Redis秒殺實戰-微信搶紅包-秒殺庫存,附案例源碼(Jmeter壓測)
- 2020 年 8 月 31 日
- 筆記
- Redis, Spring Boot, 技術乾貨
導讀
前二天我寫了一篇,Redis高級項目實戰(點我直達),SpringBoot整合Redis附源碼(點我直達),今天我們來做一下Redis秒殺系統的設計。當然啦,Redis基礎知識還不過關的,先去加強下自身內功,然後在回來看這篇,Redis基礎知識(點我直達)。為啥寫這個微信搶紅包項目呢,公司0202年08月22日,公司周年慶,搶了100多紅包🧧,O(∩_∩)O哈哈~

微信搶紅包實現原理
業務流程分析 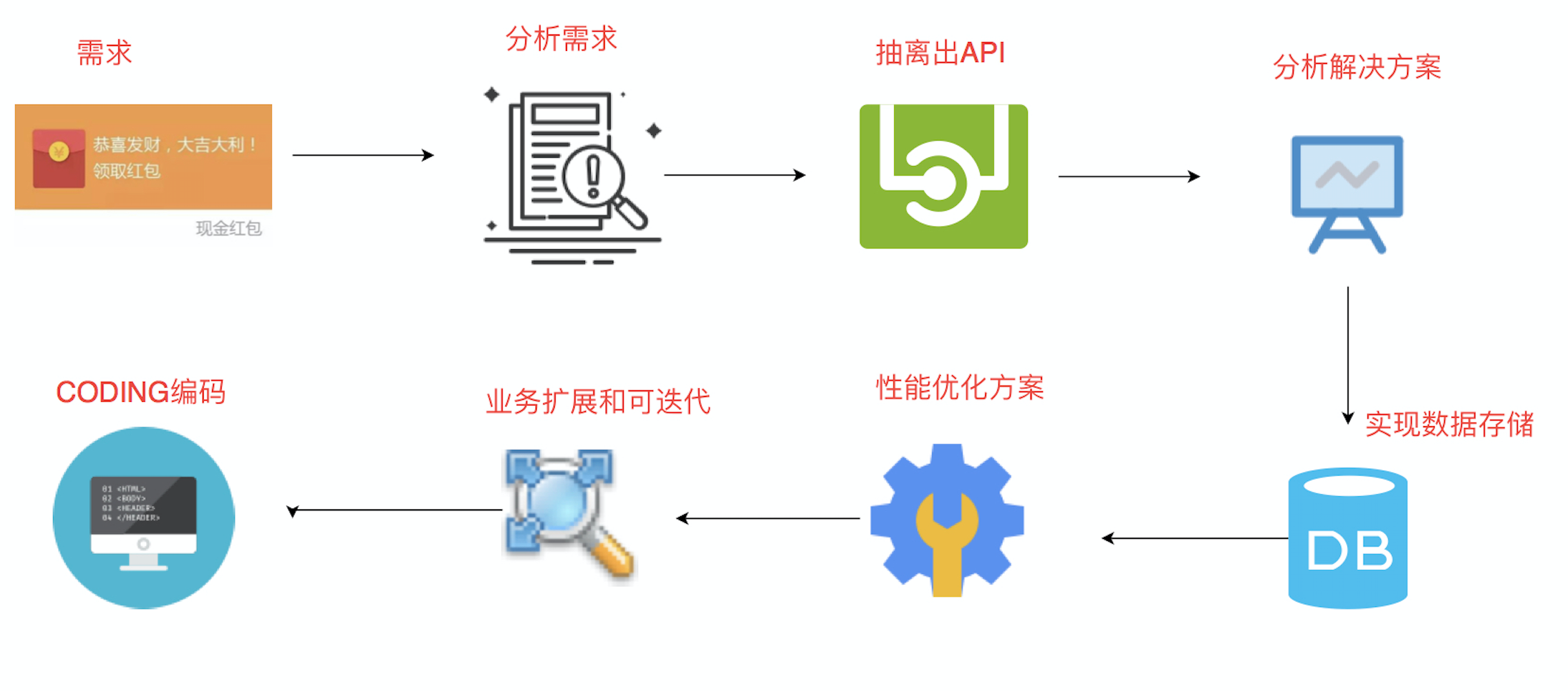

功能拆解
新建紅包
在DB、Redis分別新增一條記錄
搶紅包(並發)
請求Redis,紅包剩餘個數,大於0才可以拆,等會0時,提示用戶,紅包已搶完
拆紅包(並發)
用到技術
Redis中數據類型的String特性的原子遞減(DECR key)和減少指定值(DECRBY key decrement)
業務
- 請求Redis,當剩餘紅包個數大於0,紅包個數原子遞減,隨機獲取紅包
- 計算金額,當最後一個紅包時,最後一個紅包金額=總金額-總已搶紅包金額
- 更新數據庫
查看紅包記錄
查詢DB即可
數據庫表設計
紅包流水表
CREATE TABLE `red_packet_info` ( `id` int(11) NOT NULL AUTO_INCREMENT, `red_packet_id` bigint(11) NOT NULL DEFAULT 0 COMMENT '紅包id,采⽤ timestamp+5位隨機數', `total_amount` int(11) NOT NULL DEFAULT 0 COMMENT '紅包總⾦額,單位分', `total_packet` int(11) NOT NULL DEFAULT 0 COMMENT '紅包總個數', `remaining_amount` int(11) NOT NULL DEFAULT 0 COMMENT '剩餘紅包⾦額,單位 分', `remaining_packet` int(11) NOT NULL DEFAULT 0 COMMENT '剩餘紅包個數', `uid` int(20) NOT NULL DEFAULT 0 COMMENT '新建紅包⽤戶的⽤戶標識', `create_time` timestamp COMMENT '創建時間', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='紅包信息 表,新建⼀個紅包插⼊⼀條記錄';
紅包記錄表
CREATE TABLE `red_packet_record` ( `id` int(11) NOT NULL AUTO_INCREMENT, `amount` int(11) NOT NULL DEFAULT '0' COMMENT '搶到紅包的⾦額', `nick_name` varchar(32) NOT NULL DEFAULT '0' COMMENT '搶到紅包的⽤戶的⽤戶 名', `img_url` varchar(255) NOT NULL DEFAULT '0' COMMENT '搶到紅包的⽤戶的頭像', `uid` int(20) NOT NULL DEFAULT '0' COMMENT '搶到紅包⽤戶的⽤戶標識', `red_packet_id` bigint(11) NOT NULL DEFAULT '0' COMMENT '紅包id,采⽤ timestamp+5位隨機數', `create_time` timestamp COMMENT '創建時間', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新時間', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='搶紅包記 錄表,搶⼀個紅包插⼊⼀條記錄';


發紅包API
發紅包接口開發
- 新增一條紅包記錄
- 往mysql裏面添加一條紅包記錄
- 往redis裏面添加一條紅包數量記錄
- 往redis裏面添加一條紅包金額記錄

注意,往db中就單純存入一條記錄,Service層和Mapper層,就簡單的一條sql語句,主要是提供思路,下面會附案例源碼,不要慌
搶紅包API
- 搶紅包功能屬於原子減操作
- 當大小小於0時原子減失敗
- 當紅包個數為0時,後面進來的用戶全部搶紅包失敗,並不會進入拆紅包環節
- 搶紅包功能設計
- 將紅包ID的請求放入請求隊列中,如果發現超過紅包的個數,直接返回
- 注意事項
- 搶到紅包不一定能拆成功
搶紅包算法拆解

通過上圖算法得出,靠前面的人,手氣最佳幾率小,手氣最佳,往往在後面
- 發100元,共10個紅包,那麼平均值是10元一個,那麼發出來的紅包金額在0.01~20元之間波動
- 當前面4個紅包總共被領了30元時,剩下70元,總共6個紅包,那麼這6個紅包的金額在0.01~23.3元之間波動
搶紅包接口開發

測試
發紅包

模擬高並發搶紅包(Jmeter壓測工具)
因為我發了10個紅包,金額是20000,使用壓測工具,模擬50個請求,只允許前10個請求能搶到紅包,並且金額等於20000。



布隆過濾器(重要)
介紹
布隆過濾器是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的算法,缺點是有一定的誤識別率和刪除困難。
優點
相比於其他的數據結構,布隆過濾器在空間和時間方面都有巨大的優勢。布隆過濾器存儲空間和插入/查詢時間都是常數。另外三列函數相互之間沒有關係,方便由硬件並行實現。布隆過濾器不需要存儲元素本身,在某些對保密要求非常嚴格的場合有優勢。
缺點
但是布隆過濾器的缺點和有點一樣明顯。誤算率是其中之一。隨着存入的元素數量增加,誤算率隨之增加。但是如果元素數量太少,則使用散列表足矣。
布隆過濾器有什麼用?
- 黑客流量攻擊:故意訪問不存在的數據,導致查程序不斷訪問DB的數據
- 黑客安全阻截:當黑客訪問不存在的緩存時迅速返迴避免緩存及DB掛掉
- 網頁爬蟲對URL的去重,避免爬取相同的URL地址
- 反垃圾郵件,從數十億個垃圾郵件列表中判斷某郵件是否垃圾郵件(同理,垃圾短訊)
- 緩存擊穿,將已存在的緩存放到布隆中,當黑客訪問不存在的緩存時迅速返迴避免緩存及DB掛掉
布隆過濾器實現會員轉盤抽獎
需求
一個抽獎程序,只針對會員用戶有效

通過google布隆過濾器存儲會員數據
- 程序啟動時將數據放入內存中
- google自動創建布隆過濾器
- 用戶ID進來之後判斷是否是會員
代碼實現
引入依賴
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency>
數據庫會員表
CREATE TABLE `sys_user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `user_name` varchar(11) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '⽤戶名', `image` varchar(11) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '⽤戶頭像', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;

初始化布隆過濾器
dao層和dao映射文件,就單純的一個sql查詢,看核心方法,下面會附源碼滴,不要慌好嘛

控制層

測試

缺點
- 內存級別產部
- 重啟即失效
- 本地內存無法用在分佈式場景
- 不支持大數據量存儲
Redis布隆過濾器
優點
- 可擴展性Bloom過濾器
- 不存在重啟即失效或定時任務維護的成本
缺點
- 需要網絡IO,性能比基於內存的過濾器低
布隆過濾器安裝
下載
github://github.com/RedisBloom/RedisBloom
鏈接: //pan.baidu.com/s/16DlKLm8WGFzGkoPpy8y4Aw 密碼: 25w1
編譯
make

將Rebloom加載到Redis中
先把Redis給停掉!!!在redis.conf裏面添加一行命令->加載模塊
loadmodule /usr/soft/RedisBloom-2.2.4/redisbloom.so

測試布隆過濾器

SpringBoot整合Redis布隆過濾器(重點)
編寫兩個lua腳本
- 添加數據到指定名稱的布隆過濾器
- 從指定名稱的布隆過濾器獲取key是否存在的腳本

local bloomName = KEYS[1]
local value = KEYS[2]
--bloomFilter
local result_1 = redis.call('BF.ADD',bloomName,value)
return result_1

local bloomName = KEYS[1]
local value = KEYS[2]
--bloomFilter
local result_1 = redis.call('BF.EXISTS',bloomName,value)
return result_1
在RedisService.java中添加2個方法

驗證

秒殺系統設計
秒殺業務流程圖


數據落地存儲方案
- 通過分佈式redis減庫存
- DB存最終訂單信息數據
API性能調優
- 性能瓶頸在高並發秒殺
- 技術難題在於超賣問題
實現步驟
1、提前將秒殺數據緩存到redis
set skuId_start_1 0_1554045087 --秒殺標識
set skuId_access_1 12000 --允許搶購數
set skuId_count_1 0 --搶購計數
set skuId_booked_1 0 --真實秒殺數
- 秒殺開始前,skuId_start為0,代表活動未開始
- 當skuId_start改為1時,活動開始,開始秒殺叭
- 當接受下單數達到sku_count*1.2後,繼續攔截所有請求,商品剩餘數量為0(為啥接受搶購數為1萬2呢,看業務流程圖,涉及到「校驗訂單信息」,一般設置的值要比總數多一點,多多少自己定)
2、利用Redis緩存加速增庫存數
"skuId_booked":10000 //從0開始累加,秒殺的個數只能加到1萬
3、將用戶訂單數據寫入MQ(異步方式),可以看我另外一篇博客:點我直達
4、另外一台服務器監聽mq,將訂單信息寫入到DB
好了,以上就是完整的開發步驟,下面我們開始編寫代碼
代碼實戰
網關瀏覽攔截層
1、先判斷秒殺是否已經開始
2、利用Redis緩存incr攔截流量
- 用incr方法原子加
- 通過原子加帕努單當前skuId_access是否達到最大值
訂單信息校驗層
1、校驗當前用戶是否已經買過這個商品
- 需要存儲用戶的uid
- 存數據庫效率太低
- 存Redis value方式數據太大
- 存布隆過濾器性能高且數據量小(推薦)
2、校驗通過直接返回搶購成功
開發lua腳本實現庫存扣除
1、庫存扣除成功,獲取當前最新庫存
2、如果庫存大於0,即馬上進行庫存扣除,並且訪問搶購成功給用戶
3、考慮原子性問題
- 保證原子性的方式,採用lua腳本
- 採用lua腳本方式保證原子性帶來缺點,性能有所下降
- 不保證原子性缺點,放入請求量可能大於預期
- 當前扣除庫存場景必須保證原子性,否則會導致超賣
4、返回搶購結果
- 搶購成功
- 庫存沒了,搶購失敗
控制層

Service層

布隆過濾器

初始化redis緩存

set skuId_start_1 0_1554045087 --秒殺標識
set skuId_access_1 12000 --允許搶購數
set skuId_count_1 0 --搶購計數
set skuId_booked_1 0 --真實秒殺數
秒殺驗證
jmeter配置

壓測秒殺驗證原子性



項目下載

鏈接: //pan.baidu.com/s/1hZUPRAljkqO05fYluqJBhQ 密碼: 1iwr
尾聲
演示的時候,我使用的Redis單機的,吞吐量不是很大,感興趣的,可以自己搭建個Redis主從複製+哨兵+集群,然後再測試。
最近比較忙,沒時間完善微信搶紅包秒殺的原子性。下面那個完整案例搶庫存的,親自使用Jmeter壓測幾次,是原子性的,可以拿來借鑒,感興趣的同學,可以借鑒下面搶庫存的代碼,把微信搶紅包的功能在完善下,我就不修改啦,今天先到這,有不懂的歡迎下面留言。