python-Debug、函數裝飾器
- 2019 年 10 月 31 日
- 筆記
Debug操作:
程序出問題的時候可以用debug來看一下代碼運行軌跡,然後找找問題在哪裡
1.先給即將debug的代碼打上斷點:
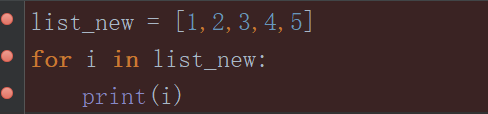
2.打完斷點之後右鍵點擊debug:
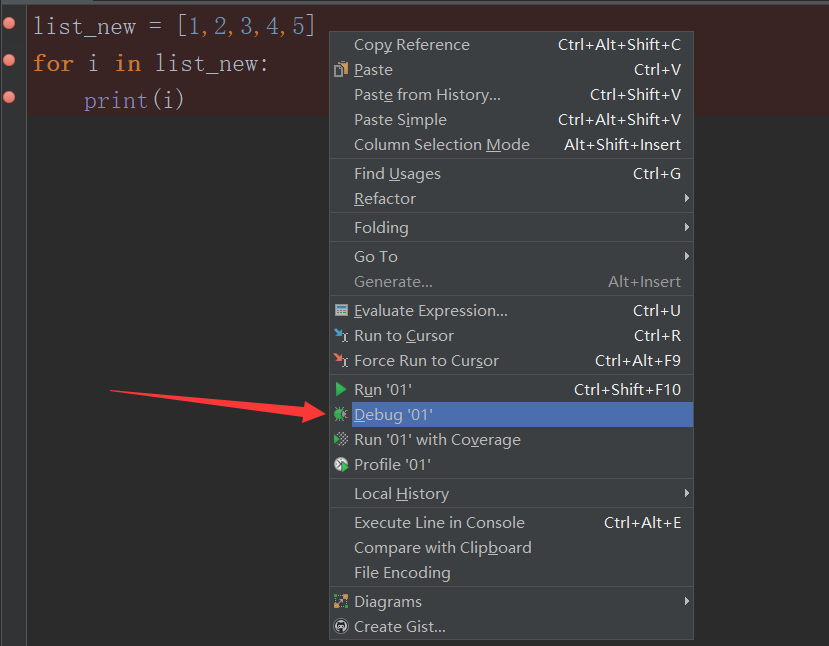
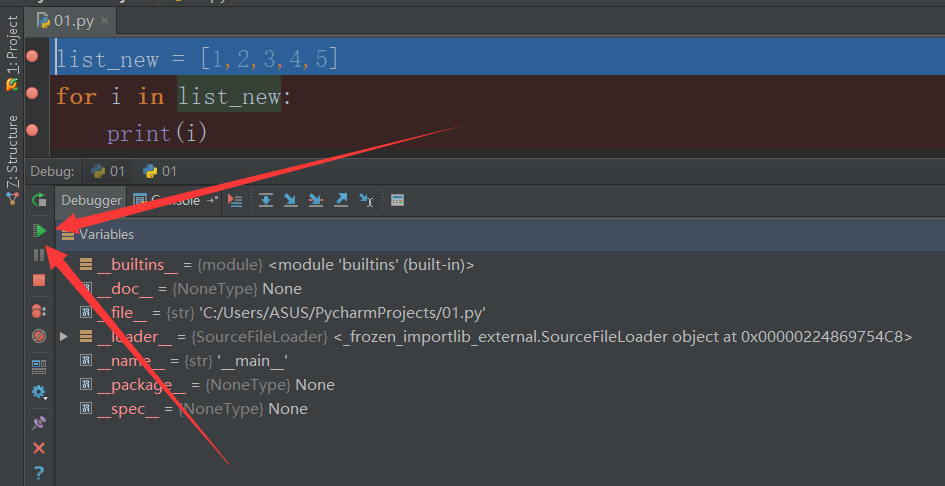
3.然後依次點擊開始按鈕讓程序開始一步步運行:
函數的裝飾器:
定義:裝飾器為其他函數添加附加功能,本質上還是一個函數
原則:①不修改被修飾函數的源代碼
②不修改被修飾函數的調用方式
有這樣一個函數:demo()
先導入時間模塊,然後函數執行時先睡兩秒,在執行打印
1 import time 2 def demo(): 3 time.sleep(2) 4 print("welcome sir") 5 demo()
現在想為demo()函數添加一個統計函數運行時間的功能,但是要遵循開放封閉原則
初步思想:
1 import time 2 def demo(): 3 start_time = time.time() 4 time.sleep(2) 5 print("welcome sir") 6 end_time = time.time() 7 print("運行時間%s" %(end_time-start_time)) 8 demo()
這樣就完美解決了,但是,我們要用可持續發展的眼光來看,假如有十萬個代碼,我們這樣一個一個添加,你不加班誰加班?
這個時候我們可以用函數的思維來解決
進步思想:
1 import time 2 def demo(): 3 time.sleep(2) 4 print("welcome sir") 5 def timmer(func_name): 6 def inner(): 7 start_time = time.time() 8 func_name() 9 end_time = time.time() 10 print("運行時間%s" %(end_time-start_time)) 11 return inner 12 res = timmer(demo) 13 res()
這樣看起來非常Nice,用到了高階函數,嵌套函數,函數閉包,但是我們違反了開放封閉原則,這個時候把res 改成 demo 就可以了
在這裡有一個命令,可以直接略過這個賦值,讓代碼看起來更美觀,執行效率更高
1 import time 2 def timmer(func_name): 3 def inner(): 4 start_time = time.time() 5 func_name() 6 end_time = time.time() 7 print("運行時間%s" %(end_time-start_time)) 8 return inner 9 @timmer 10 def demo(): 11 time.sleep(2) 12 print("welcome sir") 13 demo()
ok,代碼完成,這其實就是一個函數裝飾器,我們來解釋一下代碼運行順序

為裝飾器加上返回值:
1 import time 2 def timmer(func_name): 3 def inner(): 4 start_time = time.time() 5 res = func_name() 6 end_time = time.time() 7 print("運行時間%s" %(end_time-start_time)) 8 return res 9 return inner 10 @timmer 11 def demo(): 12 time.sleep(2) 13 return '函數demo的返回值' 14 val = demo() 15 print(val)
有參數的裝飾器:
1 import time 2 def timmer(func_name): 3 def inner(*args,**kwargs): 4 start_time = time.time() 5 res = func_name(*args,**kwargs) 6 end_time = time.time() 7 print("運行時間%s" %(end_time-start_time)) 8 return res 9 return inner 10 @timmer 11 def demo(name,age): 12 time.sleep(2) 13 return '函數demo的返回值,姓名:%s,年齡:%s' %(name,age) 14 val = demo('zrh',20) 15 print(val)
圖示流程:

迭代器:
可迭代協議:只要包括了”_iter_”方法的數據類型就是可迭代的
1 print([1,2,3].__iter__()) #打印結果:<list_iterator object at 0x000002E7F803DE88>
iterable 形容詞 可迭代的
1 from collections import Iterable #檢測一個對象是否可迭代 2 print(isinstance('aaa',Iterable)) 3 print(isinstance(123,Iterable)) 4 print(isinstance([1,2,3],Iterable))
迭代器協議:迭代器中有 __next__ 和 __iter__方法
iterator 名詞 迭代器,迭代器 就是實現了能從其中一個一個的取出值來
檢測參數是不是個迭代器:
1 from collections import Iterator 2 print(isinstance(lst_iterator,Iterator)) 3 print(isinstance([1,2,3],Iterator))
在python里,目前學過的所有的可以被for循環的基本數據類型都是可迭代的,而不是迭代器。
迭代器包含可迭代對象
可迭代對象轉換為迭代器:
可迭代對象._iter_() 這樣就變成可一個迭代器
lise_case = [1,2,3].__iter__()
迭代器存在的意義:
1.能夠對python中的基本數據類型進行統一的遍歷,不需要關心每一個值分別是什麼
2.它可以節省內存 —— 惰性運算
for循環的本質:
1 lst_iterator = [1,2,3].__iter__() 2 while True: 3 try: 4 print(lst_iterator.__next__()) 5 except StopIteration: 6 break
只不過for循環之後如果參數是一個可迭代對象,python內部會將可迭代對象轉換成迭代器而已。
生成器:
Iterator 迭代器
Gerator 生成器
生成器其實就是迭代器,生成器是用戶寫出來的
1 def generator_func(): #生成器函數 2 print(123) 3 yield 'aaa' 4 generate = generator_func() 5 print(generate) 6 print(generate.__next__()) 7 # 打印結果: 8 # <generator object generator_func at 0x0000018F3942E8C8> 9 # 123 10 # aaa
帶yield關鍵字的函數就是生成器函數,包含yield語句的函數可以用來創建生成器對象,這樣的函數也稱為生成器函數。
yield語句與return語句的作用相似,都是用來從函數中返回值,return語句一旦執行會立刻結束函數的運行
而每次執行到yield語句並返回一個值之後會暫停或掛起後面的代碼的執行,下次通過生成器對象的__next__()、for循環或其他方式索要數據時恢復執行
生成器具有惰性求值的特點
生成器運行順序:

生成器問題注意1:
1 def generator_func(): #生成器函數 2 print(123) 3 yield 'aaa' 4 print(456) 5 yield 'bbb' 6 ret_1 = generator_func().__next__() 7 print(ret_1) 8 ret_2 = generator_func().__next__() 9 print(ret_2) 10 # 輸出結果: 11 # 123 12 # aaa 13 # 123 14 # aaa 15 def generator_func(): #生成器函數 16 print(123) 17 yield 'aaa' 18 print(456) 19 yield 'bbb' 20 generate_1 = generator_func() 21 ret_1 = generate_1.__next__() 22 print(ret_1) 23 ret_2 = generate_1.__next__() 24 print(ret_2) 25 # 輸出結果: 26 # 123 27 # aaa 28 # 456 29 # bbb
第6行和第8行相當於創建了兩個生成器,第20行創建了一個生成器,21行和23行都用的是第20行創建的生成器,所以輸出結果不一樣
生成器問題注意2:

for循環完了之後生成器數據就取完了,再繼續print數據的話,就會報錯,因為沒有數據可以讀了。
一個函數有兩個以上的yield,才算一個必要的生成器,如果只有一個yield,那還不如老老實實的去寫return
生成器實例:
需求:寫一個實時監控文件輸入的內容,並將輸入內容返回的函數
1 def tail(filename): 2 f = open(filename,encoding='utf-8') 3 f.seek(0,2) 4 while True: 5 line = f.readline() 6 if not line:continue 7 yield line 8 tail_g = tail('file_1') 9 for line in tail_g:print(line,end='')

