList 存儲數據,在元素定位的時候,需要get循環獲取元素,就會比 ArrayList 更耗時。
Collections.indexedBinarySearch(list, key):
private static <T> int indexedBinarySearch(List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
以上這段代碼就是通過每次折半二分定位元素,而上面所說的耗時點就是list.get(mid),這在我們分析數據結構時已經講過。《LinkedList插入速度比ArrayList快?你確定嗎?》
Collections.iteratorBinarySearch(list, key):
private static <T> int iteratorBinarySearch(List<? extends Comparable<? super T>> list, T key)
{
int low = 0;
int high = list.size()-1;
ListIterator<? extends Comparable<? super T>> i = list.listIterator();
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = get(i, mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
上面這段代碼是元素數量大於5000個,同時是 LinkedList 時會使用迭代器 list.listIterator 的方式進行二分查找操作。也算是一個優化,但是對於鏈表的數據結構,仍然沒有數組數據結構,二分處理的速度快,主要在獲取元素的時間複雜度上O(1) 和 O(n)。
3. Collections.shuffle 洗牌算法
洗牌算法,其實就是將 List 集合中的元素進行打亂,一般可以用在抽獎、搖號、洗牌等各個場景中。
3.1 功能使用
Collections.shuffle(list);
Collections.shuffle(list, new Random(100));
它的使用方式非常簡單,主要有這麼兩種方式,一種直接傳入集合、另外一種還可以傳入固定的隨機種子這種方式可以控制洗牌範圍範圍
3.2 源碼分析
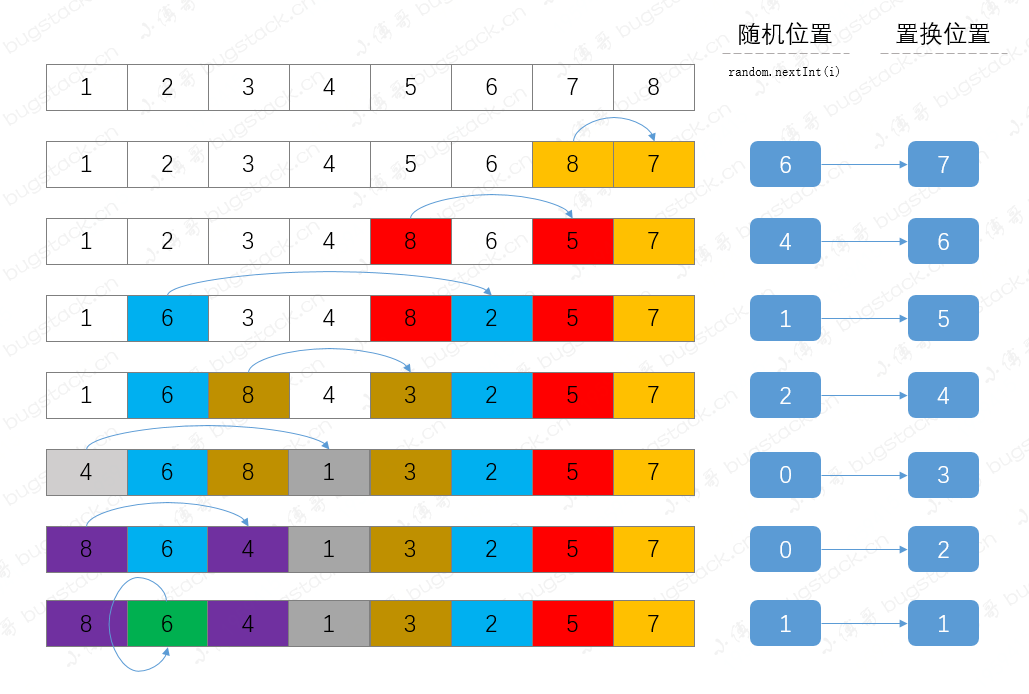
按照洗牌的邏輯,我們來實現下具體的核心邏輯代碼,如下;
@Test
public void test_shuffle() {
List<String> list = new ArrayList<String>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
list.add("6");
list.add("7");
list.add("8");
Random random = new Random();
for (int i = list.size(); i > 1; i--) {
int ri = random.nextInt(i); // 隨機位置
int ji = i - 1; // 順延
System.out.println("ri:" + ri + " ji:" + ji);
list.set(ji, list.set(ri, list.get(ji))); // 元素置換
}
System.out.println(list);
}
運行結果:
ri:6 ji:7
ri:4 ji:6
ri:1 ji:5
ri:2 ji:4
ri:0 ji:3
ri:0 ji:2
ri:1 ji:1
[8, 6, 4, 1, 3, 2, 5, 7]
這部分代碼邏輯主要是通過隨機數從逐步縮小範圍的集合中找到對應的元素,與遞減的下標位置進行元素替換,整體的執行過程如下;
4. Collections.rotate 旋轉算法
旋轉算法,可以把ArrayList或者Linkedlist,從指定的某個位置開始,進行正旋或者逆旋操作。有點像把集合理解成圓盤,把要的元素轉到自己這,其他的元素順序跟隨。
4.1 功能應用
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");
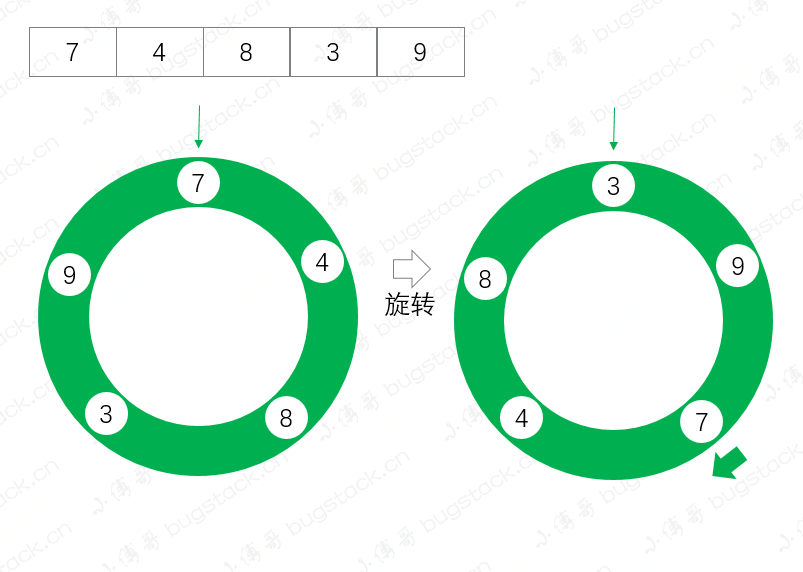
Collections.rotate(list, 2);
System.out.println(list);
這裡我們將集合順序;7、4、8、3、9,順時針旋轉2位,測試結果如下;逆時針旋轉為負數
測試結果
[3, 9, 7, 4, 8]
通過測試結果我們可以看到,從元素7開始,正向旋轉了兩位,執行效果如下圖;
4.2 源碼分析
public static void rotate(List<?> list, int distance) {
if (list instanceof RandomAccess || list.size() < ROTATE_THRESHOLD)
rotate1(list, distance);
else
rotate2(list, distance);
}
關於旋轉算法的實現類分為兩部分;
- Arraylist 或者元素數量不多時,
ROTATE_THRESHOLD = 100,則通過算法rotate1實現。 - 如果是 LinkedList 元素數量又超過了 ROTATE_THRESHOLD,則需要使用算法
rotate2實現。
那麼,這兩個算法有什麼不同呢?
4.2.1 旋轉算法,rotate1
private static <T> void rotate1(List<T> list, int distance) {
int size = list.size();
if (size == 0)
return;
distance = distance % size;
if (distance < 0)
distance += size;
if (distance == 0)
return;
for (int cycleStart = 0, nMoved = 0; nMoved != size; cycleStart++) {
T displaced = list.get(cycleStart);
int i = cycleStart;
do {
i += distance;
if (i >= size)
i -= size;
displaced = list.set(i, displaced);
nMoved ++;
} while (i != cycleStart);
}
}
這部分代碼看着稍微多一點,但是數組結構的操作起來並不複雜,基本如上面圓圈圖操作,主要包括以下步驟;
distance = distance % size;,獲取旋轉的位置。- for循環和dowhile,配合每次的旋轉操作,比如這裡第一次會把0位置元素替換到2位置,接着在dowhile中會判斷
i != cycleStart,滿足條件繼續把替換了2位置的元素繼續往下替換。直到一輪循環把所有元素都放置到正確位置。 - 最終list元素被循環替換完成,也就相當從某個位置開始,正序旋轉2個位置的操作。
4.2.2 旋轉算法,rotate2
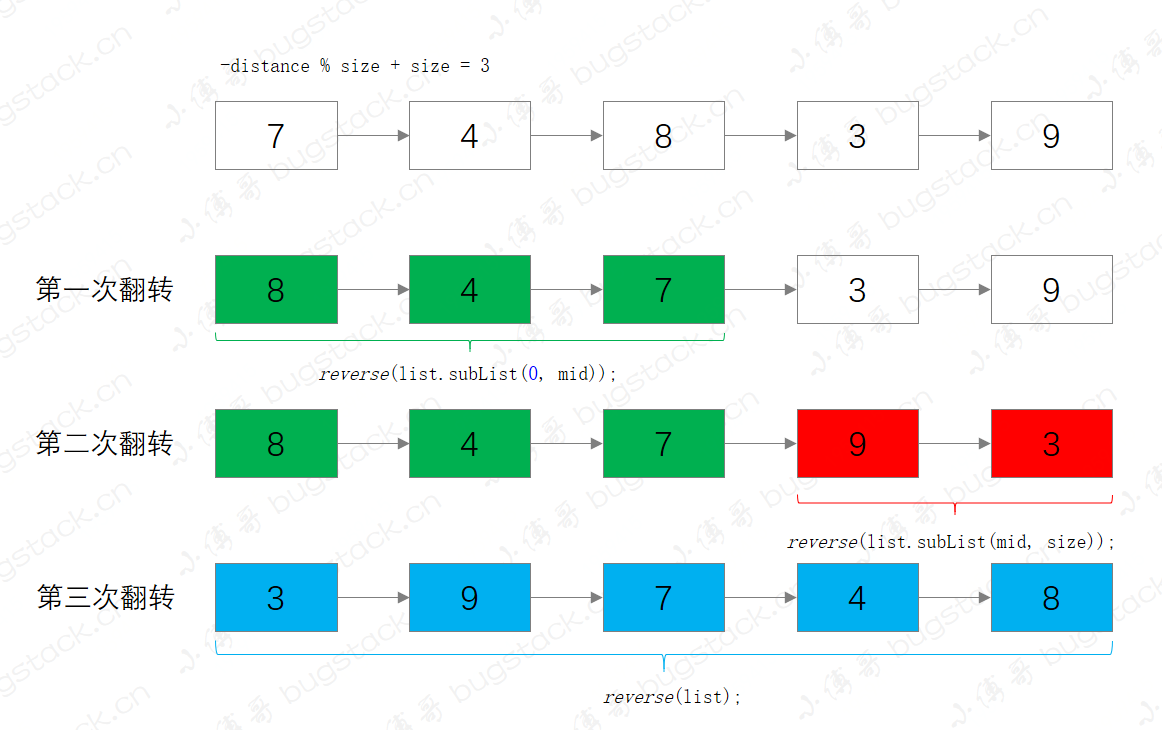
private static void rotate2(List<?> list, int distance) {
int size = list.size();
if (size == 0)
return;
int mid = -distance % size;
if (mid < 0)
mid += size;
if (mid == 0)
return;
reverse(list.subList(0, mid));
reverse(list.subList(mid, size));
reverse(list);
}
接下來這部分源碼主要是針對大於100個元素的LinkedList進行操作,所以整個算法也更加有意思,它的主要操作包括;
- 定位拆鏈位置,-distance % size + size,也就是我們要旋轉後找到的元素位置
- 第一次翻轉,把從位置0到拆鏈位置
- 第二次翻轉,把拆鏈位置到結尾
- 第三次翻轉,翻轉整個鏈表
整體執行過程,可以參考下圖,更方便理解;
5. 其他API介紹
這部分API內容,使用和設計上相對比較簡單,平時可能用的時候不多,但有的小夥伴還沒用過,就當為你掃盲了。
5.1 最大最小值
String min = Collections.min(Arrays.asList("1", "2", "3"));
String max = Collections.max(Arrays.asList("1", "2", "3"));
Collections工具包可以進行最值的獲取。
5.2 元素替換
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("8");
Collections.replaceAll(list, "8", "9");
// 測試結果: [7, 4, 9, 9]
- 可以把集合中某個元素全部替換成新的元素。
5.3 連續集合位置判斷
@Test
public void test_indexOfSubList() {
List<String> list = new ArrayList<String>();
list.add("7");
list.add("4");
list.add("8");
list.add("3");
list.add("9");
int idx = Collections.indexOfSubList(list, Arrays.asList("8", "3"));
System.out.println(idx);
// 測試結果:2
}
在使用String操作中,我們知道"74839".indexOf("8");,可以獲取某個元素在什麼位置。而在ArrayList集合操作中,可以獲取連續的元素,在集合中的位置。
5.4 synchronized
List<String> list = Collections.synchronizedList(new ArrayList<String>());
Map<String, String> map = Collections.synchronizedMap(new HashMap<String, String>());
- 這個很熟悉吧,甚至經常使用,但可能會忽略這些線程安全的方法來自於
Collections集合工具包。
四、總結
- 本章節基本將
java.util.Collections工具包中的常用方法介紹完了,以及一些算法的講解。這樣在後續需要使用到這些算法邏輯時,就可以直接使用並不需要重複造輪子。 - 學習數據結構、算法、設計模式,這三方面的知識,重點還是能落地到日常的業務開發中,否則空、假、虛,只能適合吹吹牛,並不會給項目研髮帶來實際的價值。
- 懂了就是真的懂,別讓自己太難受。死記硬背誰也受不了,耗費了大量的時間,知識也沒有吸收,學習一個知識點最好就從根本學習,不要心浮氣躁。
