惡意代碼檢測工具 — Mathematics Malware Detected Tools
- 2019 年 10 月 31 日
- 筆記
Mathematics Malware Detected Tools
重要:由於缺少測試數據,部分結論可能不正確。更多更準確的結論,還需要進行大量實驗。
概述
mmdt(Mathematics Malware Detected Tools)是一款基於數學方法的最簡單的類「機器學習」工具。該工具通過數學方法對目標對象進行處理,生成相應的標準「指紋」,通過對指紋的處理,實現「機器學習」中的「分類」、「聚類」方法。
並在此基礎上,從「分類」衍生出惡意代碼檢測功能,從「聚類」衍生出惡意代碼同源樣本挖掘功能。
備註:
- 對該工具而言,分類、聚類之間唯一的區別是有無已知標籤,除此之外完全一樣。
- 這裡「分聚類」的意思已經幾乎等價於機器學習中的分聚類,類似的,分類需要有已知的訓練集,聚類則不需要。
工具特點
工具特點如下:
- 還原最古老、原始、簡單的機器學習過程,
- 實現從數據到信息的轉換,適用於最真實的大數據場景
- 檢測過程高效、快捷,支持多級索引,實現毫秒級處理
- 單機模式對百萬級數量的特徵實現毫秒級的檢索、匹配
- 實現100%「見過即可查」,將檢出問題簡單轉化為數據問題,數據越多,檢出越多
- 不用擔心數據災難,維度災難等問題。
- 支持幾乎所有文件格式
工具目的
可參考著名工具ssdeep的目的及意義。
該工具相對於ssdeep的優勢:
- 處理結果的記憶屬性:提供處理結果存儲功能,實現對歷史數據的回溯。
- 對大數據的支持:單機版支持百萬級別的特徵數量,100萬條特徵所佔磁盤空間不足100M。
- 快速高效的匹配:增加多級索引模式,支持更高效快速的檢索、匹配。
- 完整的使用流程:傻瓜式的適用方式,類似於常規機器學習過程,設置標籤,配置參數,提供訓練集,即可以自動化的生成最小規則庫(機器學習中的最小模型)
- 智能的學習過程:學習結果實時反饋,避免重複學習。
原理概要
通過壓縮算法對文件進行縮放,生成標準文件、使用哈希函數對標準文件進行處理,得到「分片」哈希(指紋)。詳細內容參見後續論文(撰寫論文中)。
(原理不夠,表情包湊。
在完全一樣的約束條件下,能推論出一個特解。我的狀態:

弱化(減少)約束條件之後,面對新的數學問題時,我的狀態:

在群里請教大佬數學問題時,我的狀態:

配置參數說明
main.ini
主配置文件,用於配置執行相關功能時的參數選項。
[version] auto-add=0 // function-type=3時生效,用於分類「訓練模型」時(是否自動更新模型)0:不更新,非0:更新 auto-move=0 // 用於聚類時是否移動文件,0:不移動,非0:移動 function-type=3 // 選擇功能,2:相似度計算比較,3:分類訓練/掃描,4:聚類 normalization-standar=100 // 歸一化標準,默認100 scan-level=10 // 掃描覆蓋率,取值在[0, 5]之間時越大覆蓋率越高,準確性越低,其他值為默認掃描,覆蓋率最低,準確性最高 first-level=60 // 方式1的準確度,取值在[0, 100]之間,越低越準確,覆蓋率越低 second-level=50 // 方式2的準確度,取值在[0, 100]之間,越低越準確,覆蓋率越低 accury-level=3 // 計算相似度方式,取值為1、3,取值為1時使用低精度方式,取值為3時使用高精度方式 thresold=0.5 // 判定閾值 classify-id=-1 // 分類「訓練模型」是生效,需要給定當前這批文件的標籤 max-cluster-number=1000 //支持最大聚類數量 max-file-size=20971520 //支持最大處理文件大小20M,超過的截斷處理 rule-file=rule.db // 規則庫(模型存儲) label-file=classify-label.ini // 標籤配置文件classify-label.ini
標籤配置文件,用於分類(掃描)時,將id轉成對應的字符串,節約存儲空間。詳細使用參考使用場景
[version] version=1.0.0 [owner] name=mmdt [label_name] -1=Unknown // id: -1 保留值,映射為 Unknown 0=Clean // id: 0 保留值,映射為 Clean 1=Sality // id: 1 自增,映射為 Sality(病毒名) ... // 後續依次自增cmd參數
參數意義見main.ini
Version: 1.0.0 Options: --help, -h,show help info. --auto-add, -a,auto add rule. --auto-move, -b,auto move cluster. --function-type, -f,function type. --normalization-standard, -n,normalization standard. --scan-level, -l,scan level. --first-level, -d,first level. --second-level, -e,second level. --classify-id, -j,classify id. --thresold, -p,thresold value. --compare-file, -c,comare file. --max-cluster-number, -m,max cluster number. --ini-file, -i,ini file --label-file, -o,label file --rule-file, -r,rule file --target, -t,target使用場景
本段落主要說明工具的用法以及怎麼用。不同的使用場景需要配置不同的參數。
目前考慮到使用場景具體包括:
- 分類場景,惡意代碼檢測
- 聚類場景,自動同源性的化惡意代碼挖掘
- 相似度計算場景,如計算可執行文件相似度、計算源代碼相似度、計算webshell相似度、計算宏代碼相似度、計算圖片相似度
分類場景
生成特徵庫(模型「訓練」)
對有標籤樣本提取特徵,生成指紋,融入特徵庫。
執行命令如下:
./mmdt -f 3 -a 1 -j 1 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Sality/./mmdt -f 3 -a 1 -j 2 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Berbew/./mmdt -f 3 -a 1 -j 3 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Gandcrab/- …(依次對其他文件夾進行處理,生成庫文件[「模型」])
-f: 3表示採用掃描/訓練模式 -a: 1表示自動存儲滿足條件的指紋 -j: 1表示標籤id -r: 特徵庫文名稱 -o: 標籤文件 -t: 目標對象,可以是單個文件,也可以是目錄(目錄必須帶上最後的斜桿)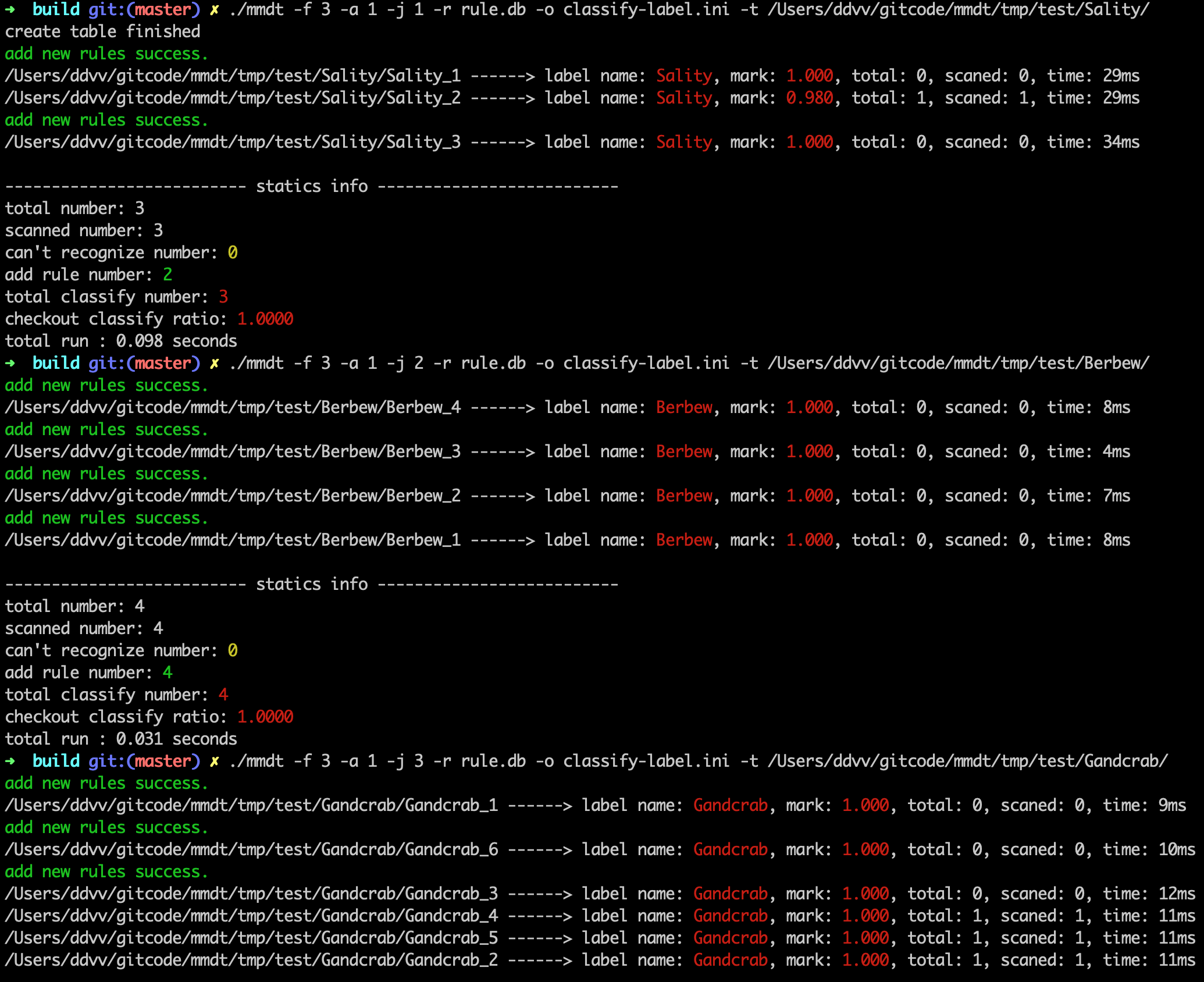
可執行文件檢測
執行命令:
./mmdt -f 3 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Wabot/./mmdt -f 3 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Gandcrab/
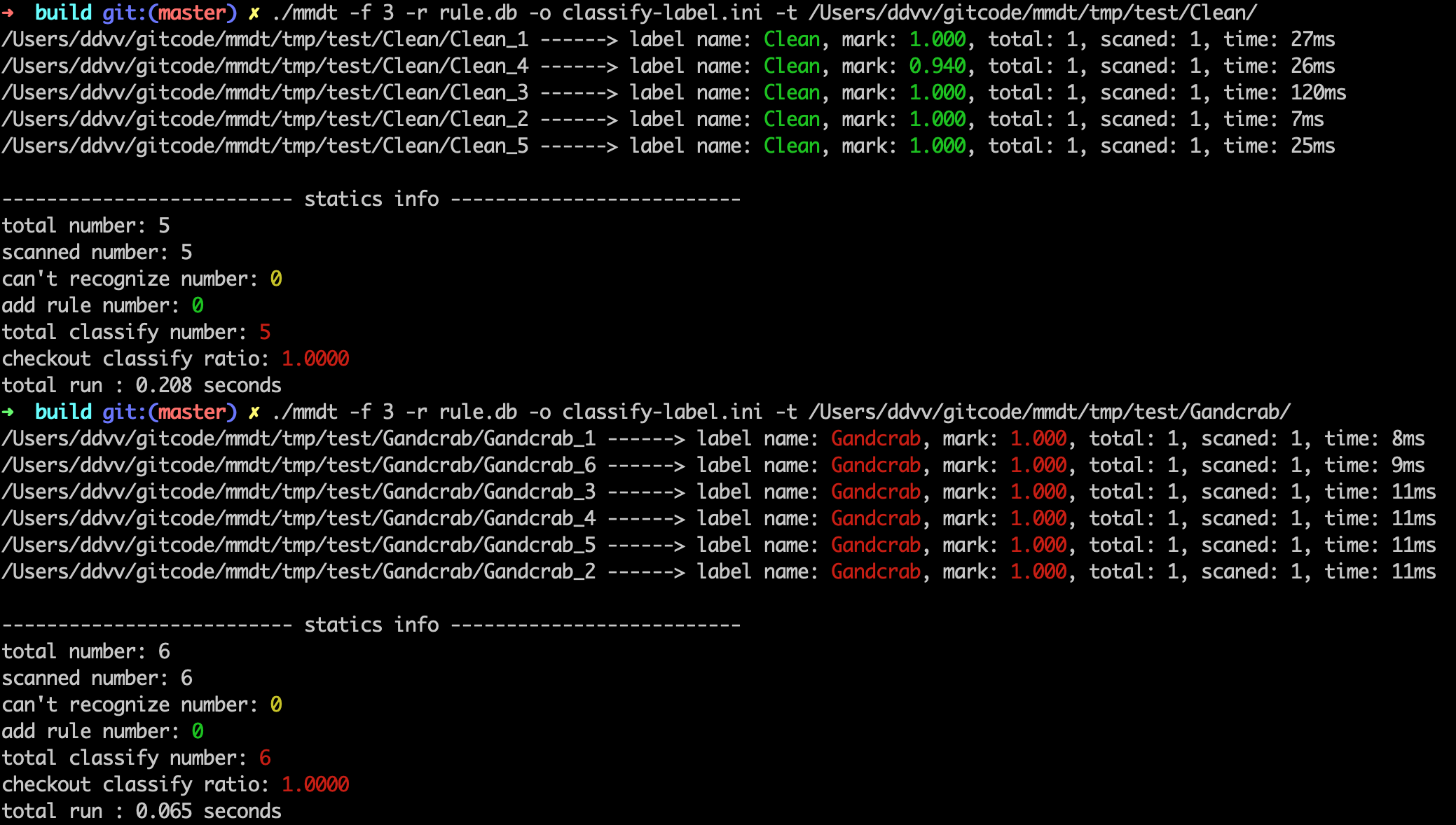
輸出檢出情況。
total number: 表示一共掃描的文件個數 scanned number: 表示本工具能處理的文件個數 can't recognize number: 表示本公舉不能處理的文件個數 add rule number: 表示添加的規則數 total classify number: 表示能識別的文件總數 checkout classify ratio: 表示識別率 total run : 表示本次程序執行時間非可執行文件檢測(與PE文件檢測完全一致)
執行命令:
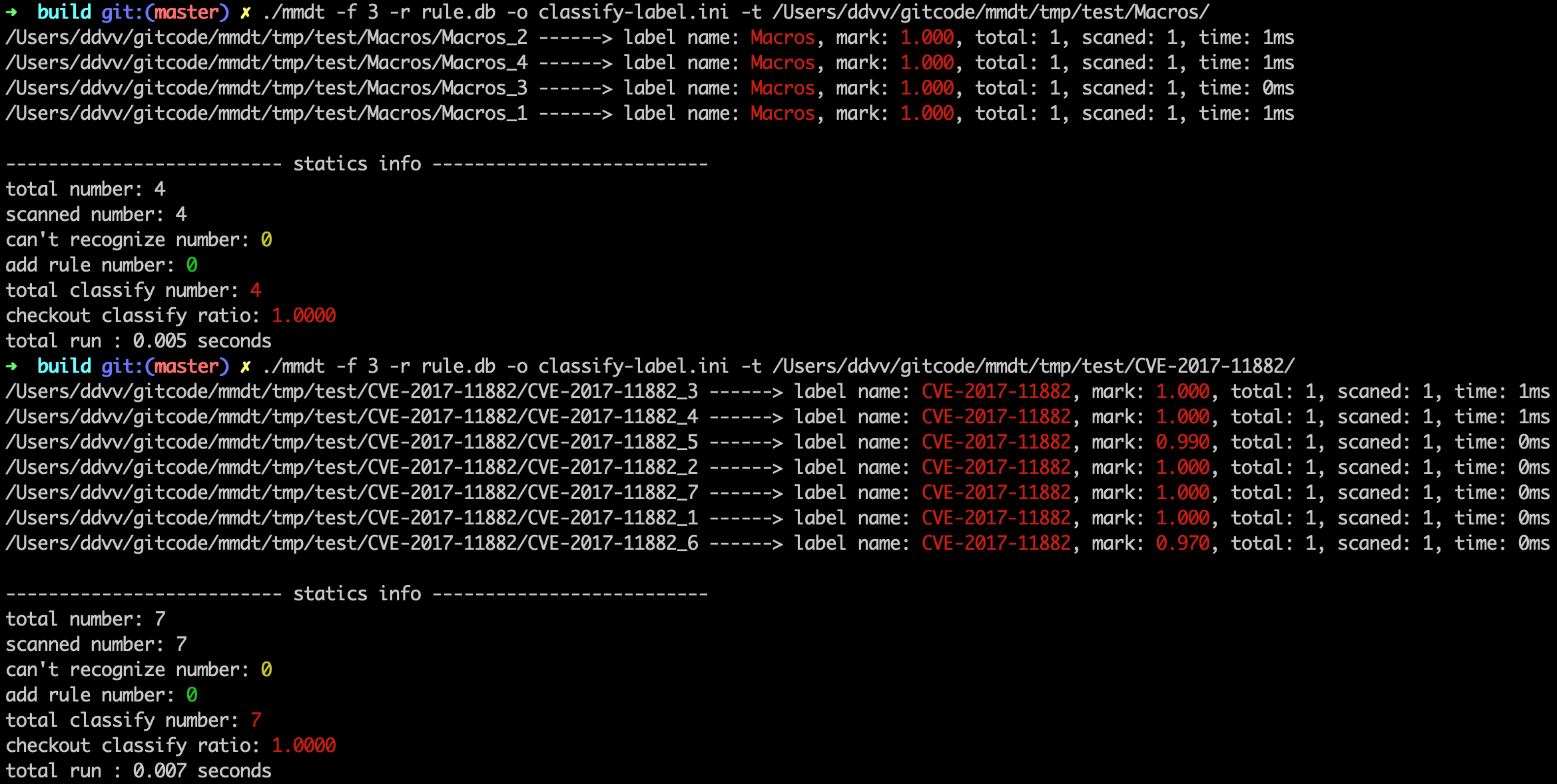
- 掃描宏:
./mmdt -f 3 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/Macros/ - 掃描11882漏洞利用:
./mmdt -f 3 -r rule.db -o classify-label.ini -t /Users/ddvv/gitcode/mmdt/tmp/test/CVE-2017-11882/
聚類場景
惡意代碼聚類
對51個文件,共計9個大類進行聚類,執行命令:
- 聚類,並將同類移動到同一個文件夾下:
./mmdt -f 4 -b 1 -m 1000 -t /Users/ddvv/gitcode/mmdt/tmp/test/All/
-f: 4表示採用聚類模式 -b: 1表示自動移動同源文件到相同目錄 -m: 表示本次聚類支持的最大類別數量 -t: 目標對象,可以是單個文件,也可以是目錄(目錄必須帶上最後的斜桿)結果如下:
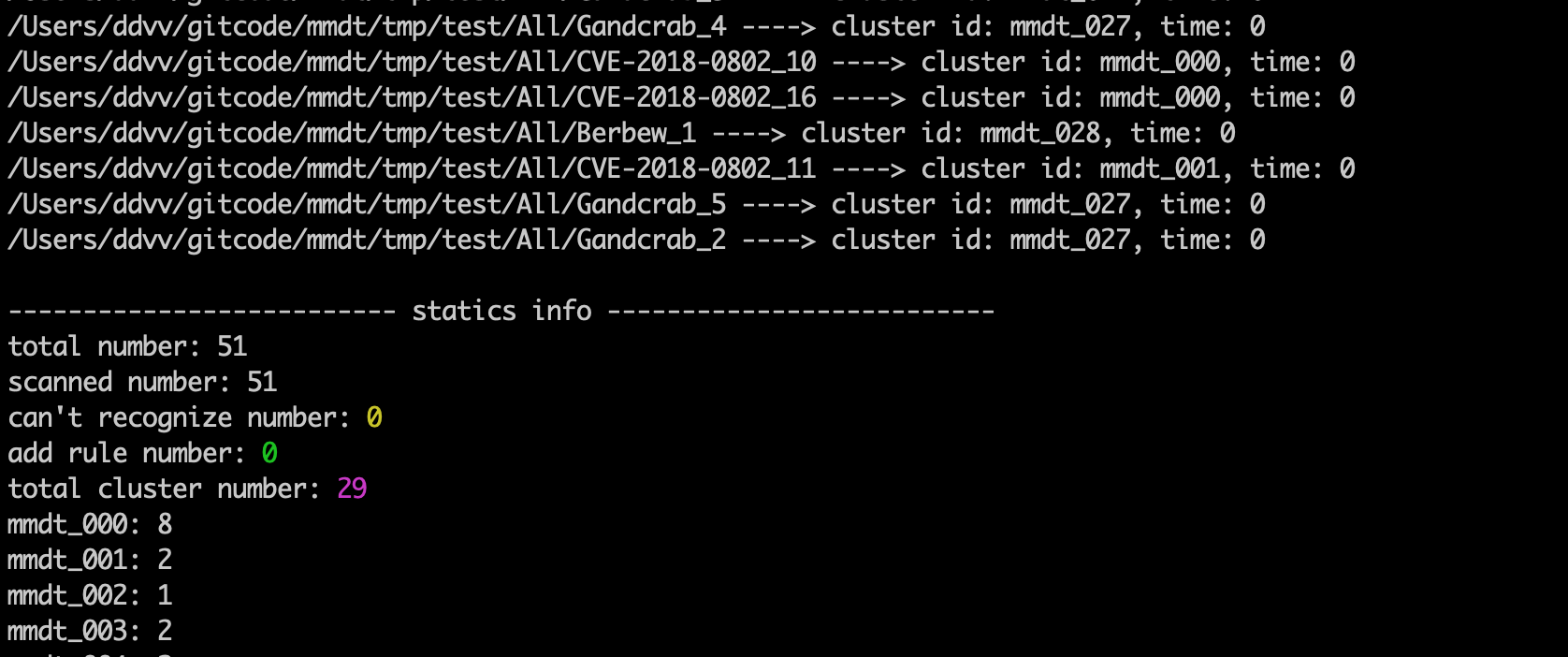
51個樣本聚類數量29類。從截圖信息可以看出,mmdt_000是CVE-2018-0802類型,共計8個樣本
相似度計算場景
用於計算文件間的相似度。
惡意文件相似度計算
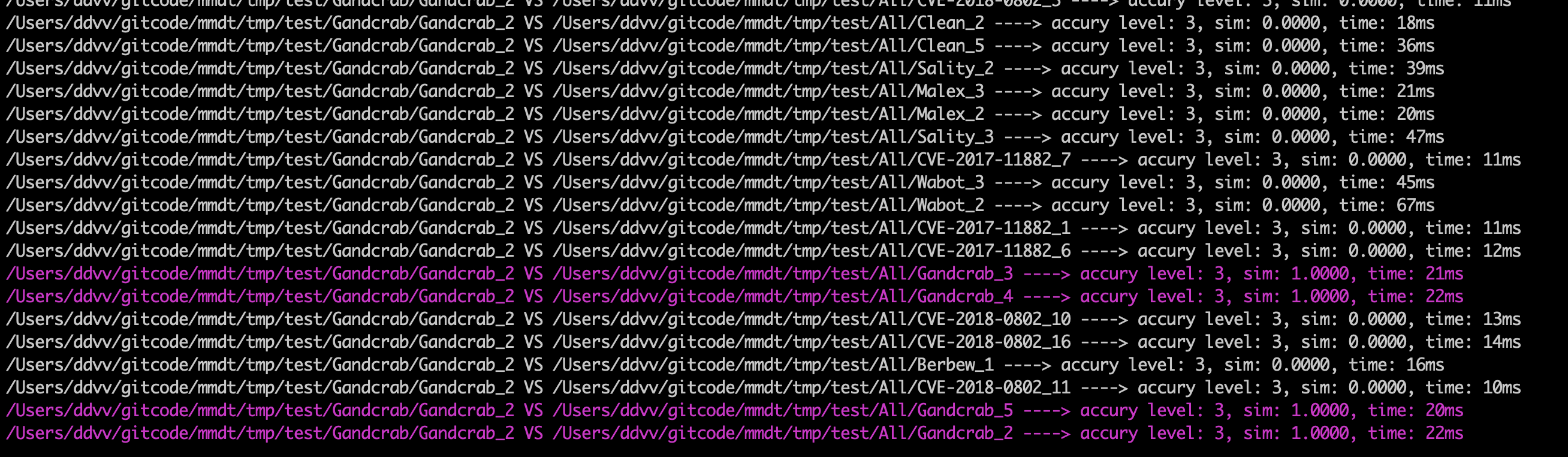
計算Gandcrab_2和其他文件之間的相似度,執行命令:
./mmdt -f 2 -c /Users/ddvv/gitcode/mmdt/tmp/test/Gandcrab/Gandcrab_2 -t /Users/ddvv/gitcode/mmdt/tmp/test/All/
-f: 2表示採用計算相似度模式 -c: 表示比較的目標對象(只能是文件,不能是文件夾) -t: 表示目標對象,可以是單個文件,也可以是目錄(目錄必須帶上最後的斜桿)結果如下:

…
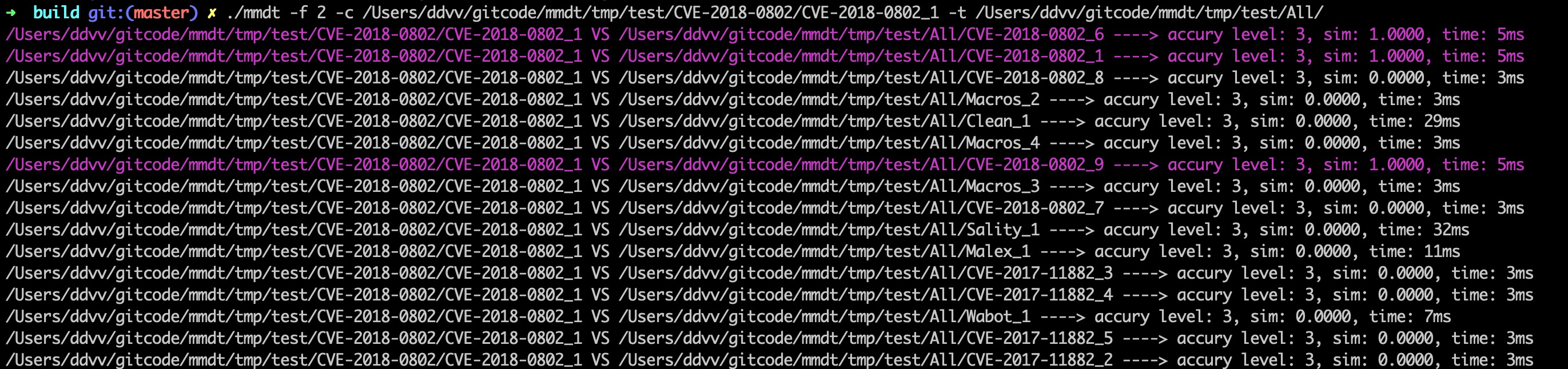
計算CVE-2018-0802_1和其他文件之間的相似度:執行命令:
./mmdt -f 2 -c /Users/ddvv/gitcode/mmdt/tmp/test/CVE-2018-0802/CVE-2018-0802_1 -t /Users/ddvv/gitcode/mmdt/tmp/test/All/
結果如下:
源代碼相似度計算
對ssdeep中不同commit間的engine.cpp源碼進行相似度計算,原始差異如下圖:
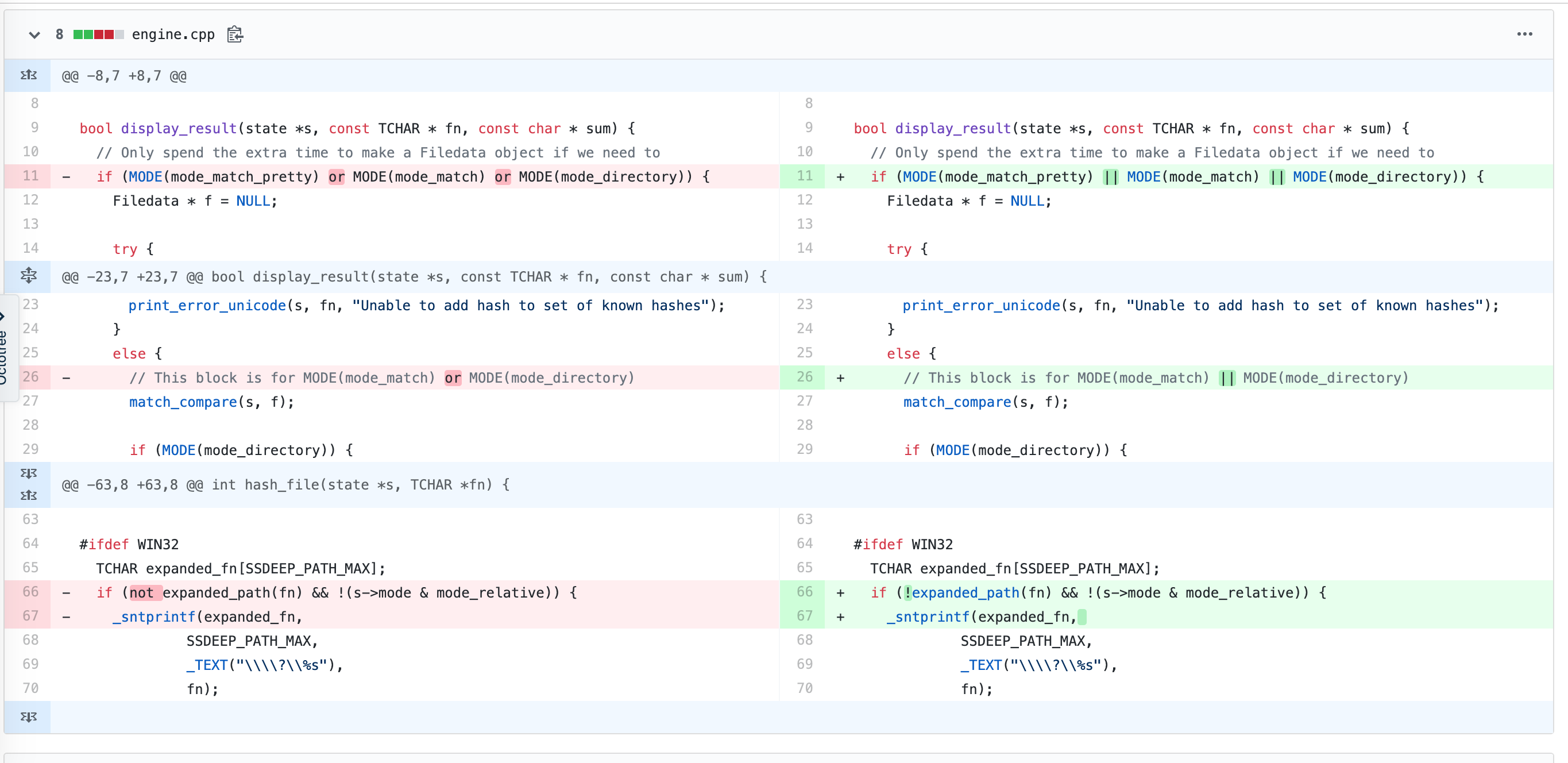
執行命令(歸一化標準設置為500),
./mmdt -f 2 -n 500 -c /Users/ddvv/gitcode/mmdt/tmp/test/source/engine_new.cpp -t /Users/ddvv/gitcode/mmdt/tmp/test/source/engine_old.cpp
相似度計算結果如下:

webshell相似度計算
對webshell進行相似度計算,原始差異如下圖:
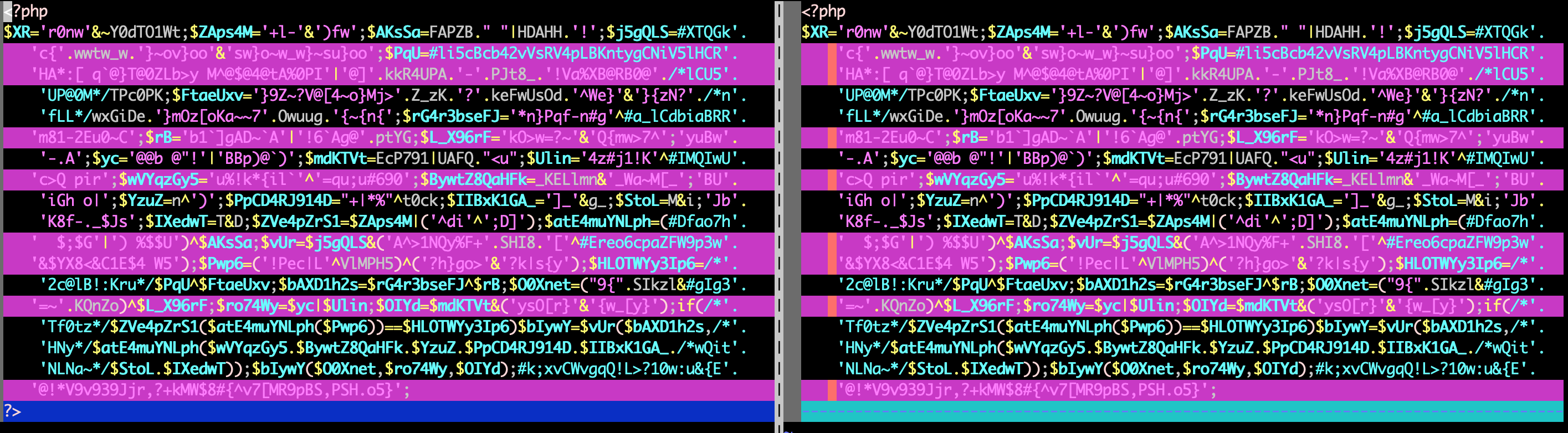
執行命令(歸一化標準設置為默認100),
./mmdt -f 2 -c /Users/ddvv/gitcode/mmdt/tmp/test/webshell/php1 -t /Users/ddvv/gitcode/mmdt/tmp/test/webshell/
相似度計算結果如下:

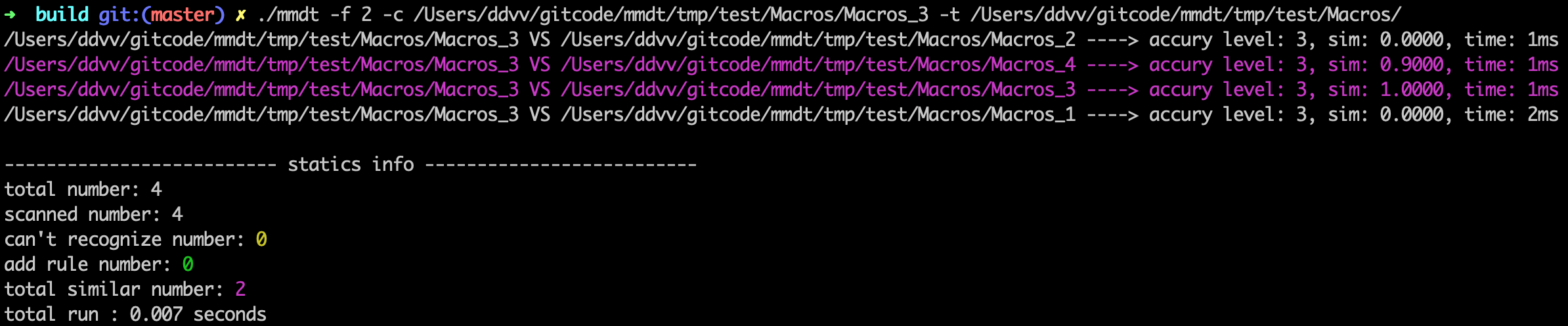
宏代碼相似度計算
對宏代碼進行相似度計算,原始差異如下圖:

執行命令(歸一化標準設置為默認100),
./mmdt -f 2 -c /Users/ddvv/gitcode/mmdt/tmp/test/Macros/Macros_3 -t /Users/ddvv/gitcode/mmdt/tmp/test/Macros/
相似度計算結果如下:
其他使用場景
通過一些參數優化等方式,有可能也能利用在相似圖像查找上面。
原圖如下:

執行命令(歸一化標準設置為210),
./mmdt -f 2 -k 3 -n 210 -c /Users/ddvv/gitcode/mmdt/tmp/test/Img/img1.jpeg -t /Users/ddvv/gitcode/mmdt/tmp/test/Img/
相似度計算結果如下:

惡意代碼檢測
對314個惡意樣本使用同一參數(見main.ini文件),進行測試統計(樣本來源參考malware-samples和APT-Sample)。
| 標籤名 | 樣本數量 | 規則數量 | 規則/樣本數量比率 |
|---|---|---|---|
| Clean | 5 | 4 | 0.800 |
| Sality | 3 | 2 | 0.667 |
| Berbew | 4 | 4 | 1.000 |
| Gandcrab | 6 | 3 | 0.500 |
| Malex | 3 | 1 | 0.333 |
| Wabot | 3 | 3 | 1.000 |
| CVE-2017-11882 | 7 | 5 | 0.714 |
| CVE-2018-0802 | 16 | 4 | 0.250 |
| Macros | 4 | 3 | 0.750 |
| Malware | 78 | 71 | 0.910 |
| APT | 185 | 171 | 0.924 |
| 總計 | 314 | 271 | 0.863 |
RS比率=規則/樣本數量比率
可推導出的結論包括:
- RS比率越低表示識別效果越好
- RS比率與惡意樣本類型相關
- RS比率高低與配置參數相關
- 放大數據集,RS比率會降低
其他
為什麼不開源代碼?
主要還是如下兩個原因:
- code水平很差,代碼太丑,暫時不好意思開源
- 這個工具是論文的驗證demo,需要完成論文後,才方便開源
為什麼提供該工具?
出於兩方面的原因考慮:
- 主要希望能換取更多的合法數據(樣本),進行測試
- 次之希望有大佬能提供測試結果,能引用到論文中。
未來是否對這個工具的改進?
會。比如考慮支持以下一些場景和功能:
- 結合動態技術,對內存做運算,生成指紋,進行匹配
- 增加C/S,B/S模式,增加緩存機制,以支持更大數據集提供更好的特徵子集
- 智能配置文檔生成,更優支持更多的文件類型
Github地址
Github — ddvv
壓縮包解壓碼
解壓碼:mmdt

