高可用集群corosync+pacemaker之crmsh使用(一)
- 2020 年 9 月 1 日
- 筆記
- Corosync/Pacemaker, crmsh, 高可用集群
上一篇博客我們聊了下高可用集群corosync+pacemaker的相關概念以及corosync的配置,回顧請參考//www.cnblogs.com/qiuhom-1874/p/13585921.html;今天我們來說一下corosync+pacemaker高可用集群的配置工具crmsh安裝和使用;在centos7上默認base參考沒有crmsh這個工具,紅帽默認在base倉庫中只留了pcs這個配置工具,所以我們要想在centos7上使用crmsh這個工具來管理corosync+pacemaker高可用集群,需要去找對應的包進行安裝;好在opensuse給centos7提供了一個倉庫,我們可以使用opensuse的參考去安裝這個工具;
1、配置opensuse倉庫
[root@node01 ~]# cd /etc/yum.repos.d/ [root@node01 yum.repos.d]# ls CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Sources.repo epel.repo CentOS-Base.repo.bak CentOS-fasttrack.repo CentOS-Vault.repo CentOS-CR.repo CentOS-Media.repo docker-ce.repo [root@node01 yum.repos.d]# rz rz waiting to receive. zmodem trl+C ȡ 100% 350 bytes 350 bytes/s 00:00:01 0 Errors [root@node01 yum.repos.d]# ls CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Sources.repo docker-ce.repo CentOS-Base.repo.bak CentOS-fasttrack.repo CentOS-Vault.repo epel.repo CentOS-CR.repo CentOS-Media.repo crmsh.repo [root@node01 yum.repos.d]# cat crmsh.repo [network_ha-clustering_Stable] name=Stable High Availability/Clustering packages (CentOS_CentOS-7) type=rpm-md baseurl=//download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/ gpgcheck=1 gpgkey=//download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/repodata/repomd.xml.key enabled=1 [root@node01 yum.repos.d]#
提示:crmsh這個工具是一個集群管理工具,只需要在某一台server安裝即可,如果有需要在其他節點管理集群,也可以在其他節點配置yum倉庫,安裝即可;
2、安裝crmsh
[root@node01 ~]# cd /etc/yum.repos.d/ [root@node01 yum.repos.d]# [root@node01 yum.repos.d]# cd [root@node01 ~]# yum install crmsh -y 已加載插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com 正在解決依賴關係 --> 正在檢查事務 ---> 軟件包 crmsh.noarch.0.3.0.0-6.2 將被 安裝 --> 正在處理依賴關係 crmsh-scripts >= 3.0.0-6.2,它被軟件包 crmsh-3.0.0-6.2.noarch 需要 --> 正在處理依賴關係 python-parallax,它被軟件包 crmsh-3.0.0-6.2.noarch 需要 --> 正在檢查事務 ---> 軟件包 crmsh-scripts.noarch.0.3.0.0-6.2 將被 安裝 ---> 軟件包 python-parallax.noarch.0.1.0.1-29.1 將被 安裝 --> 解決依賴關係完成 依賴關係解決 ==================================================================================================== Package 架構 版本 源 大小 ==================================================================================================== 正在安裝: crmsh noarch 3.0.0-6.2 network_ha-clustering_Stable 746 k 為依賴而安裝: crmsh-scripts noarch 3.0.0-6.2 network_ha-clustering_Stable 93 k python-parallax noarch 1.0.1-29.1 network_ha-clustering_Stable 36 k 事務概要 ==================================================================================================== 安裝 1 軟件包 (+2 依賴軟件包) 總計:875 k 總下載量:782 k 安裝大小:2.9 M ……省略部分內容…… Running transaction 正在安裝 : crmsh-scripts-3.0.0-6.2.noarch 1/3 正在安裝 : python-parallax-1.0.1-29.1.noarch 2/3 正在安裝 : crmsh-3.0.0-6.2.noarch 3/3 驗證中 : python-parallax-1.0.1-29.1.noarch 1/3 驗證中 : crmsh-3.0.0-6.2.noarch 2/3 驗證中 : crmsh-scripts-3.0.0-6.2.noarch 3/3 已安裝: crmsh.noarch 0:3.0.0-6.2 作為依賴被安裝: crmsh-scripts.noarch 0:3.0.0-6.2 python-parallax.noarch 0:1.0.1-29.1 完畢! [root@node01 ~]#
3、crmsh的使用
[root@node01 ~]# crm crm(live)# ls cibstatus help site cd cluster quit end script verify exit ra maintenance bye ? ls node configure back report cib resource up status corosync options history crm(live)# status Stack: corosync Current DC: node02.test.org (version 1.1.21-4.el7-f14e36fd43) - partition with quorum Last updated: Mon Aug 31 22:08:50 2020 Last change: Mon Aug 31 19:41:56 2020 by root via crm_attribute on node01.test.org 2 nodes configured 0 resources configured Online: [ node01.test.org node02.test.org ] No resources crm(live)# bye bye [root@node01 ~]# crm ls cibstatus help site cd cluster quit end script verify exit ra maintenance bye ? ls node configure back report cib resource up status corosync options history [root@node01 ~]# crm status Stack: corosync Current DC: node02.test.org (version 1.1.21-4.el7-f14e36fd43) - partition with quorum Last updated: Mon Aug 31 22:09:08 2020 Last change: Mon Aug 31 19:41:56 2020 by root via crm_attribute on node01.test.org 2 nodes configured 0 resources configured Online: [ node01.test.org node02.test.org ] No resources [root@node01 ~]#
提示:crm有兩種使用方式,一種是交互式,直接在命令行敲crm命令就可以進入交互式shell;另外一種是非交互式,在crm 命令後面直接加要執行的命令;
4、crmsh的幫助信息
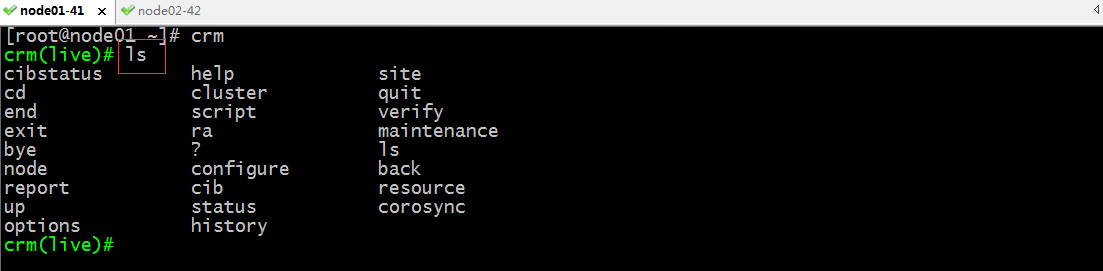
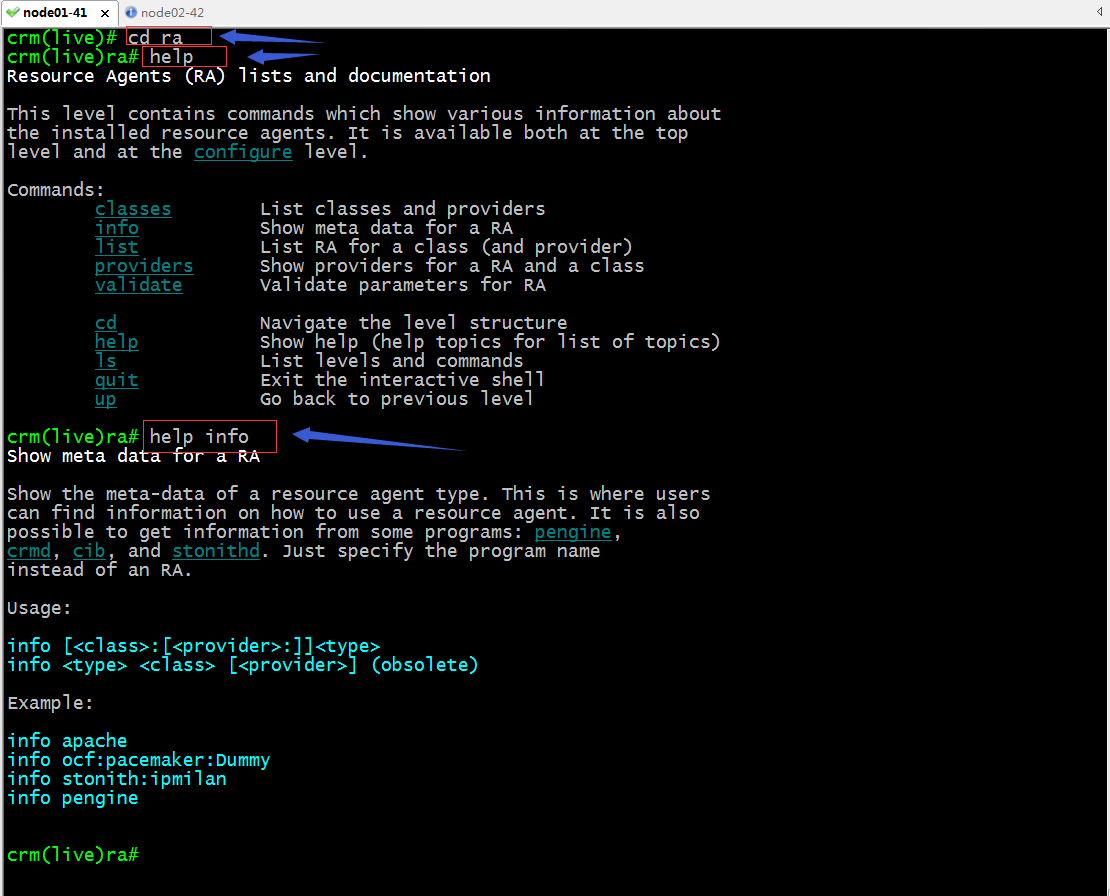
提示:進入交互式shell使用ls可以查看當前所在位置支持使用那些命令;crmsh它類似Linux中的文件系統,它可以使用ls查看當前位置可以使用的命令,也可以使用cd命令進入到下一個配置;比如要進入configure配置,我們可以使用cd configure 也可以直接敲configure進入configure配置;查看幫助可以使用help ,默認是現實當前界面的所有命令的簡要幫助,如果要查看某個命令的詳細使用格式,可以help 某個命令,如下所示;
5、常用命令使用
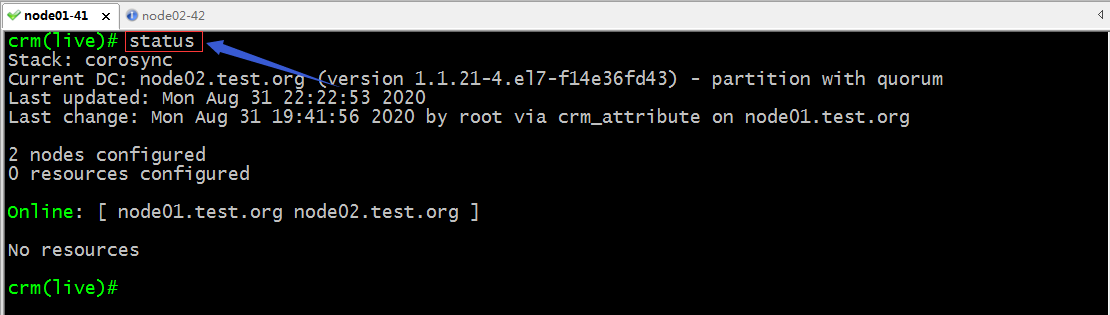
status:查看集群狀態信息同crm_mon作用一樣;
verify:驗證配置信息是否正確
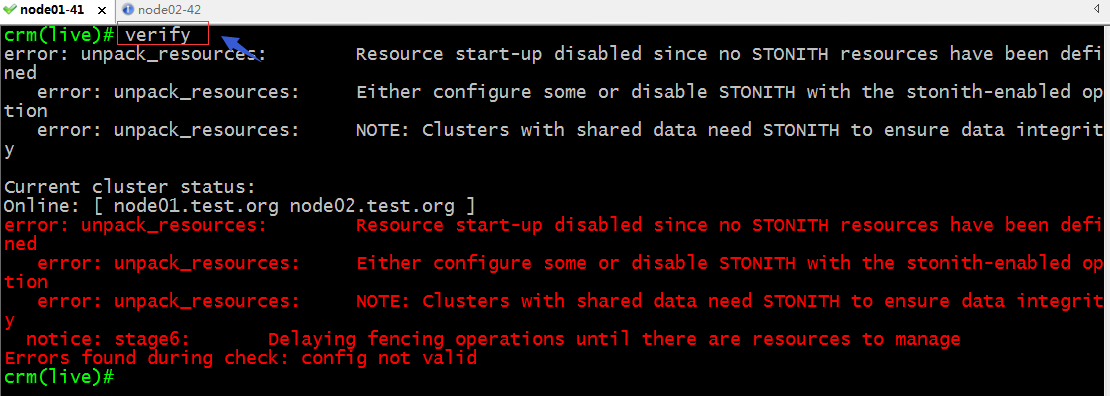
提示:以上校驗配置信息反饋給我們說我們配置了STONITH 但是並沒有發現STONITH設備;解決辦法關閉STONITH選項
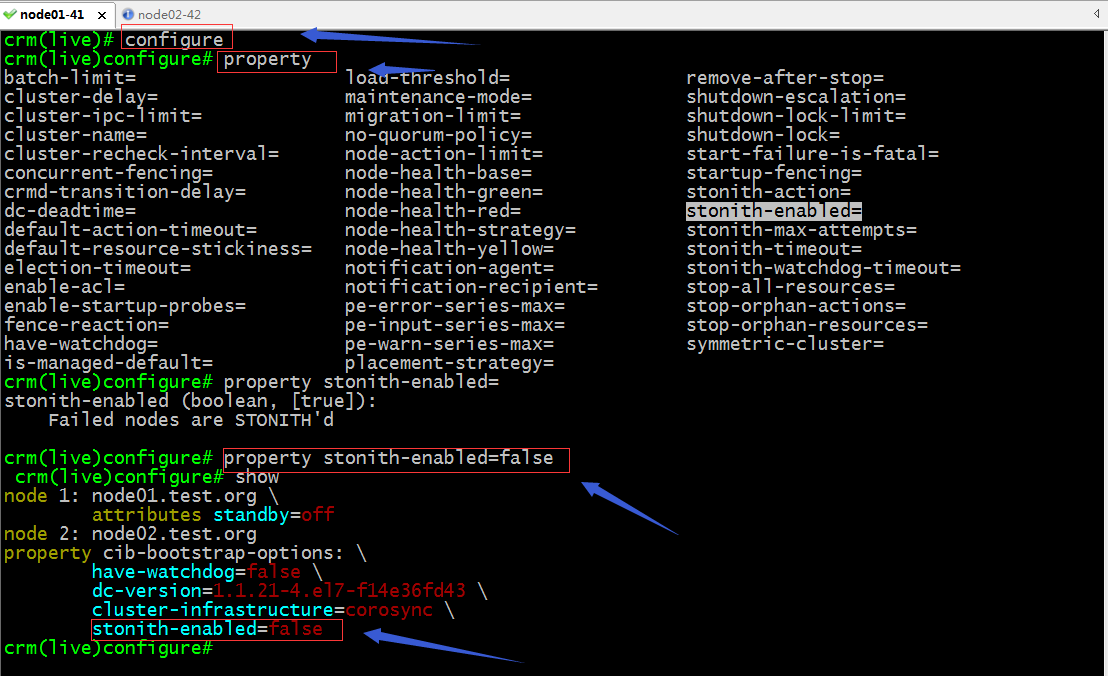
提示:我們的所有配置相關的操作都要進入到configure界面操作;property這個命令是用來設置集群相關屬性的;crmsh支持命令補全,如果不知道一個命令有那些參數可設置可以連續敲兩次tab鍵,它會列出支持的參數;
驗證配置,提交配置
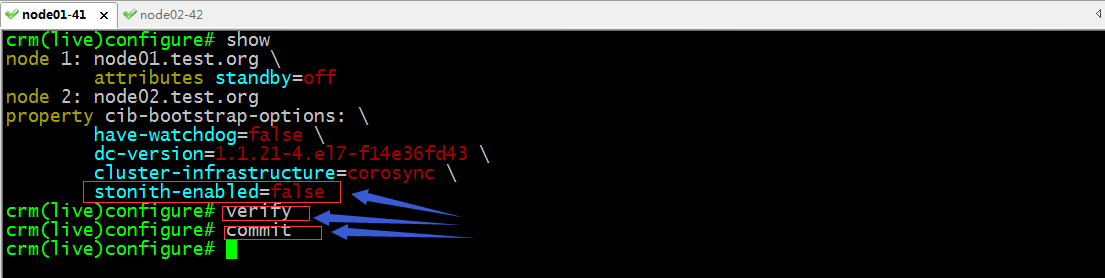
提示:只要verify沒有報任何錯誤信息都表示當前配置界面的配置信息正確;沒有任何錯誤,我們就可以使用commit命令來提交配置,讓其生效;
ra相關命令
classes:類出資源類別

info :查看指定資源代理的元數據信息,簡單講就是查看一個資源代理的詳細幫助信息;
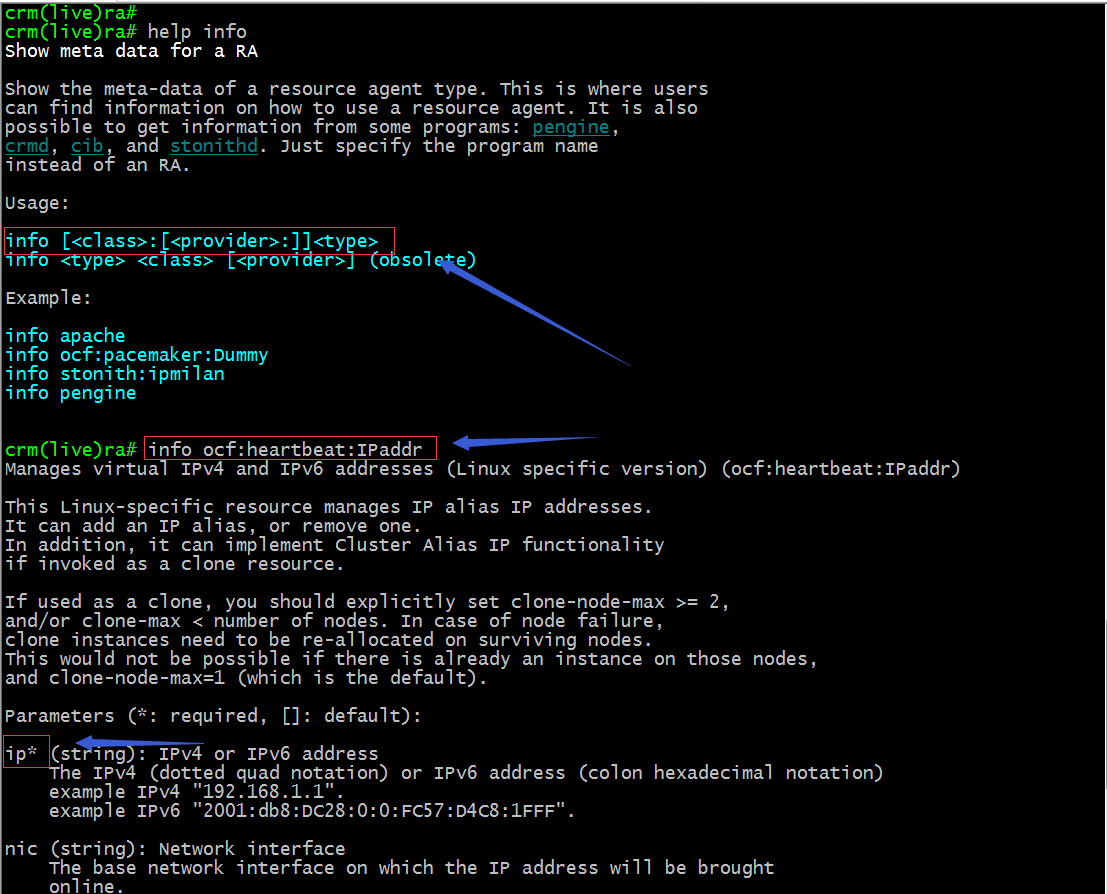
提示:以上截圖表示查看ocf類別下的heartbeat下的IPaddr這個資源的詳細幫助信息,其中帶星號的參數是比選項;
list:類出指定類別資源代理列表,就是查看指定類別的資源代理中有那些資源可以代理;
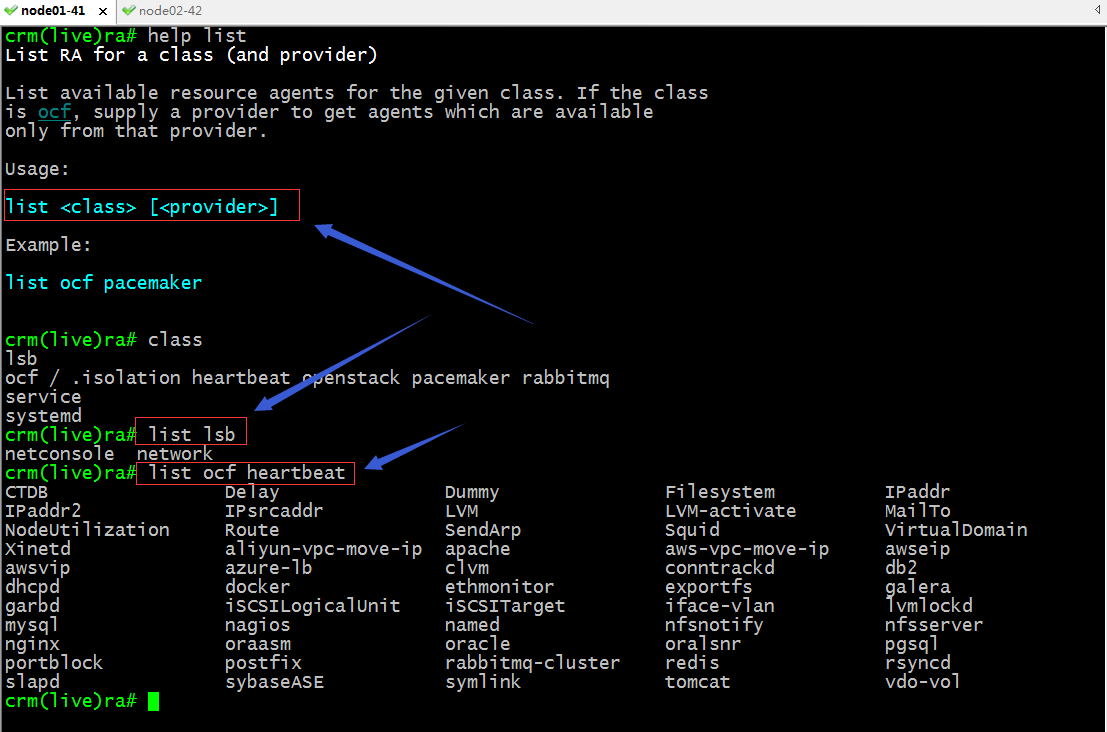
providers:查看指定資源是那個類別的資源代理;
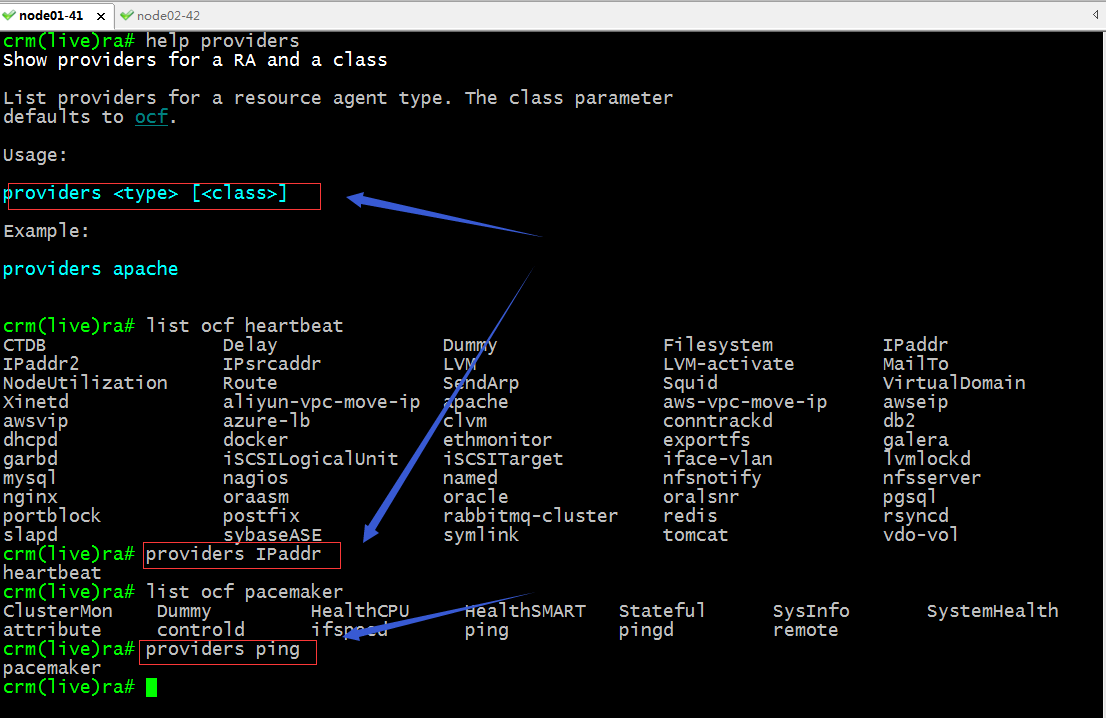
configure相關命令
primitive:定義一個基本資源;
命令使用語法
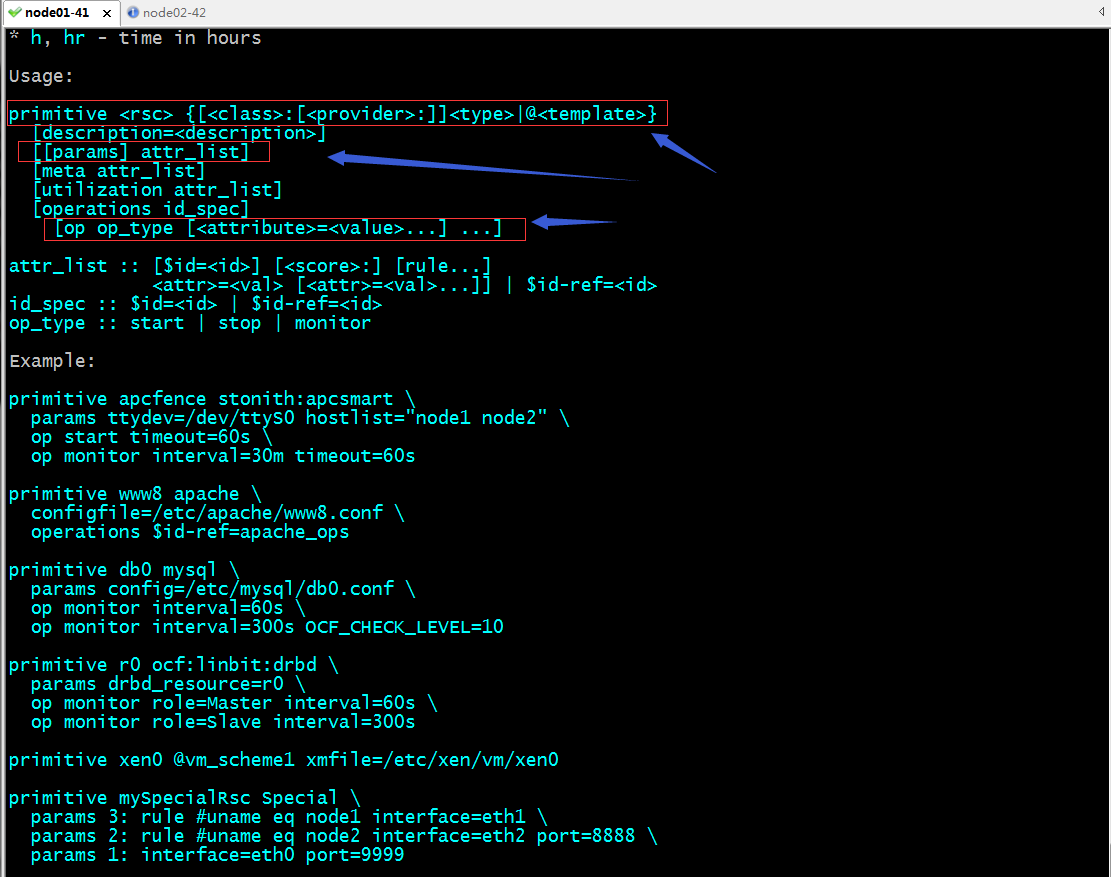
提示:在configure配置界面,可以使用primitive命令來定義一個資源,其中rsc表示給資源其一個名稱,然後指定資源的類別,和資源代理,然後加上指定資源代理需要的參數,以及選項就可以定義好一個資源;
示例:在configure配置界面定義一個ip資源
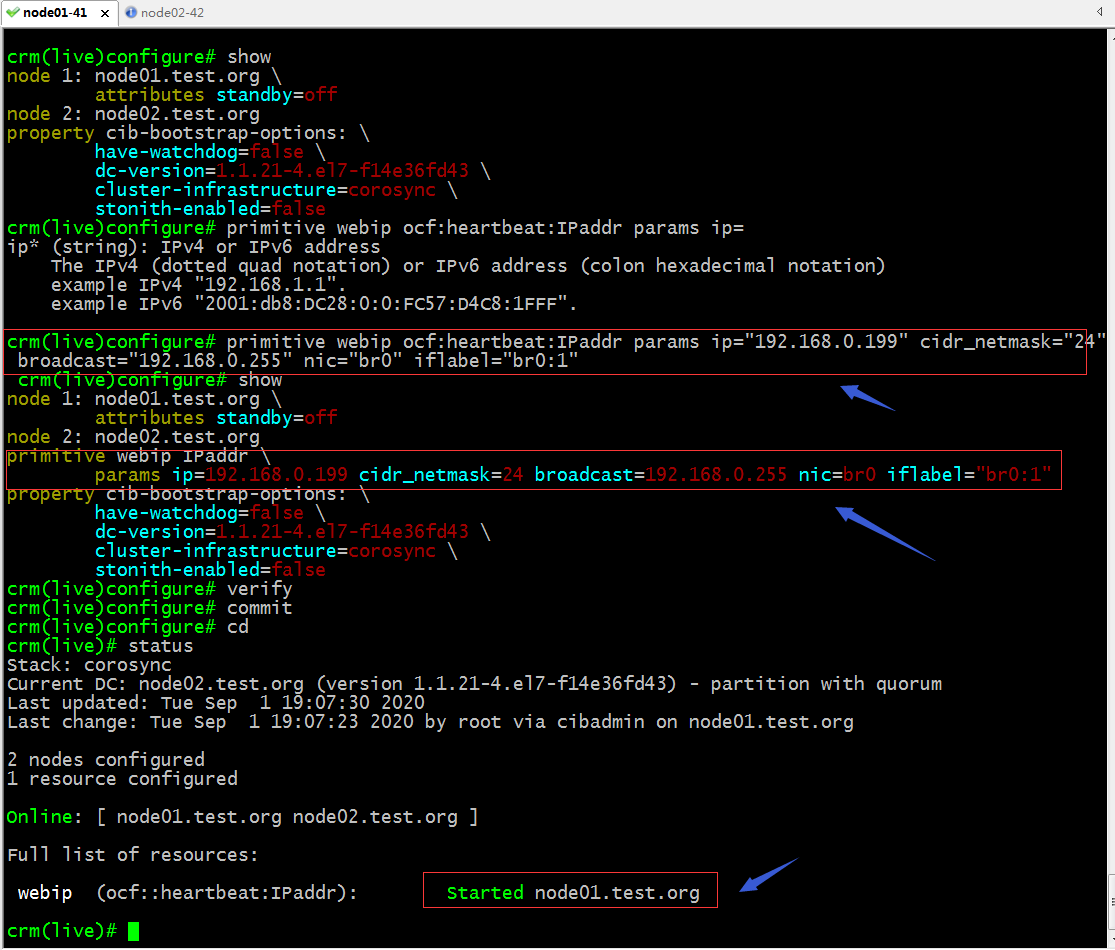
提示:可以看到當我們驗證配置界面的配置沒有問題以後,commit配置,對應的資源就生效了,並且在node01上生效了;
驗證:在node01上查看對應的ip地址是否配置上去了?

提示:可以看到對應ip地址的確在node01上給配置好了;
驗證:把node01下線,看看對應ip地址是否會轉移呢?
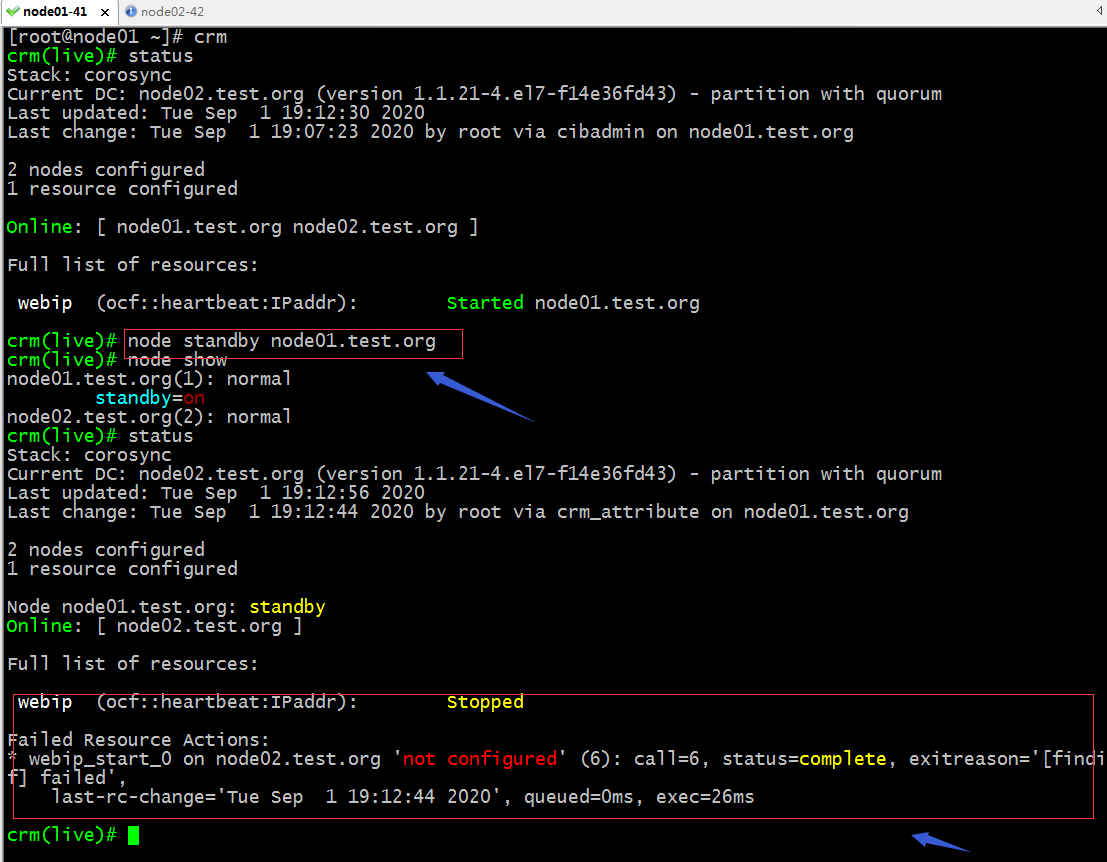
提示:我們把node01設置為standby以後,在查看集群狀態信息,可以看到對應的webip 這個資源已經停止了,並且給我們報了一個錯誤,說在node02.test.org上沒有配置;其實原因是在node02上並沒有br0這塊網卡,所以它轉移過去配置不成功;
在node02上添加一個br0網橋並把ens33橋接到br0上,把ens33的地址配置到br0上,然後重啟網絡服務,看看對應webip是否會遷移上來呢?
[root@node02 ~]# cd /etc/sysconfig/network-scripts/
[root@node02 network-scripts]# cat ifcfg-br0
TYPE=Bridge
NAME=br0
DEVICE=br0
ONBOOT=yes
IPADDR=192.168.0.42
PREFIX=24
GATEWAY=192.168.0.1
DNS1=192.168.0.1
[root@node02 network-scripts]# cat ifcfg-ens33
TYPE=Ethernet
NAME=ens33
DEVICE=ens33
ONBOOT=yes
BRIDGE=br0
[root@node02 network-scripts]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:91:99:30 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.42/24 brd 192.168.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe91:9930/64 scope link
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 52:54:00:fe:1b:15 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN qlen 1000
link/ether 52:54:00:fe:1b:15 brd ff:ff:ff:ff:ff:ff
[root@node02 network-scripts]# systemctl restart network
[root@node02 network-scripts]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master br0 state UP qlen 1000
link/ether 00:0c:29:91:99:30 brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 52:54:00:fe:1b:15 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN qlen 1000
link/ether 52:54:00:fe:1b:15 brd ff:ff:ff:ff:ff:ff
7: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 00:0c:29:91:99:30 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.42/24 brd 192.168.0.255 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::b41a:aeff:fe2e:ca6e/64 scope link
valid_lft forever preferred_lft forever
[root@node02 network-scripts]#
提示:可以看到node02上已經有br0,但是我們配置的ip地址並沒有遷移過來;
重新將node01上線,然後在下線,看看webip是否能夠遷移到node02上?
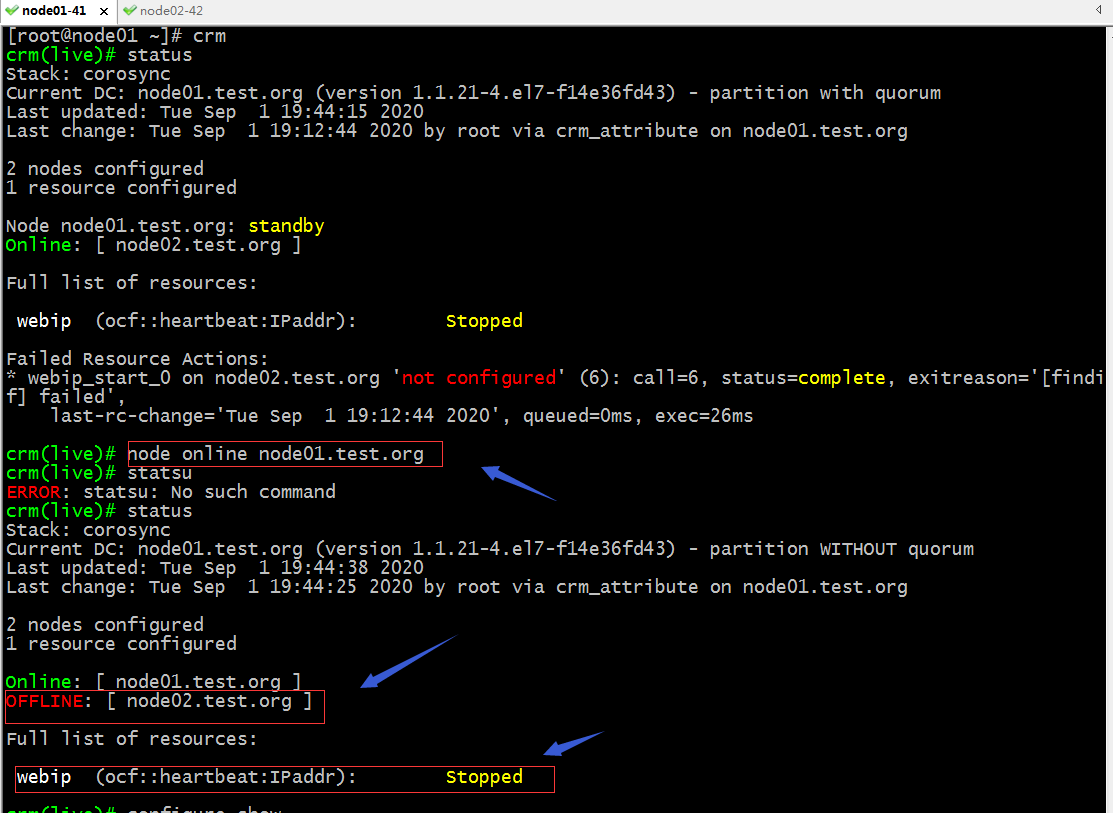
提示:重新將node01上線以後,再次查看集群狀態發現node02離線了,對應webip也停止了;這可能是因為我們剛才在node02上把地址遷移到br0上的原因;對於webip不能工作的原因是我們的集群式兩個節點的特殊集群,但其中一台server處於離線,就發生了集群網絡分區,在線的一方並沒有大於一般的選票,所以對應資源也就停止了;
重啟node02上的corosync pacemaker,然後再次使用查看集群狀態
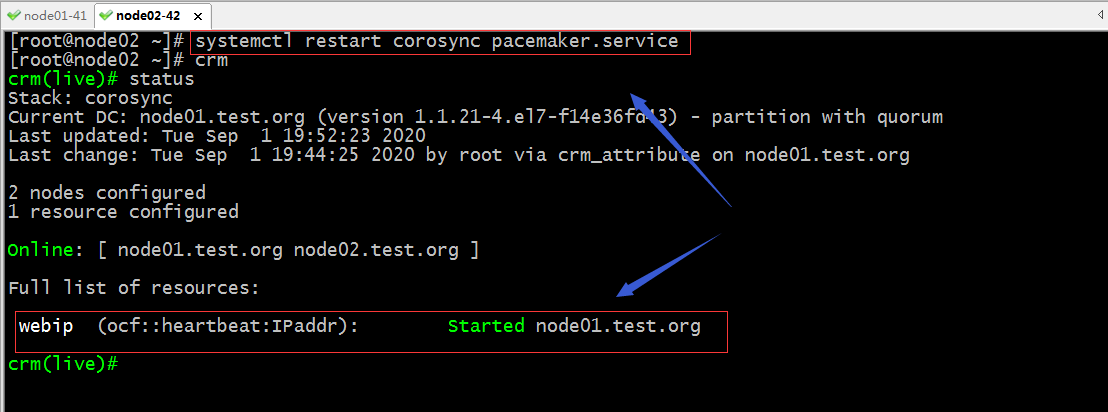
提示:重啟node02的corosync和pacemaker後,集群狀態恢復正常;
現在將node01設置成standby模式,看看是否將webip遷移到node02上?

提示:可以看到把node01設置為standby模式以後,webip就自動遷移到node02上了;
驗證:在node02上查看對應的webip是否真的遷移過來了呢?
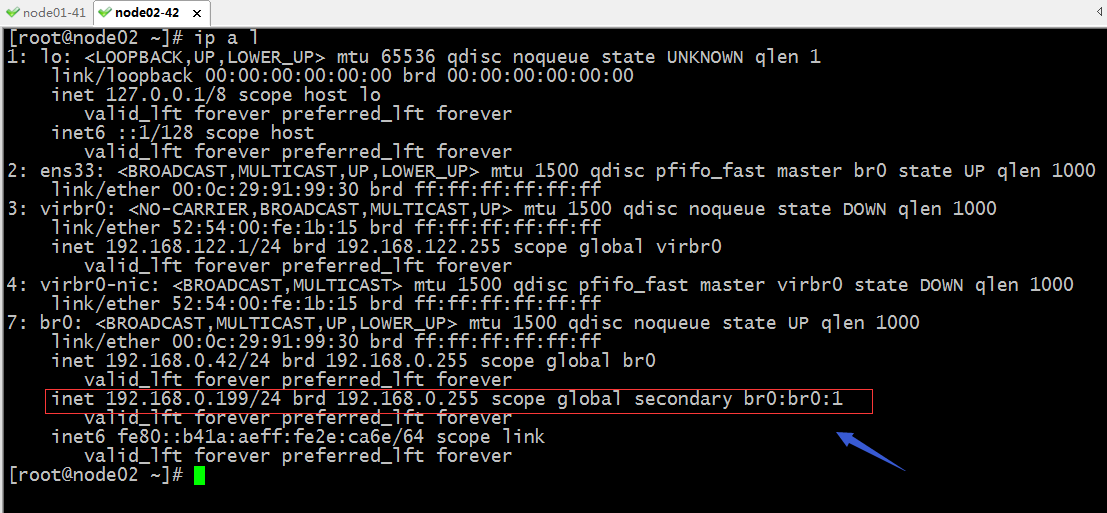
提示:在node02上也能看到對應webip資源遷移過來了;
monitor:定義資源的監控選項
命令使用語法
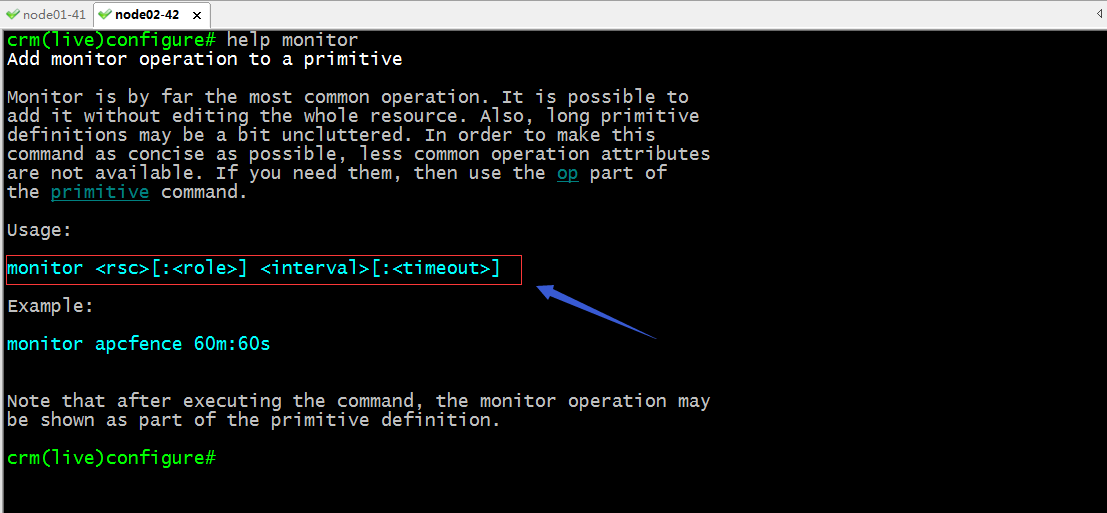
示例:給剛才的webip定義監控選項
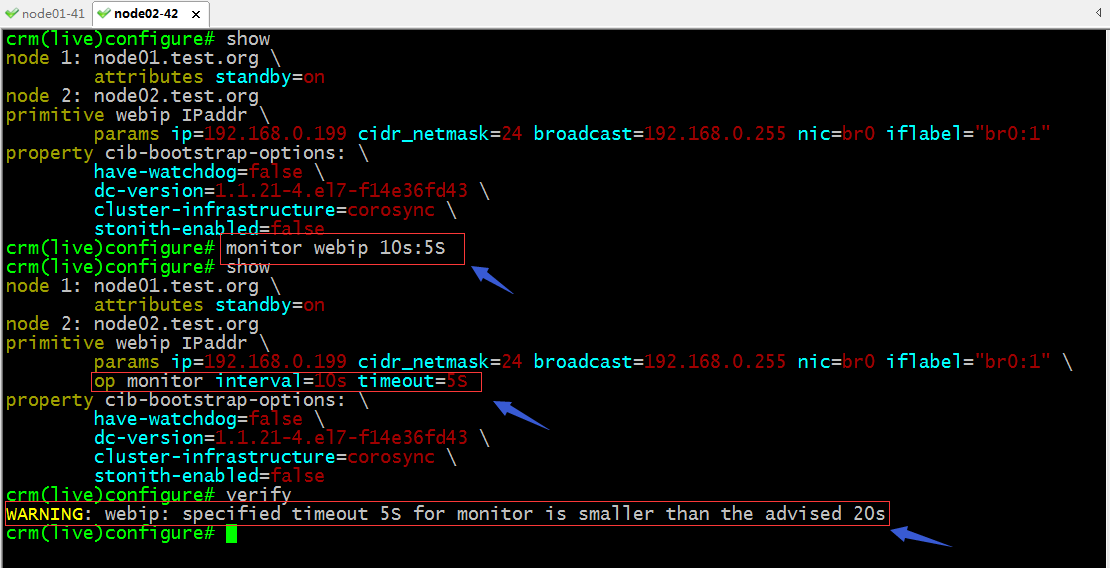
提示:從上面的截圖可以看到,我們給資源添加監控選項,不外乎在資源的後面用OP參數指定了OP參數類型是monitor,interval=# timeout=#;其實我們給資源添加監控選項在創建資源的時候就可以在其後使用OP monitor interval=時間 timeout=時間;這裡在校驗配置信息時提示我們設置的超時時間過短;為了不讓它警告我們,我們可以修改對應資源的timeout的值即可,如下
edit:用im編輯器打開配置文件,進行編輯
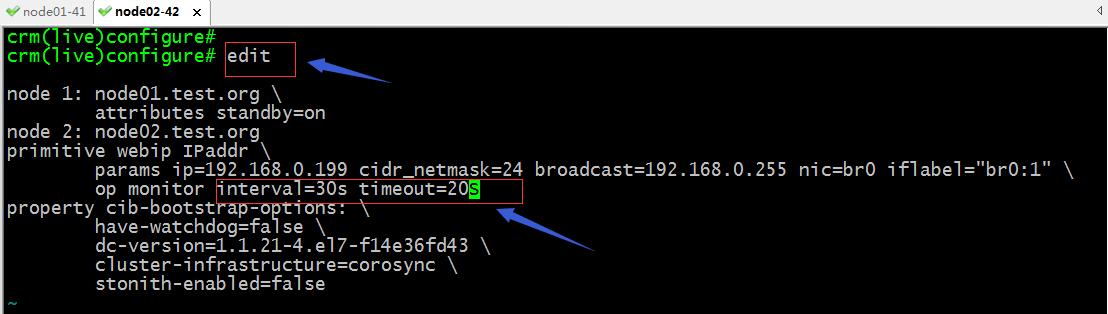
提示:使用edit命令即可打開當前configure界面的配置文件,我們可以修改自己需要修改的地方,然後保存退出即可

提示:可以看到當我們修改配置文件以後,再次使用show可以看到對應選項的值已經發生變化,校驗都沒有任何警告;
驗證:把node02上的br0:1上down掉看看,它會不會自動啟動起來?
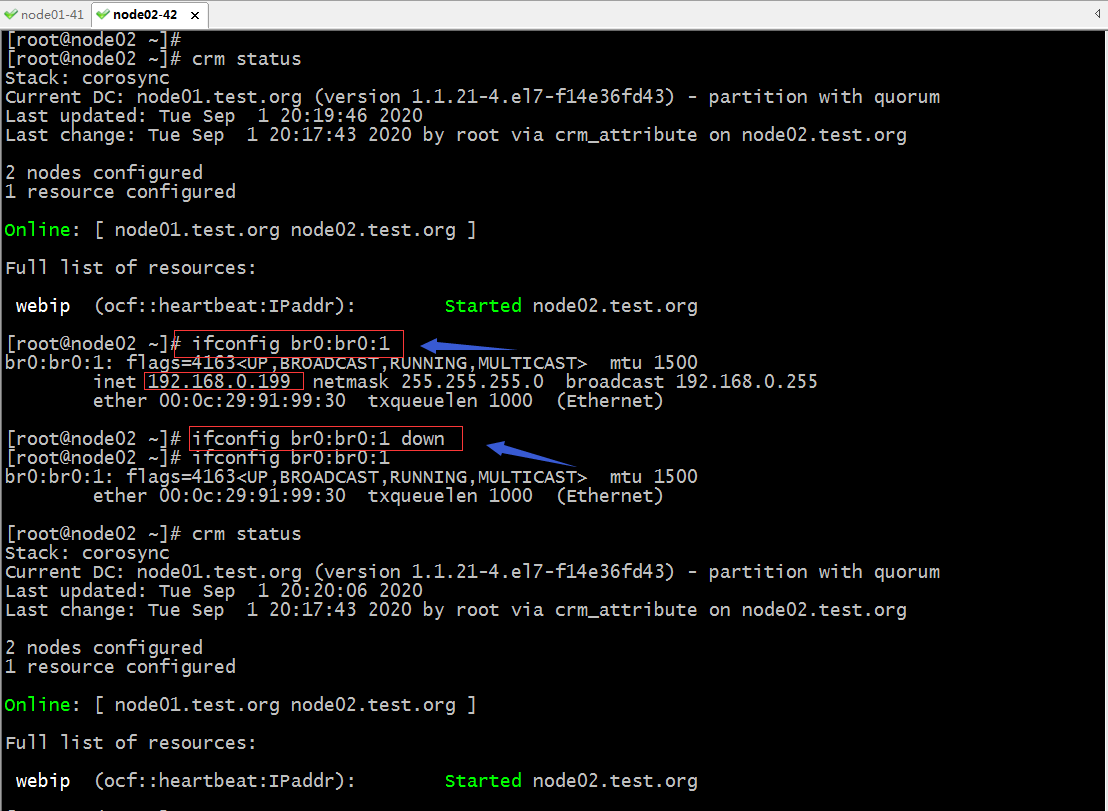
提示:剛開始把br0:br0:1down掉以後,在查看集群狀態對應webip是處於正常啟動狀態的,這是因為監控探測到時間沒有到;等上一會我們再次查看集群狀態就會發現報錯了;
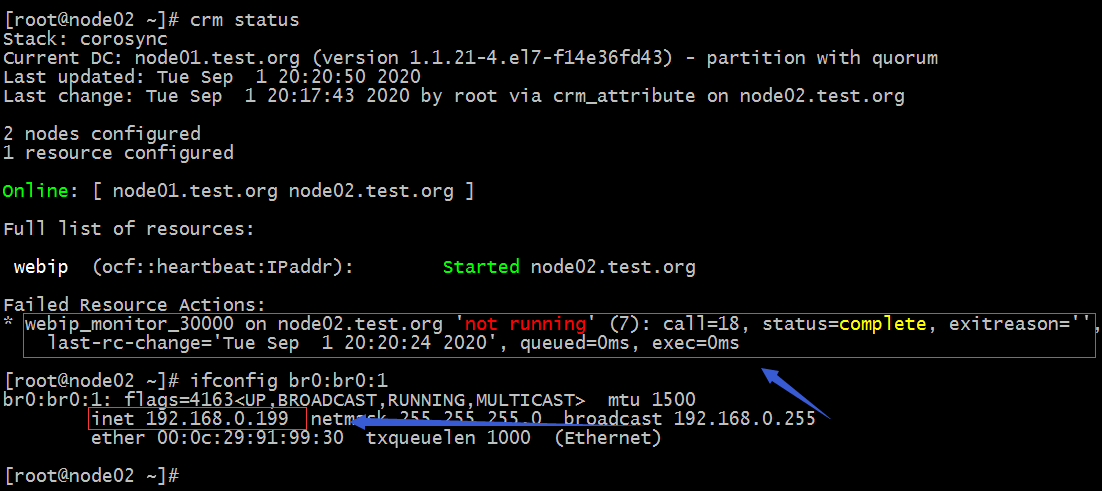
提示:我們定義的資源監控選項監控到對應資源故障以後,它會把故障寫進CIB中,然後把對應的資源進行重啟,一邊方便為門查看對應資源是否發生故障,提醒管理員排查相關故障;
示例2:定義web服務httpd託管在corosync+pacemaker高可用集群上
1、在集群節點上安裝httpd
[root@node01 ~]# yum install httpd -y
提示:在需要轉移到所有主機上都要安裝;
2、查看httpd資源代理需要用到的參數信息
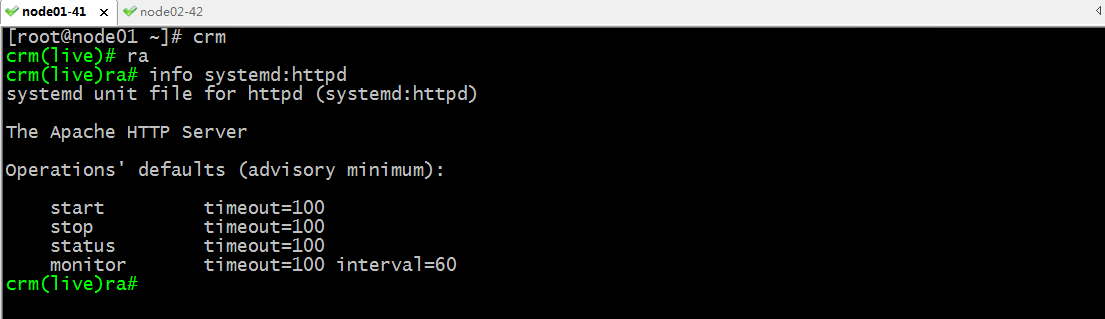
提示:從上面的截圖看,託管httpd不需要任何參數指定;
3、定義託管httpd

查看集群狀態

提示:這裡提示我們webserver在node01上啟動發生了未知錯誤,所以它在node02上啟動了;默認情況託管的服務會負載均衡的在集群節點上運行着;
在node01上排查錯誤
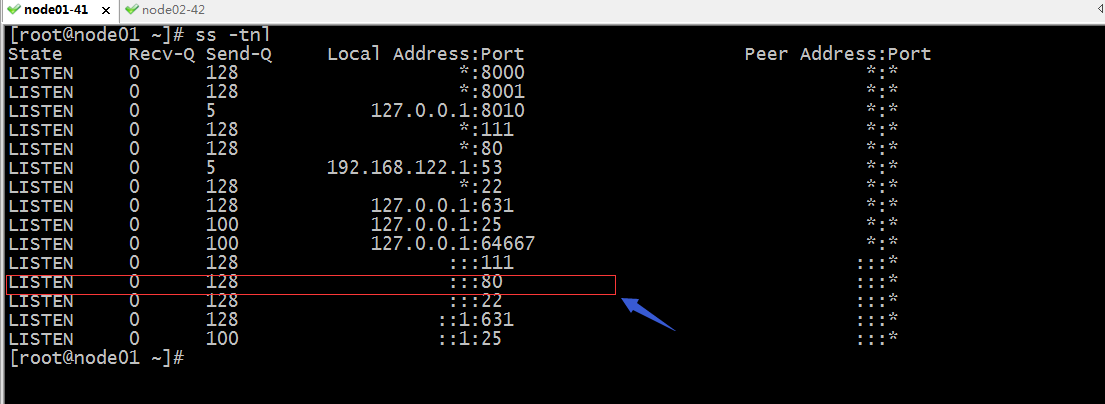
提示:在node01上查看端口信息,發現node01的80端口被佔用了,這也就導致httpd在node01上無法正常啟動;
停止掉node01的nginx服務,看看對應webserver是否會遷回node01?
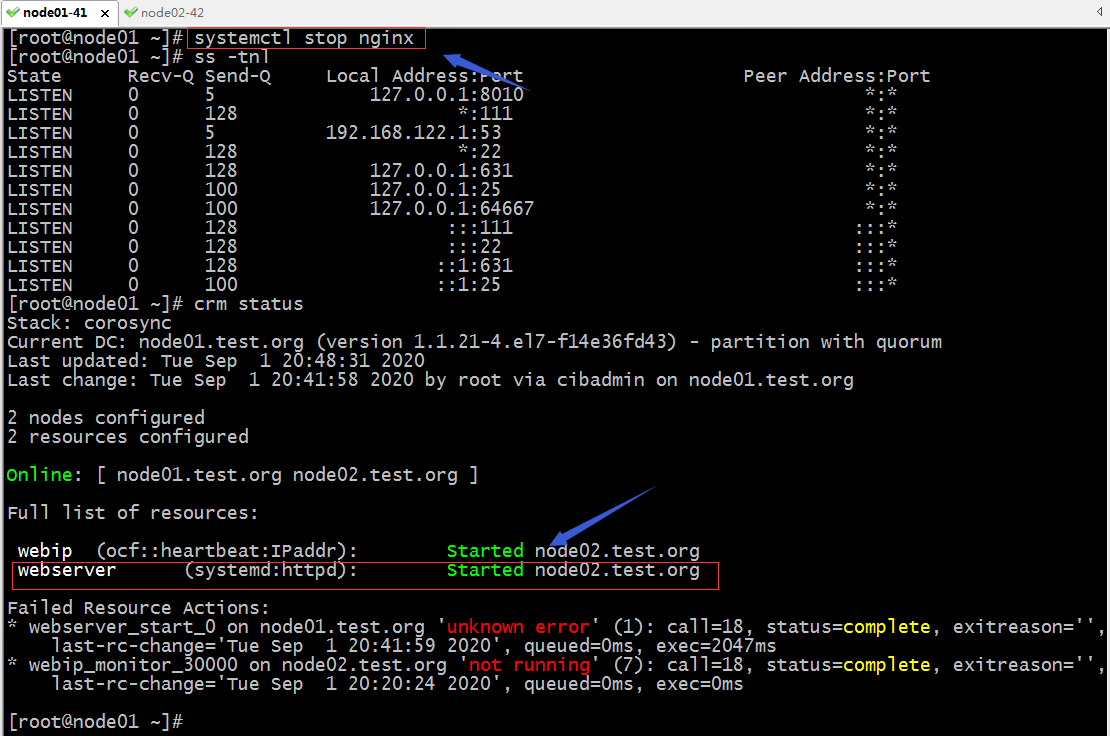
提示:可以看到把node01上的nginx服務停掉以後,webserver也沒有從node02遷回node01,這是因為webserver對node02的傾向性和對node01的傾向性是一樣的,所以它不會遷移會node01;
利用nfs共享存儲為httpd提供網頁文件
配置node03為nfs服務器
[root@node03 ~]# mkdir -p /data/htdocs/ [root@node03 ~]# cd /data/htdocs/ [root@node03 htdocs]# ls [root@node03 htdocs]# echo "<h1> This page on nfs server</h1>" > index.html [root@node03 htdocs]# cat index.html <h1> This page on nfs server</h1> [root@node03 htdocs]# cat /etc/exports /data/htdocs/ 192.168.0.0/24(rw) [root@node03 htdocs]# groupadd -g 48 apache [root@node03 htdocs]# useradd -u 48 -g 48 -s /sbin/nologin apache [root@node03 htdocs]# id apache uid=48(apache) gid=48(apache) groups=48(apache) [root@node03 htdocs]# setfacl -m u:apache:rwx /data/htdocs/ [root@node03 htdocs]# systemctl start nfs [root@node03 htdocs]# systemctl enable nfs-server.service Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service. [root@node03 htdocs]#
提示:我們共享的目錄必須要讓apache用戶對其有讀權限,其次httpd服務來訪問nfs是通過在httpd服務器上的apache用戶身份來訪問nfs,在nfs這邊它會識別其UID,所以我們在nfs上要新建一個同httpd服務器上的apache同id的用戶;並且設置該用戶對nfs共享出來的目錄有讀權限,如果業務需要上傳文件,我們還需要對共享目錄設置寫和執行權限;
配置託管nfs服務
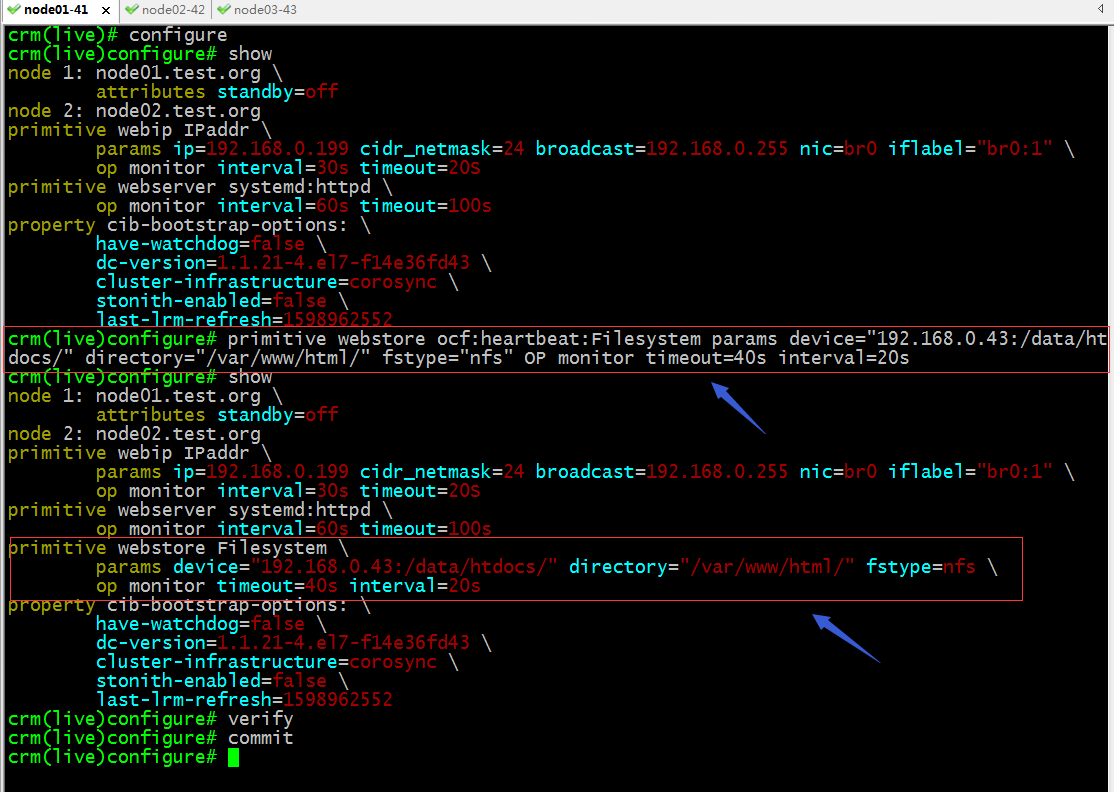
驗證:查看集群狀態,看看nfs服務是否運行到集群節點?
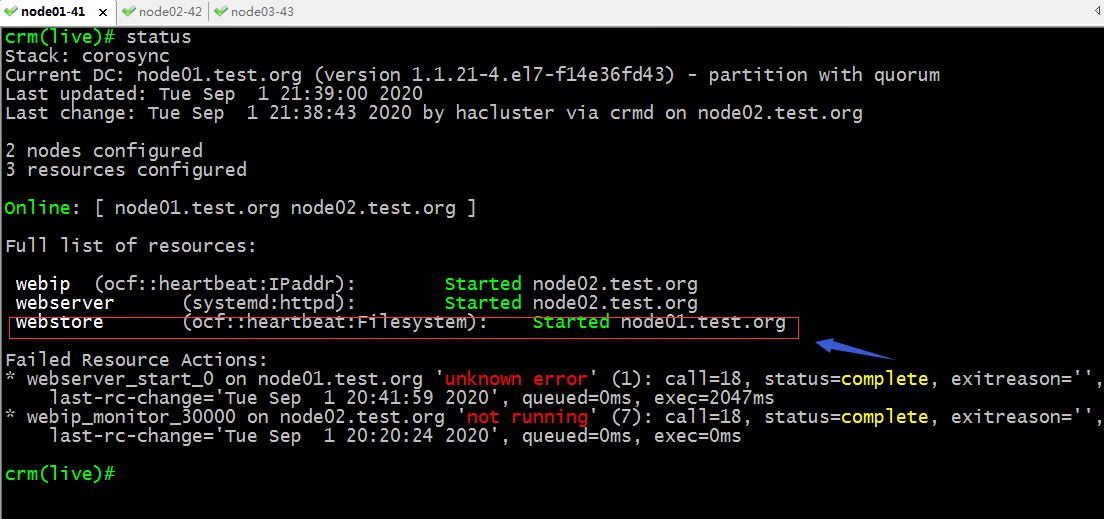
提示:可以看到westore已經在node01啟動了;
驗證:在node01上看看對應nfs是否真的掛載上了?
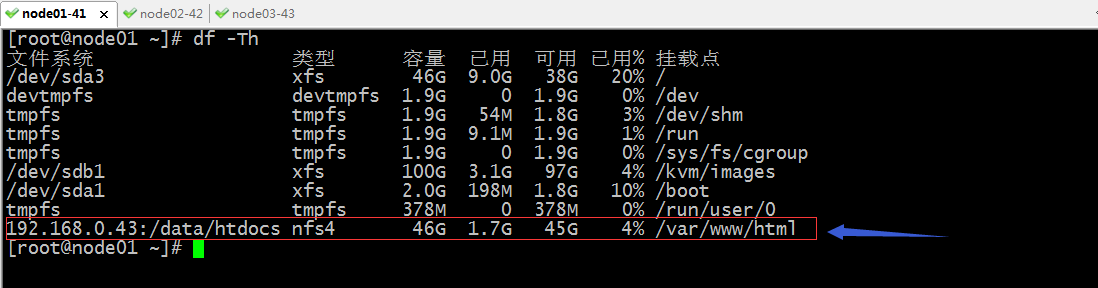
提示:可以看到node01上的確把nfs掛載到我們指定的目錄上了;
group:定義組,把多個資源歸併到一組;
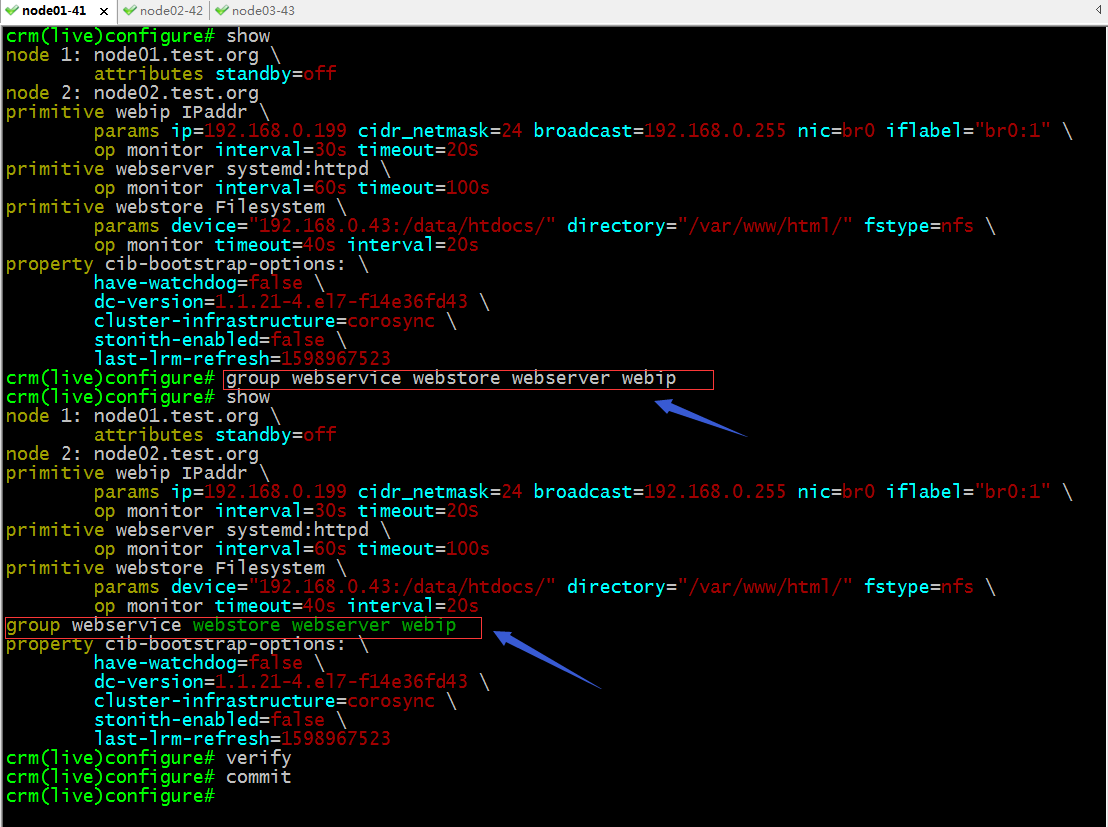
提示:這裡設置多個資源為一個組,默認它會按照先後順序啟動,停止是相反的順序,所以這裡的資源的前後決定了資源啟動順序和停止順序;
再次查看集群狀態信息
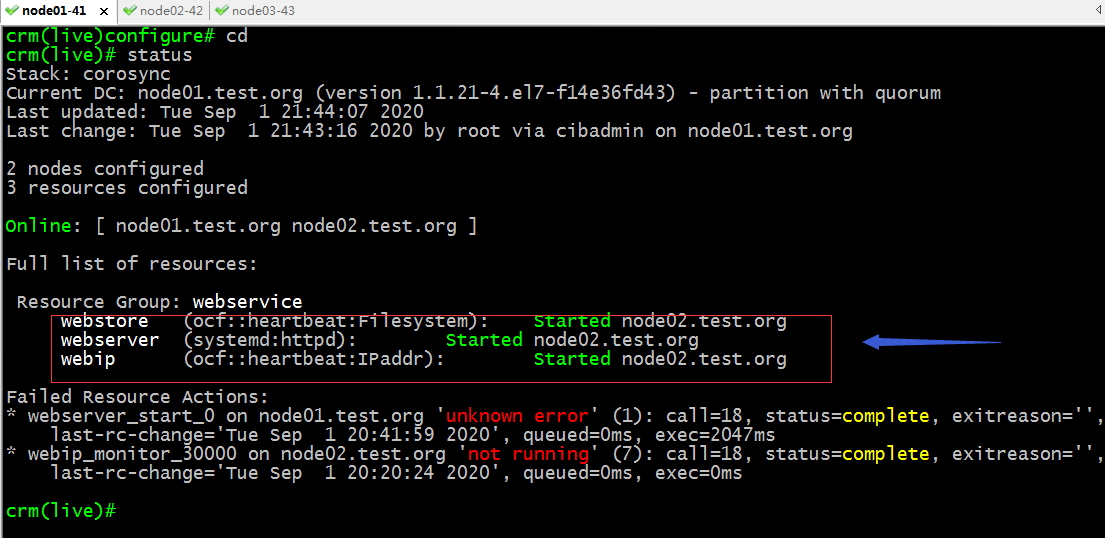
提示:可以看到webstore已經從node01遷移到node02上了;至此一個完整的web服務就託管在corosync+pacemaker高可用集群上了;
測試:用瀏覽器訪問webip看看是否能夠訪問到對應的網頁?
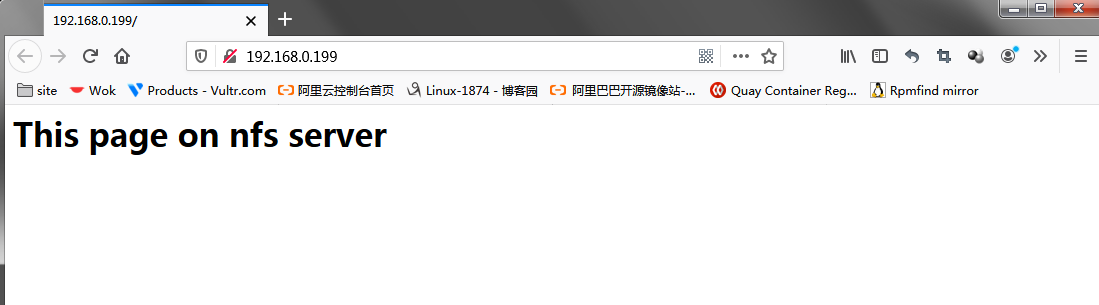
測試:把node02設置為standby模式,看看對應網頁是否能夠繼續訪問?
提示:可以看到把node02設置成standby模式以後,上面的資源都會遷移到node01上,對於服務來說只是短暫的影響,通常這種影響在用戶層面上無所感知的;
到此一個完整的web服務就託管到高可用集群corosync+pacemaker之上了;對於其他服務都是相同的邏輯;

