LeetCode刷題總結-遞歸篇
- 2019 年 10 月 27 日
- 筆記
遞歸是算法學習中很基本也很常用的一種方法,但是對於初學者來說比較難以理解(PS:難點在於不斷調用自身,產生多個返回值,理不清其返回值的具體順序,以及最終的返回值到底是哪一個?)。因此,本文將選擇LeetCode中一些比較經典的習題,通過簡單測試實例,具體講解遞歸的實現原理。本文要將的內容包括以下幾點:
- 理解遞歸的運行原理
- 求解遞歸算法的時間複雜度和空間複雜度
- 如何把遞歸用到解題中(尋找遞推關係,或者遞推公式)
- 記憶化操作
- 尾遞歸
- 剪枝操作
理解遞歸的運行原理
例1求解斐波那契數列
題目描述(題目序號:509,困難等級:簡單):
求解代碼(基礎版):
class Solution { public int fib(int N) { if(N <= 1) return N; return fib(N - 1) + fib(N - 2); } }
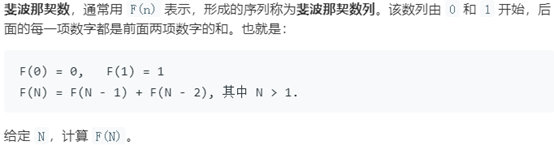
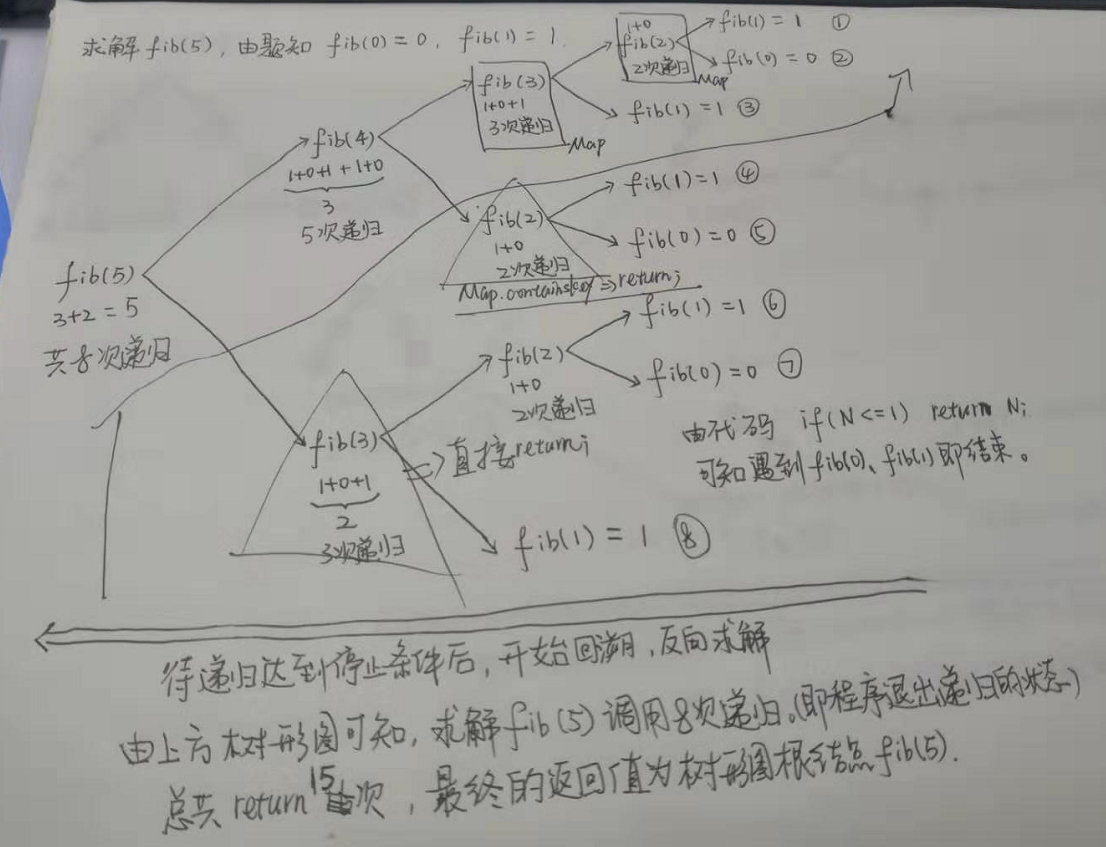
現在以N = 5為例,分析上述代碼的運行原理,具體如下圖:
遞歸的返回值很多,初學者很難理解最終的返回值是哪個,此時可以採用上圖的方式畫一個樹形圖,手動執行遞歸代碼,樹形圖的葉節點即為遞歸的終止條件,樹形圖的根節點即為最終的返回值。樹形圖的所有節點個數即為遞歸程序得到最終返回值的總體運行次數,可以藉此計算時間複雜度,這個問題會在後文講解。
例2 二叉樹的三種遍歷方式
二叉樹的遍歷方式一般有四種:前序遍歷、中序遍歷、後序遍歷和層次遍歷,前三種遍歷方式應用遞歸可以大大減少代碼量,而層次遍歷一般應用隊列方法(即非遞歸方式)求解。以下將要講解應用遞歸求解二叉樹的前、中、後序遍歷的實現原理。
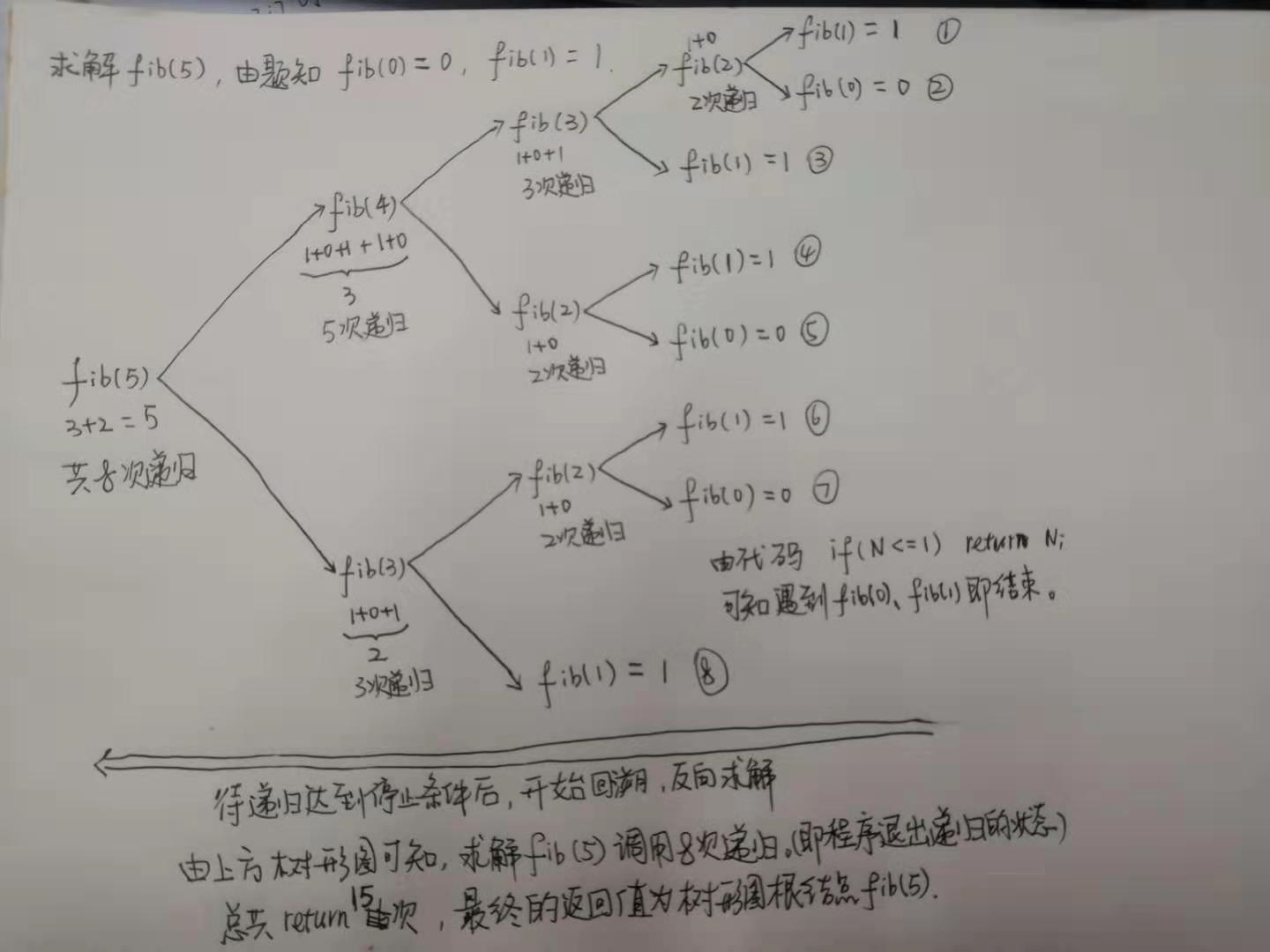
前序遍歷
前序遍歷方式:根節點->左子樹->右子樹。
題目描述(題目序號:144,困難等級:中等):

求解代碼:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public List<Integer> preorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if(root == null) return list; List<Integer> left = preorderTraversal(root.left); List<Integer> right = preorderTraversal(root.right); list.add(root.val); for(Integer l: left) list.add(l); for(Integer r: right) list.add(r);
return list; } }
具體測試實例如下圖:
中序遍歷
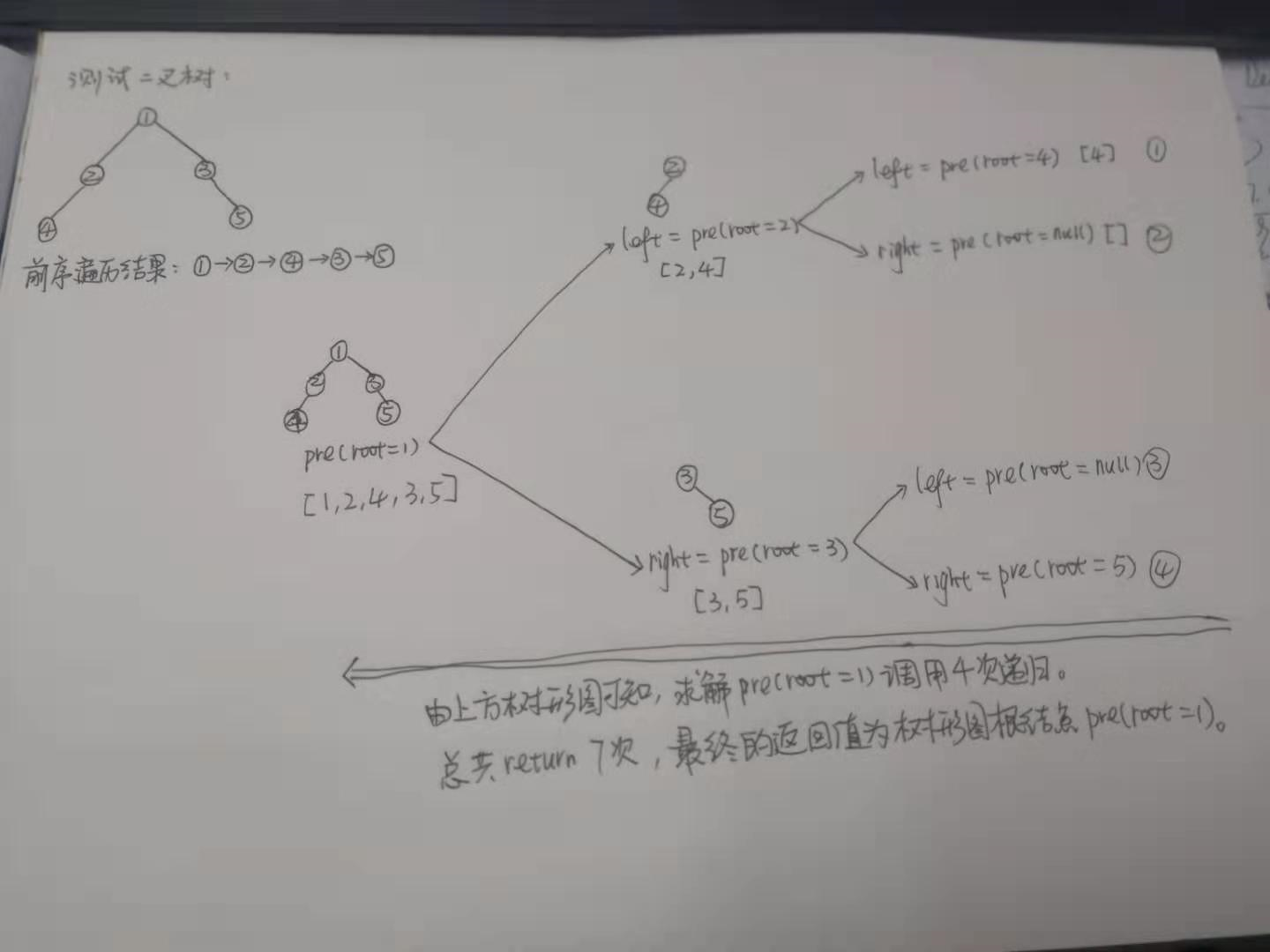
中序遍歷方式:左子樹->根節點->右子樹。
題目描述(題目序號:94,困難等級:中等):

求解代碼:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public List<Integer> inorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if(root == null) return list; List<Integer> left = inorderTraversal(root.left); List<Integer> right = inorderTraversal(root.right); for(Integer l: left) list.add(l); list.add(root.val); for(Integer r: right) list.add(r); return list; } }
具體測試實例如下圖:
後序遍歷
後序遍歷方式:左子樹->右子樹->根節點。
題目描述(題目序號:145,困難等級:困難):

求解代碼:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public List<Integer> postorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if (root == null) return list; List<Integer> left = postorderTraversal(root.left); List<Integer> right = postorderTraversal(root.right); for(Integer l: left) list.add(l); for(Integer r: right) list.add(r); list.add(root.val); return list; } }
具體測試實例如下圖:
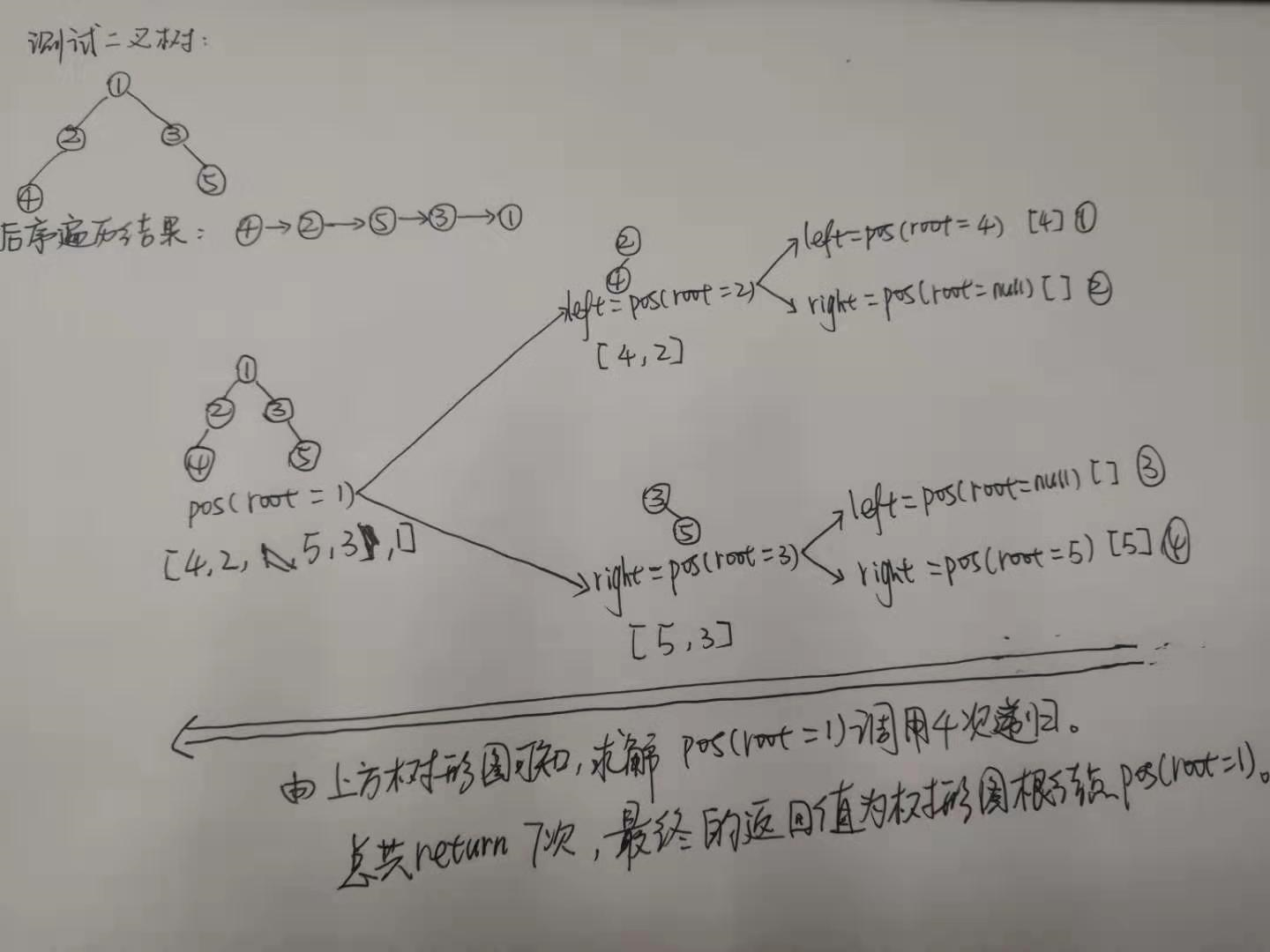
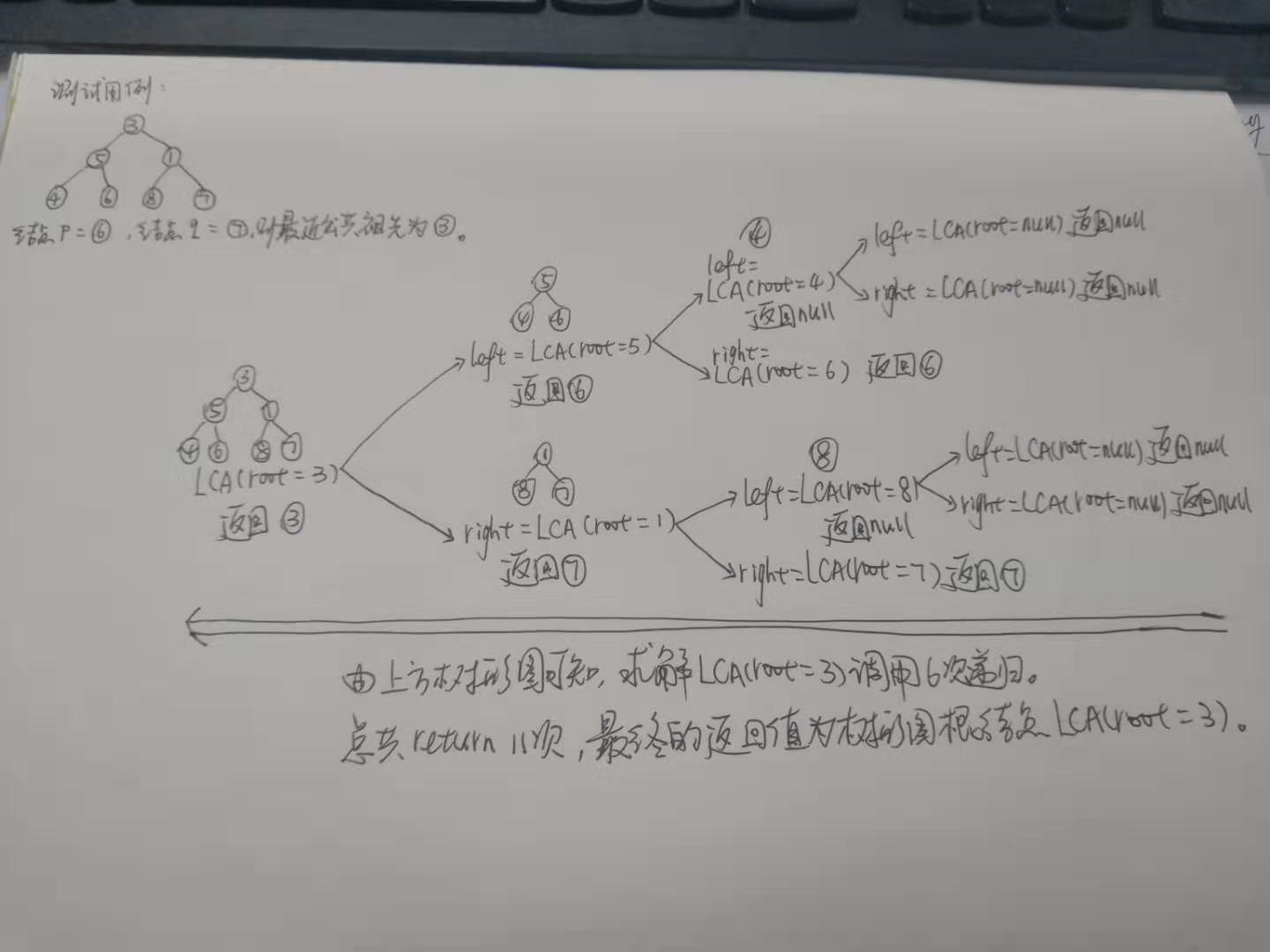
例3求解二叉樹的最近公共祖先
題目描述(題目序號:236,困難等級:中等):

求解思路:
遞歸終止條件:
(1) 根節點為空
(2) 根節點為指定的兩個節點之一
遞歸方式:
在根節點的左子樹中尋找最近公共祖先。
在根節點的右子樹中尋找最近公共祖先。
如果左子樹和右子樹返回值均不為空,說明兩個節點分別在左右子樹,最終返回root。
如果左子樹為空,說明兩個節點均在右子樹,最終返回右子樹的返回值。
如果右子樹為空,說明兩個節點均在左子樹,最終返回左子樹的返回值。
如果左子樹和右子樹均為空,說明該次沒有匹配的結果。
具體代碼如下:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if (root == null) { return root; } if (root == p || root == q) { return root; } TreeNode left = lowestCommonAncestor(root.left, p, q); TreeNode right = lowestCommonAncestor(root.right, p, q); if (left != null && right != null) { return root; } else if (left != null) { return left; } else if (right != null) { return right; } return null; } }
具體測試實例如下圖:
求解遞歸算法的時間複雜度和空間複雜度
以上一節例1斐波那契數列為例。
時間複雜度
時間複雜度一般可以理解為程序運行調用的次數。在應用遞歸解題過程中,如果當前遞歸運行過程中,相關求解過程的運行時間不受變量影響,且運行時間是常數量級,則該算法的時間複雜度為遞歸的總體返回次數。
以上一節例1中解題思路,求解fib(5)總共return15次,畫的樹形圖包含5層。那麼求解例1中示例解答程序代碼的時間複雜度,就是求解樹形圖的整體節點個數。對於n層滿二叉樹,共有2^n – 1個節點,所以求解fib(n),大約需要返回(2^n – 1)次,才能得到最終的根節點值。那麼,fib(n)的時間複雜度為O(2^n)。
空間複雜度
遞歸算法的空間複雜度一般與遞歸的深度有關。一般來說,如果當前遞歸運行過程中,消耗的空間複雜度是一個常數,那麼該算法的最終空間複雜度即為遞歸的深度。計算方式:遞歸的深度*一次遞歸的空間複雜度。
遞歸的運行狀態,隨着運行深度的增加,系統會把上一次的狀態存入系統棧中,一旦遇到遞歸終止條件,便開始不斷出棧,直到棧為空時,程序結束。所以,遞歸程序的空間複雜度一般和遞歸的深度有關。
以上一節例1中解題思路,求解fib(5)時,需要最深的層次需要經歷以下過程:
第一層:fib(5) = fib(4) + fib(3)
第二層:fib(4) = fib(3) + fib(2)
第三層:fib(3) = fib(2) + fib(1)
第四層:fib(2) = fib(1) + fib(0)
第五層:fib(1),遇到遞歸終止條件,開始進行出棧操作。
可知求解fib(5)時,遞歸的深度為5,具體可對照例1中畫的二叉樹,正好等於二叉樹的高度。那麼求解fib(n)的空間複雜度為O(n)。
如何把遞歸用到解題中(尋找遞推關係,或者遞推公式)
例4字符串的反轉
題目描述(題目序號:344,困難等級:簡單):

遞推關係:reverse(s[0,n]) = reverse(s[1,n-1])
具體代碼如下:
class Solution { public void reverseString(char[] s) { dfs(s, 0, s.length-1); } public void dfs(char[] s, int start, int end) { if(start > end) return; dfs(s, start+1, end-1); char temp = s[start]; s[start] = s[end]; s[end] = temp; } }
例5兩兩交換鏈表中的節點
題目描述(題目序號:24,困難等級:中等):
遞推關係:swapPairs(head) = swapPairs(head.next.next)
具體代碼如下:
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode(int x) { val = x; } * } */ class Solution { public ListNode swapPairs(ListNode head) { if(head == null || head.next == null){ return head; } ListNode next = head.next; head.next = swapPairs(next.next); next.next = head; return next; } }
例6 所有可能的滿二叉樹
題目描述(題目序號:894,困難等級:中等):
遞推關係: allPossibleFBT(N) = allPossibleFBT(i) + allPossibleFBT(N – 1 – i),其中i為奇數,1<= i<N。
具體代碼如下:
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public List<TreeNode> allPossibleFBT(int N) { List<TreeNode> ans = new ArrayList<>(); if (N % 2 == 0) { return ans; } if (N == 1) { TreeNode head = new TreeNode(0); ans.add(head); return ans; } for (int i = 1; i < N; i += 2) { List<TreeNode> left = allPossibleFBT(i); List<TreeNode> right = allPossibleFBT(N - 1 - i); for (TreeNode l : left) { for (TreeNode r : right) { TreeNode head = new TreeNode(0); head.left = l; head.right = r; ans.add(head); } } } return ans; } }
記憶化操作
由第一節例1的解答代碼可知,求解fib(n)的時間複雜度為O(2^n),其中進行了大量重複求值過程,比如求解fib(5)時,需要求解兩次fib(3),求解三次fib(2)等。那麼如何避免重複求解的過程呢?我們可以採用記憶化操作。
記憶化操作就是把之前遞歸求解得到的返回值保存到一個全局變量中,後面遇到對應的參數值,先判斷當前全局變量中是否包含其解,如果包含則直接返回具體解,否則進行遞歸求解。
例1:
原解答代碼:
class Solution { public int fib(int N) { if(N <= 1) return N; return fib(N - 1) + fib(N - 2); } }
時間複雜度為O(2^n),空間複雜度為O(n)。提交測試結果:
採用記憶化改進:
class Solution { private Map<Integer, Integer> map = new HashMap<>(); public int fib(int N) { if(N <= 1) return N; if(map.containsKey(N)) return map.get(N); int result = fib(N - 1) + fib(N - 2); map.put(N, result); return result; } }
具體遞歸應用測試示例如下圖:
時間複雜度為O(n),空間複雜度為O(n)。提交測試結果:

求解斐波那契數列,還有多種方法,比如矩陣乘法、數學公式直接計算等。所以,採用記憶化改進的代碼並不是最優,這點在本文不作詳細討論。
尾遞歸
尾遞歸是指在返回時,直接返回遞歸函數調用的值,不做額外的運算。比如,第一節中斐波那契數列的遞歸是返回: return fib(N-1) + fib(N-2);。返回時,需要做加法運算,這樣的遞歸調用就不屬於尾遞歸。
下面解釋引用自LeetCode解答
尾遞歸的好處是,它可以避免遞歸調用期間棧空間開銷的累積,因為系統可以為每個遞歸調用重用棧中的固定空間。
在尾遞歸的情況下,一旦從遞歸調用返回,我們也會立即返回,因此我們可以跳過整個遞歸調用返回鏈,直接返回到原始調用方。這意味着我們根本不需要所有遞歸調用的調用棧,這為我們節省了空間。
尾遞歸的優勢可以通俗的理解為:降低算法的空間複雜度,由原來應用棧存儲中間狀態,變換為不斷直接返回最終值。
通常,編譯器會識別尾遞歸模式,並優化其執行。然而,並不是所有的編程語言都支持這種優化,比如 C,C++ 支持尾遞歸函數的優化。另一方面,Java 和 Python 不支持尾遞歸優化。
剪枝操作
剪枝操作是指在遞歸調用過程中,通過添加相關判斷條件,減少不必要的遞歸操作,從而提高算法的運行速度。一般來說,良好的剪枝操作能夠降低算法的時間複雜度,提高程序的健壯性。下面將以一道算法題來說明。
題目描述(題目序號:698,困難等級:中等):

解題思路:
首先,對原始數組進行從小到大排序操作。
然後,初始化長度為K的數組,每一個元素賦值為sum(nums) / K。
最後,從排序後的數組的最後一個元素開始進行遞歸操作。依次,選擇長度為K的數組中每個元素減去數組中的元素,如果相減的差為0或者小於0則跳過,否則執行正常的相減操作。
剪枝策略:
(1) 如果數組nums中最大元素大於sum(nums) / K,則直接返回,結束程序。
(2) 如果執行當前減法操作得到的結果小於nums數組中最小值,則放棄本次遞歸操作,進行下一次遞歸操作。
具體實現代碼如下(包含剪枝):
class Solution { public boolean canPartitionKSubsets(int[] nums, int k) { int sum = 0; for(int i = 0; i < nums.length; i++){ sum += nums[i]; } if(sum % k != 0){ return false; } sum = sum / k; Arrays.sort(nums); if(nums[nums.length - 1] > sum){ return false; } int[] arr = new int[k]; Arrays.fill(arr, sum); return help(nums, nums.length - 1, arr, k); } boolean help(int[] nums, int cur, int[] arr, int k){ if(cur < 0){ return true; } for(int i = 0; i < k; i++){ //如果正好能放下當前的數或者放下當前的數後,還有機會繼續放前面的數(剪枝) if(arr[i] == nums[cur] || (arr[i] - nums[cur] >= nums[0])){ arr[i] -= nums[cur]; //遞歸,開始放下一個數 if(help(nums, cur - 1, arr, k)){ return true; } arr[i] += nums[cur]; } } return false; } }
測試結果:

將剪枝操作刪除,變成正常的遞歸調用,即把下述代碼:
//如果正好能放下當前的數或者放下當前的數後,還有機會繼續放前面的數(剪枝) if(arr[i] == nums[cur] || (arr[i] - nums[cur] >= nums[0])){
變換成:
if(arr[i] >= nums[cur]){
測試結果:

由上述對比分析可知,靈活運用剪枝操作可以有效提高程序的運行效率。

