tensorflow學習筆記——圖像數據處理
- 2019 年 10 月 3 日
- 筆記
喜歡攝影的盆友都知道圖像的亮度,對比度等屬性對圖像的影響是非常大的,相同物體在不同亮度,對比度下差別非常大。然而在很多圖像識別問題中,這些因素都不應該影響最後的結果。所以本文將學習如何對圖像數據進行預處理使訓練得到的神經網絡模型儘可能小地被無關因素所影響。但與此同時,複雜的預處理過程可能導致訓練效率的下降。為了減少預處理對於訓練速度的影響,後面也學習多線程處理輸入數據的解決方案。
在大部分圖像識別問題中,通過圖像預處理過程可以提高模型的準確率。當然在TensorFlow中提供了幾類圖像處理函數,下面一一學習。
1,圖像編碼處理
我們知道一張RGB色彩模式的圖像可以看成一個三維矩陣,矩陣中的每個數表示了圖像上不同位置,不同顏色的亮度。然而圖像在存儲時並不是直接記錄這些矩陣中的數字,而是記錄經過壓縮編碼之後的結果。所以要將一張圖像還原成一個三維矩陣,需要解碼的過程。TensorFlow提供了對JPEG和png格式圖像的編碼/解碼函數。以下代碼示範了如何使用TensorFlow中對 JPEG 格式圖像的編碼/解碼函數。
#_*_coding:utf-8_*_ # matplotlib.pyplot 是一個python 的畫圖工具。下面用這個來可視化 import matplotlib.pyplot as plt import tensorflow as tf # 讀取圖像的原始數據 picture_path = 'kd.jpg' image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess: # 將圖像使用JPEG的格式解碼從而得到圖像對應的三維矩陣 # TensorFlow提供了 tf.image.decode_png 函數對png格式的圖像進行解碼 # 解碼之後的結果為一個張量,在使用它的取值之前需要明確調用運行的過程 img_data = tf.image.decode_jpeg(image_raw_data) # 輸出解碼之後的三維矩陣 # print(img_data.eval()) ''' # 輸出解碼之後的三維矩陣如下: [[[4 6 5] [4 6 5] [4 6 5] ... [35 29 31] [26 20 24] [25 20 26]]] ''' # 使用 pyplot工具可視化得到的圖像 plt.imshow(img_data.eval()) plt.show() # 將數據的類型轉化成實數方便下面的樣例程序對圖像進行處理 # img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32) # 將表示一張圖像的三維矩陣重新按照JPEG格式編碼並存入文件中 # 打開這種圖片可以得到和原始圖像一樣的圖像 encoded_image = tf.image.encode_jpeg(img_data) with tf.gfile.GFile('output.jpg', 'wb') as f: f.write(encoded_image.eval())
下圖顯示了上面代碼可視化出來的一張圖像:
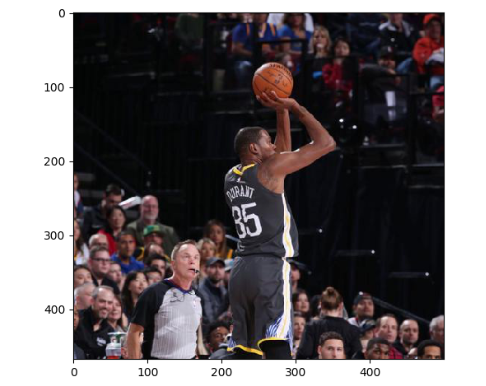
2,圖像大小調整
一般來說,網絡上獲取的圖像大小是不固定的,但神經網絡輸入節點的個數是固定的。所以在將圖像的像素作為輸入提供給神經網絡之前,需要先將圖像的大小統一。這就是圖像大小調整需要完成的任務。圖像大小調整有兩種方式,第一種是通過算法使得新的圖像盡量保存原始圖像上的所有信息。TensorFlow提供了四種不同的方法,並且將他們封裝到了 tf.image.resize_images 函數,下面代碼示範了如何使用這個函數。
# 加載原始圖像 # 讀取圖像的原始數據,然後解碼 picture_path = 'kd.jpg' image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess: # 將圖像使用JPEG的格式解碼從而得到圖像對應的三維矩陣 # TensorFlow提供了 tf.image.decode_png 函數對png格式的圖像進行解碼 # 解碼之後的結果為一個張量,在使用它的取值之前需要明確調用運行的過程 img_data = tf.image.decode_jpeg(image_raw_data) # 通過tf.image.resize_images函數調整圖像的大小 # 這個函數第一個參數為原始圖像,第二個和第三個參數為調整後圖像的大小 # method 參數給出了調整圖像大小的算法 resized = tf.image.resize_images(img_data, 300, 300, method=0) # 輸出調整後圖像的大小,此處的結果為(300, 300, ?)表示圖像的大小為300*300 # 但是在圖像的深度還沒有明確設置之前會是問號 print(img_data.get_shape)
下圖給出了 tf.image.resize_images 函數的 method 參數取值對應的圖像大小調整算法
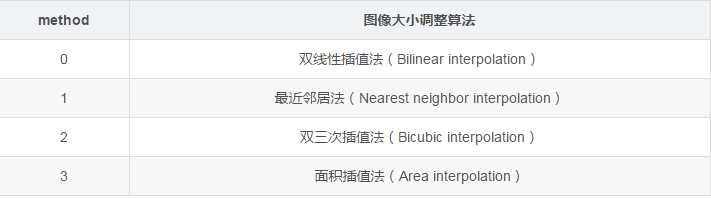
實例代碼如下:
#_*_coding:utf-8_*_ import matplotlib.pyplot as plt import tensorflow as tf import numpy as np # 讀取圖像的原始數據 picture_path = 'kd.jpg' image_raw_data = tf.gfile.FastGFile(picture_path, 'rb').read() with tf.Session() as sess: # 將圖像使用JPEG的格式解碼從而得到圖像對應的三維矩陣 # TensorFlow提供了 tf.image.decode_png 函數對png格式的圖像進行解碼 # 解碼之後的結果為一個張量,在使用它的取值之前需要明確調用運行的過程 img_data = tf.image.decode_jpeg(image_raw_data) img_data.set_shape([300, 300, 3]) print(img_data.get_shape()) # (300, 300, 3) # 重新調整圖片的大小 resized = tf.image.resize_images(img_data, [260, 260], method=0) # TensorFlow的函數處理圖片後存儲的數據是float32格式的, # 需要轉換成uint8才能正確打印圖片。 resized_photo = np.asarray(resized.eval(), dtype='uint8') # tf.image.convert_image_dtype(rgb_image, tf.float32) plt.imshow(resized_photo) plt.show()
結果如下:
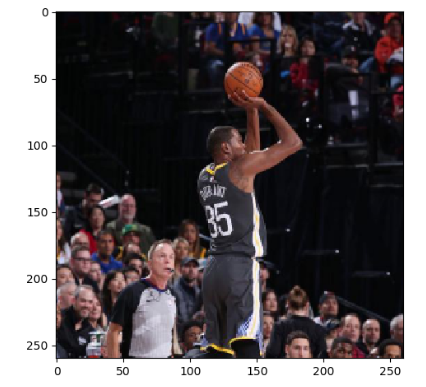
當然,我們也可以進行雙三插值法,面積插值法,最近鄰插值法進行處理。不同算法調整處理的結果會有細微差別,但不會相差太遠。
3,裁剪和填充
除了把整張圖像信息完整保存,TensorFlow還提供了API對圖像進行裁剪或者填充。TensorFlow提供了 tf.image.crop_to_bounding_box 函數 和 tf.image.pad_to_bounding_box 函數來剪裁或者填充給定區域的圖像。這兩個函數都要求給出的尺寸滿足一定的要求,否則程序會報錯。比如在使用 tf.image.crop_to_bounding_box 函數時候,TensorFlow要求提供的圖像尺寸要大於目標尺寸,也就是要求原始圖像能夠裁剪出目標圖像的大小。下面代碼展示了通過 tf.image_resize_image_with_crop_or_pad 函數來調整圖像大小的功能。
# 通過 tf.image_resize_image_with_crop_or_pad 函數調整圖像的大小 # 這個函數的第一個參數為原始圖像,後面兩個參數是調整後的模板圖像大小 # 如果原始圖像的尺寸大於目標圖像,那麼這個函數會自動截取圖像原始圖像中矩陣的部分 # 如果目標圖像大於原始圖像,這個函數會自動在原始圖像的四周填充全0的背景 # 因為我這個圖片是500*468,所以第一個命令自動裁剪,第二個命名自動填充 croped = tf.image.resize_image_with_crop_or_pad(img_data, 300, 300) padded = tf.image.resize_image_with_crop_or_pad(img_data, 600, 600)
下面示例看一下圖片:
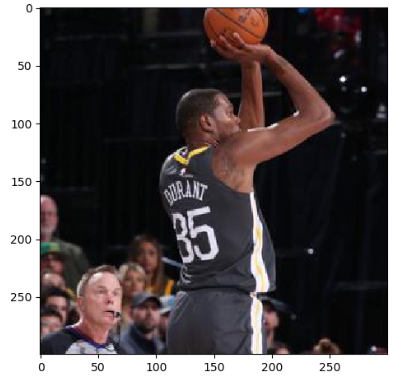
4,截取中間50%的圖片
TensorFlow還支持通過比例調整圖像大小,函數如下:
# 通過 tf.image.central_crop() 函數可以按比例裁剪圖像 # 函數第一個參數為原始圖像,第二個為調整比例 這個比例是需要在(0, 1] 的實數 # 下面意思是截取中間百分之五十 central_cropped = tf.image.central_crop(img_data, 0.5)
截取中間50%的結果展示如下:

5,翻轉圖片
TensorFlow提供了一些函數來支持對圖像的翻轉,下面代碼實現了將圖像上下反轉,左右反轉,以及沿對角線翻轉的功能。
# 上下翻轉 flipped1 = tf.image.flip_up_down(img_data) plt.imshow(flipped1.eval()) plt.show() # 左右翻轉 flipped2 = tf.image.flip_left_right(img_data) plt.imshow(flipped2.eval()) plt.show() #對角線翻轉 transposed = tf.image.transpose_image(img_data) plt.imshow(transposed.eval()) plt.show() # 以一定概率上下翻轉圖片。 #flipped = tf.image.random_flip_up_down(img_data) # 以一定概率左右翻轉圖片。 #flipped = tf.image.random_flip_left_right(img_data)
結果展示如下:



在很多圖像識別問題中,圖像的翻轉不會影響識別的結果。於是在訓練圖像識別的神經網絡模型時,可以隨機地翻轉訓練圖像。這樣訓練得到的模型可以識別不同角度的實體。比如假設在訓練數據中所有的貓頭都是向右的,那麼訓練出來的模型就無法很好的識別貓頭向左向右的貓。雖然這個問題可以通過收集更多的訓練數據來解決,但是通過隨機翻轉訓練圖像的方式可以在零成本的情況下很大的緩解該問題。所以隨機翻轉訓練圖像是一種很常見的圖像預處理方式。
6,圖像色彩調整
和圖像翻轉類似,調整圖像的亮度,對比度,飽和度和色相在很多圖像識別應用中都不會影響識別結果。所以在訓練神經網絡模型時,可以隨機調整訓練圖像的這些屬性,從而使得訓練得到的模型儘可能小的受到無關因素的影響。Tensorflow提供了調整這些色彩相關屬性的API,以下代碼顯示了如何修改圖像的亮度:
# 將圖片的亮度-0.5。 #adjusted = tf.image.adjust_brightness(img_data, -0.5) # 將圖片的亮度-0.5 #adjusted = tf.image.adjust_brightness(img_data, 0.5) # 在[-max_delta, max_delta)的範圍隨機調整圖片的亮度。 adjusted = tf.image.random_brightness(img_data, max_delta=0.5) # 將圖片的對比度-5 #adjusted = tf.image.adjust_contrast(img_data, -5) # 將圖片的對比度+5 #adjusted = tf.image.adjust_contrast(img_data, 5) # 在[lower, upper]的範圍隨機調整圖的對比度。 #adjusted = tf.image.random_contrast(img_data, lower, upper) plt.imshow(adjusted.eval()) plt.show()
結果展示如下:
7,圖像色相調整
下面代碼顯示了如何調整圖像的色相:
# 下面四條命令分別將色相加0.1 0.3 0.6 0.9 adjusted = tf.image.adjust_hue(img_data, 0.1) #adjusted = tf.image.adjust_hue(img_data, 0.3) #adjusted = tf.image.adjust_hue(img_data, 0.6) #adjusted = tf.image.adjust_hue(img_data, 0.9) # 在[-max_delta, max_delta]的範圍隨機調整圖片的色相。max_delta的取值在[0, 0.5]之間。 #adjusted = tf.image.random_hue(image, max_delta) # 將圖片的飽和度-5。 #adjusted = tf.image.adjust_saturation(img_data, -5) # 將圖片的飽和度+5。 #adjusted = tf.image.adjust_saturation(img_data, 5) # 在[lower, upper]的範圍隨機調整圖的飽和度。 #adjusted = tf.image.random_saturation(img_data, lower, upper) # 將代表一張圖片的三維矩陣中的數字均值變為0,方差變為1。 #adjusted = tf.image.per_image_whitening(img_data) plt.imshow(adjusted.eval()) plt.show()
結果展示一個調整色相0.1的圖片:
8,圖像標準化
圖像標準化的過程,其實就是將圖像上的亮度均值變為0, 方差變為1,下面代碼實現了這個功能:
# 圖像標準化 # 將代表一張圖像的三維矩陣中的數字均值變為0, 方差變為1 adjusted = tf.image.per_image_standardization(img_data) plt.imshow(adjusted.eval()) plt.show()
結果如下:
9,處理標註框
在很多圖像識別的數據集中,圖像中需要關注的物體通常會被標註圈出來,TensorFlow提供了一些工具來處理標註框。下面代碼展示了如何通過tf.image.draw_bounding_boxes函數在圖像中加入標註框。
# 將圖像縮小一些,這樣可視化能讓標註框更加清楚 img_data = tf.image.resize_images(img_data, 180, 267, method=1) # tf.image.draw_bounding_boxes 函數要求圖像矩陣中的數字為實數 # 所以需要先將圖像矩陣轉化為實數類型,次函數輸入的是一個batch的數據 #也就是多張圖像組成的四維矩陣,所以需要將解碼之後的圖像矩陣加一維 batched = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0) # 給出每一張圖像的所有標註框,一個標註框有四個數字,分別代表[ymin, xmin, ymax, xmax] # 注意這裡給出的數字都是圖像的相對位置,比如在180*267的圖像中 # [0.35, 0.47, 0.5, 0.56] 代表了從(63, 125) 到 (90, 150)的圖像 boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) result = tf.image.draw_bounding_boxes(batched, boxes) plt.imshow(result.eval()) plt.show()
和隨機翻轉圖像,隨機調整顏色類似,隨機截取圖像上有信息含量的部分也是一個提高模型健壯性(robustness)的一種方式。這樣可以使訓練得到的模型不受被識別物體大小的影響。下面程式展示了如何通過 tf.image.sample_distorted_bounding_box 函數來完成隨機截取圖像的過程。
boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) # 可以通過提供標註框的方式來告訴隨機截取圖像的算法那些部分是有信息量的 begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box( tf.shape(img_data), bounding_boxes=boxes) # 通過標註框可視化隨機截取得到的圖像 batched = tf.expand_dims( tf.image.convert_image_dtype(img_data, tf.float32), 0) image_with_box = tf.image.draw_bounding_boxes(batched, bbox_for_draw) # 截取隨機出來的圖像,因為算法帶有隨機成分,所以每次得到的結果會有所不同 distorted_image = tf.slice(img_data, begin, size) plt.imshow(distorted_image.eval()) plt.show()
結果如下:
10,圖像預處理完整樣例
上面學習了TensorFlow提供的主要圖像處理函數,在解決真實的圖像識別問題時,一般會同時使用多種處理方法,下面學習一個完整的樣例程序展示如何將不同的圖像處理函數結合成一個完整的圖像預處理流程。以下TensorFlow程序完成了從圖像片段截取,到圖像大小調整再到圖像翻轉及色彩調整的整個圖像預處理過程。
#_*_coding:utf-8_*_ import tensorflow as tf import numpy as np import matplotlib.pyplot as plt def distort_color(image, color_ordering=0): ''' 隨機調整圖片的色彩,定義兩種順序 下面將給定一張圖像,隨機調整圖像的色彩,因為點贊亮度,對比度,飽和度和色相的 順序將會影響最後得到的結果,所以可以定義多種不同的順序,具體使用哪一種順序可以 在訓練數據預處理時隨機的選擇一種,這樣可以進一步降低無關元素對模型的影響 :param image: :param color_ordering: :return: ''' if color_ordering == 0: image = tf.image.random_brightness(image, max_delta=32./255.) image = tf.image.random_saturation(image, lower=0.5, upper=1.5) image = tf.image.random_hue(image, max_delta=0.2) image = tf.image.random_contrast(image, lower=0.5, upper=1.5) else: image = tf.image.random_saturation(image, lower=0.5, upper=1.5) image = tf.image.random_brightness(image, max_delta=32./255.) image = tf.image.random_contrast(image, lower=0.5, upper=1.5) image = tf.image.random_hue(image, max_delta=0.2) #還可以elif 去設置其他的排列,但是這裡就不再一一列出了。 return tf.clip_by_value(image, 0.0, 1.0) def preprocess_for_train(image, height, width, bbox): ''' 對圖片進行預處理,將圖片轉化成神經網絡的輸入層數據 給定一張解碼後的圖像,目標圖像的尺寸以及圖像上的標註框 次函數可以對給出的額圖像進行預處理,這個函數的輸入圖像是圖像識別問題中 原始的訓練圖像,而輸出則是神經網絡模型的輸入層,注意這裡只處理模型的訓練數據 # 對於預測的數據,一般不需要使用隨機變換的步驟 :param image: :param height: :param width: :param bbox: :return: ''' # 查看是否存在標註框。如果沒有提供標註框,則認為整個圖像就是需要關注的部分 if bbox is None: bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4]) # 轉換圖像張量的類型 if image.dtype != tf.float32: image = tf.image.convert_image_dtype(image, dtype=tf.float32) # 隨機的截取圖片中一個塊。減少需要關注的物體大小對圖像識別算法ade影響 bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box( tf.shape(image), bounding_boxes=bbox) bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box( tf.shape(image), bounding_boxes=bbox) distorted_image = tf.slice(image, bbox_begin, bbox_size) # 將隨機截取的圖片調整為神經網絡輸入層的大小。大小調整的算法是隨機選擇的 distorted_image = tf.image.resize_images(distorted_image, [height, width], method=np.random.randint(4)) # 隨機左右反轉圖像 distorted_image = tf.image.random_flip_left_right(distorted_image) # 使用一種隨機的順序調整圖像色彩 distorted_image = distort_color(distorted_image, np.random.randint(2)) return distorted_image # 讀取圖像 image_raw_data = tf.gfile.FastGFile("kd.jpg", "rb").read() with tf.Session() as sess: img_data = tf.image.decode_jpeg(image_raw_data) boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) for i in range(9): result = preprocess_for_train(img_data, 299, 299, boxes) plt.imshow(result.eval()) plt.show()
運行上面的diam,可以得到下圖9張不同的圖像,因為運行6次圖像預處理。這樣就可以通過一張訓練圖像衍生出很多訓練樣本,通過將訓練圖像進行預處理,訓練得到的神經網絡模型可以識別不同大小,方位,色彩等方面的實例。
原圖如下:
處理之後的圖片如下:



11,python glob.glob的使用
函數功能:匹配所有的符合條件的問卷,並將其以 list的形式返回
示例,當前文件夾中有如下文件:

import glob list = glob.glob(‘*g’) print(list)
結果如下:
['dog.1012.jpg', 'dog.1013.jpg', 'dog.1014.jpg', 'dog.1015.jpg', 'dog.1016.jpg']
12,tensorflow tf.gfile的使用
tf.gfile()函數和python中os模塊非常的相似,一般都可以使用os模塊代替。
此函數的作用是讀寫文件,句柄具有 .read() 方法
''' 本代碼也是加載圖pb文件並獲取節點張量句柄的標準流程, feed_dict輸入節點 & sess.run(輸出節點)就可以使用模型了 ''' # 使用tf.gfile.FastGFile()函數的方法 # with tf.gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f: with open(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f: # 使用open()函數的方法 graph_def = tf.GraphDef() # 生成圖 graph_def.ParseFromString(f.read()) # 圖加載模型 # 從圖上讀取張量,同時把圖設為默認圖 bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def( graph_def, return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME]) print(gfile.FastGFile(image_path, 'rb').read() == open(image_path, 'rb').read()) # True
13,python np.squeeze()的使用
函數的作用:從數組的形狀中刪除單維條目,即把shape 中為1 的維度去掉。
#_*_coding:utf-8_*_ import numpy as np a = np.array([[1], [2], [3]]) print(a) print(a.shape) ''' 輸出結果如下: [[1] [2] [3]] (3, 1) ''' # 應用squeeze() 後 a1 = np.squeeze(a) print(a1) print(a1.shape) ''' 輸出結果如下: [1 2 3] (3,) '''
應用:在預測分析中用於處理預測數組和真實數組以方便計算預測值和真實值之間的誤差。
predictions = np.array(predictions).squeeze() labels = np.array(labels).squeeze() rmse = np.sqrt(((predictions - labels) ** 2).mean(axis=O))
14,tf.global_variables_initializer() 函數與tf.local_variables_initializer() 函數的區別
當我們訓練自己的神經網絡的時候,無一例外的就是都會加上一句sess.run(tf.global_variables_initializer() ),這行代碼的官方解釋是 初始化模型的參數。
tf.global_variables_initializer() 添加節點用於初始化全局的變量(GraphKeys.VARIABLES)。返回一個初始化所有全局變量的操作(Op)。在我們構建完整個模型並在會話中加載模型後運行這個節點,能夠將所有的變量一步到位的初始化,非常的方便。通過 feed_dict,我們也可以將指定的列表傳遞給它,只初始化列表中的變量。
示例代碼如下:
sess.run(tf.global_variables_initializer(), feed_dict={x: val_x, y: val_y, keep_prob: 1.0}
tf.local_variables_initializer() 添加節點用於初始化局部的變量(GraphKeys.LOCAL_VARIABLE), 返回一個初始化所有局部變量的操作(Op)。GraphKeys.LOCAL_VARIABLE 中的變量指的是被添加如圖中,但是未被存儲的變量。示例代碼與上面的類似。
注意:在使用局部變量時必須使用 tf.local_variables_initializer() 初始化器,在使用全局變量時必須使用 tf.global_variables_initializer() 初始化器,不然會報錯,報錯代碼類似下面:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninitialized value matching_filenames [[Node: _retval_matching_filenames_0_0 = _Retval[T=DT_STRING, index=0, _device="/job:localhost/replica:0/task:0/cpu:0"](matching_filenames)]]
此文是自己的學習筆記總結,學習於《TensorFlow深度學習框架》,俗話說,好記性不如爛筆頭,寫寫總是好的,所以若侵權,請聯繫我,謝謝。
