【通俗易懂】手把手帶你實現DeepFM!
- 2019 年 10 月 31 日
- 筆記
勘誤:本文修正了原文中的兩處錯誤。感謝群友對文中錯誤的指正!小編以後也會更加細心的校對文章質量
1、模型輸入部分,label的shape應該是[None,1]

2、FM一次項的係數應該由feature_bias獲得。

可以說,DeepFM是目前最受歡迎的CTR預估模型之一,不僅是在交流群中被大家提及最多的,同時也是在面試中最多被提及的:
1、Deepfm的原理,DeepFM是一個模型還是代表了一類模型,DeepFM對FM做了什麼樣的改進,FM的公式如何化簡併求解梯度(滴滴) 2、FM、DeepFM介紹一下(貓眼) 3、DeepFm模型介紹一下(一點資訊) 4、DeepFM介紹下 & FM推導(一點資訊)
這次咱們一起來回顧一下DeepFM模型,以及手把手來實現一波!
1、DeepFM原理回顧
先來回顧一下DeepFM的模型結構:

DeepFM包含兩部分:因子分解機部分與神經網絡部分,分別負責低階特徵的提取和高階特徵的提取。這兩部分共享同樣的嵌入層輸入。DeepFM的預測結果可以寫為:

嵌入層

嵌入層(embedding layer)的結構如上圖所示。通過嵌入層,儘管不同field的長度不同(不同離散變量的取值個數可能不同),但是embedding之後向量的長度均為K(我們提前設定好的embedding-size)。通過代碼可以發現,在得到embedding之後,我們還將對應的特徵值乘到了embedding上,這主要是由於fm部分和dnn部分共享嵌入層作為輸入,而fm中的二次項如下:

FM部分
FM部分的詳細結構如下:

FM部分是一個因子分解機。關於因子分解機可以參閱文章[Rendle, 2010] Steffen Rendle. Factorization machines. In ICDM, 2010.。因為引入了隱變量的原因,對於幾乎不出現或者很少出現的隱變量,FM也可以很好的學習。
FM的輸出公式為:

深度部分
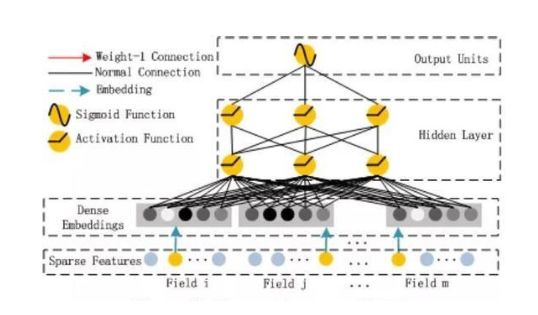
深度部分是一個多層前饋神經網絡。我們這裡不再贅述。
有關模型具體如何操作,我們可以通過代碼來進一步加深認識。
2、代碼實現
2.1 Embedding介紹
DeepFM中,很重要的一項就是embedding操作,所以我們先來看看什麼是embedding,可以簡單的理解為,將一個特徵轉換為一個向量。在推薦系統當中,我們經常會遇到離散變量,如userid、itemid。對於離散變量,我們一般的做法是將其轉換為one-hot,但對於itemid這種離散變量,轉換成one-hot之後維度非常高,但裏面只有一個是1,其餘都為0。這種情況下,我們的通常做法就是將其轉換為embedding。
embedding的過程是什麼樣子的呢?它其實就是一層全連接的神經網絡,如下圖所示:

假設一個離散變量共有5個取值,也就是說one-hot之後會變成5維,我們想將其轉換為embedding表示,其實就是接入了一層全連接神經網絡。由於只有一個位置是1,其餘位置是0,因此得到的embedding就是與其相連的圖中紅線上的權重。
2.2 tf.nn.embedding_lookup函數介紹
在tf1.x中,我們使用embedding_lookup函數來實現embedding,代碼如下:
# embedding embedding = tf.constant( [[0.21,0.41,0.51,0.11]], [0.22,0.42,0.52,0.12], [0.23,0.43,0.53,0.13], [0.24,0.44,0.54,0.14]],dtype=tf.float32) feature_batch = tf.constant([2,3,1,0]) get_embedding1 = tf.nn.embedding_lookup(embedding,feature_batch)
在embedding_lookup中,第一個參數相當於一個二維的詞表,並根據第二個參數中指定的索引,去詞表中尋找並返回對應的行。上面的過程為:

注意這裡的維度的變化,假設我們的feature_batch 是 1維的tensor,長度為4,而embedding的長度為4,那麼得到的結果是 4 * 4 的,同理,假設feature_batch是2 *4的,embedding_lookup後的結果是2 * 4 * 4。每一個索引返回embedding table中的一行,自然維度會+1。
上文說過,embedding層其實是一個全連接神經網絡層,那麼其過程等價於:

可以得到下面的代碼:
embedding = tf.constant( [ [0.21,0.41,0.51,0.11], [0.22,0.42,0.52,0.12], [0.23,0.43,0.53,0.13], [0.24,0.44,0.54,0.14] ],dtype=tf.float32) feature_batch = tf.constant([2,3,1,0]) feature_batch_one_hot = tf.one_hot(feature_batch,depth=4) get_embedding2 = tf.matmul(feature_batch_one_hot,embedding)
二者是否一致呢?我們通過代碼來驗證一下:
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) embedding1,embedding2 = sess.run([get_embedding1,get_embedding2]) print(embedding1) print(embedding2)
得到的結果為:

二者得到的結果是一致的。
因此,使用embedding_lookup的話,我們不需要將數據轉換為one-hot形式,只需要傳入對應的feature的index即可。
2.3 數據處理
接下來進入代碼實戰部分。
首先我們來看看數據處理部分,通過剛才的講解,想要給每一個特徵對應一個k維的embedding,如果我們使用embedding_lookup的話,需要得到連續變量或者離散變量對應的特徵索引feature index。聽起來好像有點抽象,咱們還是舉個簡單的例子:

這裡有三組特徵,或者說3個field的特徵,分別是性別、星期幾、職業。對應的特徵數量分別為2、7、2。我們總的特徵數量feature-size為2 + 7 + 2=11。如果轉換為one-hot的話,每一個取值都會對應一個特徵索引feature-index。
這樣,對於一個實例男/二/學生來說,將其轉換為對應的特徵索引即為0、3、9。在得到特徵索引之後,就可以通過embedding_lookup來獲取對應特徵的embedding。
當然,上面的例子中我們只展示了三個離散變量,對於連續變量,我們也會給它一個對應的特徵索引,如:

可以看到,此時共有5個field,一個連續特徵就對應一個field。
但是在FM的公式中,不光是embedding的內積,特徵取值也同樣需要。對於離散變量來說,特徵取值就是1,對於連續變量來說,特徵取值是其本身,因此,我們想要得到的數據格式如下:

定好了目標之後,咱們就開始實現代碼。先看下對應的數據集:
import pandas as pd TRAIN_FILE = "data/train.csv" TEST_FILE = "data/test.csv" NUMERIC_COLS = [ "ps_reg_01", "ps_reg_02", "ps_reg_03", "ps_car_12", "ps_car_13", "ps_car_14", "ps_car_15" ] IGNORE_COLS = [ "id", "target", "ps_calc_01", "ps_calc_02", "ps_calc_03", "ps_calc_04", "ps_calc_05", "ps_calc_06", "ps_calc_07", "ps_calc_08", "ps_calc_09", "ps_calc_10", "ps_calc_11", "ps_calc_12", "ps_calc_13", "ps_calc_14", "ps_calc_15_bin", "ps_calc_16_bin", "ps_calc_17_bin", "ps_calc_18_bin", "ps_calc_19_bin", "ps_calc_20_bin" ] dfTrain = pd.read_csv(TRAIN_FILE) dfTest = pd.read_csv(TEST_FILE) print(dfTrain.head(10))
數據集如下:

我們定義了一些不考慮的變量列、一些連續變量列,剩下的就是離散變量列,接下來,想要得到一個feature-map。這個featrue-map定義了如何將變量的不同取值轉換為其對應的特徵索引feature-index。
df = pd.concat([dfTrain,dfTest]) feature_dict = {} total_feature = 0 for col in df.columns: if col in IGNORE_COLS: continue elif col in NUMERIC_COLS: feature_dict[col] = total_feature total_feature += 1 else: unique_val = df[col].unique() feature_dict[col] = dict(zip(unique_val,range(total_feature,len(unique_val) + total_feature))) total_feature += len(unique_val) print(total_feature) print(feature_dict)
這裡,我們定義了total_feature來得到總的特徵數量,定義了feature_dict來得到變量取值到特徵索引的對應關係,結果如下:

可以看到,對於連續變量,直接是變量名到索引的映射,對於離散變量,內部會嵌套一個二級map,這個二級map定義了該離散變量的不同取值到索引的映射。
下一步,需要將訓練集和測試集轉換為兩個新的數組,分別是feature-index,將每一條數據轉換為對應的特徵索引,以及feature-value,將每一條數據轉換為對應的特徵值。
""" 對訓練集進行轉化 """ print(dfTrain.columns) train_y = dfTrain[['target']].values.tolist() dfTrain.drop(['target','id'],axis=1,inplace=True) train_feature_index = dfTrain.copy() train_feature_value = dfTrain.copy() for col in train_feature_index.columns: if col in IGNORE_COLS: train_feature_index.drop(col,axis=1,inplace=True) train_feature_value.drop(col,axis=1,inplace=True) continue elif col in NUMERIC_COLS: train_feature_index[col] = feature_dict[col] else: train_feature_index[col] = train_feature_index[col].map(feature_dict[col]) train_feature_value[col] = 1 """ 對測試集進行轉化 """ test_ids = dfTest['id'].values.tolist() dfTest.drop(['id'],axis=1,inplace=True) test_feature_index = dfTest.copy() test_feature_value = dfTest.copy() for col in test_feature_index.columns: if col in IGNORE_COLS: test_feature_index.drop(col,axis=1,inplace=True) test_feature_value.drop(col,axis=1,inplace=True) continue elif col in NUMERIC_COLS: test_feature_index[col] = feature_dict[col] else: test_feature_index[col] = test_feature_index[col].map(feature_dict[col]) test_feature_value[col] = 1
來看看此時的訓練集的特徵索引:

對應的特徵值:

此時,我們的訓練集和測試集就處理完畢了!
2.4 模型參數及輸入
接下來定義模型的一些參數,如學習率、embedding的大小、深度網絡的參數、激活函數等等,還有兩個比較重要的參數,分別是feature的大小和field的大小:
"""模型參數""" dfm_params = { "use_fm":True, "use_deep":True, "embedding_size":8, "dropout_fm":[1.0,1.0], "deep_layers":[32,32], "dropout_deep":[0.5,0.5,0.5], "deep_layer_activation":tf.nn.relu, "epoch":30, "batch_size":1024, "learning_rate":0.001, "optimizer":"adam", "batch_norm":1, "batch_norm_decay":0.995, "l2_reg":0.01, "verbose":True, "eval_metric":'gini_norm', "random_seed":3 } dfm_params['feature_size'] = total_feature dfm_params['field_size'] = len(train_feature_index.columns)
而訓練模型的輸入有三個,分別是剛才轉換得到的特徵索引和特徵值,以及label:
"""開始建立模型""" feat_index = tf.placeholder(tf.int32,shape=[None,None],name='feat_index') feat_value = tf.placeholder(tf.float32,shape=[None,None],name='feat_value') label = tf.placeholder(tf.float32,shape=[None,1],name='label')
比如剛才的兩個數據,對應的輸入為:

定義好輸入之後,再定義一下模型中所需要的weights:
"""建立weights""" weights = dict() #embeddings weights['feature_embeddings'] = tf.Variable( tf.random_normal([dfm_params['feature_size'],dfm_params['embedding_size']],0.0,0.01), name='feature_embeddings') weights['feature_bias'] = tf.Variable(tf.random_normal([dfm_params['feature_size'],1],0.0,1.0),name='feature_bias') #deep layers num_layer = len(dfm_params['deep_layers']) input_size = dfm_params['field_size'] * dfm_params['embedding_size'] glorot = np.sqrt(2.0/(input_size + dfm_params['deep_layers'][0])) weights['layer_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(input_size,dfm_params['deep_layers'][0])),dtype=np.float32 ) weights['bias_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(1,dfm_params['deep_layers'][0])),dtype=np.float32 ) for i in range(1,num_layer): glorot = np.sqrt(2.0 / (dfm_params['deep_layers'][i - 1] + dfm_params['deep_layers'][I])) weights["layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(dfm_params['deep_layers'][i - 1], dfm_params['deep_layers'][i])), dtype=np.float32) # layers[i-1] * layers[I] weights["bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(1, dfm_params['deep_layers'][i])), dtype=np.float32) # 1 * layer[I] # final concat projection layer if dfm_params['use_fm'] and dfm_params['use_deep']: input_size = dfm_params['field_size'] + dfm_params['embedding_size'] + dfm_params['deep_layers'][-1] elif dfm_params['use_fm']: input_size = dfm_params['field_size'] + dfm_params['embedding_size'] elif dfm_params['use_deep']: input_size = dfm_params['deep_layers'][-1] glorot = np.sqrt(2.0/(input_size + 1)) weights['concat_projection'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(input_size,1)),dtype=np.float32) weights['concat_bias'] = tf.Variable(tf.constant(0.01),dtype=np.float32)
介紹兩個比較重要的參數,weights['feature_embeddings']是每個特徵所對應的embedding,它的大小為feature-size * embedding-size,另一個參數是weights['feature_bias'] ,這個是FM部分計算時所用到的一次項的權重參數,可以理解為embedding-size為1的embedding table,它的大小為feature-size * 1。
假設weights['feature_embeddings']如下:

2.5 嵌入層
嵌入層,主要根據特徵索引得到對應特徵的embedding:
"""embedding""" embeddings = tf.nn.embedding_lookup(weights['feature_embeddings'],feat_index) reshaped_feat_value = tf.reshape(feat_value,shape=[-1,dfm_params['field_size'],1]) embeddings = tf.multiply(embeddings,reshaped_feat_value)
這裡注意的是,在得到對應的embedding之後,還乘上了對應的特徵值,這個主要是根據FM的公式得到的。過程表示如下:

2.6 FM部分
我們先來回顧一下FM的公式,以及二次項的化簡過程:


上面的式子中有部分同學曾經問我第一步是怎麼推導的,其實也不難,看下面的手寫過程(大夥可不要嫌棄字丑喲)

因此,一次項的計算如下,我們剛剛也說過了,通過weights['feature_bias']來得到一次項的權重係數:
fm_first_order = tf.nn.embedding_lookup(weights['feature_bias'],feat_index) fm_first_order = tf.reduce_sum(tf.multiply(fm_first_order,reshaped_feat_value),2)
對於二次項,經過化簡之後有兩部分(暫不考慮最外層的求和),我們先用excel來形象展示一下兩部分,這有助於你對下面代碼的理解。
第一部分過程如下:

第二部分的過程如下:

最後兩部分相減:

二次項部分的代碼如下:
summed_features_emb = tf.reduce_sum(embeddings,1) summed_features_emb_square = tf.square(summed_features_emb) squared_features_emb = tf.square(embeddings) squared_sum_features_emb = tf.reduce_sum(squared_features_emb,1) fm_second_order = 0.5 * tf.subtract(summed_features_emb_square,squared_sum_features_emb)
要注意這裡的fm_second_order是二維的tensor,大小為batch-size * embedding-size,也就是公式中最外層的一個求和還沒有進行,這也是代碼中與FM公式有所出入的地方。我們後面再講。
2.7 Deep部分
Deep部分很簡單了,就是幾層全連接的神經網絡:
"""deep part""" y_deep = tf.reshape(embeddings,shape=[-1,dfm_params['field_size'] * dfm_params['embedding_size']]) for i in range(0,len(dfm_params['deep_layers'])): y_deep = tf.add(tf.matmul(y_deep,weights["layer_%d" %i]), weights["bias_%d"%I]) y_deep = tf.nn.relu(y_deep)
2.8 輸出部分
最後的輸出部分,論文中的公式如下:
在我們的代碼中如下:
"""final layer""" if dfm_params['use_fm'] and dfm_params['use_deep']: concat_input = tf.concat([fm_first_order,fm_second_order,y_deep],axis=1) elif dfm_params['use_fm']: concat_input = tf.concat([fm_first_order,fm_second_order],axis=1) elif dfm_params['use_deep']: concat_input = y_deep out = tf.nn.sigmoid(tf.add(tf.matmul(concat_input,weights['concat_projection']),weights['concat_bias']))
看似有點出入,其實真的有點出入,不過無礙,咱們做兩點說明:
1)首先,這裡整體上和最終的公式是相似的,看下面的excel(由於最後一層只有一個神經元,矩陣相乘可以用對位相乘再求和代替):

2)這裡不同的地方就是,FM二次項化簡之後最外層不再是簡單的相加了,而是變成了加權求和(有點類似attention的意思),如果FM二次項部分對應的權重都是1,就是標準的FM了。
2.9 Loss and Optimizer
這一塊也不再多講,我們使用logloss來指導模型的訓練:
"""loss and optimizer""" loss = tf.losses.log_loss(tf.reshape(label,(-1,1)), out) optimizer = tf.train.AdamOptimizer(learning_rate=dfm_params['learning_rate'], beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(loss)
至此,我們整個DeepFM模型的架構就搭起來了,接下來,我們簡單測試一下代碼:
"""train""" with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(100): epoch_loss,_ = sess.run([loss,optimizer],feed_dict={feat_index:train_feature_index, feat_value:train_feature_value, label:train_y}) print("epoch %s,loss is %s" % (str(i),str(epoch_loss)))
調試成功:

好了,本次的手把手實現DeepFM教學就到這裡了,這個模型大家一定要掌握啊,推薦系統崗位校招必考!
代碼鏈接:https://github.com/princewen/tensorflow_practice/blob/master/recommendation/Basic-DeepFM-model/DeepFM-StepByStep.ipynb
數據在git最外層的readme中。


