【python數據分析實戰】電影票房數據分析(一)數據採集
- 2019 年 10 月 27 日
- 筆記
本文是爬蟲及可視化的練習項目,目標是爬取貓眼票房的全部數據並做可視化分析。
1、獲取url
我們先打開貓眼票房http://piaofang.maoyan.com/dashboard?date=2019-10-22 ,查看當日票房信息,
但是在通過xpath對該url進行解析時發現獲取不到數據。
於是按F12打開Chrome DevTool,按照如下步驟抓包
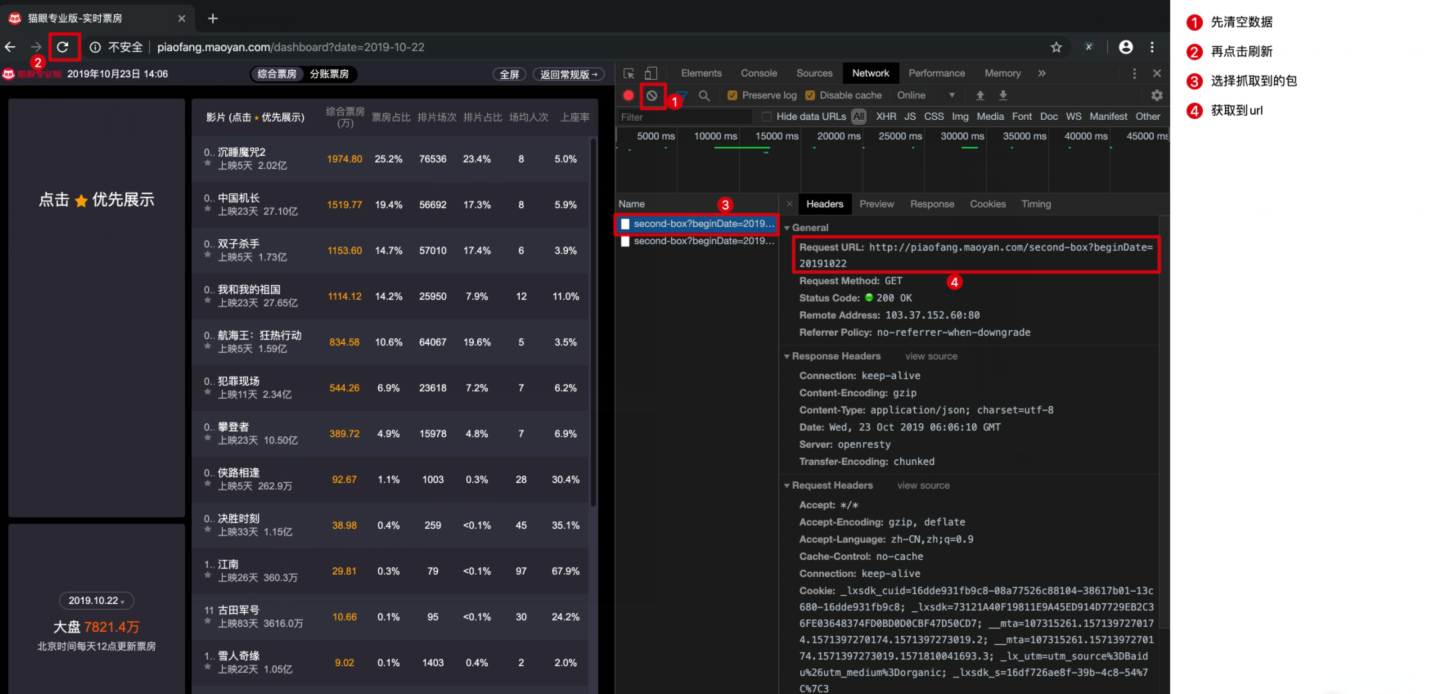
再打開獲取到的url:http://pf.maoyan.com/second-box?beginDate=20191022
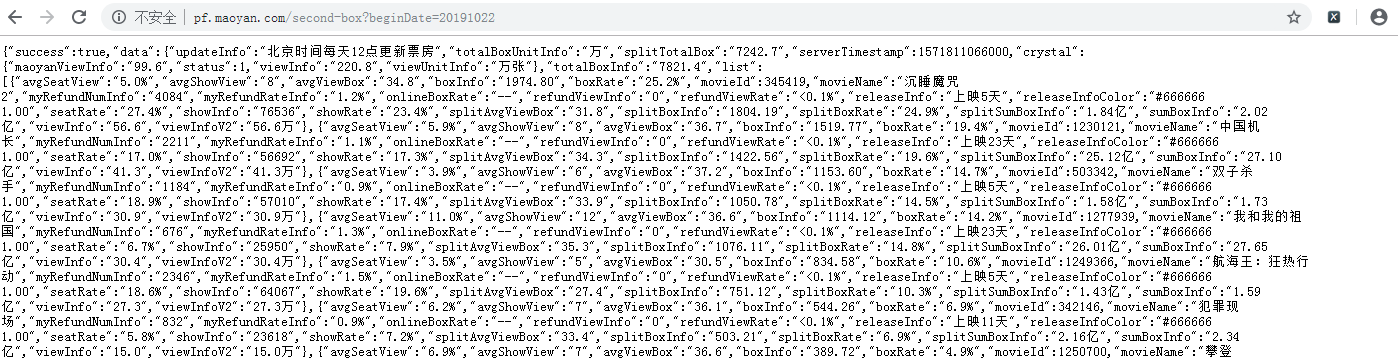
可以看到是json數據,並且url是以日期結尾的,也就是每日的票房數據都保存在對應日期的url中,這樣我們就可以通過構造url來爬取每天的票房數據。
2、開始採集
先創建了兩個函數,
一個用來獲取制定年份的所有日期,例如,傳入2019,返回[‘20190101’, ‘20190102’…’20191230′, ‘20191231’]。
當然也可以傳入多個年份的列表,如[2016,2017,2018′],返回 [‘20160101′,’20160102′, …’20170101′,…’20180101′,…’20181231’]
這裡沒有使用任何庫,用笨方法手動構造了全年的日期列表。
def get_calendar(years): """ 傳入年份(可用list傳入多個年份),得到年份中的所有日期 :param years: 可傳入list、int、str :return: 年份中全部日期的list,日期格式: "2019-09-30" """ mmdd = [] # 判斷傳入參數的格式,如果是list則排序,如果是str或int則轉為list if isinstance(years, list): years.sort() else: years = [int(years)] # 先為每個月都加入31天,然後刪掉2,4,6,9,11的31日和2月的30日,再判斷閏年來刪掉2月29日 for year in years: for m in range(1, 13): for d in range(1, 32): mmdd.append(str(year) + str(m).zfill(2) + str(d).zfill(2)) for i in [2, 4, 6, 9, 11]: mmdd.remove(str(year) + str(i).zfill(2) + "31") mmdd.remove(str(year) + "0230") if not calendar.isleap(year): mmdd.remove(str(year) + "0229") return mmdd第二個函數很簡單,傳入上一個函數得到的日期列表,返回對應日期的url列表。
def get_urls(datas): """ 通過日曆函數得到的每年全部日期,構造出全部日期的url :param datas: 全部日期 :return: 全部url """ urls = [] for date in datas: url = "http://pf.maoyan.com/second-box?beginDate={}".format(date) urls.append(url) return urls 3、存入mysql
對於將數據存到mysql還是excel中,差別只在於寫入的方法不同,前面對url的解析以及對數據的處理和獲取都基本相同,
所以這裡直接把存入mysql和存入excel寫到了一個函數中,和後面的兩個函數分別配合完成數據儲存操作。
參數說明和判斷儲存方式在函數注釋里寫的很詳細,這裡簡單說一下函數邏輯,
因json里的數據項很多,並且都以英文作為key,所有我們這裡先手動創建要獲取的數據項的中英文對照表,放到dict中,並根據這個dict來匹配主要的數據項。
最終返回一個由字典組成的list,返回的list其實沒什麼用,因為後面可視化的數據來源是直接通過sql取自mysql的,所以返回的list主要是調試時用着方便。
def get_movie_data(url, excel_or_db): """ 採集一個頁面,並將數據寫入excel或數據庫, 需要在函數外創建excel工作薄和工作表或連接好數據庫,將worksheet或Connection類作為參數傳入本函數 如果傳入的是worksheet類,函數會把數據保存到已創建excel中; 如果傳入的是Connection類,函數會把數據保存在已連接的數據庫的movies_data表中,數據庫表名手動在sql中調整,本函數內1處、get_data_save_db()函數內兩處。 :param url: 要採集的頁面 :param excel_or_db: openxl的worksheet類 或 pymysql的Connection類 :return: 返回頁面的全部數據 """ headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit' '/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'} main_key = {"avgSeatView": "上座率", "avgShowView": "場均人次", "boxInfo": "綜合票房", "boxRate": "票房佔比", "movieId": "影片ID", "movieName": "影片名稱", "releaseInfo": "上映天數", "showInfo": "當日排片場次", "showRate": "排片佔比", "sumBoxInfo": "綜合票房總收入"} # 用於數據分析的主要屬性 html = requests.get(url, headers=headers).text # 獲取頁面信息,得到json對象 result = json.loads(html, encoding="utf-8") # 將json對象轉為python對象 main_data = [] try: page_data = result["data"]["list"] # 獲取其中可用的數據部分,得到 [{電影1數據}, {電影2數據}, ...] if isinstance(excel_or_db, openpyxl.worksheet.worksheet.Worksheet): for dt in page_data: # 對頁面數據進行循環,匹配main_key中的主要屬性,將數據放到main_data中, one_movie_data = {"日期": url[-8:]} # 先把日期放入字典中 for key in main_key.keys(): one_movie_data[main_key[key]] = dt[key] # 將原數據的英文屬性名,對照main_key轉成中文 excel_or_db.append(list(one_movie_data.values())) main_data.append(one_movie_data) elif isinstance(excel_or_db, pymysql.connections.Connection): for dt in page_data: # 對頁面數據進行循環,匹配main_key中的主要屬性,將數據放到main_data中, one_movie_data = {"日期": url[-8:]} # 先把日期放入字典中 for key in main_key.keys(): one_movie_data[main_key[key]] = dt[key] # 將原數據的英文屬性名,對照main_key轉成中文 cursor = excel_or_db.cursor() sql_insert = '''insert into movies_data15 values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);''' cursor.execute(sql_insert, list(one_movie_data.values())) excel_or_db.commit() cursor.close() main_data.append(one_movie_data) except: pass return main_data因為目標網站數據量較大,為了測試方便,這裡寫了個函數來限制採集數量:達到設定值則結束採集。
def go_limit(year, *, ws, max_line=float("inf")): # float("inf")為無窮大 """ 測試時用於限制爬取條數 :return: """ num = 1 for url in get_urls(get_calendar(year)): if num <= max_line: print(num, get_movie_data(url, ws)) time.sleep(1) num += 1 else: break下面是寫入excel和寫入mysql的函數,寫成函數主要是為了看着簡潔。
def get_data_and_save_excel(): tittles = ['日期', '上座率', '場均人次', '綜合票房', '票房佔比', '影片ID', '影片名稱', '上映天數', '當日排片場次', '排片佔比', '綜合票房總收入'] workbook = openpyxl.Workbook() # 創建工作簿 worsheet = workbook.active # 獲取活躍工作表,即當前默認工作表 worsheet.append(tittles) print(go_limit(2011, ws=worsheet, max_line=20)) # 限制輸出行數,用於測試 # 配置列寬 for index in range(1, len(tittles) + 1): # 將所有列列寬均設為20 worsheet.column_dimensions[get_column_letter(index)].width = 20 workbook.save("data.xlsx")連接數據庫,開始採集,寫入數據庫
這個函數里有一個邏輯錯誤,能找到問題的小夥伴可以在留言里指出。
還有就是sql裡邊包含表名稱,本函數、get_movie_data()採集函數、以及後面的可視化函數,都用到相同的表名稱,如有變動要分別修改,很麻煩,
如果把表名稱作為參數傳遞也很麻煩,每個函數都要傳一次,
可以把表名稱作為全局變量,用外部耦合解決,用增加耦合度來換省事。
def get_data_save_db(years): """ 數據庫表名需要手動在sql中調整,本函數內2處,get_movie_data()函數內1處,3處表名需要保持一致。 """ config = {'host': 'localhost', 'port': 3306, 'user': '***', 'password': '***', 'database': '***', 'charset': 'utf8'} conn = pymysql.connect(**config) # **config是將config字典拆開傳入 cursor = conn.cursor() sql_check = '''drop table if exists movies_data15;''' # 判斷movies_data表是否存在,存在則drop sql_create = '''create table movies_data15(date varchar(8), avgSeatView varchar(8), avgShowView varchar(8), boxInfo varchar(10), boxRate varchar(8), movieId varchar(10), movieName varchar(30), releaseInfo varchar(8), showInfo varchar(8), showRate varchar(8), sumBoxInfo varchar(8), primary key (date, movieID)) DEFAULT CHARSET=utf8;''' # 創建movies_data表 cursor.execute(sql_check) cursor.execute(sql_create) conn.commit() cursor.close() print(go_limit(years, ws=conn)) # print(get_movie_data('http://pf.maoyan.com/second-box?beginDate=20110403', conn)) conn.close() get_data_save_db([i for i in range(2011,2020)]) # 採集2011年至今的所有數據至此電影票房的數據採集工作已完成,接下來要進行數據可視化,
請看《【python數據分析實戰】電影票房數據分析(二)數據可視化》