【必讀】2019年深度學習自然語言處理最新十大發展趨勢, 附報告下載
- 2019 年 10 月 30 日
- 筆記
【導讀】自然語言處理在深度學習浪潮下取得了巨大的發展,FloydHub 博客上Cathal Horan介紹了自然語言處理的10大發展趨勢,是了解NLP發展的非常好的文章。
2018年是基於深度學習的自然語言處理(NLP)研究發展快速的一年。在此之前,最引人注目的是Word2Vec,它於2013年首次發佈。
在此期間,深度學習模型在語言建模領域實現的方面出現了一種穩定的創新和突破的勢頭。
然而,2018年可能是所有這些勢頭最終結出碩果的一年,在NLP的深度學習方法方面出現了真正突破性的新發展。
去年的最後幾個月,隨着BERT模型的出現,出現了一場特別熱鬧的研究浪潮。2019年,一個新的挑戰者已經通過OpenAI GTP-2模型出現,該模型「太危險」不適合發佈。通過所有這些活動,很難從實際的業務角度了解這意味着什麼。
這對我意味着什麼?
這項研究能應用於日常應用嗎?或者,潛在的技術仍在如此迅速地發展,以至於不值得花時間去開發一種可能會被下一篇研究論文視為過時的方法?如果您想在自己的業務中應用最新的方法,了解NLP研究的趨勢是很重要的。為了幫助解決這個問題,基於最新的研究成果,在這裡預測10個關於NLP的趨勢,我們可能會在明年看到。
NLP架構的趨勢
我們可以看到的第一個趨勢是基於深度學習神經網絡架構,這是近年來NLP研究的核心。為了將它們應用到您的業務用例中,您不必詳細地了解這些架構。但是,您需要知道,對於什麼架構能夠交付最佳結果,是否仍然存在重大疑問。
如果對最佳架構沒有共識,那麼就很難知道應該採用什麼方法(如果有的話)。您將不得不投入時間和資源來尋找在您的業務中使用這些體系結構的方法。所以你需要知道2019年這一領域的趨勢。
1. 以前的word嵌入方法仍然很重要
2. 遞歸神經網絡(RNNs)不再是一個NLP標準架構
3. Transformer將成為主導的NLP深度學習架構
4. 預先訓練的模型將發展更通用的語言技能
5. 遷移學習將發揮更大的作用
6. 微調模型將變得更容易
7. BERT將改變NLP的應用前景
8. 聊天機械人將從這一階段的NLP創新中受益最多
9. 零樣本學習將變得更加有效
10. 關於人工智能的危險的討論可能會開始影響NLP的研究和應用
1. 以前的word嵌入方法仍然很重要
Word2Vec和GLoVE是在2013年左右出現的。隨着所有的新研究,你可能認為這些方法不再相關,但你錯了。Francis Galton爵士在19世紀後期提出了線性回歸的方法,但作為許多統計方法的核心部分,它今天仍然適用。
類似地,像Word2Vec這樣的方法現在是Python NLP庫(如spaCy)的標準部分,在spaCy中它們被描述為「實用NLP的基石」。如果你想快速分類常見的文本,那麼word嵌入就可以了。

Word2Vec等方法的局限性對於幫助我們了解NLP研究的未來趨勢也很重要。他們為所有未來的研究設定了一個基準。那麼,他們在哪些方面做得不夠呢?
- 每個詞只能嵌入一個詞,即每個詞只能存儲一個向量。所以" bank "只有一個意思"我把錢存進了銀行"和"河岸上有一條漂亮的長凳"
- 它們很難在大型數據集上訓練
- 你無法調整它們。為了使他們適合你的領域,你需要從零開始訓練他們
- 它們不是真正的深度神經網絡。他們被訓練在一個有一個隱藏層的神經網絡上。
2. 遞歸神經網絡(RNNs)不再是一個NLP標準架構
長期以來,RNNs一直是基於NLP的神經網絡的基礎架構。這些架構是真正的深度學習神經網絡,是從早期的創新(如Word2Vec)設定的基準發展而來的。去年討論最多的方法之一是ELMo(來自語言模型的嵌入),它使用RNNs提供最先進的嵌入表示,解決了以前方法的大多數缺點。從下圖中可以看出,與前饋網絡不同,RNNs允許隱藏層的循環返回到它們自己,並且以這種方式能夠接受可變長度的序列輸入。這就是為什麼它們非常適合處理文本輸入。
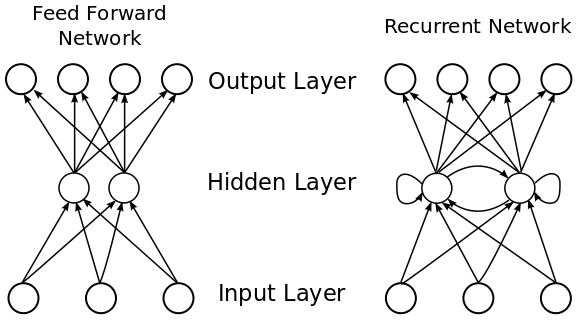
RNNs非常重要,因為它提供了一種處理數據的方法,而時間和順序非常重要。例如,對於文本相關的數據,單詞的順序很重要。改變語序或單詞可以改變一個句子的意思,或只是使它亂語。在前饋網絡中,隱含層只能訪問當前輸入。它沒有任何其他已經處理過的輸入的「內存」。相比之下,RNN能夠對其輸入進行「循環」,看看之前發生了什麼。
作為一個實際的例子,讓我們回到我們的一個bank的例句,「I lodged money in the bank」。在前饋網絡中,當我們到達「bank」這個詞時,我們對之前的詞已經沒有「記憶」了。這使得我們很難知道句子的上下文,也很難預測正確的下一個單詞。相比之下,在RNN中,我們可以參考句子中前面的單詞,然後生成下一個單詞是「bank」的概率。
RNNs和長短時記憶(LSTM)是RNN的一種改進類型,它們的詳細信息不在本文討論範圍之內。但如果你真的想深入了解這個主題,沒有比克里斯托弗•奧拉斯(Christopher Olahs)關於這個主題的精彩文章更好的起點了。
ELMo在多層RNN上接受訓練,並從上下文學習單詞嵌入。這使得它能夠根據所使用的上下文為每個單詞存儲多個向量。它附帶了一個預先訓練好的模型,這個模型是在一個非常大的數據集上訓練的,可以動態地創建基於上下文的詞嵌入,而不是像以前的靜態詞嵌入方法那樣簡單地提供查找表。

這個圖是一個兩層ELMO架構的例子。您擁有的層越多,就可以從輸入中了解到越多的上下文。低層識別基本語法和語法規則,而高層提取較高的上下文語義。ELMO使其更精確的另一個方面是它採用了雙向語言建模。因此,不是簡單地從開始到結束讀取輸入,而是從結束到開始讀取輸入。這使得它能夠捕獲句子中單詞的完整上下文。如果沒有這個,你必須假設一個特定單詞的所有上下文都出現在單詞之前或之後,這取決於你讀它的方向。
它還允許進行微調,以便能夠根據特定領域的數據進行調整。這導致一些人聲稱這是NLPs ImageNet時刻,這意味着我們越來越接近擁有可用於下游NLP任務的一般訓練模型的核心構件。
因此,RNN結構仍然是非常前沿的,值得進一步研究。直到2018年,它仍然是NLP的主要架構。一些評論家認為,現在是我們完全放棄RNNs的時候了,因此,無論如何,它們都不太可能成為2019年許多新研究的基礎。相反,2019年深度學習NLP的主要架構趨勢將是transformer。
3. Transformer將成為主導的NLP深度學習架構
雖然ELMo能夠克服以前的word嵌入式架構的許多缺點,比如它只能記住一段文本的上下文,但它仍然必須按順序處理它的輸入,一個詞一個詞地處理,或者在ELMo的情況下,一個字符一個字符地處理。
如前所述,這意味着需要將文本流輸入到輸入層。然後按順序對每個隱層進行處理。因此,在處理文本以理解上下文時,體系結構必須存儲文本的所有狀態。這使得學習較長的文本序列(如句子或段落)變得困難,也使得訓練的速度變慢。
最終,這限制了它可以訓練的數據集的大小,而這些數據集對任何訓練它的模型的能力都有已知的影響。在人工智能中,「生命始於十億個例子」。語言建模也是如此。更大的訓練集意味着您的模型輸出將更準確。因此,在輸入階段的瓶頸可能被證明是非常昂貴的,就您能夠生成的準確性而言。

Transformer架構在2017年底首次發佈,它通過創建一種允許並行輸入的方法來解決這個問題。每個單詞可以有一個單獨的嵌入和處理過程,這大大提高了訓練時間,便於在更大的數據集上進行訓練。
作為一個例子,我們只需要看看2019年的早期NLP感覺之一,OpenAI的GTP-s模型。GTP-2模型的發佈受到了很多關注,因為創建者聲稱,考慮到大規模生成「虛假」內容的可能性,發佈完整的預訓練模型是危險的。不管它們的發佈方法有什麼優點,模型本身都是在Transformer架構上訓練的。正如主要的AI專家Quoc Le所指出的,GTP-2版本展示了普通Transformer架構在大規模訓練時的威力……

隨着Transformer- xl的發佈,Transformer架構本身在2019年已經向前邁出了一步。這建立在原始轉換器的基礎上,並允許一次處理更長的輸入序列。這意味着輸入序列不需要被分割成任意固定的長度,而是可以遵循自然的語言邊界,如句子和段落。這有助於理解多個句子、段落和可能更長的文本(如冠詞)的深層上下文。
通過這種方式,Transformer架構為新模型打開了一個全新的開發階段。人們現在可以嘗試訓練更多的數據或不同類型的數據。或者,他們可以在轉換器上創建新的和創新的模型。這就是為什麼我們將在2019年看到許多NLP的新方法。
transformer架構的發佈為NLP深度學習方法創建了一個新的基線。人們可以看到這種新體系結構所提供的潛力,並很快嘗試尋找方法將其合併到新的更高級的NLP問題方法中。我們可以預計這些趨勢將持續到2019年。
4. 預先訓練的模型將發展更通用的語言技能
首先,像Transformer這樣的新架構使得在數據集上訓練模型變得更容易,而在此之前,人們認為數據集太大,而且學習數據集的計算開銷太大。這些數據集對大多數人來說都是不可用的,即使新的體系結構使得重新訓練他們自己的模型變得更容易,但對每個人來說仍然是不可行的。因此,這意味着人們需要使他們的預先訓練的模型可用現貨供應或建立和微調所需。
第二,TensorFlow Hub開啟了,這是一個可重用機器學習模型的在線存儲庫。這使它很容易快速嘗試一些先進的NLP模型,這也意味着你可以下載的模型,預先訓練了非常大的數據集。這與ELMo和Universal Sentence Encoder (USE)的出版是一致的。使用的是一種新的模型,它使用轉換器架構的編碼器部分來創建句子的密集向量表示。
5. 遷移學習將發揮更大的作用

遷移學習允許您根據自己的數據對模型進行微調
隨着更多的預先訓練模型的可用性,實現您自己的NLP任務將變得更加容易,因為您可以使用下載的模型作為您的起點。這意味着您可以在這些模型的基礎上構建自己的服務,並使用少量領域特定的數據對其進行快速培訓。如何在您自己的生產環境中實現這些下遊方法的一個很好的示例是將BERT作為服務提供的。
6. 微調模型將變得更容易
相反,原始模型的輸出,BERTs和ELMos,是一個密集的向量表示,或嵌入。嵌入從它所訓練的大的和一般的數據集中捕獲一般的語言信息。您還可以對模型進行微調,以生成對您自己的封閉域更敏感的嵌入。這種形式的微調的輸出將是另一種嵌入。因此,微調的目標不是輸出情緒或分類的概率,而是包含領域特定信息的嵌入。

7. BERT將改變NLP的應用前景

BERT的預先訓練的通用模型比它的任何前序都更強大。它已經能夠通過使用雙向方法將一種新技術納入到NLP模型的訓練中。這更類似於人類從句子中學習意義的方式,因為我們不只是在一個方向上理解上下文。我們在閱讀時也會提前投射以理解單詞的上下文。
8. 聊天機械人將從這一階段的NLP創新中受益最多

有了像GPT-2和BERT這樣的方法,情況就不一樣了。現在我們看到,一般訓練的模型可以在接近人類的水平上產生反應。而特定的封閉域聊天機械人則比較困難,因為它們需要進行微調。到2019年,將出現一種轉變,即創建工具來更容易地對模型(如BERT)進行微調,以獲得更小數量的領域特定數據。未來一年的主要問題將是,是更容易生成響應,還是使用新的NLP模型將傳入的客戶問題與之前存儲或管理的響應模板匹配起來。這種匹配將由發現問題和回答之間的相似性來驅動。調優越好,模型在識別新客戶查詢的潛在正確答案方面就越精確。
9. 零樣本學習將變得更加有效
零樣本學習是在一個非常大的數據集或一個非常不同的數據集上訓練一個通用模型。然後您可以將此模型應用於任何任務。在翻譯示例中,您將訓練一個模型並將其用作其他語言的通用翻譯程序。2018年底發表的一篇論文就做到了這一點,能夠學習93種不同語言的句子表示。

10. 關於人工智能的危險的討論可能會開始影響NLP的研究和應用
目前,深度學習NLP領域似乎是人工智能最令人興奮的領域之一。有這麼多事情要做,很難跟上最新的趨勢和發展。這是偉大的,它看起來將繼續和增長更快。唯一需要注意的是,經濟增長的速度可能太過迅猛,以至於我們需要更多的時間來考慮潛在的影響。
更多請參照請閱讀,ACL 主席、微軟亞洲研究院副院長周明博士在ACL2019主題演講《一起擁抱 ACL 和 NLP 的光明未來》,講述,NLP 領域的技術趨勢以及未來重要的發展方向。

講堂 | ACL 主席周明:一起擁抱 ACL 和 NLP 的光明未來
NLP 技術發展概覽
近年來,NLP 研究和技術發生了巨大變化。自2012年以來,最令人印象深刻的進展是基於深度神經網絡的 NLP——DNN-NLP。目前,DNN-NLP 已經形成了一整套相關技術,包括詞向量、句向量、編碼器- 解碼器、注意力機制、transformer 和各種預訓練模型。DNN-NLP 在機器翻譯、機器閱讀理解、聊天機械人、對話系統等眾多 NLP 任務中取得了重大進展。

NLP 未來之路
對於基礎任務,周明博士認為其中的關鍵問題是需要為各種模型的構建訓練和測試數據集。在設計良好的數據集上,每個人都可以提出新的方法,不同的模型之間可以相互競爭。
如果在這些任務上有所推進的話,我們的認知智能就會進一步提升,包括語言的理解水平、推理水平、回答問題能力、分析能力、解決問題的能力、寫作能力、對話能力等等。然後再加上感知智能的進步,聲音、圖象、文字的識別和生成的能力,以及多模態文、圖交叉的能力,通過文字可以生成圖象,根據圖象可以生成描述的文字等等,我們就可以推進很多應用的落地,包括搜索引擎、智能客服、AI教育、AI金融等等各個方面的應用。



